Python 学习之NumPy(一)
文章目录
- 1.为什么要学习NumPy
- 2.NumPy的数组变换以及索引访问
- 3.NumPy筛选使用介绍
- 筛选出上面nb数组中能被3整除的所有数
- 筛选出数组中小于9的所有数
- 提取出数组中所有的奇数
- 数组中所有的奇数替换为-1
- 二维数组交换2列
- 生成数值5—10,shape 为(3,5)的二维随机浮点数
- NumPy数组维度等进阶操作
- NumPy做矩阵乘法实现的两种方法
- NumPy求平均值,求和
- NumPy 求标准差,方差
- NumPy 求最大最小值,累和和累乘
- NumPy求迹
- 高维数组变为向量
- 增加或删除维度的实现方法
1.为什么要学习NumPy
通过一个案例来比较分析numpy和python的数值计算性能
import time
import numpy as nplist = range(int(10e6))tis1 =time.perf_counter()
a = [i*2 for i in list]
tis2 =time.perf_counter()print(tis2-tis1)na = np.array(range(int(10e6)))tis1 =time.perf_counter()
na2 = na * 2
tis2 =time.perf_counter()
print(tis2-tis1)

通过上面的案例 可以看出 NumPy 的数值计算能力比python自带的要快一个数量级,所以NumPy 值得我们学习它。
2.NumPy的数组变换以及索引访问
# 创建一个所有元素为True 二维数组
a = np.ones((3,5)) == 1
print(a)# 创建一个所有元素为Flase 二维数组
b = np.zeros((3,5)) == 1
print(b)#一维数组转二维
na = np.arange(100)
print(na)
nb = na.reshape((20,5))
print(nb)#numpy 索引#访问第一行第一列的元素
print(nb[1,1])#返回第一行数组
print(nb[0])#返回数组的前3行(切片)
print(nb[:3])#返回数组的第一列
print(nb[:,0])#返回数组的前3列
print(nb[:,:3])#返回数组前3行前3列
print(nb[:3,:3])
3.NumPy筛选使用介绍
筛选出上面nb数组中能被3整除的所有数
print(nb[nb % 3 == 0])
筛选出数组中小于9的所有数
print(nb[nb < 9])
提取出数组中所有的奇数
print(nb[nb % 2 != 0])
数组中所有的奇数替换为-1
#numpy 中 where的使用 3个参数 类似 三目运算符 第一个参数是条件表达式 第二个是符合条件表达式的结果 第三个是不符合的结果
print(np.where(nb % 2 == 0, nb, -1))
二维数组交换2列
#交换第一列和第三列
print(nb[:, [0, 3, 2, 1, 4]])mask = list(range(5))
mask[1], mask[3] = mask[3], mask[1]
print(nb[:, mask])
生成数值5—10,shape 为(3,5)的二维随机浮点数
n1 = np.random.randint(5, 10, (3, 5))
print(n1)# 0,1 的二维随机数组
n2 = np.random.rand(3, 5)print(n1 + n2)
NumPy数组维度等进阶操作
NumPy做矩阵乘法实现的两种方法
v1 = np.arange(3).reshape(1, 3)
v2 = np.arange(6).reshape(3, 2)# 点乘
result = np.dot(v1,v2)# 先将数组转化为矩阵
result1 = np.matrix(v1) * np.matrix(v2)print(result)
print(result1)
NumPy求平均值,求和
arr = np.random.randint(1, 10, (3, 4))# 所有数的平均值
arr.mean()# 按照行求平均值
arr.mean(axis=1)# 按照列求平均值
arr.mean(axis=0)#求和
arr.sum(axis=0)
arr.sum(axis=1)
NumPy 求标准差,方差
arr = np.arange(6).reshape(2, 3)# 标准差
print(arr.std(axis = 1))
# 方差
print(arr.var())
NumPy 求最大最小值,累和和累乘
array = np.random.randint(1,50,(3,4))array.max()array.min()# 累和arr = [1,3,5]# 累和后arr = [1,4,9]#累加array.cumsum(axis = 0)# 累乘array.cumprod(axis = 0)NumPy求迹
在Python的NumPy库中,可以使用numpy.trace()函数来计算矩阵的迹(trace)。迹是矩阵对角线上元素的和。
以下是使用NumPy计算矩阵迹的示例代码:
import numpy as np# 创建一个矩阵
matrix = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 计算矩阵的迹
trace = np.trace(matrix)print("矩阵迹:", trace)
输出结果:
矩阵迹: 15
在这个示例中,我们创建了一个3x3的矩阵,然后使用np.trace()函数计算了矩阵的迹。最后,我们将迹的结果打印出来。
注意,numpy.trace()函数只能用于二维矩阵,如果要计算高维矩阵的迹,可以先使用numpy.diagonal()函数提取对角线上的元素,然后再求和。
高维数组变为向量
在NumPy中,可以使用numpy.ravel()函数将多维数组转换为一维向量。这个函数会将数组展平成一个连续的一维数组,并按照行优先的顺序进行展平。
以下是使用numpy.ravel()函数将高维数组变为向量的示例代码:
import numpy as np# 创建一个高维数组
arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 将高维数组展平成向量
vector = np.ravel(arr)print("向量:", vector)
输出结果:
向量: [1 2 3 4 5 6 7 8 9]
在这个示例中,我们创建了一个3x3的高维数组arr,然后使用np.ravel()函数将其展平为一维向量vector。最后,我们将向量打印出来。
除了np.ravel()函数,还可以使用np.flatten()函数实现类似的功能,两者的区别在于np.ravel()函数返回的是数组的视图(view),而np.flatten()函数返回的是数组的副本(copy)。如果不关心返回的是视图还是副本,可以使用np.ravel()函数更高效。
在NumPy中,除了使用numpy.ravel()函数将多维数组展平为一维向量之外,还可以使用numpy.flatten()方法实现相同的功能。这两个方法在展平数组方面是等效的,但它们有一个重要的区别:
numpy.ravel(): 返回一个展平的数组视图(view),如果对返回的视图进行修改,原始数组也会被修改。numpy.flatten(): 返回一个展平的数组副本(copy),对返回的副本进行修改不会影响原始数组。
以下是使用numpy.flatten()方法将高维数组展平为向量的示例代码:
import numpy as np# 创建一个高维数组
arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 将高维数组展平成向量
vector = arr.flatten()print("向量:", vector)
输出结果:
向量: [1 2 3 4 5 6 7 8 9]
在这个示例中,我们使用arr.flatten()方法将高维数组arr展平为一维向量vector,并将结果打印出来。
需要注意的是,无论是numpy.ravel()函数还是numpy.flatten()方法,都会将多维数组展平为一维向量,但返回的是视图或副本的区别可能会对内存管理和性能产生一定的影响。因此,在选择使用哪种方法时,可以根据具体的需求和性能要求来进行选择。
增加或删除维度的实现方法
在NumPy中,可以使用以下方法来增加或删除数组的维度:
-
增加维度:
- 使用
numpy.newaxis或None关键字:可以在指定位置使用np.newaxis或None关键字来增加新的维度。例如,可以通过arr[:, np.newaxis]在二维数组的列维度之间增加一个新维度。
import numpy as np# 创建一个一维数组 arr = np.array([1, 2, 3])# 增加新维度 new_arr = arr[:, np.newaxis]print("新数组的形状:", new_arr.shape)输出结果:
新数组的形状: (3, 1)在这个示例中,我们使用
arr[:, np.newaxis]将一维数组arr在列维度之间增加了一个新维度,得到了形状为(3, 1)的新数组new_arr。- 使用
numpy.expand_dims()函数:该函数可以在指定位置上增加新的维度。第一个参数是输入数组,第二个参数axis是要插入新维度的位置。
import numpy as np# 创建一个一维数组 arr = np.array([1, 2, 3])# 增加新维度 new_arr = np.expand_dims(arr, axis=1)print("新数组的形状:", new_arr.shape)输出结果:
新数组的形状: (3, 1)在这个示例中,我们使用
np.expand_dims(arr, axis=1)将一维数组arr在列维度之间增加了一个新维度,得到了形状为(3, 1)的新数组new_arr。 - 使用
-
删除维度:
- 使用
numpy.squeeze()函数:该函数可以删除长度为1的维度。默认情况下,它将删除所有长度为1的维度,但也可以通过指定axis参数来仅删除特定位置的长度为1的维度。
import numpy as np# 创建一个三维数组 arr = np.array([[[1], [2], [3]]])# 删除维度 new_arr = np.squeeze(arr)print("新数组的形状:", new_arr.shape)输出结果:
新数组的形状: (3,)在这个示例中,我们使用
np.squeeze(arr)删除了长度为1的维度,将原本形状为(1, 3, 1)的三维数组arr转换为形状为(3,)的新数组new_arr。 - 使用
需要注意的是,增加或删除维度时,可以根据具体需求选择合适的方法。numpy.newaxis和None关键字的使用比较灵活,而numpy.expand_dims()和numpy.squeeze()函数更具有可读性
相关文章:
Python 学习之NumPy(一)
文章目录 1.为什么要学习NumPy2.NumPy的数组变换以及索引访问3.NumPy筛选使用介绍筛选出上面nb数组中能被3整除的所有数筛选出数组中小于9的所有数提取出数组中所有的奇数数组中所有的奇数替换为-1二维数组交换2列生成数值5—10,shape 为(3,5)的二维随机浮点数 NumP…...
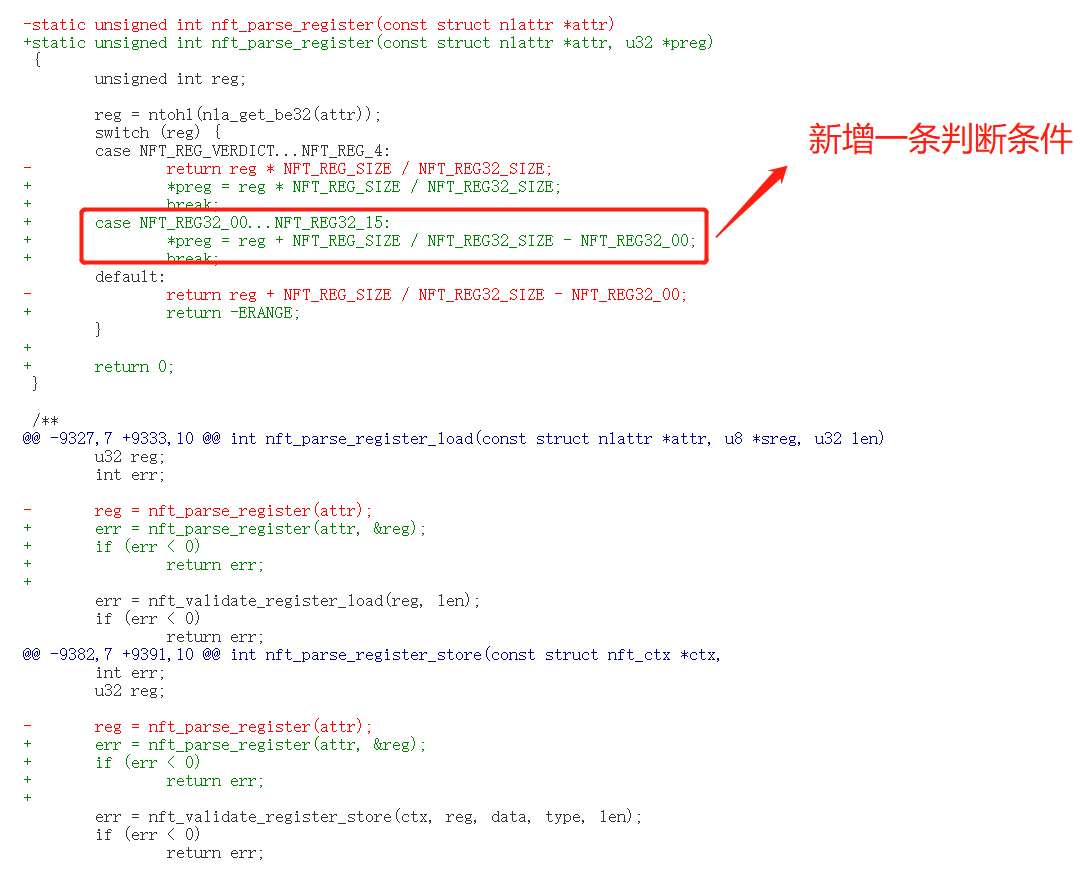
Nftables栈溢出漏洞(CVE-2022-1015)复现
背景介绍 Nftables Nftables 是一个基于内核的包过滤框架,用于 Linux 操作系统中的网络安全和防火墙功能。nftables 的设计目标是提供一种更简单、更灵活和更高效的方式来管理网络数据包的流量。 钩子点(Hook Point) 钩子点的作用是拦截数…...
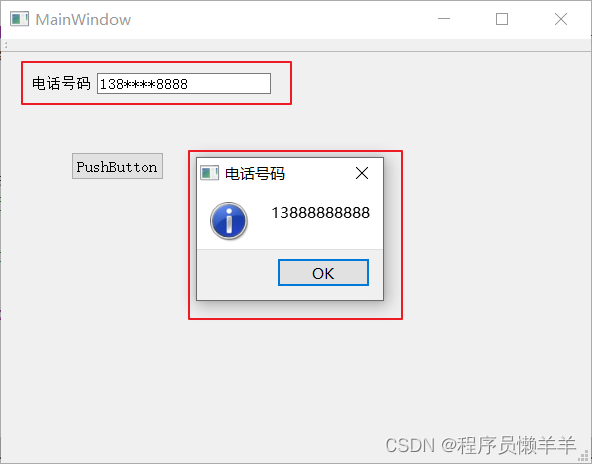
【C++】 Qt-事件(上)(事件、重写事件、事件分发)
文章目录 事件重写事件事件分发 事件 事件(event)是由系统或Qt本身在不同的时刻发出的。比如,当用户按下鼠标,敲下键盘,或窗口需要重新绘制的时候,都会发出一个相应的事件。一些事件是在对用户操作做出响应…...
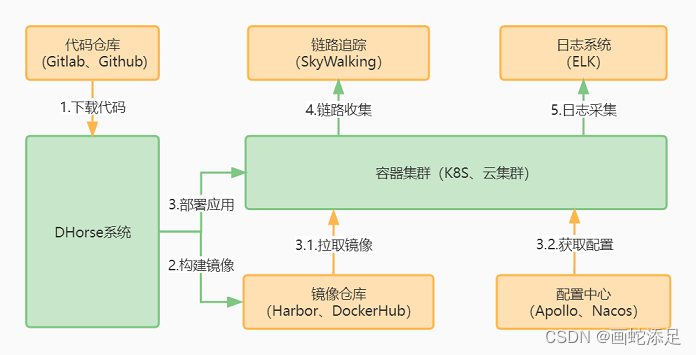
k8s部署springboot
前言 首先以SpringBoot应用为例介绍一下k8s的部署步骤。 1.从代码仓库下载代码,比如GitLab; 2.接着是进行打包,比如使用Maven; 3.编写Dockerfile文件,把步骤2产生的包制作成镜像; 4.上传步骤3的镜像到远程…...

备战秋招002(20230704)
文章目录 前言一、今天学习了什么?二、关于问题的答案1.线程池2.synchronized关键字3、volatile 总结 前言 提示:这里为每天自己的学习内容心情总结; Learn By Doing,Now or Never,Writing is organized thinking. …...

游泳买耳机买什么的比较好,列举几款实战性好的游泳耳机
对于运动用户来说,在运动时都会选择听一些节奏感比较强的音乐,让自己运动是更有活力。现在已经是三伏天中的前伏期间,不少人会选择在三伏天的日子里进行减肥瘦身,耳游泳已经成为很多人都首选运动,游泳是非常好的有氧运…...
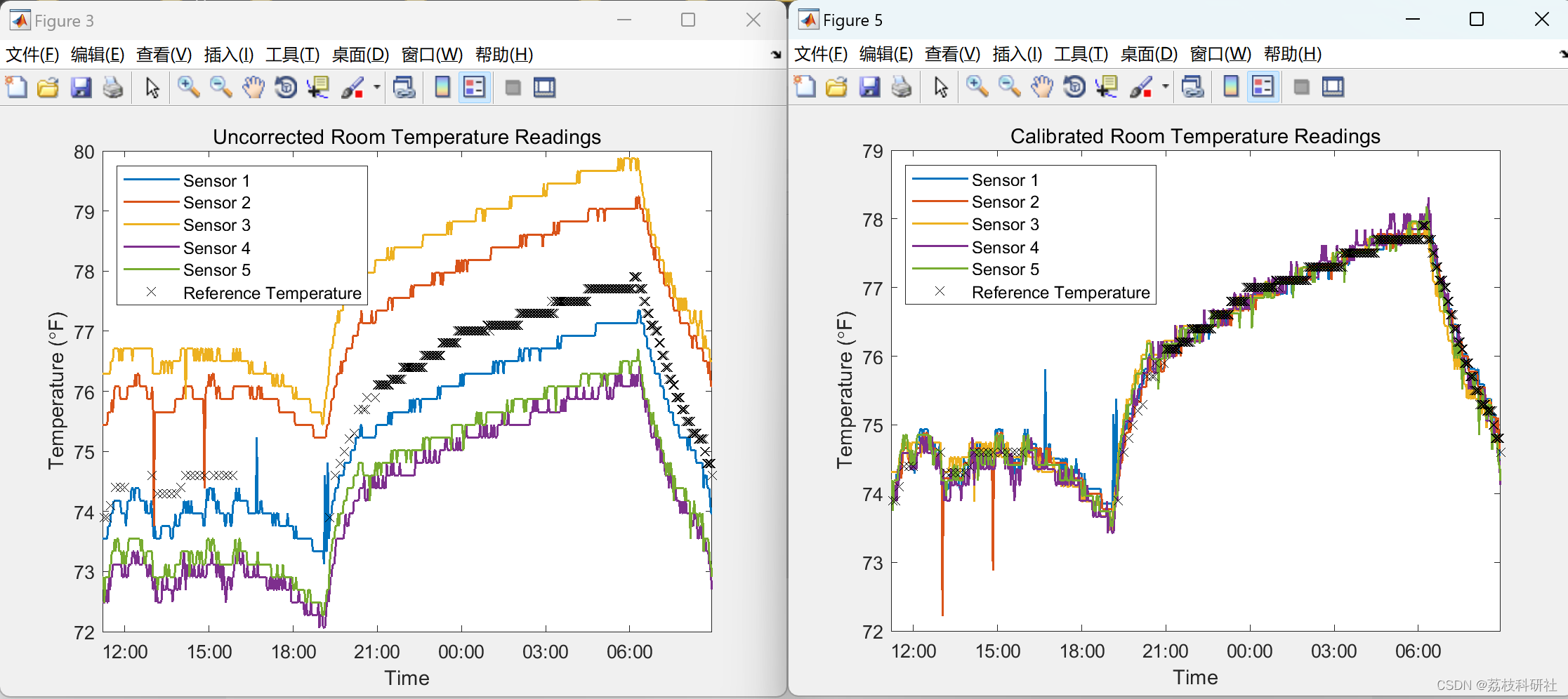
【无线传感器】使用 MATLAB和 XBee连续监控温度传感器无线网络研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Java基础-多线程JUC-生产者和消费者
1. 生产者与消费者 实现线程轮流交替执行的结果; 实现线程休眠和唤醒均要使用到锁对象; 修改标注位(foodFlag); 代码实现: public class demo11 {public static void main(String[] args) {/*** 需求&#…...
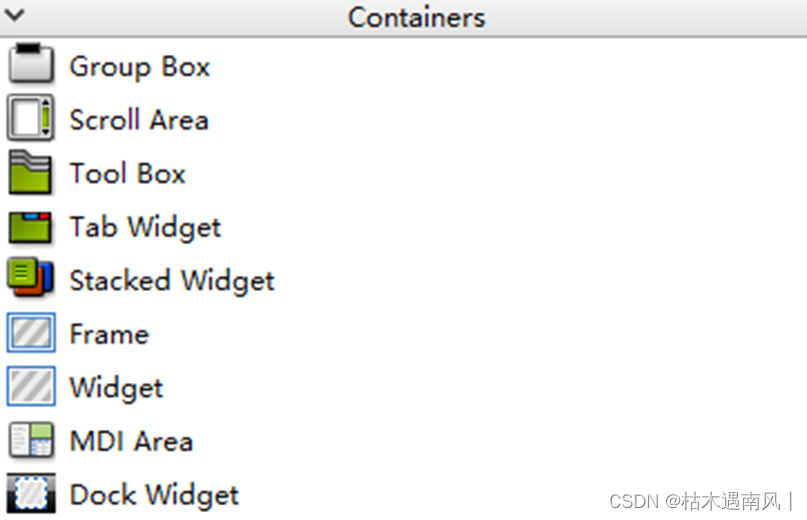
day2 QT按钮与容器
目录 按钮 1、QPushButton 2、QToolButton 3、QRadioButton 4、QCheckBox 示例 容器 编辑 1. QGroupBox(分组框) 2. QScrollArea(滚动区域) 3. QToolBox(工具箱) 4. QTabWidget(选…...
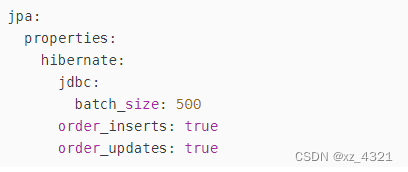
JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题 使用jpa saveAll接口的话需要了解原理: TransactionalOverridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<…...

为啥离不了 linux
Linux与Windows都是十分常见的电脑操作系统,相信你对它们二者都有所了解!在你的使用过程中,是否有什么事让你觉得在Linux上顺理成章,换到Windows上就令你费解?亦或者关于这二者你有任何想要分享的,都可以在…...

基于分形的置乱算法和基于混沌系统的置乱算法哪种更安全?
在信息安全领域中,置乱算法是一种重要的加密手段,它可以将明文进行混淆和打乱,从而实现保密性和安全性。常见的置乱算法包括基于分形的置乱算法和基于混沌系统的置乱算法。下面将从理论和实践两方面,对这两种置乱算法进行比较和分…...

pve使用cloud-image创建ubuntu模板
首先连接pve主机的终端 下载ubuntu22.04的cloud-image镜像 wget -P /opt https://mirrors.cloud.tencent.com/ubuntu-cloud-images/jammy/current/jammy-server-cloudimg-amd64.img创建虚拟机,id设为9000,使用VirtIO SCSI控制器 qm create 9000 -core…...
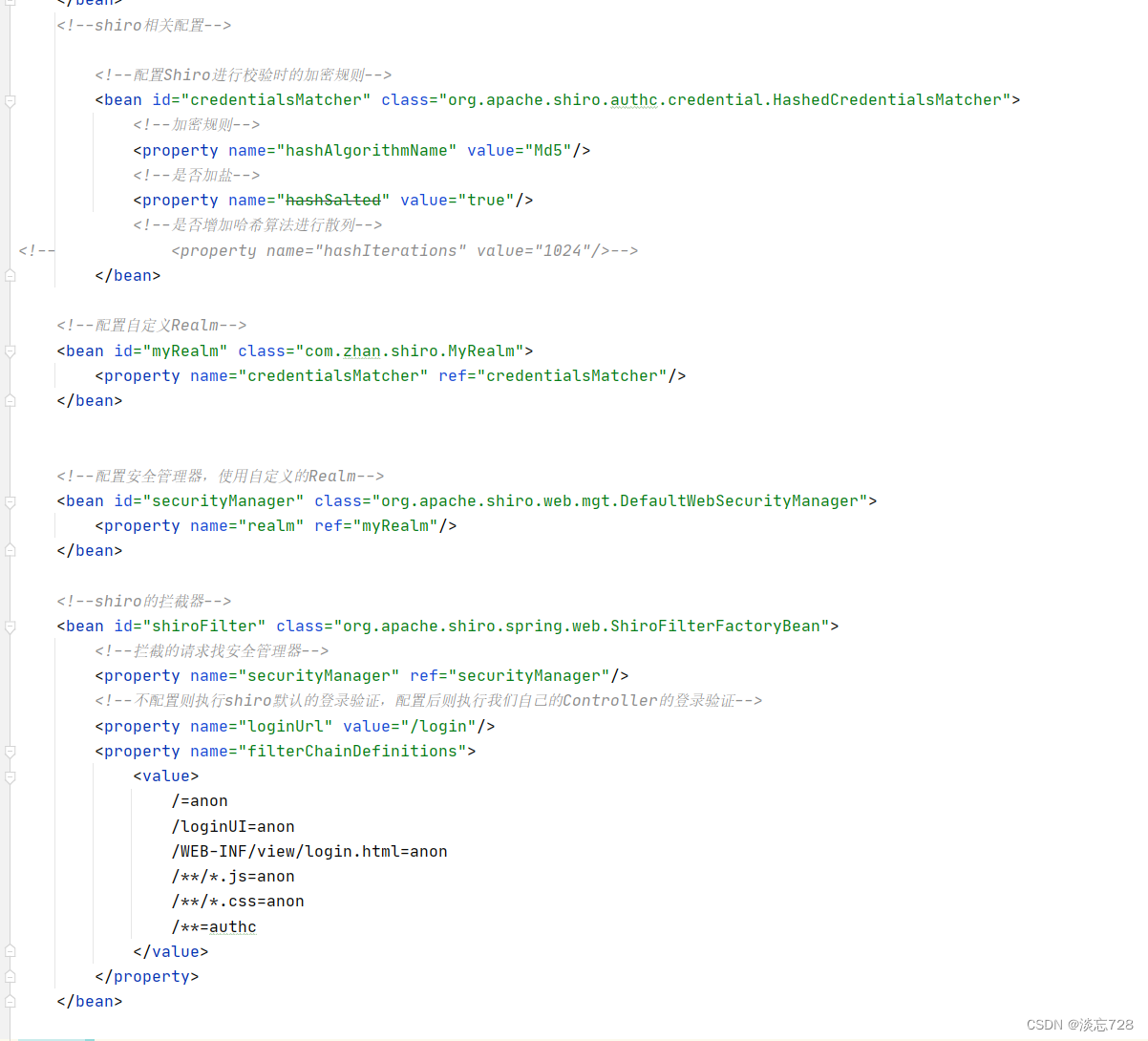
shiro入门
1、概述 Apache Shiro 是一个功能强大且易于使用的 Java 安全(权限)框架。借助 Shiro 您可以快速轻松地保护任何应用程序一一从最小的移动应用程序到最大的 Web 和企业应用程序。 作用:Shiro可以帮我们完成 :认证、授权、加密、会话管理、与 Web 集成、…...
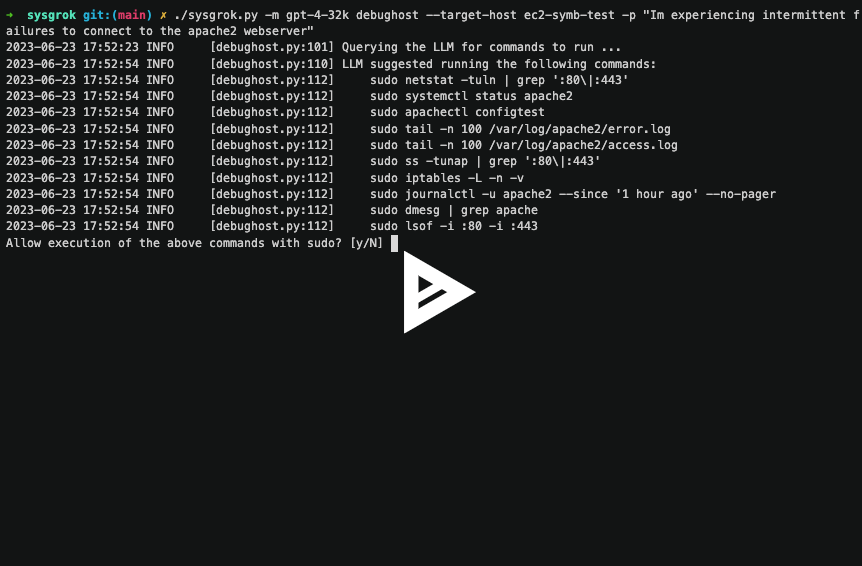
开源 sysgrok — 用于分析、理解和优化系统的人工智能助手
作者:Sean Heelan 在这篇文章中,我将介绍 sysgrok,这是一个研究原型,我们正在研究大型语言模型 (LLM)(例如 OpenAI 的 GPT 模型)如何应用于性能优化、根本原因分析和系统工程领域的问题。 你可以在 GitHub …...
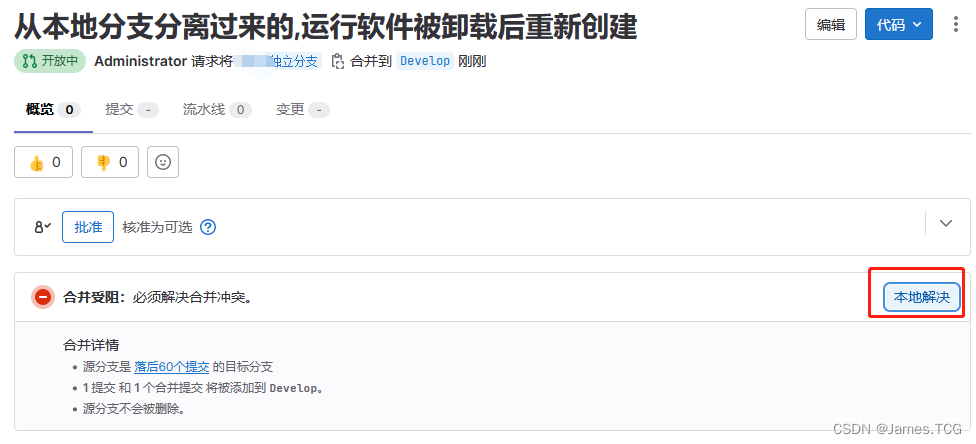
Gitlab保护分支与合并请求
目录 引言 1、成员角色指定 1、保护分支设置 2、合并请求 引言 熟悉了Git工作流之后,有几个重要的分支,如Master(改名为Main)、Develop、Release分支等,是禁止开发成员随意合并和提交的,在此分支上的提交和推送权限仅限项目负责…...

ad18学习笔记九:输出文件
一般来说提供给板卡厂的文件里要包括以下这些文件 1、装配图 2、bom文件 3、gerber文件 4、转孔文件 5、坐标文件 6、ipc网表 AD_PCB:Gerber等各类文件的输出 - 哔哩哔哩 原点|钻孔_硬件设计AD 生成 Gerber 文件 1、装配图 如何输出装配图? 【…...

PostgreSQL 内存配置 与 MemoryContext 的生命周期
PostgreSQL 内存配置与MemoryContext的生命周期 PG/GP 内存配置 数据库可用的内存 gp_vmem 整个 GP 数据库可用的内存 gp_vmem: >>> RAM 128 * GB >>> gp_vmem ((SWAP RAM) - (7.5*GB 0.05 * RAM)) / 1.7 >>> print(gp_vmem / G…...
)
vue3 组件间通信的方式(setup语法糖写法)
vue3 组件间通信的方式(setup语法糖写法) 1. Props方式 该方式用于父传子,父组件以数据绑定的形式声明要传递的数据,子组件通过defineProps()方法创建props对象,即可拿到父组件传来的数据。 // 父组件 <template><div><son…...

【Cache】Rsync远程同步
文章目录 一、rsync 概念二、rysnc 服务器部署1. 环境配置2. rysnc 同步源服务器2.1 安装 rsync2.2 建立 rsyncd.conf 配置文件2.3 创建数据文件(账号密码)2.4 启动服务2.5 数据配置 3. rysnc 客户端3.1 设置同步方法一方法二 3.2 免交互设置 4. rysnc 认…...

LFM2.5-1.2B-Thinking-GGUF开源生态初探:与Ollama等工具的对比与集成
LFM2.5-1.2B-Thinking-GGUF开源生态初探:与Ollama等工具的对比与集成 1. 开源大模型本地部署生态概览 近年来,开源大模型本地部署工具呈现百花齐放的局面。从早期的单一模型加载器,发展到如今功能丰富的模型管理生态系统,开发者…...

[特殊字符] Nano-Banana部署教程:Ubuntu/CentOS环境下的镜像拉取与启动
Nano-Banana部署教程:Ubuntu/CentOS环境下的镜像拉取与启动 1. 项目简介 Nano-Banana是一款专门为产品拆解和平铺展示风格设计的轻量级文本生成图像系统。这个项目的核心在于深度融合了Nano-Banana专属的Turbo LoRA微调权重,专门针对Knolling平铺、爆炸…...

【AI知识点】交叉注意力机制:连接不同世界的“信息桥梁”
1. 从"信息桥梁"理解交叉注意力机制 想象你正在同时阅读一本英文书和它的中文翻译版。当你遇到一个不太理解的英文句子时,会自然地在中文版本中寻找对应的段落来帮助理解——这个过程就像交叉注意力机制在神经网络中的工作方式。它就像是架设在两个不同世…...

LFM2.5-1.2B-Thinking-GGUF部署教程:适配A10/A100/L4等主流GPU显存优化方案
LFM2.5-1.2B-Thinking-GGUF部署教程:适配A10/A100/L4等主流GPU显存优化方案 1. 模型简介与核心优势 LFM2.5-1.2B-Thinking-GGUF 是 Liquid AI 推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用 GGUF 格式存储,配合高效的 llam…...

CodeMaker:让编码效率提升3倍的智能代码生成工具
CodeMaker:让编码效率提升3倍的智能代码生成工具 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 一、核心价值:重新定义开发效率 你是否也曾…...

保姆级教程:用PtitPrince的RainCloud函数,5步搞定分组数据可视化
5步精通RainCloud Plot:用PtitPrince实现专业级分组数据可视化 第一次看到同事用雨云图展示A/B测试结果时,我被这种"既见森林又见树木"的呈现方式震撼了——左侧的密度曲线如山脉般起伏,中间的箱线图标出关键分位点,右侧…...

SAM 3在内容创作中的应用:快速分离图片视频主体,提升剪辑效率
SAM 3在内容创作中的应用:快速分离图片视频主体,提升剪辑效率 1. 引言:内容创作者的痛点与解决方案 在当今内容爆炸的时代,视频创作者和设计师们面临着一个共同的挑战:如何高效地从复杂背景中分离出主体对象。传统方…...

Word转HTML图片处理全攻略:Base64 vs 文件存储的实战对比
Word转HTML图片处理全攻略:Base64 vs 文件存储的实战对比 在文档处理领域,Word转HTML的需求日益增长,尤其是需要将文档内容嵌入网页或富文本编辑器时。图片作为文档的重要组成部分,其处理方式直接影响转换效果和系统性能。本文将深…...

[模电]从PN结到实用电路:二极管的深度解析与设计指南
1. PN结:二极管的物理基础 想象一下把一块P型半导体和N型半导体紧密贴合在一起,就像把两块不同颜色的橡皮泥揉捏在一起。P型半导体里充满了带正电的"空穴"(可以理解为缺少电子的位置),而N型半导体则富含自由…...

MogFace人脸检测模型-large应用指南:从图片上传到结果分析,手把手教学
MogFace人脸检测模型-large应用指南:从图片上传到结果分析,手把手教学 1. 认识MogFace-large:为什么选择这个人脸检测模型 在开始实际操作之前,我们先简单了解下MogFace-large的核心优势。这个模型已经在Wider Face六项榜单上霸榜…...