python自动化爬虫实战
python自动化爬虫实战
偶然的一次机会再次用到爬虫,借此机会记录一下爬虫的学习经历,方便后续复用。
需求:爬取网站数据并存入的csv文件中,总体分为两步
- 爬取网站数据
- 存到到csv文件中
1、配置爬虫环境
1.1、下载自动化测试驱动
由于需要实现模拟手动点击浏览器的效果,因此笔者使用到了chromedriver.exe自动化驱动文件。这里选择谷歌浏览器相同版本的驱动。
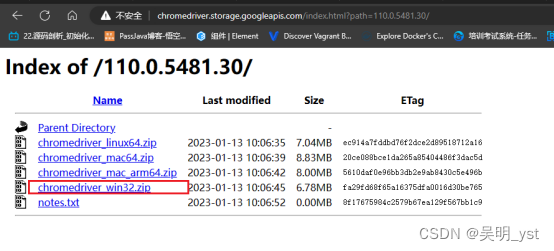
驱动下载中心
比如:笔者浏览器为110版本,因此下载110版本的driver,因为window只有32位,因此不用犹豫直接下载chromedriver_win32.zip文件
1.2、下载需要的库文件
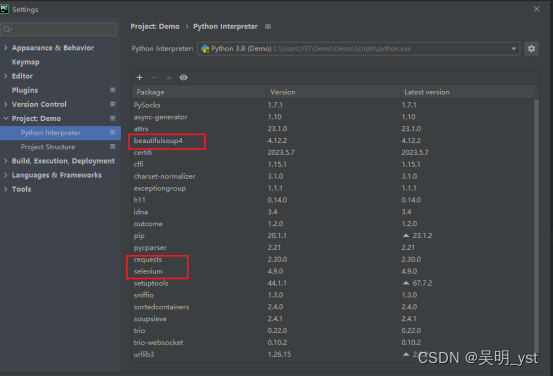
笔者这里用到了:request、 selenium、 beautifulsoup4
在Setting中的Project项目下载对应的库文件
2、编写代码
以上爬虫环境配置完成后,接下来便可以编码了。
爬虫的基本逻辑:
- 配置谷歌浏览器的驱动文件和自动化测试文件
- 创建保存爬取数据的字典和设置读取的起始页码和结束页码
- 判断是否有下一页并进行等待,如果没有下一页则直接退出
- 解析读取到的页面信息
- 保存到csv文件中
根据以上的逻辑,大致就可以理解代码的意思了
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import csv# 1、设置自动化启动的浏览器和浏览器的驱动器
options = Options()
# 设置自己电脑的浏览器启动文件目录
options.binary_location = "C:\\Users\\wuming\\Google\\Chrome\\Application\\chrome.exe"
options.add_argument('–-incognito')
options.add_argument('--disable-infobars')
options.add_argument('--start-maximized')
# 自动化浏览器驱动器
driver = webdriver.Chrome(options=options, service=Service("D:\\chromedriver.exe"))# 2、设置爬取的网站
url = 'https://bj.zu.anjuke.com/fangyuan/'
driver.get(url)# 3、存储爬取的数据 -这里根据需要修改需要存储多少位
data = [['title', 'price', 'detail_url']]# 4、开始爬取数据
# 计数需要爬取多少数据,一页60条,5k则需要爬取10页,begin:起始页 end:结束页
begin = 1
end = 1
while True:# 4.1、等待下一页按钮出现try:next_button = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.LINK_TEXT, '下一页 >')))except:break# 4.2、点击下一页按钮next_button.click()# 判断是否到达结束页,到达则退出if begin > end:breakbegin = begin + 1# 4.3、等待页面加载完成WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'zu-itemmod')))# 4.4、解析页面数据house_list = driver.find_elements(By.CLASS_NAME, 'zu-itemmod')for house in house_list:title = house.find_element(By.TAG_NAME, 'h3').text.strip()price = house.find_element(By.TAG_NAME, 'strong').text.strip()detail_url = house.find_element(By.TAG_NAME, 'a').get_attribute('href')print(title, price, detail_url)# 4.5、向data中添加数据data.append([title, price, detail_url])driver.quit()# 5、将爬取的数据存入csv文件中
with open('D:\\wuming\\data.csv', 'w', newline='') as file:writer = csv.writer(file)for row in data:writer.writerow(row)根据以上代码,相信大家已经可以爬取数据,至于内容的提取,则需要大家各显神通,后面会详细写一篇文章,说一说如何从爬取的网页中获取想要的信息。
相关文章:
python自动化爬虫实战
python自动化爬虫实战 偶然的一次机会再次用到爬虫,借此机会记录一下爬虫的学习经历,方便后续复用。 需求:爬取网站数据并存入的csv文件中,总体分为两步 爬取网站数据存到到csv文件中 1、配置爬虫环境 1.1、下载自动化测试驱动 …...

LVGL-最新版本及其版本定义标准
lvgl的最新版本是9.0.0,处于开发分支中。 稳定版本是8.3.0. 建议一般开发使用稳定版8.3.0. .\lvgl.h定义了当前版本 /*************************** CURRENT VERSION OF LVGL ***************************/ #define LVGL_VERSION_MAJOR 8 #define LVGL_VERSION_MINO…...

ORB_SLAM2算法中如何计算右目和左目两个特征点的是否匹配?
文章目录 if(kpR.octave<levelL-1 || kpR.octave>levelL+1)const int &levelL = kpL.octave;if(uR>=minU && uR<=maxU)const cv::Mat &dR = mDescriptorsRight.row(iR);const int dist = ORBmatcher::DescriptorDistance(dL,dR);筛选最佳匹配特征点…...

Android 12.0系统Settings主页去掉搜索框
1.概述 在12.0定制化开发中,在系统原生设置中主页的搜索框是要求去掉的,不需要搜索功能,所以首选看下布局文件 看下搜索框是哪个布局,然后隐藏到布局,达到实现功能的目的 2.系统Settings主页去掉搜索框的主要代码 packages/apps/Settings/src/com/android/settings/home…...

电脑数据丢失如何恢复
随着电脑使用的日益普及,数据丢失成为了很多用户不得不面对的问题。数据丢失的原因有很多,例如误删除文件、磁盘格式化、电脑病毒等等。一旦发生数据丢失的情况,我们就需要利用专业的数据恢复工具来尽快找回被丢失的数据。下面我们就来详细介…...
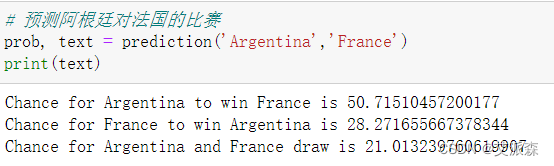
大数据分析案例-基于决策树算法构建世界杯比赛预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

Python 图形界面框架 PyQt5 使用指南
Python 图形界面框架 PyQt5 使用指南 使用Python开发图形界面的软件其实并不多,相对于GUI界面,可能Web方式的应用更受人欢迎。但对于像我一样对其他编程语言比如C#或WPF并不熟悉的人来说,未必不是一个好的工具。 常见GUI框架 PyQt5[1]&#…...
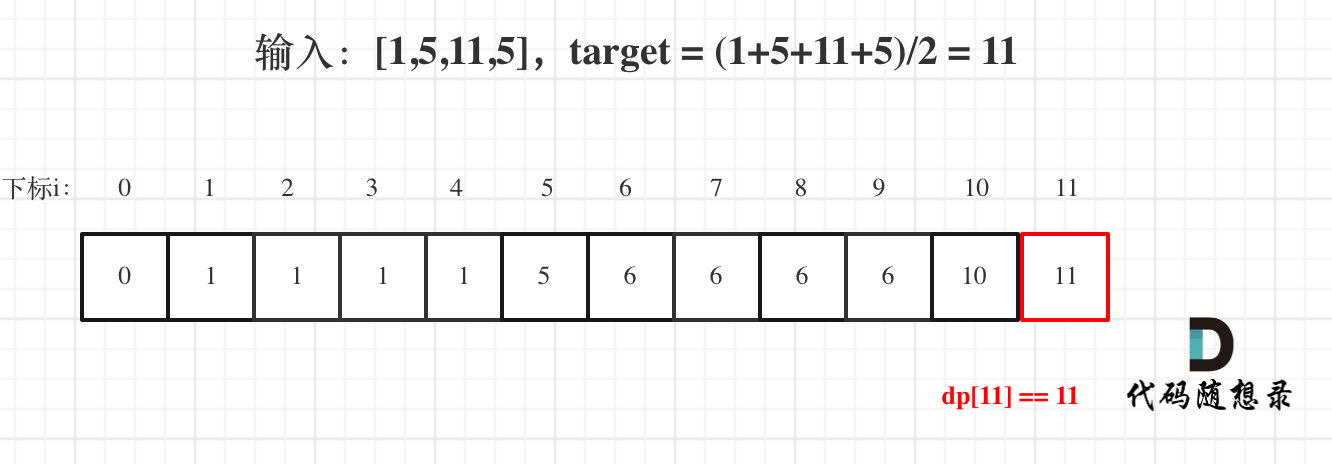
代码随想录算法训练营第四十二天 | 二维dp数组01背包, 力扣 416. 分割等和子集
背包 解析 1.确定dp数组以及下标的含义 对于背包问题,有一种写法, 是使用二维数组,即dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。 2.确定递推公式 有两个方向推出来dp[i][…...
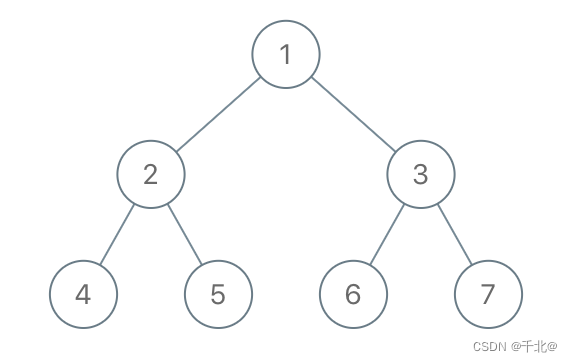
【1110. 删点成林】
来源:力扣(LeetCode) 描述: 给出二叉树的根节点 root,树上每个节点都有一个不同的值。 如果节点值在 to_delete 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的…...

第三章 JVM内存概述
附录:精选面试题 Q:为什么虚拟机必须保证一个类的Clinit( )方法在多线程的情况下被同步加锁 ? A: 因为虚拟机在加载完一个类之后直接把这个类放到本地内存的方法区(也叫原空间)中了,当其他程序再来调这个类…...
基于SpringBoot的企业客户信息反馈平台的设计与实现
背景 企业客户信息反馈平台能够通过互联网得到广泛的、全面的宣传,让尽可能多的用户了解和熟知企业客户信息反馈平台的便捷高效,不仅为客户提供了服务,而且也推广了自己,让更多的客户了解自己。对于企业客户信息反馈而言…...

【SA8295P 源码分析】01 - SA8295P 芯片介绍
【SA8295P 源码分析】01 - SA8295P 芯片介绍 一、Processors 处理器介绍二、Memory 内存介绍三、Multimedia 多媒体介绍3.1 DPU 显示处理器:Adreno DPU 11993.2 摄像头ISP:Spectra 395 ISP3.3 视频处理器:Adreno video processing unit (VPU)3.4 图像处理器:Adreno graphic…...

扩展1:Ray Core详细介绍
扩展1:Ray Core详细介绍 导航 1. 简介和背景2. Ray的基本概念和核心组件3. 分布式任务调度和依赖管理4. 对象存储和数据共享5. Actor模型和并发编程6. Ray的高级功能和扩展性7. 使用Ray构建分布式应用程序的案例研究8. Ray社区和资源9. 核心框架介绍...

day08 Spring MVC
spring MVC相当于Servlet mvc解释:模型,视图,控制器 **使用该思想的作用:**减少耦合性,提高可维护性 Spring MVC前端控制器 方式1 1.在web.xml中配置前端控制器方式2 要是用前端控制器,必须在web.xml中配置DidpatcherServlet类 <!--前端控制器--> <servlet&g…...

c++中的extern “C“
在一些c语言的library库中,我们经常可以还看下面这样的结构 #ifndef __TEST_H #define __TEST_H#ifdef _cplusplus extern "C" { #endif/*...*/#ifdef _cplusplus } #endif #endif#ifndef __TEST_H这样的宏定义应该是非常常见了,其作用是为了…...

python异常处理名称整理
Python 异常处理 python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误。你可以使用该功能来调试python程序。BaseException所有异常的基类UnboundLocalError访问未初始化的本地变量SystemExit...

SpringMVC拦截器
SpringMVC拦截器 介绍 拦截器(interceptor)的作用 SpringMVC的拦截器类似于Servlet开发中的过滤器Filter,用于对处理器 进行预处理和后处理 将拦截器按一定的顺序连接成一条链,这条链称为拦截器链(Interception Ch…...
)
Python第八章作业(初级)
目录 第1关:统计字母数量 第2关:统计文章字符数 第3关:查询高校信息 第4关:查询高校名 第5关:通讯录读取 第6关:JSON转列表 第7关:利用数据文件统计成绩 第8关:研究生录取数据…...

chatgpt赋能python:Python中如何取消列表
Python中如何取消列表 在Python中使用列表是一种非常常见的数据结构,它允许我们在其中存储任意数量的元素,并且可以非常容易地进行遍历和操作。但是,有时候我们需要从列表中删除元素。这个过程并不难,但是有些细节需要注意。本文…...
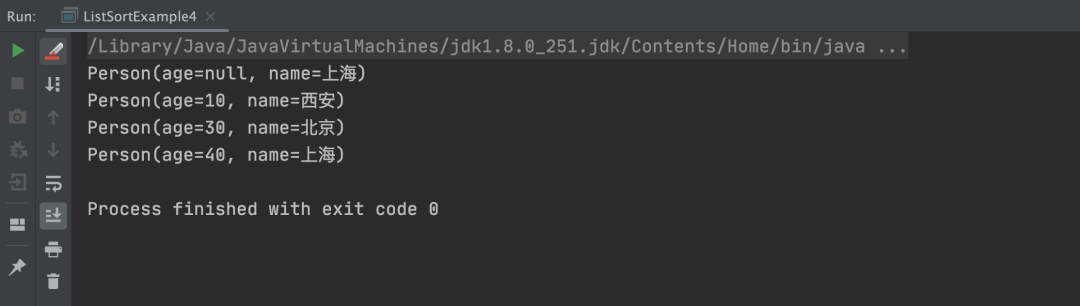
Java中List排序的3种方法
在某些特殊的场景下,我们需要在 Java 程序中对 List 集合进行排序操作。比如从第三方接口中获取所有用户的列表,但列表默认是以用户编号从小到大进行排序的,而我们的系统需要按照用户的年龄从大到小进行排序,这个时候,…...

UNT413A刷机后体验:开机无广告、流畅度飙升,这波操作值不值?
UNT413A刷机实战:从广告轰炸到极简流畅的蜕变之旅 每次打开电视盒子,那段无法跳过的30秒广告就像一场无法避免的仪式。更糟的是,系统卡顿得像是被胶水黏住,预装软件占据了宝贵的存储空间,而官方更新只会让情况变得更糟…...

3步终极解决方案:如何专业卸载Windows 10/11的Microsoft Edge浏览器
3步终极解决方案:如何专业卸载Windows 10/11的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemo…...

Nintendo Switch大气层系统完整教程:从零开始掌握自制系统
Nintendo Switch大气层系统完整教程:从零开始掌握自制系统 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 你是否曾想过,让手中的Nintendo Switch拥有无限可能&…...

告别云服务器:利用家庭宽带公网IPv6,零成本搭建你的专属开发/测试环境
告别云服务器:利用家庭宽带公网IPv6,零成本搭建你的专属开发/测试环境 在云计算成本日益攀升的今天,个人开发者和初创团队常常面临一个两难选择:要么支付高昂的云服务费用,要么忍受本地开发环境的局限性。但很少有人意…...

sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 [特殊字符]
sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 🚀 【免费下载链接】sdk-manager-plugin DEPRECATED Gradle plugin which downloads and manages your Android SDK. 项目地址: https://gitcode.com/gh_mirrors/sd/sdk-manager-plugin …...

Unity开发者为何转向VSCode:效率提升26倍的工程实践
1. 为什么我三年前就彻底卸载了Visual Studio——一个Unity老手的真实效率账在Unity项目里打开Visual Studio,等它加载完所有C#项目、符号、IntelliSense、Rider插件、Resharper缓存、NuGet包索引……这个过程平均耗时47秒——这是我用Stopwatch在2021年到2023年连续…...

【Midscene.js 实战10】集成实战:将 Midscene.js 无缝接入现有的 Playwright / Puppeteer 项目
一、开篇:你的测试代码还扛得住吗? 2026 年 3 月的一个深夜,某跨境电商团队的测试主管在工位前对着屏幕上刺眼的红色报错叹了口气。团队维护了两年、超过 600 个用例的 Playwright 自动化回归套件,因为运营团队改了商品详情页的 DOM 结构,直接挂了 40 多个用例。更让人崩…...

仓内与仓外智能物流设计技术难点
智能物流系统根据空间和边界可划分为仓内物流(Intralogistics)与仓外物流(External Logistics)。两者由于运行环境、控制变量和边界条件的根本差异,面临着截然不同的技术设计难点。一、 仓内智能物流设计技术难点&…...

【Midjourney企业版落地实战指南】:从0到1搭建合规、可控、可审计的AI设计中台
更多请点击: https://intelliparadigm.com 第一章:【Midjourney企业版落地实战指南】:从0到1搭建合规、可控、可审计的AI设计中台 企业引入Midjourney需突破个人账号局限,构建具备身份鉴权、用量管控、内容水印、操作留痕与策略审…...

回归模型评估实战指南:从指标选择到业务决策
1. 这不是“背公式”手册,而是回归模型评估的实战决策地图 你训练完一个房价预测模型,R0.87,MAE2.3万,RMSE3.8万——然后呢?是立刻上线?还是再调参?还是换数据?还是干脆换算法&#…...