第三章 仅支持追加的单表内存数据库
第三章 仅支持追加的单表内存数据库
我们将从小处着手,对数据库施加很多限制。目前,它有如下限制:
-
支持两种操作:插入一行和打印所有行
-
仅驻留在内存中(不需要持久化到磁盘)
-
支持单个硬编码表
我们的硬编码用户表结构如下所示:
| 列名 | 类型 |
|---|---|
| id | integer |
| username | varchar(32) |
| varchar(255) |
这是一个简单的架构,但它要求我们能够支持多种数据类型和多种大小的文本数据类型。
insert 语句现在需按照如下格式编写:
insert 1 cstack foo@bar.com
这意味着我们需要升级我们的 prepare_statement 函数来解析参数.
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email);
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }return PREPARE_SUCCESS;}
我们将这些解析的参数存储到语句对象内的新 Row 数据结构中:
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+typedef struct {StatementType type;
+ Row row_to_insert; // only used by insert statement} Statement;
现在我们需要将该数据复制到表示表的某个数据结构中。SQLite使用B树进行快速查找,插入和删除。我们将从更简单的东西开始。像B树一样,它会将行分组到页面中,但不是将这些页面排列为树,而是将它们排列为一个数组。
以下是实现细节:
-
将行存储在称为页的内存块中
-
每个页面存储尽可能多的行
-
行被序列化为每页的紧凑表示形式
-
按需分配页面
-
保留指向页面的固定大小的指针数组
我们先定义行的序列化表示(我们将行序列化到内存的某个地址里):
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)#define ID_SIZE size_of_attribute(Row, id)
#define USERNAME_SIZE size_of_attribute(Row, username)
#define EMAIL_SIZE size_of_attribute(Row, email)
#define ID_OFFSET (uint32_t)0
#define USERNAME_OFFSET (ID_OFFSET + ID_SIZE)
#define EMAIL_OFFSET (USERNAME_OFFSET + USERNAME_SIZE)
#define ROW_SIZE (ID_SIZE + USERNAME_SIZE + EMAIL_SIZE)#define PAGE_SIZE 4096
#define TABLE_MAX_PAGES 100
#define ROWS_PER_PAGE (PAGE_SIZE / ROW_SIZE)
#define TABLE_MAX_ROWS (ROWS_PER_PAGE * TABLE_MAX_PAGES)
序列化后的行结构将如下所示:
| 列名 | 类型 | offset |
|---|---|---|
| id | integer | 0 |
| username | varchar(32) | 4 |
| varchar(255) | 36 | |
| total | 291 |
我们还需要代码来进行序列化和反序列化转换。
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void* source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
接下来,一个 Table 指向行页并跟踪行数的结构:
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
我将页面大小设为 4 KB,因为它与大多数计算机体系结构的虚拟内存系统中使用的页面大小相同。这意味着我们数据库中的一页对应于操作系统使用的一个页面。操作系统会将页面作为整个单元移入和移出内存,而不是分解它们。
我添加了一个随意的限制,即我们最多分配 100 页。当我们切换到树结构时,数据库的最大大小将仅受文件最大大小的限制。(尽管我们仍然会限制一次在内存中保留的页面数)。
由于页面在内存中可能不会彼此相邻存在,为了使读取/写入行变得更加容易,我们假设行不应跨越页面边界。
以下是我们如何确定特定行在内存中读取/写入的位置:
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void* page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
现在我们可以根据表结构使用 execute_statement进行读/写操作:
-void execute_statement(Statement* statement) {
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table* table) {switch (statement->type) {case (STATEMENT_INSERT):
- printf("This is where we would do an insert.\n");
- break;
+ return execute_insert(statement, table);case (STATEMENT_SELECT):
- printf("This is where we would do a select.\n");
- break;
+ return execute_select(statement, table);}}
最后,我们需要初始化表,创建相应的内存释放函数并处理更多错误情况:
+ Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
int main(int argc, char* argv[]) {
+ Table* table = new_table();InputBuffer* input_buffer = new_input_buffer();while (true) {print_prompt();
@@ -105,13 +203,22 @@ int main(int argc, char* argv[]) {switch (prepare_statement(input_buffer, &statement)) {case (PREPARE_SUCCESS):break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;case (PREPARE_UNRECOGNIZED_STATEMENT):printf("Unrecognized keyword at start of '%s'.\n",input_buffer->buffer);continue;}- execute_statement(&statement);
- printf("Executed.\n");
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
+ }}}
通过这些更改,我们实际上可以将数据保存在数据库中!
PS D:\code\db021\code> make
gcc -g -O0 main.c -o db
PS D:\code\db021\code> .\db.exe
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 bob bob@example.com
Executed.
db > select
(1, cstack, foo@bar.com)
(2, bob, bob@example.com)
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
PS D:\code\db021\code>
现在我们可以基于当前代码编写一些测试用例,原因如下:
-
我们计划大幅改变存储表的数据结构,测试将捕获回归。
-
有几个边缘情况我们没有手动测试(例如填满表格)
我们将在下一部分中解决这些问题。
相关文章:

第三章 仅支持追加的单表内存数据库
第三章 仅支持追加的单表内存数据库 我们将从小处着手,对数据库施加很多限制。目前,它有如下限制: 支持两种操作:插入一行和打印所有行 仅驻留在内存中(不需要持久化到磁盘) 支持单个硬编码表 我们的硬…...

抖音seo矩阵系统源码解析
抖音SEO矩阵系统源码是一种用于优化抖音视频内容的工具,可以帮助用户提高抖音视频的搜索排名和流量,从而增加视频曝光和转化率。该系统包括两部分,即数据收集和分析模块以及SEO策略和实施模块。 数据收集和分析模块主要负责从抖音平台上收集…...

6个ChatGPT4的最佳用途
文章目录 ChatGPT 4’s Current Limitations ChatGPT 4 的当前限制1. Crafting Complex Prompts 制作复杂的提示2. Logic Problems 逻辑问题3. Verifying GPT 3.5 Text 验证 GPT 3.5 文本4. Complex Coding 复杂编码5.Nuanced Text Transformation 细微的文本转换6. Complex Kn…...
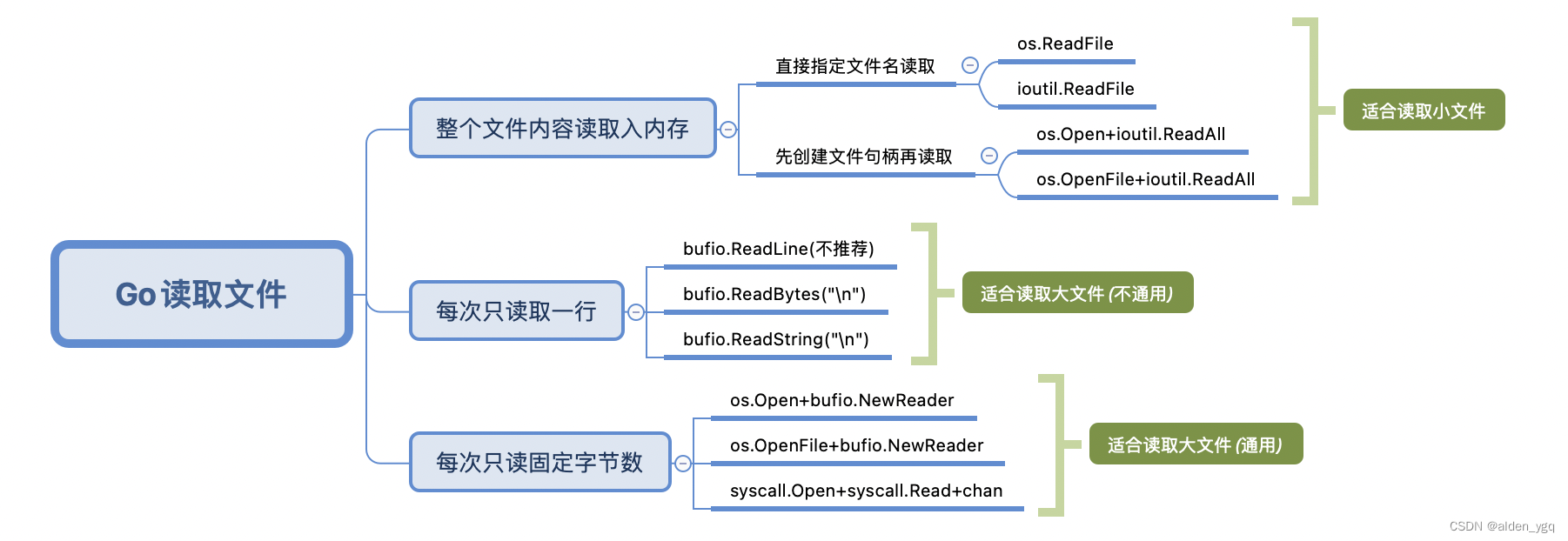
go系列-读取文件
1 概述 2 整个文件读入内存 直接将数据直接读取入内存,是效率最高的一种方式,但此种方式,仅适用于小文件,对于大文件,则不适合,因为比较浪费内存。 2.1 直接指定文化名读取 在 Go 1.16 开始,i…...

10 编码转换问题
文章目录 字符编码问题编码转换问题ANSI转UnicodeUnicode转ANSIUtf8转 ANSIutf8 转UnicodeANSI 转UTF-8Unicode 转 UTF-8 全部代码 字符编码问题 Windows API 函数 MessageBoxA:MessageBox 内部实现,字符串编码(ANSI)转换成了Unicode,在调用MessageboxW MessageBox:…...
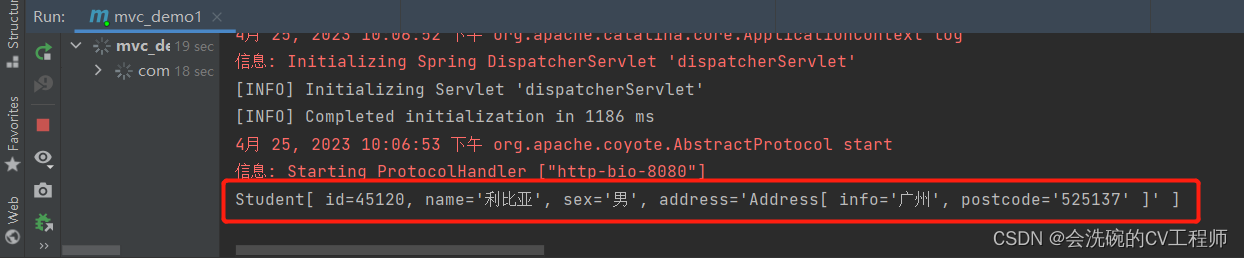
Spring MVC获取参数和自定义参数类型转换器及编码过滤器
目录 一、使用Servlet原生对象获取参数 1.1 控制器方法 1.2 测试结果 二、自定义参数类型转换器 2.1 编写类型转换器类 2.2 注册类型转换器对象 2.3 测试结果 三、编码过滤器 3.1 JSP表单 3.2 控制器方法 3.3 配置过滤器 3.4 测试结果 往期专栏&文章相关导读…...

理想的实验
1.关于“问题”的问题 一项研究计划可以围绕四个基本问题(frequently asked questions,FAQ)展开: 研究对象间的(因果)关系(relationship of interest) 这里更关注的是“因果关系”,…...

nginx配置开机启动(Windows环境)
文章目录 1、下载nginx,并解压2、配置nginx.conf,并启动Nginx3、开机自启动 1、下载nginx,并解压 2、配置nginx.conf,并启动Nginx 两种方法: 方法一:直接双击nginx.exe,双击后一个黑色弹窗一闪…...
)
MySQL 基础面试题02(事务索引)
1.什么是 MySQL 事务? MySQL 事务是指一组操作,是一个不可分割的工作单位,可以确保一组数据库操作要么全部执行,要么全部不执行。换句话说,事务是 MySQL 中保证数据一致性和完整性的机制。 在 MySQL 中,事…...
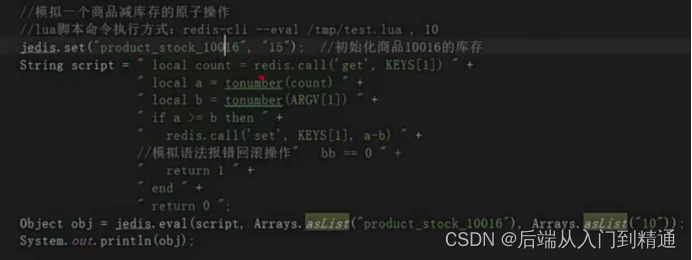
主从架构lua脚本-Redis(四)
上篇文章介绍了rdb、aof持久化。 持久化RDB/AOF-Redis(三)https://blog.csdn.net/ke1ying/article/details/131148269 redis数据备份策略 写job每小时copy一份到其他目录。目录里可以保留最近一个月数据。把目录日志保存到其他服务器,防止机…...

maven与idea版本适配问题
maven与idea版本适配问题 1.版本对应关系——3.6.3 注意:针对一些老项目 还是尽量采用 3.6.3版本,针对idea各个版本的兼容性就很兼容 0.IDEA 2022 兼容maven 3.8.1及之前的所用版本 1.IDEA 2021 兼容maven 3.8.1及之前的所用版本 2.IDEA 2020 兼容Mave…...

ChatGPT扫盲知识库
本文并不是教你如何使用ChatGPT,而是帮助小白理清一些与ChatGPT相关的概念,并解释一些常见的问题。 概念 OpenAI: 一家人工智能公司,ChatGPT属于该公司的产品之一。前身是一个非盈利组织,不过目前已经转变为一家商业公司。 GPT: O…...

chatgpt赋能python:Python轨迹可视化:用数据讲故事
Python轨迹可视化:用数据讲故事 介绍 随着物联网、智能城市等领域的发展,越来越多的数据被收集下来并存储在数据库中。这些数据对于决策者来说是非常重要的,但是如何将这些数据进行展示和分析呢?这时候Python轨迹可视化就可以派…...

K-means
K-means 主要缺点:对于高维度数据,用kmeans方法可能会受到数据形态的影响,其假设高维数据呈球形分布。...
)
归并排序(基础+提升)
目录 归并排序的理论知识 归并排序的实现 merge函数 递归实现 递归改非递归 归并排序的性能分析 题目强化 题目一:小和问题 题目二:求数组中的大两倍数对数量 题目三:LeetCode_327. 区间和的个数 归并排序的理论知识 归并排序&…...

MATLAB应用
目录 网站 智能图像色彩缩减和量化 网站 https://yarpiz.com/ 智能图像色彩缩减和量化 使用智能聚类方法:(a)k均值算法,(b)模糊c均值聚类(FCM)和(c)自组织神…...

LeetCode --- 1784. Check if Binary String Has at Most One Segment of Ones 解题报告
Given a binary string s without leading zeros, return true if s contains at most one contiguous segment of ones. Otherwise, return false. Example 1: Input: s = "1001" Output: false Explanation: The ones do not form a contiguous s…...

js:javascript中的事件体系:常见事件、事件监听、事件移除、事件冒泡、事件捕获、事件委托、阻止事件
参考资料 事件介绍Element事件 目录 常见的事件鼠标事件键盘事件Focus events 添加事件监听方式一:addEventListener()(推荐)方式二:事件处理器属性方式三:内联事件处理器(不推荐) 移除监听器方…...

【数据结构】特殊矩阵的压缩存储
🎇【数据结构】特殊矩阵的压缩存储🎇 🌈 自在飞花轻似梦,无边丝雨细如愁 🌈 🌟 正式开始学习数据结构啦~此专栏作为学习过程中的记录🌟 文章目录 🎇【数据结构】特殊矩阵的压缩存储Ἰ…...

在layui中使用vue,使用vue进行页面数据部分数据更新
layui是一款非常优秀的框架,使用也非常的广泛,许多后台管理系统都使用layui,简单便捷,但是在涉及页面部分数据变化,就比较难以处理,比如一个页面一个提交页,提交之后部分数据实时进行更新&#…...

Qwen3-14B日志分析教程:ELK栈收集推理请求、响应、错误全链路追踪
Qwen3-14B日志分析教程:ELK栈收集推理请求、响应、错误全链路追踪 1. 为什么需要日志分析 当你在私有化部署Qwen3-14B模型时,可能会遇到各种问题:为什么推理速度突然变慢了?为什么API返回了错误响应?哪些请求消耗了最…...

CryptoJS不同加密模式对比:AES-CBC vs GCM在前端安全中的选择指南
AES加密模式深度解析:CBC与GCM在前端安全中的实战抉择 前端开发者在处理用户敏感数据时,AES加密已成为标配技术方案。但在具体实施过程中,加密模式的选择往往成为决策难点——是选择经典的CBC模式,还是拥抱更现代的GCM模式&#x…...

基于S7-300与组态王的智能药片装瓶机控制系统优化设计
1. 智能药片装瓶机控制系统的核心价值 在制药生产线上,药片装瓶环节看似简单却暗藏玄机。传统的人工装瓶方式不仅效率低下,还容易出现计数错误、交叉污染等问题。我曾在某药企亲眼见过工人因疲劳导致装瓶数量出错,最终整批药品不得不报废的案…...
Transformer 从0到1:注意力机制的数学形式——Query, Key, Value 三元组
# Transformer 从0到1:注意力机制的数学形式——Query, Key, Value 三元组## 1. 引言:从序列建模的困境到注意力机制的诞生在深度学习的发展历程中,处理序列数据(如文本、音频、时间序列)一直是核心挑战之一。早期的循…...

酒精测试仪
简 介: 本文介绍了一款酒精测试仪的使用方法。测试仪开机后需等待15秒预热(数字倒计时),预热结束后对着吹气口吹气3秒即可显示测量结果。实验表明,该仪器灵敏度较高:直接吹气显示11左右,不吹气显…...

IIS请求筛选规则实战:手把手教你用‘拒绝字符串’精准拦截SQL注入和恶意爬虫
IIS请求筛选规则实战:构建精准防御体系的完整指南 当你的网站遭遇SQL注入攻击时,服务器日志里那些可疑的 OR 11--字符串是否让你夜不能寐?面对每天数十万次的恶意爬虫扫描,是否觉得传统的防火墙规则力不从心?IIS的请求…...

深度学习优化算法详解:从 SGD 到 AdamW
深度学习优化算法详解:从 SGD 到 AdamW 1. 背景与动机 优化算法是深度学习训练的核心,选择合适的优化器直接影响模型的收敛速度和最终性能。本文深入分析主流优化算法的原理和适用场景。 2. 梯度下降家族 2.1 SGD import torch import torch.nn as nnopt…...

AppSpider 7.5.025 for Windows - Web 应用程序安全测试
AppSpider 7.5.025 for Windows - Web 应用程序安全测试 Rapid7 Dynamic Application Security Testing (DAST) released March 31, 2026 请访问原文链接:https://sysin.org/blog/appspider/ 查看最新版。原创作品,转载请保留出处。 作者主页…...

告别低效:用快马ai一键生成can总线数据分析与统计脚本
在汽车电子和嵌入式系统开发中,CAN总线数据的分析是个高频需求。无论是调试车载网络问题,还是优化通信性能,都离不开对海量CAN帧数据的处理。但手动写解析脚本不仅耗时,还容易遗漏关键细节。最近我发现用InsCode(快马)平台的AI辅助…...

深圳嵌入式技术产业创新与应用全景
1. 深圳嵌入式科技产业全景扫描 深圳作为中国科技创新高地,已形成全球最完整的嵌入式技术产业链。从消费电子到工业控制,从汽车电子到医疗设备,嵌入式系统正以"润物细无声"的方式重塑各个行业。这座城市聚集了超过2000家嵌入式相关…...