JDK8 ConcurrentHashMap源码分析
文章目录
- 常量说明
- put() 方法
- putVal() 方法
- initTable():初始化数组
- treeifyBin():链表转红黑树
- tryPresize():初始化数组+扩容
- TreeBin() 构造方法:生成红黑树
- putTreeVal():往红黑树中插入值
- helpTransfer():多线程帮助扩容
- addCount():计算Map中的元素总数(put时+1,delete时-1)
- fullAddCount():CAS往CounterCell数组中加值
- sumCount():计算Map中所有元素总数
- resizeStamp():当返回值左移 RESIZE_STAMP_SHIFT 位时,一定是负数
- transfer():将旧数组元素转移到新数组中
- ForwardingNode():构造方法,hash值为-1(MOVED)
- 总结
- JDK8中的ConcurrentHashMap是怎么保证并发安全的?
常量说明
数组中 Node 节点的 Hash 值几种常量:
// hash>0表示数组中是链表,hash=0表示null
static final int MOVED = -1; // Map 在扩容,旧数组中对应节点已经被到了新数组中
static final int TREEBIN = -2; // 数组对应节点是红黑树(与HashMap不同,hashMap数组中存放的是红黑树的根节点,// 而ConcurrentHashMap给红黑树包了一层,放的是TreeBin对象,hash值为-2,其中有一个指针指向红黑树的根节点)
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
put() 方法
public V put(K key, V value) {return putVal(key, value, false);
}
putVal() 方法
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException(); // k,v不能为空int hash = spread(key.hashCode()); // 计算hash值int binCount = 0;for (Node<K,V>[] tab = table;;) { // 死循环Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable(); // 初始化数组else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //数组对应位置的值为null,tabAt方法保证调用时的可见性if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null))) // cas 往里设置值break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED) // Map正在扩容tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) { // 头节点作为锁对象if (tabAt(tab, i) == f) { if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) { // 遍历链表K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) { // 链表中存在相同的值oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) { // 遍历到链表尾部,插入pred.next = new Node<K,V>(hash, key,value, null);break;}}//HashMap:数组中是放入了红黑树的root节点,TreeNode类型//ConcurrentHashMap:数组中是放入了TreeBin对象,TreeBin对象中有一个root属性,指向红黑树root节点//相当于是给红黑树在外面包了一层,方便用数组中的节点加锁,避免了HashMap红黑树root节点会变动问题else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, // 红黑树中插入值value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD) //链表数量大于等于8时,转红黑树treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}
initTable():初始化数组
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {if ((sc = sizeCtl) < 0) // 说明正在有线程初始化Thread.yield(); //让出cpu资源else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //cas获取锁try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY; //默认容量16@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; //初始化数组table = tab = nt;sc = n - (n >>> 2); //n右移2位相当于16/4(容量的1/4),然后再用容量减掉,就剩下3/4了,和HashMap的0.75一样}} finally {sizeCtl = sc;}break;}}return tab;
}
treeifyBin():链表转红黑树
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;if (tab != null) {if ((n = tab.length) < MIN_TREEIFY_CAPACITY) //数组大小小于64,扩容tryPresize(n << 1);else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {synchronized (b) {if (tabAt(tab, index) == b) {TreeNode<K,V> hd = null, tl = null;for (Node<K,V> e = b; e != null; e = e.next) {TreeNode<K,V> p =new TreeNode<K,V>(e.hash, e.key, e.val,null, null); //Node节点转换成TreeNode节点// 构建双向链表if ((p.prev = tl) == null)hd = p;elsetl.next = p;tl = p;}setTabAt(tab, index, new TreeBin<K,V>(hd)); //构建红黑树并放入数组中}}}}
}
tryPresize():初始化数组+扩容
private final void tryPresize(int size) {int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);int sc;while ((sc = sizeCtl) >= 0) {Node<K,V>[] tab = table; int n;if (tab == null || (n = tab.length) == 0) { // 数组初始化,与initTable()方法相似n = (sc > c) ? sc : c;if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if (table == tab) { @SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}}}else if (c <= sc || n >= MAXIMUM_CAPACITY) //扩容完毕break;else if (tab == table) { //多线程扩容,与addCount()方法中逻辑相同int rs = resizeStamp(n);if (sc < 0) {Node<K,V>[] nt;if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);}}
}
TreeBin() 构造方法:生成红黑树
与 HashMap 中 treeify() 的处理一样,就不再赘述,详见:HashMap put() 方法源码分析#treeify()
// b 是双向链表的头节点
TreeBin(TreeNode<K,V> b) {super(TREEBIN, null, null, null); //设置Hash值为-2,表示一颗红黑树this.first = b;TreeNode<K,V> r = null;for (TreeNode<K,V> x = b, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (r == null) { //根节点的情况x.parent = null;x.red = false;r = x;}else {K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = r;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;r = balanceInsertion(r, x); // 与HashMap处理相同break;}}}}this.root = r;assert checkInvariants(root);
}
putTreeVal():往红黑树中插入值
final TreeNode<K,V> putTreeVal(int h, K k, V v) {// 前面的代码和HashMap的代码一样,就不赘述了Class<?> kc = null;boolean searched = false;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;if (p == null) {first = root = new TreeNode<K,V>(h, k, v, null, null);break;}else if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (pk != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.findTreeNode(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.findTreeNode(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {TreeNode<K,V> x, f = first;first = x = new TreeNode<K,V>(h, k, v, f, xp);if (f != null)f.prev = x;if (dir <= 0)xp.left = x;elsexp.right = x;if (!xp.red) //父节点是黑的,无需加锁,直接插入x.red = true;else {lockRoot(); //加写锁try {root = balanceInsertion(root, x);} finally {unlockRoot();}}break;}}assert checkInvariants(root);return null;
}
helpTransfer():多线程帮助扩容
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;
}
addCount():计算Map中的元素总数(put时+1,delete时-1)
private final void addCount(long x, int check) { //x:1;check:链表长度或者红黑树是2CounterCell[] as; long b, s;if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { //尝试直接往baseCount中加值// CounterCell数组不为空(说明有竞争) 或者 直接往baseCount中加值失败(cas失败)CounterCell a; long v; int m;boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 || // 数组为空(a = as[ThreadLocalRandom.getProbe() & m]) == null || //获取线程的随机数 & 数组长度求出对应线程的数组下标,as数组中对应下标的元素为null!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { //cas往as数组中对应位置加1fullAddCount(x, uncontended); //CAS往里加数组里加1return; //进入这个if虽然加了1,但是不会走后面的扩容逻辑了(有冲突时不执行扩容,没冲突且达到阈值时才扩容)}if (check <= 1)return;s = sumCount(); //算出当前map中元素个数}if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;while (s >= (long)(sc = sizeCtl) && (tab = table) != null && //大于阈值(sizeCtl)时扩容(n = tab.length) < MAXIMUM_CAPACITY) {int rs = resizeStamp(n);if (sc < 0) { // sc是负数说明正在扩容,与helpTransfer()方法逻辑相同if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0) //当满足这些条件时,表示扩容完毕了break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) //每有一个后续线程帮助扩容时,sc就+1transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2)) //注意,第一个线程执行扩容时,会把sc设置成负数并+2(初始值)transfer(tab, null);s = sumCount();}}
}
ThreadLocalRandom.getProbe()方法详解:关于 ConcurrentHashMap 1.8 中的线程探针哈希
fullAddCount():CAS往CounterCell数组中加值
//wasUncontended字段用来标识当前线程获取的probe通过计算后,在CounterCell数组中对应下标是否能加成功
private final void fullAddCount(long x, boolean wasUncontended) { //x:1;wasUncontended:falseint h;if ((h = ThreadLocalRandom.getProbe()) == 0) { //获取线程的hash值(多次调用值一样)ThreadLocalRandom.localInit(); //初始化h = ThreadLocalRandom.getProbe();wasUncontended = true;}boolean collide = false; // true时表示发生冲突,数组要执行扩容for (;;) { //自旋CounterCell[] as; CounterCell a; int n; long v;if ((as = counterCells) != null && (n = as.length) > 0) { // 数组不是空的,已经完成了初始化if ((a = as[(n - 1) & h]) == null) { //数组当前下标位置是空的if (cellsBusy == 0) { // Try to attach new CellCounterCell r = new CounterCell(x); // 初始化数组中对应位置的元素,且初始值为1if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { // 数组cas加锁boolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;if ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) { //再次判断rs[j] = r;created = true;}} finally { //释放锁cellsBusy = 0;}if (created) //创建成功break;continue; // 继续循环(用continue跳过了修改线程的probe值)} }collide = false;}else if (!wasUncontended) // false表示上一次cas+1的时候失败了wasUncontended = true; // 刷新状态为true,并修改线程probe的值(跳出if后)else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) //再尝试cas+1,成功则跳出循环,失败则修改线程probe的值break;else if (counterCells != as || n >= NCPU) //数组扩容后或者数组长度大于cpu核数时,不允许扩容collide = false; // At max size or staleelse if (!collide) //CAS失败,说明发生冲突,collide设置为true,下次循环过来collide 为true时,执行扩容collide = true;else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { //数组加锁,扩容try {if (counterCells == as) {// Expand table unless staleCounterCell[] rs = new CounterCell[n << 1]; //创建新数组,容量*2for (int i = 0; i < n; ++i)rs[i] = as[i]; //旧数组元素放新数组中counterCells = rs;}} finally {cellsBusy = 0;}collide = false;continue; // Retry with expanded table}h = ThreadLocalRandom.advanceProbe(h); //给线程生成一个新的Probe值(随机数)}else if (cellsBusy == 0 && counterCells == as && //cellsBusy标识数组是否被占用,0表示没有占用U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { //cas将cellsBusy改为1(加锁),保证只有一个线程能对cells数组初始化boolean init = false;try { // Initialize tableif (counterCells == as) {CounterCell[] rs = new CounterCell[2]; //初始化数组大小为2rs[h & 1] = new CounterCell(x); //对应位置直接+1counterCells = rs;init = true; //初始化完毕}} finally {cellsBusy = 0;}if (init) //初始化完毕,且计数也加了1,就跳出循环break;}else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x)) //如果其它情况都被其它线程占用,则尝试对baseCount加1break; // Fall back on using base}
}
sumCount():计算Map中所有元素总数
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount; //基础值if (as != null) {for (int i = 0; i < as.length; ++i) { //遍历CounterCell数组进行统计求和if ((a = as[i]) != null)sum += a.value;}}return sum;
}
resizeStamp():当返回值左移 RESIZE_STAMP_SHIFT 位时,一定是负数
private static int RESIZE_STAMP_BITS = 16;private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;//resizeStamp相当于把第int的第16位赋值为1(1左移15位是在第16位),然后在addCount方法中向左移动16位时,1到了符号位,所以变成负数了//RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS,所以只要 1 左移RESIZE_STAMP_BITS-1位,再左移RESIZE_STAMP_SHIFT位
//(共左移了31位,1到了第32位),1就被移到了符号位,成为了负数
static final int resizeStamp(int n) {return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
Integer.numberOfLeadingZeros(i) 方法:返回无符号整数 i 的最高非 0 位前面的 0 的个数,包括符号位在内;如果 i 为负数,这个方法将会返回 0
transfer():将旧数组元素转移到新数组中
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { //tab是旧数组,nextTab是新数组int n = tab.length, stride;if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) //计算步长,(n/8)/NCPU,最小值是16stride = MIN_TRANSFER_STRIDE; // subdivide rangeif (nextTab == null) { // 新数组为空,初始化try {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; //扩容,*2nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;transferIndex = n; //transferIndex:多线程下,数组从后往前遍历挨个元素转换,transferIndex 表示下个线程应该转换旧数组的哪个元素}int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); //ForwardingNode是个特殊的Node对象,hash值为MOVED(-1)boolean advance = true; //当前线程是否继续往前找未转移的元素boolean finishing = false; // 当前线程的扩容逻辑是否做完(只是当前线程)for (int i = 0, bound = 0;;) { Node<K,V> f; int fh;while (advance) {int nextIndex, nextBound; //nextIndex是跳过的右边界,nextBound是跳过的左边界,左闭右开//不越界的情况下,nextIndex - nextBound = stride(步长)if (--i >= bound || finishing) //倒着遍历advance = false;else if ((nextIndex = transferIndex) <= 0) { //旧数组已经转换到下标0的位置了i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) { //数组是从右往左遍历,如果越界(负数),下标就设置为0bound = nextBound;i = nextIndex - 1;advance = false;}}if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) {nextTable = null;table = nextTab; //转移到新的数组sizeCtl = (n << 1) - (n >>> 1); // *2*0.75return;}if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { //每有一个线程帮助扩容完,sc就-1if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)//这个逻辑相当于: sc != (resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2 , //(resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2 是第一个线程执行扩容时,sc 设置的初始值,之后每有一个线程帮忙扩容,就在 sc 的初始值上 + 1return; //当前线程扩容执行完毕// 当 sc == (resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2 时,会走到这儿,表示除了当前线程,其它所有帮助扩容的线程都执行完了finishing = advance = true; //表示所有线程扩容执行完毕i = n; // recheck before commit}}else if ((f = tabAt(tab, i)) == null) //数组对应位置是nulladvance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED) //数组对应位置已被其它线程处理advance = true; // 循环处理前一个位置else {synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;if (fh >= 0) { //数组中对应位置是链表// 链表在扩容时会分成高位和低位(和HashMap相同),假设单向链表最后一位是高位,然后往前推,反向遍历,runBit就指向链表节点第一次变成低位时的后一个高位节点// 即在原链表中,runBit指向的节点为头的单向链表,要么都是低位的,要么都是高位的int runBit = fh & n; //指向链表最后相同位的节点Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) { //遍历链表,找出runBit节点的位置int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) { //将runBit后的节点整个挪到新数组ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) { //遍历剩余节点,往新数组插int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0) //低位ln = new Node<K,V>(ph, pk, pv, ln); //头插法else //高位hn = new Node<K,V>(ph, pk, pv, hn);}setTabAt(nextTab, i, ln); //往新数组中设置值setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd); //往旧数组中设置fwdadvance = true;}else if (f instanceof TreeBin) { //如果数组中的元素是红黑树,与HashMap逻辑相同TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : //小于6,红黑树退化成链表(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}}}}}
}
ForwardingNode():构造方法,hash值为-1(MOVED)
ForwardingNode(Node<K,V>[] tab) {super(MOVED, null, null, null);this.nextTable = tab;
}
总结
JDK8中的ConcurrentHashMap是怎么保证并发安全的?
主要利用 Unsafe 操作 + synchronized 关键字。
Unsafe操作的使用主要负责并发安全的修改对象的属性或数组某个位置的值。synchronized主要负责在需要操作某个位置时进行加锁(该位置不为空),比如向某个位置的链表进行插入结点,向某个位置的红黑树插入结点。
JDK8中仍然有分段锁的思想,JDK8中数组的每一个位置都有一把锁。
当向 ConcurrentHashMap 中 put 一个 key,value 时,
-
首先根据
key计算对应的数组下标i,如果该位置没有元素,则通过自旋的方法去向该位置赋值。 -
如果该位置有元素,则
synchronized会加锁 -
加锁成功之后,在判断该元素的类型
a. 如果是链表节点则进行添加节点到链表中
b. 如果是红黑树则添加节点到红黑树 -
添加成功后,判断是否需要进行树化
-
addCount(),这个方法的意思是ConcurrentHashMap的元素个数加1,但是这个操作也是需要并发安全的,并且元素个数加1成功后,会继续判断是否要进行扩容,如果需要,则会进行扩容,所以这个方法很重要。 -
同时一个线程在
put时如果发现当前ConcurrentHashMap正在进行扩容则会去帮助扩容。
相关文章:

JDK8 ConcurrentHashMap源码分析
文章目录常量说明put() 方法putVal() 方法initTable():初始化数组treeifyBin():链表转红黑树tryPresize():初始化数组扩容TreeBin() 构造方法:生成红黑树putTreeVal():往红黑树中插入值helpTransfer():多线…...

前置知识-初值问题、欧拉法、改进欧拉法
1.1 初值问题 初值问题是科研、工程技术应用中最常见的一类问题, 一阶常微分方程的初值问题表述如下: 已知 u ( x ) u(x) u(x) 的起始点 ( x 0 , u 0 ) \left(x_0, u_0\right)...

睡眠影响寿命,这几个睡眠习惯赶紧改掉!
我们知道,现在睡眠不足已经成为普遍问题,但你知道睡眠的时长会影响寿命吗?熬夜对身体不好,已是老生常谈。但睡得过早,也可能影响寿命!2021年《睡眠医学》杂志一项针对21个国家11万名参与者的研究中发现&…...

Linux逻辑卷管理器(PV、VG、LV、PE)
目录 PV阶段 VG阶段 LV阶段 文件系统阶段 逆向操作(删除LVM) 逻辑卷管理器(Logical Volume Manager),简称LVM LVM的做法是将几个物理的分区(或磁盘)通过软件组合成为一块看起来时独立的大…...
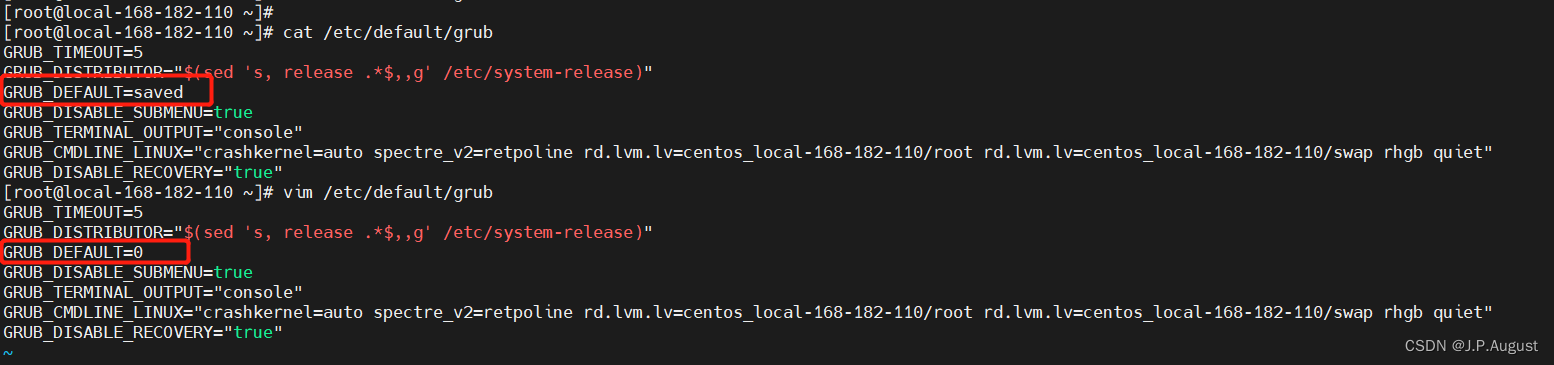
Centos7 内核升级
一、背景 在 CentOS 使用过程中,高版本的应用环境可能需要更高版本的内核才能支持,所以难免需要升级内核,所以下面将介绍yum和rpm两种升级内核方式。 关于内核种类: kernel-ml——kernel-ml 中的ml是英文【 mainline stable 】的缩写&…...
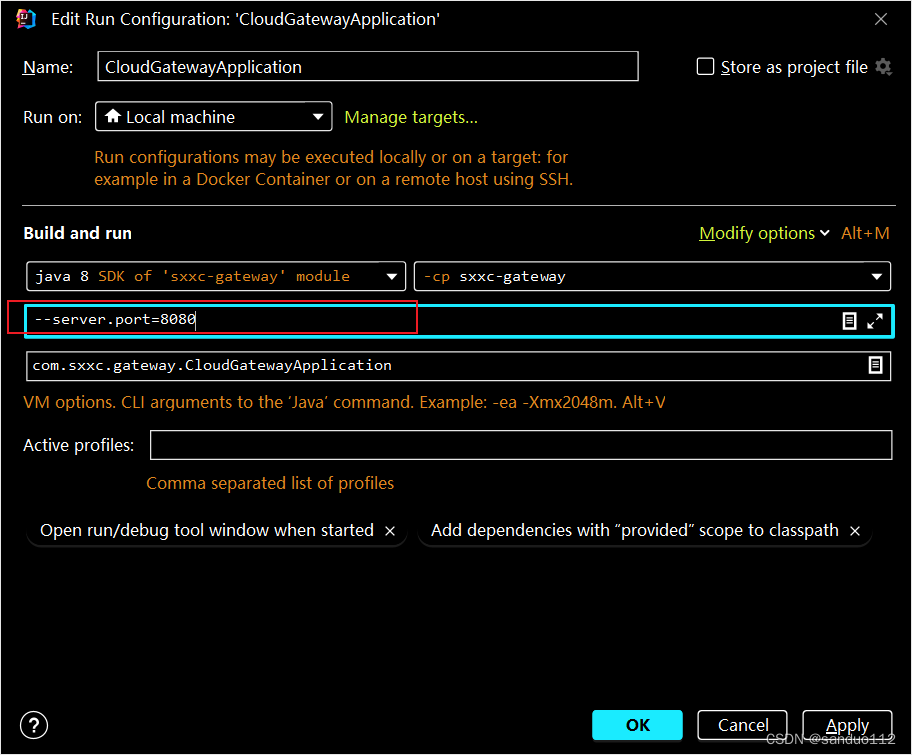
SpringBoot 启动配置文件加载和参数配置修改问题
SpringBoot 配置文件修正和参数覆盖SpringBoot 配置文件加载和参数覆盖1、SpringBoot 配置文件加载1.1、修改application.properties的参数几种方式1.2、方法一:直接CMD1.3、方法二:系统变量配置1.4、方法三:程序运行配置1.5、方法四…...
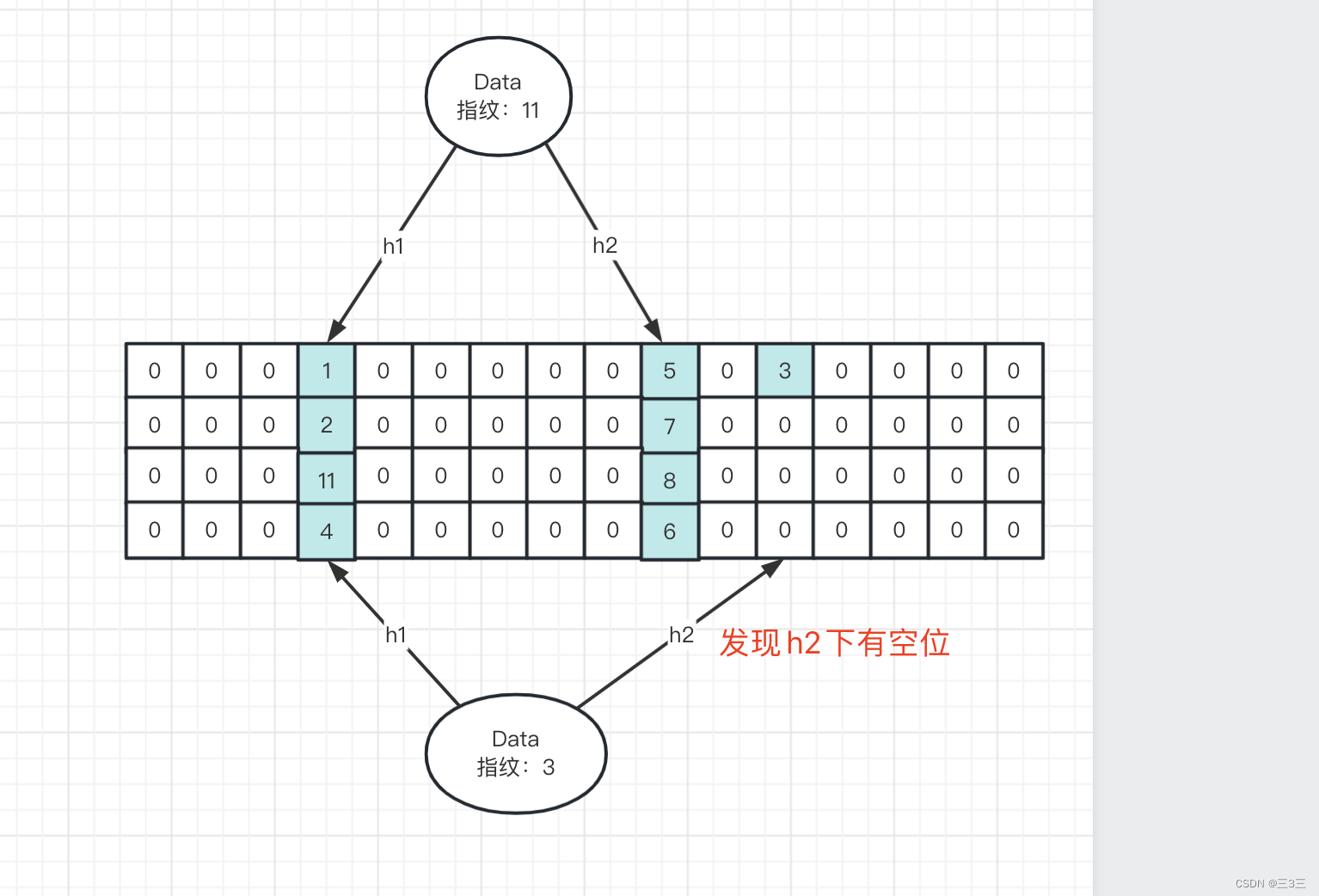
布隆过滤器和布谷鸟过滤器详解
今天和大家分享下布隆过滤器和布谷鸟过滤器 一.布隆过滤器 1.简单介绍 布隆过滤器是用于检索一个元素是否在一个集合中的算法,是一种用空间换时间的查询算法。 2.实现原理 布隆过滤器的存储结构是一个bitmap结构,初始值都是0,如下图所示&am…...
图形图像底层渲染原理分析)
WebGIS前端框架(openlayers,mapbox,leaflet)图形图像底层渲染原理分析
学了这么多的框架,做了这么多的项目,你是否清楚你使用的GIS框架(mapbox,open layers,cesium,leaflet)底层到底是什么原理?是否清楚哪些所谓的地图影像,矢量图形,图标,图像动画等是如何渲染到网页上的?这篇文章就大家解读一下WebGIS的底层原理。 首先说说历史,有时…...
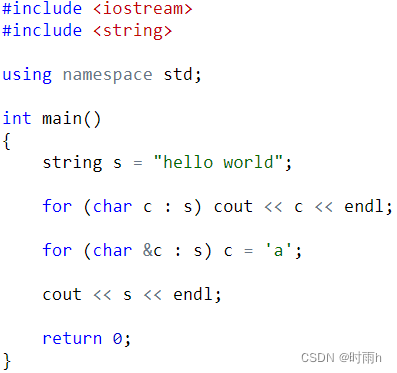
AcWing语法基础课笔记 第五章 C++中的字符串
第五章 C中的字符串 字符串是计算机与人类沟通的重要手段。 ——闫学灿 字符与整数的联系——ASCII码 每个常用字符都对应一个-128~127的数字,二者之间可以相互转化: 常用ASCII值:’A’-‘Z’ 是65~90,’a’-‘z’…...

抓包工具Charles(一)-下载安装与设置
无论是在测试、开发工作中,抓包都是很重要、很常用的技能。Charles作为一款抓包工具,能够满足大部分的工作需求。 文章目录一、下载地址二、安装三、安装根证书(电脑)四、设置五、抓包附录:[零基础入门接口功能测试教程…...
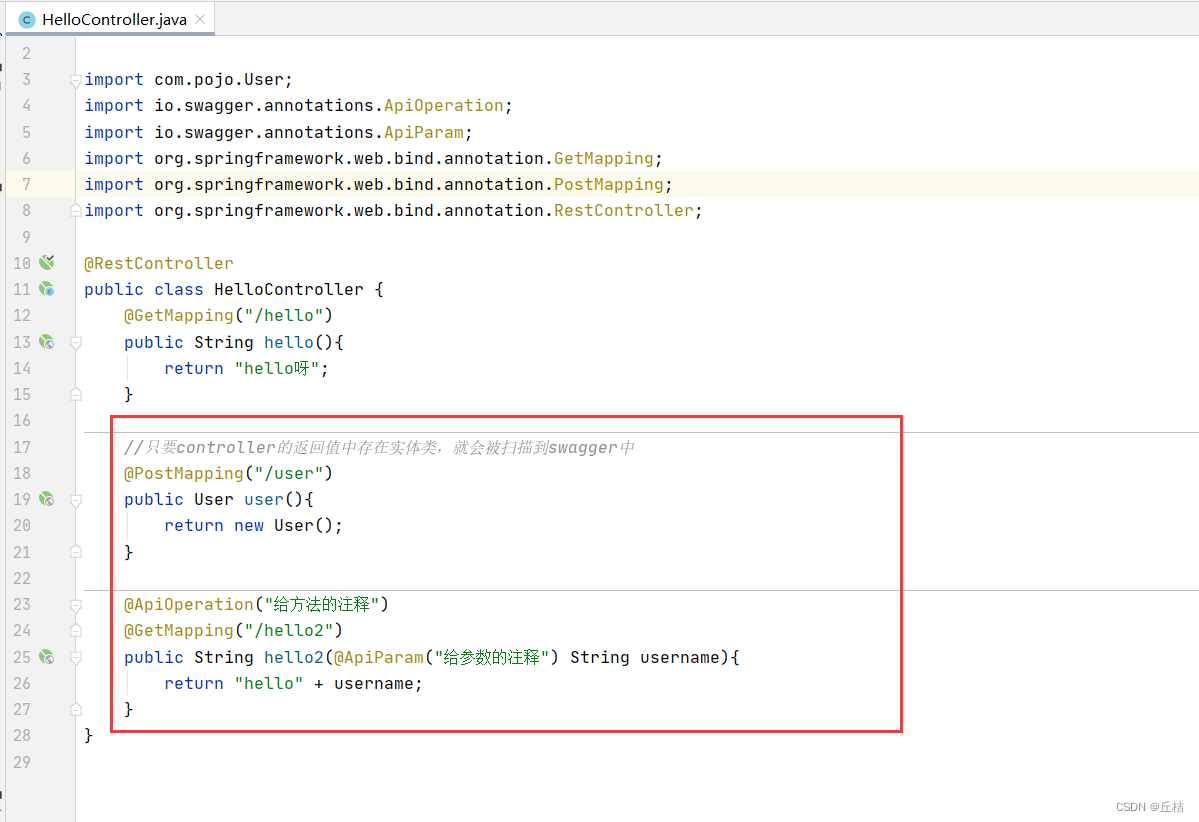
SpringBoot09:Swagger
什么是Swagger? ①是一个API框架 ②可以在线自动生成 RestFul 风格的API文档,实现API文档和API定义同步更新 ③可以直接运行、在线测试 API 接口 ④支持多种语言(Java、PHP等) 官网:API Documentation & Desi…...

Git 常用命令
笔记-git命令1、名词2、基本操作3、分支操作1、名词 master: 默认开发分支origin: 默认远程版本库Index / Stage: 暂存区Workspace: 工作区Repository: 仓库区 (或本地仓库)Remote: 远程仓库 2、基本操作 配置级别 -local (默认,高级优先…...

查看jdk安装路径,在windows上实现多个java jdk的共存解决办法,安装java19后终端乱码的解决
查看jdk安装路径, 在windows上实现多个java jdk的共存解决办法, 安装java19后终端乱码的解决 目录 一、查看jdk(java开发工具包)安装路径的方法 二、在windows上实现多个java jdk的共存 (1)、安装好多…...

链表数据结构
用途: 链表是一种用于计算机中存储与组织数据的结构,链表将数据以节点的形式串联起来,其存储的容量大小可以动态伸缩。 结构: typedef struct {int data; /*当前节点的数据*/node *next;/*下一个节点的指针*/node *last;/*上一个…...
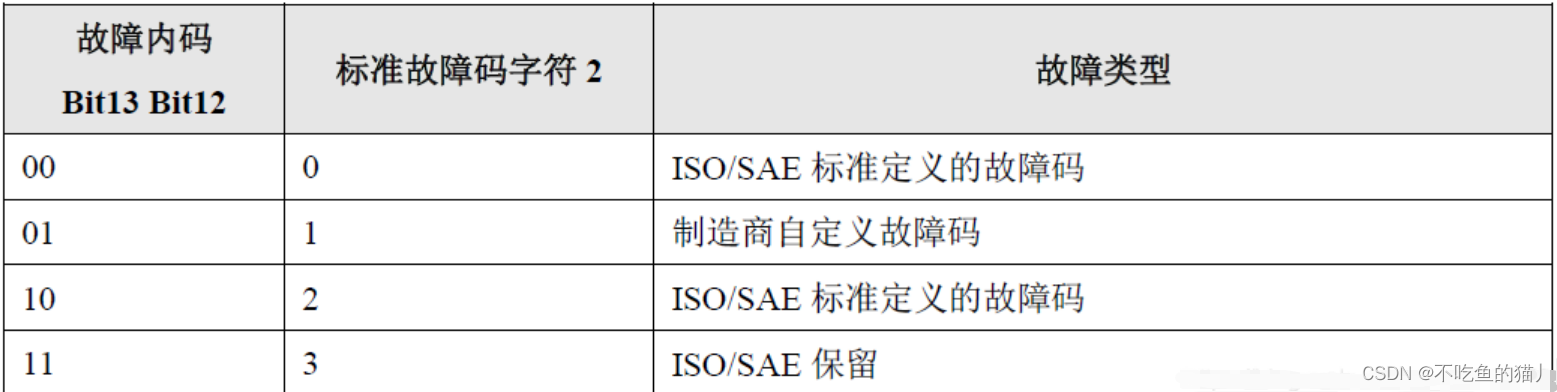
汽车DTC故障内码与标准故障码的解析与转换
目录 一、故障内码与标准故障码的解析 (1)故障内码的信息格式与解析 (2)故障内码中DTC状态的解析 (3)故障内码与标准故障码之间的对应关系 二、故障内码与标准故障码的转换代码 一、故障内码与标准故障…...
零基础学习测试还是开发?
软件测试作为IT行业的刚需职位,其实是非常适合0基础的小白同学加入学习的但是具体选择测试还是开发还是要看你个人的兴趣爱好以及学习能力,对哪个感兴趣,哪个能学的会就选择哪个就可以了 平时说起程序员印象中大都是做Java、做前端、做后端&…...
如何加入new bing候补名单
如何加入new bing候补名单 我们都知道现在最新版edges中已经提示我们可以加入new bing候补名单,但国内环境下无法正常加入new bing候补名单,这篇文章讲告诉你如何绕过限制加入new bing候补名单 下载配置 HeaderEditor 插件 下载地址microsoftedge.mic…...
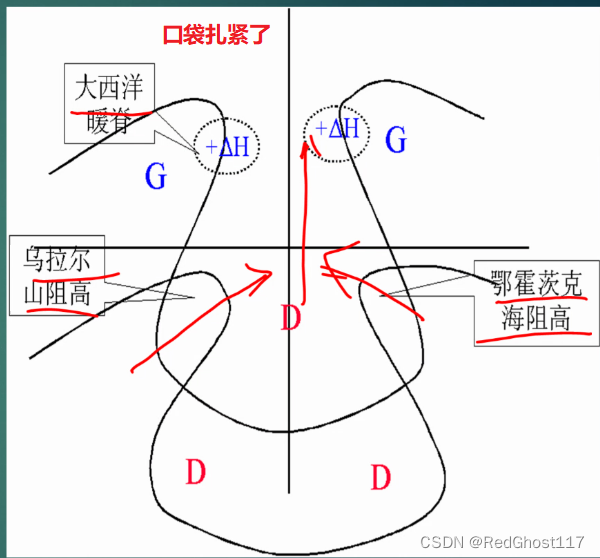
中国天气——西风带环流和寒潮
中国天气——西风带环流和寒潮 一. 西风环流概述 1. 概念 西风带:中高纬度地区平均水平环流在对流层盛行西风,称之为西风带西风带波动:西风带围绕极涡沿纬圈运动,平均而言表现为冬季三槽三脊,夏季四槽四脊ÿ…...

2022黑马Redis跟学笔记.实战篇(四)
2022黑马Redis跟学笔记.实战篇 四4.3.秒杀优惠券功能4.3.1.秒杀优惠券的基本实现一、优惠卷秒杀1.1 全局唯一ID1.2 Redis实现全局唯一Id1.3 添加优惠卷1.4 实现秒杀下单4.3.2.超卖问题4.3.3.基于乐观锁解决超卖问题1. 悲观锁2. 乐观锁3. 乐观锁解决超卖问题4.4 秒杀的一人一单限…...
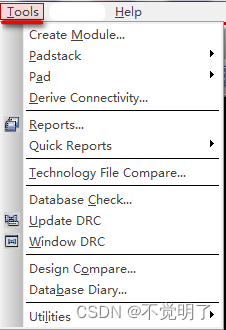
Allegro中如何删除多余D码操作指导
Allegro中如何删除多余D码操作指导 用Allegro做PCB设计的时候,在最后输出生产文件的时候,必须清除多余的D码,不让多余的D码出现在D码文件中,类似下图 如何清除多余D码,具体操作如下 点击Tools点击Padstack...

)
别再手动折腾了!用Stack Builder一键搞定PostGIS 2.1 for PostgreSQL 9.2 (Windows 64位)
告别繁琐配置:用Stack Builder轻松部署PostGIS空间数据库 在Windows环境下配置PostgreSQL的空间扩展PostGIS,传统方式往往需要手动下载安装包、配置环境变量、执行SQL脚本等一系列操作。对于刚接触空间数据库的开发者来说,这个过程既耗时又容…...

5分钟快速上手:智能象棋AI助手的完整使用教程
5分钟快速上手:智能象棋AI助手的完整使用教程 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi Vin象棋是一款基于YOLOv5深度学习的开源免费中国…...

DSP+FPGA异构架构在实时信号处理中的应用与优化
1. 实时信号处理系统架构解析在工业自动化、医疗影像和通信系统中,对信号处理实时性要求极高的场景比比皆是。传统纯软件方案往往受限于CPU的串行处理特性,难以满足严格的时序要求。这正是DSPFPGA异构架构大显身手的领域——我曾参与过多个类似项目&…...

eFuse 的核心作用
它触及了设备安全性的核心机制——eFuse。 简而言之:一台已经烧录(blown)了 eFuse 的设备,其安全机制与未烧录 eFuse 的设备有本质区别,你之前在非 eFuse 设备上成功的代码修改(强制 check_key 返回 0)很可能在烧录了 eFuse 的设备上无效。 以下是详细解释: eFuse 的…...

Docker Hub命令行工具hub-tool:镜像仓库自动化管理的终极利器
1. 项目概述:一个被低估的Docker Hub命令行利器 如果你日常工作中需要和Docker Hub打交道,无论是管理个人镜像、处理团队仓库,还是需要自动化镜像的推送、拉取和清理,那么你很可能已经受够了在浏览器和命令行之间反复横跳的繁琐。…...
)
Springboot+Vue3|毕业设计美食分享平台(源码)
目录 一、项目背景 二、技术介绍 三、功能介绍 四、代码设计 五、系统实现 一、项目背景 在移动互联网与社交媒体深度融合的时代背景下,美食已不再仅仅满足人们的饱腹之需,更演变为一种重要的社交媒介与文化符号。打开小红书、抖音等热门应用&…...

【信息科学与工程学】【财务管理】 第二十三篇 ICT行业商业逻辑分析框架03
136. 硅光子集成芯片的激光器外延片 行业代码 行业名称 行业级别 产品/服务 商业逻辑核心 投资者类型与代表公司/机构 外部关系类型与关联公司 销售与买卖经营 供应链经营 利益/利润设计/资源绑定/信息宣传 分销商/代理商/关系节点 销售策略、打法与复杂关系网络 3…...

如何为Unity游戏添加多语言支持:XUnity.AutoTranslator完整指南
如何为Unity游戏添加多语言支持:XUnity.AutoTranslator完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而无法享受心爱的Unity游戏?是否想要为你的…...

终极视频字幕提取指南:如何用本地OCR工具高效提取87种语言硬字幕
终极视频字幕提取指南:如何用本地OCR工具高效提取87种语言硬字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...