MySQL高级查询操作
文章目录
- 前言
- 聚集函数
- 分组查询:GROUP BY
- 过滤:HAVING
- 嵌套子查询
- 比较运算中使用子查询
- 带有IN的子查询
- SOME(子查询)
- ALL(子查询)
- EXISTS子查询
前言
查询语句书写顺序:
1、select
2、from
3、where
4、group by
5、having
6、order by
7、limit
查询语句执行顺序:
数据库的时候先执行from,确定数来自哪张表
再执行where,看看哪些行需要查询
再执行group by,确定是否分组
再执行having,过滤掉不要的组
然后是select,再确定查询哪些列
随后是order by排序
最后是limit限定
聚集函数
聚集函数(也叫集合函数),方便用户统计一些数据。
COUNT(*): 统计表中元组个数;
COUNT(列名):统计本列列值个数;
SUM(列名):计算列值总和(必须是数值型列);
AVG(列名):计算列值平均值(必须是数值型列);
MAX(列名):最大、最高;
MIN(列名):最小、最低。
max和min可以统计数字型数据、字符型数据、日期型数据
【例】查询最高最低的学生成绩
SELECT MAX(score),MIN(score)
FROM stu
sum和avg只适用于数字型数据
【例】统计全部学生的平均成绩
SELECT AVG(score)
FROM stu
count(*)返回表中满足条件的行数
其中*也可以写具体的列名,但是空值不统计
【例】统计老师的总人数
SELECT COUNT(*)
FROM teacher
查询工作在HK的员工人数,最高工资及最低工资
SELECT count(*) AS 员工人数,max(sal) AS 最高工资,min(sal) AS 最低工资
FROM emp e JOIN dept d
ON e.deptno = d.deptno
WHERE loc='HK';
聚合函数不能出现在 WHERE 子句中
分组查询:GROUP BY
当有每个、每组的时候需要分组
SQL语句中使用了分组查询group by,在select子句中就要使用分组统计函数
在select语句中查询分组的列
【例】查每个班级编号,平均成绩,进行分组
SELECT classid,AVG(score)
FROM stu
GROUP BY classid;
【例】统计每个出版社的出版图书的数目
分析:如果能够将所有的图书,按照出版社的名称进行分组,然后我们在统计每一组的元组的个数,我们就能能到得到期望的数据。
比如book表中字段有:bookid,name,author,public,price
可以使用GROUP BY <列名>进行分组
在<列名>上值相同的元组被分在一组,该列称为分组依据列。
然后可以使用聚集函数统计每一组的数据。
SELECT COUNT(*) , publish FROM book
GROUP BY publish
【例】统计每个人所借图书的数目。
SELECT COUNT(bookid), Reader_id
FROM Borrow
GROUP BY Reader_id
Having COUNT(bookid)>2
【例】统计每个出版社出版图书的平均价格,并显示每个出版社的名称
SELECT publish, AVG(price) AS 平均价格
FROM book
GROUP BY publish
【例】统计每个岗位和部门都相同的人数
SELECT deptno,job,COUNT(*) AS 人数
FROM emp
GROUP BY deptno,job;
过滤:HAVING
HAVING必须写在GROUP BY后面,ORDER BY前面,HAVING后面也是写条件的(和where相近)
HAVING子句用于过滤掉不满足条件的分组数据,HAVING 子句用于对分组统计后的结果进行筛选。满足HAVING 子句条件将会保留在结果中
WHERE子句中编写的是过滤筛选数据行的条件
HAVING子句是使用分组统计函数的
【例】查询出版图书平均价格高于30元的出版社名称,并显示其图书平均价格。
SELECT publish,AVG(price) FROM book
GROUP BY publish
HAVING AVG(price)>30
【例】查询出版图书多于2本的出版社名称和出版图书数目
SELECT publish, COUNT(*) FROM book
GROUP BY publish
HAVING COUNT(*)>2
【例】查询部门编号,岗位,平均工资,其中岗位在销售、经理、职员之中,把岗位和部门都相同的分在一组,保留平均工资高于1000的,平均工资按降序排列
SELECT deptid,job,AVG(sal) AS 平均工资
FROM emp
WHERE job in('salesman','manager','clerk')
GROUP BY deptid,job
HAVING avg(sal)>1000
ORDER BY 平均工资 DESC;
【例】查询部门人数大于2的部门编号,部门名称,部门人数。
员工表内字段:deptid
部门表内字段:deptid,dname
SELECT d.deptid,dname,count(*)
FROM emp e JOIN dept d
ON e.deptid = d.deptid
GROUP BY d.deptno
HAVING COUNT(*)>2;
【例】查询部门平均工资大于2000,且人数大于2的部门编号,部门名称,部门人数,部门平均工资,并按照部门人数升序排序。
员工表内字段:deptid,sal
部门表内字段:deptid,dname
SELECT d.deptid,dname,COUNT(*),avg(sal)
FROM emp e,dept d
WHERE e.deptid=d.deptid
GROUP BY d.deptid
HAVING avg(sal)>2000
AND COUNT(*)>2
ORDER BY COUNT(*);
嵌套子查询
括号内的查询叫做子查询,也叫内部查询,当条件不知道的时候用子查询
嵌套子查询就是子查询里面有个子查询
NOT IN后面的子查询要确保结果里不能包含空值(IS NOT NULL)
执行顺序:先内层后外层;先查子查询后查主查询
相关子查询运行时和主查询查询的表有关联,使用了主查询表某些列数据
【例】查询成绩最低的学生姓名和学号
解题思路:先写大框,最后写括号里面的东西(查询所有学生里面最低的成绩),变成填空题写
SELECT sname,stuid
FROM stu
WHERE score=(SELECT MIN(score) FROM stu);
【例】查询入学日期比二班入学日期最早的学生还要早的学生姓名,入学日期
SELECT sname,studate
FROM stu
WHERE studate<(SELECT min(studate) FROM stu WHERE classid=2);
比较运算中使用子查询
【例】查询成绩最好的学生的姓名
SELECT name FROM Student
WHERE Score =(SELECT MAX(Score) FROM Student)
带有IN的子查询
【例】查询与"C语言"在同一出版社的图书信息
SELECT * FROM Book WHERE publish
IN (SELECT publish FROM Book WHERE name='C语言')
【例】查询张三所借图书的图书编号
SELECT book_ID FROM Borrow
WHERE reader_ID IN (SELECT reader_ID FROM Reader WHERE name='张三')
【例】查询"张三"所借的图书的名称
SELECT name FROM Book
WHERE book_ID IN(SELECT book_ID FROM Borrow
WHERE reader_ID IN (SELECT reader_ID FROM Reader WHERE name='张三'))
查询过程:
第1步,查询 “张三” 的reader_ID。
第2步,依据 reader_ID在Borrow表中找张三所借图书的book_ID
第3步,依据 book_ID在Book表中找到图书名称。
【例】查询借书价格在20-40之间的读者的姓名
select name from reader
where reader_id in(select reader_id from borrow where book_id in( select book_id from book where price between 20 and 40))
查询张三 ‘借阅’ 计算机文化基础’的日期
select borrowdate from borrow
where reader_id in(select reader_id from reader where name='张三')and book_id in(select book_id from book where name='计算机文化基础')
查询借书价格在20-40之间的读者的姓名
select name from reader where reader_id in(select reader_id from borrow where book_id in(select book_id from book where price between 20 and 40))
SOME(子查询)
表示子查询的结果集合中某一个元素
【例】查询除不是最低价格外的所有图书
SELECT * FROM Book
WHERE price>SOME(SELECT price FROM Book)
【例】查询价格最低的图书信息
SELECT * FROM Book
WHERE NOT(price>SOME(SELECT price FROM Book))
ALL(子查询)
表示子查询的全部结果
【例】查询书价最高的图书的信息
SELECT * FROM Book
WHERE price >=ALL(SELECT price FROM Book)
【例】查询评价书价最高的出版社名称
SELECT * FROM Book
GROUP BY public
HAVING AVG(price)>=ALL(SELECT AVG(price) FROM BookGROUP BY public)
EXISTS子查询
判断子查询是否存在结果
当子查询存在结果时,EXISTS(子查询)返回值为true,否则返回值为false。
先外层查询,后内层查询;
将外层的值代入内层进行查询,根据内层查询是否存在结果,判断外层的元组是否保留在结果集中。
【例】查询借阅了图书的读者的姓名
SELECT name FROM reader WHERE
EXISTS ( SELECT * FROM borrow WHERE
borrow.reader_id=reader.reader_id)
【例】查询被借出的图书的信息
SELECT * FROM Book
WHERE EXISTS(SELECT * FROM Borrow WHERE Borrow.book_ID=Book.book_ID)
相关文章:

MySQL高级查询操作
文章目录 前言聚集函数分组查询:GROUP BY过滤:HAVING嵌套子查询比较运算中使用子查询带有IN的子查询SOME(子查询)ALL(子查询)EXISTS子查询 前言 查询语句书写顺序: 1、select 2、from 3、where 4、group by 5、having 6、order by 7、limit …...
Day53【动态规划】1143.最长公共子序列、1035.不相交的线、53.最大子序和
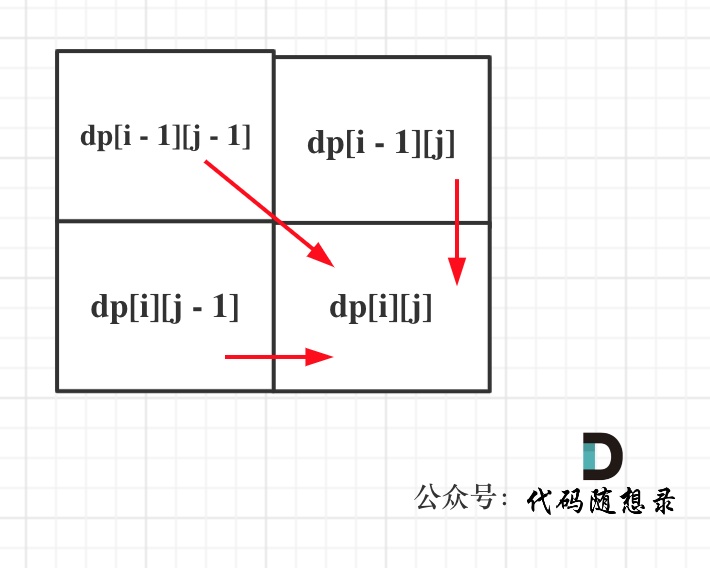
1143.最长公共子序列 力扣题目链接/文章讲解 视频讲解 本题最大的难点还是定义 dp 数组 本题和718.最长重复子数组区别在于这里不要求是连续的了,但要有相对顺序 直接动态规划五部曲! 1、确定 dp 数组下标及值含义 dp[i][j]:取 text1…...

Three.js--》实现3d地球模型展示
目录 项目搭建 实现网页简单布局 初始化three.js基础代码 创建环境背景 加载地球模型 实现光柱效果 添加月球模型 今天简单实现一个three.js的小Demo,加强自己对three知识的掌握与学习,只有在项目中才能灵活将所学知识运用起来,话不多…...
<SQL>《SQL命令(含例句)精心整理版(6)》
《SQL命令(含例句)精心整理版(6)》 18 DB2查询语句18.1 查询数据库大小18.2 查看表占表空间大小18.3 查看正在执行的语句18.4 db2expln 查看执行计划18.5 db2advis 查看优化建议 19 空值19.1 NULL19.2 TRIM 18 DB2查询语句 18.1 …...
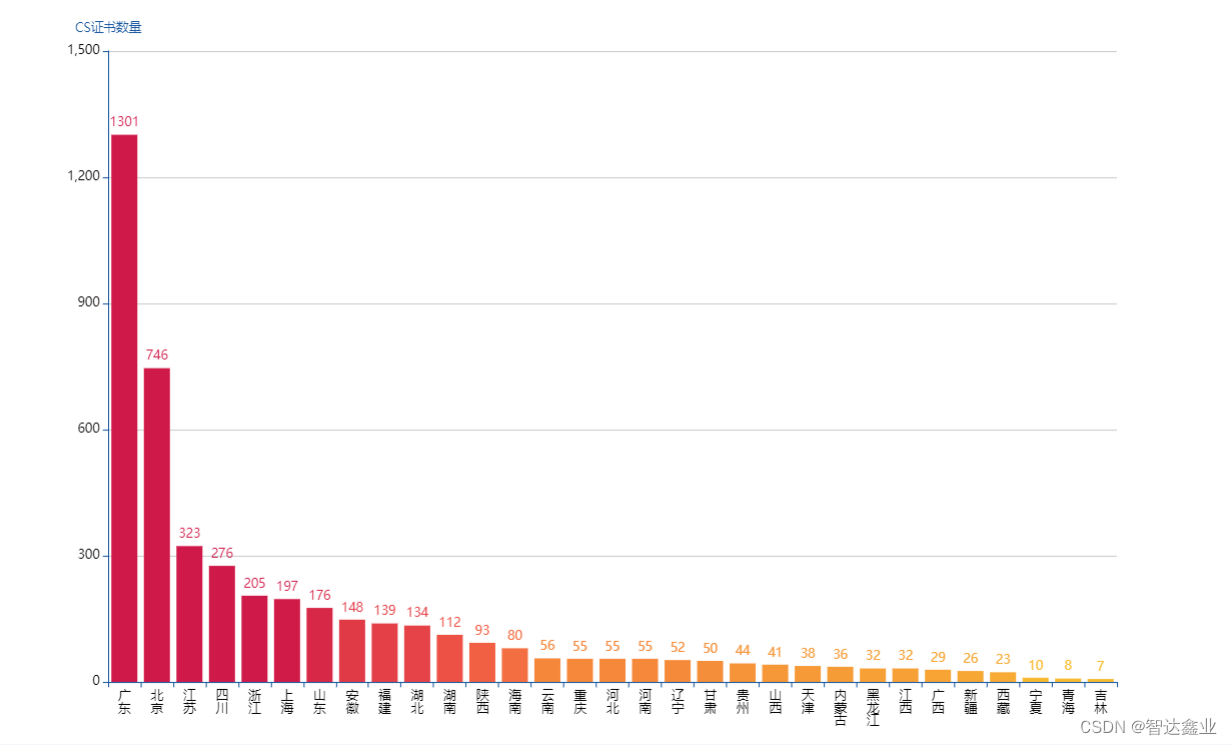
信息系统建设和服务能力评估证书CS
信息系统建设和服务能力评估体系CS简介 简介:本标准(团标T/CITIF 001-2019)是信息系统建设和服务能力评估体系系列标准的第一个,提出了对信息系统建设和服务提供者的综合能力要求。 发证单位:中国电子信息行业联合会。…...

vue3引入路由
1.首先在项目中安装路由 npm install vue-router -S 2.src文件夹下新建》views文件夹》新建home文件夹》新建Home.vue文件 在src文件夹下》新建router文件夹》新建index.js import { createRouter,createWebHashHistory } from vue-router const route s[ { path:/, compo…...
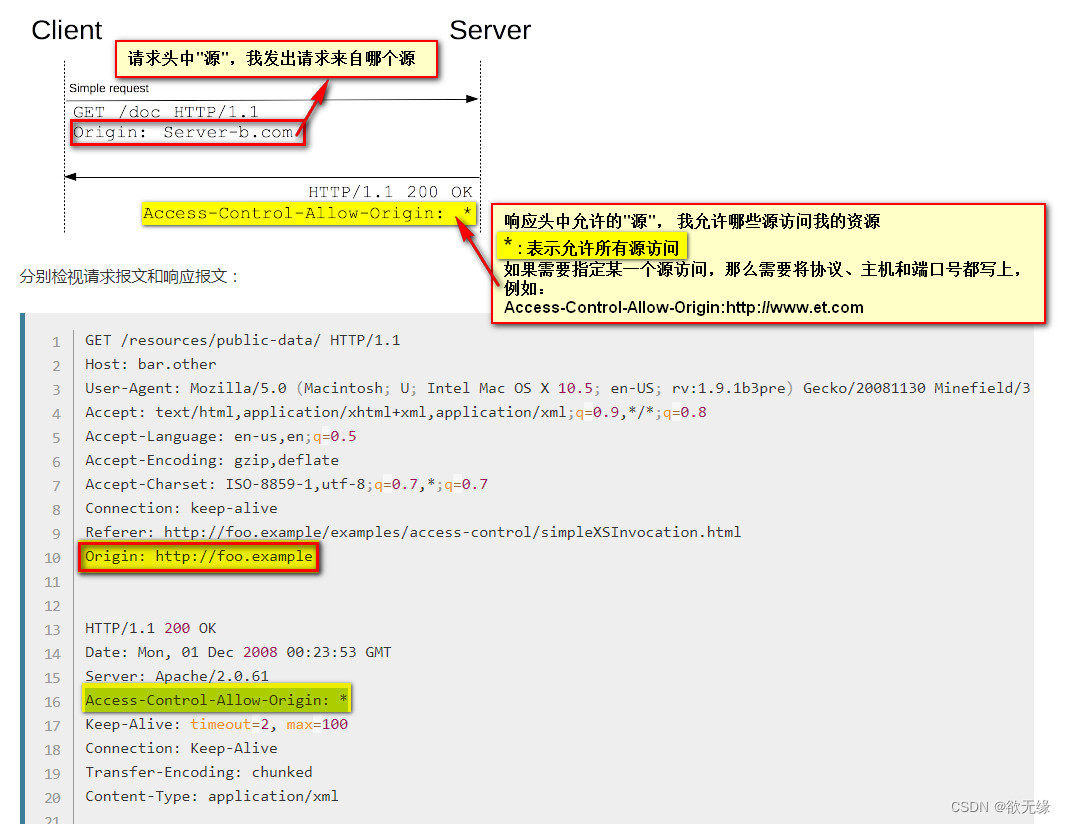
前后端联调跨域问题
文章目录 什么是同源策略如何判断是否同源?跨域资源共享(CORS)如何解决跨域问题 什么是同源策略 同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。 如何判断是否同源? 如果…...
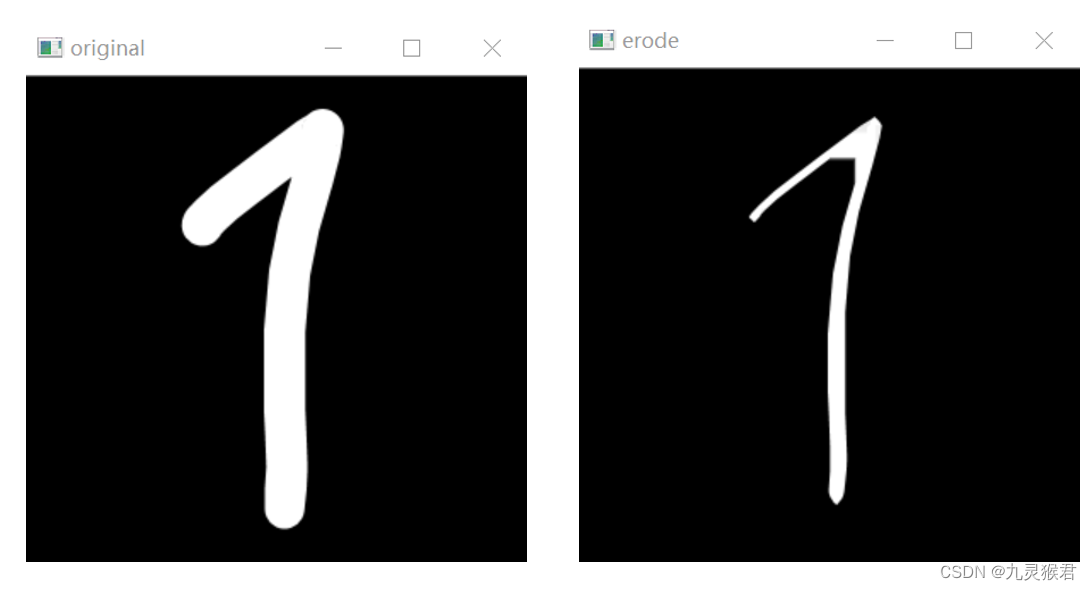
day11 - 手写数字笔迹细化
手写数字笔迹细化 对于手写数字识别实验中,经常会遇到因为笔迹较粗导致误识别的情况,所以我们通常会先将笔迹进行细化,笔迹变细以后,数字的特征会更明显,后续进行识别的准确率就会更高。 例如数字7 和 1 ,…...

C++ QT QDBus基操
以下是使用QDBus进行跨进程通信的具体用法: 1. 创建DBus服务 在服务端进程中,需要创建一个DBus服务,并注册DBus对象。示例代码如下: #include <QDBusConnection> #include <QDBusMessage> #include <QDBusInterf…...
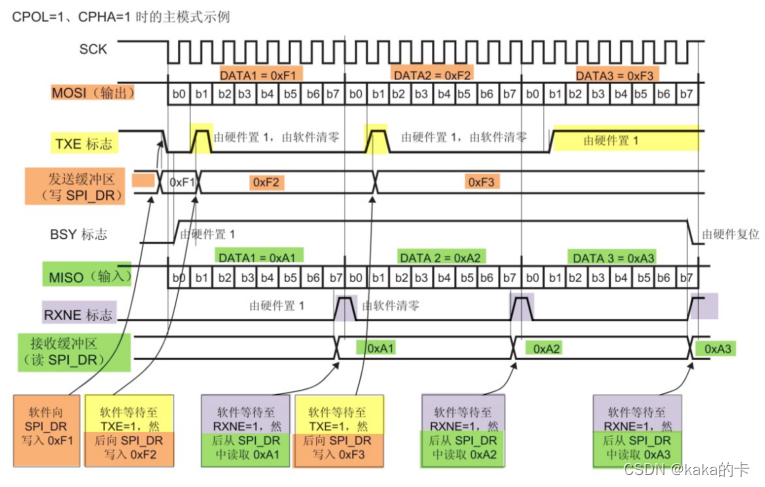
STM32的SPI外设
文章目录 1. STM32 的 SPI 外设简介2. STM32 的 SPI 架构剖析2.1 通讯引脚2.2 时钟控制逻辑2.3 数据控制逻辑2.4 整体控制逻辑 3. 通讯过程4. SPI 初始化结构体详解 1. STM32 的 SPI 外设简介 STM32 的 SPI 外设可用作通讯的主机及从机,支持最高的 SCK 时钟频率为 …...

VMWare ESXI6.7创建虚拟机
VMware ESXi:专门构建的裸机 管理程序 首先开启ESXI主机 登录ESXI 打开浏览器输入物理机ip,输入账号密码进行登录 创建虚拟机 选择创建类型 创建RedHat7.6 选择存储类型和数据存储 仅一个存储,直接点下一页即可 配置虚拟机硬件和虚拟机附…...
TensorFlow 1.x学习(系列二 :4):自实现线性回归
目录 线性回归基本介绍常用的op自实现线性回归预测tensorflow 变量作用域模型的保存和加载 线性回归基本介绍 线性回归: w 1 ∗ x 1 w 2 ∗ x 2 w 3 ∗ x 3 . . . w n ∗ x n b i a s w_1 * x_1 w_2 * x_2 w_3 * x_3 ... w_n * x_n bias w1∗x1w2∗…...

Openwrt折腾记6-网络摄像头
前言: 前几天买了个电视机上的摄像头,但是估计是电视配置或软件不好,视频通话太卡顿。今天把它装的极路由4的usb上了。由于当初挑的是电视免驱的,所以我猜想是通用的芯片。 调查驱动 LINUX uvc支持型号的列表里 http://www.ide…...
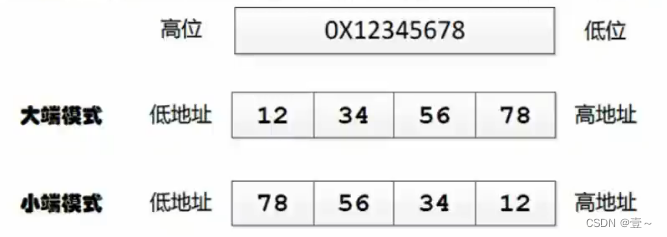
C++判断大端小端
C判断大端小端 1. 基础知识 大端小端其实表示的是数据在存储器中的存放顺序。 大端模式:数据的高字节存放在内存的低地址中,而低字节则存放在高地址中。地址由小到大增加,数据则从高位向低位存放,这种存放方式符合人类的正常思维…...

K8S RBAC之Kubeconfig设置用户权限,不同的用户访问不同的namespace
1.CA签发客户端证书 检查证书是否存在 # ll /etc/kubernetes/pki/ 总用量 48K -rw-r----- 1 kube root 2.1K 3月 2 16:44 apiserver.crt -rw------- 1 kube root 1.7K 3月 2 16:44 apiserver.key -rw-r----- 1 kube root 1.2K 3月 2 16:44 apiserver-kubelet-client.cr…...
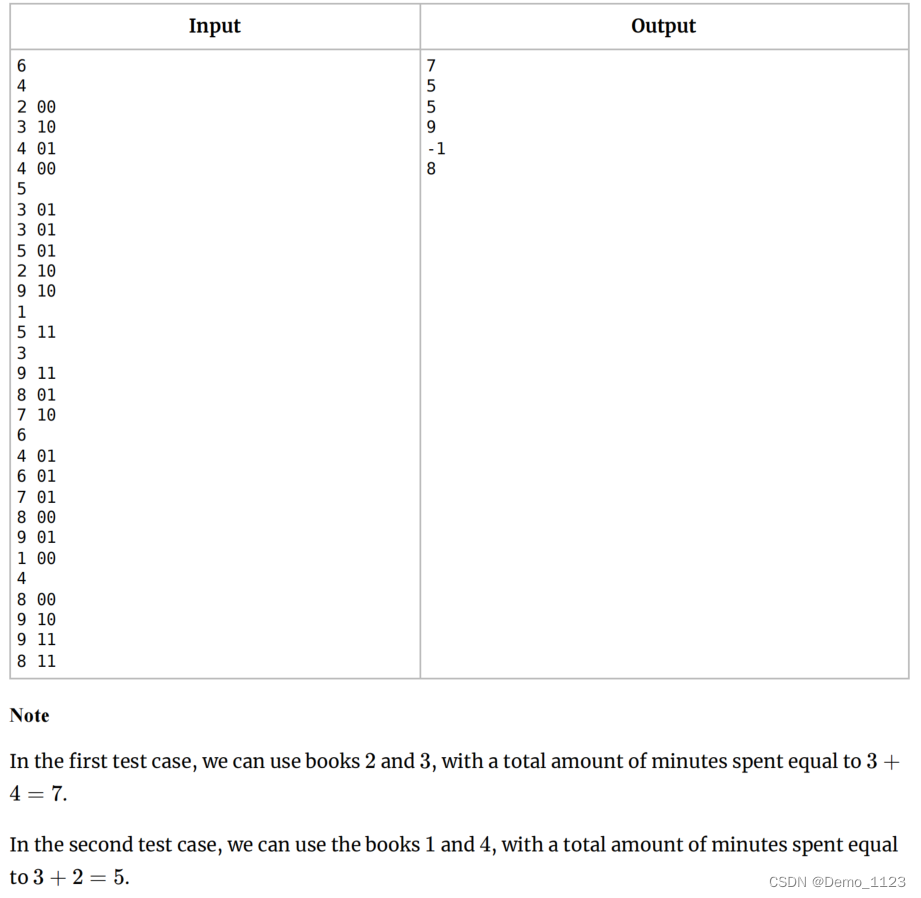
CodeForces..学习读书吧.[简单].[条件判断].[找最小值]
题目描述: 题目解读: 给定一组数,分别是 “时间 内容”,内容分为00,01,10,11四种,求能够得到11的最小时间。 解题思路: 看似00,01,10࿰…...

灵活使用Postman环境变量和全局变量,提高接口测试效率!
目录 前言: 环境变量和全局变量的概念 环境变量和全局变量的使用方法 1. 定义变量 2. 使用变量 环境变量和全局变量的实例代码 变量的继承和覆盖 变量的动态设置 总结: 前言: Postman是一个流行的API开发和接口测试工具,…...

Springboot+Vue3 整合海康获取视频流并展示
目录 1.后端 1.1 导入依赖 1.2 代码实战 2.前端 2.1 首先安装海康的web插件,前端vue3代码如下: 1.后端 1.1 导入依赖 <dependency><groupId>com.hikvision.ga</groupId><artifactId>artemis-http-client</artifactId&g…...
Linux——进程退出
目录 一.进程退出时有三种选择: 1.1 echo $?命令: 功能: 打印距离现在最近一次执行某进程的退出码 例2代码: 例3: 例4代码: 1.3 进程运行过程中可能会出现的错误种类: 二.总结ÿ…...

组长给组员派活,把组长自己的需求和要改的bug派给组员,合理吗?
组长把自己的工作派给手下,合理吗? 一位程序员问: 组长给他派活,把组长自己的需求或者要改的bug派给他。组长分派完需求之后,他一个人干两个项目,组长却无所事事,这样合理吗? 有人说…...

ESP32音频录制系统:构建智能声音采集的完整解决方案
ESP32音频录制系统:构建智能声音采集的完整解决方案 【免费下载链接】esp32_SoundRecorder ESP32 Sound recorder with simple code in arduino-esp32. (I2S interface) 项目地址: https://gitcode.com/gh_mirrors/es/esp32_SoundRecorder 在物联网和嵌入式系…...

终极指南:Commit Message Emoji 让每次提交都充满仪式感
终极指南:Commit Message Emoji 让每次提交都充满仪式感 【免费下载链接】commit-message-emoji Every commit is important. So lets celebrate each and every commit with a corresponding emoji! :smile: 项目地址: https://gitcode.com/gh_mirrors/co/commit…...

极速净化Windows 11:Win11Debloat一键释放系统潜能
极速净化Windows 11:Win11Debloat一键释放系统潜能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custo…...

终极解决方案:三步彻底卸载Windows系统中顽固的Microsoft Edge浏览器
终极解决方案:三步彻底卸载Windows系统中顽固的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRem…...

LoRA微调实战:零基础在笔记本上高效微调大模型
1. 项目概述:为什么LoRA让普通人也能“调教”大模型你有没有过这种时刻:盯着屏幕上那个动辄上百GB的开源大模型权重文件,手指悬在下载按钮上,心里却在盘算——我的笔记本连显存都快被Chrome吃光了,真要跑起来ÿ…...

生成式AI初学者本地部署实操指南:从报错诊断到模型运行
1. 这不是又一篇“AI科普文”,而是一份写给真实初学者的实操手记Generative AI: A Beginner’s Viewpoint Part 2——这个标题乍看像课程续集,但如果你正站在ChatGPT第一次弹出对话框的那一刻、刚下载完Stable Diffusion却卡在WebUI启动界面、或对着Jupy…...

皮线、裸纤总是分不清?试试这个算法一键校准技巧
不知道你有没有经历过这种工地上的"崩溃瞬间":大热天蹲在居民楼昏暗的楼道里,蚊子在耳边嗡嗡叫,你手里正拉着一根刚从住户门缝里拽出来的皮线光缆,准备跟分纤箱引出来的单模裸纤做熔接。结果放进机器,合上盖…...

Linux 环境变量详解及实例
Linux环境变量 1 ~/.bash_profile && ~/.bashrc 用户登陆Linux操作系统的时候,"/etc/profile", "~/.bash_profile"等配置文件会被自动执行。 执行过程是这样的: 登陆Linux系统时,首先启动"/etc/profil…...

别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低
别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低 在音频调谐器里校准乐器音高时,工程师发现440Hz的标准音高在1024点FFT中总是显示为439.2Hz;5G基站接收端解调时,载波频率的微小偏移导致误码率飙升ÿ…...

Triangle Splatting:3D渲染中几何精度与效率的平衡技术
1. Triangle Splatting技术概述在实时3D渲染领域,渲染效率与视觉质量的平衡一直是核心挑战。传统三角形光栅化虽然硬件友好,但难以实现柔和的边缘效果;而基于点的渲染技术(如Gaussian Splatting)虽能产生自然过渡&…...