Hive学习---3、DML(Data Manipulation Language)数据操作、查询
1、DML(Data Manipulation Language)数据操作
1.1 Load
load语句可将文件导入到Hive表中
1、语法
load data [local] inpath 'filepath' [overwrite] into table tablename [partition(partcol1=val1,partcol2=val2...)]
2、关键字说明
(1)local:表示从本地加载数据到Hive表,否则从HDFS加载数据到Hive表。
(2)OverWrite:表示覆盖表中已有的数据,否则表示追加
(3)Partition:表示上传到指定分区,若目标是分区表,需指定分区
3、案例实操
(1)创建一张表
create table student(id int, name string
)
row format delimited fields terminated by '\t';
(2)加载本地文件到Hive中
load data local inpath '/opt/module/datas/student.txt' into table student;
(3)加载HDFS文件到Hive中
- 上传文件到HDFS
hadoop fs -put /opt/module/datas/student.txt /user/zhm
- 加载HDFS上数据,导入完成后去HDFS上查看文件是否还存在
load data inpath '/user/zhm/student.txt'
into table student;
(4)加载数据覆盖表中已有的数据
load data inpath '/user/zhm/student.txt'
overwrite into table student;
1.2 Insert
1.2.1 将查询结果插入表中
1、语法
insert (into | overwrite) table tablename [partition(partcol1=val1,partcol2=val2...)] select_statement
2、关键字说明
(1)Into:将结果追加到目标表中
(2)OverWrite:用结果覆盖原有数据
3、案例
(1)创建一张表
create table student1(id int, name string
)
row format delimited fields terminated by '\t';
(2)将查询结果插入数据
insert overwrite table student3
select id, name
from student;
1.2.2 将给定values插入表中
1、语法
insert (into |overwrite ) table tablename [partition(partcol1=val1,partcol2=val2)...] values values_row[,values_row...]
2、案例
insert into table student1 values(1,'zhm'),(2,'zhm1');
1.2.3 将查询结果写入目标路径
1、语法
insert OverWrite [local] Directory directory [row format rwo_format] [stored as file_format] select_statement
2、案例
insert overwrite local directory '/opt/module/datas/student' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
select id,name from student;
1.3 Export&Import
Export导出语句可将表的数据和元数据信息一并导出到HDFS路径,Import可将Export导出的内容导入Hive,表的数据和元数据信息都会恢复。Export和Import可用于两个Hive实例之间的数据迁移。
1、语法
--导出
export table tablename To 'export_target_path'--导入
Import [external] table new_or_original_tablename from 'source_path' [location 'import_target_path']
2、案例
--导出
export table default.student to '/user/hive/warehouse/export/student';--导入
import table student2 from '/user/hive/warehouse/export/student';
2、查询
2.1 基础语法
select [all|distinct] select_expr,select_expr,...
from table_name --从哪个表查
[where where_condition] --过滤
[group by col_list] --分组查询
[having col_list] --分组后过滤
[order by col_list] --排序
[cluster by col_list
| [distribute by col_list] [sort by col_list]]
[limit number] --限制输出的行数
2.2 基本查询(select…from)
2.2.1 全表查询和特定列查询
1、全表查询
select * from emp;
2、选择特定列查询
select empno, ename from emp;
注意:
(1)SQL语言的大小写不敏感
(2)SQL可以写在一行或多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写
(5)使用缩进提高语句的可读性
2.2.2 列别名
(1)重命名一个列
(2)便于计算
(3)紧跟列名,也可以在列名和别名之间加入关键字‘as’
select ename AS name, deptno dn
from emp;
2.2.3 Limit 语句
典型的查询会返回多行数据。Limit子句用于限制返回的行数
select * from emp limit 2,3; -- 表示从第2行(不包括)开始,向下抓取3行
2.2.4 Where语句
(1)使用where子句将不满足条件的行过滤
(2)where子句紧随from子句
注意:where 子句中不能使用别名
--查询出薪水大于1000的所有员工
select * from emp where sal > 1000;
2.2.5 关系运算符
1、基本语法
如下操作符主要用于where和having语句中
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回true,反之返回false |
| A<=>B | 基本数据类型 | 如果A和B都为null或者都不为null,则返回true,如果只有一边为null,返回false |
| A<>B, A!=B | 基本数据类型 | A或者B为null则返回null;如果A不等于B,则返回true,反之返回false |
| A<B | 基本数据类型 | A或者B为null,则返回null;如果A小于B,则返回true,反之返回false |
| A<=B | 基本数据类型 | A或者B为null,则返回null;如果A小于等于B,则返回true,反之返回false |
| A>B | 基本数据类型 | A或者B为null,则返回null;如果A大于B,则返回true,反之返回false |
| A>=B | 基本数据类型 | A或者B为null,则返回null;如果A大于等于B,则返回true,反之返回false |
| A [not] between B and C | 基本数据类型 | 如果A,B或者C任一为null,则结果为null。如果A的值大于等于B而且小于或等于C,则结果为true,反之为false。如果使用not关键字则可达到相反的效果。 |
| A is null | 所有数据类型 | 如果A等于null,则返回true,反之返回false |
| A is not null | 所有数据类型 | 如果A不等于null,则返回true,反之返回false |
| in(数值1,数值2) | 所有数据类型 | 使用 in运算显示列表中的值 |
| A [not] like B | string 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回true;反之返回false。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母‘x’结尾,而‘%x%’表示A包含有字母‘x’,可以位于开头,结尾或者字符串中间。如果使用not关键字则可达到相反的效果。 |
| A rlike B, A regexp B | string 类型 | B是基于java的正则表达式,如果A与其匹配,则返回true;反之返回false。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
--查询薪水大于1000,部门是30
select *
from emp
where sal > 1000 and deptno = 30;--查询薪水大于1000,或者部门是30
select *
from emp
where sal>1000 or deptno=30;--查询除了20部门和30部门以外的员工信息
select *
from emp
where deptno not in(30, 20);
2.2.6 逻辑运算函数
1、基本语法
| 操作符 | 含义 |
|---|---|
| and | 逻辑并 |
| or | 逻辑或 |
| not | 逻辑否 |
2.2.7 聚合函数
1、语法
| 函数名 | 函数作用 |
|---|---|
| count(*) | 表示统计所有行数,包含null值; |
| count(某列) | 表示该列一共有多少行,不包含null值 |
| max() | 求最大值,不包含null,除非所有值都是null |
| min() | 求最小值,不包含null,除非所有值都是null |
| sum() | 求和,不包含null |
| avg() | 求平均值,不包含null |
--求总行数(count)
select count(*) cnt from emp;--求工资的最大值(max)
select max(sal) max_sal from emp;--求工资的最小值(min)
select min(sal) min_sal from emp;--求工资的总和(sum)
select sum(sal) sum_sal from emp; --求工资的平均值(avg)
select avg(sal) avg_sal from emp;
2.3 分组
2.3.1 group by
Group by 语句通常会和聚合函数一起使用,按照一个或者多个队列结果进行分组,然后对每个组执行聚合操作。
--计算emp表每个部门的平均工资。
select t.deptno, avg(t.sal) avg_sal
from emp t
group by t.deptno;--计算emp每个部门中每个岗位的最高薪水
select t.deptno, t.job, max(t.sal) max_sal
from emp t
group by t.deptno, t.job;
2.3.2 Having语句
1、Having和where的不同点
(1)where后面不能写分组聚哈函数,而Having后面可以使用分组聚合函数
(2)having只用于group by 分组统计语句
--求每个部门的平均工资
select deptno, avg(sal)
from emp
group by deptno;--求每个部门的平均薪水大于2000的部门。
select deptno, avg(sal) avg_sal
from emp
group by deptno
having avg_sal > 2000;
2.4 Join
2.4.1 等值Join
Hive支持通常的sql join语句,但是只支持等值连接,不支持非等值连接。
--根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称。
select e.empno, e.ename, d.dname
from emp e
join dept d
on e.deptno = d.deptno;
2.4.2 表的别名
1、好处
(1)使用别名可以简化查询
(2)区分字段来源
--合并员工表和部门表。
select e.*,d.*
from emp e
join dept d
on e.deptno = d.deptno;
2.4.3 内连接
只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
select e.empno, e.ename, d.deptno
from emp e
join dept d
on e.deptno = d.deptno;
2.4.4 左外连接
join操作符左边表中符合where子句的所有记录将会被返回。
select e.empno, e.ename, d.deptno
from emp e
left join dept d
on e.deptno = d.deptno;
2.4.5 右外连接
join操作符右边表中符合where子句的所有记录将会被返回。
select e.empno, e.ename, d.deptno
from emp e
right join dept d
on e.deptno = d.deptno;
2.4.6 满外连接
将会返回所有表中符合where语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用null值替代。
select e.empno, e.ename, d.deptno
from emp e
full join dept d
on e.deptno = d.deptno;
2.4.7 多表连接
注意:连接n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
select e.ename, d.dname, l.loc_name
from emp e
join dept d
on d.deptno = e.deptno
join location l
on d.loc = l.loc;
大多数情况下,Hive会对每对join连接对象启动一个MapReduce任务。本立会首先启动一个MapReduce job对表e和表d进行连接操作,然后再启动一个MapReduce job将第一个MapReduce job的输出和表1进行连接操作。
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
2.4.8 笛卡尔积
1、笛卡尔积会在下面条件产生
(1)省略连接条件
(2)连接条件无效
(3)所以表中的所有行互相连接
select empno, dname
from emp, dept;
2.4.9 联合(union和union all)
1、union和union all上下拼接
union和union all都是上下拼接sql的结果,这点和join是有区别的,join是左右关联,union和union all是上下拼接。union去重,union all不去重。
union和union all上下拼接sql结果时有两个要求:
(1)两个sql结果,列的个数必须相同
(2)两个sql结果,上下所对应列的类型必须一致
select *
from emp
where deptno=30
union
select *
from emp
where deptno=40;
2.5 排序
2.5.1 全局排序(Order by)
只有一个Reduce
1、使用Order by 子句排序
asc(ascend):升序(默认)
desc(descend):降序
2、Order by 子句在select语句的末尾
--查询员工信息按工资升序排列
select *
from emp
order by sal;--查询员工信息按工资降序排列
select *
from emp
order by sal desc;--按照别名排序案例实操
select ename, sal * 2 twosal
from emp
order by twosal;--多个列排序案例实操
select ename, deptno, sal
from emp
order by deptno, sal;2.5.2 每个Reduce内部排序(Sort by)
对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用Sort by。
Sort by为每个reduce产生一个排序文件。每个Reduce内部进行排序,对全局结果集来说不是排序。
1、设置reduce个数
set mapreduce.job.reduces=3;
2、查看设置reduce个数
set mapreduce.job.reduces;
3、根据部门编号降序查看员工信息
select *
from emp
sort by deptno desc;
2.5.3 分区(Distribute by)
Distribute By:在有些情况下,我们需要控制某个特定行应该到哪个Reducer,通常是为了进行后续的聚集操作。distribute by子句可以做这件事。distribute by类似MapReduce中partition(自定义分区),进行分区,结合sort by使用。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
--先按照部门编号分区,再按照员工编号薪资排序
set mapreduce.job.reduces=3;
insert overwrite local directory
'/opt/module/hive/datas/distribute-result'
select *
from emp
distribute by deptno
sort by sal desc;
注意:
(1)distribute by的分区规则是根据分区字段的hash码与reduce的个数进行相除后,余数相同的分到一个区
(2)Hive要求distribute by语句要写在sort by语句之前。
2.5.4 分区排序(Cluster by)
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为asc或者desc。
select *
from emp
cluster by deptno;或
select *
from emp
distribute by deptno
sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
相关文章:
数据操作、查询)
Hive学习---3、DML(Data Manipulation Language)数据操作、查询
1、DML(Data Manipulation Language)数据操作 1.1 Load load语句可将文件导入到Hive表中 1、语法 load data [local] inpath filepath [overwrite] into table tablename [partition(partcol1val1,partcol2val2...)]2、关键字说明 (1&…...

chatgpt赋能python:Python去除重复元素的几种方法
Python去除重复元素的几种方法 在Python编程中,去除列表、集合、字典等数据结构中的重复元素是一个常见的操作。本文将介绍Python中去除重复元素的几种方法,并分析它们的优缺点。 方法一:使用set去重 Set是Python中的一种集合类数据结构&a…...
2年测试我迷茫了,软件测试大佬都会哪些技能?我的测试进阶之路...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Python自动化测试&…...

21天学会C++:Day7----auto关键字
CSDN的uu们,大家好。这里是C入门的第七讲。 座右铭:前路坎坷,披荆斩棘,扶摇直上。 博客主页: 姬如祎 收录专栏:C专题 目录 1. 知识引入 2. auto的使用 2.1 auto与指针和引用结合起来使用 2.2 在同一…...

Vue3 + ElementPlus实战学习——模拟简单的联系人列表管理后台
文章目录 📋前言🎯demo 介绍🎯功能分析🧩数据的展示与分页功能🧩编辑功能🧩删除功能 🎯部分代码分析🎯完整代码📝最后 📋前言 这篇文章介绍一下基于 Vue3 和…...
【Go语言从入门到实战】并发篇
Go语言从入门到实战 — 并发篇 协程 Thread vs Groutine 相比之下,协程的栈大小就小很多了,创建起来也会更快,也更节省系统资源。 一个 goroutine 的栈,和操作系统线程一样,会保存其活跃或挂起的函数调用的本地变量…...
)
img标签请求 添加自定义header(二)
之前写过一篇关于img添加自定义请求头的处理方式(点击这里),那么本篇我们来看另外几种实现方法。 自定义指令 以Vue为例,我们可以定义一个全局指令,对img标签进行一些处理。 <template><img :src"src…...

Set和weakSet Map和WeakMap
Set和weakSet的用法和区别 1.Set 和weakSet 它是类似于数组,且成员值都是唯一的, 2.Set有 add has delete clear size keys values forEach entries 3.weakSet 有add has delete 4.WeakSet中只能存放对象类型,不能存放基本类型 5.WeakSet它是…...

Qt基础之三十六:异常处理
本文将介绍如何在Qt中使用try...catch和调试dump文件来处理异常。 Qt版本5.12.6 一.使用try...catch 一段简单的捕获异常的代码,新建一个控制台工程,pro文件不用修改 #include <QCoreApplication> #include <QDebug>int main(int argc, char *argv[]) {QCoreA…...

【HMS Core】【ML Kit】活体检测FAQ合集
【问题描述1】 使用示例代码集成活体检测SDK时,报错state code -7001 【解决方案】 使用示例代码前请详细阅读示例工程中的“README”文件。您需要完成以下操作后才可以运行示例代码。 在AppGallery Connect网站下载自己应用的“agconnect-services.json”文件&a…...

ChatGPT:使用OpenAI创建自己的AI网站,使用 flask web框架快速搭建网站主体
使用OpenAI创建自己的AI网站 如果你还是一个OpenAI的小白,有OpenAI的账号,但想调用OpenAI的API搞一些有意思的事,那么这一系列的教程将仔细的为你讲解如何使用OpenAI的API制作属于自己的AI网站。 使用 flask web框架快速搭建网站主体 之前…...
后端(一):Tomcat
我们之前的前端是被我们一笔带过的,那不是我们要讲的重点,而这里的后端则是重点。本章先来认识认识后端的基础。 Tomcat 是什么 我们先来聊聊什么叫做tomcat,我们熟悉的那个是汤姆猫: 这和我们Java世界中的Tomcat 不是同一只猫&…...
)
华为OD机试之最小调整顺序次数、特异性双端队列(Java源码)
最小调整顺序次数、特异性双端队列 题目描述 有一个特异性的双端队列,该队列可以从头部或尾部添加数据,但是只能从头部移出数据。 小A依次执行2n个指令往队列中添加数据和移出数据。其中n个指令是添加数据(可能从头部添加、也可能从尾部添加…...

2023年武汉住建厅七大员怎么报名?报名流程?精准题库一次过??
2023年武汉住建厅七大员怎么报名?报名流程?精准题库一次过?? 2023年武汉住建厅七大员是指施工员、质量员、资料员、材料员、机械员、标准员、劳务员,报的最多的可能就是施工员,质量员和资料员 报名流程: 1…...

Rust每日一练(Leetday0014) 组合总和II、缺失正数、接雨水
目录 40. 组合总和 II Combination Sum II 🌟🌟 41. 缺失的第一个正数 First Missing Positive 🌟🌟🌟 42. 接雨水 Trapping Rain Water 🌟🌟🌟 🌟 每日一练刷题…...
EnjoyVIID部署
1、下载 git clone https://gitee.com/tsingeye/EnjoyVIID.git 2、导入数据库 创建表enjoyviid 导入数据库(修改数据库文件里的编码) EnjoyVIID/sql/tsingeye-viid.sql 3、修改配置 vim EnjoyVIID/tsingeye-admin/src/main/resources/application-dev.yml 修改数据库连接、re…...

用Python解决爱因斯坦的数学问题
1 问题 有一条阶梯,若每步跨2阶,则剩最后一阶,若每步跨3阶,则最后剩2阶,若每步跨5阶,则最后剩4阶,若每步跨6阶,则最后剩5阶,只有每次跨7阶,最后才刚好不剩&am…...

ChatGPT提示词攻略之基本原则
下面是调用openai的completion接口的函数。但在本文中并不是重点。了解一下就好。 import openai import osfrom dotenv import load_dotenv, find_dotenv _ load_dotenv(find_dotenv())openai.api_key os.getenv(OPENAI_API_KEY)def get_completion(prompt, model"gp…...
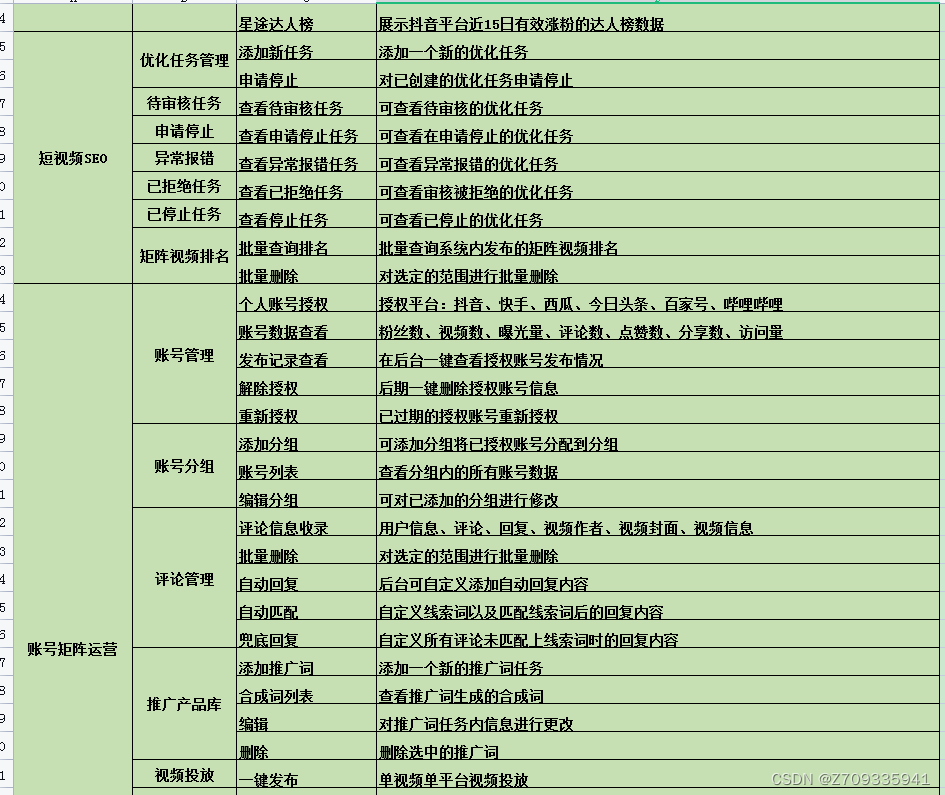
抖音seo源码如何开发部署?
前言:抖音seo源码,抖音矩阵系统源码搭建,抖音矩阵同步分发。抖音seo源码部署是需要对接到这些正规接口再来做开发的,目前账号矩阵程序开发的功能,围绕一键管理多个账号,做到定时投放,关键词自动…...

Java中常见锁的分类及概念分析
基于线程对同一把锁的获取情况分类 可重入锁 同一个线程可以多次获取锁 每次获取锁,锁的计数器加1,每次释放锁锁的计数器减1 锁的计数器归零,锁完全释放 Java中提供的synchronized,ReentrantLock,ReentrantReadWriteL…...

安卓HTTPS抓包证书信任问题深度解析与系统级迁移方案
1. 为什么安卓抓包总在“证书信任”这关卡住?——一个被低估的系统级权限问题你是不是也经历过:Fiddler、Charles 或 mitmproxy 在电脑上配置得严丝合缝,手机 Wi-Fi 代理一设就通,HTTP 流量哗哗跑,可一到 HTTPS&#x…...

第38天:SQL详解之DML
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、基本查询与投影 1.1 查询所有列 1.2 投影与别名 二、数据筛选(WHERE 子句) 2.1 等值与比较筛选 2.2 多条件组合(AND / OR) 2.3 范围查询(BETWEEN) 2.4 CASE 表达式与…...

Keil编译器数据类型详解与嵌入式开发实践
1. 变量范围查询指南:Keil编译器数据类型详解 作为一名嵌入式开发老手,我深知在Keil环境下编程时,准确掌握各种数据类型的取值范围是多么重要。今天就来系统梳理C51/C166/C251编译器中的数据类型范围问题,这些经验都是我在实际项目…...

Windows平台PDF处理终极方案:告别编译烦恼,三分钟快速部署
Windows平台PDF处理终极方案:告别编译烦恼,三分钟快速部署 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上…...

UABEA:跨平台Unity游戏资源编辑神器,解锁游戏模组制作新境界
UABEA:跨平台Unity游戏资源编辑神器,解锁游戏模组制作新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 你是否曾想修改游戏中的角色皮肤、替换背景音乐,或是深…...

甲言Jiayan:终极古汉语NLP解决方案,让文言文处理变得简单高效
甲言Jiayan:终极古汉语NLP解决方案,让文言文处理变得简单高效 【免费下载链接】Jiayan 甲言,专注于古代汉语(古汉语/古文/文言文/文言)处理的NLP工具包,支持文言词库构建、分词、词性标注、断句和标点。Jiayan, the 1st NLP toolk…...
)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设) 录制完一段音频后,你是否经常遇到这样的困扰:人声听起来闷闷的像隔了层棉被,或是尖锐刺耳到让人皱眉,又或者整体浑浊不清缺乏层次感&…...

挖 SRC 必备 25 个漏洞平台 零基础入门到实战全汇总
【值得收藏】程序员必看:网络安全漏洞挖掘平台大全,附高额奖励攻略 本文详细介绍了30网络安全应急响应中心(SRC)平台,包括腾讯、360、华为、京东等企业官方漏洞平台,以及补天、Seebug等第三方平台。这些平台允许白帽黑客提交企业…...

VN设备通道乱序问题解析与Vector硬件固定配置实战
1. 问题根源:为什么VN设备的通道会“乱跑”?在汽车电子测试领域,Vector的VN系列设备(如VN1640A、VN1610等)是进行CAN、LIN、FlexRay等总线通信测试与仿真的核心工具。当我们在一个复杂的台架上部署了多台同型号的VN设备…...

3步快速诊断法:BlenderGIS插件从崩溃到稳定运行的完整解决方案
3步快速诊断法:BlenderGIS插件从崩溃到稳定运行的完整解决方案 【免费下载链接】BlenderGIS Blender addons to make the bridge between Blender and geographic data 项目地址: https://gitcode.com/gh_mirrors/bl/BlenderGIS BlenderGIS是一款强大的Blend…...