Pytorch个人学习记录总结 07
目录
神经网络-非线性激活
神经网络-线形层及其他层介绍
神经网络-非线性激活
官方文档地址:torch.nn — PyTorch 2.0 documentation
常用的:Sigmoid、ReLU、LeakyReLU等。
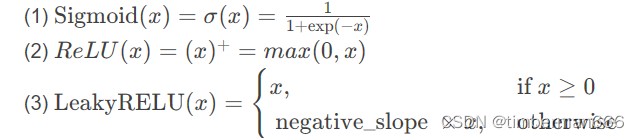
作用:为模型引入非线性特征,这样才能在训练过程中训练出符合更多特征的模型。
其中有个参数是inplace,默认为False,表示是否就地改变输入值,True则表示直接改变了input不再有另外的返回值;False则没有直接改变input并有返回值(建议是inplace=False)。
import torch
from torch import nninput = torch.tensor([[3, -1],[-0.5, 1]])
input = torch.reshape(input, (1, 1, 2, 2))relu = nn.ReLU()
input_relu = relu(input)print('input={}\ninput_relu:{}'.format(input, input_relu))# input=tensor([[[[ 3.0000, -1.0000],
# [-0.5000, 1.0000]]]])
# input_relu:tensor([[[[3., 0.],
# [0., 1.]]]])
神经网络-线形层及其他层介绍
Linear Layers中的torch.nn.Linear(in_features, out_features, bias=True)。默认bias=True。对传入数据应用线性变换
Parameters:
in_features– size of each input sample(每个输入样本的大小)out_features– size of each output sample(每个输出样本的大小)bias– If set to False, the layer will not learn an additive bias. Default: True(如果为False,则该层不会学习加法偏置,默认为true)
Shape:分别关注输入、输出的最后一个维度的大小,在训练过程中,nn.Linear往往是当作的展平为一维后最后几步的全连接层,所以此时就只关注了通道数,即往往Input和Outputs是一维的)
“展平为一维”经常用到torch.nn.Flatten(start_dim=1, end_dim=- 1)
想说一下start_dim,它表示“从start_dim开始把后面的维度都展平到同一维度上”,默认是是1,在实际训练中从start_dim=1开始展平,因为在训练中的tensor是4维的,分别是[batch_size, C, H, W],而第0维的batch_size不能动它,所以是从1开始的。
还比较重要的有:torch.nn.BatchNorm2d、torch.nn.Dropout、Loss Functions(之后再讲)。其它的Transformer Layers、Recurrent Layers都不是很常用。
import torch# 对4维tensor展平,start_dim=1input = torch.arange(54)
input = torch.reshape(input, (2, 3, 3, 3))y_0 = torch.flatten(input)
y_1 = torch.flatten(input, start_dim=1)print(input.shape)
print(y_0.shape)
print(y_1.shape)# torch.Size([2, 3, 3, 3])
# torch.Size([54])
# torch.Size([2, 27])
相关文章:
Pytorch个人学习记录总结 07
目录 神经网络-非线性激活 神经网络-线形层及其他层介绍 神经网络-非线性激活 官方文档地址:torch.nn — PyTorch 2.0 documentation 常用的:Sigmoid、ReLU、LeakyReLU等。 作用:为模型引入非线性特征,这样才能在训练过程中…...
vue3+ts+elementui-plus二次封装树形表格
复制粘贴即可: 一、定义table组件 <template><div classmain><div><el-table ref"multipleTableRef" :height"height" :default-expand-all"isExpend" :data"treeTableData"style"width: 100%…...
)
机器学习/深度学习常见算法实现(秋招版)
包括BN层、卷积层、池化层、交叉熵、随机梯度下降法、非极大抑制、k均值聚类等秋招常见的代码实现。 1. BN层 import numpy as npdef batch_norm(outputs, gamma, beta, epsilon1e-6, momentum0.9, running_mean0, running_var1)::param outputs: [B, L]:param gamma: mean:p…...

京东技术专家首推:Spring 微服务架构设计,GitHub 星标 128K
前言 本书提供了实现大型响应式微服务的实用方法和指导原则,并通过示例全面 讲解如何构建微服务。本书深入介绍了 Spring Boot、Spring Cloud、 Docker、Mesos 和 Marathon,还会教授如何用 Spring Boot 部署自治服务,而 无须使用重量级应用服…...

R语言--森林图制作
#数据准备- data5 #install.packages("rmda")rm(list=ls())library(MASS)library(rmda)library(dplyr) #mutate依赖环境library(magrittr) #%>%依赖setwd("D:/R/nomo5new2")data...

Tomcat中利用war包部署
在Tomcat中利用war包部署Web应用程序时,默认情况下,应用程序的上下文路径(也称为项目名称)将是war文件的名称(去除.war扩展名)。这意味着您在访问Web应用程序时必须在URL中包含项目名称。例如,如…...
[JAVAee]线程安全
目录 线程安全的理解 线程不安全的原因 ①非原子性 ②可见性 ③代码重排序 体会何为不安全的线程 保证线程安全 一个代码在多线程的环境下就很容易出现错误. 线程安全的理解 线程安全是什么呢?通俗的来讲,线程安全就是在多线程的环境下,代码的结果是符合我们预期的,就…...

ELK环境搭建——概况
Elastic Stack,核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash等等。能够安全可靠地从任何来源获取任何格式的数据,然后对数据进行搜索、分析和可视化。 目录 一:Elasticsearch: 1.1 从数据中探寻各种问题的答案 1.1.1 定义您自己的搜索方式...

面试知识点整理
计算机的物理内存是有限的,所以操作系统在遇到内存不足时,会通过换页机制暂时把 某个进程未使用的内存中的数据搬移到硬盘上(比如 Linux 的 swap 分区),并在系统页表中 删除相应的表项。当该进程访问数据已经被搬移到硬…...

腾讯云服务器CVM计算型c6/c5实例CPU型号、处理器主频大全
腾讯云服务器CVM计算型C6、C5、C4、CN3、C3和C2实例,计算型C6云服务器CPU采用Intel Xeon Ice Lake处理器,主频3.2GHz,睿频3.5GHz,腾讯云服务器网分享更多计算型CVM云服务器CPU型号、处理器主频性能说明: 目录 云服务…...

vue3笔记-脚手架篇
第一章 基础篇 第二章 脚手架篇 vue2与vue3的一些区别 响应式系统: Vue 2 使用 Object.defineProperty 进行响应式数据的劫持和监听,它对数据监听是一项项的进行监听,因此,当新增属性发生变化时,它无法监测到&…...

数字的补数
题目: 对整数的二进制表示取反(0 变 1 ,1 变 0)后,再转换为十进制表示,可以得到这个整数的补数。 例如,整数 5 的二进制表示是 "101" ,取反后得到 "010" &…...

Taskfile demo
https://github.com/yangyang5214/blog/issues/1 makefile 很好用,但是有些语法我不会。 go-task yml & shell 不错,推荐 Taskfile.yml https://github.com/go-task/task/blob/main/.golangci.yml # go install github.com/go-task/task/v3/cmd/ta…...

MyBatis学习笔记之高级映射及延迟加载
文章目录 环境搭建,数据配置多对一的映射的思路逻辑级联属性映射association分布查询 一对多的映射的思路逻辑collection分布 环境搭建,数据配置 t_class表 t_stu表 多对一的映射的思路逻辑 多对一:多个学生对应一个班级 多的一方是st…...

小程序如何删除/上架/下架商品
在小程序中,产品的删除、上架和下架是常见的操作,可以根据实际需求来管理商品的展示与销售。下面将介绍如何在小程序中删除上架下架商品的具体步骤。 进入商品管理页面, 在个人中心点击管理入口,然后找到“商品管理”菜单并点击。…...
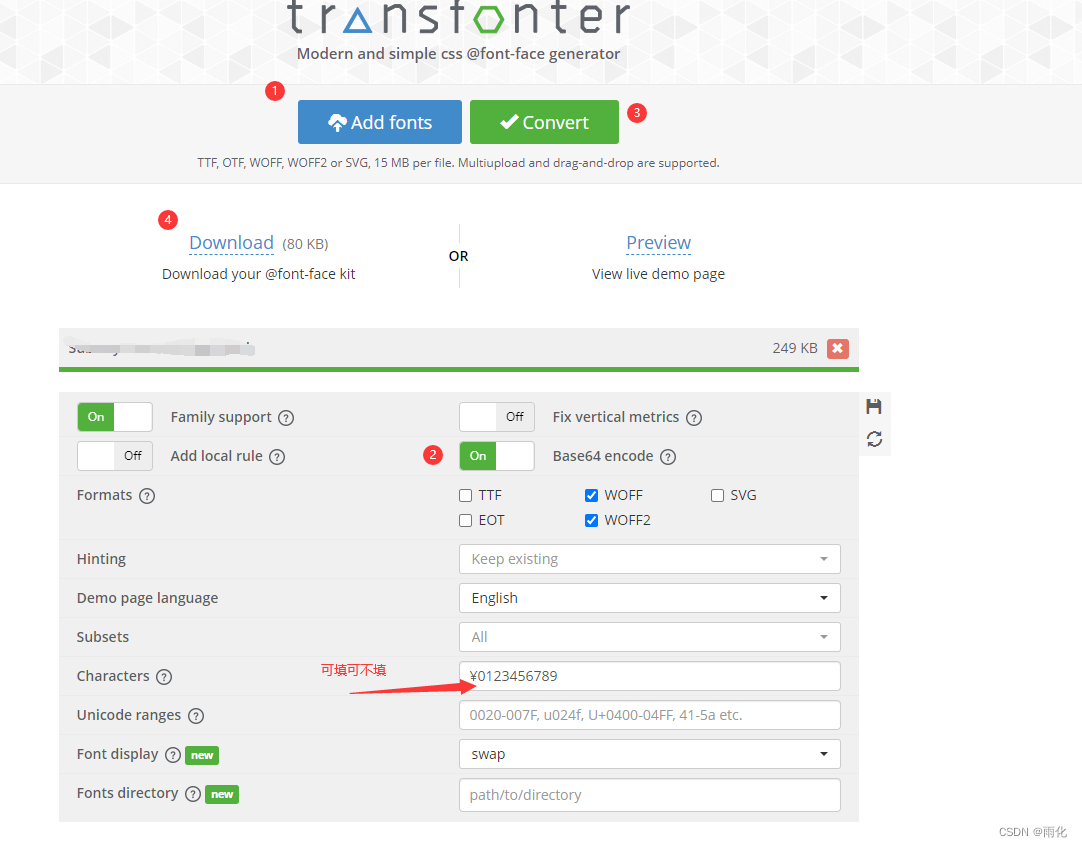
Failed to load local font resource:微信小程序加载第三方字体
加载本地字体.ttf 将ttf转换为base64格式:https://transfonter.org/ 步骤如下 将下载后的stylesheet.css 里的font-family属性名字改一下,然后引进页面里就行了,全局样式就放app.scss,单页面就引入单页面 注: .title…...
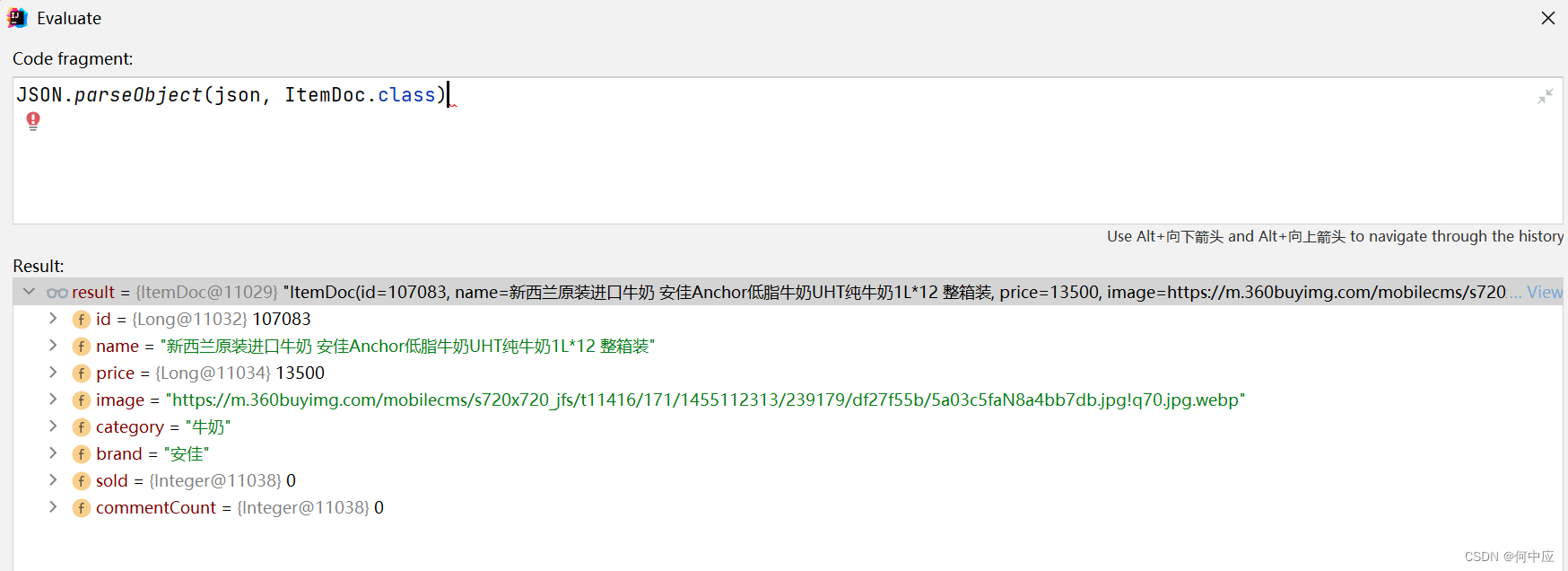
使用fastjson错误
说明:使用fastjson时,对象解析不成功,一直报错,但是json格式没有错; 错误信息:Method threw ‘com.alibaba.fastjson.JSONException’ exception. json数据是正确的 分析:注意看,fa…...
【GitOps系列】使用Kustomize和Helm定义应用配置
文章目录 使用 Kustomize 定义应用改造示例应用1.创建基准和多环境目录2.环境差异分析3.为 Base 目录创建通用 Manifest4.为开发环境目录创建差异 Manifest5.为预发布环境创建差异 Manifest6.为生产环境创建差异 Manifest 部署 Kustomize 应用部署到开发环境部署到生产环境 使用…...

Android kotlin高阶函数与Java lambda表达式介绍与实战
一、介绍 目前在Java JDK版本的不断升高,新的表达式已开始出现,但是在Android混淆开发中,kotlin的语言与Java的语言是紧密贴合的。所以Java lambda表达式在kotlin中以新的身份出现:高阶函数与lambda表达式特别类似。接下来我讲会先…...
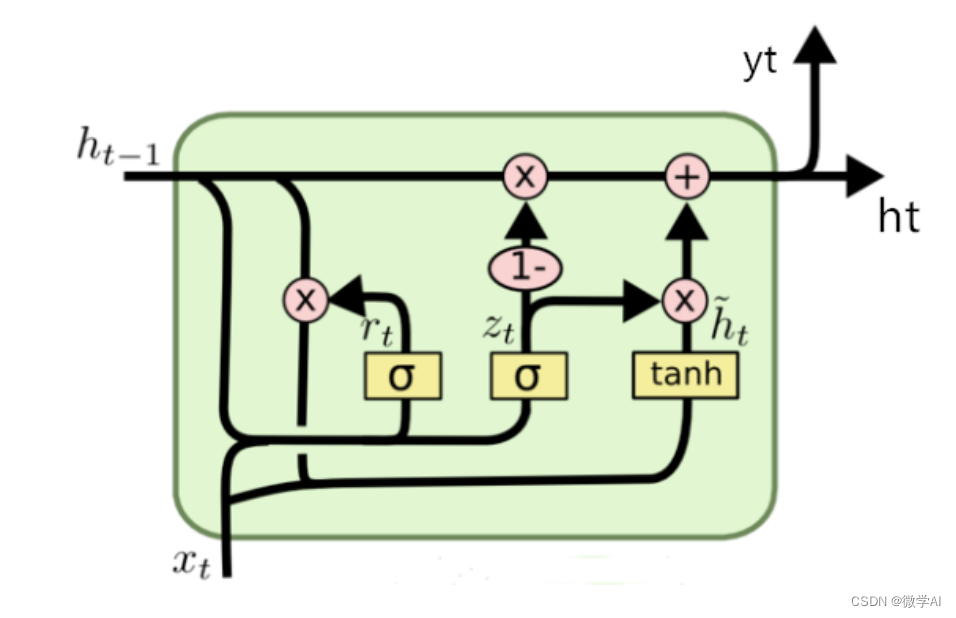
自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程。本文主要介绍关键词抽取样例数据、GRU模型模型构建与训练、命名实体识别(NER)、模型评估与应用,项目的目标是通过训练一个GRU模型…...

【分箱进阶篇】分箱的工程细节:从训练到部署的完整模式
基础篇参考:【分箱基础篇】pandas 分箱双子星:pd.cut 与 pd.qcut 我们在基础篇讲了 pd.cut 和 pd.qcut 各自怎么用。但在实际项目里,分箱不是调一次函数就完事的。通常来说,训练集上算出来的切分点要保存下来,测试集…...
)
别再只防SSH了!给OpenWRT的Web管理后台LuCI也加上fail2ban防护(附日志配置避坑指南)
OpenWRT安全加固:为LuCI管理界面部署fail2ban防护的完整方案 路由器作为家庭网络的入口,其安全性往往被严重低估。大多数用户会记得给SSH服务配置fail2ban防护,却忽略了同样暴露在公网的Web管理界面——LuCI。这种安全防护的"偏科"…...

Swagger2Word:高效转换与文档自动化的API文档解决方案
Swagger2Word:高效转换与文档自动化的API文档解决方案 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 在软件开发过程中,API文档的管理和维护常常成为团队协作的痛点。开发人员使用Swagger/OpenAPI规…...

告别电台收听难题:foobox-cn网络电台收听方案
告别电台收听难题:foobox-cn网络电台收听方案 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn foobox-cn作为foobar2000的DUI皮肤(桌面用户界面定制方案)࿰…...

ChatGLM3-6B-128K在客服系统中的应用:智能回复生成
ChatGLM3-6B-128K在客服系统中的应用:智能回复生成 1. 引言 想象一下,一个繁忙的电商客服中心,每天要处理成千上万的客户咨询。传统的人工客服需要不断重复回答相似的问题,不仅效率低下,还容易因为疲劳而出错。现在&…...

基于StructBERT的代码相似性检测在编程教育中的应用
基于StructBERT的代码相似性检测在编程教育中的应用 1. 引言 如果你是编程课的老师,面对几十份甚至上百份学生提交的作业,最头疼的是什么?是逐行检查代码逻辑,还是判断学生之间是否存在抄袭?传统的代码相似性检查工具…...
Windows个性化视觉增强:TranslucentTB打造专属任务栏体验
Windows个性化视觉增强:TranslucentTB打造专属任务栏体验 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 您是否曾感到Window…...

5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南
5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...
原理入门:模型辅助理解AI视觉基础)
通义千问1.5-1.8B-Chat-GPTQ-Int4 卷积神经网络(CNN)原理入门:模型辅助理解AI视觉基础
通义千问1.5-1.8B-Chat-GPTQ-Int4 卷积神经网络(CNN)原理入门:模型辅助理解AI视觉基础 你是不是经常看到“AI识别图片”、“自动驾驶看路”、“手机相册自动分类”这些功能,然后好奇它们是怎么做到的?其实,…...

DAMOYOLO-S基础教程:理解count字段与实际业务中目标计数逻辑映射
DAMOYOLO-S基础教程:理解count字段与实际业务中目标计数逻辑映射 1. 从一次“数数”的困惑说起 前两天,一个做零售分析的朋友找我帮忙。他兴奋地告诉我,他们用上了最新的AI目标检测模型,想自动统计货架上的商品数量。他上传了一…...