19 贝叶斯线性回归
文章目录
- 19 贝叶斯线性回归
- 19.1 频率派线性回归
- 19.2 Bayesian Method
- 19.2.1 Inference问题
- 19.2.2 Prediction问题
19 贝叶斯线性回归
19.1 频率派线性回归
数据与模型:
-
样本:
{ ( x i , y i ) } i = 1 N , x i ∈ R p , y i ∈ R p {\lbrace (x_i, y_i) \rbrace}_{i=1}^{N}, \quad x_i \in {\mathbb R}^p, \quad y_i \in {\mathbb R}^p {(xi,yi)}i=1N,xi∈Rp,yi∈RpX = ( x 1 x 2 … x N ) T = ( x 1 T x 2 T … x N T ) = ( x 11 x 12 … x 1 N x 21 x 22 … x 2 N … x N 1 x N 2 … x N N ) , Y = ( y 1 T y 2 T … y N T ) X = (x_1 \ x_2 \ \dots \ x_N )^T = \begin{pmatrix} x_1^T \\ x_2^T \\ \dots \\ x_N^T \end{pmatrix} = \begin{pmatrix} x_{11} & x_{12} & \dots & x_{1N} \\ x_{21} & x_{22} & \dots & x_{2N} \\ \dots \\ x_{N1} & x_{N2} & \dots & x_{NN} \\ \end{pmatrix} , Y = \begin{pmatrix} y_1^T \\ y_2^T \\ \dots \\ y_N^T \end{pmatrix} X=(x1 x2 … xN)T= x1Tx2T…xNT = x11x21…xN1x12x22xN2………x1Nx2NxNN ,Y= y1Ty2T…yNT
-
回归方程:
f ( x ) = w T x = x T w , y = f ( x ) + ε ⏟ n o i s e , ε ∽ N ( 0 , σ 2 ) f(x) = w^T x = x^T w, \quad y = f(x) + \underbrace{\varepsilon}_{noise}, \quad \varepsilon \backsim N(0,\sigma^2) f(x)=wTx=xTw,y=f(x)+noise ε,ε∽N(0,σ2)
其中 x , y , ε x, y, \varepsilon x,y,ε都是随机变量,假设 w w w用于表示参数
在频率派的线性回归中,我们是通过假设 w w w表示一个未知的常量,转化为优化问题进行求解。我们将这种方法称为点估计,在过去我们学习过了两种方法:
-
L S E ⟸ M L E ( noise is Gaussian ) LSE \impliedby MLE(\text{noise is Gaussian}) LSE⟸MLE(noise is Gaussian)——极大似然估计:
w M L E = a r g max w P ( D a t a ∣ w ) w_{MLE} = arg\max_{w} P(Data|w) wMLE=argwmaxP(Data∣w) -
R e g u l a r i z e d L S E ⟸ M A P ( noise is Gaussian ) Regularized \ LSE \impliedby MAP(\text{noise is Gaussian}) Regularized LSE⟸MAP(noise is Gaussian)——最大后验估计:
w M A P = a r g max w P ( w ∣ D a t a ) ⏟ ∝ P ( D a t a ∣ w ) ⋅ P ( w ) = a r g max w P ( D a t a ∣ w ) ⋅ P ( w ) w_{MAP} = arg\max_{w} \underbrace{P(w|Data)}_{\propto P(Data|w) \cdot P(w)} = arg\max_{w} P(Data|w) \cdot P(w) wMAP=argwmax∝P(Data∣w)⋅P(w) P(w∣Data)=argwmaxP(Data∣w)⋅P(w)
其中若 P ( w ) P(w) P(w)表示为Gaussian Dist则为岭回归(Ridge),若 P ( w ) P(w) P(w)表示为Laplace则为Lasso
在本章我们的目标是通过Bayesian Method解决线性回归问题:
- 假定 w w w是一个随机变量
- 求出后验 P ( w ∣ D a t a ) P(w|Data) P(w∣Data)
19.2 Bayesian Method
数据与模型:
-
样本数据:
{ ( x i , y i ) } i = 1 N , x i ∈ R p , y i ∈ R p {\lbrace (x_i, y_i) \rbrace}_{i=1}^{N}, \quad x_i \in {\mathbb R}^p, \quad y_i \in {\mathbb R}^p {(xi,yi)}i=1N,xi∈Rp,yi∈RpX = ( x 1 x 2 … x N ) T = ( x 1 T x 2 T … x N T ) = ( x 11 x 12 … x 1 N x 21 x 22 … x 2 N … x N 1 x N 2 … x N N ) , Y = ( y 1 T y 2 T … y N T ) X = (x_1 \ x_2 \ \dots \ x_N )^T = \begin{pmatrix} x_1^T \\ x_2^T \\ \dots \\ x_N^T \end{pmatrix} = \begin{pmatrix} x_{11} & x_{12} & \dots & x_{1N} \\ x_{21} & x_{22} & \dots & x_{2N} \\ \dots \\ x_{N1} & x_{N2} & \dots & x_{NN} \\ \end{pmatrix} , Y = \begin{pmatrix} y_1^T \\ y_2^T \\ \dots \\ y_N^T \end{pmatrix} X=(x1 x2 … xN)T= x1Tx2T…xNT = x11x21…xN1x12x22xN2………x1Nx2NxNN ,Y= y1Ty2T…yNT
-
模型:
f ( x ) = w T x = x T w , y = f ( x ) + ε ⏟ n o i s e , ε ∽ N ( 0 , σ 2 ) f(x) = w^T x = x^T w, \quad y = f(x) + \underbrace{\varepsilon}_{noise}, \quad \varepsilon \backsim N(0,\sigma^2) f(x)=wTx=xTw,y=f(x)+noise ε,ε∽N(0,σ2)
其中 x , y , ε , w x, y, \varepsilon, w x,y,ε,w都是随机变量,假设用于表示参数 -
问题表示:
{ I n f e r e n c e : p o s t e r i o r ( w ) P r e d i c t i o n : x ∗ → y ∗ \begin{cases} Inference: posterior(w) \\ Prediction: x^* \rightarrow y^* \end{cases} {Inference:posterior(w)Prediction:x∗→y∗
19.2.1 Inference问题
Inference问题就是求解后验: P ( w ∣ D a t a ) P(w|Data) P(w∣Data)。接下来进行逐步的推导:
P ( w ∣ D a t a ) = P ( w ∣ X , Y ) = P ( w , Y ∣ X ) P ( Y ∣ X ) = P ( Y ∣ w , X ) ⏞ l i k e l i h o o d ⋅ P ( w ∣ X ) ⏞ p r i o r ∫ P ( Y ∣ w , X ) ⋅ P ( w ∣ X ) d w \begin{align} P(w|Data) = P(w|X, Y) = \frac{P(w, Y| X)}{P(Y|X)} = \frac{\overbrace{P(Y|w, X)}^{likelihood} \cdot \overbrace{P(w|X)}^{prior}}{\int P(Y|w, X) \cdot P(w|X) {\rm d}w} \end{align} P(w∣Data)=P(w∣X,Y)=P(Y∣X)P(w,Y∣X)=∫P(Y∣w,X)⋅P(w∣X)dwP(Y∣w,X) likelihood⋅P(w∣X) prior
将后验拆解开之后,我们只需要分开求解likelihood和prior:
-
求解likelihood:
P ( Y ∣ w , X ) = ∏ i = 1 N P ( y i ∣ w , x i ) = ∏ i = 1 N N ( y i ∣ w T x i , σ 2 ) P(Y|w, X) = \prod_{i=1}^{N} P(y_i| w, x_i) = \prod_{i=1}^{N} N(y_i| w^T x_i, \sigma^2) P(Y∣w,X)=i=1∏NP(yi∣w,xi)=i=1∏NN(yi∣wTxi,σ2) -
假设prior:
p ( w ∣ X ) = N ( 0 , Σ p ) p(w|X) = N(0, \Sigma_p) p(w∣X)=N(0,Σp)
所以求解后验可以写为:
P ( w ∣ D a t a ) ∝ P ( Y ∣ w , X ) ⋅ P ( w ∣ X ) ∝ ∏ i = 1 N N ( y i ∣ w T x i , σ 2 ) ⋅ N ( 0 , Σ p ) \begin{align} P(w|Data) &\propto P(Y|w,X) \cdot P(w|X) \\ &\propto \prod_{i=1}^{N} N(y_i| w^T x_i, \sigma^2) \cdot N(0, \Sigma_p) \end{align} P(w∣Data)∝P(Y∣w,X)⋅P(w∣X)∝i=1∏NN(yi∣wTxi,σ2)⋅N(0,Σp)
我们先将likelihood进行一个变换:
P ( Y ∣ w , X ) = ∏ i = 1 N N ( y i ∣ w T x i , σ 2 ) = ∏ i = 1 N 1 ( 2 π ) 1 2 σ exp { − 1 2 σ 2 ( y i − w T x i ) 2 } = 1 ( 2 π ) N 2 σ N exp { − 1 2 σ 2 ∑ i = 1 N ( y i − w T x i ) 2 } = 1 ( 2 π ) N 2 σ N ⏟ ∣ Σ ∣ 1 2 exp { − 1 2 ( Y − X w ) ⏟ x − μ T σ − 2 I ⏟ Σ − 1 ( Y − X w ) } = N ( X w , σ − 2 I ) \begin{align} P(Y|w, X) &= \prod_{i=1}^{N} N(y_i| w^T x_i, \sigma^2) \\ &= \prod_{i=1}^{N} \frac{ 1 }{ {(2 \pi)}^\frac{1}{2} \sigma } \exp{\lbrace -\frac{1}{2\sigma^2} {( y_i - w^T x_i )}^2 \rbrace} \\ &= \frac{ 1 }{ {(2 \pi)}^\frac{N}{2} \sigma^N } \exp{\lbrace -\frac{1}{2\sigma^2} \sum_{i=1}^N {( y_i - w^T x_i )}^2 \rbrace} \\ &= \frac{ 1 }{ {(2 \pi)}^\frac{N}{2} \underbrace{\sigma^N}_{{|\Sigma|}^\frac{1}{2}} } \exp{\lbrace -\frac{1}{2} {\underbrace{(Y-Xw)}_{x-\mu}}^T \underbrace{\sigma^{-2} I}_{\Sigma^{-1}} {(Y-Xw)} \rbrace} \\ &= N(Xw, \sigma^{-2} I) \end{align} P(Y∣w,X)=i=1∏NN(yi∣wTxi,σ2)=i=1∏N(2π)21σ1exp{−2σ21(yi−wTxi)2}=(2π)2NσN1exp{−2σ21i=1∑N(yi−wTxi)2}=(2π)2N∣Σ∣21 σN1exp{−21x−μ (Y−Xw)TΣ−1 σ−2I(Y−Xw)}=N(Xw,σ−2I)
通过上文的likelihood我们可以求解:
P ( w ∣ D a t a ) ∝ P ( Y ∣ w , X ) ⋅ P ( w ∣ X ) = N ( X w , σ − 2 I ) ) ⋅ N ( 0 , Σ p ) ∝ exp { − 1 2 ( Y − X w ) T σ − 2 I ( Y − X w ) } ⋅ exp { − 1 2 w T Σ p − 1 w } = exp { − 1 2 ( Y − X w ) T σ − 2 I ( Y − X w ) − 1 2 w T Σ p − 1 w } = exp { − 1 2 ( Y T Y − 2 Y T X w + w T X T X w ) − 1 2 w T Σ p − 1 w } \begin{align} P(w|Data) &\propto P(Y|w,X) \cdot P(w|X) = N(Xw, \sigma^{-2} I)) \cdot N(0, \Sigma_p) \\ &\propto \exp{\lbrace -\frac{1}{2} {{(Y-Xw)}}^T {\sigma^{-2} I} {(Y-Xw)} \rbrace} \cdot \exp{\lbrace -\frac{1}{2} w^T \Sigma_p^{-1} w \rbrace} \\ &= \exp{\lbrace -\frac{1}{2} {{(Y-Xw)}}^T {\sigma^{-2} I} {(Y-Xw)} -\frac{1}{2} w^T \Sigma_p^{-1} w \rbrace} \\ &= \exp{\lbrace -\frac{1}{2} {( Y^T Y - 2Y^T X w + w^T X^T X w )} -\frac{1}{2} w^T \Sigma_p^{-1} w \rbrace} \\ \end{align} P(w∣Data)∝P(Y∣w,X)⋅P(w∣X)=N(Xw,σ−2I))⋅N(0,Σp)∝exp{−21(Y−Xw)Tσ−2I(Y−Xw)}⋅exp{−21wTΣp−1w}=exp{−21(Y−Xw)Tσ−2I(Y−Xw)−21wTΣp−1w}=exp{−21(YTY−2YTXw+wTXTXw)−21wTΣp−1w}
引入配方法:
若将标准的高斯分布可以得到二次项和一次项:
p ( x ) ∝ exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } = exp { − 1 2 ( x T Σ − 1 x − x T Σ − 1 μ ⏟ 1 × 1 − μ T Σ − 1 x ⏟ 1 × 1 + μ T Σ − 1 μ ) } = exp { − 1 2 ( x T Σ − 1 x − 2 μ T Σ − 1 x + μ T Σ − 1 μ ⏟ 与 x 无关 ) } ∝ exp { − 1 2 x T Σ − 1 x ⏟ 二次项 − μ T Σ − 1 x ⏟ 一次项 } \begin{align} p(x) &\propto \exp{\lbrace -\frac{1}{2}{(x-\mu)}^T \Sigma^{-1} (x-\mu) \rbrace} \\ &= \exp{\lbrace -\frac{1}{2} (x^T \Sigma^{-1} x - \underbrace{x^T \Sigma^{-1} \mu}_{1 \times 1} - \underbrace{\mu^T \Sigma^{-1} x}_{1 \times 1} + \mu^T \Sigma^{-1} \mu) \rbrace} \\ &= \exp{\lbrace -\frac{1}{2} (x^T \Sigma^{-1} x - 2 \mu^T \Sigma^{-1} x + \underbrace{\mu^T \Sigma^{-1} \mu}_{与x无关}) \rbrace} \\ &\propto \exp{\lbrace \underbrace{-\frac{1}{2} x^T \Sigma^{-1} x}_{二次项} - \underbrace{\mu^T \Sigma^{-1} x}_{一次项} \rbrace} \\ \end{align} p(x)∝exp{−21(x−μ)TΣ−1(x−μ)}=exp{−21(xTΣ−1x−1×1 xTΣ−1μ−1×1 μTΣ−1x+μTΣ−1μ)}=exp{−21(xTΣ−1x−2μTΣ−1x+与x无关 μTΣ−1μ)}∝exp{二次项 −21xTΣ−1x−一次项 μTΣ−1x}
我们可以通过二次项和一次项求出均值和方差
让我们用配方法,取出 P ( w ∣ D a t a ) P(w|Data) P(w∣Data)的二次项和一次项,假设 P ( w ∣ D a t a ) P(w|Data) P(w∣Data)的均值和方差表示为 μ w , Σ w \mu_w, \Sigma_w μw,Σw:
{ 二次项: − 1 2 σ 2 w T X T X w − 1 2 w T Σ p − 1 w = − 1 2 ( w T ( σ − 2 X T X + Σ p − 1 ) w ) ⏟ − 1 2 x T Σ w − 1 x 一次项: σ − 2 Y T X w ⏟ μ T Σ w − 1 x ⟹ { Σ w − 1 = ( σ − 2 X T X + Σ p − 1 ) μ T Σ w − 1 = σ − 2 Y T X \begin{align} &\begin{cases} \text{二次项:} -\frac{1}{2 \sigma^2} w^T X^T X w - \frac{1}{2} w^T \Sigma_p^{-1} w = \underbrace{ -\frac{1}{2} {(w^T {(\sigma^{-2} X^T X + \Sigma_p^{-1})} w)}}_{-\frac{1}{2} x^T \Sigma_w^{-1} x} \\ \text{一次项:} \underbrace{\sigma^{-2} Y^T X w}_{\mu^T \Sigma_w^{-1} x} \end{cases} \\ \implies &\begin{cases} \Sigma_w^{-1} = {(\sigma^{-2} X^T X + \Sigma_p^{-1})} \\ \mu^T \Sigma_w^{-1} = \sigma^{-2} Y^T X \end{cases} \end{align} ⟹⎩ ⎨ ⎧二次项:−2σ21wTXTXw−21wTΣp−1w=−21xTΣw−1x −21(wT(σ−2XTX+Σp−1)w)一次项:μTΣw−1x σ−2YTXw{Σw−1=(σ−2XTX+Σp−1)μTΣw−1=σ−2YTX
通过上文的方程可以简单求解出均值和方差:
{ Σ w = ( σ − 2 X T X + Σ p − 1 ) − 1 μ T = σ − 4 X T X Y T X + σ − 2 Σ p − 1 Y T X \begin{cases} \Sigma_w = {(\sigma^{-2} X^T X + \Sigma_p^{-1})}^{-1} \\ \mu^T = \sigma^{-4} X^T X Y^T X + \sigma^{-2} \Sigma_p^{-1} Y^T X \end{cases} {Σw=(σ−2XTX+Σp−1)−1μT=σ−4XTXYTX+σ−2Σp−1YTX
19.2.2 Prediction问题
Prediction问题是假设已有数据为 x ∗ x^* x∗,要求在 y ∗ y^* y∗的条件下的概率分布。
我们的条件有:
{ f ( x ) = x T w w ∽ N ( μ w , Σ w ) \begin{cases} f(x) = x^T w \\ w \backsim N(\mu_w, \Sigma_w) \end{cases} {f(x)=xTww∽N(μw,Σw)
此时我们已知 f ( x ∗ ) = x ∗ T w f(x^*) = {x^*}^T w f(x∗)=x∗Tw,可以根据参数的分布得到 P ( x ∗ T w ) P({x^*}^T w) P(x∗Tw):
w ∽ N ( μ w , Σ w ) ⟹ x ∗ T w ∽ N ( x ∗ T μ w , x ∗ T Σ w x ∗ ) \begin{align} & w \backsim N(\mu_w, \Sigma_w) \\ \implies & {x^*}^T w \backsim N({x^*}^T \mu_w, {x^*}^T \Sigma_w x^*) \end{align} ⟹w∽N(μw,Σw)x∗Tw∽N(x∗Tμw,x∗TΣwx∗)
实际情况是我们要求解 y = f ( x ∗ ) + ε , ε ∽ N ( 0 , σ 2 ) y = f(x^*) + \varepsilon, \quad \varepsilon \backsim N(0, \sigma^2) y=f(x∗)+ε,ε∽N(0,σ2),也就是求解分布 P ( y ∗ ∣ D a t a , x ∗ ) P(y^*| Data, x^*) P(y∗∣Data,x∗):
{ y = x ∗ T w + ε , ε ∽ N ( 0 , σ 2 ) x ∗ T w ∽ N ( x ∗ T μ w , x ∗ T Σ w x ∗ ) ⟹ P ( y ∗ ∣ D a t a , x ∗ ) = N ( x ∗ T μ w , x ∗ T Σ w x ∗ + σ 2 ) \begin{align} &\begin{cases} y = {x^*}^T w + \varepsilon, \quad \varepsilon \backsim N(0, \sigma^2) \\ {x^*}^T w \backsim N({x^*}^T \mu_w, {x^*}^T \Sigma_w x^*) \end{cases} \\ \implies & P(y^*|Data, x^*) = N({x^*}^T \mu_w, {x^*}^T \Sigma_w x^* + \sigma^2) \end{align} ⟹{y=x∗Tw+ε,ε∽N(0,σ2)x∗Tw∽N(x∗Tμw,x∗TΣwx∗)P(y∗∣Data,x∗)=N(x∗Tμw,x∗TΣwx∗+σ2)
相关文章:

19 贝叶斯线性回归
文章目录 19 贝叶斯线性回归19.1 频率派线性回归19.2 Bayesian Method19.2.1 Inference问题19.2.2 Prediction问题 19 贝叶斯线性回归 19.1 频率派线性回归 数据与模型: 样本: { ( x i , y i ) } i 1 N , x i ∈ R p , y i ∈ R p {\lbrace (x_i, y_…...
第七十天学习记录:高等数学:微分(宋浩板书)
微分的定义 基本微分公式与法则 复合函数的微分 微分的几何意义 微分在近似计算中应用 sin(xy) sin(x)cos(y) cos(x)sin(y)可以用三角形的几何图形来进行证明。 假设在一个单位圆上,点A(x,y)的坐标为(x,y),点B(x’, y’)的坐标为(x’, y’)。则以两点…...

Jmeter
目录 一、jmeter 安装 二、jmeter 介绍 1、jmeter是什么? 2、jmeter 用来做什么? 3、优点 4、缺点 5、jmeter 目录介绍 ①_bin 目录介绍 ② docs 目录 — — 接口文档目录 ③ extras目录 — — 扩展插件目录 ④ lib 目录 — — 所用到的插件目录 ⑤ lic…...

Flutter 学习 之 时间转换工具类
Flutter 学习之时间转换工具类 在 Flutter 应用程序开发中,处理时间戳是非常常见的需求。我们通常需要将时间戳转换为人类可读的日期时间格式。为了实现这一点,我们可以创建一个时间转换工具类。 实现方法 以下是一个简单的时间转换工具类的示例&…...
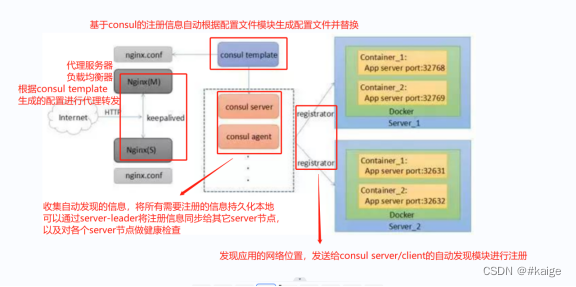
docker consul
docker consul的容器服务更新与发现 服务注册与发现是微服务架构中不可或缺的重要组件,起始服务都是单节点的,不保障高可用性,也不考虑服务的承载压力,服务之间调用单纯的通过接口访问的,直到后来出现多个节点的分布式…...
全志V3S嵌入式驱动开发(开发环境再升级)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 前面我们陆陆续续开发了差不多有10个驱动,涉及到网口、串口、音频和视频等几个方面。但是整个开发的效率还是比较低的。每次开发调试的…...

ChatGPT:人工智能助手的新时代
ChatGPT:人工智能助手的新时代 文章目录 ChatGPT:人工智能助手的新时代引言ChatGPT的原理GPT-3.5架构概述预训练和微调过程生成式对话生成技术 ChatGPT的应用场景智能助理客服机器人虚拟角色教育辅助创意生成个性化推荐 ChatGPT的优势ChatGPT的使用技巧与…...

【面试】二、Java补充知识
JVM中的存储 JVM的五块存储区: 方法区(线程共享) 方法区用来存储类的各种信息(类名、方法信息等)、静态变量、常量和编译后的代码也存储在方法区中 方法区中也存在运行时常量池 常量池中会存放程序运行时生成的各种…...

LISTENER、TNSNAMES和SQLNET配置文件
LISTENER、TNSNAMES和SQLNET配置文件 用户连接验证listener.ora文件配置监听日志local_listener参数 tnsnames.ora文件配置 sqlnet.ora文件配置 用户连接验证 Oracle数据库中用户有三种常见的登录验证方式: 通过操作系统用户验证:必须是在数据库服务器…...
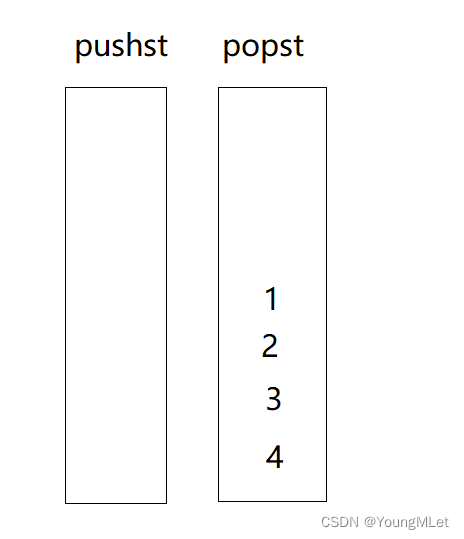
【Leetcode -225.用队列实现栈 -232.用栈实现队列】
Leetcode Leetcode -225.用队列实现栈Leetcode -232.用栈实现队列 Leetcode -225.用队列实现栈 题目:仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 …...
悟道3.0全面开源!LeCun VS Max 智源大会最新演讲
夕小瑶科技说 原创 作者 | 小戏 2023 年智源大会如期召开! 这场汇集了 Geoffery Hinton、Yann LeCun、姚期智、Joseph Sifakis、Sam Altman、Russell 等一众几乎是 AI 领域学界业界“半壁江山”的大佬们的学术盛会,聚焦 AI 领域的前沿问题,…...
2023蓝桥杯大学A组C++决赛游记+个人题解
Day0 发烧了一晚上没睡着,感觉鼻子被打火机烧烤一样难受,心情烦躁 早上6点起来吃了个早饭,思考能力完全丧失了,开始看此花亭奇谭 看了六集,准备复习数据结构考试,然后秒睡 一睁眼就是下午2点了 挂了个…...

wkhtmltopdf踩坑记录
1. 不支持writing-mode。 需求是文字纵向排列,内容从左到右,本来用的是writing-mode: tb-rl;,插件转pdf后发现失效。 解决方法: 让每一列文字单独用一个div容器包裹,对它的宽度进行限制,控制每一行只能出现…...

贪心算法part2 | ● 122.买卖股票的最佳时机II ● 55. 跳跃游戏 ● 45.跳跃游戏II
文章目录 122.买卖股票的最佳时机II思路思路代码官方题解困难 55. 跳跃游戏思路思路代码官方题解代码困难 45.跳跃游戏II思路思路代码困难 今日收获 122.买卖股票的最佳时机II 122.买卖股票的最佳时机II 思路 局部最优:将当天价格和前一天比较,价格涨…...

[C++]异常笔记
我不怕练过一万种腿法的对手,就怕将一种腿法 练一万次的对手。 什么是C的异常 在C中,异常处理通常使用try-catch块来实现。try块用于包含可能会抛出异常的代码,而catch块用于捕获并处理异常。当异常被抛出时,程序会跳过try块中未执行…...

浅谈一级机电管道设计中的压力与介质温度
管道设计是工程设计中的一个非常重要的部分,管道的设计需要考虑到许多因素,其中就包括管道设计压力分类和介质温度分类。这两个因素是在设计管道时必须非常严格考虑的, 首先是管道设计压力分类。在管道设计中,根据工作要求和要传输…...
使用 macvlan 网络)
Docker网络模型(八)使用 macvlan 网络
使用 macvlan 网络 一些应用程序,特别是传统的应用程序或监控网络流量的应用程序,期望直接连接到物理网络。在这种情况下,你可以使用 macvlan 网络驱动为每个容器的虚拟网络接口分配一个MAC地址,使其看起来像一个直接连接到物理网…...
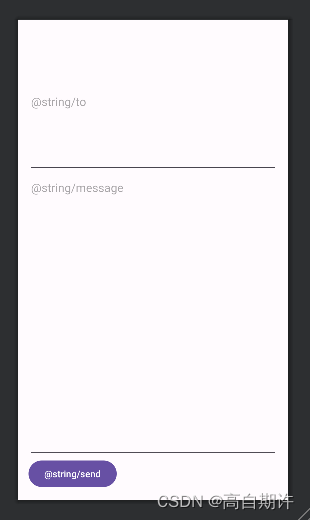
控制视图内容的位置
文本域中的提示内容在默认情况下是垂直居中的,要改变文本在文本域中的位置,可以使用android:gravity来实现。 利用android:gravity可以指定如何在视图中放置视图内容,例如,如何在文本域中放置文本。 如果希望视图文本显示在上方&a…...

【分布式系统与一致性协议】
分布式系统与一致性协议 CAP原理APCPCA总结BASE理论 一致性拜占庭将军问题 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。 分布式系统的设计目标一般包含如下: 可用性:可用性是分…...

音视频领域的未来发展方向展望
文章目录 音视频领域的未来发展方向全景音视频技术虚拟现实和增强现实的区别 人工智能技术可视化智能分析智能语音交互图像识别和视频分析技术 语音处理智能推荐技术远程实时通信 流媒体技术未来方向 音视频领域的未来发展方向 全景音视频技术:全景音视频技术是近年…...

Wi-Fi卸载技术解析:从运营商策略到用户体验的深度实践
1. 项目概述:当“大哥”开始管理你的Wi-Fi十年前,一篇发表在EE Times上的文章提出了一个在今天看来依然尖锐的问题:智能手机用户使用Wi-Fi是件好事吗?这甚至上升到了“人权”层面——每个有手机的人是否都应该有权访问Wi-Fi&#…...

手机跑多模态也能快到飞起!面壁MiniCPM-V 4.6开源
大模型技术正快步从云端机房走入普通人的智能手机,让移动设备直接处理复杂的图文与视频任务成为现实。面壁智能最新开源的一款多模态模型,以极低的算力成本,超低的首Token延迟,成功打通当前三大主流手机操作系统。MiniCPM-V 4.6专…...

告别枯燥理论:用51单片机和DAC0832做个迷你音乐合成器,汇编语言实现《小星星》
用51单片机和DAC0832打造迷你音乐合成器:汇编语言实现《小星星》全解析 在嵌入式系统学习的道路上,很多初学者都会遇到一个共同的问题:如何将枯燥的理论知识转化为有趣的实际应用?今天,我们就来打破常规,用…...

颠覆性网络拓扑可视化:基于Vue+SVG的一站式轻量级解决方案
颠覆性网络拓扑可视化:基于VueSVG的一站式轻量级解决方案 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在复杂的网络架构设计和运维管理中,网络工程师和开发人员经常…...

我用了半年只留下这1个!2026年英语录音转文字选它真不踩坑
做学术调研的朋友多半都遇过这些坑:熬了半个月跑了10场受访者访谈,攒了8小时录音,手动整理整整花了一周,眼睛都熬花了还错漏一堆;听国外名家讲座录了音,转写工具一堆专业词汇识别错,口音还认不出…...

为什么92%的用户调不出正宗120胶片感?揭秘Midjourney底层色彩映射矩阵与胶片光谱响应偏差
更多请点击: https://intelliparadigm.com 第一章:胶片感的视觉本质与数字复现困境 胶片感并非单一参数可定义的视觉效果,而是由卤化银晶体随机分布、显影化学反应非线性响应、颗粒噪点的空间相关性以及动态范围压缩特性共同构成的模拟物理现…...

如何使用MIKE IO高效处理水文数据:从零开始构建专业工作流
如何使用MIKE IO高效处理水文数据:从零开始构建专业工作流 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio 水文数据处理是环境科学、水利工程和海洋…...

从NASA航天电子设计看高可靠性电源与模拟电路工程实践
1. 从太空迷到电子工程师:我的技术启蒙之路我是一名不折不扣的太空迷。这个身份的烙印,始于童年时守在电视机前,目睹第一艘“水星号”载人飞船发射升空的那一天。沃尔特克朗凯特在新闻中从各个科学角度进行的详尽报道,让我整整一天…...

【JWT】JWS与JWE实战解析:从结构差异到安全选型指南
1. JWT、JWS与JWE的核心概念解析 第一次接触JWT相关技术时,我也曾被各种缩写搞得晕头转向。直到在真实项目中踩过几次坑,才真正理解它们之间的关系。简单来说,JWT就像是一个快递包裹,而JWS和JWE则是两种不同的包装方式——前者像…...
OpenMMLab MMTracking 目标跟踪算法库
MMTracking是OpenMMLab(商汤科技与港中文MMLab联合推出)体系下的一款开源视频目标感知工具箱。你可以把它理解为“视频版”的MMDetection,它将该领域内纷繁复杂的算法、数据集和评估标准,统一整合到了一个高效、模块化的框架中。 …...