hive任务reduce步骤卡在99%原因及解决
我们在写sql的时候经常发现读取数据不多,但是代码运行时间异常长的情况,这通常是发生了数据倾斜现象。数据倾斜现象本质上是因为数据中的key分布不均匀,大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,从而拉慢了整个计算过程速度。
本文将介绍如何通过日志分析,判断数据中的哪个key分布不均,从而导致了数据倾斜问题。
任务是否发生了倾斜
hive判断

hive运行日志
当我们在hive作业运行日志中,发现reduce任务长时间卡在99%时,即可判断任务发生了数据倾斜。
其原理是这样的:

分布式处理逻辑
分布式处理实际上是按数据中的key将数据分摊到多个机器上运行,假如出现了数据倾斜问题,如上图。可以想象,当1min过去后,我们的任务完成率只有67%,并且在接下来的9min时间内,任务完成率将持续卡在67%上。因此,当我们发现任务完成率长时间卡在99%时,即判断发生了数据倾斜。
spark判断

spark UI界面
我们进入spark UI界面,发现第2个job的运行时间长达1.8h,而其他job运行时间不超过2min,判断该job有可能发生数据倾斜。

进一步分析job,可以看到该job只存在一个stage(9)

stage界面
进一步分析stage,发现不管是duration还是shuffle的数据量,max和median都有明显的差距,可以肯定是job(5)的stage(9)发生倾斜。
hive输出也可以帮助排查
hive数据倾斜表象:Table 0 has 10000 rows for join key [0,0]
有hive任务发生数据倾斜,reduce端一直99%,有一个reduce任务卡主了。
打开这个reduce任务的log日志,发现如下日志:
[INFO] org.apache.hadoop.hive.ql.exec.JoinOperator: Table 0 has 10000 rows for join key [0,0]
打开hive源码定为输入日志行:
if (sz == nextSz) {LOG.info("Table {} has {} rows for join key {}", alias, sz, keyObject);nextSz = getNextSize(nextSz);
}
输出的类是org.apache.hadoop.hive.ql.exec.JoinOperator,是hive中join运算符的实现类,具体运行机制尚不清楚。
查询资料得知,当一个key关联了超过1000行时,会输出一条该警告日志,此后每1000会输出一条。所以这条日志的目的在于警告可能存在的Join数据倾斜的风险。
寻找倾斜key
当我们发现任务倾斜了,自然而然就希望找到倾斜的key,从而修复数据倾斜的现象。当然,这部分我也会分为hive和spark两个部分进行介绍。
hive识别
step1:确认是哪个Job出现了严重的倾斜问题

hive运行日志
通过搜索tracking的方式,我们发现第3个job的reduce任务一直卡在99%上,判断其发生了倾斜问题。
step2:进入相应的Tracking URL,查看SUCCESSFUL REDUCE

很明显,其他的taske都在2min之内完成,只有000000_1需要耗费1个多小时的时间完成。
另外注意,这里面需要排除一种特殊情况。有时候,某个task执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于task执行节点问题导致的个别task慢。如果推测执行后的task执行任务也特别慢,那更能说明该task可能会有倾斜问题。
step3:进入log日志,查看syslog

hive的syslog日志
可以从log日志中看到,该job仅仅运行了file和group操作后,就将数据写入至hive表中。那么,我们可以确认的是,该job运行的是最后一个group by操作。
step4:对照运行sql

运行sql
我们可以看到,在group by阶段,count(distinct)的出现造成了数据倾斜。
spark识别
step1:找到该任务运行的stage

spark UI界面
我们看到该运行任务,可以发现第2个job运行时间长达1.8h,远大于其他job,可以判定倾斜发生在job(5)。
step2:点击SQL,查看Details for Query

Details for Query
可以从sort time total/peak memory total/spill size total看出来,左表的package_name分布不均匀,此时可以通过查看scan parquet了解具体是哪张表。
step3:对照运行sql

运行sql代码
查询package_name的分布情况
select package_name,count(1) as cnt from test1 where date=20220619 group by package_name order by cnt desc limit 10;
package_name的分布验证了我们的猜想,test1.package_name造成了数据倾斜
过滤掉倾斜数据
当少量key重复次数特别多,如果这种key不是业务需要的key,可以直接过滤掉。
比如一张埋点日志表ods.page_event_log,
需要和订单表dw.order_info_fact做join关联。
在执行Hive的过程中发现任务卡在map 100%、reduce 99%,最后的1%一直运行不完。考虑应该是在join的过程中出现了数据倾斜,下面进行排查。
对于ods.page_event_log表查看出现次数最多的key:
select cookieid,count(*) as numfrom ods.page_event_logwhere data_date = "20190101"
group by cookieid
distribute by cookieid
sort by num desc limit 10
同样的,对另一张join表也做对应的排查
select cookieid,count(*) as num
from dw.order_info_fact
group by cookieid
distribute by cookieid
sort by num desc limit 10
从sql统计的结果可以看出,日志表和订单表通过cookieid进行join,当cookieid为0的时候,join操作将会产生142286×142286条数据,数量如此庞大的节点系统无法处理过来。同样当cookieid为NULL值和空值时也会出现这种情况,而且cookieid为这3个值时并没有实际的业务意义。因此在对两个表做关联时,排除掉这3个值以后,就可以很快计算出结果了,所以做好前期的数据清洗对一个大数据平台是至关重要的,生产无小事。
引入随机数
当我们用sql对数据group by时,MR会将相同的key拉取到同一个节点上进行聚合,如果某组的数据量很大时,会出现当前节点任务负载过重,从而导致数据倾斜。这时候可以考虑引入随机数,将原来的一个key值拆分成多组进行聚合。
比如现在需要统计用户的订单量,sql如下:
select t1.user_id,t2.order_numfrom (select user_idfrom dim.user_info_fact # 用户维度表where data_date = "20190101" and user_status_id=1) t1 join ( select user_id,count(*) as order_num from dw.dw_order_fact # 订单表where site_id in (600, 900)and order_status_id in(1,2,3)group by user_id) t2 on t1.user_id = t2.user_id其中,用户维度表有2000w条数据,订单表有10亿条数据,任务在未优化前跑了一小时还没跑完,怀疑出现了数据倾斜。这里可以把key值加上一定的前缀转换成多个key,这样原本一个task上处理的key就会分发到其他多个task,然后去掉前缀再进行一次聚合得到最终结果。
优化后的sql如下: 这里把原来可能1个task执行的任务并行成了1000个随机数task做聚合,再把聚合的结果通过user_id做sum,在集群的整体性能不受影响的情况下,可以有效提高整体的计算速度。
select t1.user_id,t2.order_numfrom (select user_idfrom dim_user_info_factwhere data_date = "20190101" ) t1 join ( select t.user_id,sum(t.order_num) as order_numfrom (select user_id,round(rand()*1000) as rnd,count(1) as order_num from dw.order_info_factwhere pay_status in (1,3)group by user_id,round(rand()*1000)) t group by t.user_id) t2 on t1.user_id = t2.user_id还有一种可能
可能仅仅是因为你给的资源太少了 ,适当增加map和reduce的内存和个数,以及小文件合并之类的
相关文章:
hive任务reduce步骤卡在99%原因及解决
我们在写sql的时候经常发现读取数据不多,但是代码运行时间异常长的情况,这通常是发生了数据倾斜现象。数据倾斜现象本质上是因为数据中的key分布不均匀,大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均…...

C++11 -- lambda表达式
文章目录 lamaba表达式的引入lambda表达式语法lamabda达式各部分说明捕获列表说明 lamaba表达式底层原理探索 lamaba表达式的引入 在C11之前,如果我们想对自定义类型Goods排序,可以根据姓名,价格,学号按照从大到小或者从小到大的方式排序,可是,这样我们要写额外写6个相关的仿函…...
【开源项目】银行查询服务的设计和实现
银行查询服务的设计和实现 项目地址github:https://github.com/xl-echo/bankInquiryService项目地址gitee:https://gitee.com/xl-echo/bank-inquiry-service 银行查询服务的设计初衷是:为提供更加便利的查询服务,我们在分布式系…...

Linux服务器禁止密码登录,设置秘钥登录
生成SSH密钥 (客户机端) 执行ssh-keygen -t rsa命令创建RSA密钥对,执行结果如下(键入3次回车): [rootnode01 .ssh]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): [回车] En…...

第十八章 开发Productions - ObjectScript Productions - 通过引用或作为输出传递值
文章目录 第十八章 开发Productions - ObjectScript Productions - 通过引用或作为输出传递值典型的回调方法典型的辅助方法 第十八章 开发Productions - ObjectScript Productions - 通过引用或作为输出传递值典型的回调方法典型的辅助方法 第十八章 开发Productions - Object…...

【云原生|Kubernetes】07-Pod健康检查和服务可用性检查
【云原生|Kubernetes】07-Pod健康检查和服务可用性检查 文章目录 【云原生|Kubernetes】07-Pod健康检查和服务可用性检查前言Pod探针Liveness(Pod存活探针)Readiness(Pod服务就绪探针)Startup(启动探针) 定义Liveness存活探针EXec探针HTTP探针TCP探针gRPC探针使用命名端口 定义…...

jeecgboot使用的问题记录
最近使用jeecgboot些项目,总结使用过程中的问题。 form表单 1.下拉框 — 使用字典方式 {label: 工单状态,field: orderStatus,component: JDictSelectTag,componentProps: {dictCode: emergency_order_status,}, } 2.下拉框—使用接口获取数据方式 配置项 { l…...

【C++】数组 - 一维数组,二维数组
文章目录 1. 一维数组1.1 一维数组定义方式1.2 数组名1.3 冒泡排序 2. 二维数组2.1 二维数组定义方式2.2 数组名 所谓数组,就是一个集合,里边存放了相同类型的数据元素。 特点1:数组中的每个数据元素都是相同的数据类型 特点2:数…...

前端:使用rollup的简单记录
目录 rollup安装 简单使用 1、命令行打包 2、配置文件打包 问题 1、报错提示:(node:23744) Warning: To load an ES module, set "type": "module" in the package.json or use the .mjs extension.(Use node --trace-warnings ... to sho…...
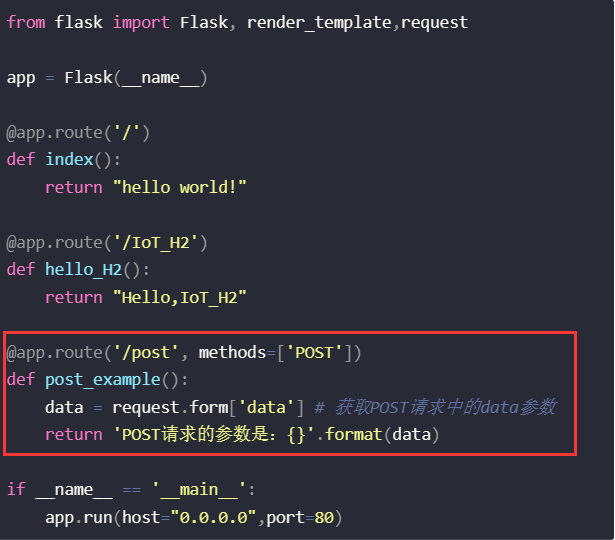
基于flask的web应用开发——接受post请求
目录 0. 前言1. 了解post方法2. 在flask中实现3. 具体讲解 0. 前言 操作系统:Windows10 家庭版 开发环境:Pycahrm Comunity 2022.3 Python解释器版本:Python3.8 第三方库:flask 1. 了解post方法 POST是HTTP协议定义的一种请…...
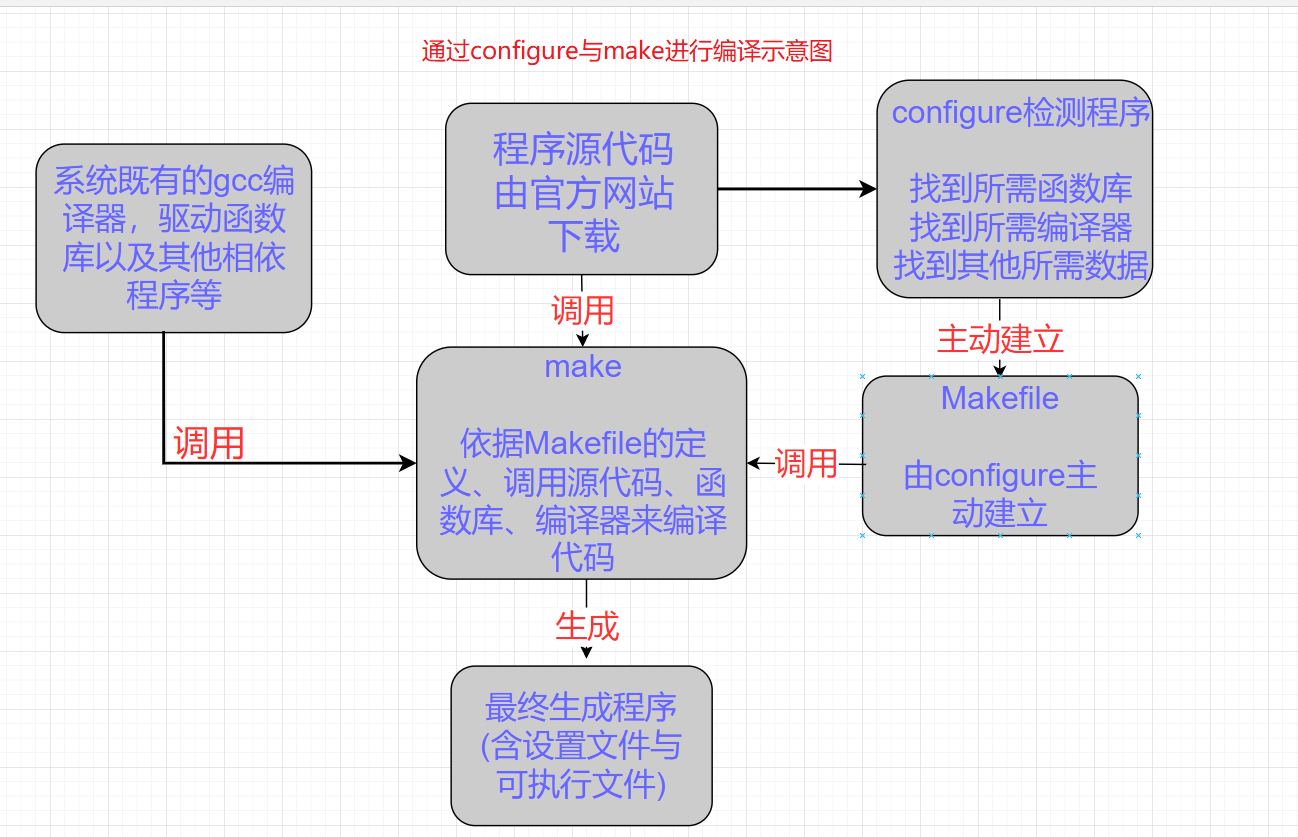
Linux源码包的安装与升级
文章目录 Linux源码包的安装与升级什么是源代码、编译器与可执行文件什么是函数库什么是make与configure什么是Tarball的软件如何安装与升级软件 Linux源码包的安装与升级 如果你想在自己的Linux服务器上运行网站,就需要安装一个Web服务器软件,否则无法…...
电子合同签署协议开源版系统开发
电子合同签署协议开源版系统开发 H5TP6mysqlphp 源码开源不加密 以下是电子合同系统可能包含的功能列表: 用户注册和登录:用户可以注册并登录系统,以便创建、签署和管理合同。合同创建:用户可以创建新合同,包括填写合…...

【每日一题Day221】LC2455可被三整除的偶数的平均值 | 模拟
可被三整除的偶数的平均值【LC2455】 给你一个由正整数组成的整数数组 nums ,返回其中可被 3 整除的所有偶数的平均值。 注意:n 个元素的平均值等于 n 个元素 求和 再除以 n ,结果 向下取整 到最接近的整数。 思路 遍历数组,如果某…...
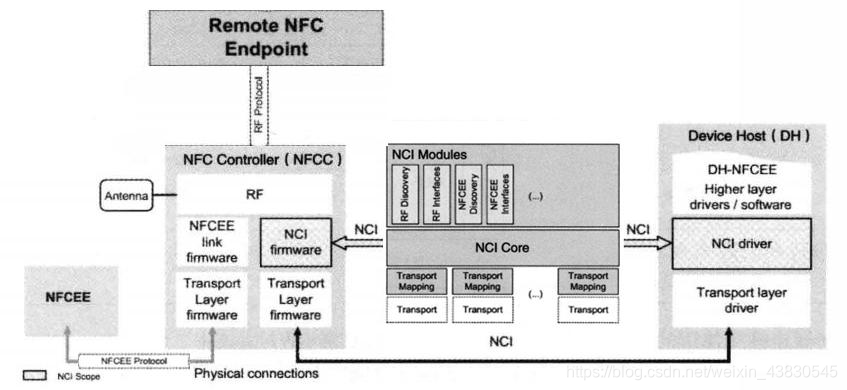
NCI架构-1
1、NFCC和DH通过物理连线相连,物理连线对应为Transport Layer(传输层),支持SPI、I2C、UART、USB等; 2、DH中所有和NFC相关的应用程序都可视为DH-NFCEE(EE:Execution Enviroment),图左的NFCEE模块可运行一些…...

lambda使用场景
字符串转换为数组: [rootmaster pyflink]# cat t300.py f(lambda i: (i, 1)) x11 22 33 print(f(x)) [rootmaster pyflink]# python t300.py (11 22 33, 1) [rootmaster pyflink]# cat t301.py f(lambda i: i[0]) x(aa,11, 22, 33) print(f(x)) [rootmaster pyflink]# pyth…...

Python模拟Postgres数据库连接
psycopg2 psycopg2是一个Python库,用于在Python应用程序中连接和操作PostgreSQL数据库。它是PostgreSQL数据库的官方驱动程序之一,具有广泛的应用和支持。 以下是一些psycopg2的特点和功能: 连接到PostgreSQL数据库:psycopg2提供…...
(转载)基于粒子群算法的多目标搜索算法(matlab实现)
1 理论基础 在实际工程优化问题中,多数问题是多目标优化问题。相对于单目标优化问题,多目标优化问题的显著特点是优化各个目标使其同时达到综合的最优值。然而,由于多目标优化问题的各个目标之间往往是相互冲突的,在满足其中一个…...
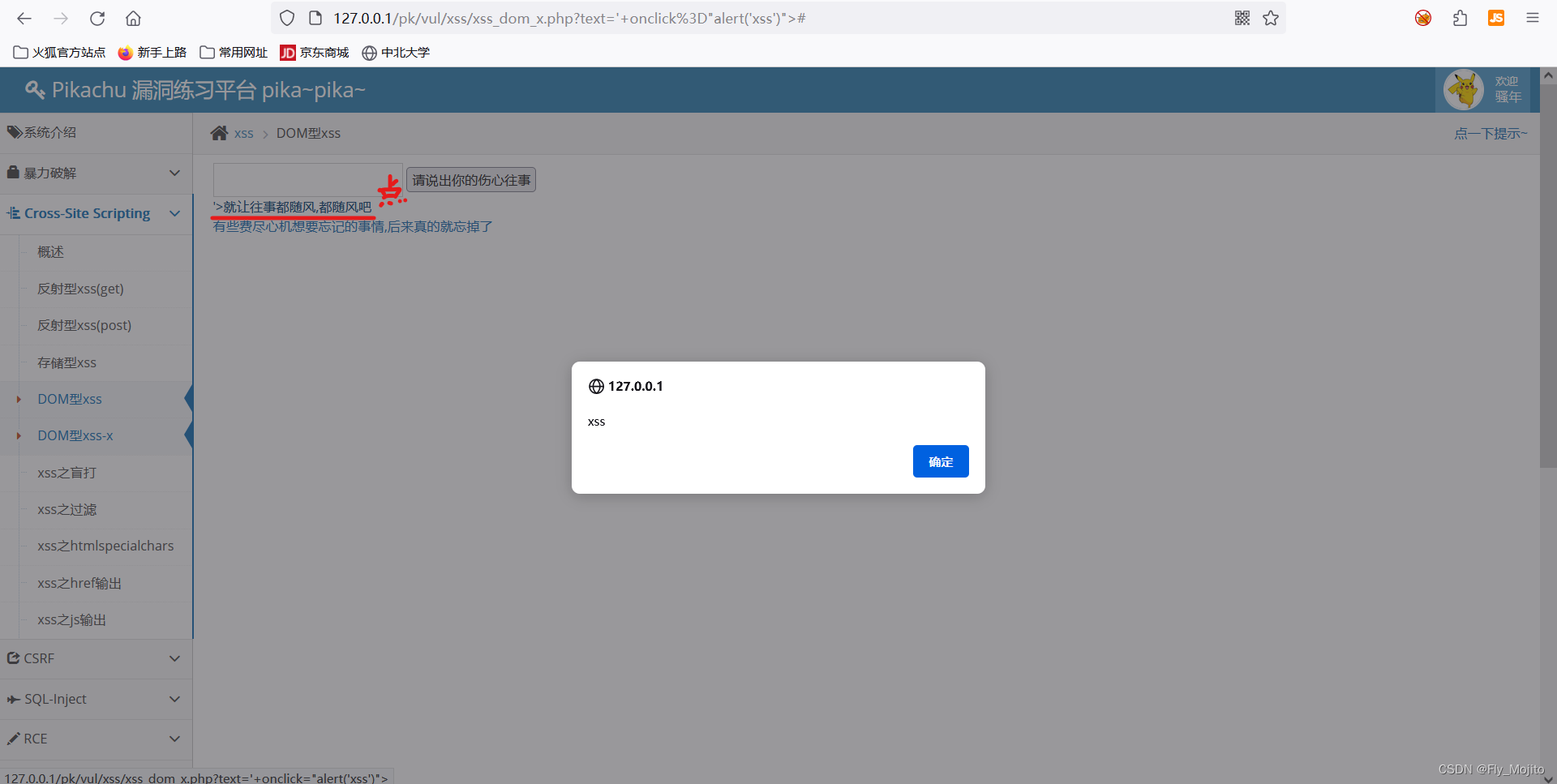
皮卡丘存储型xss、DOM型xss、DOM型xss-x
1.存储型xss 看题目,我们先留言,看它的过滤机制 发现可以永久存储并输出我们的留言 之后插入payload: <script>alert(xss)</script> 成功弹窗! 2.DOM型xss Dom型xss,简单的说,就是向文档对象传入xss参…...
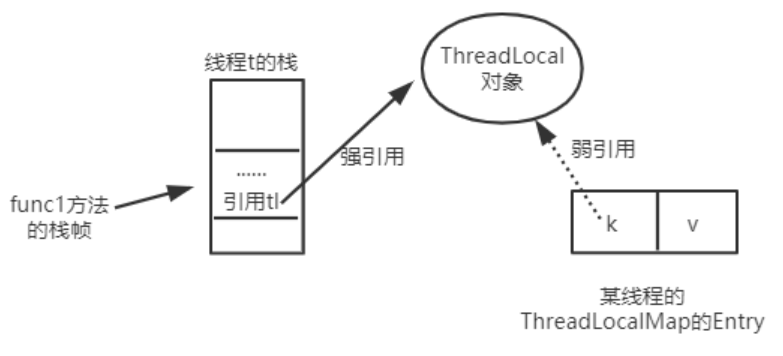
ThreadLocal源码
介绍 ThreadLocal是一个线程的本地变量,也就意味着这个变量是线程独有的,是不能与其他线程共享的。这样就可以避免资源竞争带来的多线程的问题。 但是,这种解决多线程安全问题的方式和加锁方式(synchronized、Lock) 是有本质的区…...
数据操作、查询)
Hive学习---3、DML(Data Manipulation Language)数据操作、查询
1、DML(Data Manipulation Language)数据操作 1.1 Load load语句可将文件导入到Hive表中 1、语法 load data [local] inpath filepath [overwrite] into table tablename [partition(partcol1val1,partcol2val2...)]2、关键字说明 (1&…...

硬件性能突破:免费AMD处理器调试工具SMUDebugTool终极指南
硬件性能突破:免费AMD处理器调试工具SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

如何高效实现Android Studio中文界面革命性升级
如何高效实现Android Studio中文界面革命性升级 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因为Android Studio的英…...

AI驱动的JMeter脚本生成:基于OpenAPI契约与作用域约束的DSL构建
1. 这不是“AI写脚本”,而是把JMeter从“手绘电路图”升级成“EDA自动布线”你有没有在凌晨两点,对着Postman里复制粘贴的27个接口参数发呆?一边点开Swagger文档截图,一边在JMeter里手动拖拽HTTP请求、填Header、加JSON提取器、设…...

OpenAI通用推理模型攻克近80年数学难题,打脸7个月前虚假突破质疑
【导语:5月21日,OpenAI宣布其一款未对外发布的内部通用推理模型独立完成原创数学证明,推翻了匈牙利数学家保罗埃尔德什1946年提出的“平面单位距离猜想”,这是AI首次独立攻克数学领域核心著名公开难题。】AI攻克近80年几何猜想Ope…...

Hive 3.1.3部署后,你可能会遇到的3个连接与权限报错及解决实录
Hive 3.1.3部署后三大经典连接与权限问题深度解析 当你终于按照教程完成Hive 3.1.3的安装,却在最后连接阶段遭遇各种"拦路虎"时,那种挫败感我深有体会。本文将带你直击三个最具代表性的连接与权限问题,从报错现象到根因分析&#x…...

从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册
从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册 第一次接触Xilinx UltraScale系列FPGA的GTY收发器时,最让人头疼的莫过于时钟配置。面对QPLL0、QPLL1和CPLL三种时钟源,以及N1、N2、M、D等分频参数,新手工程师…...

python政府集中采购管理系统设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能模块技术实现要点应用价值项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背…...

无风扇嵌入式主板:静默革命,如何重塑工业自动化与边缘计算的可靠性?
1. 项目概述:为什么嵌入式主板要“静悄悄”?在工业自动化、智能终端、医疗设备这些对稳定性和可靠性要求极高的领域里,你经常会听到设备内部风扇“呼呼”作响的声音。这声音背后,是传统工控机或PC架构主板为了散热而不得不做的妥协…...

Linux 环境变量详解及实例
Linux环境变量 1 ~/.bash_profile && ~/.bashrc 用户登陆Linux操作系统的时候,"/etc/profile", "~/.bash_profile"等配置文件会被自动执行。 执行过程是这样的: 登陆Linux系统时,首先启动"/etc/profil…...

别再为查重和 AIGC 检测头秃!okbiye 降重 + 降 AIGC 双功能,论文安全过审的最后一道防线
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 一、前言:论文提交前,你最怕的两个 “隐形杀手” 论文写到定稿,才发现重复率超标、AIGC 检测不过&am…...