初识轻量级分布式任务调度平台 xxl-job
文章目录
- 前言
- xxl-job的目录结构
- 项目依赖 (父 pom.xml)
- xxl-job-admin 启动
- xxl-job-executor-sample (项目使用示例)
- xxl-job-executor-sample-frameless : 不使用框架的接入方式案例
- xxl-job-executor-sample-springboot : springboot接入方案案例
- xxl-job执行器器启动流程分析
- 调度中心启动流程分析
- 创建调度器以及对调度器进行初始化
- 调度器初始化
- 国际化初始化
- 触发器线程池创建
- 注册监控器启动
- 失败监控器启动
- 日志任务启动
- 调度启动
- 总结
- 定时任务执行流程分析-客户端触发
- trigger方法准备触发任务
- processTrigger触发任务
- 总结
- 定时任务执行流程分析-服务端执行
- 执行阻塞策略
- 注册任务
- 保存触发参数到缓存
- xxl-job 执行器路由选择
- xxl-job定时任务执行流程分析-任务执行
- 处理器的初始化
- 任务的执行
- 销毁清理工作
前言
大家好,这里是 Rocky 编程日记 ,喜欢后端架构及中间件源码,目前正在阅读
xxl-job源码。同时也把自己学习该xxl-job笔记,代码分享出来,供大家学习交流,如若笔记中有不对的地方,那一定是当时我的理解还不够,希望你能及时提出。
如果对于该笔记存在很多疑惑,欢迎和我交流讨论
最后也感谢您的阅读,点赞,关注,收藏~
前人述备矣,我只是知识的搬运工
xxl-job 源码均在个人的开源项目中, 源代码仓库地址: https://gitee.com/Rocky-BCRJ/xxl-job.git

官方文档: https://www.xuxueli.com/xxl-job/
xxl-job的目录结构
- xxl-job-admin : 是后台管理页面
- xxl-job-core : 项目的核心包
- xxl-job-executor-sample (项目使用示例)
- xxl-job-executor-sample-frameless : 不使用框架的接入方式案例
- xxl-job-executor-sample-springboot : springboot接入方案案例
- doc : 项目文档和sql
项目依赖 (父 pom.xml)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xuxueli</groupId><artifactId>xxl-job</artifactId><version>2.4.0-SNAPSHOT</version><packaging>pom</packaging><name>${project.artifactId}</name><description>A distributed task scheduling framework.</description><url>https://www.xuxueli.com/</url><modules><module>xxl-job-core</module><module>xxl-job-admin</module><module>xxl-job-executor-samples</module></modules><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><maven.compiler.encoding>UTF-8</maven.compiler.encoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><maven.test.skip>true</maven.test.skip><netty-all.version>4.1.63.Final</netty-all.version><gson.version>2.9.0</gson.version><spring.version>5.3.20</spring.version><spring-boot.version>2.6.7</spring-boot.version><mybatis-spring-boot-starter.version>2.2.2</mybatis-spring-boot-starter.version><mysql-connector-java.version>8.0.29</mysql-connector-java.version><slf4j-api.version>1.7.36</slf4j-api.version><junit-jupiter.version>5.8.2</junit-jupiter.version><javax.annotation-api.version>1.3.2</javax.annotation-api.version><groovy.version>3.0.10</groovy.version><maven-source-plugin.version>3.2.1</maven-source-plugin.version><maven-javadoc-plugin.version>3.4.0</maven-javadoc-plugin.version><maven-gpg-plugin.version>3.0.1</maven-gpg-plugin.version></properties></project>
xxl-job-admin 启动
- 从 xxl-job 文件 doc 目录下 执行项目中的 SQL, 生成库表操作
- 更改该模块下数据库链接,修改日志文件路径,打包,启动项目
- 浏览器输入 http://localhost:8080/xxl-job-admin/
- 访问之后登录,账号 : admin 密码: 123456
xxl-job-executor-sample (项目使用示例)
xxl-job-executor-sample-frameless : 不使用框架的接入方式案例
-
项目只依赖了
xxl-job-core<dependencies><!-- slf4j --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j-api.version}</version></dependency><!-- junit --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-engine</artifactId><version>${junit-jupiter.version}</version><scope>test</scope></dependency><!-- xxl-job-core --><dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>${project.parent.version}</version></dependency></dependencies> -
关于
xxl-job的核心配置文件### xxl-job admin address list, such as "http://address" or "http://address01,http://address02" xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin### xxl-job, access token xxl.job.accessToken=default_token### xxl-job executor appname xxl.job.executor.appname=xxl-job-executor-sample ### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null xxl.job.executor.address= ### xxl-job executor server-info xxl.job.executor.ip= xxl.job.executor.port=9998 ### xxl-job executor log-path xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler ### xxl-job executor log-retention-days xxl.job.executor.logretentiondays=30
xxl-job-executor-sample-springboot : springboot接入方案案例
xxl-job执行器器启动流程分析
在项目代码 FramelessApplication 类的 main 中
FrameLessXxlJobConfig.getInstance().initXxlJobExecutor();
上述代码即为启动任务执行器的代码。进入到 FrameLessXxlJobConfig#initXxlJobExecutor()方法中
/*** init* 初始化 XxlJobSimpleExecutor 执行器*/public void initXxlJobExecutor() {// load executor prop // 从配置文件(xxl-job-executor.properties)中加载配置 放到 PropertiesProperties xxlJobProp = loadProperties("xxl-job-executor.properties");// init executor // 创建普通的任务执行器xxlJobExecutor = new XxlJobSimpleExecutor();xxlJobExecutor.setAdminAddresses(xxlJobProp.getProperty("xxl.job.admin.addresses"));xxlJobExecutor.setAccessToken(xxlJobProp.getProperty("xxl.job.accessToken"));xxlJobExecutor.setAppname(xxlJobProp.getProperty("xxl.job.executor.appname"));xxlJobExecutor.setAddress(xxlJobProp.getProperty("xxl.job.executor.address"));xxlJobExecutor.setIp(xxlJobProp.getProperty("xxl.job.executor.ip"));xxlJobExecutor.setPort(Integer.valueOf(xxlJobProp.getProperty("xxl.job.executor.port")));xxlJobExecutor.setLogPath(xxlJobProp.getProperty("xxl.job.executor.logpath"));xxlJobExecutor.setLogRetentionDays(Integer.valueOf(xxlJobProp.getProperty("xxl.job.executor.logretentiondays")));// registry job bean// 注册定时任务的bean, 将 SampleXxlJob 加入到定时任务里去xxlJobExecutor.setXxlJobBeanList(Arrays.asList(new SampleXxlJob()));// start executortry {// 启动执行器xxlJobExecutor.start();} catch (Exception e) {logger.error(e.getMessage(), e);}}
SampleXxlJob 类中有一系列由 @XxlJob注解修饰的方法。这些 @XxlJob注解修饰的方法就是定时任务。我们再来看一下执行器的启动start方法:
@Overridepublic void start() {// init JobHandler Repository (for method)// 初始化任务处理器initJobHandlerMethodRepository(xxlJobBeanList);// super starttry {// 调用父类的 startsuper.start();} catch (Exception e) {throw new RuntimeException(e);}}
调用父类的 start方法启动执行器,父类的start方法如下:
/*** 开始* <p>* 1.初始化日志路径* 2.初始化admin的客户端* 3.初始化日志清理线程* 4.初始化回调线程池* 5.初始化执行器服务* </p>* @throws Exception 异常*/public void start() throws Exception {// init logpath// 初始化日志路径XxlJobFileAppender.initLogPath(logPath);// init invoker, admin-client// 初始化admin的客户端initAdminBizList(adminAddresses, accessToken);// init JobLogFileCleanThread// 初始化日志清理线程JobLogFileCleanThread.getInstance().start(logRetentionDays);// init TriggerCallbackThread// 初始化回调线程池TriggerCallbackThread.getInstance().start();// init executor-server// 初始化执行器服务initEmbedServer(address, ip, port, appname, accessToken);}
初始化日志路径
/*** 初始化日志路径* <p>* 首先创建了保存日志的文件目录* 然后在创建保存脚本的文件目录* </p>* @param logPath 日志路径*/public static void initLogPath(String logPath){// initif (logPath!=null && logPath.trim().length()>0) {logBasePath = logPath;}// mk base dir// 创建父类目录File logPathDir = new File(logBasePath);if (!logPathDir.exists()) {logPathDir.mkdirs();}logBasePath = logPathDir.getPath();// mk glue dir// 创建脚本代码目录File glueBaseDir = new File(logPathDir, "gluesource");if (!glueBaseDir.exists()) {glueBaseDir.mkdirs();}glueSrcPath = glueBaseDir.getPath();}
初始化admin的客户端
/*** 初始化admin的客户端** @param adminAddresses 管理地址* @param accessToken 访问令牌* @throws Exception 异常*/private void initAdminBizList(String adminAddresses, String accessToken) throws Exception {// 遍历 调度器 的地址if (adminAddresses!=null && adminAddresses.trim().length()>0) {// 以逗号分隔for (String address: adminAddresses.trim().split(",")) {if (address!=null && address.trim().length()>0) {// 初始化admin客户端AdminBiz adminBiz = new AdminBizClient(address.trim(), accessToken);if (adminBizList == null) {adminBizList = new ArrayList<AdminBiz>();}// 保存到list中adminBizList.add(adminBiz);}}}}
初始化日志清理线程
启动一个线程localThread,用来清理过期的日志文件。localThread的run方法一直执行,首先获取所有的日志文件目录,日志文件形式如logPath/yyyy-MM-dd/9999.log,获取logPath/yyyy-MM-dd/目录下的所有日志文件,然后判断日志文件是否已经过期,过期时间是配置的,如果当前时间减去日志文件创建时间(yyyy-MM-dd)大于配置的日志清理天数,说明日志文件已经过期,一般配置只保存30天的日志,30天以前的日志都删除掉。
初始化执行器服务
启动了一个netty服务器,用于执行器接收admin的http请求。主要接收admin发送的空闲检测请求、运行定时任务的请求、停止运行定时任务的请求、获取日志的请求。最后a还向dmin注册了执行器,注册执行器是调用AdminBizClient的registry方法注册的,AdminBizClient的registry方法通过http将注册请求转发给admin服务的AdminBizImpl类的registry方法,AdminBizImpl类的registry方法将注册请求保存在数据库中。
执行器服务接收admin服务的请求, 交给ExecutorBiz接口处理,ExecutorBiz接口有五个方法,分别是beat(心跳检测)、idleBeat(空闲检测)、run(运行定时任务)、kill(停止运行任务)、log(获取日志)。ExecutorBiz接口有两个实现:ExecutorBizClient和ExecutorBizImpl,ExecutorBizClient是执行器客户端,ExecutorBizImpl执行器服务端。admin服务通过ExecutorBizClient类的方法通过http将请求转发给执行器服务的ExecutorBizImpl对应的方法。
调度中心启动流程分析
创建调度器以及对调度器进行初始化
/*** 创建调度器以及对调度器进行初始化* @throws Exception 异常*/@Overridepublic void afterPropertiesSet() throws Exception {adminConfig = this;// 新建调度器xxlJobScheduler = new XxlJobScheduler();// 调度器初始化xxlJobScheduler.init();}
调度器初始化
/*** 调度器初始化* <p>* 1.国际化初始化* 2.触发器线程池创建* 3.注册监控器启动* 4.失败监控器启动* 5.丢失监控器启动* 6.日志任务启动* 7.调度启动* </p>** @throws Exception 异常*/public void init() throws Exception {// init i18n 初始化国际化initI18n();// admin trigger pool start 触发器线程池创建JobTriggerPoolHelper.toStart();// admin registry monitor run 注册监控器启动JobRegistryHelper.getInstance().start();// admin fail-monitor run 失败监控器启动JobFailMonitorHelper.getInstance().start();// admin lose-monitor run ( depend on JobTriggerPoolHelper )// 丢失监控器启动JobCompleteHelper.getInstance().start();// admin log report start// 日志报告启动JobLogReportHelper.getInstance().start();// start-schedule ( depend on JobTriggerPoolHelper )// 调度启动JobScheduleHelper.getInstance().start();logger.info(">>>>>>>>> init xxl-job admin success.");}
国际化初始化
/*** init i18n* 国际化初始化*/private void initI18n(){for (ExecutorBlockStrategyEnum item:ExecutorBlockStrategyEnum.values()) {item.setTitle(I18nUtil.getString("jobconf_block_".concat(item.name())));}}
ExecutorBlockStrategyEnum是执行阻塞策略枚举,主要有单机串行、丢弃后续调度、覆盖之前调度三种策略,initI18n方法就是设置执行策略的title值。
I18nUtil.getString方法就是根据配置读取resources/il8n/目录下的其中一个文件,该目录下有message_en.properties、message_zh_CN.properties、message_zh_TC.properties三个文件,分别为英语、中文简体、中文繁体是属性文件。
I18nUtil.getString方法获取到执行阻塞策略的值赋值给title.
触发器线程池创建
public static void toStart() {helper.start();}public void start(){// 快速触发线程fastTriggerPool = new ThreadPoolExecutor(10,XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax(),60L,TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(1000),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "xxl-job, admin JobTriggerPoolHelper-fastTriggerPool-" + r.hashCode());}});// 慢速触发线程池slowTriggerPool = new ThreadPoolExecutor(10,XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax(),60L,TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(2000),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "xxl-job, admin JobTriggerPoolHelper-slowTriggerPool-" + r.hashCode());}});}
触发器线程池创建调用了JobTriggerPoolHelper类的start方法,start方法创建了两个线程池、fastTriggerPool为快速线程池、slowTriggerPool为慢速线程池,都是采用阻塞队列LinkedBlockingQueue,快速线程池的阻塞队列大小为1000,慢速线程池的阻塞队列大小为2000。
快速线程池、慢速线程池在什么时候被用来调度任务呢?
默认是用快速调度器调度任务的,当缓存中等待被调度的同一个任务的数量大于10的时候,就用慢速调度器调度任务。
注册监控器启动
public void start(){// for registry or remove// 调度任务注册线程池registryOrRemoveThreadPool = new ThreadPoolExecutor(2,10,30L,TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(2000),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "xxl-job, admin JobRegistryMonitorHelper-registryOrRemoveThreadPool-" + r.hashCode());}},new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {r.run();logger.warn(">>>>>>>>>>> xxl-job, registry or remove too fast, match threadpool rejected handler(run now).");}});// for monitor// 注册监控器线程registryMonitorThread = new Thread(new Runnable() {@Overridepublic void run() {while (!toStop) {try {// auto registry groupList<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().findByAddressType(0);if (groupList!=null && !groupList.isEmpty()) {// remove dead address (admin/executor)List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findDead(RegistryConfig.DEAD_TIMEOUT, new Date());if (ids!=null && ids.size()>0) {XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);}// fresh online address (admin/executor)HashMap<String, List<String>> appAddressMap = new HashMap<String, List<String>>();List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date());if (list != null) {for (XxlJobRegistry item: list) {if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) {String appname = item.getRegistryKey();List<String> registryList = appAddressMap.get(appname);if (registryList == null) {registryList = new ArrayList<String>();}if (!registryList.contains(item.getRegistryValue())) {registryList.add(item.getRegistryValue());}appAddressMap.put(appname, registryList);}}}// fresh group addressfor (XxlJobGroup group: groupList) {List<String> registryList = appAddressMap.get(group.getAppname());String addressListStr = null;if (registryList!=null && !registryList.isEmpty()) {Collections.sort(registryList);StringBuilder addressListSB = new StringBuilder();for (String item:registryList) {addressListSB.append(item).append(",");}addressListStr = addressListSB.toString();addressListStr = addressListStr.substring(0, addressListStr.length()-1);}group.setAddressList(addressListStr);group.setUpdateTime(new Date());XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);}}} catch (Exception e) {if (!toStop) {logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);}}try {TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);} catch (InterruptedException e) {if (!toStop) {logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);}}}logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop");}});registryMonitorThread.setDaemon(true);registryMonitorThread.setName("xxl-job, admin JobRegistryMonitorHelper-registryMonitorThread");registryMonitorThread.start();}
JobRegistryHelper的 start 创建了一个调度任务注册线程池
registryOrRemoveThreadPool以及注册监控器线程registryMonitorThread,调度任务注册线程池用来执行调度任务的注册,注册监控器线程用来监控执行器的机器是否下线。
然后将registryMonitorThread设置为守护线程,最后启动registryMonitorThread线程,开始监控执行器的机器。
registryMonitorThread线程的run方法的代码被省略,接下来分析下run方法的具体逻辑:
// 注册监控器线程registryMonitorThread = new Thread(new Runnable() {@Overridepublic void run() {while (!toStop) {try {// auto registry group// 自动注册的执行器列表List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().findByAddressType(0);if (groupList!=null && !groupList.isEmpty()) {// remove dead address (admin/executor)// 获取已经下线的机器地址记录List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findDead(RegistryConfig.DEAD_TIMEOUT, new Date());if (ids!=null && ids.size()>0) {// 删除已经下线的注册XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);}// fresh online address (admin/executor) 刷新在线的机器HashMap<String, List<String>> appAddressMap = new HashMap<String, List<String>>();// 查询存活的执行器注册机器List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date());if (list != null) {for (XxlJobRegistry item: list) {//如果是执行器,将同一个应用的调度任务放在list中if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) {String appname = item.getRegistryKey();List<String> registryList = appAddressMap.get(appname);if (registryList == null) {registryList = new ArrayList<String>();}if (!registryList.contains(item.getRegistryValue())) {registryList.add(item.getRegistryValue());}appAddressMap.put(appname, registryList);}}}// fresh group address// 遍历自动注册的执行器列表for (XxlJobGroup group: groupList) {List<String> registryList = appAddressMap.get(group.getAppname());String addressListStr = null;if (registryList!=null && !registryList.isEmpty()) {Collections.sort(registryList);StringBuilder addressListSB = new StringBuilder();// 执行器地址拼接for (String item:registryList) {addressListSB.append(item).append(",");}addressListStr = addressListSB.toString();addressListStr = addressListStr.substring(0, addressListStr.length()-1);}// 设置地址group.setAddressList(addressListStr);// 设置注册更新时间group.setUpdateTime(new Date());// 更新注册的执行器地址XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);}}} catch (Exception e) {if (!toStop) {logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);}}try {TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);} catch (InterruptedException e) {if (!toStop) {logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);}}}logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop");}});
run()方法一直执行,直到服务停止,主要做了两件事:
- 将已经下线的执行器的记录从数据库中删除
- 将还在线的执行器机器记录重新设置执行器地址以及更新执行器的时间,然后更新数据库的记录。
怎么判定执行器已经下线了?如果数据库中的update_time字段小于当前时间减去死亡期限,那么说明已经执行器在死亡期限没有进行更新时间,就判定已经下线了。
执行器在启动的时候,会启动一个执行器线程不断的执行注册任务,执行器任务会更新update_time字段。
失败监控器启动
public void start(){monitorThread = new Thread(new Runnable() {@Overridepublic void run() {//代码省略}});monitorThread.setDaemon(true);monitorThread.setName("xxl-job, admin JobFailMonitorHelper");monitorThread.start();
}
上述代码创建了一个名字为monitorThread的线程,并设为守护线程,然后启动这个线程。线程的run方法的代码被省略,run方法的代码如下:
@Overridepublic void run() {// monitorwhile (!toStop) {try {// 获取失败任务日志, 最多1000条List<Long> failLogIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findFailJobLogIds(1000);if (failLogIds!=null && !failLogIds.isEmpty()) {// 遍历失败日志for (long failLogId: failLogIds) {// lock log// 将默认(0)告警状态设置为锁定状态(-1)int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, 0, -1);if (lockRet < 1) {continue;}XxlJobLog log = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().load(failLogId);// 获取任务信息XxlJobInfo info = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(log.getJobId());// 1、fail retry monitor// 如果失败重试次数大于0if (log.getExecutorFailRetryCount() > 0) {// 触发任务执行JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY, (log.getExecutorFailRetryCount()-1), log.getExecutorShardingParam(), log.getExecutorParam(), null);String retryMsg = "<br><br><span style=\"color:#F39C12;\" > >>>>>>>>>>>"+ I18nUtil.getString("jobconf_trigger_type_retry") +"<<<<<<<<<<< </span><br>";log.setTriggerMsg(log.getTriggerMsg() + retryMsg);// 更新触发日志XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(log);}// 2、fail alarm monitorint newAlarmStatus = 0; // 告警状态:0-默认、-1=锁定状态、1-无需告警、2-告警成功、3-告警失败// 如果告警右键不为nullif (info != null) {// 告警boolean alarmResult = XxlJobAdminConfig.getAdminConfig().getJobAlarmer().alarm(info, log);newAlarmStatus = alarmResult?2:3;} else {newAlarmStatus = 1;}// 将锁定(-1)的日志更新为新的告警状态XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, -1, newAlarmStatus);}}} catch (Exception e) {if (!toStop) {logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}", e);}}try {TimeUnit.SECONDS.sleep(10);} catch (Exception e) {if (!toStop) {logger.error(e.getMessage(), e);}}}logger.info(">>>>>>>>>>> xxl-job, job fail monitor thread stop");}
run方法一直运行,直到线程停止。run方法的首先从数据库中获取失败的调度任务日志列表,每次最多一千条。遍历失败的调度任务日志列表,首先将失败的调度任务日志进行锁定,暂停给告警邮件发送告警信息。如果调度任务的失败重试次数大于0,触发任务执行,更新任务日志信息。当邮件不为空时,触发告警信息,最后将锁定的日志状态更新为告警状态。
日志任务启动
主要做了两件事:
- 统计当前时间前三天的触发任务的数量、运行中的任务的数量、成功的任务数量、任务失败的数量,然后保存在数据库中。
- 根据配置的保存日志的过期时间,将已经过期的日志从数据库中查出来,然后清理过期的日志。日志任务启动是创意了一个线程,然后一直在后台运行。
调度启动
调度启动创建了两个线程,一个线程是用于不断从数据库把5秒内要执行的任务读出,立即触发或者放到时间轮等待触发,一个是用于触发任务。
总结
调用中心启动就是启动springboot项目。
在启动的过程中加载XxlJobAdminConfig配置类,在配置类中,会进行一系列的初始化工作,加载配置信息,创建以及初始化一系列化线程在后台一直异步运行,提高了性能。
定时任务执行流程分析-客户端触发
客户端触发是记录触发的日志、准备触发参数触发远程服务器的执行。
trigger方法准备触发任务
/*** trigger job* <p>* 1.根据任务id从数据库中获取执行的任务* 2.根据任务组名字从数据库中获取任务组,如果地址不为空,覆盖原来的地址列表,设置触发类型为手动触发。* 3.判断路由策略,如果是分片广播,遍历地址列表,触发所有的机器,否则只触发一台机器。* 4.分片广播是要触发所有的机器并行处理任务。* </p>* * @param jobId 工作id* @param triggerType 触发类型* @param failRetryCount 失败重试计数* >=0: use this param* <0: use param from job info config * @param executorShardingParam 遗嘱执行人切分参数* @param executorParam 执行器参数* null: use job param* not null: cover job param* @param addressList 地址列表* null: use executor addressList* not null: cover*/public static void trigger(int jobId,TriggerTypeEnum triggerType,int failRetryCount,String executorShardingParam,String executorParam,String addressList) {// load data// 从数据库中获取任务XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);if (jobInfo == null) {logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);return;}// 设置执行参数if (executorParam != null) {jobInfo.setExecutorParam(executorParam);}// 重试次数int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());// 如果地址不为空,覆盖原来的地址列表// cover addressListif (addressList!=null && addressList.trim().length()>0) {group.setAddressType(1);group.setAddressList(addressList.trim());}// sharding paramint[] shardingParam = null;// executorShardingParam不等于nullif (executorShardingParam!=null){String[] shardingArr = executorShardingParam.split("/");if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {shardingParam = new int[2];shardingParam[0] = Integer.valueOf(shardingArr[0]);shardingParam[1] = Integer.valueOf(shardingArr[1]);}}// 分片广播if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()&& shardingParam==null) {// 并行处理for (int i = 0; i < group.getRegistryList().size(); i++) {// 处理触发processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());}} else {if (shardingParam == null) {shardingParam = new int[]{0, 1};}processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);}}processTrigger触发任务
/*** <p>* 获取执行阻塞策略* 获取路由策略* 保存任务日志* 初始化触发参数* 初始化执行器的地址:如果路由策略是分片广播,执行地址就为第index的地址,否则从通过路由获取执行地址。* 触发远程执行器,即触发远程的定时任务* 设置触发信息并保存触发日志* </p>* @param group job group, registry list may be empty* @param jobInfo* @param finalFailRetryCount* @param triggerType* @param index sharding index* @param total sharding index*/private static void processTrigger(XxlJobGroup group, XxlJobInfo jobInfo, int finalFailRetryCount, TriggerTypeEnum triggerType, int index, int total){// param// 执行阻塞策略ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(jobInfo.getExecutorBlockStrategy(), ExecutorBlockStrategyEnum.SERIAL_EXECUTION); // block strategy// 路由策略ExecutorRouteStrategyEnum executorRouteStrategyEnum = ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null); // route strategy// 分片广播String shardingParam = (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==executorRouteStrategyEnum)?String.valueOf(index).concat("/").concat(String.valueOf(total)):null;// 1、save log-id 保存日志XxlJobLog jobLog = new XxlJobLog();jobLog.setJobGroup(jobInfo.getJobGroup());jobLog.setJobId(jobInfo.getId());jobLog.setTriggerTime(new Date());XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().save(jobLog);logger.debug(">>>>>>>>>>> xxl-job trigger start, jobId:{}", jobLog.getId());// 2、init trigger-param 初始化触发参数TriggerParam triggerParam = new TriggerParam();triggerParam.setJobId(jobInfo.getId());triggerParam.setExecutorHandler(jobInfo.getExecutorHandler());triggerParam.setExecutorParams(jobInfo.getExecutorParam());triggerParam.setExecutorBlockStrategy(jobInfo.getExecutorBlockStrategy());triggerParam.setExecutorTimeout(jobInfo.getExecutorTimeout());triggerParam.setLogId(jobLog.getId());triggerParam.setLogDateTime(jobLog.getTriggerTime().getTime());triggerParam.setGlueType(jobInfo.getGlueType());triggerParam.setGlueSource(jobInfo.getGlueSource());triggerParam.setGlueUpdatetime(jobInfo.getGlueUpdatetime().getTime());triggerParam.setBroadcastIndex(index);triggerParam.setBroadcastTotal(total);// 3、init address 初始化地址String address = null;ReturnT<String> routeAddressResult = null;if (group.getRegistryList()!=null && !group.getRegistryList().isEmpty()) {if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == executorRouteStrategyEnum) {if (index < group.getRegistryList().size()) {address = group.getRegistryList().get(index);} else {address = group.getRegistryList().get(0);}} else {// 路由获取地址routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());if (routeAddressResult.getCode() == ReturnT.SUCCESS_CODE) {address = routeAddressResult.getContent();}}} else {routeAddressResult = new ReturnT<String>(ReturnT.FAIL_CODE, I18nUtil.getString("jobconf_trigger_address_empty"));}// 4、trigger remote executor 触发远程执行器ReturnT<String> triggerResult = null;if (address != null) {triggerResult = runExecutor(triggerParam, address);} else {triggerResult = new ReturnT<String>(ReturnT.FAIL_CODE, null);}// 5、collection trigger info 触发信息StringBuffer triggerMsgSb = new StringBuffer();triggerMsgSb.append(I18nUtil.getString("jobconf_trigger_type")).append(":").append(triggerType.getTitle());triggerMsgSb.append("<br>").append(I18nUtil.getString("jobconf_trigger_admin_adress")).append(":").append(IpUtil.getIp());triggerMsgSb.append("<br>").append(I18nUtil.getString("jobconf_trigger_exe_regtype")).append(":").append( (group.getAddressType() == 0)?I18nUtil.getString("jobgroup_field_addressType_0"):I18nUtil.getString("jobgroup_field_addressType_1") );triggerMsgSb.append("<br>").append(I18nUtil.getString("jobconf_trigger_exe_regaddress")).append(":").append(group.getRegistryList());triggerMsgSb.append("<br>").append(I18nUtil.getString("jobinfo_field_executorRouteStrategy")).append(":").append(executorRouteStrategyEnum.getTitle());if (shardingParam != null) {triggerMsgSb.append("("+shardingParam+")");}triggerMsgSb.append("<br>").append(I18nUtil.getString("jobinfo_field_executorBlockStrategy")).append(":").append(blockStrategy.getTitle());triggerMsgSb.append("<br>").append(I18nUtil.getString("jobinfo_field_timeout")).append(":").append(jobInfo.getExecutorTimeout());triggerMsgSb.append("<br>").append(I18nUtil.getString("jobinfo_field_executorFailRetryCount")).append(":").append(finalFailRetryCount);triggerMsgSb.append("<br><br><span style=\"color:#00c0ef;\" > >>>>>>>>>>>"+ I18nUtil.getString("jobconf_trigger_run") +"<<<<<<<<<<< </span><br>").append((routeAddressResult!=null&&routeAddressResult.getMsg()!=null)?routeAddressResult.getMsg()+"<br><br>":"").append(triggerResult.getMsg()!=null?triggerResult.getMsg():"");// 6、save log trigger-info 保存触发日志jobLog.setExecutorAddress(address);jobLog.setExecutorHandler(jobInfo.getExecutorHandler());jobLog.setExecutorParam(jobInfo.getExecutorParam());jobLog.setExecutorShardingParam(shardingParam);jobLog.setExecutorFailRetryCount(finalFailRetryCount);//jobLog.setTriggerTime();jobLog.setTriggerCode(triggerResult.getCode());jobLog.setTriggerMsg(triggerMsgSb.toString());XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(jobLog);logger.debug(">>>>>>>>>>> xxl-job trigger end, jobId:{}", jobLog.getId());} public static ReturnT<String> runExecutor(TriggerParam triggerParam, String address){ReturnT<String> runResult = null;try {// 获取执行器ExecutorBiz executorBiz = XxlJobScheduler.getExecutorBiz(address);// 执行任务runResult = executorBiz.run(triggerParam);} catch (Exception e) {logger.error(">>>>>>>>>>> xxl-job trigger error, please check if the executor[{}] is running.", address, e);runResult = new ReturnT<String>(ReturnT.FAIL_CODE, ThrowableUtil.toString(e));}// 返回执行结果StringBuffer runResultSB = new StringBuffer(I18nUtil.getString("jobconf_trigger_run") + ":");runResultSB.append("<br>address:").append(address);runResultSB.append("<br>code:").append(runResult.getCode());runResultSB.append("<br>msg:").append(runResult.getMsg());runResult.setMsg(runResultSB.toString());return runResult;}
runExecutor方法通过 XxlJobScheduler.getExecutorBiz方法获取执行器ExecutorBiz,然后调用执行器ExecutorBiz的run方法执行任务。getExecutorBiz方法首先通过地址从executorBizRepository(map)获取ExecutorBiz,如果获取的ExecutorBiz不为null,则直接返回,否则,创建一个ExecutorBizClient保存在executorBizRepository中,然后将创建的ExecutorBizClient返回。
ExecutorBiz接口有两个实现,分别是ExecutorBizClient(执行器客户端)、ExecutorBizImpl(执行器服务端),ExecutorBizClien类就是客户端操作任务的类,ExecutorBizImpl就是服务端操作任务的类。ExecutorBiz接口有beat(心跳检测)、idleBeat(空闲检测)、run(执行任务)、kill(停止任务)、log(打印日志)这些方法。
我们看看ExecutorBizClien的run方法:
public ReturnT<String> run(TriggerParam triggerParam) {return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class);
}
ExecutorBizClien的run方法比较简单,就是调用http请求发送触发参数触发服务端的任务执行,然后将结果返回给客户端。请求的地址为addressUrl + “run”,当客户端发送请求以后,ExecutorBizImpl的run方法将会接收请求处理,然后将处理的结果返回,这篇文章就讲到这里,服务端执行定时任务放到下一篇文章进行讲解。
总结
客户端触发任务执行,首先从数据库中查询出需要执行的任务,然后做好任务执行的准备,如日志的记录、触发参数的初始化、获取执行的地址等,然后发送http请求给服务端执行任务,服务器将处理任务的结果返回给客户端。客户端触发任务执行,是通过http请求触发任务执行,如果请求丢失,那么就会错过任务的执行。
定时任务执行流程分析-服务端执行
执行器启动时,会初始化一个EmbedServer类,该类的start方法会启动netty服务器。netty服务器会接收客户端发送过来的http请求,当接收到触发请求(请求路径是/run)会交给EmbedServer类的process方法处理,process方法将会调用ExecutorBizImpl的run方法处理客户端发送的触发请求。
ExecutorBizImpl的run方法处理流程大致如下:
/*** <p>* 1.加载任务处理器与任务执行线程,校验任务处理器与任务执行线程* 2.执行阻塞策略* 3.注册任务* 4.保存触发参数到缓存** </p>** @param triggerParam 触发参数* @return {@link ReturnT}<{@link String}>*/@Overridepublic ReturnT<String> run(TriggerParam triggerParam) {// load old:jobHandler + jobThread// 加载旧的任务处理器和任务线程JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;String removeOldReason = null;// valid:jobHandler + jobThreadGlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());if (GlueTypeEnum.BEAN == glueTypeEnum) {// new jobhandler// new jobhandler 从缓存中加载任务处理器,根据处理器名字IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());// valid old jobThread// valid old jobThread 如果新的任务处理器与旧的任务处理器不同,将旧的任务处理器以及旧的任务线程gcif (jobThread!=null && jobHandler != newJobHandler) {// change handler, need kill old threadremoveOldReason = "change jobhandler or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = newJobHandler;if (jobHandler == null) {return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");}}} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof GlueJobHandler&& ((GlueJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change handler or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {try {IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());jobHandler = new GlueJobHandler(originJobHandler, triggerParam.getGlueUpdatetime());} catch (Exception e) {logger.error(e.getMessage(), e);return new ReturnT<String>(ReturnT.FAIL_CODE, e.getMessage());}}} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {// valid old jobThreadif (jobThread != null &&!(jobThread.getHandler() instanceof ScriptJobHandler&& ((ScriptJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {// change script or gluesource updated, need kill old threadremoveOldReason = "change job source or glue type, and terminate the old job thread.";jobThread = null;jobHandler = null;}// valid handlerif (jobHandler == null) {jobHandler = new ScriptJobHandler(triggerParam.getJobId(), triggerParam.getGlueUpdatetime(), triggerParam.getGlueSource(), GlueTypeEnum.match(triggerParam.getGlueType()));}} else {return new ReturnT<String>(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");}// executor block strategyif (jobThread != null) {ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// discard when runningif (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// kill running jobThreadif (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {// just queue trigger}}// replace thread (new or exists invalid)if (jobThread == null) {jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);}// push data to queueReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);return pushResult;}
run方法首先根据任务id从缓存jobThreadRepository(map)中获取任务执行线程jobThread,任务执行线程jobThread保存着任务处理器jobHandler,然后进行校验任务执行线程以及任务处理器。在了解校验过程之前,我们先了解下xxl-job定时任务的种类,xxll0job支持java、groovy、脚本(Shell、Python、PHP、NodeJs、PowerShell)的定时任务。
接下来检验任务执行线程以及任务处理器,就是按照Java、groovy、脚本分别进行校验。
当任务的种类是java时,根据任务处理器的名字从jobHandlerRepository(map)中获取任务处理器,如果新的任务处理器与旧的任务处理器不同,将旧的任务处理器以及旧的任务线程设置为null,等待被java虚拟机gc掉,这样做的目的是,如果已经重新设置了新的任务执行线程和任务处理器,那么就旧的gc掉,不至于一直存在内存中。
如果任务的种类是groovy时,判断任务执行线程不等于null、任务处理器已经更改和groovy的代码被更新了,那么就将旧的任务执行线程和任务执行器设置为null,等待被gc,如果任务处理器还是为null,那么新创建GlueJobHandler任务处理器。
如果是任务的种类是脚本类型,判断任务执行线程不等于null、任务处理器已经更改和脚本的代码被更新了,那么就将旧的任务执行线程和任务执行器设置为null,等待被gc,如果任务处理器还是为null,那么新创建ScriptJobHandler任务处理器。
执行阻塞策略
// 执行阻塞策略if (jobThread != null) {// 阻塞策略ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// discard when running 如果任务正在执行,直接返回结果,不再往下执行任务if (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// kill running jobThread 覆盖之前的if (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {// just queue trigger}}
xxl-job 有三种阻塞队列,分别为SERIAL_EXECUTION(单机串行)、DISCARD_LATER(丢弃)、COVER_EARLY(覆盖之前的)。当阻塞策略为丢弃,则判断该执行线程是否正在执行,如果是则直接返回结果,不再往下执行任务了。当阻塞策略为覆盖之前的,则判断执行线程是否正在执行,如果是则杀掉原来的执行线程。如果阻塞策略是这俩种之外,则不做什么。
注册任务
// replace thread (new or exists invalid) // 如果任务线程等于null,注册任务线程并启动线程if (jobThread == null) {jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);}public static JobThread registJobThread(int jobId, IJobHandler handler, String removeOldReason){JobThread newJobThread = new JobThread(jobId, handler);newJobThread.start();logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}", new Object[]{jobId, handler});JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread); // putIfAbsent | oh my god, map's put method return the old value!!!if (oldJobThread != null) {oldJobThread.toStop(removeOldReason);oldJobThread.interrupt();}return newJobThread;}
如果任务线程等于null,注册任务线程并启动线程。registJobThread方法首先新建一个任务线程,并调用newJobThread的start方法启动任务线程。然后加入jobThreadRepository进行缓存,当旧的oldJobThread不等于null,则停止掉旧的任务线程。
保存触发参数到缓存
// push data to queue// 保存触发参数到缓存ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);return pushResult;public ReturnT<String> pushTriggerQueue(TriggerParam triggerParam) {// avoid repeatif (triggerLogIdSet.contains(triggerParam.getLogId())) {logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());return new ReturnT<String>(ReturnT.FAIL_CODE, "repeate trigger job, logId:" + triggerParam.getLogId());}triggerLogIdSet.add(triggerParam.getLogId());triggerQueue.add(triggerParam);return ReturnT.SUCCESS;}
pushTriggerQueue方法判断任务id是否已经存在triggerLogIdSet中,如果存在就直接返回结果,如果不存在就添加到triggerLogIdSet中,然后将触发参数保存在triggerQueue队列中。
xxl-job 执行器路由选择
现在的服务大部分都是微服务,在分布式环境中,服务在多台服务器上部署。
xxl-job为了防止定时任务在同一时间内多台服务运行定时任务,利用数据库的悲观锁保证同一时间内只有一台服务运行定时任务,在运行定时任务之前首先获取到锁(select lock for update),然后才运行定时任务,当任务运行完成时,释放悲观锁,其他服务就可以去尝试获取锁而执行定时任务。
上述是xxl-job在分布式环境中如何保证同一时间只有一台服务运行定时任务,那么如何从多台服务中选出一台服务来运行定时任务,这就设计到xxl-job执行路由选择的问题,接下来分析xxl-job是如何选择执行器的。
执行器路由抽象类 ExecutorRouter 的 route 方法是选择服务器地址的,决定哪一台服务器来执行定时任务。子列展示如下:
// com/xxl/job/admin/core/route/ExecutorRouteStrategyEnum.java/*** 执行器地址列表的第一个列表*/FIRST(I18nUtil.getString("jobconf_route_first"), new ExecutorRouteFirst()),/*** 执行器地址列表的最后一个地址*/LAST(I18nUtil.getString("jobconf_route_last"), new ExecutorRouteLast()),/*** 轮询路由,轮询选择一个执行器地址*/ROUND(I18nUtil.getString("jobconf_route_round"), new ExecutorRouteRound()),/*** 随机路由,随机选择一个执行器地址*/RANDOM(I18nUtil.getString("jobconf_route_random"), new ExecutorRouteRandom()),/*** 哈希一致性路由,通过哈希一致性算法选择执行器地址*/CONSISTENT_HASH(I18nUtil.getString("jobconf_route_consistenthash"), new ExecutorRouteConsistentHash()),/*** 最不经常使用路由,使用频率最低的执行器地址*/LEAST_FREQUENTLY_USED(I18nUtil.getString("jobconf_route_lfu"), new ExecutorRouteLFU()),/*** 最近最少使用(最近最久未使用路由,选择最近最久未被使用的执行器地址)*/LEAST_RECENTLY_USED(I18nUtil.getString("jobconf_route_lru"), new ExecutorRouteLRU()),/*** 故障转移路由,查找心跳正常的执行器地址*/FAILOVER(I18nUtil.getString("jobconf_route_failover"), new ExecutorRouteFailover()),/*** 忙碌转移路由,从执行器地址列表查找心跳正常的执行器地址*/BUSYOVER(I18nUtil.getString("jobconf_route_busyover"), new ExecutorRouteBusyover()),/*** 分片广播*/SHARDING_BROADCAST(I18nUtil.getString("jobconf_route_shard"), null);
Xxl-job 执行器路由选择可以去xxl-job的源码仓库观看。
xxl-job定时任务执行流程分析-任务执行
在服务端执行的流程中,将任务交给任务线程池JobThread执行,JobThread的run方法主要做了几件事:
- 处理器的初始化
- 任务的执行
- 销毁清理工作
处理器的初始化
// inittry {handler.init();} catch (Throwable e) {logger.error(e.getMessage(), e);}
处理器的初始化比较简单,调用IJobHandler的init方法,IJobHandler是接口类型,有三种方法,分别是init(初始化方法)、execute(执行方法)、destroy(销毁)方法。IJobHandler接口将在下面具体分析。
任务的执行
销毁清理工作
// callback trigger request in queue// 如果任务停止了,需要将队列中的所有触发删除(所有定时任务删除)while(triggerQueue !=null && triggerQueue.size()>0){// 从队列中获取触发参数TriggerParam triggerParam = triggerQueue.poll();if (triggerParam!=null) {// is killedTriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(),triggerParam.getLogDateTime(),XxlJobContext.HANDLE_CODE_FAIL,stopReason + " [job not executed, in the job queue, killed.]"));}}// destroy// 执行器的销毁方法try {handler.destroy();} catch (Throwable e) {logger.error(e.getMessage(), e);}
相关文章:
初识轻量级分布式任务调度平台 xxl-job
文章目录 前言xxl-job的目录结构项目依赖 (父 pom.xml)xxl-job-admin 启动xxl-job-executor-sample (项目使用示例)xxl-job-executor-sample-frameless : 不使用框架的接入方式案例xxl-job-executor-sample-springboot : springboot接入方案案例 xxl-job执行器器启动流程分析调…...

web 语音通话 jssip
先把封装好的地址安上(非本人封装):webrtc-webphone: 基于JsSIP开发的webrtc软电话 jssip中文文档:jssip中文开发文档(完整版) - 简书 jssip使用文档:(我没有运行过,但…...

随风摇曳的她——美蕨(matlab实现)
目录 1 随风摇曳的她 2 摇曳带来的哲思 3 Matlab代码实现 1 随风摇曳的她 梦幻的场景、浪漫的气息,带上心爱的人,拥抱在这片花海之下,便有了电影男女主角的氛围感; 就算阅尽了世间风貌,也抵不上和她在一起时锦短情长&a…...

时序数据库的流计算支持
一、时序数据及其特点 时序数据(Time Series Data)是基于相对稳定频率持续产生的一系列指标监测数据,比如一年内的道琼斯指数、一天内不同时间点的测量气温等。时序数据有以下几个特点: 历史数据的不变性数据的有效性数据的时效…...

springboot启动流程 (3) 自动装配
在SpringBoot中,EnableAutoConfiguration注解用于开启自动装配功能。 本文将详细分析该注解的工作流程。 EnableAutoConfiguration注解 启用SpringBoot自动装配功能,尝试猜测和配置可能需要的组件Bean。 自动装配类通常是根据类路径和定义的Bean来应…...

ansible-roles模块
roles用于层次性,结构化地组织playbook,roles能够根据层次型结构自动装载变量文件,tasks以及handlers等。要使用只要载playbook中使用include指令引入即可。 (roles就是通过分别将变量,文件,任务ÿ…...

聊聊我做 NeRF-3D重建性能优化经历
我们新推出大淘宝技术年度特刊《长期主义,往往从一些小事开始——工程师成长总结专题》,专题收录多位工程师真诚的心路历程与经验思考,覆盖终端、服务端、数据算法、技术质量等7大技术领域,欢迎一起沟通交流。 本文为此系列第四篇…...

未磁科技全球首台64通道无液氦心磁图仪及首个培训基地落户北京安贞医院
【全球首台64通道无液氦心磁图仪在北京安贞医院举行开机仪式】 近日,在北京安贞医院举行了未磁科技全球首台64通道无液氦心磁图仪开机仪式,中国医学装备协会赵自林理事长、北京安贞医院纪智礼书记、张宏家院长、宋现涛教授,以及未磁科技蔡宾…...

SpringBoot 如何使用 ApplicationEventPublisher 发布事件
SpringBoot 如何使用 ApplicationEventPublisher 发布事件 在 SpringBoot 应用程序中,我们可以使用 ApplicationEventPublisher 接口来发布事件。事件可以是任何对象,当该对象被发布时,所有监听该事件的监听器都会收到通知。 下面是一个简单…...
【深度学习】2-3 神经网络-输出层设计
前馈神经网络(Feedforward Neural Network),之前介绍的单层感知机、多层感知机等都属于前馈神经网络,它之所以称为前馈(Feedforward),或许与其信息往前流有关:数据从输入开始,流过中间计算过程,最后达到输出…...

Python网络爬虫开发:使用PyQt5和WebKit构建可定制的爬虫
部分数据来源:ChatGPT 引言 在网络爬虫开发中,使用Web浏览器模拟用户行为是非常重要的。而在这个过程中,基于 WebKit 的框架可以提供比其他技术更紧密的浏览器集成,以及更高效、更多样化的页面交互方式。 在本文中,我们将通过一个使用基于 WebKit 的爬虫示例,并与类似…...
Laya3.0游戏框架搭建流程(随时更新)
近两年AI绘图技术有了长足发展,准备把以前玩过的游戏类型重制下,也算是圆了一个情怀梦。 鉴于unity商用水印和启动时间的原因,我决定使用Laya来开发。目前laya已经更新到了3.0以上版本,就用目前比较新的版本。 之后关于开发中遇到…...

.net 软件开发模式——三层架构
三层架构是一种常用的软件开发架构模式,它将应用程序分为三个层次:表示层、业务逻辑层和数据访问层。每一层都有明确的职责和功能,分别负责用户交互、业务处理和数据存储等任务。这种架构模式的优点包括易于维护和扩展、更好的组织结构和代码…...

SpringBoot如何优雅的实现重试功能
文章目录 使用背景spring-retry介绍快速使用加入依赖开启Retry使用参数 使用背景 在有些特定场景,如和第三方对接。 我们调用接口时需要支持重试功能,第一次调用没成功,我们需要等待x秒后再次调用。 通常会设置重试次数,避免业务…...
【CEEMDAN-VMD-GRU】完备集合经验模态分解-变分模态分解-门控循环单元预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
—— 适用于 UNIX、Linux 和 Windows 的远程桌面解决方案)
OpenText Exceed TurboX(ETX)—— 适用于 UNIX、Linux 和 Windows 的远程桌面解决方案
由于新技术的采用,以及商业全球化和全球协作的现实,几乎所有企业(无论其规模和所处行业)的员工的工作方式、时间和地点都发生了重大变化。业务领导者正在推动其 IT 部门提出解决方案,以帮助其远程员工提高工作效率&…...
【人工智能】— 逻辑回归分类、对数几率、决策边界、似然估计、梯度下降
【人工智能】— 逻辑回归分类、对数几率、决策边界、似然估计、梯度下降 逻辑回归分类Logistic Regression ClassificationLogistic Regression: Log OddsLogistic Regression: Decision BoundaryLikelihood under the Logistic ModelTraining the Logistic ModelGradient Desc…...

k8s pod “cpu和内存“ 资源限制
转载用于收藏学习:原文 文章目录 Pod资源限制requests:limits:docker run命令和 CPU 限制相关的所有选项如下: Pod资源限制 为了保证充分利用集群资源,且确保重要容器在运行周期内能够分配到足够的资源稳定运行&#x…...
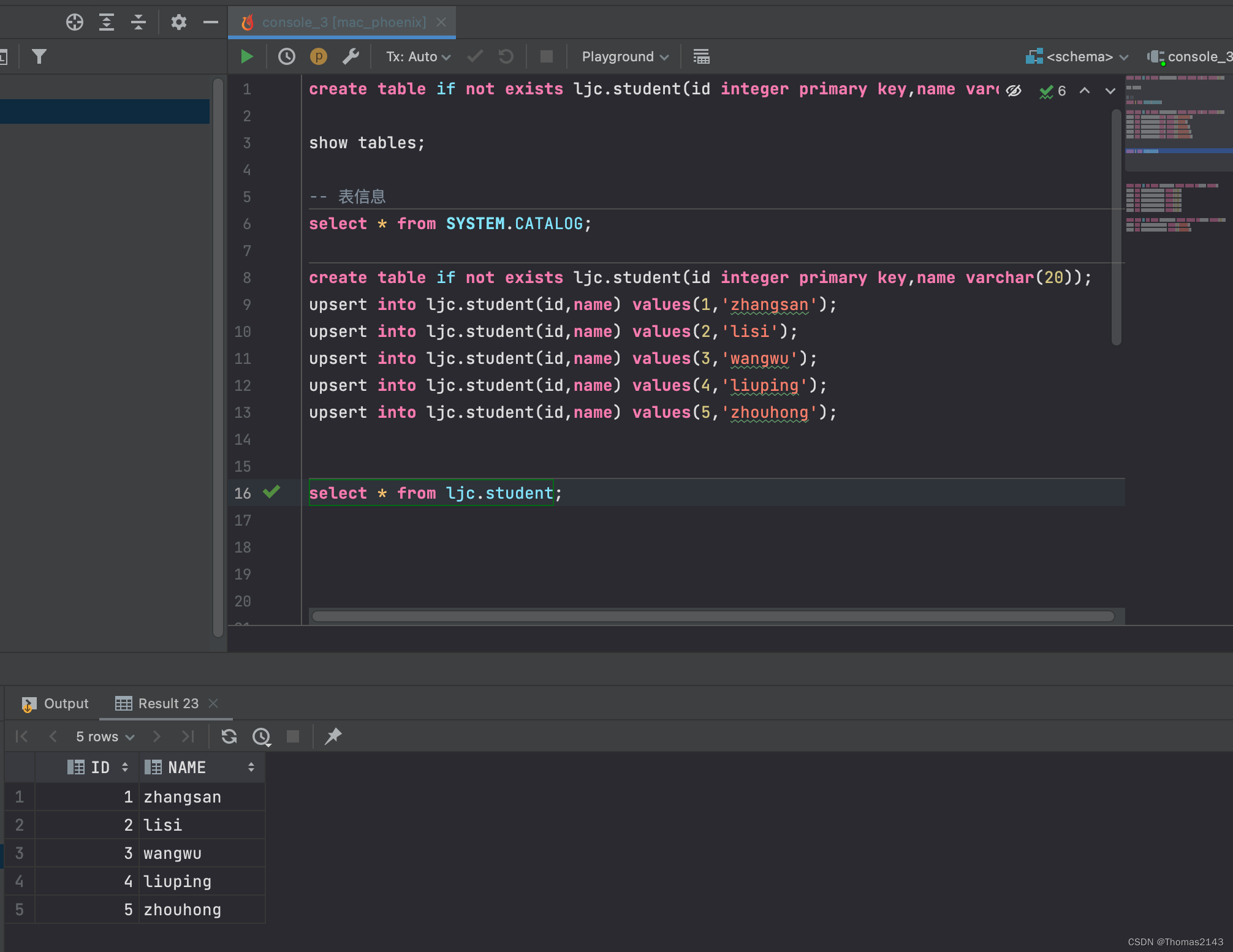
datagrip 连接 phoenix
jar替换完后尽量重启datagrip. 然后重新连接即可. 不重启貌似报错... 效果:...

黑客入侵的常法
1.无论什么站,无论什么语言,我要渗透,第一件事就是扫目录,最好一下扫出个上传点,直接上传 shell ,诸位不要笑,有时候你花很久搞一个站,最后发现有个现成的上传点,而且很容…...

CMOS闩锁效应原理与防护设计实践
1. 闩锁效应基础原理剖析闩锁效应(Latch-up)是CMOS集成电路设计中最为棘手的可靠性问题之一。这种现象本质上是由芯片内部寄生形成的PNP-NPN晶体管对构成的晶闸管结构(SCR)被意外触发导致的。当特定条件满足时,这些寄生元件会形成正反馈回路,导致电源与地…...

模型运行记录
1753...

使用Taotoken后模型API调用的延迟与稳定性观测体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后模型API调用的延迟与稳定性观测体验分享 作为一名日常需要与多种大模型API打交道的开发者,模型服务的稳…...

TextInputLayout实战:从属性解析到自定义样式进阶
1. TextInputLayout基础入门:从零开始掌握Material输入框 第一次接触TextInputLayout时,我被它丝滑的浮动提示动画惊艳到了。相比传统的EditText,这个Material Design组件确实能让表单界面瞬间提升好几个档次。记得去年做登录页面重构时&…...

【JVM】面试题-有哪些垃圾回收器
【JVM】面试题-有哪些垃圾回收器 在JVM的内存管理中,垃圾收集算法是内存回收的核心逻辑与方法论,而垃圾收集器则是将这套方法论落地实现的具体工具。 不同的垃圾收集器针对JVM堆的不同分代(新生代、老年代)设计,具备不…...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...

企业内如何通过 Taotoken 实现 API 访问权限的精细化控制与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过 Taotoken 实现 API 访问权限的精细化控制与审计 当企业将大模型能力引入内部工作流时,如何安全、可控地…...

订阅Token Plan套餐后在长期项目中的成本节约效果分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 订阅Token Plan套餐后在长期项目中的成本节约效果分析 对于需要持续、稳定调用大模型的个人开发者或团队而言,成本控制…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...

基于LangGraph与MCP构建Farcaster AI智能体:从架构到DeFi集成实战
1. 项目概述:一个面向Farcaster生态的AI智能体最近在探索SocialFi和AI Agent的结合点,发现了一个挺有意思的项目:oceantruong/farcaster-agent。简单来说,这是一个专门为Farcaster社交网络设计的AI智能体框架。Farcaster本身是一个…...