【设计模式与范式:行为型】61 | 策略模式(下):如何实现一个支持给不同大小文件排序的小程序?
上一节课,我们主要介绍了策略模式的原理和实现,以及如何利用策略模式来移除 if-else 或者 switch-case 分支判断逻辑。今天,我们结合“给文件排序”这样一个具体的例子,来详细讲一讲策略模式的设计意图和应用场景。
除此之外,在今天的讲解中,我还会通过一步一步地分析、重构,给你展示一个设计模式是如何“创造”出来的。通过今天的学习,你会发现,设计原则和思想其实比设计模式更加普适和重要,掌握了代码的设计原则和思想,我们甚至可以自己创造出来新的设计模式。
话不多说,让我们正式开始今天的学习吧!
问题与解决思路
假设有这样一个需求,希望写一个小程序,实现对一个文件进行排序的功能。文件中只包含整型数,并且,相邻的数字通过逗号来区隔。如果由你来编写这样一个小程序,你会如何来实现呢?你可以把它当作面试题,先自己思考一下,再来看我下面的讲解。
你可能会说,这不是很简单嘛,只需要将文件中的内容读取出来,并且通过逗号分割成一个一个的数字,放到内存数组中,然后编写某种排序算法(比如快排),或者直接使用编程语言提供的排序函数,对数组进行排序,最后再将数组中的数据写入文件就可以了。
但是,如果文件很大呢?比如有 10GB 大小,因为内存有限(比如只有 8GB 大小),我们没办法一次性加载文件中的所有数据到内存中,这个时候,我们就要利用外部排序算法(具体怎么做,可以参看我的另一个专栏《数据结构与算法之美》中的“排序”相关章节)了。
如果文件更大,比如有 100GB 大小,我们为了利用 CPU 多核的优势,可以在外部排序的基础之上进行优化,加入多线程并发排序的功能,这就有点类似“单机版”的 MapReduce。
如果文件非常大,比如有 1TB 大小,即便是单机多线程排序,这也算很慢了。这个时候,我们可以使用真正的 MapReduce 框架,利用多机的处理能力,提高排序的效率。
代码实现与分析
解决思路讲完了,不难理解。接下来,我们看一下,如何将解决思路翻译成代码实现。
我先用最简单直接的方式实现将它实现出来。具体代码我贴在下面了,你可以先看一下。因为我们是在讲设计模式,不是讲算法,所以,在下面的代码实现中,我只给出了跟设计模式相关的骨架代码,并没有给出每种排序算法的具体代码实现。感兴趣的话,你可以自行实现一下。
public class Sorter {private static final long GB = 1000 * 1000 * 1000;public void sortFile(String filePath) {// 省略校验逻辑File file = new File(filePath);long fileSize = file.length();if (fileSize < 6 * GB) { // [0, 6GB)quickSort(filePath);} else if (fileSize < 10 * GB) { // [6GB, 10GB)externalSort(filePath);} else if (fileSize < 100 * GB) { // [10GB, 100GB)concurrentExternalSort(filePath);} else { // [100GB, ~)mapreduceSort(filePath);}}private void quickSort(String filePath) {// 快速排序}private void externalSort(String filePath) {// 外部排序}private void concurrentExternalSort(String filePath) {// 多线程外部排序}private void mapreduceSort(String filePath) {// 利用MapReduce多机排序}
}
public class SortingTool {public static void main(String[] args) {Sorter sorter = new Sorter();sorter.sortFile(args[0]);}
}
在“编码规范”那一部分我们讲过,函数的行数不能过多,最好不要超过一屏的大小。所以,为了避免 sortFile() 函数过长,我们把每种排序算法从 sortFile() 函数中抽离出来,拆分成 4 个独立的排序函数。
如果只是开发一个简单的工具,那上面的代码实现就足够了。毕竟,代码不多,后续修改、扩展的需求也不多,怎么写都不会导致代码不可维护。但是,如果我们是在开发一个大型项目,排序文件只是其中的一个功能模块,那我们就要在代码设计、代码质量上下点儿功夫了。只有每个小的功能模块都写好,整个项目的代码才能不差。
在刚刚的代码中,我们并没有给出每种排序算法的代码实现。实际上,如果自己实现一下的话,你会发现,每种排序算法的实现逻辑都比较复杂,代码行数都比较多。所有排序算法的代码实现都堆在 Sorter 一个类中,这就会导致这个类的代码很多。而在“编码规范”那一部分中,我们也讲到,一个类的代码太多也会影响到可读性、可维护性。除此之外,所有的排序算法都设计成 Sorter 的私有函数,也会影响代码的可复用性。
代码优化与重构
只要掌握了我们之前讲过的设计原则和思想,针对上面的问题,即便我们想不到该用什么设计模式来重构,也应该能知道该如何解决,那就是将 Sorter 类中的某些代码拆分出来,独立成职责更加单一的小类。实际上,拆分是应对类或者函数代码过多、应对代码复杂性的一个常用手段。按照这个解决思路,我们对代码进行重构。重构之后的代码如下所示:
public interface ISortAlg {void sort(String filePath);
}
public class QuickSort implements ISortAlg {@Overridepublic void sort(String filePath) {//...}
}
public class ExternalSort implements ISortAlg {@Overridepublic void sort(String filePath) {//...}
}
public class ConcurrentExternalSort implements ISortAlg {@Overridepublic void sort(String filePath) {//...}
}
public class MapReduceSort implements ISortAlg {@Overridepublic void sort(String filePath) {//...}
}
public class Sorter {private static final long GB = 1000 * 1000 * 1000;public void sortFile(String filePath) {// 省略校验逻辑File file = new File(filePath);long fileSize = file.length();ISortAlg sortAlg;if (fileSize < 6 * GB) { // [0, 6GB)sortAlg = new QuickSort();} else if (fileSize < 10 * GB) { // [6GB, 10GB)sortAlg = new ExternalSort();} else if (fileSize < 100 * GB) { // [10GB, 100GB)sortAlg = new ConcurrentExternalSort();} else { // [100GB, ~)sortAlg = new MapReduceSort();}sortAlg.sort(filePath);}
}
经过拆分之后,每个类的代码都不会太多,每个类的逻辑都不会太复杂,代码的可读性、可维护性提高了。除此之外,我们将排序算法设计成独立的类,跟具体的业务逻辑(代码中的 if-else 那部分逻辑)解耦,也让排序算法能够复用。这一步实际上就是策略模式的第一步,也就是将策略的定义分离出来。
实际上,上面的代码还可以继续优化。每种排序类都是无状态的,我们没必要在每次使用的时候,都重新创建一个新的对象。所以,我们可以使用工厂模式对对象的创建进行封装。按照这个思路,我们对代码进行重构。重构之后的代码如下所示:
public class SortAlgFactory {private static final Map<String, ISortAlg> algs = new HashMap<>();static {algs.put("QuickSort", new QuickSort());algs.put("ExternalSort", new ExternalSort());algs.put("ConcurrentExternalSort", new ConcurrentExternalSort());algs.put("MapReduceSort", new MapReduceSort());}public static ISortAlg getSortAlg(String type) {if (type == null || type.isEmpty()) {throw new IllegalArgumentException("type should not be empty.");}return algs.get(type);}
}
public class Sorter {private static final long GB = 1000 * 1000 * 1000;public void sortFile(String filePath) {// 省略校验逻辑File file = new File(filePath);long fileSize = file.length();ISortAlg sortAlg;if (fileSize < 6 * GB) { // [0, 6GB)sortAlg = SortAlgFactory.getSortAlg("QuickSort");} else if (fileSize < 10 * GB) { // [6GB, 10GB)sortAlg = SortAlgFactory.getSortAlg("ExternalSort");} else if (fileSize < 100 * GB) { // [10GB, 100GB)sortAlg = SortAlgFactory.getSortAlg("ConcurrentExternalSort");} else { // [100GB, ~)sortAlg = SortAlgFactory.getSortAlg("MapReduceSort");}sortAlg.sort(filePath);}
}
经过上面两次重构之后,现在的代码实际上已经符合策略模式的代码结构了。我们通过策略模式将策略的定义、创建、使用解耦,让每一部分都不至于太复杂。不过,Sorter 类中的 sortFile() 函数还是有一堆 if-else 逻辑。这里的 if-else 逻辑分支不多、也不复杂,这样写完全没问题。但如果你特别想将 if-else 分支判断移除掉,那也是有办法的。我直接给出代码,你一看就能明白。实际上,这也是基于查表法来解决的,其中的“algs”就是“表”。
public class Sorter {private static final long GB = 1000 * 1000 * 1000;private static final List<AlgRange> algs = new ArrayList<>();static {algs.add(new AlgRange(0, 6*GB, SortAlgFactory.getSortAlg("QuickSort")));algs.add(new AlgRange(6*GB, 10*GB, SortAlgFactory.getSortAlg("ExternalSort")));algs.add(new AlgRange(10*GB, 100*GB, SortAlgFactory.getSortAlg("ConcurrentExternalSort")));algs.add(new AlgRange(100*GB, Long.MAX_VALUE, SortAlgFactory.getSortAlg("MapReduceSort")));}public void sortFile(String filePath) {// 省略校验逻辑File file = new File(filePath);long fileSize = file.length();ISortAlg sortAlg = null;for (AlgRange algRange : algs) {if (algRange.inRange(fileSize)) {sortAlg = algRange.getAlg();break;}}sortAlg.sort(filePath);}private static class AlgRange {private long start;private long end;private ISortAlg alg;public AlgRange(long start, long end, ISortAlg alg) {this.start = start;this.end = end;this.alg = alg;}public ISortAlg getAlg() {return alg;}public boolean inRange(long size) {return size >= start && size < end;}}
}
现在的代码实现就更加优美了。我们把可变的部分隔离到了策略工厂类和 Sorter 类中的静态代码段中。当要添加一个新的排序算法时,我们只需要修改策略工厂类和 Sort 类中的静态代码段,其他代码都不需要修改,这样就将代码改动最小化、集中化了。
你可能会说,即便这样,当我们添加新的排序算法的时候,还是需要修改代码,并不完全符合开闭原则。有什么办法让我们完全满足开闭原则呢?
对于 Java 语言来说,我们可以通过反射来避免对策略工厂类的修改。具体是这么做的:我们通过一个配置文件或者自定义的 annotation 来标注都有哪些策略类;策略工厂类读取配置文件或者搜索被 annotation 标注的策略类,然后通过反射了动态地加载这些策略类、创建策略对象;当我们新添加一个策略的时候,只需要将这个新添加的策略类添加到配置文件或者用 annotation 标注即可。还记得上一节课的课堂讨论题吗?我们也可以用这种方法来解决。
对于 Sorter 来说,我们可以通过同样的方法来避免修改。我们通过将文件大小区间和算法之间的对应关系放到配置文件中。当添加新的排序算法时,我们只需要改动配置文件即可,不需要改动代码。
重点回顾
好了,今天的内容到此就讲完了。我们一块来总结回顾一下,你需要重点掌握的内容。
一提到 if-else 分支判断,有人就觉得它是烂代码。如果 if-else 分支判断不复杂、代码不多,这并没有任何问题,毕竟 if-else 分支判断几乎是所有编程语言都会提供的语法,存在即有理由。遵循 KISS 原则,怎么简单怎么来,就是最好的设计。非得用策略模式,搞出 n 多类,反倒是一种过度设计。
一提到策略模式,有人就觉得,它的作用是避免 if-else 分支判断逻辑。实际上,这种认识是很片面的。策略模式主要的作用还是解耦策略的定义、创建和使用,控制代码的复杂度,让每个部分都不至于过于复杂、代码量过多。除此之外,对于复杂代码来说,策略模式还能让其满足开闭原则,添加新策略的时候,最小化、集中化代码改动,减少引入 bug 的风险。
实际上,设计原则和思想比设计模式更加普适和重要。掌握了代码的设计原则和思想,我们能更清楚的了解,为什么要用某种设计模式,就能更恰到好处地应用设计模式。
课堂讨论
- 在过去的项目开发中,你有没有用过策略模式,都是为了解决什么问题才使用的?
- 你可以说一说,在什么情况下,我们才有必要去掉代码中的 if-else 或者 switch-case 分支逻辑呢?
相关文章:
:如何实现一个支持给不同大小文件排序的小程序?)
【设计模式与范式:行为型】61 | 策略模式(下):如何实现一个支持给不同大小文件排序的小程序?
上一节课,我们主要介绍了策略模式的原理和实现,以及如何利用策略模式来移除 if-else 或者 switch-case 分支判断逻辑。今天,我们结合“给文件排序”这样一个具体的例子,来详细讲一讲策略模式的设计意图和应用场景。 除此之外&…...
【C++】auto_ptr为何被唾弃?以及其他智能指针的学习
搭配异常可以让异常的代码更简洁 文章目录 智能指针 内存泄漏的危害 1.auto_ptr(非常不建议使用) 2.unique_ptr 3.shared_ptr 4.weak_ptr总结 智能指针 C中为什么会需要智能指针呢?下面我们看一下样例: int div() {int a, b;cin >&g…...

数据结构练习题1:基本概念
练习题1:基本概念 1 抽象数据类型概念分析2. 逻辑结构与存储结构概念分析3.综合选择题4.综合判断题5.时间复杂度相关习题6 时间复杂度计算方法(一、二、三层循环) 1 抽象数据类型概念分析 1.可以用(抽象数据类型)定义…...

如何消除Msxml2.XMLHTTP组件的缓存
之前使用这个组件,是每隔十分钟取数据,没有遇到这个缓存问题, 这次使用它是频繁访问接口,就出现了一直不变的问题。觉得是缓存没有清除的问题。 网上搜了一些方案。最好的方案就是给url地址末尾给一个随机参数。用于让组件觉得是…...
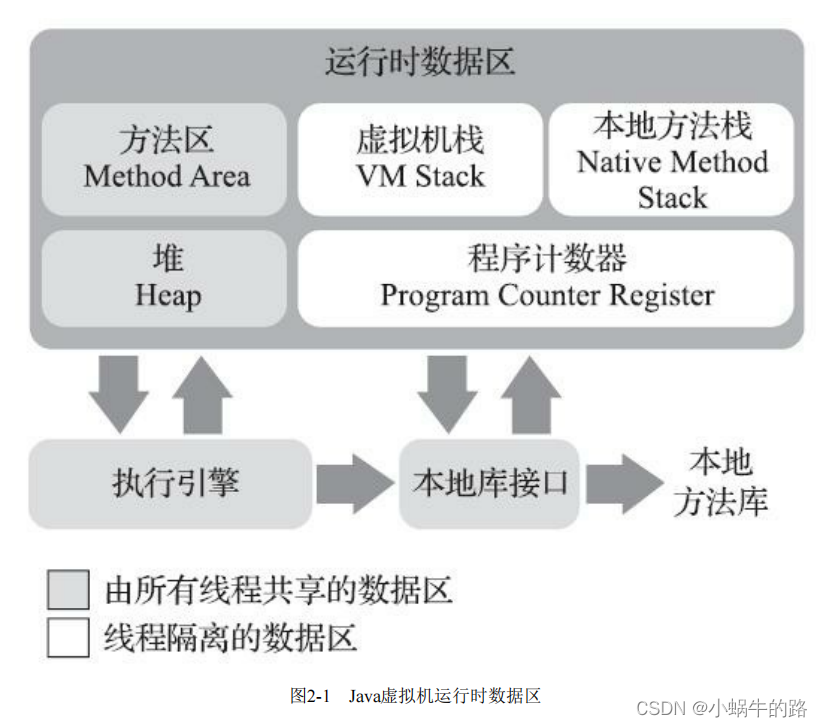
深入理解Java虚拟机jvm-运行时数据区域(基于OpenJDK12)
运行时数据区域 运行时数据区域程序计数器Java虚拟机栈本地方法栈Java堆方法区运行时常量池直接内存 运行时数据区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的…...
 基础demo)
(OpenCV) 基础demo
文章目录 前言Demo图片录制播放人脸识别 END 前言 OpenCV - Open Computer Vision Library OpenCV的名声想必不用多说了。 本文介绍4个基础使用demo。分别为,显示图片,录制视频,播放视频和一个基于开源算法库的人脸识别小demo。 只要环境…...

using 的使用
作者: 苏丙榅 链接: https://subingwen.cn/cpp/using/ 在 C 中 using 用于声明命名空间,使用命名空间也可以防止命名冲突。在程序中声明了命名空间之后,就可以直接使用命名空间中的定义的类了。在 C11 中赋予了 using 新的功能,让C变得更年轻…...

Websocket、Socket、HTTP之间的关系
Websocket、Socket、HTTP之间的关系 ★ Websocket是什么?★ Websocket的原理★ websocket具有以下特点:★ webSocket可以用来做什么?★ websocket与socket区别:★ WebSocket与HTTP区别 ★ Websocket是什么? ● Websocket是HTML5下…...

hustoj LiveCD版系统在局域网虚拟机安装和配置
root权限 打开terminal命令行输入sudo su输入初始密码freeproblemsetmysql数据库的密码的位置,如何登陆数据库 数据库账号密码存放在两个配置文件中: /home/judge/etc/judge.conf/home/judge/src/web/include/db_info.inc.php 新版本中,快…...

读书-代码整洁之道10-14
类 类的三大特性:封装、继承、多态;类应该短小;单一权责原则认为,类或模块应有且只有一条加以修改的理由;当类丧失了内聚性,就拆分它;隔离修改 系统 构造和使用是非常不一样的过程。每个应用…...

UDP 广播/组播
广播UDP与单播UDP的区别就是IP地址不同,广播使用广播地址xxx.xxx.xxx.255,将消息发送到在同一广播网络上的每个主机,广播/组播只能用udp进行实现 函数:int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_topt…...

高效创作助手:ChatGPT最新版实现批量撰写聚合文章的全新水平
随着人工智能技术的不断发展,ChatGPT最新版作为一款智能创作助手,实现了批量撰写聚合文章的全新水平。它能够在短时间内生成高质量的文章,极大地提高了创作效率。本文将从随机8-20个方面对ChatGPT最新版进行详细的阐述,让我们一起…...

Python中的包是什么,如何创建和使用包?
在Python中,包是一种将相关模块分组在一起的方式。它可以让我们更好地组织和重用代码。 一个Python包实际上是一个文件夹,其中包含该包的Python模块和其他资源文件(例如配置文件、数据文件等)。包的根目录通常包含一个名为__init…...
Spring Cloud Alibaba Seata(二)
目录 一、Seata 1、Seata-AT模式 1.1、具体案例 1.2、通过Seata的AT模式解决分布式事务 2、Seata-XA模式 3、Seata-TCC模式 4、Seata-SAGA模式 一、Seata 1、Seata-AT模式 概念:AT模式是一种无侵入的分布式事务解决方案,在 AT 模式下,…...

如何在 MySQL 中使用 COALESCE 函数
1. 简介 在 MySQL 中,COALESCE 函数可以用来返回参数列表中的第一个非空值。如果所有参数都为空,则返回 NULL。本文将介绍 COALESCE 函数的语法和用法,并通过示例演示其效果。 2. 语法 COALESCE 函数的语法如下所示: COALESCE(…...
——初识分布式爬虫scrapy_redis)
Python爬虫之Scrapy框架系列(22)——初识分布式爬虫scrapy_redis
目录: 分布式爬虫(Scrapy\_redis):1.简单介绍:2.Scrapy_redis的安装:分布式爬虫(Scrapy_redis): 官方文档:https://scrapy-redis.readthedocs.io/en/stable/1.简单介绍: scrapy_redis是一个基于Redis的Scrapy组件,用于scrapy项目的分布式部署和开发。 特点: 分布…...
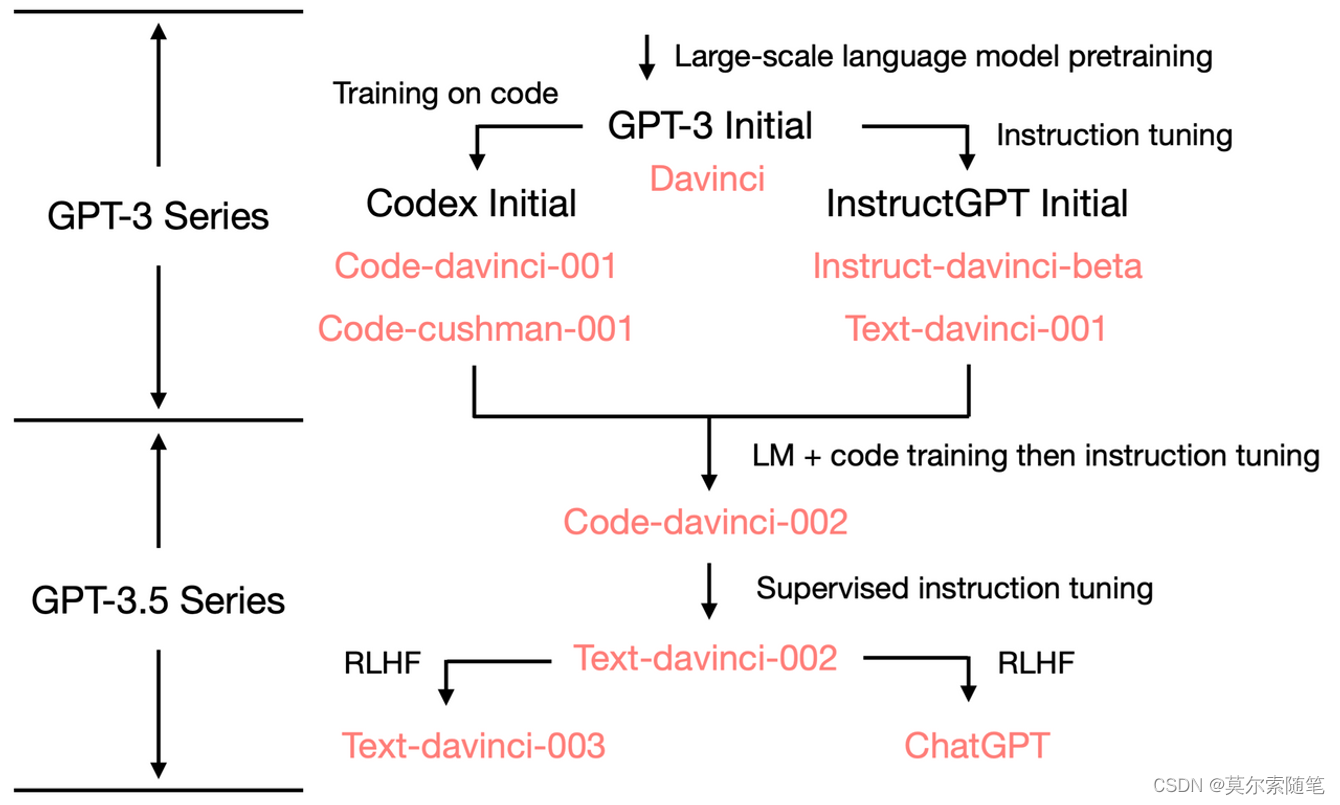
ChatGPT的前世今生
原文首发于博客文章ChatGPT发展概览 ChatGPT 是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出。该程序使用基于 GPT-3.5、GPT-4 架构的大语言模型并以强化学习训练。ChatGPT目前仍以文字方式交互,而除了可以用人类自然对话方式来交互,…...
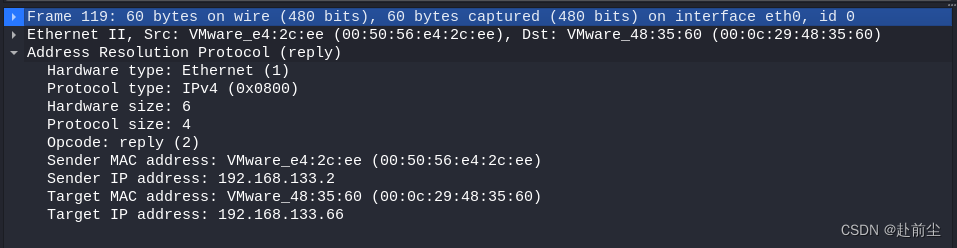
WireShark常用协议抓包与原理分析
1.ARP协议(地址解析协议) nmap 发现网关nmap -sn 192.168.133.2wireshark 抓请求包和响应包 arp请求包内容 arp响应包内容 总结:请求包包含包类型(request),源IP地址,源MAC地址,目标IP地址,目标MAC地址(未知,此处为全0);响应包包含包类型(reply),源IP地址,源…...
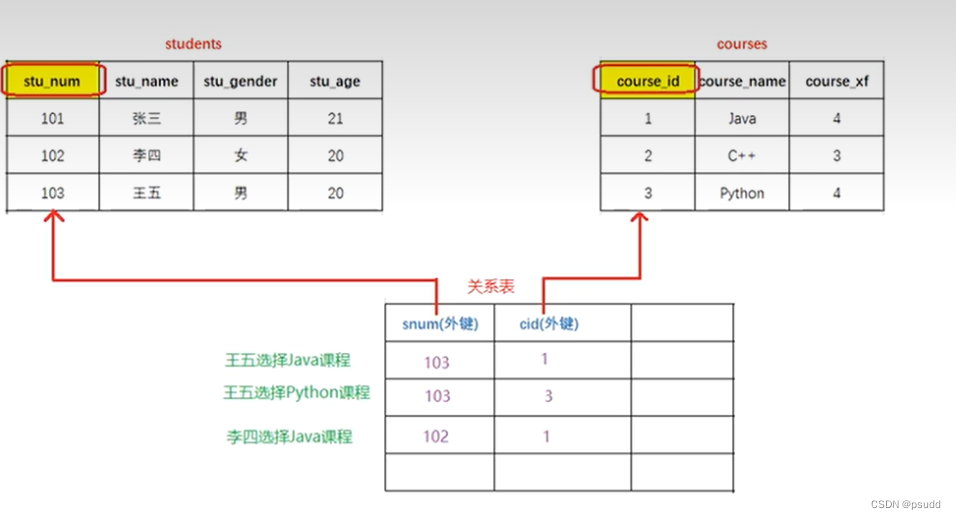
Mysql数据库操作总结
文章目录 1. DDL(Data Definition Language - 数据定义语言)1.1 数据库1.2 数据表(创建查询删除)1.3 数据表(修改) 2. 数据类型2.1 数值2.2 字符2.3 日期 3. 字段约束3.1 约束3.2 主键约束修改3.3 主键自增 联合主键 4. DML(Data Manipulation Language - 数据操作语言)4.1 添…...

在 ZBrush、Substance 3D Painter 和 UE5 中创作警探角色(P2)
大家好,下篇分享咱们继续来说警探角色的重新拓扑、UV、材质贴图和渲染处理。 重新拓扑/UV 这是对我来说最不有趣的部分——重新拓扑。它显然是实时角色中非常重要的一部分,不容忽视,因为它会影响大量的 UV、绑定和后期渲染,这里…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案
TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作不便而烦恼吗?…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...