剖析Linux文件系统
Linux 文件系统体系结构是一个对复杂系统进行抽象化的有趣例子。通过使用一组通用的 API 函数,Linux 可以在许多种存储设备上支持许多种文件系统。例如,read 函数调用可以从指定的文件描述符读取一定数量的字节。read 函数不了解文件系统的类型,比如 ext3 或 NFS。它也不了解文件系统所在的存储媒体,比如 AT Attachment Packet Interface(ATAPI)磁盘、Serial-Attached SCSI(SAS)磁盘或 Serial Advanced Technology Attachment(SATA)磁盘。但是,当通过调用 read 函数读取一个文件时,数据会正常返回。本文讲解这个机制的实现方法,并介绍 Linux 文件系统层的主要结构。
什么是文件系统
首先回答最常见的问题,“什么是文件系统”。
文件系统是对一个存储设备上的数据和元数据进行组织的机制。由于定义如此宽泛,支持它的代码会很有意思。
正如前面提到的,有许多种文件系统和媒体。由于存在这么多类型,可以预料到 Linux 文件系统接口实现为分层的体系结构,从而将用户接口层、文件系统实现和操作存储设备的驱动程序分隔开。
挂载
在 Linux 中将一个文件系统与一个存储设备关联起来的过程称为挂载(mount)。使用 mount 命令将一个文件系统附着到当前文件系统层次结构中(根)。在执行挂载时,要提供文件系统类型、文件系统和一个挂载点。
为了说明 Linux 文件系统层的功能(以及挂载的方法),我们在当前文件系统的一个文件中创建一个文件系统。实现的方法是,首先用 dd 命令创建一个指定大小的文件(使用 /dev/zero 作为源进行文件复制)—— 换句话说,一个用零进行初始化的文件,见清单 1。
清单 1. 创建一个经过初始化的文件
$ dd if=/dev/zero of=file.img bs=1k count=10000
10000+0 records in
10000+0 records out
$现在有了一个 10MB 的 file.img 文件。使用 losetup 命令将一个循环设备与这个文件关联起来,让它看起来像一个块设备,而不是文件系统中的常规文件:
$ losetup /dev/loop0 file.img
$这个文件现在作为一个块设备出现(由 /dev/loop0 表示)。然后用 mke2fs 在这个设备上创建一个文件系统。这个命令创建一个指定大小的新的 ext2 文件系统,见清单 2。清单 2. 用循环设备创建 ext2 文件系统
$ mke2fs -c /dev/loop0 10000
mke2fs 1.35 (28-Feb-2004)
max_blocks 1024000, rsv_groups = 1250, rsv_gdb = 39
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
2512 inodes, 10000 blocks
500 blocks (5.00%) reserved for the super user
...
$使用 mount 命令将循环设备(/dev/loop0)所表示的 file.img 文件挂装到挂载点 /mnt/point1。注意,文件系统类型指定为 ext2。挂载之后,就可以将这个挂载点当作一个新的文件系统,比如使用 ls 命令,见清单 3。清单 3. 创建挂装点并通过循环设备挂装文件系统
$ mkdir /mnt/point1
$ mount -t ext2 /dev/loop0 /mnt/point1
$ ls /mnt/point1
lost+found
$如清单 4 所示,还可以继续这个过程:在刚才挂载的文件系统中创建一个新文件,将它与一个循环设备关联起来,再在上面创建另一个文件系统。清单 4. 在循环文件系统中创建一个新的循环文件系统
$ dd if=/dev/zero of=/mnt/point1/file.img bs=1k count=1000
1000+0 records in
1000+0 records out
$ losetup /dev/loop1 /mnt/point1/file.img
$ mke2fs -c /dev/loop1 1000
mke2fs 1.35 (28-Feb-2004)
max_blocks 1024000, rsv_groups = 125, rsv_gdb = 3
Filesystem label=
...
$ mkdir /mnt/point2
$ mount -t ext2 /dev/loop1 /mnt/point2
$ ls /mnt/point2
lost+found
$ ls /mnt/point1
file.img lost+found
$通过这个简单的演示很容易体会到 Linux 文件系统(和循环设备)是多么强大。可以按照相同的方法在文件上用循环设备创建加密的文件系统。可以在需要时使用循环设备临时挂装文件,这有助于保护数据。
文件系统体系结构
既然已经看到了文件系统的构造方法,现在就看看 Linux 文件系统层的体系结构。本文从两个角度考察 Linux 文件系统。首先采用高层体系结构的角度。然后进行深层次讨论,介绍实现文件系统层的主要结构。
高层体系结构
尽管大多数文件系统代码在内核中(后面讨论的用户空间文件系统除外),但是图 1 所示的体系结构显示了用户空间和内核中与文件系统相关的主要组件之间的关系。
图 1. Linux 文件系统组件的体系结构

用户空间包含一些应用程序(例如,文件系统的使用者)和 GNU C 库(glibc),它们为文件系统调用(打开、读取、写和关闭)提供用户接口。系统调用接口的作用就像是交换器,它将系统调用从用户空间发送到内核空间中的适当端点。
VFS 是底层文件系统的主要接口。这个组件导出一组接口,然后将它们抽象到各个文件系统,各个文件系统的行为可能差异很大。有两个针对文件系统对象的缓存(inode 和 dentry)。它们缓存最近使用过的文件系统对象。
每个文件系统实现(比如 ext2、JFS 等等)导出一组通用接口,供 VFS 使用。缓冲区会缓存文件系统和相关块设备之间的请求。例如,对底层设备驱动程序的读写请求会通过缓冲区缓存来传递。
这就允许在其中缓存请求,减少访问物理设备的次数,加快访问速度。以最近使用(LRU)列表的形式管理缓冲区缓存。
注意,可以使用 sync 命令将缓冲区缓存中的请求发送到存储媒体(迫使所有未写的数据发送到设备驱动程序,进而发送到存储设备)。
这就是 VFS 和文件系统组件的高层情况。现在,讨论实现这个子系统的主要结构。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
主要结构
Linux 以一组通用对象的角度看待所有文件系统。这些对象是超级块(superblock)、inode、dentry 和文件。
超级块在每个文件系统的根上,超级块描述和维护文件系统的状态。文件系统中管理的每个对象(文件或目录)在 Linux 中表示为一个 inode。
inode 包含管理文件系统中的对象所需的所有元数据(包括可以在对象上执行的操作)。
另一组结构称为 dentry,它们用来实现名称和 inode 之间的映射,有一个目录缓存用来保存最近使用的 dentry。dentry 还维护目录和文件之间的关系,从而支持在文件系统中移动。
最后,VFS 文件表示一个打开的文件(保存打开的文件的状态,比如写偏移量等等)。
虚拟文件系统层
VFS 作为文件系统接口的根层。VFS 记录当前支持的文件系统以及当前挂装的文件系统。
可以使用一组注册函数在 Linux 中动态地添加或删除文件系统。内核保存当前支持的文件系统的列表,可以通过 /proc 文件系统在用户空间中查看这个列表。这个虚拟文件还显示当前与这些文件系统相关联的设备。
在 Linux 中添加新文件系统的方法是调用 register_filesystem。这个函数的参数定义一个文件系统结构(file_system_type)的引用,这个结构定义文件系统的名称、一组属性和两个超级块函数。也可以注销文件系统。
在注册新的文件系统时,会把这个文件系统和它的相关信息添加到 file_systems 列表中(见图 2 和 linux/ include/ linux/ mount.h)。这个列表定义可以支持的文件系统。在命令行上输入 cat /proc/filesystems,就可以查看这个列表。
图 2. 向内核注册的文件系统

VFS 中维护的另一个结构是挂装的文件系统(见图 3)。这个结构提供当前挂装的文件系统(见 linux /include /linux/fs.h)。它链接下面讨论的超级块结构。
图 3. 挂装的文件系统列表

超级块
超级块结构表示一个文件系统。它包含管理文件系统所需的信息,包括文件系统名称(比如 ext2)、文件系统的大小和状态、块设备的引用和元数据信息(比如空闲列表等等)。
超级块通常存储在存储媒体上,但是如果超级块不存在,也可以实时创建它。可以在 ./linux/include/linux/fs.h 中找到超级块结构(见图 4)。
图 4. 超级块结构和 inode 操作

超级块中的一个重要元素是超级块操作的定义。这个结构定义一组用来管理这个文件系统中的 inode 的函数。例如,可以用 alloc_inode 分配 inode,用 destroy_inode 删除 inode。可以用 read_inode和 write_inode 读写 inode,用 sync_fs 执行文件系统同步。可以在 ./linux /include/ linux/fs.h 中找到 super_operations 结构。每个文件系统提供自己的 inode 方法,这些方法实现操作并向 VFS 层提供通用的抽象。
inode和dentry
inode 表示文件系统中的一个对象,它具有惟一标识符。各个文件系统提供将文件名映射为惟一 inode 标识符和 inode 引用的方法。
图 5 显示 inode 结构的一部分以及两个相关结构。请特别注意 inode_operations 和file_operations。这些结构表示可以在这个 inode 上执行的操作。inode_operations 定义直接在 inode 上执行的操作,而 file_operations 定义与文件和目录相关的方法(标准系统调用)。
图 5. inode 结构和相关联的操作

inode 和目录缓存分别保存最近使用的 inode 和 dentry。
注意,对于 inode 缓存中的每个 inode,在目录缓存中都有一个对应的 dentry。可以在 ./linux/include/linux/fs.h 中找到 inode 和dentry 结构。
缓冲区缓存
除了各个文件系统实现(可以在 ./linux/fs 中找到)之外,文件系统层的底部是缓冲区缓存。这个组件跟踪来自文件系统实现和物理设备(通过设备驱动程序)的读写请求。
为了提高效率,Linux 对请求进行缓存,避免将所有请求发送到物理设备。缓存中缓存最近使用的缓冲区(页面),这些缓冲区可以快速提供给各个文件系统。
有趣的文件系统
本文没有讨论 Linux 中可用的具体文件系统,但是值得在这里稍微提一下。Linux 支持许多种文件系统,包括 MINIX、MS-DOS 和 ext2 等老式文件系统。
Linux 还支持 ext3、JFS 和 ReiserFS 等新的日志型文件系统。另外,Linux 支持加密文件系统(比如 CFS)和虚拟文件系统(比如 /proc)。
最后一种值得注意的文件系统是 Filesystem in Userspace(FUSE)。这种文件系统可以将文件系统请求通过 VFS 发送回用户空间。所以,如果你有兴趣创建自己的文件系统,那么通过使用 FUSE 进行开发是一种不错的方法。
结束语
尽管文件系统的实现并不复杂,但它是可伸缩和可扩展的体系结构的好例子。文件系统体系结构已经发展了许多年,并成功地支持了许多不同类型的文件系统和许多目标存储设备类型。由于使用了基于插件的体系结构和多层的函数间接性,Linux 文件系统在近期的发展很值得关注。

相关文章:
剖析Linux文件系统
Linux 文件系统体系结构是一个对复杂系统进行抽象化的有趣例子。通过使用一组通用的 API 函数,Linux 可以在许多种存储设备上支持许多种文件系统。例如,read 函数调用可以从指定的文件描述符读取一定数量的字节。read 函数不了解文件系统的类型ÿ…...
简介Maven结构与配置方法
一、Maven是什么 Maven是apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。 它有什么用呢? 比如我以前要IOUtils这个包,那要到网站下去下载下来,再导入。 当jar包多的时候,一个一个导出,…...

好用的网址6
PPT课件网:http://www.pptkj.net/ ImgUpscaler:AI Image Upscaler - Upscale Photo, Cartoons in Batch Free 加强图片 AI Draw:AI Draw | Convert Images to One-Line Drawings with AI ZToDoList:https://www.ztodolis…...

MySQL数据库---笔记5
MySQL数据库---笔记5 一、锁1.1、介绍1.2、全局锁1.2.1、全局锁介绍1.2.2、一致性数据备份 1.3、表级锁1.3.1、表锁1.3.2、元数据锁(meta data lock , MDL)1.3.3、意向锁 1.4、行级锁1.4.1、介绍1.4.2、行锁1.4.3、间隙锁/临建锁 二、InnoDB引擎2.1、逻辑…...

Yocto:初始
1.构建Yocto项目前,需要先安装其所依赖的一些组件及工具 1 System Requirements — The Yocto Project 4.2.999 documentation 需要依次安装: $ sudo apt install gawk wget git diffstat unzip texinfo gcc build-essential chrpath socat cpio python3 python3-pip python…...
autodl算力租用平台应用于pycharm
一、GPU租用选择 1、创建实例 首先进入算力市场 博客以2080为例,选择计费方式,选择合适的主机,选择要创建实例中的GPU数量,选择镜像(内置了不同的深度学习框架),最后创建即可 2、SSH远程连…...

高德地图的使用
JS API 结合 Vue 使用 高德地图 jsapi 下载、引入 npm add amap/amap-jsapi-loaderimport AMapLoader from amap/amap-jsapi-loader 使用2.0版本的loader需要在window对象下先配置 securityJsCode JS API 安全密钥使用 JS API 使用 script 标签同步加载增加代理服务器设置…...

<List<Map<String,String>>> 删除元素常见的误区以及删除方法
看到这么标题可能觉得这个真是太easy了,不就remove吗,分分钟搞定。 但结果却出乎意料,下面我们来j简单说说list删除数据可能遇到的坑: 先说明我们可能会遇到的两个问题: 1.java.lang.IndexOutOfBoundsException(索引越…...

Linux下的编辑器——vim的简单上手指南
文章目录 一.概念1. 什么是 vim2. Vim 的模式①命令模式② 插入模式③底线命令模式 二.vim的基本操作1.如何启动vim?2. [命令模式」切换至 「插入模式」3.「插入模式」 切换至 「命令模式」4.「命令模式」切换至 「底行模式」5. 如何退出 vim? 三.vim指令…...
)
C++多线程学习(二、多线程的几种创造方式【有返回值的之后讲】)
目录 创建多线程 1.普通函数充当线程处理函数创造线程 2.Lambda表达式充当线程处理函数 3.带参函数创建线程 3.1普通参数 3.2传入引用 3.3智能指针充当函数参数 4.通过类中的成员函数创建 4.1仿函数方式创建:类名的方式调用 4.2普通类中的成员函数 创建多…...

前端开发框架生命周期详解:Vue、React和Angular
引言 作为前端开发者,掌握前端开发框架的生命周期是非常重要的。在现代Web应用开发中,Vue.js、React和Angular是三个最流行的前端开发框架。本篇博客将详细解读这三个框架的生命周期,包括每个阶段的含义、用途以及如何最大限度地利用它们。通…...

【Java从入门到大牛】程序流程控制
🔥 本文由 程序喵正在路上 原创,CSDN首发! 💖 系列专栏:Java从入门到大牛 🌠 首发时间:2023年7月7日 🦋 欢迎关注🖱点赞👍收藏🌟留言🐾…...

UML学习统一建模语言
unified modeling language 统一建模语言 面向对象软件分析与设计建模的事实标准 类命名:帕斯卡特命名 类之间的关系 关联关系:班级和学生,一个类的对象作为另一个类的成员变量; 通过非构造和setter注入的方式建立联系…...
【C++学习笔记】RAII思想——智能指针
智能指针 1 内存泄漏问题2 RAII(Resource Acquisition Is Initialization)2.1 使用RAII思想设计的SmartPtr类2.2 智能指针的原理2.3 小总结智能指针原理 3 智能指针的拷贝问题3.1 std::auto_ptr3.2 std::unique_ptr3.3 std::shared_ptr3.3.1 拷贝构造函数…...

ubantu配置python环境
安装python 参考博客 安装pycharm 博客 创建Pycharm快捷方式 博客 ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1, currently the ‘ssl’ module is compiled with File “/home/r00t/IdeaProjects/data/venv/lib/python3.9/site-packages/urllib3/init.py”…...
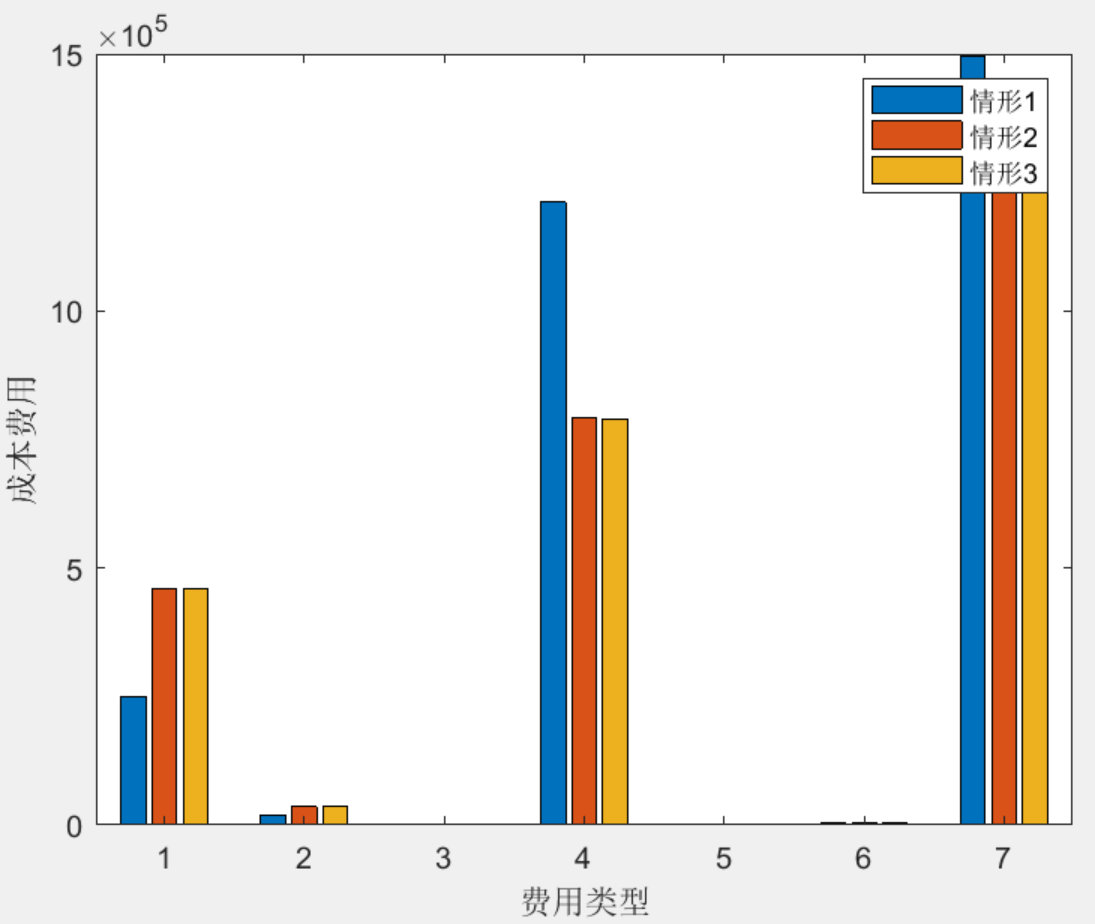
单向/双向V2G环境下分布式电源与电动汽车充电站联合配置方法(matlab代码)
目录 1 主要内容 目标函数 电动汽车负荷建模 算例系统图 程序亮点 2 部分代码 3 程序结果 4 下载链接 1 主要内容 该程序复现博士文章《互动环境下分布式电源与电动汽车充电站的优化配置方法研究》第五章《单向/双向V2G环境下分布式电源与电动汽车充电站联合配置方法》…...

dockerfile常用指令
Dockerfile常用指令 视频学习资料来源这里,点击本行文字即可跳转,讲的比较详细,不过比较老,跟最新的肯定是有一些差异的 Dockerfile官网文档的话点击这里 中文文档可以看看这个,不过没有详细的代码demo 或者是看这个 或…...

Matlab/simulink与dsp28335联合开发教程
一.入门篇(开发环境搭建) 1.1 Code Composer Studio 软件安装1.2 MATLAB 软件安装1.3 Control_SUIT3.4 软件安装1.4 C2000 Simulink 开发工具箱安装1.5 Visual_Studio_Professional 二. 基础篇(片内外设使用) 2.1 G…...
新项目搞完啦!!!
大家好,我是鱼皮。 经过了 7 场直播,总时长近 20 小时,我在 自己的编程导航 的第 5 个 全程直播开发 的项目 —— 智能 BI 项目,完结啦! 我在这里对该项目做一个简单的总结,希望让更多需要它的同学看到&am…...
)
分享一个可交互的小场景(二)
先看效果: 可互动的小场景 再看代码: JS部分 <script>var rotateDiv document.getElementById(rot);var rotateIcons document.getElementById(rot-icons);var clickRotateDiv document.getElementById(click-rot);var angle 0;clickRotateDi…...

RK3568上Qt5.12.8编译eglfs报错?手把手教你解决fbdev_window.h缺失问题
RK3568 Qt5.12.8编译eglfs报错全解析:从fbdev_window.h缺失到完整解决方案 在嵌入式开发领域,RK3568作为Rockchip推出的高性能处理器,结合Qt框架的图形界面开发能力,为工业控制、智能终端等场景提供了强大的解决方案。然而&#…...

嵌入式Linux C++开发框架AppKit实战解析
1. 嵌入式Linux C开发框架AppKit深度解析在嵌入式Linux开发领域,C开发者经常面临一个尴尬局面:标准库功能有限,而ROS等框架又过于庞大。AppKit框架正是为解决这一痛点而生,它提供了恰到好处的中间层抽象。我在多个工业控制项目中实…...

降低AI检测率哪个工具好?10款免费工具2026亲测,亲测有用
很多同学在写论文时都会遇到同一个难题:用AI辅助写完的内容,一查AIGC率高到离谱,被导师打回要求整改。后台最近也收到不少私信问:怎么才能有效降低AI检测率?有没有靠谱的免费降AI率工具推荐? 我自己当初也踩…...

Linux内核container_of宏解析与应用
1. 理解container_of宏的核心作用在Linux内核开发中,container_of宏是一个极其重要且频繁使用的工具。它的核心功能是通过结构体成员的地址反推出整个结构体的起始地址。想象一下,你手里只有一张照片的某个局部,却能准确找到这张照片在相册中…...

阿里千问Qwen3.5-Omni:全模态大模型的新王者
Qwen3.5-Omni:全模态能力的新巅峰3月30日,阿里发布的千问新一代全模态大模型Qwen3.5-Omni,在音视频理解、识别、交互等215项任务中取得SOTA(性能最佳),超越Gemini-3.1 Pro,成为全球最强的全模态…...

5大核心价值重构云游戏体验:Sunshine让你的游戏突破硬件与空间限制
5大核心价值重构云游戏体验:Sunshine让你的游戏突破硬件与空间限制 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在数字娱乐日益碎片化的今天,玩家们面临…...

我不是在用 AI 助手,我在把自己的能力沉淀成组织资产
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。查询参数/dishes?spicytrue&typeSichuan -> 好比…...

桌面图标杂乱如何高效管理?NoFences开源工具让文件归类效率提升60%
桌面图标杂乱如何高效管理?NoFences开源工具让文件归类效率提升60% 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 每天面对布满数十个图标的电脑桌面,…...

OpCore-Simplify:3步搞定黑苹果EFI配置,告别繁琐手动调试
OpCore-Simplify:3步搞定黑苹果EFI配置,告别繁琐手动调试 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经被黑苹果复…...

SEKA与AdaSEKA:破解大模型注意力引导难题的新方案
【导语:在自然语言处理领域,让大模型重点关注提示词某句话存在挑战。爱丁堡大学等团队提出SEKA及其自适应变体AdaSEKA,解决了现有方法的延迟和显存瓶颈问题,为大语言模型发展带来新思路。】SEKA:改写Key向量引导注意力…...