简单机器学习工程化过程
1、确认需求(构建问题)
我们需要做什么?
比如根据一些输入数据,预测某个值?
比如输入一些特征,判断这个是个什么动物?
这里我们要可以尝试分析一下,我们要处理的是个什么问题?
分类问题?回归问题?
目前有哪些方案处理这种问题?比如逻辑回归? SVM?神经网络?随机森林?
确认特征(获取数据)
要确认好我们需要哪些特征,以及这些特征的数据应该如何获取到?
比如数据库获取? 从文件(txt、excel等)读取?并对数据做简单的处理,比如去掉缺省值等
3、特征处理
特征编码(为什么要进行编码? 因为很多特征是字符串,我们得转化为数字或者二进制才能计算)
比较常用的:
onehot编码
# pandas进行onehot编码
import pandas as pd
df = pd.DataFrame([["green","M",20,"class1"],["red","L",21,"class2"],["blue","XL",30,"class3"],
])
df.columns = ["color","size","weight","class label"]
df2 = pd.get_dummies(df["class label"])# sklearn工具类进行onehot编码
from sklearn.feature_extraction import DictVectorizer
alist = [{"city":"beijing","temp":33},{"city":"GZ","temp":42},{"city":"SH","temp":40},
]
d = DictVectorizer(sparse=False)
feature = d.fit_transform(alist)
print(d.get_feature_names())
print(feature)Label Encoding
但是一次只能处理一列,要for进行处理
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
df[‘Sex’]=le.fit_transform(df[‘Sex’])注:编码要注意的是,你编码过程模型的输入输出也是经过编码的。 上述两种编码是基于列种值的类别来进行编码的,所以你每训练一次,都需要保存下编码的类别,并在预测输入数据的时候,使用相同的类别数据进行编码:
我们可以直接保存old_data和encoder_data和之间的映射关系,字典或者下面的csv格式里都可以。
for col in beat_sparse_cols: # sparse_feature encoderlbe = LabelEncoder()# 直接在原来的表上进行修改beat_data[col] = lbe.fit_transform(beat_data[col])# # method 2: save dict(selected), 为每个lbe保存一个对应的字典name = "encoding_" + str(col) + "_dict"locals()[name] = {}for i in list(lbe.classes_):# encoding[i] = lbe.transform([i])[0]locals()[name][i] = lbe.transform([i])[0]# save the lbe dict, note the indexdf = pd.DataFrame(locals()[name], index = [0])# df = pd.DataFrame(list(my_dict.items()), columns=['key', 'value']) # 否则默认保存的key是strdf.to_csv(save_dir + "/" + str(col) + "lbe_dict.csv", index = False)
在预测的新数据的时候,加载出来,查找类别,对新输入进行编码。遇到没有类别的要特殊处理如:
# train and test are pandas.DataFrame's and c is whatever column
le = LabelEncoder()
le.fit(train[c])
test[c] = test[c].map(lambda s: '<unknown>' if s not in le.classes_ else s)
le.classes_ = np.append(le.classes_, '<unknown>')
train[c] = le.transform(train[c])
test[c] = le.transform(test[c])
归一化(当所有数据权重一样时使用)
# 归一化
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler(feature_range=(0,1))
data = [[90,2,10,40],[60,5,15,45],[73,3,13,45]
]
data = mm.fit_transform(data)标准化(当数据存在巨大异常值时使用)
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
data = [[90,2,10,40],[60,5,15,45],[73,3,13,45]
]
data =ss.fit_transform(data)
print(data)方差过滤和PCA
# Filter过滤式(方差过滤)
from sklearn.feature_selection import VarianceThreshold
v = VarianceThreshold(threshold=2)
a=v.fit_transform([[0,2,4,3],[0,3,7,3],[0,9,6,3]])# PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
a = pca.fit_transform([[0,2,4,3],[0,3,7,3],[0,9,6,3]])包括PCA和标准化也和编码一样,要考虑输入单个数据的时候,如何进行?
如何进行反标准化等。
4、选择算法、训练模型
选择算法不再多说。
必须要做参数等交叉验证,方便看看哪个算法的哪个算子上表现的最好。
model_selection.cross_val_score
【sklearn】sklearn中的交叉验证_sklearn交叉验证_L鲸鱼与海的博客-CSDN博客
训练好后,将模型保存下来:
【Sklearn】3种模型保存的文件格式及调用方法_sklearn 导出模型_人工智的博客-CSDN博客
5、工程化(应用化)
选个框架django活动flask进行web化
【python】Django_人工智的博客-CSDN博客
6、部署上线
django是单线程比较慢,可以将其部署到一个web容器上,
相关文章:

简单机器学习工程化过程
1、确认需求(构建问题) 我们需要做什么? 比如根据一些输入数据,预测某个值? 比如输入一些特征,判断这个是个什么动物? 这里我们要可以尝试分析一下,我们要处理的是个什么问题&…...
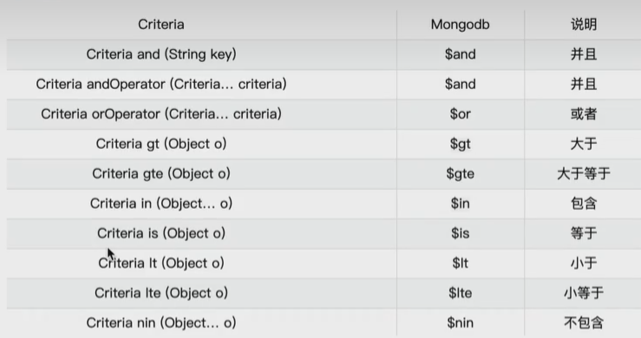
【MongoDB】SpringBoot整合MongoDB
【MongoDB】SpringBoot整合MongoDB 文章目录 【MongoDB】SpringBoot整合MongoDB0. 准备工作1. 集合操作1.1 创建集合1.2 删除集合 2. 相关注解3. 文档操作3.1 添加文档3.2 批量添加文档3.3 查询文档3.3.1 查询所有文档3.3.2 根据id查询3.3.3 等值查询3.3.4 范围查询3.3.5 and查…...
对齐音乐bpm的技术)
关于游戏引擎(godot)对齐音乐bpm的技术
引擎默认底层 1. _process(): 每秒钟调用60次(无限的) 数学 1. bpm1分钟节拍数量60s节拍数量 bpm120 60s120拍 2. 每拍子时间 60/bpm 3. 每个拍子触发周期所需要的帧数 每拍子时间*60(帧率) 这个是从帧数级别上对齐拍子的时间&#x…...
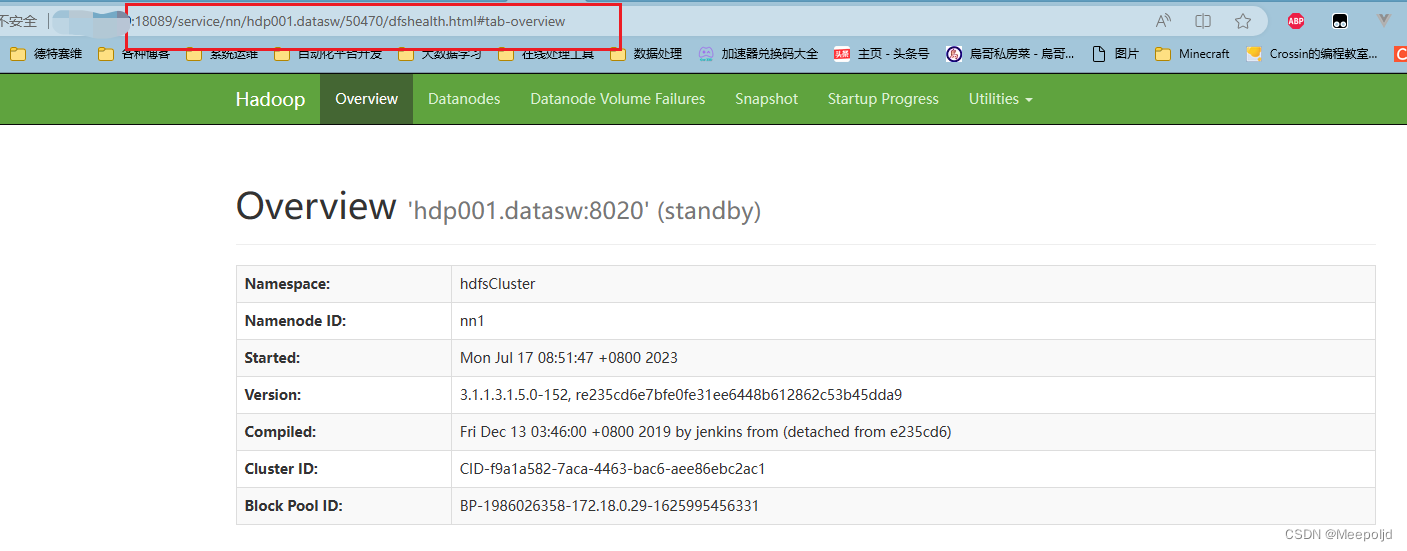
【Go】实现一个代理Kerberos环境部分组件控制台的Web服务
实现一个代理Kerberos环境部分组件控制台的Web服务 背景安全措施引入的问题SSO单点登录 过程整体设计路由反向代理登录会话组件代理YarnHbase 结果 背景 首先要说明下我们目前有部分集群的环境使用的是HDP-3.1.5.0的大数据集群,除了集成了一些自定义的服务以外&…...

Spring Security 6.x 系列【63】扩展篇之匿名认证
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 本系列Spring Authorization Server 版本 1.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 概述2. 配置3. Anonymo…...

供应链管理系统有哪些?
1万字干货分享,国内外 20款 供应链管理软件都给你讲的明明白白。如果你还不知道怎么选择,一定要翻到第三大段,这里我将会通过8年的软件产品选型经验告诉你,怎么样才能快速选到适合自己的软件工具。 (为防后续找不到&a…...
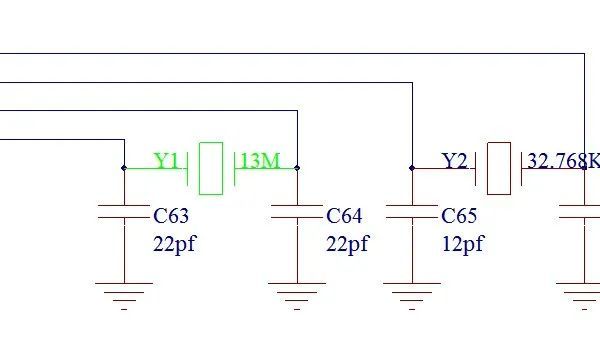
如何在PADS Logic中查找器件
PADS Logic提供类似于Windows的查找功能,可以进行器件的查找。 (1)在Logic设计界面中,将菜单显示中的“选择工具栏”进行打开,如图1所示,会弹出对应的“选择工具栏”的分栏菜单选项,如图2所示。…...

Android 生成pdf文件
Android 生成pdf文件 1.使用官方的方式 使用官方的方式也就是PdfDocument类的使用 1.1 基本使用 /**** 将tv内容写入到pdf文件*/RequiresApi(api Build.VERSION_CODES.KITKAT)private void newPdf() {// 创建一个PDF文本对象PdfDocument document new PdfDocument();//创建…...
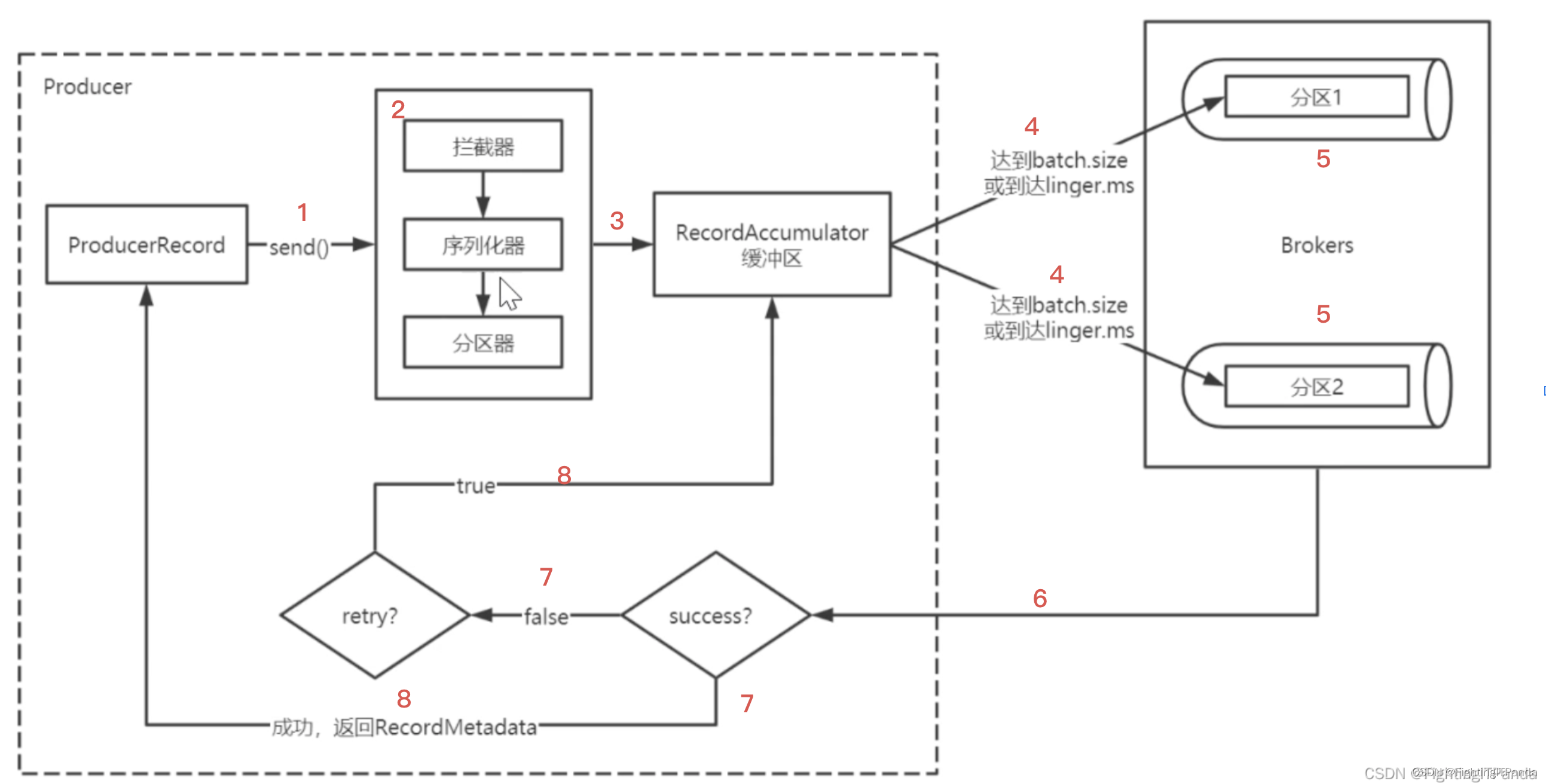
Kafka 入门到起飞 - 生产者发送消息流程解析
生产者通过send()方法发送消息消息会经过拦截器->序列化器->分区器 进行加工然后将消息存在缓冲区当缓冲区中消息达到条件会按批次发送到broker对应分区上broker将接收到的消息进行刷盘持久化消息处理broker会返回给producer响应落盘成功返回元数据…...

基于单片机智能台灯坐姿矫正器视力保护器的设计与实现
功能介绍 以51单片机作为主控系统;LCD1602液晶显示当前当前光线强度、台灯灯光强度、当前时间、坐姿距离等;按键设置当前时间,闹钟、提醒时间、坐姿最小距离;通过超声波检测坐姿,当坐姿不正容易对眼睛和身体腰部等造成…...
欧姆龙以太网模块如何设置ip连接 Kepware opc步骤
在数字化和自动化的今天,PLC在工业控制领域的作用日益重要。然而,PLC通讯口的有限资源成为了困扰工程师们的问题。为了解决这一问题,捷米特推出了JM-ETH-CP转以太网模块,让即插即用的以太网通讯成为可能,不仅有效利用了…...
PLEX如何搭建个人局域网的视频网站
Plex是一款功能非常强大的影音媒体管理系统,最大的优势是多平台支持和界面优美,几乎可以在所有的平台上安装plex服务器和客户端,让你可以随时随地享受存储在家中的电影、照片、音乐,并且可以实现观看记录无缝衔接,手机…...

java学习02
一、基本数据类型 Java有两大数据类型,内置数据类型和引用数据类型。 内置数据类型 Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。 byte࿱…...

libcurl库使用实例
libcurl libcurl是一个功能强大的跨平台网络传输库,支持多种协议,包括HTTP、FTP、SMTP等,同时提供了易于使用的API。 安装 ubuntu18.04平台安装 sudo apt-get install libcurl4-openssl-dev实例 这个示例使用libcurl库发送一个简单的HTTP …...
大数据存储架构详解:数据仓库、数据集市、数据湖、数据网格、湖仓一体
前言 本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据理论体系 思维导图 数据仓库 数据仓库是一个面向主题的&…...
 网页控制五自由度机械臂)
ESP32(MicroPython) 网页控制五自由度机械臂
ESP32(MicroPython) 网页控制五自由度机械臂 本程序通过网页控制五自由度机械臂,驱动方案改用PCA9685。 代码如下 #导入Pin模块 from machine import Pin import time from machine import SoftI2C from servo import Servos import networ…...

前端笔记_OAuth规则机制下实现个人站点接入qq三方登录
文章目录 ⭐前言⭐qq三方登录流程💖qq互联中心创建网页应用💖配置回调地址redirect_uri💖流程分析 ⭐思路分解⭐技术选型实现💖技术选型:💖实现 ⭐结束 ⭐前言 大家好,我是yma16,本…...
huggingface新作品:快速和简便的训练模型
AutoTrain Advanced是一个用于训练和部署最先进的机器学习模型的工具。它旨在提供更快速、更简便的方式来进行模型训练和部署。 安装 您可以通过PIP安装AutoTrain-Advanced的Python包。请注意,为了使AutoTrain Advanced正常工作,您将需要python > 3.…...
利用鸿鹄优化共享储能的SCADA 系统功能,赋能用户数据自助分析
摘要 本文主要介绍了共享储能的 SCADA 系统大数据架构,以及如何利用鸿鹄来更好的优化 SCADA 系统功能,如何为用户进行数据自助分析赋能。 1、共享储能介绍 说到共享储能,可能不少朋友比较陌生,下面我们简单介绍一下共享储能的价值…...

noSQL语句练习
Redis练习题 string list hash结构中,每个至少完成5个命令,包含插入 修改 删除 查询,list 和hash还需要增加遍历的操作命令 1、 string类型数据的命令操作: (1) 设置键值: 127.0.0.1:63…...
)
麒麟V10系统下国产海量数据库安装全攻略(含内核参数优化与避坑指南)
麒麟V10系统下国产海量数据库安装全攻略(含内核参数优化与避坑指南) 在国产化技术快速发展的今天,越来越多的企业和机构开始采用国产操作系统和数据库产品。麒麟V10作为国产操作系统的代表之一,其稳定性和安全性得到了广泛认可。而…...

打破数据标注瓶颈:Label Studio如何让AI训练效率提升300%?
打破数据标注瓶颈:Label Studio如何让AI训练效率提升300%? 【免费下载链接】label-studio Label Studio is a multi-type data labeling and annotation tool with standardized output format 项目地址: https://gitcode.com/GitHub_Trending/la/labe…...
,自适应融合多尺度特征,优化小目标与遮挡目标感知,二次创新CNBlock结构)
ConvNeXt 改进 :ConvNeXt添加SAConv(可切换空洞卷积),自适应融合多尺度特征,优化小目标与遮挡目标感知,二次创新CNBlock结构
本文教的是方法,也给出几种改进方法,二次创新结构,百变不离其宗,一文带你改进自己模型,科研路上少走弯路。 作者提出的技术结合了递归特征金字塔和可切换空洞卷积,通过强化多尺度特征学习和自适应的空洞卷积,显著提升了目标检测的效果。 理论介绍 空洞卷积(Atrous Co…...

医学图像分类实战:基于kvasir v2胃病数据集的深度卷积网络性能对比
1. 医学图像分类与KVASIR V2数据集简介 胃镜图像分类是计算机辅助诊断系统中的关键环节。KVASIR V2作为目前最全面的公开胃病数据集,包含8类常见胃部病变的8000张高清图像,每类1000张。这些图像由专业胃肠病专家标注,覆盖了从正常黏膜到早期…...
)
Oracle RAC OCR坏了怎么办?手把手教你用ocrconfig修复与备份(附11g/12c实战命令)
Oracle RAC OCR故障应急指南:从诊断到修复的全链路实战 凌晨三点,当手机铃声划破寂静,作为DBA的你从睡梦中惊醒。电话那头传来运维同事急促的声音:"生产环境RAC集群所有节点突然离线,CRS服务无法启动!…...

x265帧内预测实战:从35种模式到MPM优化的效率提升技巧
x265帧内预测深度优化:从35种模式到MPM的工程实践 在视频编码领域,HEVC标准相比前代H.264引入了更复杂的帧内预测机制,其中x265作为开源编码器实现,其帧内预测模块的优化直接影响编码效率。本文将深入剖析x265帧内预测的核心技术…...

Repomix Git日志集成:掌握commit历史分析的终极指南
Repomix Git日志集成:掌握commit历史分析的终极指南 【免费下载链接】repomix 📦 Repomix (formerly Repopack) is a powerful tool that packs your entire repository into a single, AI-friendly file. Perfect for when you need to feed your codeb…...

利用快马平台快速生成PyTorch图像分类原型,十分钟验证模型思路
最近在尝试用PyTorch做图像分类的原型验证时,发现从零开始搭建环境、写基础代码特别耗时。后来尝试用InsCode(快马)平台生成项目模板,十分钟就完成了模型验证。这里分享下用PyTorch快速构建MNIST分类器的关键步骤和踩坑经验。 数据准备环节 平台生成的代…...
)
Delphi 终极实战:将自定义控件打包成 BPL,安装到 Delphi 工具栏(组件库实战)
前面我们手写了专属 UI 组件库(MyUIClass.pas),但如果你想在以后的项目中一键调用这些控件,而不是每次都复制粘贴代码,那就必须将它们打包成 Delphi 组件包(BPL 文件)。学会这篇,你将…...

OpenClaw语音控制扩展:Qwen3.5-4B-Claude对接Whisper实现声控自动化
OpenClaw语音控制扩展:Qwen3.5-4B-Claude对接Whisper实现声控自动化 1. 为什么需要语音控制自动化 去年冬天的一个深夜,我在赶制项目文档时突发奇想:如果能让AI听懂我的语音指令直接操作电脑,是不是连键盘都不用碰了?…...