hadoop环境配置及HDFS配置
环境与配置
- ubuntu 20.04.6 /centos8
- hadoop 3.3.5
指令有部分不一样但是,配置是相同的
安装步骤
- 创建一个虚拟机,克隆三个虚拟机,master内存改大一点4G,salve内存1Gj
- 修改主机名和配置静态ip(管理员模式下))
`
hostnamectl set-hostname node1 # 修改主机名
sudo passwd root #设置root密码
sudo apt install -y ifupdown net-tools #安装网络服务
sudo apt-get install openssh-server -y # 安装ssh服务
init 6 # 重启
vi /etc/network/interfaces # 创建文件夹,填入下面的内容
auto lo
iface lo inet loopback
auto ens33
iface ens33 inet static
address 192.168.139.130
netmask 255.255.255.0
gateway 192.168.139.2
dns-nameservers 223.5.5.5
dns-nameservers 8.8.8.8
systemctl restart networking(重启网络服务)
可参考链接: https://blog.csdn.net/alfiy/article/details/122279914
3. 修改windows的hosts和linux的host
vim /etc/hosts # 修改主机映射
4. 设置ssh免密登录,三台机器都要
ssh-keygen -t rsa -b 4096
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
如果报错 Permission denied (publickey,password)
参考: https://blog.csdn.net/weixin_41891385/article/details/118631106
每台机器创建hadoop用户
sudo useradd -r -m -s /bin/bash hadoop
sudo passwd hadoop
sudo vim /etc/sudoers
复制root那一行,把root改为hadoop
参考链接: https://www.cnblogs.com/geyouneihan/p/9839153.html
`
- 把hadoop包分别拉倒三个虚拟机中
`
mkdir -p /export/server
tar -zxvf jdk.tar.gz -C /export/server/
ln -s /export/server/jdk jdk
vim /etc/profile 添加下面内容
export JAVA_HOME=/export/server/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
source /etc/profile
先删除系统的java链接,然后在添加自己的软连接
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java
apt-get install lib32z1 # 解决报错问题
验证
java -version
javac -version
scp -r jdk/ node2:pwd/ 远程复制到node2,首先先进入到jdk所在的文件夹
6. 关闭防火墙 sudo ufw disable 7.同步三台机器的时间
sudo apt install -y ntp
rm -f /etc/localtime ;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
apt install ntpdate
ntpdate -u ntp.aliyun.com
sudo service ntp restart
8. 安装hadoop设置软连,修改hadoop文件夹下面的/etc/里面的文件
worker 文件添加
node1
node2
node3
vim hadoop-env.sh 添加
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR= H A D O O P H O M E / e t c / h a d o o p e x p o r t H A D O O P L O G D I R = HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR= HADOOPHOME/etc/hadoopexportHADOOPLOGDIR=HADOOP_HOME/logs
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
下面这些参数是ubuntu系统需要的
export HADOOP_COMMON_HOME= H A D O O P H O M E e x p o r t H A D O O P H D F S H O M E = HADOOP_HOME export HADOOP_HDFS_HOME= HADOOPHOMEexportHADOOPHDFSHOME=HADOOP_HOME
export HADOOP_YARN_HOME= H A D O O P H O M E e x p o r t H A D O O P M A P R E D H O M E = HADOOP_HOME export HADOOP_MAPRED_HOME= HADOOPHOMEexportHADOOPMAPREDHOME=HADOOP_HOME
core-site.xml 添加
fs.defaultFS
hdfs://node1:9001
hdfs-site.xml 添加
dfs.datanode.data.dir.perm
700
dfs.namenode.name.dir
/data/nn
dfs.namenode.hosts
node1,node2,node3
dfs.blocksize
268435456
dfs.namenode.handler.count
100
dfs.datanode.data.dir
/data/dn
dfs.namenode.datanode.registration.ip-hostname-check
false
dfs.replication
3
三台机器都创建datanode和namenode对应的文件夹
mkdir -p /data/nn;mkdir -p /data/dn
把node1的hadoop文件夹复制到node2,node3
scp -r hadoop-3.3.5/ node2:pwd/
scp -r hadoop-3.3.5/ node3:pwd/
复制完之后创建软连
ln -s /export/server/hadoop hadoop
三台机器都操作配置环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin::$HADOOP_HOME/sbin
source /etc/profile
为hadoop用户创建权限操作/data,/export
chown -R hadoop:hadoop /data; chown -R hadoop:hadoop /export
9.格式化hadoop
su hadoop
hadoop namenode -format
10.启动hadoop
start-dfs.sh
jps 查看启动状态
stop-dfs.sh
`
11. 如果三个节点总有一个datanode或者主节点的namenode启动失败
删除 data/dn;data/nn;hadoop/logs;hadoop/tmp里面的内容
hadoop namenode -format 最好执行一次,否则每次执行都要删除上面的内容
相关文章:

hadoop环境配置及HDFS配置
环境与配置 ubuntu 20.04.6 /centos8hadoop 3.3.5 指令有部分不一样但是,配置是相同的 安装步骤 创建一个虚拟机,克隆三个虚拟机,master内存改大一点4G,salve内存1Gj修改主机名和配置静态ip(管理员模式下)) hostnamectl set-hostname node1 # 修改主机名 sudo passwd root …...

HTML中 meta的基本应用
meta 标签的定义 meta 标签是 head 部分的一个辅助性标签,提供关于 HTML 文档的元数据。它并不会显示在页面上,但对于机器是可读的。可用于浏览器(如何显示内容或重新加载页面),搜索引擎(SEO)或…...

docker compose 下 Redis 主备配置
1、准备两台虚拟机或者物理机 node1 IP:192.168.123.78 node2 IP:192.168.123.82 2、安装docker和docker compose 3、安装node1,配置docker-compose.yml version: 3services:redis-rs1:container_name: redis_node1image: redis:5.0.3rest…...

Tomcat ServletConfig和ServletContext接口概述
ServletConfig是一个接口,是Servlet规范中的一员 WEB服务器实现了ServletConfig接口,这里指的是Tomcat服务器 一个Servlet对象中有一个ServletConfig对象,Servlet和ServletConfig对象是一对一 ServletConfig对象是Tomcat服务器创建的…...

linux内核open文件流程
打开文件流程 本文基本Linux5.15 当应用层通过open api打开一个文件,内核中究竟如何处理? 本身用来描述内核中对应open 系统调用的处理流程。 数据结构 fdtable 一个进程可以打开很多文件, 内核用fdtable来管理这些文件。 include/linu…...
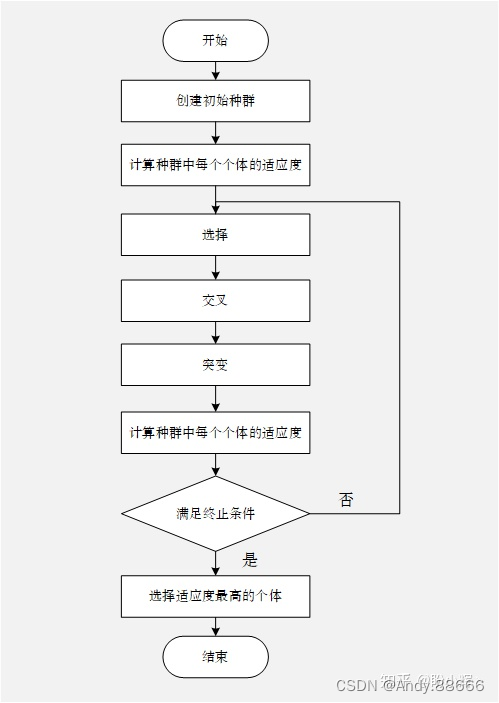
遗传算法讲解
遗传算法(Genetic Algorithm,GA) 是模拟生物在自然环境中的遗传和进化的过程而形成的自适应全局优化搜索算法。它借用了生物遗传学的观点,通过自然选择、遗传和变异等作用机制,实现各个个体适应性的提高。 基因型 (G…...
)
PostgreSQL修炼之道之高可用性方案设计(十六)
20 高可用性方案设计(一) 在一个生产系统中,通常都需要用高可用方案来保证系统的不间断运行。本章将详细介绍如何实现PostgreSQL数据库的高可用方案。 20.1 高可用架构基础 通常数据库的高可用方案都是让多个数据库服务器协同工作࿰…...

Bybit面经
缘起 V2EX有广告内推,看描述还挺不错 贴主5 年半工作经验,有两年大厂工作经历,20 年 11 月来到新加坡分公司开始工作 后来是猎头Jeff找的我 0318 主面 主要一个面试官是后端开发金融背景 某条金融线的负责人;其余是交叉面试。面…...
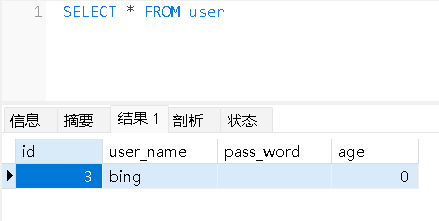
GORM---创建
目录 模型定义使用Create创建记录一次性创建多条数据批量插入数据时开启事务默认值问题 模型定义 定义一个PersonInfo结构体。 type PersonInfo struct {Id uint64 gorm:"column:id;primary_key;NOT NULL" json:"id"UserName string gorm:"co…...

高级查询 — 分组汇总
关于分组汇总 1.概述 将查询结果按某一列或者多列的值分组。 group by子句 分组后聚合函数将作用于每一个组,即每一组都有一个函数值。 语法 select 字段列表 from 表名 where 筛选条件 group by 分组的字段;select 字段列表 from 表名 group by 分组的字段 hav…...

【多线程】阻塞队列
1. 认识阻塞队列和消息队列 阻塞队列也是一个队列,也是一个特殊的队列,也遵守先进先出的原则,但是带有特殊的功能。 如果阻塞队列为空,执行出队列操作,就会阻塞等待,阻塞到另一个线程往阻塞队列中添加元素(…...

python2升级python3
查看当前版本 [roottest-01 node-v18.16.0]# python -V Python 2.7.5 安装依赖 [roottest-01 node-v18.16.0]# yum install -y gcc gcc-c zlib zlib-devel readline-devel 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base…...
(与spark的结合)--非bulk_insert模式)
Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景 之前讨论的都是’hoodie.datasource.write.operation’:bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件: /dt1/.hoodie_partition_metadata /dt1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_202305282…...
)
Java之旅(九)
Java 循环语句 Java 中的循环语句包括 for、while 和 do-while,它们都可以用于实现循环结构。 for 语句用于循环执行一段代码块,直到给定的条件表达式的布尔值为 false。 for 语句的一般格式如下: for (initialization; condition; update…...

6年测试经验之谈,为什么要做自动化测试?
一、自动化测试 自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。 个人认为,只要能服务于测试工作,能够帮助我们提升工作效率的,不管是所谓的自动化工具,还是简单的SQL 脚本、批处理脚本,还是自己编写…...

二分法的边界条件 2517. 礼盒的最大甜蜜度
2517. 礼盒的最大甜蜜度 给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。 商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两种糖果 价格 绝对差的最小值。 返回礼盒的 最大 甜蜜度。 记录一…...

java设计模式(十六)命令模式
目录 定义模式结构角色职责代码实现适用场景优缺点 定义 命令模式(Command Pattern) 又叫动作模式或事务模式。指的是将一个请求封装成一个对象,使发出请求的责任和执行请求的责任分割开,然后可以使用不同的请求把客户端参数化&a…...

[运维] iptables限制指定ip访问指定端口和只允许指定ip访问指定端口
iptables限制指定ip访问指定端口 要使用iptables限制特定IP地址访问特定端口,您可以使用以下命令: iptables -A INPUT -p tcp -s <IP地址> --dport <端口号> -j DROP请将 <IP地址> 替换为要限制的IP地址,将 <端口号&g…...
)
JS学习笔记(3. 流程控制)
1. 分歧 1.1 if条件 if (条件) {...} // 为真则执行,单条语句可省略大括号 if (条件) {...} else {...}// 为真则执行if,否则执行else if (条件1) {...} else if (条件2) {...} else {...} // 条件1为真则,条件2为真则,否则执…...
遥感云大数据在灾害、水体与湿地领域典型案例及GPT模型教程
详情点击链接:遥感云大数据在灾害、水体与湿地领域典型案例及GPT模型教程 一:平台及基础开发平台 GEE平台及典型应用案例; GEE开发环境及常用数据资源; ChatGPT、文心一言等GPT模型 JavaScript基础; GEE遥感云重…...

AtlasOS终极解决:2502/2503错误代码效率提升方案
AtlasOS终极解决:2502/2503错误代码效率提升方案 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trending/atlas1/Atl…...

利用M2LOrder实现安全高效的内网穿透方案设计与验证
利用M2LOrder实现安全高效的内网穿透方案设计与验证 1. 引言 你有没有遇到过这样的麻烦事?自己电脑上开发了一个网站或者服务,想给同事或者客户临时看一下效果,结果发现对方根本访问不了。原因很简单,你的服务跑在公司的内网或者…...

Phi-3 Forest Laboratory 数学公式处理:集成MathType逻辑的LaTeX代码生成
Phi-3 Forest Laboratory 数学公式处理:集成MathType逻辑的LaTeX代码生成 你是不是也遇到过这样的场景?写论文或者做笔记时,需要插入一个复杂的数学公式,比如那个让人头疼的“二元二次方程的求根公式”。你打开LaTeX编辑器&#…...

OpenClaw安全加固:Qwen3.5-4B-Claude操作权限精细化控制
OpenClaw安全加固:Qwen3.5-4B-Claude操作权限精细化控制 1. 为什么需要权限控制? 上周我在调试OpenClaw自动化脚本时,差点酿成一场"灾难"——AI助手误将我的工作文档识别为临时文件,准备执行删除操作。幸亏当时设置了…...

Phi-3 Mini 128K应用场景:技术团队内部知识沉淀问答系统
Phi-3 Mini 128K应用场景:技术团队内部知识沉淀问答系统 1. 技术团队的知识管理痛点 在快节奏的技术开发环境中,团队经常面临这样的困境:新成员加入时需要花费大量时间熟悉项目历史,关键问题的解决方案分散在各个聊天记录和邮件…...

Magpie插件管理终极指南:如何让窗口缩放效果始终保持最佳状态
Magpie插件管理终极指南:如何让窗口缩放效果始终保持最佳状态 【免费下载链接】Magpie An all-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 在Windows窗口缩放领域,Magpie凭借其强大的插件…...

Python 3.12+ 新特性与性能工程化:迁移清单与常见坑
[toc]> 专栏定位:Python 工程化进阶(第40章) > 适读人群:后端工程师、基础架构、计划升级 Python 运行时的团队摘要Python 3.12 起在解释器层面持续优化(如 inlined comprehensions、更好的错误信息、f-string …...

终极指南:掌握AMD Ryzen SMU调试工具,解锁硬件调优新境界
终极指南:掌握AMD Ryzen SMU调试工具,解锁硬件调优新境界 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

PyTorch/TensorFlow张量加速实战:3个被90%工程师忽略的底层CUDA内核调优技巧
第一章:PyTorch/TensorFlow张量加速实战:3个被90%工程师忽略的底层CUDA内核调优技巧CUDA流与默认流解耦:避免隐式同步瓶颈 PyTorch 和 TensorFlow 默认将所有 CUDA 操作提交至默认流(null stream),导致跨 k…...

Z-Image-Turbo-rinaiqiao-huiyewunv 数据预处理管道构建:使用Python自动化准备训练数据
Z-Image-Turbo-rinaiqiao-huiyewunv 数据预处理管道构建:使用Python自动化准备训练数据 你是不是也遇到过这样的情况:好不容易找到了一个心仪的图像生成模型,比如Z-Image-Turbo-rinaiqiao-huiyewunv,想用自己的数据训练一下&…...