从C语言到C++_13(string的模拟实现)深浅拷贝+传统/现代写法
目录
1. string默认成员函数
1.1 构造和析构
1.2 深浅拷贝介绍
1.3 拷贝构造的实现
1.4 赋值的实现
1.5 写时拷贝(了解)
2. string 的部分函数实现
2.1 完整默认成员函数代码:
2.2 c_str() 的实现
2.3 全缺省构造函数的实现
2.4 size() 和 operator[] 的实现
3. string的迭代器
3.1 string迭代器的实现
3.2 迭代器和范围for再思考
4. string的增删查改函数实现
4.1 reserve() 的实现
4.2 push_back() 的实现
4.3 append() 的实现
4.4 operator+= 的实现
4.5 insert() 的实现
4.6 resize() 的实现
4.7 find() 的实现
4.8 erase() 的实现
5. 传统写法和现代写法
5.1 拷贝构造的现代写法
5.2 赋值重载的现代写法
6. operator 运算符重载
6.1 六个比较运算符重载
6.2 流插入和流提取重载
7. 完整代码:
string.h:
Test.c:
本章完。
1. string默认成员函数
1.1 构造和析构
我们先试着来实现 string 的构造和析构:
整体框架:
string.h
#pragma once#include<iostream>
#include<string>
#include<assert.h>
using namespace std;namespace rtx
{class string{public:string(const char* s){}~string() {}private:char* _str;};void test_string1(){string s1("hello world");}
}Test.c:
#include "string.h"int main()
{try{rtx::test_string1();}catch (const exception& e){cout << e.what() << endl;}return 0;
}这里为了和原有的 string 进行区分,我们搞一个命名空间给它们括起来。
我们的测试就放在简单提到的try catch上,然后该序号就能测试了。
构造函数是这样写吗?这样写的话拷贝构造能直接用默认生成的吗
string(const char* s): _str(new char[strlen(s) + 1])// 开strlen大小的空间(多开一个放\0){strcpy(_str, str);}然后我们先实现析构,用 new[] 对应的 delete[] 来析构:
~string() {delete[] _str;_str = nullptr;}放到上面的框架:编译通过
此时我们改一下测试用例 test_string1,如果我们要用 s1 拷贝构造一下 s2:

详细解析:

1.2 深浅拷贝介绍
如何解决这样的问题呢?
我们 s2 拷贝构造你 s1,本意并不是想跟你指向一块空间!
我们的本意是想让 s2 有一块自己的空间,并且能使其内容是 s1 里的 hello world
这就是深拷贝。

所以这里就涉及到了深浅拷贝的问题,我们下面就来探讨一下深浅拷贝的问题。
浅拷贝:(直接把内存无脑指过去) 也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。深拷贝:(开一块一样大的空间,再把数据拷贝下来,指向我自己开的空间) 如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供。
1.3 拷贝构造的实现
我们之前实现日期类的时候,用自动生成的拷贝构造(浅拷贝)是可以的,
所以当时我们不用自己实现拷贝构造,让它默认生成就足够了。
但是像 string 这样的类,它的拷贝构造我们不得不亲自写:
string(const string& s):_str(new char[s._capacity + 1]){strcpy(_str, s._str);}
这就实现了深拷贝。
1.4 赋值的实现
现在有一个 s3,如果我们想把 s3 赋值给 s1:
void test_string1(){string s1("hello world");string s2(s1);string s3("!!!");s1 = s3;}如果你不自己实现赋值,就和之前一样,会是浅拷贝,也会造成崩溃。
所以,我们仍然需要自己实现一个 operator= ,首先思路如下:
string& operator=(const string& s){if (this != &s){delete[] _str;// 释放原有空间_str = new char[s._capacity + 1];// 开辟新的空间strcpy(_str, s._str);// 赋值_size = s._size;_capacity = s._capacity;}return *this;}根据我们的实现思路,首先释放原有空间,然后开辟新的空间,
最后把 s3 的值赋值给 s1。为了防止自己给自己赋值,我们可以判断一下。
这时我们还要考虑一个难以发现的问题,如果 new 失败了怎么办?
抛异常!失败了没问题,也不会走到 strcpy,但问题是我们已经把原有的空间释放掉了,
走到析构那里二次释放可能会崩,所以我们得解决这个问题。
可以试着把释放原有空间的步骤放到后面:
string& operator=(const string& s){if (this != &s){char* tmp = new char[s._capacity + 1];// 开辟新的空间strcpy(tmp, s._str);// 赋值到tmpdelete[] _str;// 释放原有空间_str = tmp;// tmp赋值到想要的地方,出去tmp就销毁了_size = s._size;_capacity = s._capacity;}return *this;}这样一来,就算是动态内存开辟失败了,我们也不用担心出问题了。
这是更标准的实现方式,我们先去开辟空间,放到临时变量 tmp 中,tmp 翻车就不会执行下面的代码,tmp 没有翻车,再去释放原有的空间,最后再把 tmp 的值交付给 s1,
这是非常保险的,有效避免了空间没开成还把 s1 空间释放掉的 "偷鸡不成蚀把米" 的事发生。
1.5 写时拷贝(了解)

写时拷贝技术实际上是运用了一个 “引用计数” 的概念来实现的。在开辟的空间中多维护四个字节来存储引用计数。
有两种方法:
①:多开辟四个字节(pCount)的空间,用来记录有多少个指针指向这片空间。
②:在开辟空间的头部预留四个字节的空间来记录有多少个指针指向这片空间。
当我们多开辟一份空间时,让引用计数+1,如果有释放空间,那就让计数-1,但是此时不是真正的释放,是假释放,等到引用计数变为 0 时,才会真正的释放空间。如果有修改或写的操作,那么也让原空间的引用计数-1,并且真正开辟新的空间。
写时拷贝涉及多线程等不好的问题,所以了解一ha就行
2. string 的部分函数实现
刚才我们为了方便讲解深浅拷贝的问题,有些地方所以没有写全。
我们知道string有这几个接口函数:
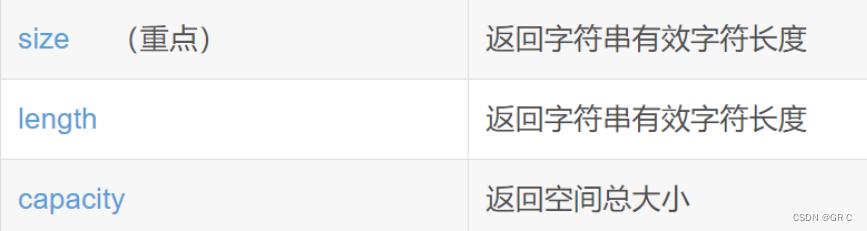
我们实现只是实现常用的,且length和size是一样的,我们现在增加一些成员:
private:char* _str;size_t _size;size_t _capacity; // 有效字符的空间数,不算\02.1 完整默认成员函数代码:
#pragma once#include<iostream>
#include<string>
#include<assert.h>
using namespace std;namespace rtx
{class string{public:string(const char* s){_size =strlen(s);// 因为要算多次strlen 效率低 且放在初始化列表关联到声明顺序 所以不用初始化列表_capacity = _size;_str = new char[_size + 1];// 开_size+1大小的空间(多开一个放\0)strcpy(_str, s);}string(const string& s):_str(new char[s._capacity + 1]), _size(s._size), _capacity(s._capacity){strcpy(_str, s._str);}string& operator=(const string& s){if (this != &s){char* tmp = new char[s._capacity + 1];// 开辟新的空间strcpy(tmp, s._str);// 赋值到tmpdelete[] _str;// 释放原有空间_str = tmp;// tmp赋值到想要的地方,出去tmp就销毁了_size = s.size();_capacity = s._capacity;}return *this;}~string() {delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity;};void test_string1(){string s1("hello world");string s2(s1);string s3("!!!");s1 = s3;}
}2.2 c_str() 的实现
c_str() 返回的是C语言字符串的指针常量,是可读不写的:
const char* c_str() const {return _str;}返回const char*,因为是可读不可写的,所以我们需要用 const 修饰。
c_str 返回的是当前字符串的首字符地址,这里我们直接 return _str 即可实现。
测试一下:
void test_string1(){string s1("hello world");string s2(s1);string s3("!!!");s1 = s3;cout << s1.c_str() << endl;cout << s2.c_str() << endl;cout << s3.c_str() << endl;}
2.3 全缺省构造函数的实现
还要考虑不带参的情况,比如下面的 s4:
void test_string1(){string s1("hello world");string s2(s1);string s3("!!!");s1 = s3;cout << s1.c_str() << endl;cout << s2.c_str() << endl;cout << s3.c_str() << endl;string s4;}无参构造函数:
string(): _str(new char[1]), _size(0), _capacity(0) {_str[0] = '\0';}一般的类都是提供全缺省的,值得注意的是,这里缺省值给的是 " "
有人看到指针 char* 可能给缺省值一个空指针 nullptr:
string(const char* str = nullptr)也就相当于直接对这个字符串进行解引用了,这里的字符串又是空,所以会引发空指针问题。
所以我们这里给的是一个空的字符串 " ",常量字符串默认就带有 \0,这样就不会出问题:
string(const char* s = ""){_size =strlen(s);// 因为要算多次strlen 效率低 且放在初始化列表关联到声明顺序 所以不用初始化列表_capacity = _size;_str = new char[_size + 1];// 开_size+1大小的空间(多开一个放\0)strcpy(_str, s);}这样达到的效果和无参构造函数是一样的,且无参编译器不知道调用哪个,
所以我们就需把无参构造函数删了。
2.4 size() 和 operator[] 的实现
size()的实现:
size_t size() const{return _size;}size() 只需要返回成员 _size 即可,考虑到不需要修改,我们加上 const。
operator[] 的实现:
char& operator[](size_t pos){assert(pos < _size);return _str[pos];}直接返回字符串对应下标位置的元素,
因为返回的是一个字符,所以我们这里引用返回 char。
我们来测试一下,遍历整个字符串,这样既可以测试到 size() 也可以测试到 operator[] :
void test_string2() {string s1("hello world");string s2;for (size_t i = 0; i < s1.size(); i++) {cout << s1[i] << " ";}cout << endl;s1[0] = 'x';for (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;}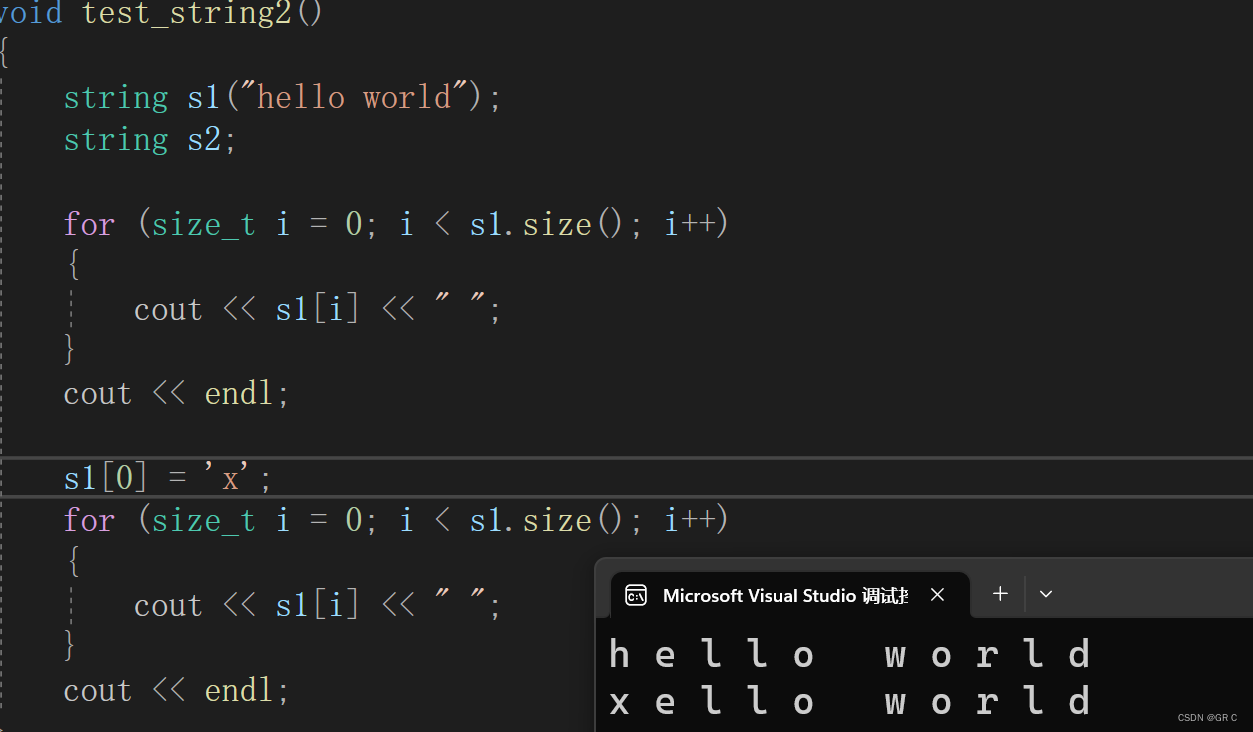
普通对象可以调用,但是 const 对象呢?所以我们还要考虑一下 const 对象。
我们写一个 const 对象的重载版本:
const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}因为返回的是 pos 位置字符的 const 引用,所以可读但不可写。
3. string的迭代器
在上上篇中,我们首次讲解迭代器,为了方便理解,我们当时解释其为像指针一样的类型。
实际上,有没有一种可能,它就是一种指针呢?
遗憾的是,迭代器并非指针,而是类模板。 只是它表现地像指针,模拟了指针的部分功能。
string迭代器的实现非常简单,它就是一个 char* 的指针罢了。
后面我们讲解 list 的时候它的迭代器又不是指针了,又是自定义类型了。
所以迭代器是一个像指针的东西,有可能是指针有可能不是指针。
3.1 string迭代器的实现
实现迭代器的 begin() 和 end() :
typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}
const 迭代器就是可以读但是不可以写的迭代器,实现一下 const 迭代器:
typedef const char* const_iterator;const_iterator begin() const {return _str;}const_iterator end() const{return _str + _size;}3.2 迭代器和范围for再思考
迭代器的底层是连续的物理空间,给原生指针++解引用能正好贴合迭代器的行为,能做到遍历。
但是对于链表和树型结构来说,迭代器的实现就没有这么简单了。
但是,强大的迭代器通过统一的封装,无论是树、链表还是数组……
它都能用统一的方式遍历,这就是迭代器的优势,也是它的强大之处。
我们上一章提到过范围for遍历string,我们能不能直接用在我们写的迭代器上:
void test_string3(){string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";// 读it++;}cout << endl;it = s1.begin();while (it != s1.end()){(*it)++;// 写,++的优先级比*高,+=就低,可以 *it += 1;cout << *it << " ";it++;}cout << endl;for (auto& e : s1){cout << e << " ";}cout << endl;}
我们也妹写范围 for 啊,怎么就能直接用了?
所以范围 for 根本就不需要自己实现,你只要把迭代器实现好,范围 for 直接就可以用。
范围 for 的本质是由迭代器支持的,编译时范围 for 会被替换成迭代器。
这么一看,又是自动加加,又是自动判断结束的范围 for,好像也没那么回事儿。
4. string的增删查改函数实现
4.1 reserve() 的实现
我们先实现一下 reserve 增容:
这里可以检查一下是否真的需要增容,万一接收的 new_capacity 比 _capacity 小,就不动。
void reserve(size_t new_capacity){if (new_capacity > _capacity){char* tmp = new char[new_capacity + 1];// 开新空间strcpy(tmp, _str);// 搬运delete[] _str; // 释放原空间_str = tmp;// 没问题,递交给_str_capacity = new_capacity;// 更新容量}}这里我们之前讲数据结构用的是 realloc,现在我们熟悉熟悉用 new,
还是用申请新空间、原空间数据拷贝到新空间,再释放空间地方式去扩容。
我们的 _capacity 存储的是有效字符,没算 \0,所以这里还要 +1 为 \0 开一个空间。
4.2 push_back() 的实现
void push_back(const char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = ch;// 在_size位置放字符后++_str[_size] = '\0';// 易漏}首先检查是否需要增容,如果需要就调用我们上面实现的 reserve 函数,
参数传递可以用三目操作符,防止容量是0的情况,0乘任何数都是0从而引发问题的情况。
测试一下效果如何:

4.3 append() 的实现
append 是追加字符串的,首先我们把要追加的字符串长度计算出来,
然后看容量够不够,不够我们就交给 reserve 去扩容,扩 _size + len,够用就行。
void append(const char* str){int len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);// 首字符+_size大小就是\0位置_size += len;}这里我们甚至都不需要用 strcat,因为它的位置我们很清楚,不就在 _str + _size 后面插入吗。
用 strcat 还需要遍历找到原来位置的 \0,麻烦且效率低,strcat 函数我们以后尽量都不用。
4.4 operator+= 的实现
这就是我们一章说的 "用起来爽到飞起" 的 += ,因为字符和字符串都可以用 += 去操作。
所以我们需要两个重载版本,一个是字符的,一个是字符串的。
我们不需要自己实现了,直接复用 push_back 和 append 就好了:
string& operator+=(const char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}测试:
void test_string4() {string s1("hello world");cout << s1.c_str() << endl;s1.push_back('!');cout << s1.c_str() << endl;s1.push_back('R');cout << s1.c_str() << endl;s1.append("abcd");cout << s1.c_str() << endl;s1 += 'e';s1 += "fgh";cout << s1.c_str() << endl;}
4.5 insert() 的实现
insert:字符
string& insert(size_t pos, const char ch){assert(pos < _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}for (size_t i = _size + 1;i > pos; --i)// 挪动数据,+1是挪动\0{_str[i] = _str[i - 1];}_str[pos] = ch;++_size;return *this;}insert:字符串
string& insert(size_t pos, const char* str){assert(pos <= _size);int len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}for (size_t i = _size + len ;i > pos + len - 1; --i)// 挪动数据,画图注意边界,参考上面inser字符的len == 1{_str[i] = _str[i - len];// 首先看\0 _size+len-len就是\0的位置}strncpy(_str + pos, str, len);_size += len;return *this;}测试:
void test_string4() {string s1("hello world");cout << s1.c_str() << endl;s1.push_back('!');cout << s1.c_str() << endl;s1.push_back('R');cout << s1.c_str() << endl;s1.append("abcd");cout << s1.c_str() << endl;s1 += 'e';s1 += "fgh";cout << s1.c_str() << endl;s1.insert(0, 'x');s1.insert(6, 'T');cout << s1.c_str() << endl;s1.insert(6, "PPPPPPPPPP");cout << s1.c_str() << endl;s1.insert(0, "PPPPPPPPPP");cout << s1.c_str() << endl;}
(测试后push_back 和 append 直接复用还能测试一波)
+=又是复用push_back 和 append 的,直接套娃开始:
void reserve(size_t new_capacity){if (new_capacity > _capacity){char* tmp = new char[new_capacity + 1];// 开新空间strcpy(tmp, _str);// 搬运delete[] _str; // 释放原空间_str = tmp;// 没问题,递交给_str_capacity = new_capacity;// 更新容量}}void push_back(const char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = ch;// 在_size位置放字符后++_str[_size] = '\0';// 易漏//insert(_size, ch);}
4.6 resize() 的实现
我们为了扩容,先实现了 reverse,现在我们再顺便实现一下 resize。
这里再提一下 reverse 和 resize 的区别:
resize 分给初始值和不给初始值的情况,所以有两种:

库里面也是这么实现的。
但是我们上面讲构造函数的时候说过,我们可以使用全缺省的方式,这样就可以二合一了。
resize 实现的难点是要考虑种种情况,我们来举个例子分析一下:
如果欲增容量比 _size 小的情况:
因为标准库是没有缩容的,所以我们实现的时候也不考虑去缩容。我们可以加一个 \0 去截断。
如果预增容量比 _size 大的情况:
resize 是开空间 + 初始化,开空间的工作我们就可以交给已经实现好的 reserve,
然后再写 resize 的初始化的功能,我们这里可以使用 memset 函数。
void resize(size_t new_capacity, const char ch = '\0'){if (new_capacity > _size)// 插入数据{reserve(new_capacity);//for (size_t i = _size; i < new_capacity; ++i)//{// _str[i] = ch;//}memset(_str + _size, ch, new_capacity - _size);// 上面的for循环即memset的功能_str[new_capacity] = '\0';_size = new_capacity;}else// 删除数据{_str[new_capacity] = '\0';_size = new_capacity;}}4.7 find() 的实现
find:查找字符
如果遍历完整个字符串都没找到,就返回 npos(找到库的来)。
这个 npos 我们可以在成员变量中定义:
size_t find(const char ch) const{for (size_t i = 0; i < _size; i++) {if (ch == _str[i])// 找到了{return i; // 返回下标}}return npos;// 找不到}private:char* _str;size_t _size;size_t _capacity;public:const static size_t npos = -1;// const static 语法特殊处理,直接可以当成定义初始化find:查找字符串
这里我们可以用 strstr 去找子串,如果找到了,返回的是子串首次出现的地址。
如果没找到,返回的是空。所以我们这里可以做判断,如果是 nullptr 就返回 npos。
如果找到了,就返回对应下标,子串地址 - 开头,就是下标了。
size_t find(const char* str, size_t pos = 0) const{const char* ptr = strstr(_str + pos, str);if (ptr == nullptr) {return npos;}else {return ptr - _str; // 减开头}}4.8 erase() 的实现
string& erase(size_t pos, size_t len = npos) {assert(pos < _size);if (len == npos || pos + len >= _size)// 如果pos后面的都删完了,注意len == npos 不能忽略,因为npos + len 有可能重回到 1{_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len;}return *this;}测试find 和 erase:

5. 传统写法和现代写法
对于拷贝构造的深拷贝,传统写法就是本本分分分地去完成深拷贝:
string(const string& s)/传统写法:_str(new char[s._capacity + 1]), _size(s._size), _capacity(s._capacity){strcpy(_str, s._str);}5.1 拷贝构造的现代写法
现在我们来介绍一种现代写法,它和传统写法本质工作是一样的,即完成深拷贝。
现代写法的方式不是本本分分地去按着 Step 一步步干活,而是 "投机取巧" 地去完成深拷贝。
void swap(string& s)// s和*this换{::swap(s._str, _str);//注意这里要加域作用符,默认是全局的,不然就是自己调自己了::swap(s._size, _size);::swap(s._capacity, _capacity);}string(const string& s)/现代写法:_str(nullptr), _size(0), _capacity(0){string tmp(s._str);swap(tmp);// tmp和*this换}现代写法的本质就是复用了构造函数。
我想拷贝,但我又不想自己干,我把活交给工具人 tmp 来帮我干。
值得注意的是如果不给原_str赋空指针,那么它的默认指向会是个随机值。和tmp交换后,tmp 是一个局部对象,我们把 s2 原来的指针和 tmp 交换了,那么 tmp 就成了个随机值了。tmp 出了作用域要调用析构函数,对随机值指向的空间进行释放,怎么释放?都不是你自己的 new / malloc 出来的,你还硬要对它释放,就可能会引发崩溃。但是 delete / free 一个空,是不会报错的,因为会进行一个检查。所以是可以 delete 一个空的,我们这里初始化列表中把 nullptr 给 _str,是为了交换完之后, nullptr 能交到 tmp 手中,这样 tmp 出了作用域调用析构函数就不会翻车了。
5.2 赋值重载的现代写法
赋值重载的传统写法:
string& operator=(const string& s)/传统写法{if (this != &s){char* tmp = new char[s._capacity + 1];// 开辟新的空间strcpy(tmp, s._str);// 赋值到tmpdelete[] _str;// 释放原有空间_str = tmp;// tmp赋值到想要的地方,出去tmp就销毁了_size = s._size;_capacity = s._capacity;}return *this;} 赋值重载的现代写法:
string& operator=(const string& s)/现代写法{if (this != &s){string tmp(s);swap(tmp);// tmp和*this换}return *this;}比上面的拷贝构造的现代写法还要压榨tmp,交换完之后,正好让 tmp 出作用域调用析构函数,属实是一石二鸟的美事。把 tmp 压榨的干干净净,还让 tmp 帮忙把屁股擦干净(释放空间)。
用上面的测试简单测一下:

总结:
现代写法在 string 中体现的优势还不够大,因为好像和传统写法差不多。
但是到后面实现 vector、list 的时候,会发现现代写法的优势真的是太大了。
现代写法写起来会更简单些,比如如果是个链表,传统写法就不是 strcpy 这么简单的了,
你还要一个一个结点拷贝过去,但是现代写法只需要调用 swap 交换一下就可以了。
现代写法更加简洁,只是在 string 这里优势体现的不明显罢了,我们后面可以慢慢体会。
6. operator 运算符重载
6.1 六个比较运算符重载
学日期类的时候就说过,只需实现 > 和 ==,剩下的都可以复用解决:
而且> 和 ==可以直接用strcmp ,剩下的复用,你不想用strcmp时剩下的也不用改了:
bool operator>(const string& s) const{return strcmp(_str, s._str) > 0;}bool operator==(const string& s) const{return strcmp(_str, s._str) == 0;} bool operator>=(const string& s) const// 养成this指针写在前面的习惯{return *this > s || *this == s;}bool operator<(const string& s) const{return !(*this >= s);} bool operator<=(const string& s) const{return !(*this > s);} bool operator!=(const string& s) const{return !(*this == s);}6.2 流插入和流提取重载
我们当时实现日期类的流插入和流提取时,也详细讲过这些,当时讲解了友元。
在友元那一章我们说过 "占参问题" ,这里就不再多做解释了。
如果我们重载成成员函数,第一个位置就会被隐含的 this 指针占据。
这样实现出来的流插入必然会不符合我们的使用习惯,所以我们选择在全局实现。
在全局里不存在隐含的 this 指针了。
而且我们已经有operator [ ] 可以访问私有成员了,所以不需要设置成友元函数:
流插入很简单:
ostream& operator<<(ostream& out, string& s){for (size_t i = 0;i < s.size();++i){out << s[i];}return out;}但是流提取是这么简单吗?下面的代码有什么问题?:
istream& operator>>(istream& in, string& s){char ch;in >> ch;while (ch != ' ' && ch != '\n'){s += ch;in >> ch;}return in;}我们发现这样输入空格和换行也终止不了程序,因为cin会自动忽略空格和换行。
有什么办法?cin有一个get的成员函数,可以获取每一个字符,现在我们查下文档会用就行,
后面我们还会详细的讲解IO流,流提取普通实现:
istream& operator>>(istream& in, string& s){char ch;ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}return in;}这样实现的流提取有一个缺陷:频繁的 += 效率低,能想到什么办法优化?
以下是类似库里面的实现:(思路类似缓冲区)
istream& operator>>(istream& in, string& s)// 流插入优化(类似库里面的){char ch;ch = in.get();const size_t N = 32;char buff[N];// C++11支持的变长数组size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == N - 1)// 如果buff的容量满了{buff[i] = '\0';// 在后面放\0,s += buff;// += 到 s 上i = 0;// 把 i 重新变成0 用来再次使用buff数组}ch = in.get();}buff[i] = '\0';// 处理一下buff剩余的s += buff;return in;}简单测试下:
void test_string6(){string s1;string s2;cin >> s1 >> s2;cout << s1 << endl << s2 << endl;cout << (s1 > s2) << endl;cout << (s1 == s2) << endl;cout << (s1 >= s2) << endl;cout << (s1 < s2) << endl;cout << (s1 <= s2) << endl;cout << (s1 != s2) << endl;}
7. 完整代码:
string.h:
#pragma once#include<iostream>
#include<string>
#include<assert.h>
using namespace std;namespace rtx
{class string{public:string(const char* s = ""){_size =strlen(s);// 因为要算多次strlen 效率低 且放在初始化列表关联到声明顺序 所以不用初始化列表_capacity = _size;_str = new char[_size + 1];// 开_size+1大小的空间(多开一个放\0)strcpy(_str, s);}//string(const string& s)/传统写法// :_str(new char[s._capacity + 1])// , _size(s._size)// , _capacity(s._capacity)//{// strcpy(_str, s._str);//}void swap(string& s)// s和*this换{::swap(s._str, _str);//注意这里要加域作用符,默认是全局的,不然就是自己调自己了::swap(s._size, _size);::swap(s._capacity, _capacity);}string(const string& s)/现代写法:_str(nullptr), _size(0), _capacity(0){string tmp(s._str);swap(tmp);// tmp和*this换}//string& operator=(const string& s)/传统写法//{// if (this != &s)// {// char* tmp = new char[s._capacity + 1];// 开辟新的空间// strcpy(tmp, s._str);// 赋值到tmp// delete[] _str;// 释放原有空间// _str = tmp;// tmp赋值到想要的地方,出去tmp就销毁了// _size = s._size;// _capacity = s._capacity;// }// return *this;//} string& operator=(const string& s)/现代写法{if (this != &s){string tmp(s);swap(tmp);// tmp和*this换}return *this;}~string() {delete[] _str;_str = nullptr;}const char* c_str() const {return _str;}size_t size() const{return _size;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}typedef const char* const_iterator;const_iterator begin() const {return _str;}const_iterator end() const{return _str + _size;}void reserve(size_t new_capacity){if (new_capacity > _capacity){char* tmp = new char[new_capacity + 1];// 开新空间strcpy(tmp, _str);// 搬运delete[] _str; // 释放原空间_str = tmp;// 没问题,递交给_str_capacity = new_capacity;// 更新容量}}void push_back(const char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = ch;// 在_size位置放字符后++_str[_size] = '\0';// 易漏//insert(_size, ch);}void append(const char* str){int len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);// 首字符+_size大小就是\0位置_size += len;//insert(_size, str);}string& operator+=(const char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}string& insert(size_t pos, const char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}for (size_t i = _size + 1;i > pos; --i)// 挪动数据,+1是挪动\0{_str[i] = _str[i - 1];}_str[pos] = ch;++_size;return *this;}string& insert(size_t pos, const char* str){assert(pos <= _size);int len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}for (size_t i = _size + len ;i > pos + len - 1; --i)// 挪动数据,画图注意边界,参考上面inser字符的len == 1{_str[i] = _str[i - len];// 首先看\0 _size+len-len就是\0的位置}strncpy(_str + pos, str, len);_size += len;return *this;}void resize(size_t new_capacity, const char ch = '\0'){if (new_capacity > _size)// 插入数据{reserve(new_capacity);//for (size_t i = _size; i < new_capacity; ++i)//{// _str[i] = ch;//}memset(_str + _size, ch, new_capacity - _size);// 上面的for循环即memset的功能_str[new_capacity] = '\0';_size = new_capacity;}else// 删除数据{_str[new_capacity] = '\0';_size = new_capacity;}}size_t find(char ch) const{for (size_t i = 0; i < _size; i++) {if (ch == _str[i])// 找到了{return i; // 返回下标}}return npos;// 找不到}size_t find(const char* str, size_t pos = 0) const{const char* ptr = strstr(_str + pos, str);if (ptr == nullptr) {return npos;}else {return ptr - _str; // 减开头}}string& erase(size_t pos, size_t len = npos) {assert(pos < _size);if (len == npos || pos + len >= _size)// 如果pos后面的都删完了,注意len == npos 不能忽略,因为npos + len 有可能重回到 1{_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len;}return *this;}bool operator>(const string& s) const{return strcmp(_str, s._str) > 0;}bool operator==(const string& s) const{return strcmp(_str, s._str) == 0;} bool operator>=(const string& s) const// 养成this指针写在前面的习惯{return *this > s || *this == s;}bool operator<(const string& s) const{return !(*this >= s);} bool operator<=(const string& s) const{return !(*this > s);} bool operator!=(const string& s) const{return !(*this == s);}private:char* _str;size_t _size;size_t _capacity;public:const static size_t npos = -1;// const static 语法特殊处理,直接可以当成定义初始化};ostream& operator<<(ostream& out, string& s){for (size_t i = 0;i < s.size();++i){out << s[i];}return out;}//istream& operator>>(istream& in, string& s)// 流插入普通实现//{// char ch;// ch = in.get();// while (ch != ' ' && ch != '\n')// {// s += ch;// ch = in.get();// }// return in;//}istream& operator>>(istream& in, string& s)// 流插入优化(类似库里面的){char ch;ch = in.get();const size_t N = 32;char buff[N];// C++11支持的变长数组size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == N - 1)// 如果buff的容量满了{buff[i] = '\0';// 在后面放\0,s += buff;// += 到 s 上i = 0;// 把 i 重新变成0 用来再次使用buff数组}ch = in.get();}buff[i] = '\0';// 处理一下buff剩余的s += buff;return in;}void test_string1(){string s1("hello world");string s2(s1);string s3("!!!");s1 = s3;cout << s1.c_str() << endl;cout << s2.c_str() << endl;cout << s3.c_str() << endl;string s4;cout << s4.c_str() << endl;}void test_string2() {string s1("hello world");string s2;for (size_t i = 0; i < s1.size(); i++) {cout << s1[i] << " ";}cout << endl;s1[0] = 'x';for (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;}void test_string3(){string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";// 读it++;}cout << endl;it = s1.begin();while (it != s1.end()){(*it)++;// 写,++的优先级比*高,+=就低,可以 *it += 1;cout << *it << " ";it++;}cout << endl;for (auto& e : s1){cout << e << " ";}cout << endl;}void test_string4() {string s1("hello world");cout << s1.c_str() << endl;s1.push_back('!');cout << s1.c_str() << endl;s1.push_back('R');cout << s1.c_str() << endl;s1.append("abcd");cout << s1.c_str() << endl;s1 += 'e';s1 += "fgh";cout << s1.c_str() << endl;s1.insert(0, 'x');s1.insert(6, 'T');cout << s1.c_str() << endl;s1.insert(6, "PPPPPPPPPP");cout << s1.c_str() << endl;s1.insert(0, "PPPPPPPPPP");cout << s1.c_str() << endl;s1.resize(100,'x');cout << s1.c_str() << endl;}void test_string5(){string s1("hello world");string s2(s1);string s3 = s1;cout << s2.c_str() << endl << s3.c_str() << endl;cout << s1.find('d') << endl;// 打印d的下标:6cout << s1.find("world") << endl;// 打印了w的下标:10cout << s1.find("wold") << endl;// 打印了npos:4294967295cout << s1.find("world", 9) << endl;// 打印了npos:4294967295s1.erase(9, 2);// 从下标9开始删除2个字符cout << s1.c_str() << endl;s1.erase(s1.find('o'), 2);// 找到o,其下标为4,从下标4开始删除2个字符cout << s1.c_str() << endl;s1.erase(5);// 从下标5开始删完cout << s1.c_str() << endl;}void test_string6(){string s1;string s2;cin >> s1 >> s2;cout << s1 << endl << s2 << endl;cout << (s1 > s2) << endl;cout << (s1 == s2) << endl;cout << (s1 >= s2) << endl;cout << (s1 < s2) << endl;cout << (s1 <= s2) << endl;cout << (s1 != s2) << endl;}
}Test.c:
#define _CRT_SECURE_NO_WARNINGS 1#include "string.h"int main()
{try{rtx::test_string6();}catch (const exception& e){cout << e.what() << endl;}return 0;
}本章完。
这篇博客两万多个字了......刚开始接触确实有点累der
不过STL的实现都是类似的,以后的学习就轻松多了,
下一步:了解vector的接口函数,写写vector的OJ题,模拟实现vector。
想笑~ 来伪装掉下的眼泪~

23年5月27,早起把博客发出去,我又行了。
相关文章:
从C语言到C++_13(string的模拟实现)深浅拷贝+传统/现代写法
前面已经对 string 类进行了简单的介绍和应用,大家只要能够正常使用即可。 在面试中,面试官总喜欢让学生自己 来模拟实现string类, 最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。 为了更深入学习STL,下面我…...
方法详解)
reduce()方法详解
一、 定义和用法 reduce() 方法将数组缩减为单个值。 reduce() 方法为数组的每个值(从左到右)执行提供的函数。 函数的返回值存储在累加器中(结果/总计)。 注释:对没有值的数组元素,不执行 reduce() 方法。…...

C++虚假唤醒
概念: 虚假唤醒是指在使用条件变量时,线程被唤醒但条件并没有满足,导致线程执行错误的情况,这个过程就是虚假唤醒。 虚假唤醒弊端: 虚假唤醒会导致程序的正确性受到影响,因为唤醒的线程并没有满足条件&…...

【AI】dragonGPT - 单机部署、极速便捷
dragonGPT 从数据私有化,到prompt向量库匹配,再到查询,一条龙服务,单机部署,极简操作 pre a.需要下载gpt4all model到本地. ggml Model Download Link 然后将存放model的地址写入.env MODEL_PATH your pathb.…...

Uuiapp使用生命周期,路由跳转传参
Uniapp生命周期: 1. beforeCreate:在实例初始化之后,数据观测和事件配置之前被调用。 2. created:在实例创建完成后被立即调用。 3. beforeMount:在挂载开始之前被调用:相关的 render 函数首次被调用。 …...
习题)
定积分的计算(牛顿-莱布尼茨公式)习题
前置知识:定积分的计算(牛顿-莱布尼茨公式) 习题1 计算 ∫ 0 2 ( x 2 − 2 x 3 ) d x \int_0^2(x^2-2x3)dx ∫02(x2−2x3)dx 解: \qquad 原式 ( 1 3 x 3 − x 2 3 x ) ∣ 0 2 ( 8 3 − 4 6 ) − 0 14 3 (\dfrac 13x^3-…...

leak 记录今天的一个小题
先看题, add没有大小限制,这里edit可以溢出8字节,也就是可以改后边的size,可以调用4次free没有调用函数只是把指针置0,show可以用一次. void __fastcall __noreturn main(__int64 a1, char **a2, char **a3) {init_0(a1, a2, a3);while ( 1 ){menu();switch ( read_n() ){cas…...

软考A计划-试题模拟含答案解析-卷二
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&am…...

【C++】pthread
一、pthread简介 pthread是C98接口且只支持Linux,使用时需要包含头文件#include <pthread.h>,编译时需要链接pthread库,其中p是POSIX的缩写,而POSIX是Portable Operating System Interface的缩写,是IEEE为要在各…...
2023年前端面试题汇总-浏览器原理
1. 浏览器安全 1.1. 什么是 XSS 攻击? 1.1. 1. 概念 XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 cookie 等。 XSS 的本质是因为网站没有对…...

react介绍,react语法,react高级特性,react编程技巧
React是一个用于构建用户界面的JavaScript库。它由Facebook开发,于2013年首次发布。React的主要目标是提高应用程序的性能和可维护性。React采用了一种称为“组件”的模式,使开发人员可以将应用程序拆分为小而独立的部分,从而更容易编写和维护…...
Locust接口性能测试
谈到性能测试工具,我们首先想到的是LoadRunner或JMeter。LoadRunner是非常有名的商业性能测试工具,功能非常强大。但现在一般不推荐使用该工具来进行性能测试,主要是使用也较为复杂,而且该工具体积比较大,需要付费且价…...
)
Python类的特殊方法(通过故事来学习)
在一座森林里,住着三只动物:狼、兔和熊。这三只动物都有不同的特点和能力,但是它们所有的行为都可以被抽象成一个“动物”类。现在,让我们来看看Python中的类和特殊方法如何帮助我们实现这个故事。 首先,我们可以定义…...

Vue.js 中的父子组件通信方式
Vue.js 中的父子组件通信方式 在 Vue.js 中,组件是构建应用程序的基本单元。当我们在应用程序中使用组件时,组件之间的通信是非常重要的。在 Vue.js 中,父子组件通信是最常见的组件通信方式之一。在本文中,我们将讨论 Vue.js 中的…...
Python之并发编程二多进程理论
一、什么是进程 进程:正在进行的一个过程或者说一个任务。而负责执行任务则是cpu。 二、进程与程序的区别 程序仅仅只是一堆代码而已,而进程指的是程序的运行过程。 三、并发与并行 无论是并行还是并发,在用户看来都是’同时’运行的&am…...
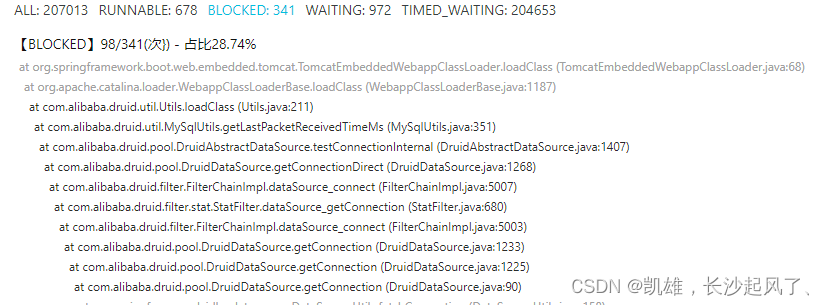
纯干货:数据库连接耗时慢原因排查
背景 最近公司的社区相关的服务需要优化,由于对业务不熟悉,只能借助监控从一些慢接口开始尝试探索慢的原因。由于社区相关的功能务是公司小程序流量入口,所以相应的服务访问量还是比较高的。针对这类高访问的项目,任何不留神的地…...
【OneNet】| stm32+esp8266-01s—— OneNet初体验 | 平台注册及设备创建 | demo使用
系列文章目录 失败了也挺可爱,成功了就超帅。 文章目录 前言1. OneNet平台注册2. 创建多协议接入设备3. 硬件连接4. 下载并运行Demo4.1 Demo下载4.2 运行Demo本小节结束 前言 最近准备耍下 Onenet平台 。下载了官方demo 遇到几个问题 1、创建接入设备 因为平台网页…...
解决win无法删除多层嵌套文件夹
起因:昨天研究jpackage工具,不小心搞得一个文件夹里嵌套了好几百个文件夹,用win自己的删除删不掉,shiftdel直接删除也不行,直接弹窗删除错误; 后来用电脑管家下载了个“文件粉碎”,添加目录&am…...

用Vue简单开发一个学习界面
文章目录 一.首先创建我们的Vue文件夹二.源代码BodyDemoHearderDemoHomeDemoMarkdownDemoFileManager.jsMain.js(注意绑定)APP源代码 效果图(按钮功能)新增二级菜单(v-for)需要的可以私信 一.首先创建我们的…...

Oracle数据库从入门到精通系列之五:数据文件
Oracle数据库从入门到精通系列之五:数据文件 一、数据文件二、Oracle数据库存储分配单位三、Oracle数据库文件系统机制四、段五、区段六、块七、表空间八、Oracle数据库存储层次体系小结一、数据文件 数据文件和重做文件是数据库中最重要的文件,数据最终会存储在这些文件中。…...

Flut Renamer:免费跨平台批量文件重命名工具的完整使用指南
Flut Renamer:免费跨平台批量文件重命名工具的完整使用指南 【免费下载链接】renamer Flut Renamer - A bulk file renamer written in flutter (dart). Available on Linux, Windows, Android, iOS and macOS. 项目地址: https://gitcode.com/gh_mirrors/ren/ren…...

Play Integrity API Checker:构建企业级Android安全防御体系的技术架构与商业价值
Play Integrity API Checker:构建企业级Android安全防御体系的技术架构与商业价值 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integ…...

终极解决方案:3步恢复Calibre-Web豆瓣元数据获取功能
终极解决方案:3步恢复Calibre-Web豆瓣元数据获取功能 【免费下载链接】calibre-web-douban-api 新版calibre-web已经移除douban-api了,添加一个豆瓣api实现 项目地址: https://gitcode.com/gh_mirrors/ca/calibre-web-douban-api 还在为Calibre-W…...

如何快速解决Windows软件兼容性问题:VisualCppRedist AIO终极指南
如何快速解决Windows软件兼容性问题:VisualCppRedist AIO终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在运行某些软件或游戏时…...

终极Win11系统优化指南:Win11Debloat深度清理教程
终极Win11系统优化指南:Win11Debloat深度清理教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

NLP文本预处理全流程实战:从数据清洗到向量化的工程实践指南
1. 项目概述:从文本到智能的桥梁在人工智能的众多分支中,自然语言处理(NLP)一直是最具挑战性也最引人入胜的领域之一。它的核心目标直白而宏大:让机器能像人一样理解、运用和生成语言。这听起来像是科幻小说的情节&…...

终极免费方案:5分钟解锁Windows多用户远程桌面完整指南
终极免费方案:5分钟解锁Windows多用户远程桌面完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版限制远程桌面连接而烦恼吗?RDP Wrapper Library为您提供完美的解…...

终极模组管理指南:XXMI启动器让你的米哈游游戏体验提升10倍
终极模组管理指南:XXMI启动器让你的米哈游游戏体验提升10倍 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款专为米哈游系列游戏设计的开源模组管理平…...

JMeter并发与持续性压测:从按钮操作到系统心跳诊断
1. 这不是“点几下就出报告”的玩具,而是压测工程师的听诊器很多人第一次打开 JMeter,以为它就是个高级版的 Postman:填个 URL、点个“启动”,等几秒弹出个 Summary Report,看到平均响应时间 86ms 就松一口气ÿ…...

信用评分中的算法公平性:从理论到实践的全面解析
1. 项目概述:当信用评分遇上算法公平性在金融科技领域,信用评分模型早已不是新鲜事物。从传统的逻辑回归到如今复杂的梯度提升树和神经网络,机器学习模型凭借其强大的预测能力,已经成为银行和金融机构进行信贷决策、管理风险的核心…...