Spark写入Hive报错Mkdir failed on :com.alibaba.jfs.JindoRequestPath
1. 报错内容
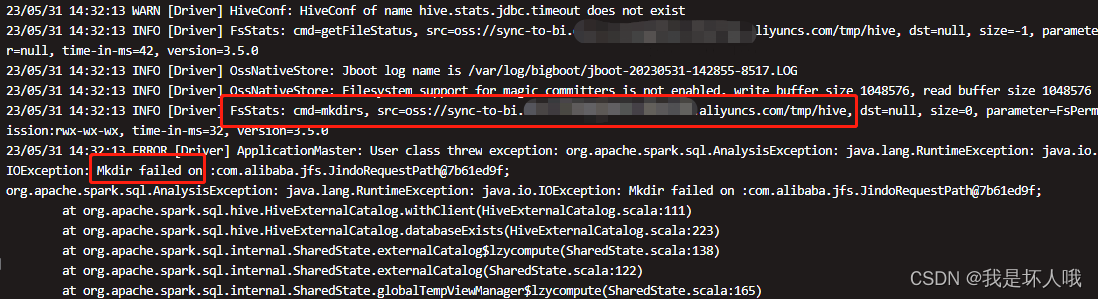
23/05/31 14:32:13 INFO [Driver] FsStats: cmd=mkdirs, src=oss://sync-to-bi.[马赛克].aliyuncs.com/tmp/hive, dst=null, size=0, parameter=FsPermission:rwx-wx-wx, time-in-ms=32, version=3.5.0
23/05/31 14:32:13 ERROR [Driver] ApplicationMaster: User class threw exception: org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9f;
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9f;at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:111)at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:223)at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:138)at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:122)at org.apache.spark.sql.internal.SharedState.globalTempViewManager$lzycompute(SharedState.scala:165)at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:160)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager$lzycompute(SessionCatalog.scala:91)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager(SessionCatalog.scala:91)at org.apache.spark.sql.catalyst.catalog.SessionCatalog.isTemporaryTable(SessionCatalog.scala:782)at org.apache.spark.sql.internal.CatalogImpl.tableExists(CatalogImpl.scala:260)at com.tcl.task.terminalmanage.TerminalManageUtils$.saveDataFrame2Hive(TerminalManageUtils.scala:148)at com.tcl.task.terminalmanage.warehouse.ods.Ods_Nps_Stability_Crash_Dropbox$.execute(Ods_Nps_Stability_Crash_Dropbox.scala:47)at com.tcl.task.terminalmanage.CommonMain.main(CommonMain.scala:28)at com.tcl.task.terminalmanage.warehouse.ods.Ods_Nps_Stability_Crash_Dropbox.main(Ods_Nps_Stability_Crash_Dropbox.scala)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:685)
Caused by: java.lang.RuntimeException: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9fat org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:606)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:544)at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:199)at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:129)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:284)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:386)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:288)at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:67)at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:66)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:224)at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:102)... 20 more
Caused by: java.io.IOException: Mkdir failed on :com.alibaba.jfs.JindoRequestPath@7b61ed9fat com.alibaba.jfs.OssFileletSystem.mkdir(OssFileletSystem.java:184)at com.aliyun.emr.fs.internal.ossnative.OssNativeStore.mkdirs(OssNativeStore.java:521)at com.aliyun.emr.fs.oss.JindoOssFileSystem.mkdirsCore(JindoOssFileSystem.java:194)at com.aliyun.emr.fs.common.AbstractJindoShimsFileSystem.mkdirs(AbstractJindoShimsFileSystem.java:389)at org.apache.hadoop.hive.ql.exec.Utilities.createDirsWithPermission(Utilities.java:3385)at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:705)at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:650)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:582)... 36 more
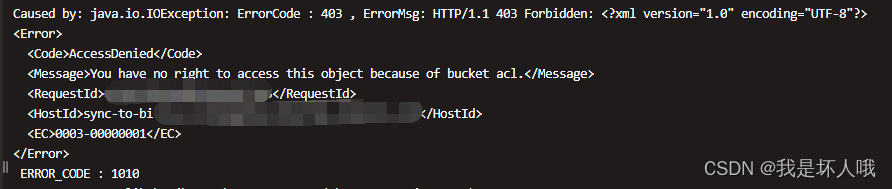
Caused by: java.io.IOException: ErrorCode : 403 , ErrorMsg: HTTP/1.1 403 Forbidden: <?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>You have no right to access this object because of bucket acl.</Message><RequestId>6[马赛克]5</RequestId><HostId>sync-to-bi.[马赛克].aliyuncs.com</HostId><EC>0003-00000001</EC>
</Error>ERROR_CODE : 1010at com.alibaba.jboot.JbootFuture.get(JbootFuture.java:145)at com.alibaba.jfs.OssFileletSystem.mkdir(OssFileletSystem.java:178)... 43 more2. 报错程序
package com.tcl.task.terminalmanage.warehouse.odsimport com.tcl.task.terminalmanage.{CommonMain, TerminalManageUtils}
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._object Ods_Nps_Stability_Crash_Dropbox extends CommonMain {val HiveDatabase = "te[马赛克]"val HiveTableName = "ods_[马赛克]_di"val ck_Table = "ods_[马赛克]_cluster"val colNames = Array("[马赛克]", "[马赛克]","[反正就是一些字段名]")override def execute(spark: SparkSession, calcDate: String): Unit = {spark.sql("set spark.sql.caseSensitive=true")val sc = spark.sparkContextval logPath = "oss://[马赛克]@sync-to-bi.[马赛克]/" + dateConverYYmm(calcDate) + "*"if (!Mutils.isPathExistTest(logPath, sc)) {return}var df = spark.read.json(logPath)for (col <- colNames) {if (!df.columns.contains(col)) {df = df.withColumn(col, lit(""))}}val result = df.withColumn("recordDate",lit(calcDate)).select("[马赛克]", "[马赛克]","[反正就是一些字段名]","recordDate")TerminalManageUtils.saveDataFrame2Hive(spark,result,HiveDatabase,HiveTableName,calcDate,0)}//2022-10-15def dateConverYYmm(date: String) = {val str1 = date.substring(0, 4)val str2 = date.substring(5, 7)val str3 = date.substring(8, 10)str1 + str2 + str3}}
程序很简单,就是数仓ODS层计算逻辑,直接从阿里云OSS读取数据,补充上一些必要的列,最后数据落盘到hive表。
3. 问题分析
3.1 分析报错内容
根据下面两段报错提示可以得出:Spark Driver在写入Hive时,试图在oss://sync-to-bi.[马赛克].aliyuncs.com/tmp/hive这个路径下创建目录。但是sync-to-bi这个是数据源桶,只有读权限,没有写权限,自然会AccessDenied。
问题的关键在于:为什么Spark Driver要在写入Hive时,往数据源的/tmp/hive创建目录?
/tmp/hive目录存放的是Hive的临时操作目录比如插入数据,insert into插入Hive表数据的操作,Hive的操作产生的操作临时文件都会存储在这里,或者比如在${HIVE_HOME}/bin下执行,sh hive,进入Hive的命令行模式,都会在这里/tmp/hive目录下产生一个Hive当前用户名字命名的临时文件夹,这个文件夹权限是700,默认是hadoop的启动用户,我的hadoop用户是hadoopadmin,所以名字是hadoopadmin的文件夹
-- Hive的/tmp/hive以及/user/hive/warehouse目录对Hive的影响 | 码农家园
如果像上面说的,insert into操作会在tmp/hive产生临时文件。那为什么不是在目标OSS创建临时文件,而是在源数据的OSS创建?我能在代码中指定产生临时文件的位置吗?
3.2 根据猜想进行尝试
尝试修改默认fs,指向目标OSS,即hive表location所在的OSS
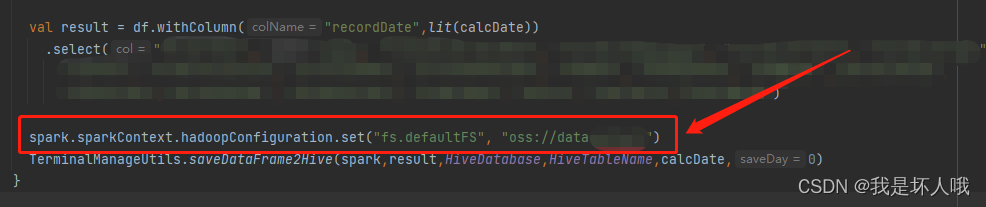
再次运行代码,竟然真的成功了!但是进一步思考,在父类CommonMain中本就是有默认fs的配置
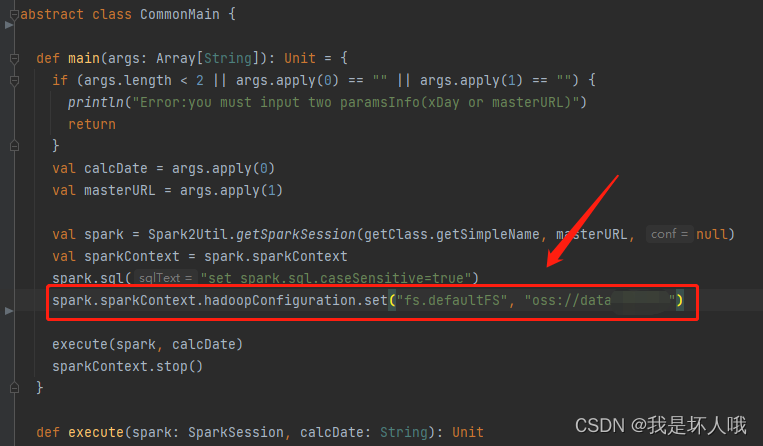
那么,为什么父类中的配置没有生效?
3.3 添加日志分析父类fs配置不生效的原因
package com.tcl.task.terminalmanage.warehouse.odsimport com.tcl.task.terminalmanage.{CommonMain, TerminalManageUtils}
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._object Ods_Nps_Stability_Crash_Dropbox extends CommonMain {private val logger = LoggerFactory.getLogger("Luo")val HiveDatabase = "te[马赛克]"val HiveTableName = "ods_[马赛克]_di"val ck_Table = "ods_[马赛克]_cluster"val colNames = Array("[马赛克]", "[马赛克]","[反正就是一些字段名]")override def execute(spark: SparkSession, calcDate: String): Unit = {logger.info("-------1--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))spark.sql("set spark.sql.caseSensitive=true")val sc = spark.sparkContextval logPath = "oss://[马赛克]@sync-to-bi.[马赛克]/" + dateConverYYmm(calcDate) + "*"logger.info("-------2--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))if (!Mutils.isPathExistTest(logPath, sc)) {return}logger.info("-------3--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))var df = spark.read.json(logPath)logger.info("-------4--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))for (col <- colNames) {if (!df.columns.contains(col)) {df = df.withColumn(col, lit(""))}}val result = df.withColumn("recordDate",lit(calcDate)).select("[马赛克]", "[马赛克]","[反正就是一些字段名]","recordDate")logger.info("-------5--------" + spark.sparkContext.hadoopConfiguration.get("fs.defaultFS"))TerminalManageUtils.saveDataFrame2Hive(spark,result,HiveDatabase,HiveTableName,calcDate,0)}//2022-10-15def dateConverYYmm(date: String) = {val str1 = date.substring(0, 4)val str2 = date.substring(5, 7)val str3 = date.substring(8, 10)str1 + str2 + str3}}
日志结果:
Luo: -------1--------oss://data[马赛克]
Luo: -------2--------oss://data[马赛克]
Luo: -------3--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
Luo: -------4--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
Luo: -------5--------oss://[马赛克]@sync-to-bi.[马赛克].aliyuncs.com
谁承想,问题竟然出现在了一个路径是否存在的分支判断。

由于很明显程序运行不会进入这个if分支,所以它自动被忽略了。分支不会执行,但判断条件一定是会执行的。 而越容易出问题的,往往就是在这种非常容易被忽略的地方。
4. 总结
如果程序出现了一些“灵异”现象,很有可能,问题出现在你一开始就忽略的地方。
相关文章:
Spark写入Hive报错Mkdir failed on :com.alibaba.jfs.JindoRequestPath
1. 报错内容 23/05/31 14:32:13 INFO [Driver] FsStats: cmdmkdirs, srcoss://sync-to-bi.[马赛克].aliyuncs.com/tmp/hive, dstnull, size0, parameterFsPermission:rwx-wx-wx, time-in-ms32, version3.5.0 23/05/31 14:32:13 ERROR [Driver] ApplicationMaster: User class …...
分布式id解决方法--雪花算法
uuid,jdk自带,但是数据库性能差,32位呀。 mysql数据库主键越短越好,Btree产生节点分裂,大大降低数据库性能,所以uuid不建议。 redis的自增,但是要配置维护redis集群,就为了一个id&a…...

5年经验之谈:月薪3000到30000,测试工程师的变“行”记
自我介绍下,我是一名转IT测试人,我的专业是化学,去化工厂实习才发现这专业的坑人之处,化学试剂害人不浅,有毒,易燃易爆,实验室经常用丙酮,甲醇,四氯化碳,接触…...

PMP考试都是什么题?
PMP新版大纲加入了ACP敏捷管理的内容,说是敏捷混合题型占到了 50%,但是这次318的考试,敏捷题占了大半,都说敏捷和情景快要占到80%-90%。 所以有友友说开了四个小时盲盒,题目读不懂,或者觉得4个选项都不对或…...

macbook2023系统清理软件cleanmymac中文版
cleanmymac x 中文版基本都是大家首选Mac清理软件了。它集各种功能于一身,几乎满足用户所有的清理需求。它可以清理,优化,保养和监测您的电脑,确保您的Mac运行畅通无阻!支持一键快速清理Mac,快速检查并安全…...
基于Python+AIML+Tornado的智能聊天机器人(NLP+深度学习)含全部工程源码+语料库 适合个人二次开发
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境Tornado 环境 模块实现1. 前端2. 后端3. 语料库4. 系统测试 其它资料下载 前言 本项目旨在利用AIML技术构建一个聊天机器人,实现用户通过聊天界面与机器人交互的功能。通过提供的工程源代码…...

算法Day15 | 层序遍历,102,107,199,637,429,515,116,117,104,111,226,101
Day15 层序遍历102.二叉树的层序遍历107.二叉树的层次遍历 II199.二叉树的右视图637.二叉树的层平均值429.N叉树的层序遍历515.在每个树行中找最大值116.填充每个节点的下一个右侧节点指针117.填充每个节点的下一个右侧节点指针II104.二叉树的最大深度111.二叉树的最小深度 226…...
Prometheus+Grafana学习(十一)安装使用pushgateway
Pushgateway允许短暂和批量作业将其指标暴露给 Prometheus。由于这些工作的生命周期可能不足够长,不能够存在足够的时间以让 Prometheus 抓取它们的指标。Pushgateway 允许它们可以将其指标推送到 Pushgateway,然后 Pushgateway 再将这些指标暴露给 Prom…...

深入理解C/C++预处理器指令#pragma once以及与ifndef的比较
#pragma once用法总结 为了防止重复引用造成二义性 在C/C中,在使用预编译指令#include的时候,为了防止重复引用造成二义性,通常有两种方式 第一种是#ifndef指令防止代码块重复引用,比如说 #ifndef _CODE_BLOCK #define _CODE_BLO…...
git 环境配置 + gitee拉取代码
好嘛 配环境的时候 老是忘记这个命令行 干脆自己写一个记录一下 也不用搜了 1.先从git官网下载git 安装 2.然后从gitee拉取代码的时候提示 这是因为换了新电脑没有加入新的公钥啦 哎 所以老是记不住命令行 first : git config --global user.name “Your Name” …...

港联证券|港股拥抱特专科技企业 内资券商“修炼内功”蓄势而为
港股市场新一轮改革举措渐次落地。特别是港交所推出特专科技公司上市机制,吸引符合资格的科技企业申请赴港上市,成为这一轮港股市场改革的“重头戏”。 作为香港资本市场的重要参与者,内资券商立足香港、背靠内地、辐射全球,走出一…...

多项创新技术加持,实现零COGS的Microsoft Editor语法检查器
编者按:Microsoft Editor 是一款人工智能写作辅助工具,其中的语法检查器(grammar checker)功能不仅可以帮助不同水平、领域的用户在写作过程中检查语法错误,还可以对错误进行解释并给出正确的修改建议。神经语法检查器…...
Python编程环境搭建:Windows中如何安装Python
在 Windows 上安装 Python 和安装普通软件一样简单,下载安装包以后猛击“下一步”即可。 Python 安装包下载地址:https://www.python.org/downloads/ 打开该链接,可以看到有两个版本的 Python,分别是 Python 3.x 和 Python 2.x&…...

Sui Builder House首尔站倒计时!
Sui主网上线后的第一场Builder House活动即将在韩国首尔举行,同期将举办首场线下面对面的黑客松。活动历时两天,将为与会者提供独特的学习、交流和娱乐的机会。活动详情请查看:Sui Builder House首尔站|主网上线后首次亮相。 Sui…...

Java设计模式-状态模式
简介 在软件开发领域,设计模式是一组经过验证的、被广泛接受的解决问题的方案。其中之一是状态模式,它提供了一种优雅的方式来管理对象的不同状态。 状态模式是一种行为型设计模式,它允许对象在内部状态发生改变时改变其行为。状态模式将对…...

智慧社区用什么技术开发
智慧社区是指利用信息技术和先进的管理理念,将社区内的各种公共服务进行整合和优化,提高社区居民的生活品质和社区管理的效率。为了实现智慧社区的建设,需要采用多种技术,包括但不限于以下几种: 1.物联网技术…...

多线程 线程池饱和策略
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。 这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。 在JDK 1…...

进程间通信之信号
进程间通信之信号 1. 信号2. 信号由谁产生?3. 有哪些信号4. 信号的安装5. 信号的发送1) 使用kill函数2)使用alarm函数3) 使用raise6.发送多个信号7. 信号集1. 信号 什么是信号? 信号是给程序提供一种可以处理异步事件的方法,它利用软件中断来实现。不能自定义信号,所有信号…...

二分查找三道题
二分查找 两种写法:左闭右闭[left,right]、左闭右开[left,right) 主要有几点不同:1. right是从num.length开始还是从num.length-1开始。2.left<还是<right。3.rightmid还是mid1 左闭右闭写法: public int search(int[] nums, int targ…...
MyBatis 框架
MyBatis 框架 MyBatis 简介搭建 MyBatis 开发环境核心配置文件详解mapper 映射文件(实现增删改查)MyBatis获取参数值的两种方式MyBatis的各种查询功能特殊SQL的执行自定义映射resultMapresultMap 字段和属性的映射多对一映射处理一对多映射处理 动态SQLM…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

接口测试用例设计:超详细防御体系与分层校验实践
1. 为什么“超详细”三个字在接口测试用例里不是修饰词,而是生死线我带过三支不同行业的测试团队——金融支付、SaaS中台、IoT设备管理平台。每次新人入职第一周,我都会收走他们写的前5条接口测试用例,逐行标红批注。不是因为格式不对&#x…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...
:setup / onboard 与本地配置初始化)
OpenClaw 源码解析(五):setup / onboard 与本地配置初始化
1. 本期目标 上一期我们分析了 OpenClaw 的 CLI 启动链路:用户输入 openclaw 命令后,程序会先经过 entry.ts、run-main、Commander Program 构建和命令注册流程,然后再进入具体命令逻辑。 这一期继续往下看,重点分析两个最基础的…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...
的6个关键参数,选型不踩坑)
别光看手册!手把手教你读懂气体放电管(GDT)的6个关键参数,选型不踩坑
气体放电管实战选型指南:从参数表到电路设计的6个关键决策点 每次打开气体放电管(GDT)的英文数据手册,面对密密麻麻的参数表格和波形图,不少工程师都会陷入选择困难——这些数值到底如何影响实际电路保护效果…...