pytorch讲解(部分)
友爱的目录
- 自动求导机制
- 从后向中排除子图
- 自动求导如何编码历史信息
- Variable上的In-place操作
- In-place正确性检查
- CUDA语义
- 最佳实践
- 使用固定的内存缓冲区
- 使用 nn.DataParallel 替代 multiprocessing
- 扩展PyTorch
- 扩展 torch.autograd
- 扩展 torch.nn
- 多进程最佳实践
- 共享CUDA张量
- 最佳实践和提示
- 避免和抵制死锁
- 重用经过队列的缓冲区
- 异步多进程训练(例如Hogwild)
- 序列化语义
- PACKAGE参考
- 参考文献
自动求导机制
了解这些并不是绝对必要的,但我们建议您熟悉它,因为它将帮助您编写更高效,更简洁的程序,并可帮助您进行调试。
从后向中排除子图
每个变量都有两个标志:requires_grad和volatile。它们都允许从梯度计算中精细地排除子图,并可以提高效率。
>>> x = Variable(torch.randn(5, 5))
>>> y = Variable(torch.randn(5, 5))
>>> z = Variable(torch.randn(5, 5), requires_grad=True)
>>> a = x + y
>>> a.requires_grad
False
>>> b = a + z
>>> b.requires_grad
True
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():param.requires_grad = False
# Replace the last fully-connected layer
# Parameters of newly constructed modules have requires_grad=True by default
model.fc = nn.Linear(512, 100)# Optimize only the classifier
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
>>> regular_input = Variable(torch.randn(5, 5))
>>> volatile_input = Variable(torch.randn(5, 5), volatile=True)
>>> model = torchvision.models.resnet18(pretrained=True)
>>> model(regular_input).requires_grad
True
>>> model(volatile_input).requires_grad
False
>>> model(volatile_input).volatile
True
>>> model(volatile_input).creator is None
True
自动求导如何编码历史信息
Variable上的In-place操作
In-place正确性检查
CUDA语义
torch.cuda会记录当前选择的GPU,并且分配的所有CUDA张量将在上面创建。可以使用torch.cuda.device上下文管理器更改所选设备。
x = torch.cuda.FloatTensor(1)
# x.get_device() == 0
y = torch.FloatTensor(1).cuda()
# y.get_device() == 0with torch.cuda.device(1):# allocates a tensor on GPU 1a = torch.cuda.FloatTensor(1)# transfers a tensor from CPU to GPU 1b = torch.FloatTensor(1).cuda()# a.get_device() == b.get_device() == 1c = a + b# c.get_device() == 1z = x + y# z.get_device() == 0# even within a context, you can give a GPU id to the .cuda calld = torch.randn(2).cuda(2)# d.get_device() == 2
最佳实践
使用固定的内存缓冲区
当副本来自固定(页锁)内存时,主机到GPU的复制速度要快很多。CPU张量和存储开放了一个pin_memory() 方法,它返回该对象的副本,而它的数据放在固定区域中。
另外,一旦固定了张量或存储,就可以使用异步的GPU副本。只需传递一个额外的async=True参数到 cuda() 的调用。这可以用于将数据传输与计算重叠。
通过将pin_memory=True 传递给其构造函数,可以使DataLoader将batch返回到固定内存中。
使用 nn.DataParallel 替代 multiprocessing
大多数涉及批量输入和多个GPU的情况应默认使用DataParallel来使用多个GPU。尽管有GIL的存在,单个python进程也可能使多个GPU饱和。
从0.1.9版本开始,大量的GPU(8+)可能未被充分利用。然而,这是一个已知的问题,也正在积极开发。和往常一样,测试你的用例吧。
调用multiprocessing来利用CUDA模型存在重要的注意事项;使用具有多处理功能的CUDA模型有重要的注意事项; 除非就是需要谨慎地满足数据处理需求,否则您的程序很可能会出现错误或未定义的行为。
扩展PyTorch
本篇文章中包含如何扩展 torch.nn, torch.autograd和使用我们的 C 库 编写自定义的C 扩展。
扩展 torch.autograd
# Inherit from Function
class Linear(Function):# bias is an optional argumentdef forward(self, input, weight, bias=None):self.save_for_backward(input, weight, bias)output = input.mm(weight.t())if bias is not None:output += bias.unsqueeze(0).expand_as(output)return output# This function has only a single output, so it gets only one gradientdef backward(self, grad_output):# This is a pattern that is very convenient - at the top of backward# unpack saved_tensors and initialize all gradients w.r.t. inputs to# None. Thanks to the fact that additional trailing Nones are# ignored, the return statement is simple even when the function has# optional inputs.input, weight, bias = self.saved_tensorsgrad_input = grad_weight = grad_bias = None# These needs_input_grad checks are optional and there only to# improve efficiency. If you want to make your code simpler, you can# skip them. Returning gradients for inputs that don't require it is# not an error.if self.needs_input_grad[0]:grad_input = grad_output.mm(weight)if self.needs_input_grad[1]:grad_weight = grad_output.t().mm(input)if bias is not None and self.needs_input_grad[2]:grad_bias = grad_output.sum(0).squeeze(0)return grad_input, grad_weight, grad_bias
现在,为了可以更简单的使用自定义的operation,我们建议将其用一个简单的 helper function 包装起来。 functions:
def linear(input, weight, bias=None):# First braces create a Function object. Any arguments given here# will be passed to __init__. Second braces will invoke the __call__# operator, that will then use forward() to compute the result and# return it.return Linear()(input, weight, bias)
你可能想知道你刚刚实现的 backward方法是否正确的计算了梯度。你可以使用 小的有限的差分进行数值估计。
from torch.autograd import gradcheck# gradchek takes a tuple of tensor as input, check if your gradient
# evaluated with these tensors are close enough to numerical
# approximations and returns True if they all verify this condition.
input = (Variable(torch.randn(20,20).double(), requires_grad=True),)
test = gradcheck.gradcheck(Linear(), input, eps=1e-6, atol=1e-4)
print(test)
扩展 torch.nn
class Linear(nn.Module):def __init__(self, input_features, output_features, bias=True):self.input_features = input_featuresself.output_features = output_features# nn.Parameter is a special kind of Variable, that will get# automatically registered as Module's parameter once it's assigned# as an attribute. Parameters and buffers need to be registered, or# they won't appear in .parameters() (doesn't apply to buffers), and# won't be converted when e.g. .cuda() is called. You can use# .register_buffer() to register buffers.# nn.Parameters can never be volatile and, different than Variables,# they require gradients by default.self.weight = nn.Parameter(torch.Tensor(input_features, output_features))if bias:self.bias = nn.Parameter(torch.Tensor(output_features))else:# You should always register all possible parameters, but the# optional ones can be None if you want.self.register_parameter('bias', None)# Not a very smart way to initialize weightsself.weight.data.uniform_(-0.1, 0.1)if bias is not None:self.bias.data.uniform_(-0.1, 0.1)def forward(self, input):# See the autograd section for explanation of what happens here.return Linear()(input, self.weight, self.bias)#注意这个Linear是之前实现过的Linear
多进程最佳实践
共享CUDA张量
最佳实践和提示
避免和抵制死锁
重用经过队列的缓冲区
异步多进程训练(例如Hogwild)
import torch.multiprocessing as mp
from model import MyModeldef train(model):# Construct data_loader, optimizer, etc.for data, labels in data_loader:optimizer.zero_grad()loss_fn(model(data), labels).backward()optimizer.step() # This will update the shared parametersif __name__ == '__main__':num_processes = 4model = MyModel()# NOTE: this is required for the ``fork`` method to workmodel.share_memory()processes = []for rank in range(num_processes):p = mp.Process(target=train, args=(model,))p.start()processes.append(p)for p in processes:p.join()
序列化语义
PACKAGE参考
参考文献
参考链接:https://pytorch-cn.readthedocs.io/zh/latest/
相关文章:
)
pytorch讲解(部分)
友爱的目录 自动求导机制从后向中排除子图自动求导如何编码历史信息Variable上的In-place操作In-place正确性检查 CUDA语义最佳实践使用固定的内存缓冲区使用 nn.DataParallel 替代 multiprocessing 扩展PyTorch扩展 torch.autograd扩展 torch.nn 多进程最佳实践共享CUDA张量最…...
)
C++ 基本的7种数据类型和4种类型转换(C++复习向p3)
文章目录 基本内置类型存储范围typedef 声明新名字enum 枚举类型类型转换 基本内置类型 boolcharintfloatdoublevoidwchar_t ⇒ short int 存储范围 可以这样 sizeof(int) 来确认 int 占用字节数 char,1字节,-128~127 或 0~255 wchar_t,2…...
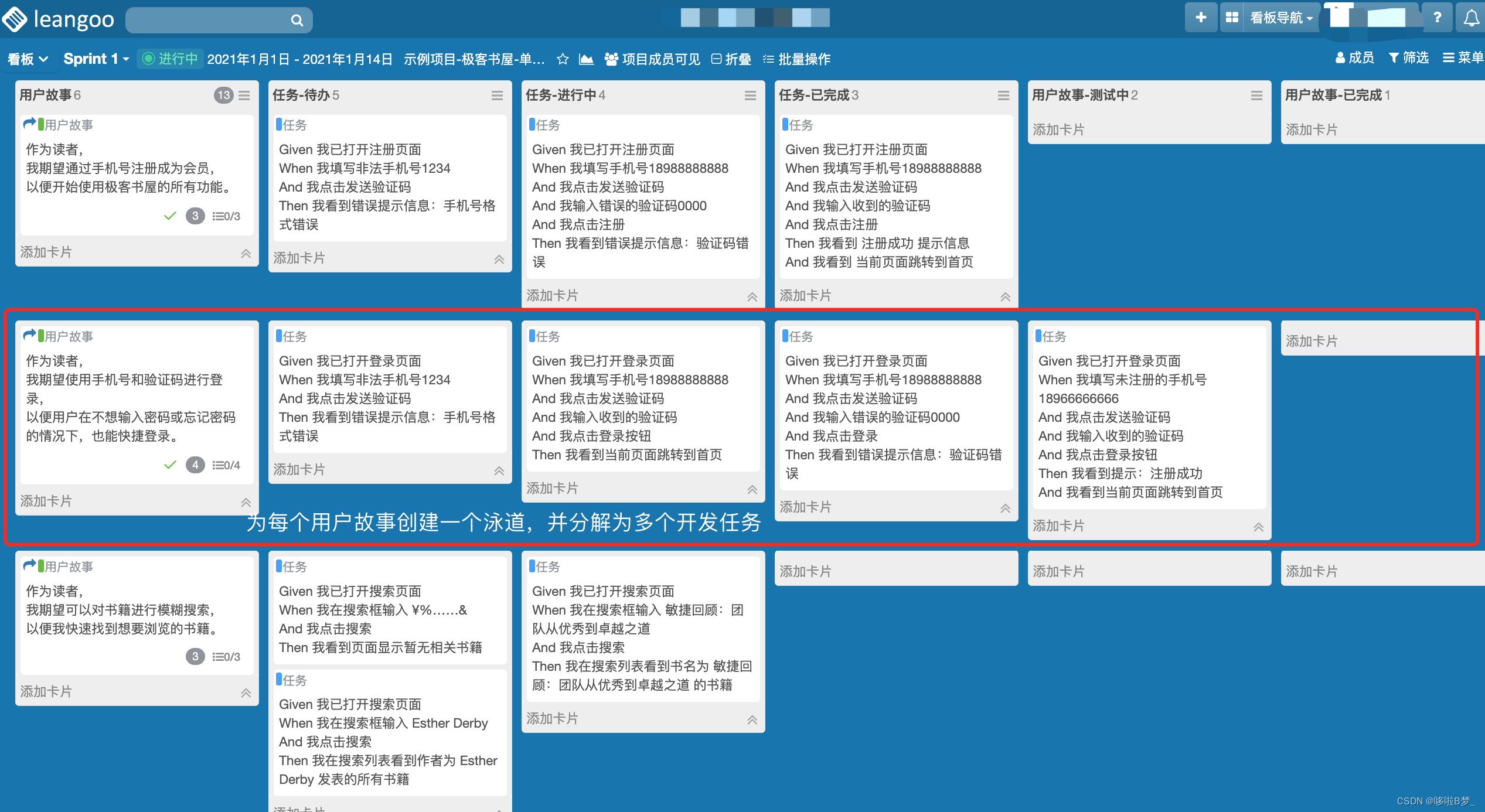
Scrum敏捷迭代规划和执行
Sprint Backlog看板 迭代工作的开展是围绕Sprint Backlog展开的,在Leangoo中,我们需要为每个迭代创建一个Sprint Backlog看板。Sprint Backlog(迭代)看板,用于管理当前Sprint的需求和开发任务,可视化展示每…...
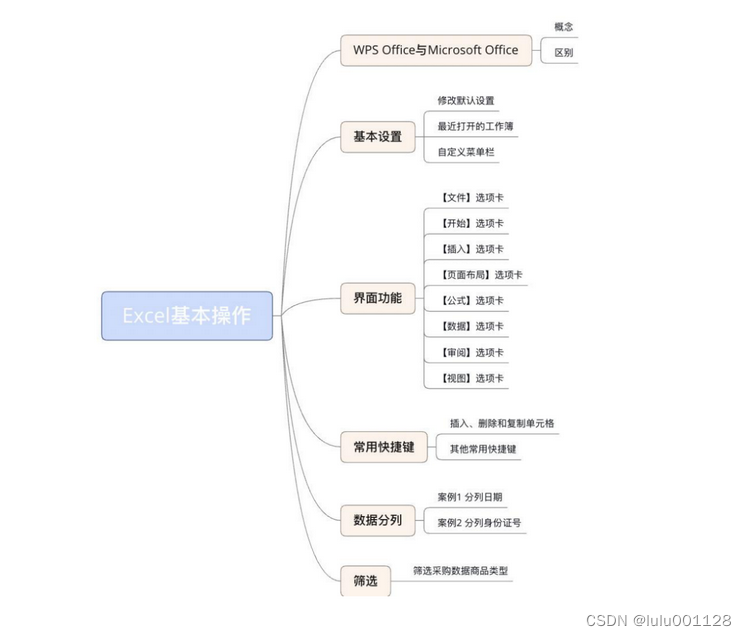
智警杯赛前学习1.1---excel基本操作
修改默认设置 步骤一:打开“Excel选项”窗口,打开“文件”菜单,选择“选项”标签 步骤二:在“Excel选项”窗口中,选择“常规与保存”标签,在“常规与保存”标签中,可以修改录入数据时的默认字体…...
 主要特点和用途)
【Android】Handle(一) 主要特点和用途
在Android中,Handler是一种消息处理机制,它允许我们在不同线程之间交换信息并更新UI。具体来说,Handler可以将一个Runnable或Message对象加入到消息队列中,并在合适的时间去执行它们。 以下是Handler的主要特点和用途:…...

40亿个QQ号,限制1G内存,如何去重?【已通过代码实现】
前几天发现一个有趣的文章 “40亿个QQ号,限制1G内存,如何去重?”,发现很有意思,就想着用代码实现一下,下面是分析和实现过程 一、审题分析 一个 QQ 号现在最长有 11 位,因为 int 是四字节,数值范围是2的31次方,因此得使用 long 存储,但考虑到实现,使用 int 存储(1…...

Talk预告 | 新加坡国立大学张傲:10%成本定制类 GPT-4 多模态大模型
本期为TechBeat人工智能社区第502期线上Talk! 北京时间06月01日(周四)20:00,新加坡国立大学在读博士生 — 张傲的Talk将准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “10%成本定制类 GPT-4 多模态大模型 ”,届时将介…...

从C语言到C++_13(string的模拟实现)深浅拷贝+传统/现代写法
前面已经对 string 类进行了简单的介绍和应用,大家只要能够正常使用即可。 在面试中,面试官总喜欢让学生自己 来模拟实现string类, 最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。 为了更深入学习STL,下面我…...
方法详解)
reduce()方法详解
一、 定义和用法 reduce() 方法将数组缩减为单个值。 reduce() 方法为数组的每个值(从左到右)执行提供的函数。 函数的返回值存储在累加器中(结果/总计)。 注释:对没有值的数组元素,不执行 reduce() 方法。…...

C++虚假唤醒
概念: 虚假唤醒是指在使用条件变量时,线程被唤醒但条件并没有满足,导致线程执行错误的情况,这个过程就是虚假唤醒。 虚假唤醒弊端: 虚假唤醒会导致程序的正确性受到影响,因为唤醒的线程并没有满足条件&…...

【AI】dragonGPT - 单机部署、极速便捷
dragonGPT 从数据私有化,到prompt向量库匹配,再到查询,一条龙服务,单机部署,极简操作 pre a.需要下载gpt4all model到本地. ggml Model Download Link 然后将存放model的地址写入.env MODEL_PATH your pathb.…...

Uuiapp使用生命周期,路由跳转传参
Uniapp生命周期: 1. beforeCreate:在实例初始化之后,数据观测和事件配置之前被调用。 2. created:在实例创建完成后被立即调用。 3. beforeMount:在挂载开始之前被调用:相关的 render 函数首次被调用。 …...
习题)
定积分的计算(牛顿-莱布尼茨公式)习题
前置知识:定积分的计算(牛顿-莱布尼茨公式) 习题1 计算 ∫ 0 2 ( x 2 − 2 x 3 ) d x \int_0^2(x^2-2x3)dx ∫02(x2−2x3)dx 解: \qquad 原式 ( 1 3 x 3 − x 2 3 x ) ∣ 0 2 ( 8 3 − 4 6 ) − 0 14 3 (\dfrac 13x^3-…...

leak 记录今天的一个小题
先看题, add没有大小限制,这里edit可以溢出8字节,也就是可以改后边的size,可以调用4次free没有调用函数只是把指针置0,show可以用一次. void __fastcall __noreturn main(__int64 a1, char **a2, char **a3) {init_0(a1, a2, a3);while ( 1 ){menu();switch ( read_n() ){cas…...

软考A计划-试题模拟含答案解析-卷二
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&am…...

【C++】pthread
一、pthread简介 pthread是C98接口且只支持Linux,使用时需要包含头文件#include <pthread.h>,编译时需要链接pthread库,其中p是POSIX的缩写,而POSIX是Portable Operating System Interface的缩写,是IEEE为要在各…...
2023年前端面试题汇总-浏览器原理
1. 浏览器安全 1.1. 什么是 XSS 攻击? 1.1. 1. 概念 XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 cookie 等。 XSS 的本质是因为网站没有对…...

react介绍,react语法,react高级特性,react编程技巧
React是一个用于构建用户界面的JavaScript库。它由Facebook开发,于2013年首次发布。React的主要目标是提高应用程序的性能和可维护性。React采用了一种称为“组件”的模式,使开发人员可以将应用程序拆分为小而独立的部分,从而更容易编写和维护…...
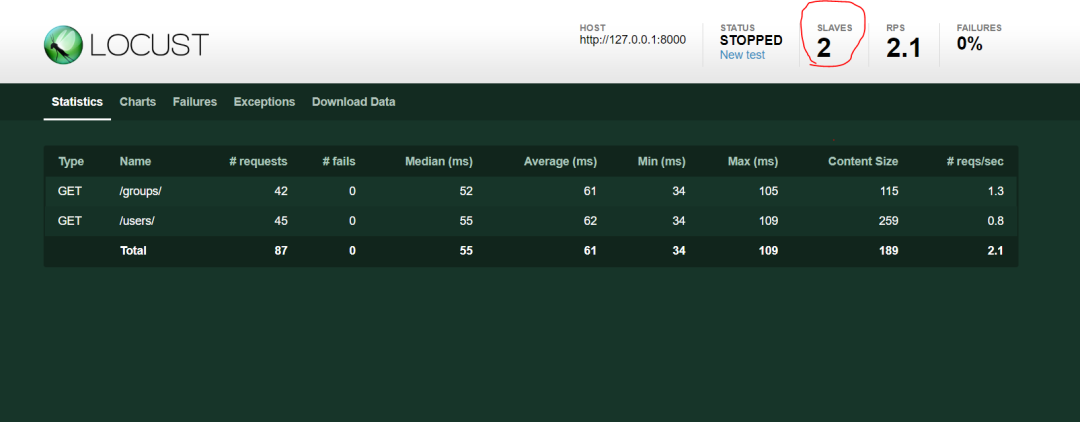
Locust接口性能测试
谈到性能测试工具,我们首先想到的是LoadRunner或JMeter。LoadRunner是非常有名的商业性能测试工具,功能非常强大。但现在一般不推荐使用该工具来进行性能测试,主要是使用也较为复杂,而且该工具体积比较大,需要付费且价…...
)
Python类的特殊方法(通过故事来学习)
在一座森林里,住着三只动物:狼、兔和熊。这三只动物都有不同的特点和能力,但是它们所有的行为都可以被抽象成一个“动物”类。现在,让我们来看看Python中的类和特殊方法如何帮助我们实现这个故事。 首先,我们可以定义…...

GNSS欺骗干扰检测算法与实验验证方法【附仿真】
✨ 长期致力于GNSS欺骗干扰检测、信号检测、伪距差分、捷联惯性导航、IMU信号生成、四元数、对偶四元数、惯性辅助、单星紧组合、欺骗干扰场景模拟研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,…...
)
Sora 2视频音频不同步?深度解析OpenAI未公开的时间戳嵌入机制,3分钟强制同步方案(含Python自动校准工具)
更多请点击: https://codechina.net 第一章:Sora 2视频音频不同步现象的系统性归因 视频与音频流在 Sora 2 模型推理及播放阶段出现时间偏移,是影响用户体验的关键缺陷。该现象并非单一环节导致,而是由多层级时序建模、硬件调度、…...

微信小程序抓包实战:安卓模拟器+BurpSuite无Root稳定方案
1. 为什么微信小程序抓包成了“玄学”,而这条路径能绕过所有坑做移动安全测试或前端调试的同行,大概率都经历过这种场景:想看看微信小程序发了什么请求、带了哪些参数、响应体里有没有敏感字段,结果一上手就卡在第一步——连包都抓…...

机器学习模型自洽性:方差、公平性与弃权机制
1. 项目概述:当机器学习模型“拿不准”时,我们该让它闭嘴吗?在机器学习,尤其是涉及公平性决策的场景里,我们常常面临一个两难困境:模型必须给出一个明确的“是”或“否”的答案,但有时它自己内部…...

Adobe-GenP终极指南:3分钟解锁Adobe全家桶完整方案
Adobe-GenP终极指南:3分钟解锁Adobe全家桶完整方案 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud设计的智能…...

GTA5线上小助手:终极方案助你高效称霸洛圣都
GTA5线上小助手:终极方案助你高效称霸洛圣都 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 厌倦了在GTA5线上模式中重复枯燥的刷钱任务?想要快速解锁所有服装和载具却不知从何入…...

JHenTai:5大核心功能打造你的全平台漫画阅读体验
JHenTai:5大核心功能打造你的全平台漫画阅读体验 【免费下载链接】JHenTai A cross-platform manga app made for e-hentai & exhentai by Flutter 项目地址: https://gitcode.com/gh_mirrors/jh/JHenTai 在数字阅读时代,寻找一款既能在手机上…...

5分钟掌握qmcdump:解锁QQ音乐加密音频的终极指南
5分钟掌握qmcdump:解锁QQ音乐加密音频的终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

熬夜赶论文效率低到哭?学长安利这几个AI论文写作软件
熬夜赶论文效率低到哭?选题没思路、大纲难搭建、初稿写不顺、文献找不全、润色没方向、降重费时间、格式不规范——这些论文写作的痛点,其实都可以通过用对AI工具、走对流程来解决。资深教授普遍推荐:千笔AI(中文全流程首选&#…...

高基数分类变量编码实战:均值、低秩与多项式逻辑回归方法解析
1. 项目概述:高基数分类变量的编码困局与破局思路在数据科学和机器学习的日常建模工作中,分类变量(Categorical Variables)的处理是绕不开的一环。从用户ID、邮政编码到产品SKU,这些变量往往携带了丰富的信息ÿ…...