性能测试如何入门?熬夜7天整理出这一份3000字超全学习指南

赶鸭子上架要我搞性能测试,怎么办?
我第一次真正意义上搞性能测试是在2014年。项目组要求搞性能测试,我之前也没搞过,对服务端也不熟悉。就那么一脸懵逼地开始搞性能。当时我连linux上有哪些能看系统资源的命令都不知道。稀里糊涂地进行了好几轮地性能测试之后,我最大的感受是:对于非专家的测试人员来说,搞性能测试是一个团队活动,而非个人活动。整个过程中,我更多地是借助团队地力量来搞。系统监控不会,找运维帮忙,软件架构不懂,找架构师帮忙,服务器参数不会调,开发替我调。而在这次做完这一波性能测试之后,我下决心要搞懂性能测试到底是怎么搞的。毕竟,刚毕业的时候就听说了,自动化测试和性能测试这俩方向好,但我从来没听谁把“性能测试到底是怎么回事”讲清楚过。我自己在后面的工作中琢磨了很多年,直到最近这两年才琢磨得差不多了,很想跟大家分享一下。
想搞性能测试,要学什么东西?
2006年我还在读书的时候,学校里的软件质量课程里,老师跟我们讲“用win runner做性能测试”。2008年我毕业进第一家公司的时候,公司里的培训老师跟我讲,“用load runner做性能测试“。2011年,我在另一家公司做接口测试的时候,我们用soapUI做功能测试,soapUI的公司的网站上跟我讲,“用loadUI做性能测试”。2012年,我在自学的时候又网上看到了“用jmeter做性能测试”。而后来,gatling,grinder,locust,tsung,工具多得数不胜数。那么,我早就想问了,性能测试就是使用这些测试工具吗?
搞性能测试,并不只是搞搞工具
性能测试最需要的东西,不在于工具,而在于对整个待测系统的理解。首先要理解整个待测系统它的软件架构,硬件架构,网络架构,理解它是如何运行的。它由哪些部分组成,各个部分之间是怎样交互的。用户怎样使用这个系统。在理解系统的基础上,我们可以得出系统的各个部分的性能要求是怎样。也就是性能需求。
而测试的过程也就是验证和探索这些性能需求。
为各种性能需求设计测试场景,再编写测试脚本,执行测试脚本,汇总测试结果,再分析测试结果,进行调优,再重复测试与调优,最后产出测试报告。指明系统是否符合性能需求,哪里还达不到要求。
这其中,跟性能测试工具有关的,只有“编写测试脚本,执行测试脚本”。其他的所有步骤需要的是:计算机科学与技术的各方面综合知识、对业务的理解、对待测系统技术实现的理解。至于性能测试的工具,我们可以选用开源工具,也可以选择自己开发工具。当我们全盘理解性能测试之后,就可以针对具体的需求开发性能测试工具来解决各种实际问题。注意自己开发的性能测试工具与开源工具的区别:自己开发的工具可以很有针对性,而开源工具需要考虑兼容性与普适性。两者的开发重点完全不同。开源工具以推广这个工具为目标,而自己写的工具以最快/最经济解决实际问题为目标。
搞性能测试,如何入门
说了这么多,性能测试到底要如何入门呢。
一方面,工具仍旧是要的,建议使用jmeter等开源工具作为入门学习的工具。照着用户手册操作一遍,花个几天时间就能上手。
更重要的另一方面,我们需要理解性能测试的原理,做性能测试的基本步骤,场景设计的基本策略。不知道这些,光拿个工具,有什么用呢。现实业务千变万化,往往需要测的东西,并不是那么简单拿个工具随便搞搞就能搞好的东西。
一、什么是性能测试
二、性能测试的目的
三、如何做性能测试
四、性能测试关注的指标
五、性能结果分析
六、性能测试资源分享
一、什么是性能测试
是不断的通过不同场景的系统表现去探究系统设计与资源消耗之间的平衡。
我们可以认为性能测试是:通过在测试环境下对系统或构件的性能进行探测,用以验证在生产环境下系统性能是否达到预估的性能需求,发现系统可能存在的性能瓶颈,进而改善优化并系统的性能,提高系统的可扩展性、稳定性。
从上面的描述可以看出,性能测试的主要工作包括:获得预估的性能需求、搭建测试环境、执行测试、分析测试结果。其中,最为重要两个工作是确定测试的目的、方案,并对结果进行分析。
二、性能测试的目的
(1)验证系统是否满足预期需求;
(2)验证系统在高压下的表现;
(3)验证系统是否能持续稳定的运行;
(4)探测系统的瓶颈和产生瓶颈的原因;
(5)探测系统设计与资源之间的最佳平衡,改善并优化系统的性能。
三、如何做性能测试
1. 负载测试: 找到系统稳定时(或满足性能需求下)的最大吞吐量;(要有响应时间、成功率的限制,比如定义:99.9%的响应时间必需在1ms之内,平均响应时间在1ms以内,100%的请求成功)
2. 稳定性(通过浸泡测试soak test): 以系统稳定时的最大吞吐量(或满足性能需求时的最大吞吐量),长时间对系统进行测试,已检查系统是否稳定
3. 压力测试: 找到系统极限值,系统瓶颈(系统崩溃临界值)(要求:响应时间可以变慢,但系统不能崩溃;)(根据测试目的,选择是进行负载、压力、稳定性还是几种测试;)

4. 并发有两个概念:
多个用户同时进行相同操作,访问同一接口——单个业务接口并发;
多个用户同时访问系统,但进行不同的操作,访问不同的接口——系统级并发;(在性能测试过程中,根据 具体场景和业务 选择合适的方案,一般第2种更符合实际场景。以上2种都需要进行测试;)
5. 测试流程: 确定测试目的与需求——根据需求与场景,梳理测试要点——根据测试目的,制定测试方案——准备测试环境与数据——测试执行(脚本或工具)——统计测试结果——分析结果——测试报告
PS:
1 .测试执行时,执行多次,取平均结果更为准确。
2. 单机并发不够时,采用多机分布式并发;
3. 测试过程,一定要尽可能模拟实际应用场景;
四、性能测试关注的指标
测试人员关注(单次业务相关指标):
并发用户数
响应时间:TP(百分比分布统计)
吞吐量:tps/qps
成功率
失败率
开发人员关注(系统层面指标):
1. Tomcat、数据库等;
2. 容量:系统能承载的最大访问量是多少?系统最大的业务处理量是多少?
3. 稳定性:是否支持7*24小时(一周)的业务访问?
运维人员关注(硬件资源相关指标 ):
硬件资源消耗情况:CPU、内存、I/O读写速度、网络带宽等
五、性能结果分析
以下相关指标分析时需注意:
1.响应时间不要光看平均值,平均值不靠谱。要求最好定成:99.9%请求必须<1s,所有的平均响应时间必须<1s,这两个条件限制;
2.响应时间要和吞吐量TPS/QPS挂钩;

系统的性能如果只看吞吐量,不看响应时间是没有意义的。我的系统可以顶10万请求,但是响应时间已经到了5秒钟,这样的系统已经不可用了,这样的吞吐量也是没有意义的。
我们知道,当并发量(吞吐量)上涨的时候,系统会变得越来越不稳定,响应时间的波动也会越来越大,响应时间也会变得越来越慢,而吞吐率也越来越上不去(如上图所示),包括CPU的使用率情况也会如此。所以,当系统变得不稳定的时候,吞吐量已经没有意义了。吞吐量有意义的时候仅当系统稳定的时候。
所以,吞吐量的值必须有响应时间来卡。比如:TP99小于100ms的时候,系统可以承载的最大并发数是1000qps。这意味着,我们要不断的在不同的并发数上测试,以找到软件的最稳定时的最大吞吐量。
3. 响应时间吞吐量要和成功率挂钩 ;
不难理解,如果请求可以并发10w,但是成功率只有40%,那也没什么用。
性能测试的失败率的容忍应该是非常低的。对于一些关键系统,成功请求数必须在100%,一点都不能含糊。
4. CPU、内存等硬件资源占比持续超过90%,说明性能存在瓶颈;
5. 带宽波动起伏很大,说明带宽受限;
六、性能测试资源分享
下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!【保证100%免费】
凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助……

相关文章:
性能测试如何入门?熬夜7天整理出这一份3000字超全学习指南
赶鸭子上架要我搞性能测试,怎么办? 我第一次真正意义上搞性能测试是在2014年。项目组要求搞性能测试,我之前也没搞过,对服务端也不熟悉。就那么一脸懵逼地开始搞性能。当时我连linux上有哪些能看系统资源的命令都不知道。稀里糊涂…...
信息安全实践1.2(重放攻击)
前言 这个实验是看一本书做的,就是李华峰老师的书——《Metasploit Web 渗透测试实战》,我之前写过一篇Slowloris DoS攻击的博客,也是看这本书写的,总的来说,有用处。这篇博客其实也只是很浅显的去做一下重放攻击。 要…...
上海亚商投顾:沪指高开高走 地产股迎来久违反弹
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日高开高走,沪指午后涨近1%,深成指、创业板指涨超1.2%,上证50盘中大…...
Vim学习笔记【Ch02】
Vim学习笔记 系列笔记链接Ch02 Buffers, Windows, TabsBuffers什么是buffer查看所有bufferbuffer之间的切换删除buffer退出所有窗口 Windows窗口的创建窗口切换快捷键其他快捷键 Tabs什么是tabtab相关命令 window和buffer结合的3D移动小结 系列笔记链接 Ch00,Ch01 …...

《低代码指南》——低代码维格云能源行业解决方案
目录 典型场景介绍: 一、能源资产管理 二、碳核查 三、配电运营 总 结: 从业界实际情况来看,流程建设本身是一个对业务现实进行抽象的过程,这个过程即使不考虑软件开发的门槛,对于很多客户而言也是个涉及较长周期的复杂工作,往往需要咨询专家或专业公司帮助其建设内…...

【自制C++深度学习推理框架】Layer的设计思路
Layer的设计思路 Layer的抽象 如果将深度学习中的所有层分为两类, 那么肯定是"带权重"的层和"不带权重"的层。 基于层的共性,我们定义了一个Layer的基类,提供了一些基本接口,并可以通过继承和多态机制实现不同类型的L…...

Rust每日一练(Leetday0011) 下一排列、有效括号、搜索旋转数组
目录 31. 下一个排列 Next Permutation 🌟🌟 32. 最长有效括号 Longest Valid Parentheses 🌟🌟🌟 33. 搜索旋转排序数组 Search-in-rotated-sorted-array 🌟🌟 🌟 每日一练刷…...

STL --- 五. 函数对象 Function Objects
目录 1、函数对象的定义和作用 2、函数对象的分类和使用 3、std 常用的函数对象 4、函数对象的适配器 5、std 算法和函数对象区别 1、函数对象的定义和作用 STL(Standard Template Library)中的函数对象(Functor)是一种重载…...

Java IO 流操作详解
Java IO 流操作详解 一、简介1. 什么是IO流2. IO流的分类3. IO流的作用 二、Java IO流的输入操作1. 文件输入流2. 字节输入流3. 缓冲输入流4. 对象输入流 三、Java IO流的输出操作1. 文件输出流2. 字节输出流3. 缓冲输出流4. 对象输出流 四、Java IO流的常用方法解析1. 字节读写…...

Halcon 形状匹配参数详解
find_shape_model(Image : : ModelID, AngleStart, AngleExtent, MinScore, NumMatches, MaxOverlap, SubPixel, NumLevels, Greediness : Row, Column, Angle, Score) find_shape_model(Image : : //搜索图像 ModelID, //模板句柄 AngleStart, // 搜索时的起始角度 AngleExte…...

C++11强类型枚举
C11引入了强类型枚举(enum class),也称为枚举类。 强类型枚举是一种更加类型安全的枚举类型,相对于传统的枚举类型,强类型枚举可以提供更好的安全性和可读性。 强类型枚举的格式如下: enum class 枚举名 …...
)
pytorch讲解(部分)
友爱的目录 自动求导机制从后向中排除子图自动求导如何编码历史信息Variable上的In-place操作In-place正确性检查 CUDA语义最佳实践使用固定的内存缓冲区使用 nn.DataParallel 替代 multiprocessing 扩展PyTorch扩展 torch.autograd扩展 torch.nn 多进程最佳实践共享CUDA张量最…...
)
C++ 基本的7种数据类型和4种类型转换(C++复习向p3)
文章目录 基本内置类型存储范围typedef 声明新名字enum 枚举类型类型转换 基本内置类型 boolcharintfloatdoublevoidwchar_t ⇒ short int 存储范围 可以这样 sizeof(int) 来确认 int 占用字节数 char,1字节,-128~127 或 0~255 wchar_t,2…...
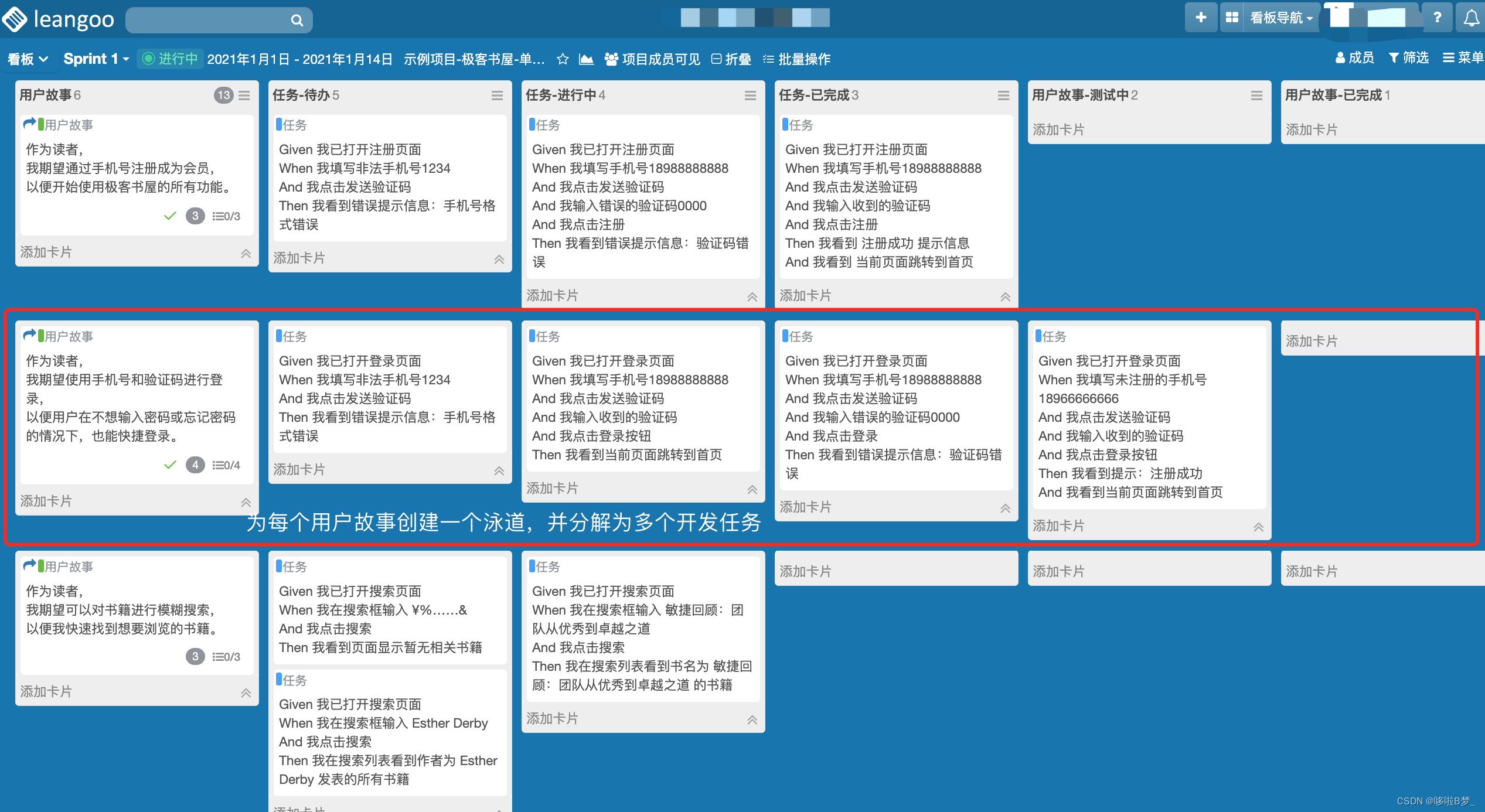
Scrum敏捷迭代规划和执行
Sprint Backlog看板 迭代工作的开展是围绕Sprint Backlog展开的,在Leangoo中,我们需要为每个迭代创建一个Sprint Backlog看板。Sprint Backlog(迭代)看板,用于管理当前Sprint的需求和开发任务,可视化展示每…...
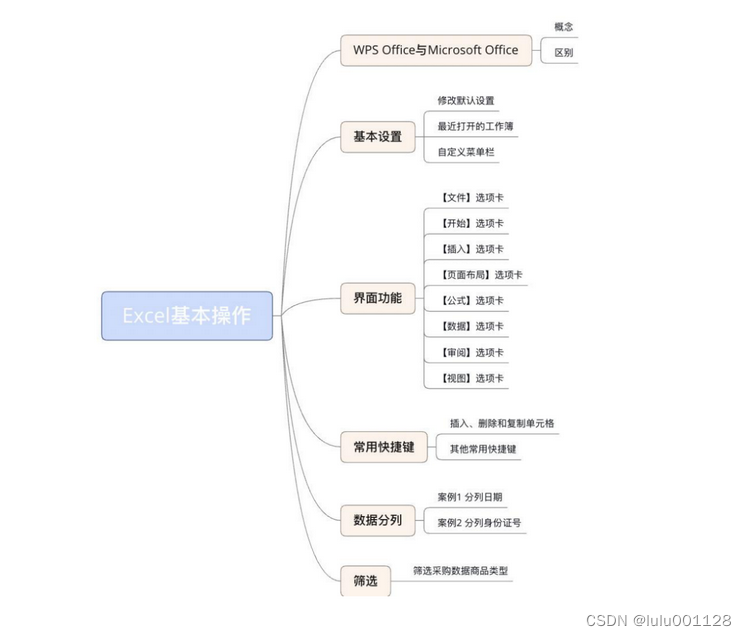
智警杯赛前学习1.1---excel基本操作
修改默认设置 步骤一:打开“Excel选项”窗口,打开“文件”菜单,选择“选项”标签 步骤二:在“Excel选项”窗口中,选择“常规与保存”标签,在“常规与保存”标签中,可以修改录入数据时的默认字体…...
 主要特点和用途)
【Android】Handle(一) 主要特点和用途
在Android中,Handler是一种消息处理机制,它允许我们在不同线程之间交换信息并更新UI。具体来说,Handler可以将一个Runnable或Message对象加入到消息队列中,并在合适的时间去执行它们。 以下是Handler的主要特点和用途:…...

40亿个QQ号,限制1G内存,如何去重?【已通过代码实现】
前几天发现一个有趣的文章 “40亿个QQ号,限制1G内存,如何去重?”,发现很有意思,就想着用代码实现一下,下面是分析和实现过程 一、审题分析 一个 QQ 号现在最长有 11 位,因为 int 是四字节,数值范围是2的31次方,因此得使用 long 存储,但考虑到实现,使用 int 存储(1…...

Talk预告 | 新加坡国立大学张傲:10%成本定制类 GPT-4 多模态大模型
本期为TechBeat人工智能社区第502期线上Talk! 北京时间06月01日(周四)20:00,新加坡国立大学在读博士生 — 张傲的Talk将准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “10%成本定制类 GPT-4 多模态大模型 ”,届时将介…...

从C语言到C++_13(string的模拟实现)深浅拷贝+传统/现代写法
前面已经对 string 类进行了简单的介绍和应用,大家只要能够正常使用即可。 在面试中,面试官总喜欢让学生自己 来模拟实现string类, 最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。 为了更深入学习STL,下面我…...
方法详解)
reduce()方法详解
一、 定义和用法 reduce() 方法将数组缩减为单个值。 reduce() 方法为数组的每个值(从左到右)执行提供的函数。 函数的返回值存储在累加器中(结果/总计)。 注释:对没有值的数组元素,不执行 reduce() 方法。…...

从激活困境到一键解放:KMS_VL_ALL_AIO如何重塑你的Windows与Office体验
从激活困境到一键解放:KMS_VL_ALL_AIO如何重塑你的Windows与Office体验 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows激活问题而烦恼?每次重装系统后…...

渗透测试新手必练的10个靶场:从DVWA到Active的四阶实战路径
1. 为什么这10个靶场不是“随便选的”,而是新手绕不开的实战起点刚入行做渗透测试的朋友,常会陷入一个典型误区:花大量时间看漏洞原理、背命令、刷CTF题,却迟迟不敢碰真实靶机。我带过不少实习生,第一周让他们连上一个…...

告别VNC客户端!用noVNC在浏览器里远程操控CentOS桌面,附Xshell/Xftp联动技巧
浏览器原生远程桌面方案:noVNC与终端工具链的高效整合指南每次连接远程服务器都要切换多个客户端的日子该结束了。想象一下这样的场景:清晨的咖啡馆里,你只需打开浏览器就能直接访问CentOS的图形界面,同时在一个标签页里用Xshell执…...
)
终极指南:如何将STL文件快速转换为STEP格式(免费工具完整教程)
终极指南:如何将STL文件快速转换为STEP格式(免费工具完整教程) 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在现代3D设计与制造流程中,STL到S…...

FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器
FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?每次…...

基于椭圆特征与多保真度学习的CFD小数据加速初始化方法
1. 项目概述与核心价值在计算流体动力学(CFD)的日常仿真工作中,我们经常面临一个看似简单却极其耗时的难题:如何给一个复杂的流场计算提供一个“像样”的初始猜测?新手可能会直接使用均匀来流条件,而有经验…...

构建高性能医疗对话数据引擎:792,099条中文医疗问答数据集的技术架构与应用
构建高性能医疗对话数据引擎:792,099条中文医疗问答数据集的技术架构与应用 【免费下载链接】Chinese-medical-dialogue-data Chinese medical dialogue data 中文医疗对话数据集 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-medical-dialogue-data …...

DLSS Swapper完全指南:智能管理游戏DLSS版本的开源革命
DLSS Swapper完全指南:智能管理游戏DLSS版本的开源革命 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾在《赛博朋克2077》中为DLSS版本过旧导致的画面闪烁而烦恼?是否因为《控制》中的…...

终极免费色彩校准方案:用novideo_srgb解决NVIDIA显卡广色域显示器色彩过饱和问题
终极免费色彩校准方案:用novideo_srgb解决NVIDIA显卡广色域显示器色彩过饱和问题 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirro…...

VMware Workstation Pro 17免费许可证密钥终极指南:快速搭建专业虚拟化环境
VMware Workstation Pro 17免费许可证密钥终极指南:快速搭建专业虚拟化环境 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major …...