大数据存储架构详解:数据仓库、数据集市、数据湖、数据网格、湖仓一体
前言
本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据理论体系
思维导图

数据仓库
数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、
相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合。
数据仓库的主要目标是提供一致、可靠、易于访问的数据,
以支持企业的决策制定和分析。
它可以帮助企业了解自己的业务、市场以及客户,
并提供决策支持和预测分析的能力。
数据仓库在商业智能和数据分析领域有着广泛的应用。
关于数据仓库的详情请参考我的博客——数据仓库是什么?
关于商业智能请参考我的博客——什么是商业智能(BI)?
数据库 VS 数据仓库
| 区别 | 数据库 | 数据仓库 |
|---|---|---|
| 设计目标 | 支持企业的日常业务操作 | 支持企业的决策制定和分析 |
| 数据结构 | 面向应用的设计 | 面向主题的设计 |
| 数据处理方式 | 在线事务处理(OLTP)方式 | 在线分析处理(OLAP)方式 |
| 数据范围 | 当前状态数据 | 存储历史的、完整的、反应历史变化的数据 |
| 数据变化 | 支持频繁的增删改查操作 | 可添加、无删除、无变更、反应历史变化的 |
| 设计理论 | 遵循三范式、避免冗余 | 违范式、适当冗余 |
| 处理量 | 频繁、小批次、高并发、低延迟 | 非频繁、大批量、高吞吐、有延迟 |
关于数据库和数据仓库的对比详情请参考我的博客——数据仓库与数据库的区别?
OLTP vs OLAP
| 对比项目 | OLTP | OLAP |
|---|---|---|
| 用户 | 操作人员、底层管理人员 | 决策人员、高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| DB设计 | 基于ER模型,面向应用 | 星型/雪花/星座模型,面向主题 |
| DB规模 | GB至TB | ≥TB |
| 数据 | 最新的、细节的、二维的、分立的 | 历史的、聚集的、多维的、集成的 |
| 存储规模 | 读/写数条(甚至数百条)记录 | 读上百万条(甚至上亿条)记录 |
| 操作频度 | 非常频繁(以秒计) | 比较稀松(以小时甚至以周计) |
| 工作单元 | 严格的事务 | 复杂的查询 |
| 用户数 | 数百个至数千万个 | 数个至数百个 |
| 度量 | 事务春吐量 | 査询吞吐量、响应时间 |
关于 OLTP 和 OLAP 的对比详情请参考我的博客——OLTP和OLAP的区别?
数据仓库分层
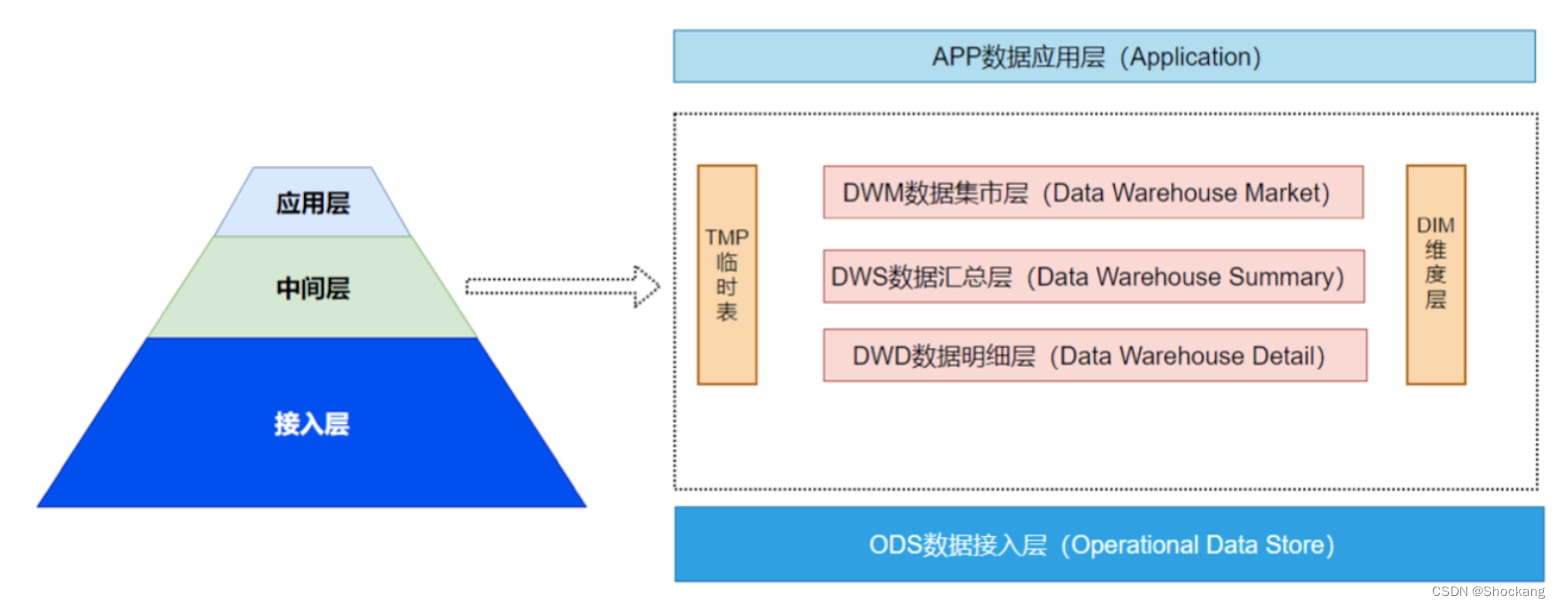
数据仓库分层的详情请参考我的博客——数据仓库是如何分层的?
数据仓库建模
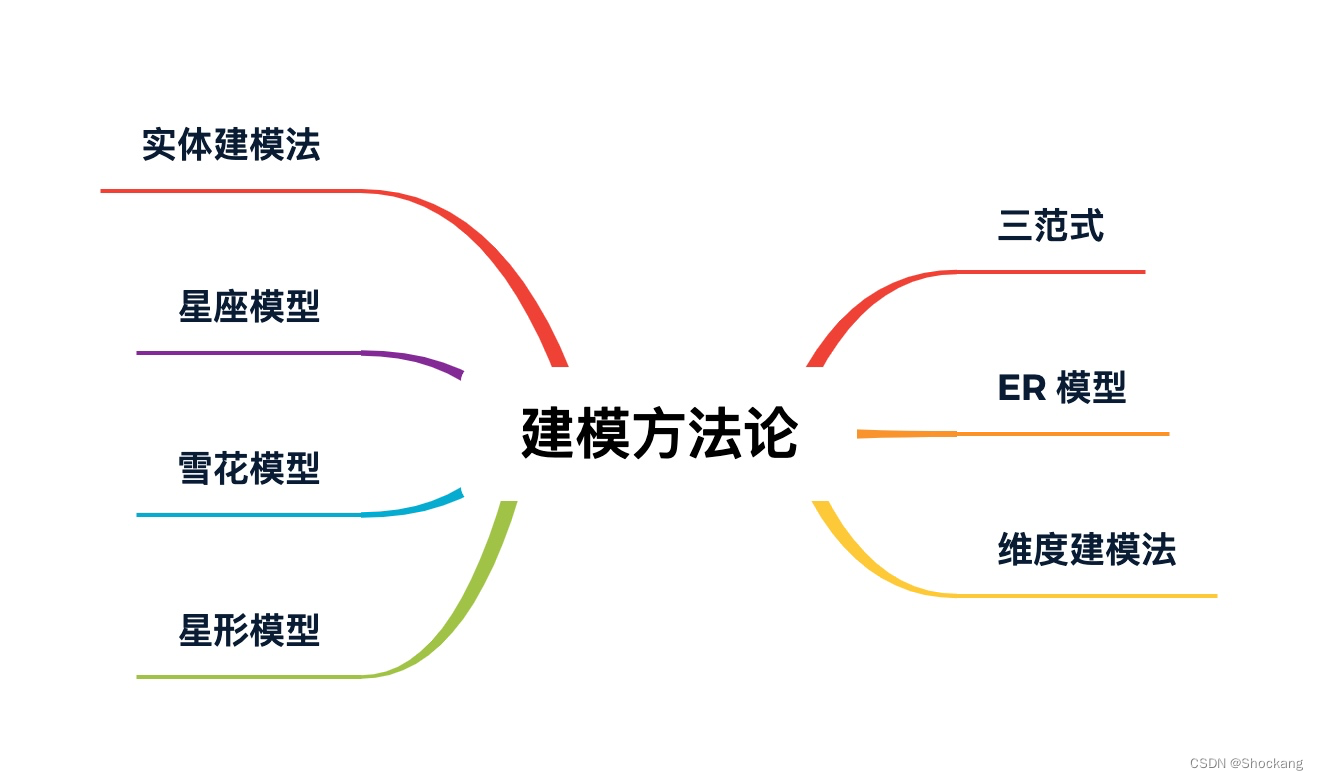
关于建模方法论的详情请参考我的下面 2 篇博客:
- 典型的数据仓库建模方法论
- 数据仓库是如何建模的?
数据集市
数据集市是一个专门针对特定业务部门或主题领域的数据仓库子集。
它集中于存储公司在更大的存储系统中选定的一小部分数据,
并且从比数据仓库更少的数据来源中获取数据。
关于数据集市的详情请参考我的博客——数据集市是什么?数据集市和数据仓库有什么区别
如果把数据仓库看作是全公司的数据集合的话,数据集市可以看作是其中一个部门的,这个部门只负责处理特定业务的数据。
数据集市 VS 数据仓库
数据仓库(Data Warehouse)是一个用于整个企业的存储库,包含来自不同业务、系统和部门的集成数据。它基于整个企业的数据模型建立,面向企业范围内的主题。
数据仓库的特点包括:
- 覆盖全企业:数据仓库为整个企业的各个部门和运作提供决策支持。
- 集成数据:数据仓库汇集来自多个业务、系统和部门的数据,通过数据清洗、整合和转换,以满足企业的分析和报告需求。
- 企业级架构:数据仓库是一个企业级的解决方案,通常由专业团队负责设计、构建和维护。
- 面向企业主题:数据仓库的主题是与整个企业运营相关的,如销售、客户、供应链等。
数据集市(Data Mart)是一个面向特定业务领域或功能单元的主题化数据存储库。它通常是部门级的,为某个局部范围内的管理人员提供决策支持。
数据集市的特点包括:
- 部门级应用:数据集市主要为某个特定部门或功能单元的业务需求服务,提供针对该部门的数据分析和报告。
- 面向部门主题:数据集市的主题是与特定业务或功能单元相关的,如销售业绩、市场营销、财务等。
- 数据来源:数据集市的数据来源可以是从数据仓库获取的(从属数据集市),也可以来自各个生产系统(独立数据集市)。
- 相对较小规模:数据集市的规模通常是几十GB的数量级,相对于数据仓库来说较小。
下面是描述数据仓库和数据集市区别的表格:
| 数据仓库 | 数据集市 | |
|---|---|---|
| 适用范围 | 整个企业 | 特定部门或功能单元 |
| 数据来源 | 来自不同业务、系统和部门的集成数据 | 可从数据仓库获取,或来自各生产系统 |
| 规模 | 较大(企业级) | 相对较小(部门级) |
| 架构 | 企业级架构 | 部门级架构 |
| 主题 | 面向企业主题 | 面向部门主题 |
| 目标 | 为整个企业各部门提供决策支持 | 为特定部门提供决策支持 |
| 功能 | 提供企业范围内的数据分析和报告 | 提供部门级的数据分析和报告 |
数据湖
数据湖是一个存储大规模、多样化数据的组织方法,可以存储结构化、非结构化和半结构化的数据,是一个大型、灵活的数据存储仓库,可以将企业的所有数据源整合起来。
关于数据湖的详情请参考我的博客——什么是数据湖?为什么需要数据湖?
结构化、半结构化和非结构化数据
结构化、半结构化和非结构化数据是不同类型的数据分类。
-
结构化数据:结构化数据是指可以使用关系型数据库表示和存储的数据,通常以
二维表的形式呈现。结构化数据具有以下特点:- 数据以行为单位,每行数据表示一个实体的信息,且每行的属性是相同的。
- 数据可以用统一的结构表示,如数字、符号等。
- 数据可以用二维表结构逻辑表达实现,包含属性和元组。例如,成绩单可以作为属性,而90分可以作为对应的元组。
- 存储和排列有一定的规律,便于查询和修改等操作。
-
半结构化数据:半结构化数据是结构化数据的一种形式,它不完全符合关系型数据的规范。半结构化数据具有以下特点:
- 半结构化数据既有数据又有结构,但结构不是严格固定的。
- 半结构化数据可以使用各种数据表示格式,例如
XML、JSON等。 - 数据的结构可能在不同的记录中有所变化,但仍具有一定的可解析性和组织性。
- 半结构化数据常见于Web数据、日志文件、配置文件等场景。
-
非结构化数据:非结构化数据是指没有固定结构和格式的数据,通常无法以关系型数据库的形式进行存储和表示。非结构化数据具有以下特点:
- 数据没有明确的组织结构,可能是自由
文本、图像、音频、视频等形式的数据。 - 非结构化数据不适合使用传统的关系型数据库进行存储和管理。
- 非结构化数据的分析和处理需要采用特定的技术和工具,如自然语言处理、图像处理、音频处理等。
- 非结构化数据常见于社交媒体内容、电子邮件、文档、多媒体文件等。
- 数据没有明确的组织结构,可能是自由
综上所述,结构化数据是具有固定结构和规律排列的数据,半结构化数据是介于结构化数据和非结构化数据之间的数据形式,而非结构化数据则是没有明确结构和格式的数据。这些不同类型的数据在分析和处理时需要采用不同的方法和工具来处理和管理。
数据仓库 vs 数据湖
| 参数 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据存储 | 结构化数据 | 结构化、半结构化和非结构化数据 |
| 数据准备 | 经过清洗和处理的数据 | 原始数据,不需要预处理 |
| 数据结构 | 预定义的模式,具有严格的架构 | 没有固定模式,数据以原始形式存储 |
| 数据目的 | 支持商业智能和分析 | 支持探索性分析和机器学习 |
| 用户 | 商业分析师和业务用户 | 数据科学家和工程师 |
| 数据访问 | SQL查询 | 多种工具和技术,如Apache Spark和Hadoop |
| 数据规模 | 相对较小(相对于数据湖) | 可以存储大规模数据,包括PB级数据 |
| 数据处理方式 | 提取、转换和加载(ETL) | 提取、加载和转换(ELT) |
| 数据处理速度 | 高性能,适合历史数据分析 | 高度灵活,适合实时和流式数据分析 |
| 数据架构 | 星型或雪花型 | 没有特定的数据架构 |
| 成本 | 相对较高,需要预定义模式和规划 | 相对较低,可以存储各种类型的数据 |
数据网格
数据网格(DataMesh)是一个新兴的概念,旨在帮助组织更好地管理和利用分散在不同系统和应用程序中的数据资产。它强调将数据资产转化为可重用、可组合、可交互的数据元素,以支持组织内部和跨组织的业务创新和数字化转型。
DataMesh的核心理念是基于事件驱动的架构,通过将业务事件和数据元素相结合,将数据资产转化为可编程的、可组装的服务和功能。这种方法可以帮助组织更好地理解和利用其数据资产,并支持更高效、更灵活的业务流程和数据处理。
DataMesh还强调数据治理和数据安全,以确保数据的准确性、可靠性和安全性。它提供了一组数据管理和治理工具,以帮助组织更好地管理其数据资产,并确保符合法规和标准的要求。
关于数据网格的详情请参考我的博客——数据网格(Data Mesh)是什么?
数据仓库 VS 数据网格
| 特征 | Data Warehouse(数据仓库) | DataMesh(数据网格) |
|---|---|---|
| 来源 | 传统上,数据仓库是将各种异构数据源集成到一个集中的位置(通常是一个数据库)中。 | 数据网格将数据分散在不同的领域团队中,每个团队负责自己的数据产品。 |
| 数据拥有权 | 数据仓库通常由中央团队负责管理和维护。 | 数据网格将数据拥有权下放给领域团队,每个团队可以自主管理和拥有自己的数据。 |
| 架构 | 数据仓库通常采用集中式架构,将数据集成到一个中心存储中。 | 数据网格采用分布式架构,数据存储在不同的领域团队中,通过标准化的规则和语法进行连接和交互。 |
| 数据冗余性和业务对齐 | 数据仓库通常会合并和整合数据,以消除冗余并满足业务需求。 | 数据网格允许数据在不同的领域团队之间存在冗余,以满足各自的业务需求。 |
| 数据观测性的重要性 | 数据仓库需要观测数据质量,以确保数据的高质量和可靠性。 | 数据网格同样需要观测数据质量,确保数据的可靠性和可发现性。 |
| 目标 | 数据仓库旨在提供一个一致、可信赖的数据源,用于企业的决策支持和分析。 | 数据网格旨在通过领域团队拥有的数据产品,实现更快速的洞察和分析,并推动数据驱动的决策制定。 |
湖仓一体
湖仓一体是一个全新的开放式数据架构,它将数据湖和数据仓库的优势组合在一起,
提供了数据湖的灵活性和可扩展性以及数据仓库的数据管理功能。
这个架构是在数据湖较低成本的数据存储基础设施上构建的,
它不仅保留了数据湖的特点,如存储非结构化数据和半结构化数据,
还可以支持事务、数据治理和数据模型化等功能,这些特点是数据仓库所具备的。
关于湖仓一体的详情请参考我的博客——湖仓一体(Lakehouse)是什么?
数据仓库 VS 湖仓一体
| 特征 | 数据仓库 | 湖仓一体 |
|---|---|---|
| 数据存储方式 | 结构化数据 | 结构化、半结构化和非结构化数据 |
| 数据处理方式 | 批量处理 | 批量处理和实时处理 |
| 数据集成 | 集成的 | 非集成的 |
| 数据模型 | 事实和维度模型 | 没有明确的数据模型 |
| 数据更新频率 | 周期性更新 | 实时或近实时更新 |
| 数据访问方式 | 预定义的查询 | 自助查询 |
| 数据可伸缩性 | 受限制 | 高度可伸缩 |
| 数据安全性 | 严格的访问控制 | 灵活的访问控制 |
| 数据处理工具和技术 | ETL工具和SQL | 大数据处理工具和技术 |
| 目标用户 | 决策者和分析师 | 决策者、分析师和数据科学家 |
总结
数据库、数据仓库、数据集市、数据湖、数据网格和湖仓一体是数据管理和存储的不同解决方案,它们在以下方面有所区别:
- 数据库(Database)是一个存储相关数据的地方,用于捕获特定情况的数据。它可以是结构化、关系型、非结构化或NoSQL数据库。数据库主要用于在线事务处理(
OLTP),处理实时的事务数据,并具有特定的目的和应用。 - 数据仓库(Data Warehouse)是组织的核心分析系统,用于存储历史数据和支持数据分析。数据仓库与操作数据存储(Operational Data Store,ODS)一起工作,将各种数据库中的数据捕获并统一存储在一个位置。数据仓库采用提取-转换-加载(Extract-Transform-Load,ETL)或类似的ELT过程,将数据从数据库中提取出来,经过转换和清洗后加载到数据仓库中。数据仓库通常使用SQL查询数据,并使用表、索引、键、视图和数据类型进行数据组织和完整性。数据仓库主要用于在线分析处理(
OLAP),支持企业内部的数据分析和商业智能。 - 数据集市(Data Mart)是数据仓库的子集,为
特定的业务部门或业务单元提供数据支持。数据集市通常是针对特定需求进行建立的,以满足某个部门的数据分析和决策需求。数据集市包含在数据仓库中,其中的数据集是为了实时分析和行动结果而使用。 - 数据湖(Data Lake)是一个用于存储原始数据的大型存储库,可以存储
结构化、半结构化和非结构化数据。数据湖接收来自不同来源的数据,而不对其进行特定格式的转换和处理。数据湖存储的数据可以在需要时进行处理和分析。数据湖适用于需要存储大量原始数据,并进行灵活的数据分析和探索的场景。 - 数据网格(DataMesh)是一种数据组织和架构的概念,旨在实现
数据的自治和共享。DataMesh鼓励将数据所有权和管理责任下放给数据所有者,以便更好地支持跨组织和跨团队的数据共享和协作。 - 湖仓一体(LakeHouse)是将
数据湖和数据仓库集成在一起的解决方案。它结合了数据湖的灵活性和数据仓库的结构化分析能力,使得用户可以同时进行原始数据探索和历史数据分析。
综上所述,数据库主要用于在线事务处理,数据仓库用于存储历史数据和支持数据分析,数据集市是数据仓库的子集,满足特定业务部门的需求,数据湖存储原始数据并支持灵活的数据分析,数据网格鼓励数据自治和共享,湖仓一体则是将数据湖和数据仓库集成在一起的解决方案。
下面是一个表格,描述了数据库、数据仓库、数据集市、数据湖、数据网格和湖仓一体之间的主要区别:
| 数据库(Database) | 数据仓库(Data Warehouse) | 数据集市(Data Mart) | 数据湖(Data Lake) | 数据网格(DataMesh) | 湖仓一体(LakeHouse) | |
|---|---|---|---|---|---|---|
| 定义 | 存储相关数据的地方 | 存储历史数据和支持数据分析 | 针对特定业务部门的数据子集 | 存储原始数据的大型存储库 | 数据的自治和共享 | 将数据湖和数据仓库集成的解决方案 |
| 用途 | 在线事务处理(OLTP) | 在线分析处理(OLAP) | 特定业务部门的数据分析和决策支持 | 灵活的数据分析和探索 | 跨组织和跨团队的数据共享和协作 | 原始数据探索和历史数据分析 |
| 数据类型 | 结构化、关系型、非结构化、NoSQL | 结构化 | 结构化 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 |
| 数据处理 | 实时事务数据处理 | 提取-转换-加载(ETL)或类似ELT过程 | 针对特定需求的数据提取和整合 | 原始数据存储,按需处理和分析 | 数据所有者自治,分布式数据共享 | 结合原始数据探索和历史数据分析 |
| 查询 | SQL查询 | SQL查询 | SQL查询 | 按需处理和分析 | 分布式数据查询和共享 | 结合原始数据探索和历史数据分析 |
| 数据组织 | 表、索引、键、视图、数据类型 | 表、索引、键、视图、数据类型 | 表、索引、键、视图、数据类型 | 灵活的数据组织 | 分布式数据组织和架构 | 灵活的数据组织 |
| 数据共享 | 有限的共享能力 | 针对特定用户和部门的共享 | 针对特定业务部门的共享 | 强调跨组织和跨团队的共享 | 强调数据自治和共享 | 结合数据湖和数据仓库的共享能力 |
| 数据分析 | 实时事务数据分析 | 历史数据分析和商业智能 | 特定业务部门的数据分析和决策支持 | 灵活的数据分析和探索 | 跨组织和跨团队的数据分析和协作 | 结合原始数据探索和历史数据分析 |
相关文章:
大数据存储架构详解:数据仓库、数据集市、数据湖、数据网格、湖仓一体
前言 本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据理论体系 思维导图 数据仓库 数据仓库是一个面向主题的&…...
 网页控制五自由度机械臂)
ESP32(MicroPython) 网页控制五自由度机械臂
ESP32(MicroPython) 网页控制五自由度机械臂 本程序通过网页控制五自由度机械臂,驱动方案改用PCA9685。 代码如下 #导入Pin模块 from machine import Pin import time from machine import SoftI2C from servo import Servos import networ…...

前端笔记_OAuth规则机制下实现个人站点接入qq三方登录
文章目录 ⭐前言⭐qq三方登录流程💖qq互联中心创建网页应用💖配置回调地址redirect_uri💖流程分析 ⭐思路分解⭐技术选型实现💖技术选型:💖实现 ⭐结束 ⭐前言 大家好,我是yma16,本…...
huggingface新作品:快速和简便的训练模型
AutoTrain Advanced是一个用于训练和部署最先进的机器学习模型的工具。它旨在提供更快速、更简便的方式来进行模型训练和部署。 安装 您可以通过PIP安装AutoTrain-Advanced的Python包。请注意,为了使AutoTrain Advanced正常工作,您将需要python > 3.…...
利用鸿鹄优化共享储能的SCADA 系统功能,赋能用户数据自助分析
摘要 本文主要介绍了共享储能的 SCADA 系统大数据架构,以及如何利用鸿鹄来更好的优化 SCADA 系统功能,如何为用户进行数据自助分析赋能。 1、共享储能介绍 说到共享储能,可能不少朋友比较陌生,下面我们简单介绍一下共享储能的价值…...

noSQL语句练习
Redis练习题 string list hash结构中,每个至少完成5个命令,包含插入 修改 删除 查询,list 和hash还需要增加遍历的操作命令 1、 string类型数据的命令操作: (1) 设置键值: 127.0.0.1:63…...

Spring:Bean生命周期
Bean 生命周期生命周期 Bean 生命周期是 bean 对象从创建到销毁的整个过程。 简单的 Bean 生命周期的过程: 1.实例化(调用构造方法对 bean 进行实例化) 2.依赖注入(调用 set 方法对 bean 进行赋值) 3.初始化(手动配置 xml 文件中 bean 标签的 init-method 属性值,来指…...
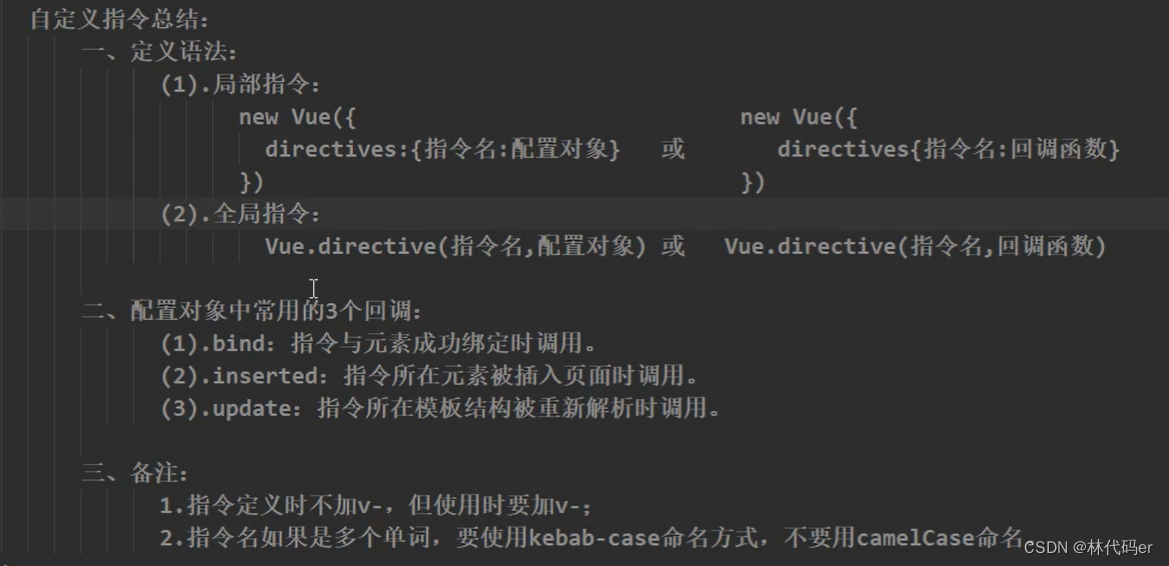
Vue自定义指令
需求1:定义一个v-big指令,和v-text功能类似,但会把绑定的数值放大10倍。 需求2:定义一个v-fbind指令,和v-bind功能类似,但可以让其所绑定的input元素默认获取焦点。 自定义指令函数式v-big: &l…...
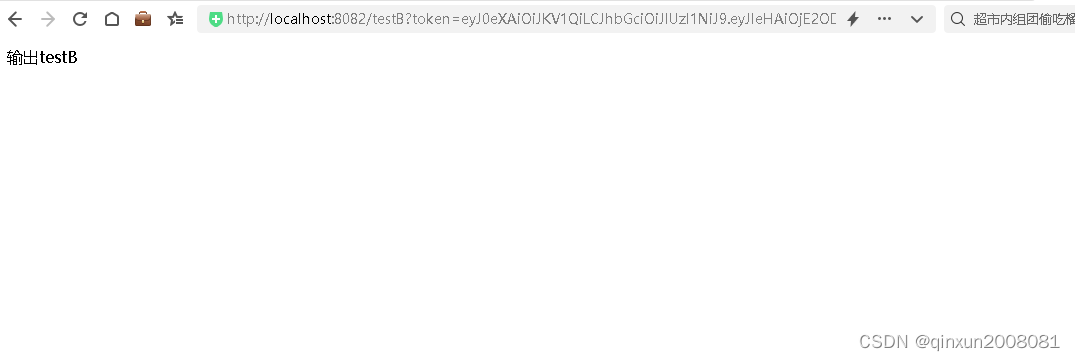
SpringBoot+JWT实现单点登录解决方案
一、什么是单点登录? 单点登录是一种统一认证和授权机制,指在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的系统,不需要重新登录验证。 单点登录一般用于互相授信的系统,实现单一位置登录,其他信任的…...
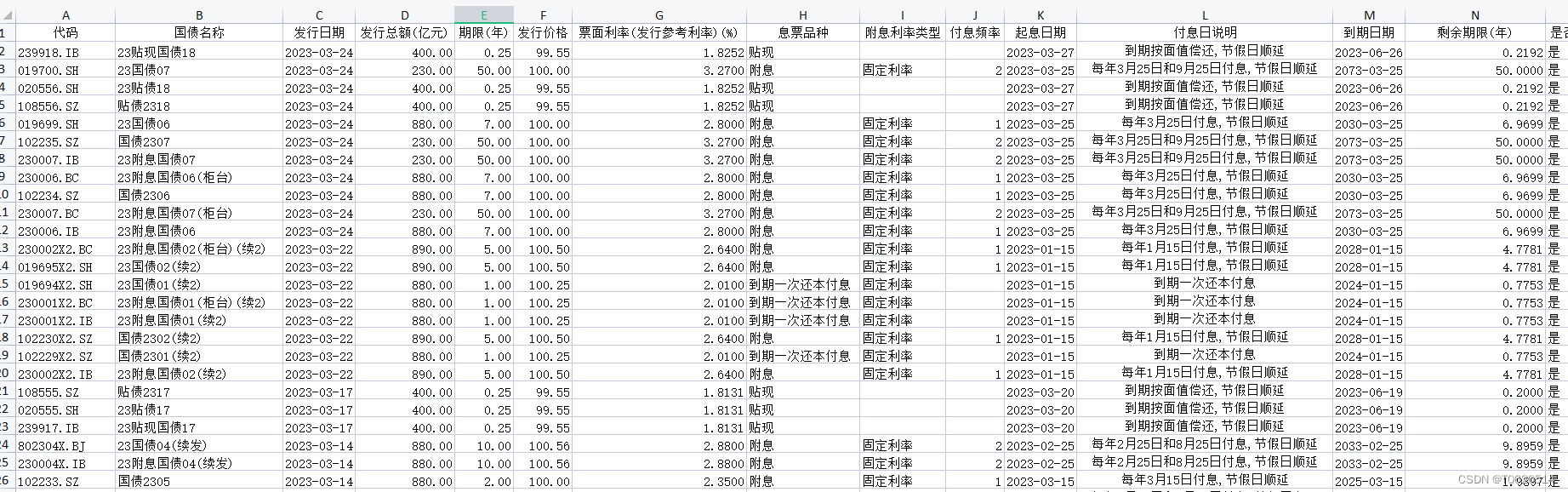
中国国债发行数据集(2002-2023)
国债是由国家发行的债券,由于国债的发行主体是国家,所以它具有最高的信用度,被公认为是最安全的投资工具。国债按照交易市场的不同分为三类,即银行间市场国债、交易所市场国债和柜台市场国债;按照交易方式的不同分为三…...
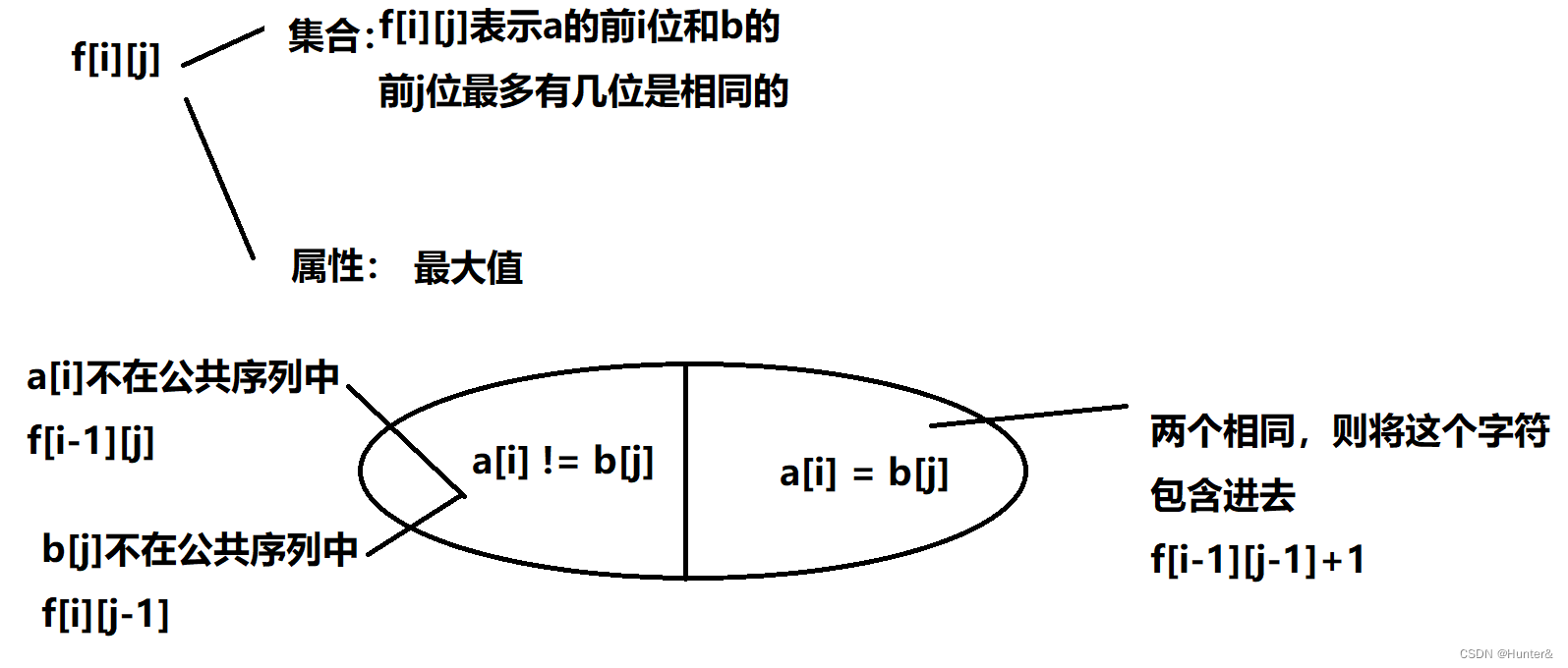
曲师大2023大一新生排位赛-C.String题解
C.String 题目描述 众所周知,许师哥精通字符串。 一天,许师哥意外的获得了一个字符串,但他发现这个字符串并不是一个回文串,因此他非常生气。于是他决定从这个字符串中删除若干个字符使得 剩余的字符串为一个回文串。 回想回文串…...

Linux Ubuntu安装RabbitMQ服务
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...

什么是测试用例?如何设计?
在学习或者实际的测试工作中经常都会提到“测试用例”这个词,没错,测试用例是测试工作的核心,不管要做的是什么样的测试,在真正动手执行测试之前,我们都需要先根据软件需求来设计测试用例,之后再依据设计好…...
Maven —— 项目管理工具
前言 在这篇文章中,荔枝会介绍如何在项目工程中借助Maven的力量来开发,主要涉及Maven的下载安装、环境变量的配置、IDEA中的Maven的路径配置和信息修改以及通过Maven来快速构建项目。希望能对需要配置的小伙伴们有帮助哈哈哈哈~~~ 文章目录 前言 一、初…...

Ubuntu 命令行编辑文件后如何保存退出
在 Ubuntu 命令行中编辑文件后,可以使用以下步骤保存并退出: 按下键盘上的 Ctrl 键和 X 键组合,以退出编辑模式。如果文件已更改,你将看到提示,询问是否保存更改。按下 Y 键来确认保存更改,或按下 N 键取消…...
AHB协议理解
从小父亲就教育我,做一个对社会有用的人! 目录 Chapter1 AHB Block Diagram Ginput signal lnput signals Output Signal Chapter3 Transfers AHB接口Overview Chapter6 Data Buses HWDATA HRDATA Chapter1 Introduction AHB: Advanced High-performanc…...
【UE5 多人联机教程】01-创建主界面
目录 工程地址 步骤 参考链接 工程地址 GitHub - UE4-Maple/C_MP_Lobby: 多人大厅教程项目 步骤 1. 先新建一个工程 2. 将下载的工程中的Plugins目录拷贝到自己新建的工程下 3. 打开工程,新建一个游戏实例 这里命名为“GI_Main” 在项目设置中设置游戏实例类为…...

HarmonyOS学习路之方舟开发框架—学习ArkTS语言(基本语法 五)
Styles装饰器:定义组件重用样式 如果每个组件的样式都需要单独设置,在开发过程中会出现大量代码在进行重复样式设置,虽然可以复制粘贴,但为了代码简洁性和后续方便维护,我们推出了可以提炼公共样式进行复用的装饰器St…...

React(3)
1.案例选项卡 import React, { Component } from reactexport default class App extends Component {state{tabList:[{id:1,text:"电影"},{id:2,text:"影院"},{id:3,text:"我的"}]}render() {return (<div><ul>{this.state.tabList…...

LangChain大型语言模型(LLM)应用开发(三):Chains
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…...
)
Windows Server远程管理新选择:一键脚本部署noVNC服务端(含开机自启配置)
Windows Server远程管理新选择:一键脚本部署noVNC服务端(含开机自启配置) 对于需要管理Windows Server的系统管理员来说,远程访问是不可或缺的功能。传统的RDP虽然稳定,但在某些场景下可能受限,比如网络环境…...

OpCore Simplify:终极指南!让黑苹果配置从8小时缩短到45分钟的自动化神器
OpCore Simplify:终极指南!让黑苹果配置从8小时缩短到45分钟的自动化神器 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在…...

2026年AI前20岗位薪酬出炉!搞AI大模型的远超同行?
AI相关,细分技术领域,薪资前20岗位,都有哪些。 今天这篇文章与铁铁们分享一下。 1 薪资榜单 如下图所示,排名第一:深度学习算法工程师,平均月薪达到3万1千; 排名第二的架构师,薪资与…...

Dify工作流终极指南:3天从新手到专家的完整免费教程
Dify工作流终极指南:3天从新手到专家的完整免费教程 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Wo…...

零基础养龙虾:OpenClaw部署从入门到上手,一篇讲透!
2026年,OpenClaw(昵称 “龙虾”)凭借 “能真正动手干活” 的核心能力,成为开源AI Agent领域的顶流。它不仅能像ChatGPT一样聊天,更能自主操作电脑——整理文件、控制浏览器、发送邮件、甚至调用硬件设备。因其图标酷似…...

FastAdmin+PHPStudy保姆级安装教程:从下载到配置数据库的完整流程
FastAdminPHPStudy极速开发环境搭建实战指南 作为一名长期使用FastAdmin框架的开发者,我深知一个顺畅的本地开发环境对项目效率的影响。本文将带你从零开始,用最简洁的方式完成FastAdmin与PHPStudy的完美搭配,避开那些新手常踩的"坑&quo…...

RT-Thread Nano 3.0.3移植STM32F103后,第一个实战:用FinSH组件实现串口命令行调试
RT-Thread Nano 3.0.3移植STM32F103实战:FinSH组件实现串口命令行调试 当你成功将RT-Thread Nano移植到STM32F103开发板后,第一个令人兴奋的里程碑就是让系统真正"活"起来——而FinSH组件正是实现这一目标的完美起点。这个内置的命令行交互工具…...

PostgreSQL 模式级权限迁移:一键批量修改所有表与对象的所有者
1. 为什么需要批量修改PostgreSQL对象所有者? 在实际的数据库运维工作中,经常会遇到需要批量修改数据库对象所有者的情况。我遇到过不少这样的场景:公司部门重组后,原先由开发团队A负责的项目转交给团队B维护;或者某个…...

如何在Mac上免费本地运行Stable Diffusion:Mochi Diffusion终极指南
如何在Mac上免费本地运行Stable Diffusion:Mochi Diffusion终极指南 【免费下载链接】MochiDiffusion Run Stable Diffusion on Mac natively 项目地址: https://gitcode.com/gh_mirrors/mo/MochiDiffusion 还在寻找能在Mac上完美运行Stable Diffusion的免费…...

环境感知驱动的EFI构建:让OpenCore配置效率提升300%
环境感知驱动的EFI构建:让OpenCore配置效率提升300% 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpenCore配置(OpenCore是一…...