【C++】哈希表特性总结及unordered_map和unordered_set的模拟实现
✍作者:阿润菜菜
📖专栏:C++
文章目录
- 前言
- 一、哈希表的特性 - 哈希函数和哈希冲突
- 1 哈希函数
- 2. 哈希冲突
- 二、闭散列的实现 -- 开放地址法
- 1. 定义数据结构
- 2.insert()
- 3.Find()
- 4. Erase()
- 5.仿函数处理key值不能取模无法映射 --- BKDRHash
- 三、开散列的实现 --- 链地址法(哈希桶)
- 1. 定义框架结构
- 2.insert()
- 3.Find()
- 4.Erase()
- 四、封装实现unordered系列容器
- 1.迭代器设计
- 2.unordered_map的[ ]操作
前言
- unordered系列关联式容器是C++11中新增的一类容器,包括unordered_map,unordered_set,unordered_multimap和unordered_multiset。
- 它们的底层实现是哈希表,可以快速地查找和插入元素,时间复杂度为O(1)。
- 它们的元素是无序的,因此遍历时元素的顺序是不确定的。
- 它们的使用方式和红黑树结构的关联式容器(如map和set)基本类似,只是需要包含不同的头文件(<unordered_map>或<unordered_set>)。
- 它们支持直接访问操作符(operator[]),可以使用key作为参数直接访问value。
- 哈希最大的作用就是查找(效率很高的),哈希并不具有排序的功能,unordered_map和unordered_set仅仅只有去重的功能而已
一、哈希表的特性 - 哈希函数和哈希冲突
- 哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表中有多少条数据,插入和查找的时间复杂度都是为O(1)。
- 哈希表是通过把关键码值映射到表中一个位置来访问记录,这个映射函数叫做散列函数或哈希函数。
- 哈希表的元素是无序的,因为散列函数的映射结果是随机的。
- 哈希表可能会产生碰撞,也叫哈希冲突,就是不同的关键码值映射到同一个位置,这时就需要采用一些方法来解决碰撞,比如开放地址法或链表法,同时。
1 哈希函数
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B,常用的A是1,B是0。
优点:简单、均匀
缺点:需要事先知道关键字的分布情况,若分布较广,则空间消耗比较高。
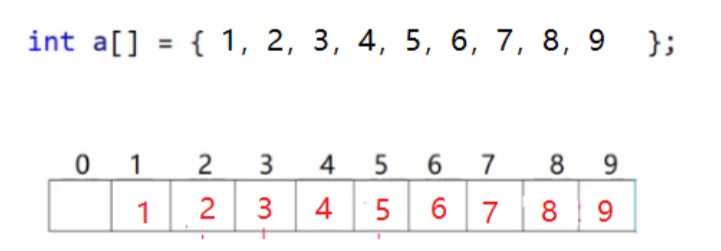
使用场景:适合查找比较小且连续的情况 - 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址,一般不这么干,最常用的就是拿vector.size()作为除数,每次扩容将vector.size()扩容二倍。但后面开散列的解决方式那里,我们会仿照库,用质数的集合作为vector.size(),然后用其作为除数。
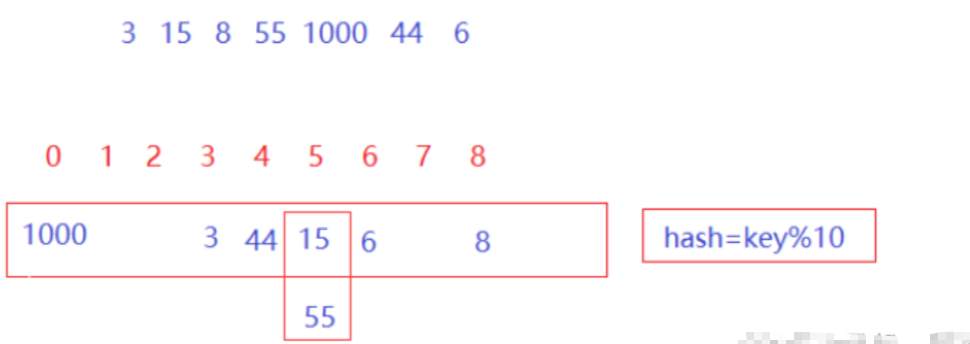
2. 哈希冲突
当多个关键码key在通过哈希函数映射之后,得到了相同的哈希地址,也就是多个key映射到同一个位置上时,这种现象称为哈希冲突或哈希碰撞。解决哈希冲突的办法一般为两种,一种是闭散列的方式解决,即用线性探测或二次探测的方式向后寻找空的哈希位置,一种是开散列的方式解决,即将哈希冲突的元素通过单链表链接,逻辑上像哈希表挂了一个个的桶,所以这样的解决方式也可称为链地址法,或哈希桶方式。
区别概念:介绍一下闭散列和开散列:
- 开散列和闭散列都是解决哈希冲突的方法,也就是当不同的关键码值映射到同一个位置时,如何处理的问题。
- 开散列方法又叫链地址法,它是把发生冲突的关键码存储在散列表主表之外,每个位置对应一个链表,链表的头节点存储在主表中。这样,当查找一个关键码时,先通过散列函数得到其位置,然后在对应的链表中进行查找。
- 闭散列方法又叫开放地址法,它是把发生冲突的关键码存储在主表中另一个槽内。这样,当查找一个关键码时,如果发现其位置已经被占用,就按照一定的规则寻找下一个空闲的位置,直到找到或者遍历整个表。
- 开散列和闭散列的区别是:
- 开散列需要额外的空间来存储链表节点,而闭散列不需要;
- 开散列可以容纳任意多的元素,而闭散列的容量有限;
- 开散列的查找效率取决于链表的长度,而闭散列的查找效率取决于探测规则;
- 开散列更适合关键码值分布不均匀的情况,而闭散列更适合关键码值分布均匀且空间紧张的情况。
二、闭散列的实现 – 开放地址法
1. 定义数据结构
闭散列的实现,我们以键值作为存储元素来讲解。
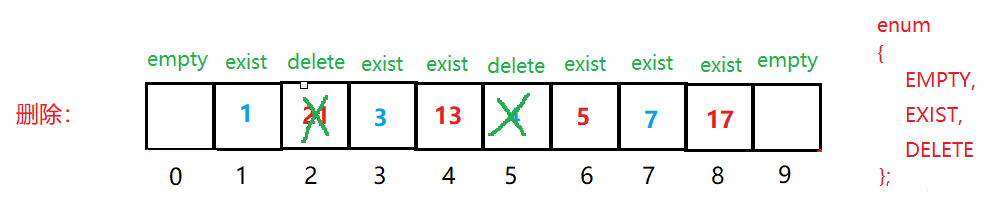
我们采用vector作为底层容器,用vector来存储哈希结点,哈希结点是一个结构体,其中存储键值对和状态值,_state用于标定哈希映射位置为空、存在、删除三种状态。
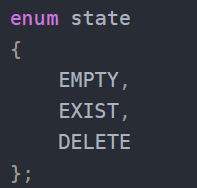
同时为了判断什么时候进行哈希表的扩容,在hashTable类中多增加了一个无符号整型的_n变量,表示当前哈希表中存储数据的个数,方便我们用数据个数和vector.size()作除法,看结果是否大于负载因子,如果大于则扩容,如果不大于则继续插入。
enum state
{EMPTY,EXIST,DELETE
};
template <class K, class V>
struct HashNode
{HashNode(): _state(EMPTY){}HashNode(const pair<K, V>& kv):_kv(kv), _state(EMPTY){}pair<K, V> _kv; //数据enum state _state; //状态
};
//......
};
2.insert()
负载因子
哈希表冲突越多,效率越低
若表中位置都满了,就需要扩容 ,我们利用负载因子进行判断何时扩容
负载因子的概念
负载因子 = 填入表的元素个数 / 表的长度
表示 表储存数量的百分比
填入表的元素个数 越大,表示冲突的可能性越大,
填入表的元素个数 越小,表示冲突的可能性越小
所以在开放定址法时,应该控制在0.7-0.8以下,超过就会扩容
线性探测
哈希表的线性探测原理是一种解决哈希冲突的方法,它的基本思想是:当发生哈希冲突时,就从当前位置开始,顺序查找下一个空闲的位置,然后将数据插入到该位置。
例如,如果我们要将数据 88 插入到哈希表中,经过哈希函数计算得到的数组下标是 16 ,但是在数组下标为 16 的位置已经有其他元素了,那么就继续查找 17 , 18 ,直到找到一个空闲的位置,然后将 88 插入到该位置。
在实现扩容时,我们进行代码复用,我们不再新建立vector,而是新建立一个哈希表,对新哈希表中的vector进行扩容,然后调用哈希表的Insert函数,将原vector中的键值对的关键码插入到新哈希表当中,这样就不需要自己在写代码,进行代码复用即可。最后将新哈希表中的vector和原哈希表的vector进行swap即可,这样就完成了原有数据到新表中的挪动,然后再插入要插入的kv即可。
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;//大于标定的负载因子,进行扩容,降低哈希冲突的概率if (_n * 10 / _tables.size() > 7)//可能会出现除0错误{//旧表数据,重新计算,映射到新表/*vector<Node> newtables;newtables.resize(2 * _tables.size()); */HashTable<K, V, BKDRHash<K>> newHT;newHT._tables.resize(2 * _tables.size());for (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);//取原表中的数据插入到新表的vector里面,键值对之间发生赋值重载。因为newHT是新开的初始化好的哈希表//递归通常是自己调用自己,这里不是递归,仅仅是代码复用而已。}}_tables.swap(newHT._tables);}size_t hashi = Hash()(kv.first) % _tables.size();//这里不能%capacity,某些位置不是可用的,vector[]会对下标检查while (_tables[hashi]._state == EXIST){//线性探测++hashi;//二次探测//hashi = hashi + i * i;//降低冲突概率,但还是有可能会冲突,占其他位置hashi %= _tables.size();}/*_tables[hashi] = Node(kv);_tables[hashi]._state = EXIST;*///在构造新表对象时,默认构造已经初始化好哈希表里面的结点空间了,你再开空间拷贝数据浪费。_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;
}
3.Find()
查找的思想非常简单,我们首先利用要查找的key值求出映射的哈希地址,如果当前位置的状态为存在或者删除,则继续找,若在循环中找到了,则返回对应位置的地址,若没找到则返回nullptr,遇见空则结束查找。
在线性探测中,如果查找到尾部了,则让hashi%=vector的size即可,让hashi回到开头的位置。但有一种极端特殊情况,就是边插入边删除,这样整个哈希表中的结点状态有可能都是delete或exist,则在线性探测中不会遇到empty,while会陷入死循环,所以在while里面多加一层判断,如果start等于hashi,说明在哈希表中已经线性探测一圈了,那此时就返回,因为找了一圈都没找到key,那就说明key不在哈希表里面。
Node* Find(const K& key)
{size_t hashi = Hash()(key) % _tables.size();size_t start = hashi;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._kv.first == key && _tables[hashi]._state == EXIST){return &_tables[hashi];}++hashi;hashi %= _tables.size();//防止越界if (start == hashi)break;}return nullptr;
}
4. Erase()
大部分数据结构容器的删除其实都是伪删除或者叫做惰性删除,因为我们无法做到释放一大块空间的某一部分空间,所以在数据结构这里的删除基本都是用标记的伪删除 ,哈希表的删除也一样,我们在每个结点里面增加一个状态标记,用状态来标记当前结点是否被删除。如果删除结点不存在,则返回false。
bool Erase(const K& key)
{Node* ret = Find(key);if (ret == nullptr)return false;ret->_state = DELETE;--_n;return true;
}
5.仿函数处理key值不能取模无法映射 — BKDRHash
上面代码中,对于整型数据可以完成key值取模映射,那如果我们的数据是string类型,怎么解决?string如何对vector的size取模呢?此时就需要仿函数来完成自定义类型转换为整型的操作了,只有转换为整型,我们才能取模,进而才能完成哈希映射的工作。
对于其他类型,比如int,char,short,double等,我们直接强转为size_t,这样就可以完成哈希映射。
字符串转换为整型的场景还是比较常见的,网上有很多关于字符串哈希的算法,我们取最优的算法,思路就是将每一个字符对应的ascll码分别拆下来,每次的hash值都为上一次的hash值×131后再加上字符的ascll码值,遍历完字符串后,最后的hash为字符串转成整型的结果,这样每个字符串转换后的整型是极大概率不重复的,是一个非常不错的哈希算法,被人们称为BKDRHash。
template <class K>
struct BKDRHash
{size_t operator()(const K& key){return (size_t)key;//只要这个地方能转成整型,那就可以映射,指针浮点数负数都可以,但string不行}
};
template <>
struct BKDRHash<string>
{size_t operator()(const string& key){//return key[0];//字符串第一个字符是整型,那就可以整型提升,只要是个整型能进行%模运算,完成映射即可。size_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;}return hash;}
};
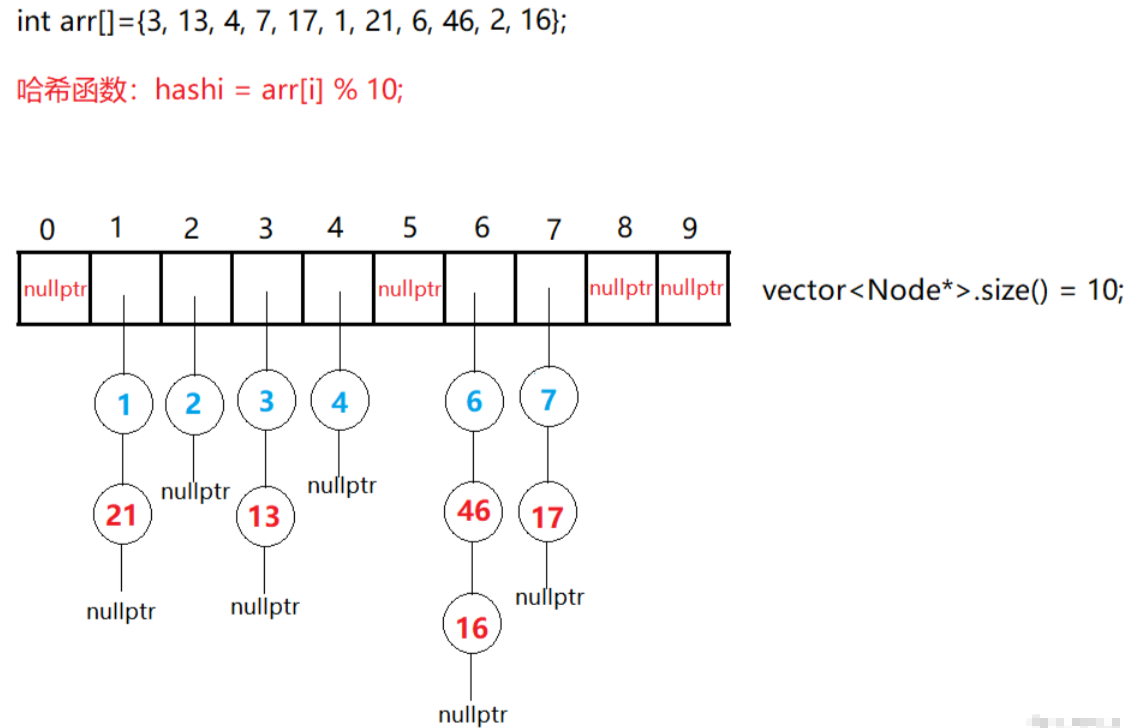
三、开散列的实现 — 链地址法(哈希桶)
开散列的哈希表是最常用的方式,库里面的unordered_map和unordered_set用的也是哈希桶的方式实现的,我们模拟实现的哈希桶也仿照库实现,哈希结点node里面存储键值对和下一个结点指针。
1. 定义框架结构
在哈希表的模板参数中,也多加了一个缺省仿函数类的参数,也就是Hash,因为我们需要Hash的仿函数对象或匿名构造,将key转成整型。
template <class K, class V>
struct hashNode
{hashNode(const pair<K,V>& kv):_kv(kv),_next(nullptr){}pair<K, V> _kv;hashNode<K, V>* _next;
};
template <class K, class V, class Hash = BKDRHash<K>>
class hashTable
{
public:typedef hashNode<K, V> Node;…………省略
private:vector<Node*> _table;size_t _n;
};对于哈希桶,我们必须写出析构函数,因为编译器默认生成的析构函数会调用vector的析构,而vector的析构仅仅只能将自己的空间还给操作系统,如果某些节点指针指向了具体的节点,则只归还vector的空间是不够的,还需要归还那些申请的节点空间。
所以需要遍历每一个哈希桶,将每一个桶里面的节点都还给操作系统,这里就用到单链表的节点删除的知识了,在删除前需要保留下一个位置,要不然delete归还空间之后就找不到下一个节点的位置了。
2.insert()
为什么进行头插?
对单链表进行尾插,因为尾插还需要找尾,那就需要遍历桶,这样的效率太低,并且桶中也不要求次序什么的,所以我们直接进行头插即可,头插的效率很高,因为映射找到哈希地址之后即可进行头插。
- 哈希桶的负载因子,官方默认值为1.0,那就是_n和vector.size()相等的时候进行扩容,扩容的目的还是重新建立映射关系,缓解哈希冲突,因为如果某一个哈希桶的结点个数过多,在哈希映射之后还需要遍历哈希桶寻找结点,会降低哈希查找的效率,所以扩容就是多增加哈希桶的个数,减少平均哈希桶中结点的个数,提高哈希查找的效率。
2.注意我们遍历原表的每个结点指针,将每个指针指向结点的key重新计算哈希映射关系,头插到新的vector里面,在每完成一个桶的重新映射关系后,将原vector中的桶位置的指针置为空,否则析构的时候,结点会被析构两遍。等到原表的所有结点遍历完之后,将新的vector和原来的vector一交换即可,临时对象_newtable在离开函数栈帧时会被销毁,调用vector的默认析构完成空间的归还即可
研究表明,每次除留余数法最好模一个素数,这会大概率降低哈希冲突的可能性。所以我们下面的扩容大小每次挑选小于2倍的最大素数作为扩容后的vector大小,这里复用了一下stl库里面的素数表。
inline unsigned long __stl_next_prime(unsigned long n)
{static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (size_t i = 0; i < __stl_num_primes; i++){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return __stl_prime_list[__stl_num_primes - 1];
}
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))//不允许重复元素return false;//负载因子控制在1,超过就扩容if (_n == _table.size()){vector<Node*> _newtable;_newtable.resize(__stl_next_prime(_table.size()), nullptr);//resize开空间后,默认值为Node*()的构造,我们也可以自己写for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(cur->_kv.first) % _newtable.size();cur->_next = _newtable[hashi];_newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(_newtable);}size_t hashi = Hash()(kv.first) % _table.size();Node* newnode = new Node(kv);newnode->_next = _table[hashi];//newnode的next指向当前表哈希映射位置的结点地址_table[hashi] = newnode;//让newnode做头++_n;return true;
}
3.Find()
哈希桶的查找和闭散列的哈希表很相似,先通过key找到映射的哈希桶,然后去对应的哈希桶里面找查找的结点即可,找到返回结点地址,未找到返回nullptr即可。
Node* Find(const K& key)
{size_t hashi = Hash()(key) % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}
4.Erase()
哈希桶的erase其实就是单链表结点的删除,如果是头删,那就是下一个指针作头,如果是中间删除,则记录前一个结点位置,让前一个结点的next指向删除结点的next。然后归还结点空间的使用权,即为delete结点指针。
bool Erase(const K& key)
{Node* ret = Find(key);if (!ret)return false;size_t hashi = Hash()(key) % _table.size();Node* cur = _table[hashi];if (cur->_kv.first == key)//头删{_table[hashi] = cur->_next;delete cur;cur = nullptr;}else//中间删除{while (cur){Node* prev = cur;cur = cur->_next;if (cur->_kv.first == key){prev->_next = cur->_next;delete cur;cur = nullptr;}}}--_n;return true;
}
四、封装实现unordered系列容器
封装实现unordered系列容器所需硬件的哈希表结构以及哈希函数、插入、查找、删除这些接口我们直接复用开散列哈希桶的接口即可,重点在于我们实现容器的迭代器操作,只要实现了迭代器的操作,那我们自己封装的unordered系列容器基本上就能跑起来了。
1.迭代器设计
- 迭代器需要定义一些模板参数,包括键值类型、元素类型、哈希函数类、键值获取类等。其中,元素类型对于unordered_set来说就是键值类型,对于unordered_map来说就是pair<const key, value>类型。哈希函数类用于将元素类型转换为整数类型,键值获取类用于从元素类型中提取键值。
- 迭代器需要封装两个指针,一个是节点指针,用于指向当前遍历的元素,另一个是哈希表指针,用于在遍历完一个链表后找到下一个不为空的链表。
- 迭代器需要重载一些运算符,包括*和->运算符,用于访问当前元素的数据域;++运算符,用于移动到下一个元素;==和!=运算符,用于比较两个迭代器是否指向同一个元素。
- 迭代器需要提供一些构造函数和析构函数,用于创建和销毁迭代器对象。
//前置声明
template <class K, class T, class Hash, class KeyOfT>
class hashTable;template <class K, class T, class Hash, class KeyOfT>
struct __HTIterator
{typedef hashNode<T> Node;typedef hashTable<K, T, Hash, KeyOfT> HT;typedef __HTIterator<K, T, Hash, KeyOfT> Self;Node* _node;HT* _ht;__HTIterator(Node* node, HT* ht):_node(node),_ht(ht){}Self& operator++(){if (_node->_next){_node = _node->_next;}else{//当前桶走完了,要去哈希表里面找下一个桶size_t hashi = Hash()(KeyOfT()(_node->_data)) % _ht->_table.size();hashi++;while (hashi != _ht->_table.size() && _ht->_table[hashi] == nullptr){hashi++;}if (hashi == _ht->_table.size())_node = nullptr;else_node = _ht->_table[hashi];}return *this;}T& operator->(){return &_node->_data;}T* operator*(){return _node->_data;}bool operator!=(const Self& it)const{return _node != it._node;}bool operator==(const Self& it)const{return _node == it._node;}
};
2.unordered_map的[ ]操作
我们知道unordered_map是一个无序关联容器,内部使用哈希表和桶来存储键值对。所以当使用[ ]操作符访问一个键时,unordered_map应先计算该键的哈希值,然后根据哈希值找到对应的桶。
- 如果桶中没有任何元素,或者没有找到与该键相等的元素,unordered_map会在桶中插入一个新的节点,键为给定的键,值为默认构造的值。
- 如果桶中有一个或多个元素,并且找到了与该键相等的元素,unordered_map会返回该元素的引用¹。
- 如果桶中有多个元素,并且没有找到与该键相等的元素,unordered_map会在桶的末尾插入一个新的节点,键为给定的键,值为默认构造的值。
V& operator[](const K& key)
{pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;
}pair<iterator,bool> Insert(const T& data)
{KeyOfT kot;iterator it = Find(kot(data));if (it != end())return make_pair(it, false);//如果插入的值已经存在那就不再进行插入,返回对应位置迭代器即可。if (_n == _table.size()){vector<Node*> _newtable;_newtable.resize(__stl_next_prime(_table.size()), nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(kot(cur->_data)) % _newtable.size();cur->_next = _newtable[hashi];_newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(_newtable);}size_t hashi = Hash()(kot(data)) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);
}void test_unordered_map()
{string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" , "蓝莓" ,"草莓" };unordered_map<string, int> countMap;for (auto& e : arr){countMap[e]++;}unordered_map<string, int>::iterator it = countMap.begin();//1.不用语法糖,一点一点遍历也可以while (it != countMap.end()){cout << it->first << ":" << it->second << endl;++it;}//2.我们实现了迭代器,直接用语法糖也可以。for (const auto& kv : countMap)//将解引用后的迭代器赋值给kv{cout << kv.first << ":" << kv.second << endl;}
}
本节完

相关文章:
【C++】哈希表特性总结及unordered_map和unordered_set的模拟实现
✍作者:阿润菜菜 📖专栏:C 文章目录 前言一、哈希表的特性 - 哈希函数和哈希冲突1 哈希函数2. 哈希冲突 二、闭散列的实现 -- 开放地址法1. 定义数据结构2.insert()3.Find()4. Erase()5.仿函数处理key值不能取模无法映射 --- BKDRHash 三、开…...
)
Qt在Linux内核中的应用及解析(qtlinux内核)
Qt是跨平台开发的一种工具,尤其适合在Linux内核中的应用开发中使用。Qt能够让开发者在Linux桌面上开发出强大的图形化应用程序,为Linux系统用户提供更加人性化、实用、智能化的服务。本文将从Qt在Linux内核中的应用场景、应用程序开发中的具体使用、以及…...
Xpdf 阅读器源码编译后查看文件中文乱码问题解决
经查阅,是由于缺少中文字体包: 第一步:下载所需要的字体包 下载https://dl.xpdfreader.com/xpdf-t1fonts.tar.gz 包含下载中文字体包(非嵌入字体) http://ftp.gnu.org/gnu/non-gnu/chinese-fonts-truetype/gkai00mp…...
)
Java - AQS-CountDownLatch实现类(二)
前言 在Java中,AbstractQueuedSynchronizer(简称AQS)是一个用于实现同步器的抽象类,它为实现各种类型的同步器(如锁、信号量等)提供了基本的框架。AQS通过一个双向队列(等待队列)和…...

rsut基础
这篇文章是实战性质的,也就是说原理部分较少,属于经验总结,rust对于模块的例子太少了。rust特性比较多(悲),本文的内容可能只是一部分,实现方式也不一定是这一种。 关于 rust 模块的相关内容&a…...

高压放大器和示波器的关系是什么
高压放大器和示波器是电子工程领域中常见的两种设备,它们在实际的电路设计、测试和分析中都扮演着重要的角色。下面安泰电子将从定义、功能、应用场景等方面为您介绍高压放大器和示波器的关系。 图:ATA-7000系列高压放大器 一、高压放大器的定义及功能 高…...
5个超实用视频素材网站,免费下载~
推荐几个高清无水印的视频素材网站,重点是可以免费下载使用,建议收藏! 菜鸟图库 https://www.sucai999.com/video.html?vNTYxMjky 可以称之为最大素材库,在这里你可以找到设计、办公、图片、视频、音频等各种素材。视频素材就有…...
(BoW、N-gram、tf-idf))
【NLP模型】文本建模(1)(BoW、N-gram、tf-idf)
目录 一、说明 二、BoW模型产生发展 2.1 产生和历史 2.2 原理介绍 三、具体实现...

Java——网络编程套接字
目录 一、网络编程基础 1.1 为什么需要网络编程?——丰富的网络资源 二、什么是网络编程? 三、网络编程中的基本概念 3.2 请求和响应 3.3 客户端和服务端 常见的客户端服务端模型 四、Socket套接字 五、通信模型 5.1 Java数据报套接字通信模型 5.2 Java流…...
160套小程序源码
源码列表如下: AppleMusic (知乎日报) 微信小程序 d artand 今日更新求职招聘类 医药网 口碑外卖点餐 城市天气 外卖小程序 定位天气 家居在线 微信小程序-大好商城,wechat-weapp 微信小程序的掘金信息流 微信跳一跳小游戏源码 微票源码-demo 急救应急处…...

有效项目进度管理的 10 条规则
项目进度管理是项目中比较关键的方面之一,因为它将决定事情的进展方式、进展速度以及是否会取得进展。换句话说,它可以让你较好地控制项目,帮助你预测不可预测的情况,并使所有相关团队能够高效地协同工作。 以下是有效项目进度管…...
javaWebssh服装租赁店信息管理系统台myeclipse开发mysql数据库MVC模式java编程计算机网页设计
一、源码特点 java ssh服装租赁店信息管理系统是一套完善的web设计系统(系统采用ssh框架进行设计开发),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要 采用B/S模式开发。开发环境为TO…...
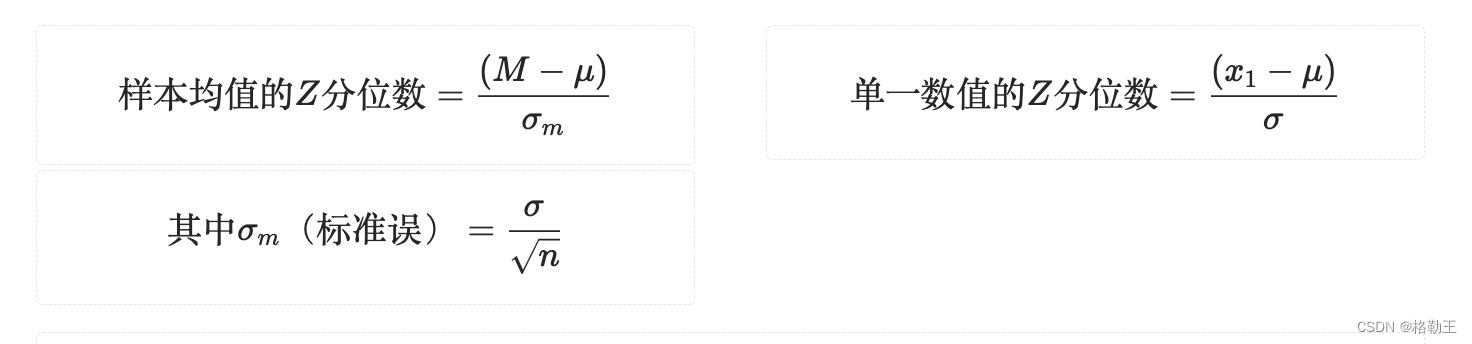
概率论:样本与总体分布,Z分数与概率
参考书目:《行为科学统计精要》(第八版)——弗雷德里克J格雷维特 数据及其样本的分布 描述一组数据分布 描述一组样本数据的分布 描述样本数据的均值和整体数据一样,但是样本标准差的公式除以了n-1,这里引入自由度的…...
【JavaSE】Java基础语法(十二):ArrayList
文章目录 1. ArrayList的构造方法和添加方法2. ArrayList类常用方法3. ArrayList存储学生对象并遍历 集合和数组的区别 : 共同点:都是存储数据的容器不同点:数组的容量是固定的,集合的容量是可变的 1. ArrayList的构造方法和添加方法 ArrayL…...

c++—封装:运算符重载、友元
1. 友元 (1)友元函数 ①是一种允许非类成员函数访问类的私有成员的一种机制;可以把一个函数指定为类的友元,也可以把整个类指定为另一个类的友元; ②友元函数在类作用域外定义,但需要在类体中进行声明&…...
【K8s】安全认证与DashBoard
文章目录 一、概述1、客户端2、认证、鉴权与准入控制 二、认证管理1、认证方式2、HTTPS证书认证 三、授权管理1、授权与RBAC2、Role 与 ClusterRole3、RoleBinding 与 ClusterRoleBinding4、案例:创建一个只能管理dev空间下Pods资源的账号 四、准入控制五、DashBoar…...
SpringMVC第七阶段:SpringMVC的增删改查(01)
SpringMVC的增删改查 1、准备单表的数据库 drop database if exists springmvc;create database springmvc;use springmvc; ##创建图书表 create table t_book(id int(11) primary key auto_increment, ## 主键name varchar(50) not null, ## 书名 author varchar(50) no…...
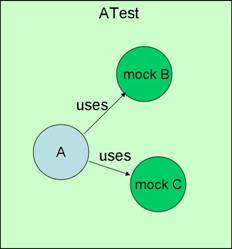
接口测试-Mock测试方法
一、关于Mock测试 1、什么是Mock测试? Mock 测试就是在测试过程中,对于某些不容易构造(如 HttpServletRequest 必须在Servlet 容器中才能构造出来)或者不容易获取的比较复杂的对象(如 JDBC 中的ResultSet 对象&#…...
关于宝塔部署jar包和war包
文章目录 前言一、jar包部署二、war包部署1.maven如果打包不了使用命令打包2.安装Tomcat进行访问是否成功2.进入Tomcat目录进行配置war包 一、项目访问方法 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、jar包部署 1.其实jar包没什么讲的&…...
-第十节)
SpringMVC框架面试专题(初级-中级)-第十节
欢迎大家一起探讨~如果可以帮到大家请为我点赞关注哦~ 截止到本节关于SpringMVC的内容已经更新完毕,后续会更新SpringBoot框架的面试题;大家在背题的时候切记不要死记硬背,需要理解 这是什么?有什么操作&a…...

AI给组内同事的脚本能力价值打了1折!
以前一个做了七八年前端设计的工程师,遇到一个简单的VCD波形解析需求,第一反应可能是是找工具组的人或者脚本能力强的人帮忙。这个场景挺普遍的,只是大家都不太好意思说出来。现在有个概念叫 Vibe Coding,核心是借助AI工具&#x…...

仿真数据与真实数据:机器人训练的数据策略选择
仿真数据与真实数据:机器人训练的数据策略选择摘要:仿真数据和真实数据各有优劣,如何选择和配比直接影响训练效果和项目成本。本文从数据特性、适用场景、配比策略三个维度给出系统分析,并提供Sim-to-Real迁移的工程化方案。关键词…...
)
gmapping算法源码实现分析(一)
gmapping算法源码实现分析(一) —— slam-gmapping功能包主干流程分析 1. slam_gmapping.cpp 初始化流程: SlamGmapping() 构造函数├─> init() - 创建 GridSlamProcessor 实例,读取参数└─> startLiveSlam() - 设置订阅和回调├─&g…...

机器学习引导的多目标运动规划:TSP与采样搜索的深度耦合
1. 项目概述:当机器人需要“跑腿”时,我们如何为它规划最优路线?想象一下,你是一个仓库管理员,手里有一台自动导引车(AGV),今天它的任务是从仓库的充电桩出发,依次去货架…...

ARM SME架构下BFloat16矩阵运算优化实践
1. ARM SME架构与BFloat16计算概述在当今高性能计算领域,特别是机器学习和人工智能应用中,计算效率和内存带宽利用率成为了关键瓶颈。ARMv9架构引入的SME(Scalable Matrix Extension)扩展正是针对这一需求而设计,其中B…...

Unity UI实战:Input Field输入框从入门到精通,搞定用户交互与数据获取
Unity UI实战:Input Field输入框从入门到精通,搞定用户交互与数据获取在游戏和应用开发中,用户输入是不可或缺的交互环节。无论是简单的登录界面、复杂的设置面板,还是实时聊天系统,Input Field都是连接用户与程序的关…...
手把手教你重置)
Kali Linux忘记root密码别慌!两种方法(登录态/非登录态)手把手教你重置
Kali Linux忘记root密码的终极恢复指南:从原理到实战当你正专注于一个关键的安全测试项目,突然发现无法执行需要root权限的操作——这种场景对Kali Linux用户来说并不陌生。作为渗透测试和网络安全研究的标配系统,Kali Linux的root账户是系统…...

人形机器人场景数据采集实战:从方案设计到质量验收
人形机器人场景数据采集实战:从方案设计到质量验收 摘要:人形机器人场景数据采集与传统工业数据采集有本质区别——场景复杂、交互多样、数据量巨大。本文基于多个落地项目经验,从采集方案设计、设备选型、场景编排、质量验收四个环节&#x…...

【深度解析】从 Mythos 到 DeepSeek 降价:大模型工程化选型、成本控制与 API 实战
摘要 近期 AI 大模型市场持续加速迭代:Anthropic Mythos 进入部署测试信号增强,OpenAI、Gemini 系列持续升级,DeepSeek 则通过永久降价重塑开发成本结构。本文从工程视角解析模型发布信号、Agentic 系统成本模型,并给出 OpenAI 兼…...

Qt应用AES/RSA加密监控:Frida+对象生命周期追踪框架
1. 这不是“又一个 Frida 教程”,而是一套可复用的逆向监控工程框架你有没有遇到过这样的场景:在分析一款 Qt 桌面客户端时,发现它用 AES 加密了用户登录凭证,用 RSA 加密了设备指纹,但所有加解密逻辑都藏在QByteArray…...