基于深度学习的高精度课堂人脸检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度课堂人脸检测系统可用于日常生活中或野外来检测与定位课堂人脸目标,利用深度学习算法可实现图片、视频、摄像头等方式的课堂人脸目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型训练数据集,使用Pysdie6库来搭建页面展示系统,同时支持ONNX、PT等模型作为权重模型的输出。本系统支持的功能包括课堂人脸训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;摄像头的上传、检测、可视化结果展示与结束检测;已检测目标列表、位置信息;前向推理用时。另外本课堂人脸检测系统同时支持原始图像与检测结果图像的同时展示,原始视频与检测结果视频的同时展示。本博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。

基本介绍
近年来,机器学习和深度学习取得了较大的发展,深度学习方法在检测精度和速度方面与传统方法相比表现出更良好的性能。YOLOv5是单阶段目标检测算法YOLO的第五代,根据实验得出结论,其在速度与准确性能方面都有了明显提升,开源的代码可见https://github.com/ultralytics/yolov5。因此本博文利用YOLOv5检测算法实现一种高精度课堂人脸检测模型,再搭配上Pyside6库写出界面系统,完成目标检测识别页面的开发。注意到YOLO系列算法的最新进展已有YOLOv6、YOLOv7、YOLOv8等算法,将本系统中检测算法替换为最新算法的代码也将在后面发布,欢迎关注收藏。
环境搭建
(1)下载完整文件到自己电脑上,然后使用cmd打开到文件目录
(2)利用Conda创建环境(Anacodna),conda create -n yolo5 python=3.8 然后安装torch和torchvision(pip install torch1.10.0+cu113 torchvision0.11.0+cu113 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple)其中-i https://pypi.tuna.tsinghua.edu.cn/simple代表使用清华源,这行命令要求nvidia-smi显示的CUDA版本>=11.3,最后安装剩余依赖包使用:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple


(3)安装Pyside6库 pip install pyside6==6.3 -i https://pypi.tuna.tsinghua.edu.cn/simple

(4)对于windows系统下的pycocotools库的安装:pip install pycocotools-windows -i https://pypi.tuna.tsinghua.edu.cn/simple
界面及功能展示
下面给出本博文设计的软件界面,整体界面简洁大方,大体功能包括训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;已检测目标列表、位置信息;前向推理用时。希望大家可以喜欢,初始界面如下图:

模型选择与初始化
用户可以点击模型权重选择按钮上传训练好的模型权重,训练权重格式可为.pt、.onnx以及。engine等,之后再点击模型权重初始化按钮可实现已选择模型初始化信息的设置。


置信分与IOU的改变
在Confidence或IOU下方的输入框中改变值即可同步改变滑动条的进度,同时改变滑动条的进度值也可同步改变输入框的值;Confidence或IOU值的改变将同步到模型里的配置,将改变检测置信度阈值与IOU阈值。
图像选择、检测与导出
用户可以点击选择图像按钮上传单张图片进行检测与识别。

再点击图像检测按钮可完成输入图像的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

再点击检测结果展示按钮可在系统左下方显示输入图像检测的结果,系统将显示识别出图片中的目标的类别、位置和置信度信息。

点击图像检测结果导出按钮即可导出检测后的图像,在保存栏里输入保存的图片名称及后缀即可实现检测结果图像的保存。

点击结束图像检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频。
视频选择、检测与导出
用户可以点击选择视频按钮上传视频进行检测与识别,之后系统会将视频的第一帧输入到系统界面的左上方显示。

再点击视频检测按钮可完成输入视频的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击暂停视频检测按钮即可实现输入视频的暂停,此时按钮变为继续视频检测,输入视频帧与帧检测结果会保留在系统界面,可点击下拉目标框选择已检测目标的坐标位置信息,再点击继续视频检测按钮即可实现输入视频的检测。
点击视频检测结果导出按钮即可导出检测后的视频,在保存栏里输入保存的图片名称及后缀即可实现检测结果视频的保存。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频。
摄像头打开、检测与结束
用户可以点击打开摄像头按钮来打开摄像头设备进行检测与识别,之后系统会将摄像头图像输入到系统界面的左上方显示。

再点击摄像头检测按钮可完成输入摄像头的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频或打开摄像按钮来上传图像、视频或打开摄像头。
算法原理介绍
本系统采用了基于深度学习的单阶段目标检测算法YOLOv5,相比于YOLOv3和YOLOv4,YOLOv5在检测精度和速度上都有很大的提升。YOLOv5算法的核心思想是将目标检测问题转化为一个回归问题,通过直接预测物体中心点的坐标来代替Anchor框。此外,YOLOv5使用SPP(Spatial Pyramid Pooling)的特征提取方法,这种方法可以在不增加计算量的情况下,有效地提取多尺度特征,提高检测性能。YOLOv5s模型的整体结构如下图所示。

YOLOv5网络结构是由Input、Backbone、Neck、Prediction组成。YOLOv5的Input部分是网络的输入端,采用Mosaic数据增强方式,对输入数据随机裁剪,然后进行拼接。Backbone是YOLOv5提取特征的网络部分,特征提取能力直接影响整个网络性能。在特征提取阶段,YOLOv5使用CSPNet(Cross Stage Partial Network)结构,它将输入特征图分为两部分,一部分通过一系列卷积层进行处理,另一部分直接进行下采样,最后将这两部分特征图进行融合。这种设计使得网络具有更强的非线性表达能力,可以更好地处理目标检测任务中的复杂背景和多样化物体。在Neck阶段使用连续的卷积核C3结构块融合特征图。在Prediction阶段,模型使用结果特征图预测目标的中心坐标与尺寸信息。博主觉得YOLOv5不失为一种目标检测的高性能解决方案,能够以较高的准确率对目标进行分类与定位。当然现在YOLOv6、YOLOv7、YOLOv8等算法也在不断提出和改进,后续博主也会将这些算法融入到本系统中,敬请期待。
数据集介绍
本系统使用的课堂人脸数据集手动标注了人脸这一个类别,数据集总计9072张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的课堂人脸检测识别数据集包含训练集7203张图片,验证集1869张图片,选取部分数据部分样本数据集如下图所示。由于YOLOv5算法对输入图片大小有限制,需要将所有图片调整为相同的大小。为了在不影响检测精度的情况下尽可能减小图片的失真,我们将所有图片调整为640x640的大小,并保持原有的宽高比例。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。

关键代码解析
本系统的深度学习模型使用PyTorch实现,基于YOLOv5算法进行目标检测。在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。
在测试阶段,我们使用了训练好的模型来对新的图片和视频进行检测。通过设置阈值,将置信度低于阈值的检测框过滤掉,最终得到检测结果。同时,我们还可以将检测结果保存为图片或视频格式,以便进行后续分析和应用。本系统基于YOLOv5算法,使用PyTorch实现。代码中用到的主要库包括PyTorch、NumPy、OpenCV、PyQt等。


Pyside6界面设计
Pyside6是Python语言的GUI编程解决方案之一,可以快速地为Python程序创建GUI应用。在本博文中,我们使用Pyside6库创建一个图形化界面,为用户提供简单易用的交互界面,实现用户选择图片、视频进行目标检测。
我们使用Qt Designer设计图形界面,然后使用Pyside6将设计好的UI文件转换为Python代码。图形界面中包含多个UI控件,例如:标签、按钮、文本框、多选框等。通过Pyside6中的信号槽机制,可以使得UI控件与程序逻辑代码相互连接。
实验结果与分析
在实验结果与分析部分,我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练过程。在训练阶段,我们使用了前面介绍的课堂人脸数据集进行训练,使用了YOLOv5算法对数据集训练,总计训练了300个epochs。在训练过程中,我们使用tensorboard记录了模型在训练集和验证集上的损失曲线。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征。在训练结束后,我们使用模型在数据集的验证集上进行了评估,得到了以下结果。

下图展示了我们训练的YOLOv5模型在验证集上的PR曲线,从图中可以看出,模型取得了较高的召回率和精确率,整体表现良好。

下图展示了本博文在使用YOLOv5模型对课堂人脸数据集进行训练时候的Mosaic数据增强图像。


综上,本博文训练得到的YOLOv5模型在数据集上表现良好,具有较高的检测精度和鲁棒性,可以在实际场景中应用。另外本博主对整个系统进行了详细测试,最终开发出一版流畅的高精度目标检测系统界面,就是本博文演示部分的展示,完整的UI界面、测试图片视频、代码文件等均已打包上传,感兴趣的朋友可以关注我私信获取。
其他基于深度学习的目标检测系统如西红柿、猫狗、山羊、野生目标、烟头、二维码、头盔、交警、野生动物、野外烟雾、人体摔倒识别、红外行人、家禽猪、苹果、推土机、蜜蜂、打电话、鸽子、足球、奶牛、人脸口罩、安全背心、烟雾检测系统等有需要的朋友关注我,从博主其他视频中获取下载链接。
完整项目目录如下所示:

相关文章:
基于深度学习的高精度课堂人脸检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度课堂人脸检测系统可用于日常生活中或野外来检测与定位课堂人脸目标,利用深度学习算法可实现图片、视频、摄像头等方式的课堂人脸目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标…...

Mysql错误日志、通用查询日志、二进制日志和慢日志的介绍和查看
一.日志 1.日志和备份的必要性 日志刷新 2.mysql的日志类型 (1)错误日志 查看当前错误日志和是否记录警告设置 (2)通用查询日志 查看通用查询日志的设置 (3)二进制日志 查看二进制文件的设置&…...
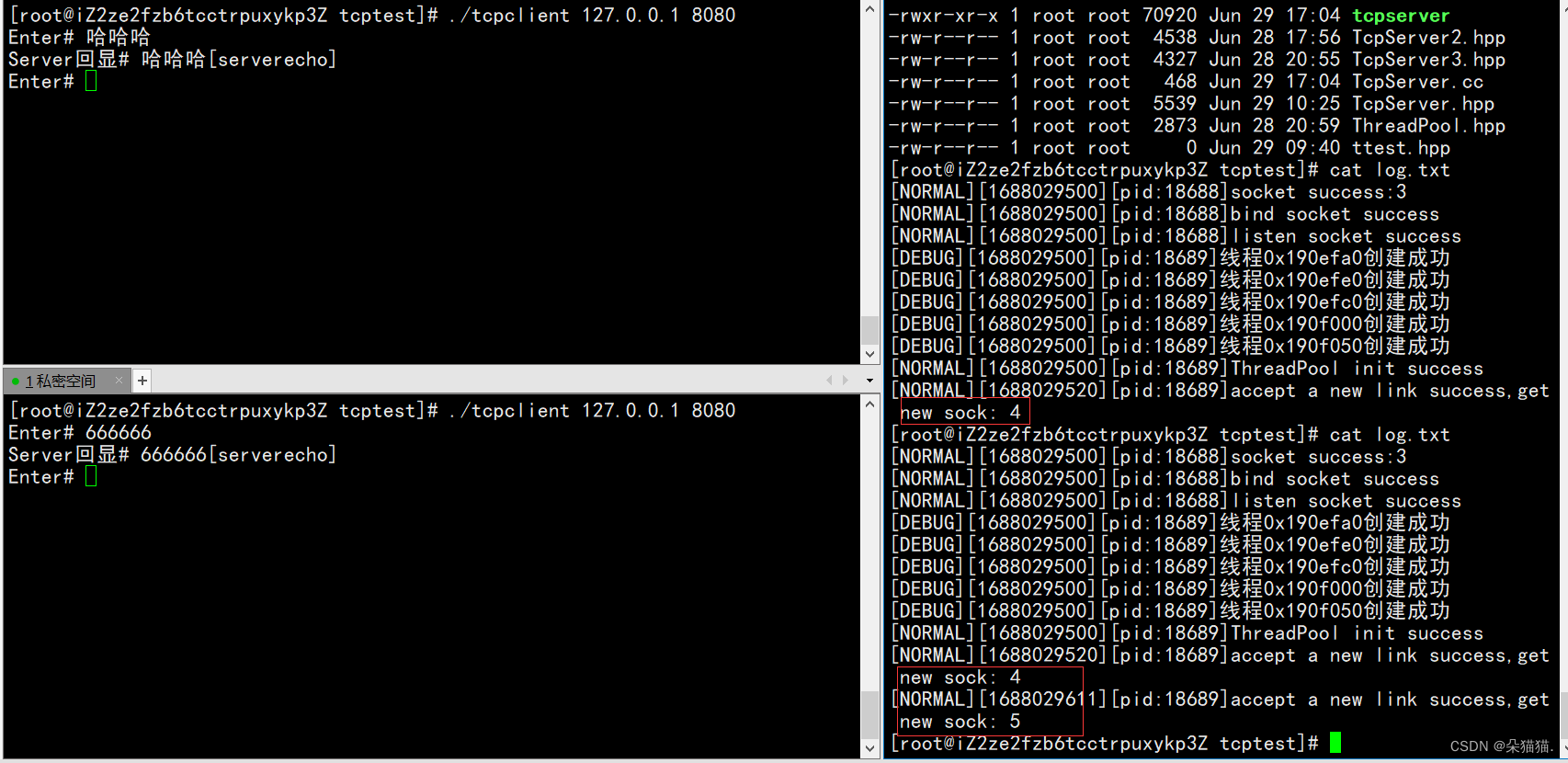
【Linux】Tcp服务器的三种与客户端通信方法及守护进程化
全是干货~ 文章目录 前言一、多进程版二、多线程版三、线程池版四、Tcp服务器日志的改进五、将Tcp服务器守护进程化总结 前言 在上一篇文章中,我们实现了Tcp服务器,但是为了演示多进程和多线程的效果,我们将服务器与客户通通信写成了一下死循…...

【Spring Cloud】git 仓库新的配置是如何刷新到各个微服务的原理步骤
文章目录 1. 第一次启动时2. 后续直接在 git 修改配置时3. 参考资料 本文描述了在 git 仓库修改了配置之后,新的配置是如何刷新到各个微服务的步骤 前言: 1、假设现有有 3 个微服务,1 个是 配置中心,另外 2 个是普通微服务&#x…...
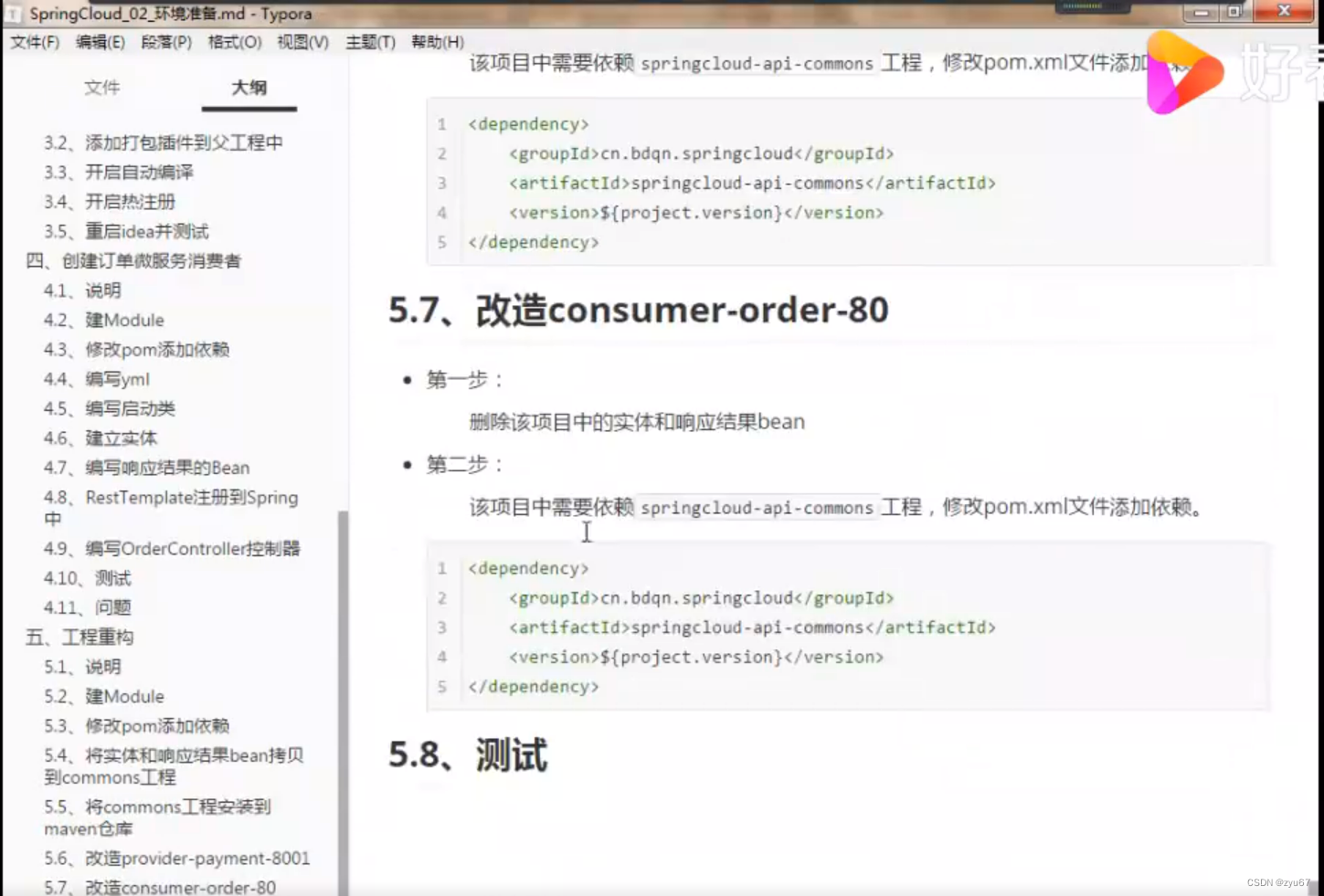
三,创建订单微服务消费者 第三章
4.3 修改pom添加依赖 <dependencies><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--监控--><dependency><groupId&g…...

【雕爷学编程】Arduino动手做(87)---ULN2003步进电机模组2
37款传感器与执行器的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止这37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的&am…...
【C#】微软的Roslyn 是个啥?
一、说明 Roslyn 是微软重写的C#编译器并开源。 Roslyn 是 C# 和 Visual Basic.NET 开源编译器的代号。以下是它如何在过去十年企业Microsoft的最黑暗中开始,并成为所有C#(和VB)的开源,跨平台,公共语言引擎,…...
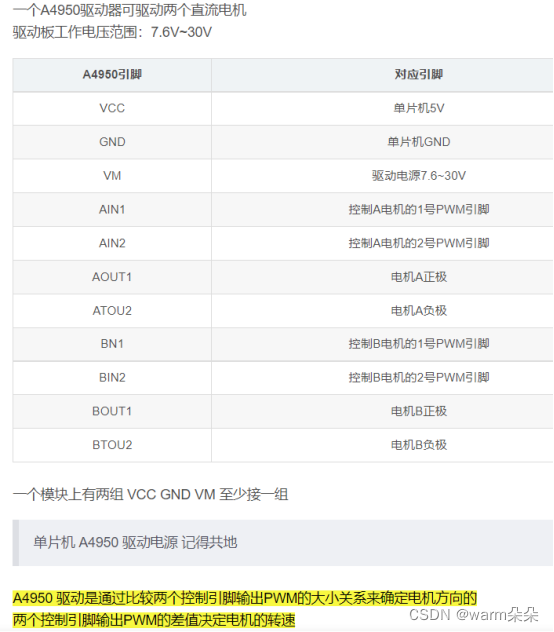
两个小封装电机驱动芯片:MLX813XX、A4950
一.MLX813XX MELEXIS的微型电机驱动MLX813XX系列芯片集成MCU、预驱动以及功率模块等能够满足10W以下的电机驱动。 相对于普通分离器件的解决方案,MLX813XX系列电机驱动芯片是一款高集成度的驱动控制芯片,可以满足汽车系统高品质和低成本的要…...
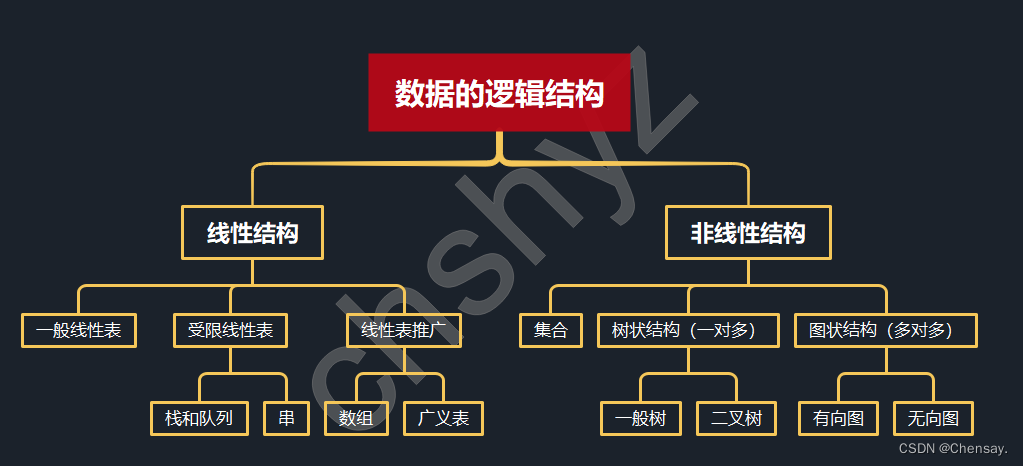
数据结构【绪论】
数据结构入门级 第一章绪论 什么是数据结构?什么是数据类型? 程序数据结构算法 一、基本概念: 数据:指所有能被计算机处理的,无论图、文字、符号等。数据元素:数据的基本单位,通常作为整体考…...
掌握无人机遥感数据预处理的全链条理论与实践流程、典型农林植被性状的估算理论与实践方法、利用MATLAB进行编程实践(脚本与GUI开发)以及期刊论文插图制作等
目录 专题一 认识主被动无人机遥感数据 专题二 预处理无人机遥感数据 专题三 定量估算农林植被关键性状 专题四 期刊论文插图精细制作与Appdesigner应用开发 近地面无人机植被定量遥感与生理参数反演 更多推荐 遥感技术作为一种空间大数据手段,能够从多时、多…...

Angular中组件设计需要注意什么?
在 Angular 中设计组件时,有几个重要的方面需要注意。以下是一些建议: 1、单一职责原则:确保每个组件只负责一个明确定义的任务。这有助于保持组件简单、可维护,并且易于重用。 2、组件通信:了解组件之间的通信方式。…...

电容触摸屏(TP)的工艺结构
液晶显示屏(LCM),触摸屏(TP) “GG、GP、GF”这是结构分类,第一个字母表面材质(又称为上层),第二个字母是触摸屏的材质(又称为下层),两者贴合在一起。 G玻璃,FFILM,“”贴…...

Qt小妙招:如何在可执行文件生成后,在pro文件中添加其他命令操作?
问题描述: 场景1:我的可执行文件设置生成路径为某个最终目录的bin目录下,当我要修改某些config.ini或者xxx.json,或者一些qss,css文件的时候,我想直接在构建的时候,Qtcreator帮我直接拷贝过去,…...

做好防雷检测的意义和作用
防雷检测是指对雷电防护装置的性能、质量和安全进行检测的活动,是保障人民生命财产和公共安全的重要措施。我国对防雷检测行业有明确的国家标准和管理办法,要求从事防雷检测的单位和人员具备相应的资质和能力,遵守相关的技术规范和规程&#…...

计算机启动过程uefi+gpt方式
启动过程: 一、通电 按下开关,不用多说 二、uefi阶段 通电后,cpu第一条指令是执行uefi固件代码。 uefi固件代码固化在主板上的rom中。 (一)uefi介绍 UEFI,全称Unified Extensible Firmware Interface&am…...

探索容器镜像安全管理之道
邓宇星,Rancher 中国软件架构师,7 年云原生领域经验,参与 Rancher 1.x 到 Rancher 2.x 版本迭代变化,目前负责 Rancher for openEuler(RFO)项目开发。 最近 Rancher v2.7.4 发布了,作为一个安全更新版本,也…...

【MySQL】内置函数
🌠 作者:阿亮joy. 🎆专栏:《零基础入门MySQL》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉函…...

使用arm-none-eabi-gcc编译器搭建STM32的Vscode开发环境
工具 make:Windows中没有make,但是可以通过安装MinGW或者MinGW-w64,得到make。gcc-arm-none-eabi:建议最新版,防止调试报错OpenOCDvscodecubeMX VSCODE 插件 Arm Assembly:汇编文件解析C/C:c…...

图数据库Neo4j学习二——cypher基本语法
1命名规范 名称应以字母字符开头,不以数字开头,名称不应包含符号,下划线除外可以很长,最多65535( 2^16 - 1) 或65534字符,具体取决于 Neo4j 的版本名称区分大小写。:PERSON和:Person是:person三个不同的标签ÿ…...

ChatGPT:人工智能交互的未来之光
一、ChatGPT:开启自然语言交流新纪元 ChatGPT 是基于 GPT(生成式预训练)技术的最新版本,它采用深度学习模型,通过在大规模文本数据上的预训练来理解自然语言,并生成具有连贯性和合理性的回复。ChatGPT 是一…...

Linux时钟子系统:CCF框架与驱动开发实践
1. Linux时钟子系统概述在嵌入式Linux系统中,时钟管理是驱动开发的基础环节之一。时钟子系统负责为整个系统提供精确的时序控制,从CPU主频到外设工作时钟,都需要通过时钟子系统进行管理和配置。Linux内核通过CCF(Common Clock Fra…...

实战揭秘:抖音直播弹幕抓取的三大技术突破与完整实现方案
实战揭秘:抖音直播弹幕抓取的三大技术突破与完整实现方案 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 在直播电商蓬勃发…...

终极EdgeRemover指南:专业卸载Windows Edge浏览器的完整解决方案
终极EdgeRemover指南:专业卸载Windows Edge浏览器的完整解决方案 【免费下载链接】EdgeRemover PowerShell script to remove Microsoft Edge in a non-forceful manner. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover EdgeRemover是一款专业的P…...
)
别再纠结FP32了!手把手教你用PyTorch的BF16和FP16加速大模型训练(附完整代码)
突破显存瓶颈:PyTorch混合精度训练实战指南 当你在深夜盯着屏幕上那个"CUDA out of memory"的错误提示时,是否感到一阵无力?大模型训练就像是在走钢丝——一边是宝贵的显存资源,另一边是模型性能的悬崖。作为一名经历过…...

javaweb铁路火车接发车课程作业培训考试系统证书
目录同行可拿货,招校园代理 ,本人源头供货商铁路火车接发车课程作业培训考试系统证书的功能分析系统概述功能模块分析技术实现要点行业合规性扩展功能建议项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 …...

暗黑破坏神2存档全功能解决方案:d2s-editor高效修改与管理指南
暗黑破坏神2存档全功能解决方案:d2s-editor高效修改与管理指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor d2s-editor是一款专为《暗黑破坏神2》玩家设计的开源存档编辑工具,提供d2s格式(…...

针对C++开源项目的AI工具讲解。我将它们分为两大类,便于理解
以下是针对C开源项目的AI工具讲解。我将它们分为两大类,便于理解: C开发者使用AI工具来提升开源项目开发效率(代码补全、调试、重构、文档生成等)。用C开发的开源AI工具/框架(这些工具本身是C开源项目,常用…...

Python 学习笔记:学习路线图规划
1989 年的圣诞节期间,时任荷兰数学和计算机科学研究学会(CWI)研究员的 Guido van Rossum[1] 决定基于 ABC 语言设计并实现一门新的脚本编程语言,最初目的是用于替代 Unix shell 和部分 C 程序,以承担 Amoeba 分布式操作…...

ClickHouse可视化工具大比拼:Tabix vs DBeaver,哪个更适合你?
ClickHouse可视化工具深度评测:Tabix与DBeaver的实战对比 当你面对ClickHouse海量数据时,一个得心应手的可视化工具能让你事半功倍。作为目前最流行的两款ClickHouse客户端,Tabix和DBeaver各有拥趸,但究竟哪款更适合你的工作场景…...

EPSON机器人通信避坑指南:TCP/IP协议在LS3-401S上的常见问题与解决方案
EPSON机器人通信避坑指南:TCP/IP协议在LS3-401S上的常见问题与解决方案 在工业自动化领域,EPSON LS3-401S机器人凭借其高精度和可靠性广受青睐。然而,在实际部署过程中,TCP/IP通信问题往往成为工程师们的"拦路虎"。本文…...