LangChain大型语言模型(LLM)应用开发(五):评估

LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。
今天我们来学习DeepLearning.AI的在线课程:LangChain for LLM Application Development的第五门课:Evaluation(评估),所谓评估是指检验LLM回答的问题是否正确的方法,在上一篇博客Q&A over Documents中我们解释了如何通过langchain来实现对文档的问答功能,在文档的问答过程中LLM会就用户提出的关于文档内容的相关问题进行回答,那么今天我们需要研究的就是如何来检验LLM的回答是否正确?
要评估LLM回答问题的准确性大致需要下面几个步骤:
- 需要创建一组关于相关的问答测试集(包含了问题和标准答案)
- 让LLM回答测试集中的所有问题,并收集LLM给出的所有答案
- 将LLM的答案与问答测试集中的标准答案做比对,并给LLM的表现评分
下面我们就开始来讨论评估LLM表现吧!
创建基于文档问答的Q/A应用
首先我们还是要做一些基础性工作,比如设置openai的api key,导入一些langchain的基础库:
import pandas as pd
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import DocArrayInMemorySearch
import osfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file接下来我们需要导入一个csv文件,该文档主要包含2列,name和description,其中name表示商品的名称,description表示该商品的说明信息,我们需要对改文档的产品信息进行问答。
df=pd.read_csv("OutdoorClothingCatalog_1000.csv")df
下面我们查看一下其中的某个商品信息:
print(df[:1].name.values[0])
print('------------------------')
print(df[:1].description.values[0])
下面我们将该商品的信息翻译成中文,这样便于大家理解:

接下来我们要创建一个用于回答文档内容的chain:RetrievalQA, 创建RetrievalQA需要包含以下几个步骤:
- 创建一个文档加载器CSVLoad实例
- 创建向量数据库索引index
- 创建llm
- 创建文档问答chain,RetrievalQA
#1.创建文档加载器
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
data = loader.load()#2.创建向量数据库索引
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])#3.创建llm
llm= ChatOpenAI(temperature = 0.0)#4.创建文档问答chain
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=index.vectorstore.as_retriever(), verbose=True,chain_type_kwargs = {"document_separator": "<<<<>>>>>"}
)上述代码的主要功能及作用在LangChain大型语言模型(LLM)应用开发(四):Q&A over Documents这篇博客中都已说明,这里不再赘述。
设置测试的数据
下面我们查看一下经过档加载器CSVLoad加载后生成的data内的信息,这里我们抽取data中的第九和第十条数据看看它们的主要内容:

手动创建测试集
需要说明的是这里我们的文档是csv文件,所以我们使用的是文档加载器是CSVLoader,CSVLoader会对csv文件中的每一行数据进行分割,所以这里看到的data[10],data[11]的内容则是csv文件中的第10,第11条数据的内容。下面我们根据这两条数据手动设置两条“问答对”,每一个“问答对”中包含一个query,一个answer:
examples = [{"query": "Do the Cozy Comfort Pullover Set\have side pockets?","answer": "Yes"},{"query": "What collection is the Ultra-Lofty \850 Stretch Down Hooded Jacket from?","answer": "The DownTek collection"}
]让LLM生成Q/A测试用例
在我以前写的两篇博客中(使用大型语言模(LLM)构建系统(七):评估1,与 使用大型语言模(LLM)构建系统(七):评估2)我们使用的方法都是通过手动的方法来构建测试数据集,比如说我们可以手动创建10个问题和10个答案,然后让LLM回答这10个问题,再将LLM给出的答案与我们准备好的答案做比较,最后再给LLM打分。评估的流程大概就是这样,但是这里有一个问题,就是我们需要手动去创建所有的问题集和答案集,那会是一个非常耗费人力和时间的成本。那有没有一种可以自动创建大量问题集和答案集的方法呢?那当然是有的,今天我们就来介绍Langchain提供的方法:QAGenerateChain,我们可以通过QAGenerateChain来为我们的文档自动创建问答集:
from langchain.evaluation.qa import QAGenerateChainexample_gen_chain = QAGenerateChain.from_llm(ChatOpenAI())new_examples = example_gen_chain.apply([{"doc": t} for t in data[:5]])
print(new_examples)
这里我们对上述代码做个简单说明,我们创建了一个QAGenerateChain,然后我们应用了QAGenerateChain的apply方法对data中的前5条数据创建了5个“问答对”,由于创建问答集是由LLM来自动完成的,因此会涉及到token成本的问题,所以我们这里出于演示的目的,只对data中的前5条数据创建问答集。
那QAGenerateChain是如何自动创建问题集的,一个简单的apply方法似乎隐藏了很多的细节,如果你对这个隐藏的细节感兴趣,那我们可以尝试用debug的方式来打开这个潘多拉魔盒:
import langchain#打开debug
langchain.debug = Truenew_examples = example_gen_chain.apply([{"doc": t} for t in data[:5]])#关闭debug
langchain.debug = False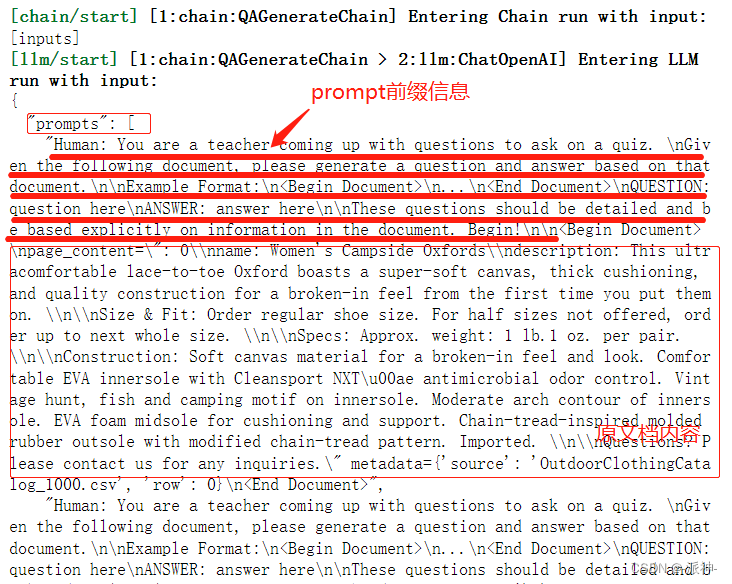
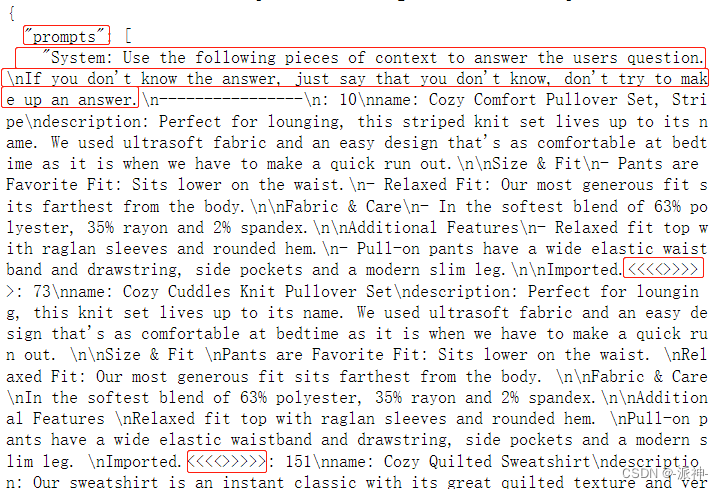
从上面展现的细节中我们可以看到,原来在QAGenerateChain中有一个内置的prompt,在这个内置的prompt的前缀信息中,以"Human"的角色要求LLM对给与它的文档产生一个question和answer。这个prompt的前缀信息大概就长这个样子:
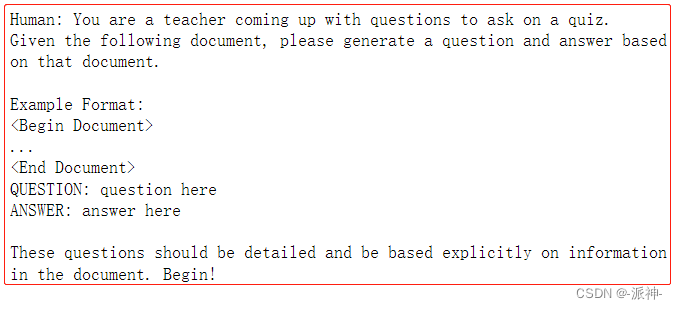
QAGenerateChain会在data中的每一条数据中都运用这个prompt模板,因此data中的每一条数据都会产生一条“问答对”。有了问答集以后,我们还需要对问答集进行解析,从中过滤出真正有用的信息,不过我们首先需要创建一个解析函数parse_strings:
def parse_strings(strings_list):parsed_list = []for s in strings_list:s = s.replace('\n\n','\n')split_s = s.split('\n')# Ensure there are 2 parts in the split stringif len(split_s) != 2:continuequestion_part, answer_part = split_s# Ensure each part has the correct prefixif not question_part.startswith('QUESTION: ') or not answer_part.startswith('ANSWER: '):continue# Remove the prefixes and strip leading/trailing whitespacequestion = question_part.replace('QUESTION: ', '').strip()answer = answer_part.replace('ANSWER: ', '').strip()parsed_list.append({"query": question, "answer": answer})return parsed_list#对问答集进行解析
new_examples = parse_strings([t['text'] for t in new_examples])
print(new_examples)
这里经过解析以后我们的new_examples 中只包含了5个query和5个answer,没有其他多余的信息,这正是我们想要的测试集。
组合测试集
还记得我们前面手动创建的两个问答集吗?现在我们需要将之前手动创建的问答集合并到QAGenerateChain创建的问答集中,这样在答集中既有手动创建的例子又有llm自动创建的例子,这会使我们的测试集更加完善:
examples += new_examplesexamples 
这里我们看到examples 的前两条数据就是我们先前手动创建的,接下来我们就需要让之前创建的文档问答chain来回答这个测试集里的问题,来看看LLM是怎么回答的吧:
qa.run(examples[0]["query"]) 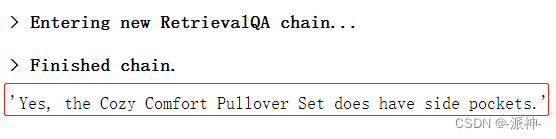
这里我们看到qa回答了第0个问题:“Yes, the Cozy Comfort Pullover Set does have side pockets.” ,这里的第0个问题就是先前我们手动创建的第一个问题,并且我们手动创建的answer是 :"Yes", 这里我们发现问答chain qa回答的也是“Yes”,只是它比我们的答案还多了一段说明:“the Cozy Comfort Pullover Set does have side pockets.”。
你想知道问答chain qa是怎么找到问题的答案的吗?魔鬼往往隐藏在细节中,下面让我们打开debug,看看问答chain qa是如何找到问题的答案!
langchain.debug = Trueqa.run(examples[0]["query"])langchain.debug = False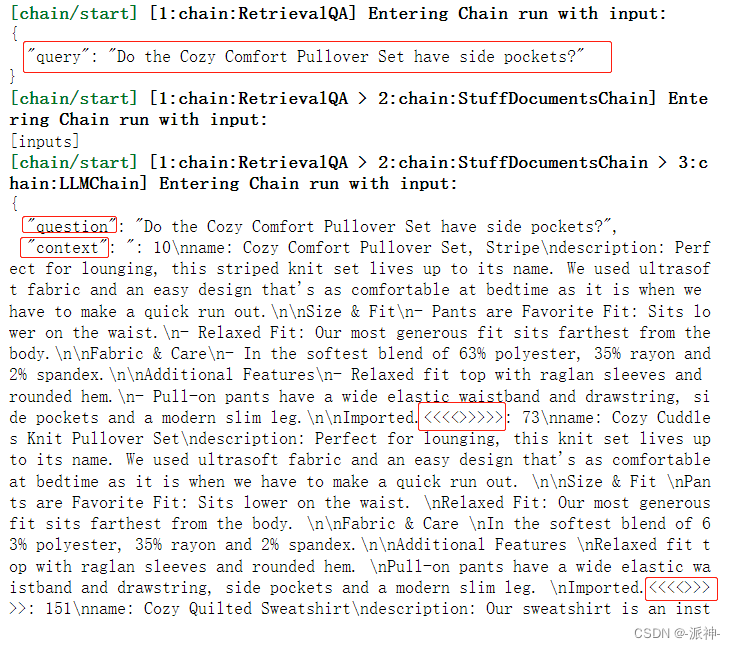
这里我们稍微对问答chain qa寻找答案的过程进行一些说明,首先qa拿到问题,然后根据问题去向量数据库中搜索和问题相关的产品信息(会在全部产品中搜索),由于向量数据库中可能会存在多条产品信息和问题相关,因此这里会用“<<<<>>>>>”来分隔搜索到的多个产品信息,这里所谓的搜索是指向量间的相似度计算和比较,首先将问题转换成向量,再计算问题向量和数据库中每个向量的相似度,获取相似度最高的n条向量,然后再将这些相似的向量再转换成对应的文本即可。当这些步骤完成以后我们就看到了上述的结果,其中罗列了question和content,question是我们提出的问题,而“content”则是搜索到的多个相关产品信息,它们被用“<<<<>>>>>”分隔。这里需要加入一个我的个人判断:在搜索相关文档的时候应该是没有llm参与的,因此不会产生token成本的问题。在有了问题和相关产品信息后,接下来就需要LLM登场了,这里就会有一个prompt,在这个prompt中有一个System前缀信息,它告诉llm需要做什么,紧接着前缀信息的是多个产品信息,它们被用<<<<>>>>>进行分隔,最后是我们的问题,这里用Human来标识我们的问题。
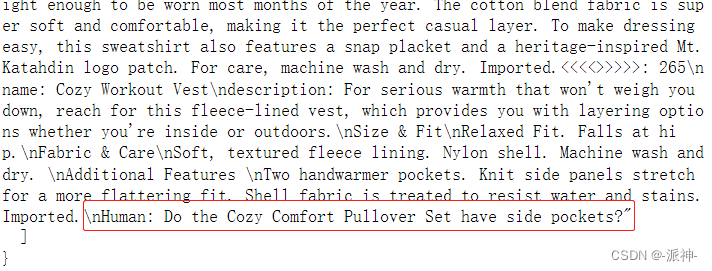
下面是输出部分,LLM会根据给它的prompt输出一个内容较多的json格式的结果,其中包含了问题的答案:

最后经过过滤,得到了最终的答案:

前面我们让问答chain qa回答了测试集中的一个问题,下面我们要做的是让qa来回答测试集中的所有问题:
predictions = qa.apply(examples)
基于LLM的自我评估
让我们来理一下思路,首先我们让LLM自动创建了问答测试集,接着我们又让LLM回答了测试集中所有的问题并得到了所有问题的回复信息。接下来我们要做的就是将这些问题的回复信息与测试集里的答案进行比对,更其妙的是这个比对过程也将是由LLM自己来完成,也就是说我们的LLM既当球员,又当裁判,最后再由“裁判”给出比对的结果,不过我需要指出的这里既当球员,又当裁判的LLM并非是同一个chain构成的,它们来自于不同的chain,也就是说这些chain的职能是不同的:
from langchain.evaluation.qa import QAEvalChain#创建LLM
llm = ChatOpenAI(temperature=0)#创建评估chain
eval_chain = QAEvalChain.from_llm(llm)#生成评估结果
graded_outputs = eval_chain.evaluate(examples, predictions)#统计评估结果
for i, eg in enumerate(examples):print(f"Example {i}:")print("Question: " + predictions[i]['query'])print("Real Answer: " + predictions[i]['answer'])print("Predicted Answer: " + predictions[i]['result'])print("Predicted Grade: " + graded_outputs[i]['text'])print()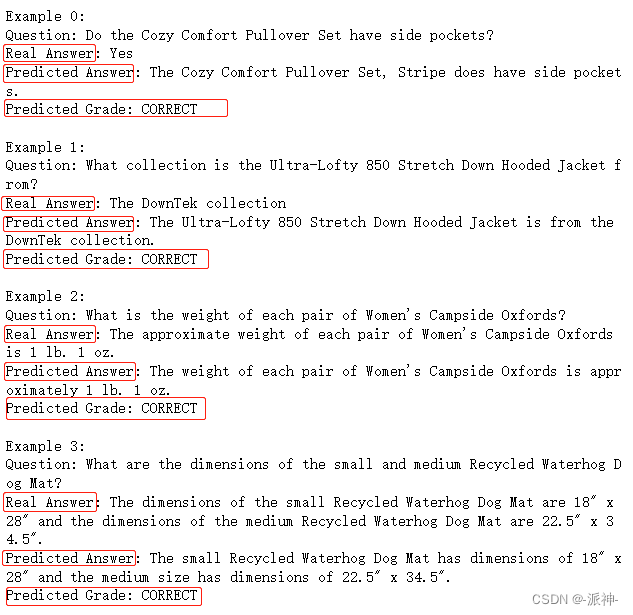
从上面的返回结果中我们看到,每一个问题中都包含了Question,Real Answer,Predicted Anser和Predicted Grade 四组内容,其中Real Answer是有先前的QAGenerateChain创建的问答测试集中的答案,而Predicted Answer则是由我们的问答chain qa回答的问题,最后的Predicted Grade则是由上面代码中的QAEvalChain回答的。
总结
今天我们学习了如何利用Langchain来评估LLM的表现,和以前评估openai模型的方法不同的是,这里我们使用的是全自动方式,即全自动方式生成测试集,然后全自动的给出问题的预测结果,最好全自动的评估预测结果的准确性,通过这种全自动的方式解放了我们的双手,使我们不需要因为没有测试数据集而苦恼,大大提高了生产率。
参考资料
QA Generation | 🦜️🔗 Langchain
Question Answering | 🦜️🔗 Langchain
相关文章:
LangChain大型语言模型(LLM)应用开发(五):评估
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…...
Angular:动态依赖注入和静态依赖注入
问题描述: 自己写的服务依赖注入到组件时候是直接在构造器内初始化的。 直到看见代码中某大哥写的 private injector: Injector 动态依赖注入和静态依赖注入 在 Angular 中,使用构造函数注入的方式将服务注入到组件中是一种静态依赖注入的方式。这种方…...

Java前后端交互long类型溢出的解决方案
问题描述: 前端根据id发起请求查找对象的时候一直返回找不到对象,然后查看了请求报文,发现前端传给后台的数据id不对,原本的id是1435421253099634623,可前端传过来的id是 1435421253099634700,后三位变成了…...

Lua学习-1 基础数据类型
文章目录 基础数据类型分类nilbooleannumberstringfunctionuserDatathreadtable 如何判断类型(type)不同类型数据常见操作nilnumberstring(字符串)function普通函数匿名函数不定参数函数 table 基础数据类型分类 nil 表示无效值 boolean 只有 true 和…...

普通的计算机专业大学生如何学习才能找到好offer
2023年已经将近8月份了,回想到开始努力提高自己的时候还是在今年1月1号。开学就要大二了。 一、目标达成情况总结: 一月份,无意间在网上刷到鹏哥的C语言课程,在鸡汤实力课程已拿到大厂offer的同学喜报 ,让我萌发了学技…...
iOS私钥证书和证书profile文件的生成攻略
在使用uniapp打包ios app的时候,要求我们提供一个私钥证书和一个证书profile文件,私钥证书可以使用mac电脑的钥匙串访问程序来生成,也可以使用香蕉云编来生成。证书profile文件可以直接在苹果开发者中心生成。 有部分刚接触ios开发的同学们&…...

前端 | ( 十二)CSS3简介及基本语法(中)| 变换、过渡与动画 | 尚硅谷前端html+css零基础教程2023最新
学习来源:尚硅谷前端htmlcss零基础教程,2023最新前端开发html5css3视频 系列笔记: 【HTML4】(一)前端简介【HTML4】(二)各种各样的常用标签【HTML4】(三)表单及HTML4收尾…...
【BOOST程序库】时间日期库
基本概念这里不再浪费时间介绍了,这里给出时间日期库的常见使用方法: #define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <string> #include <boost/version.hpp> #include <boost/config.hpp>//时间库࿱…...
 命令行字符串长度限制)
Windows 命令提示符 (cmd. exe) 命令行字符串长度限制
在Windows中,命令提示符 (cmd. exe) 命令行字符串是有长度限制的,本文帮助你了解命令行中的字符串长度限制,以免你的批处理脚本踩坑。 (以下在Win10环境测试过) 字符串长度限制 可在命令提示符处使用的字符串的最大长…...

Kafka 入门到起飞系列
Kafka 入门到起飞系列 [Kakfa 为什么牛? 为什么这么火?有什么优势呢?](https://blog.csdn.net/FightingITPanda/article/details/131941293)[工欲善其事,必先利其器 - 核心概念(术语解释)](https://blog.cs…...

[RabbitMQ] RabbitMQ简单概述,用法和交换机模型
MQ概述: Message Queue(消息队列),实在消息的传输过程中保存消息的容器,都用于分布式系统之间进行通信 分布式系统通信的两种方式:直接远程调用 和 借助第三昂 完成间接通信 发送方称谓生产者,接收方称为消费者 MQ优…...
Oracle 多条记录根据某个字段获取相邻两条数据间的间隔天数,小于31天的记录都筛选出来
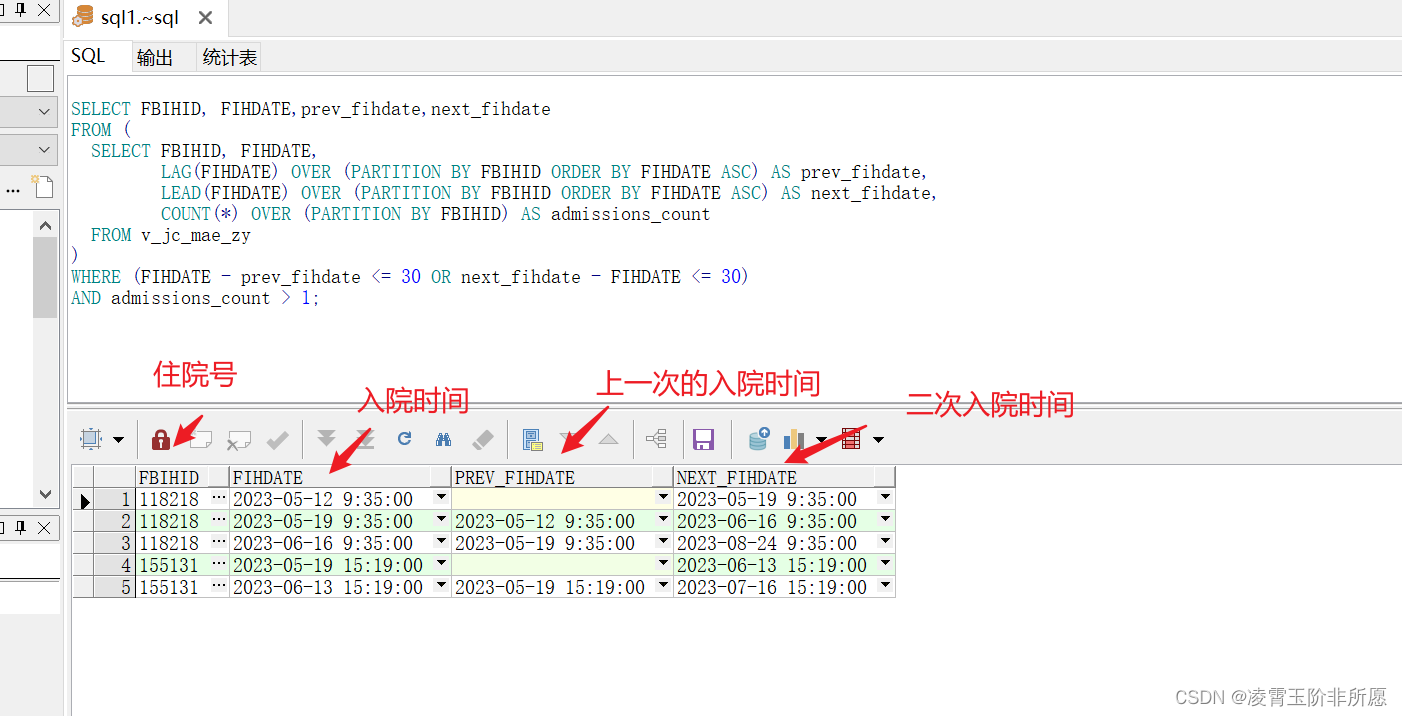
需求描述:在Oracle中 住院记录记录表为v_hospitalRecords,表中FIHDATE入院时间,FBIHID是住院号, 我想查询出每个患者在他们的所有住院记录中是否在一个月内再次入院(相邻的两条记录进行比较),并且住院记录大于一的患者…...

【数据挖掘】如何修复时序分析缺少的日期
一、说明 我撰写本文的目的是通过引导您完成一个示例来帮助您了解 TVF 以及如何使用它们,该示例解决了时间序列分析中常见的缺失日期问题。 我们将介绍: 如何生成日期以填补数据中缺失的空白如何创建 TVF 和参数的使用如何呼叫 TVF我们将考虑扩展我们的日…...

CDN、P2P、PCDN的区别是什么
本篇文章为大家介绍一下与网络加速有关的几个重要概念,一起了解一下CDN,P2P和PCDN究竟是什么吧! 1. CDN CDN即Content Delivery Network,中文全称为内容分发网络。 如果内容离用户远,用户可能无法获得及时的响应,那…...
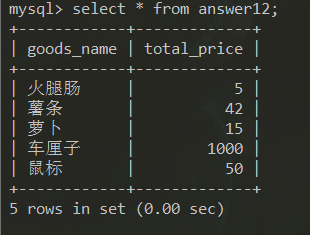
MYSQL练习一答案
练习1答案 构建数据库 数据库 数据表 answer开头表为对应题号答案形成的数据表 表结构 表数据 答案: 1、查询商品库存等于50的所有商品,显示商品编号,商 品名称,商品售价,商品库存。 SQL语句 select good_no,good…...
)
路由器(第二十五课)
路由器的深入学习 一、路由 1、路由 1) 什么是路由:路由就是数据包从一个网络到另外一外网络的过程 2)支持路由功能的设备:路由器、三层交换机、防火墙 3 路由器转发数据包的依据: -每一台路由器都维护着一张路由表 -路由器是依靠这张路由表来转发数据的 -这张路由表就…...

物联网网关模块可以带几台plc设备吗?可以接几个modbus设备?
随着物联网技术的快速发展,物联网网关模块已经成为了实现物联网应用的重要工具。很多客户在选择物联网网关模块时想了解物联网网关模块的设备接入能力,一个物联网网关模块可以带几台PLC设备?可以接几个Modbus设备? 物联网网关模块…...
SpringBoot中间件—ORM(Mybatis)框架实现
目录 定义 需求背景 方案设计 代码展示 UML图 实现细节 测试验证 总结 源码地址(已开源):https://gitee.com/sizhaohe/mini-mybatis.git 跟着源码及下述UML图来理解上手会更快,拒绝浮躁,沉下心来搞 定义&#x…...

结构化思维:高效能项目经理人的底层能力
大家好,我是老原。 我们经常会说「高效能」,那怎么成为高效能人士?其实除了拼体力和心力以外,高效能更重要的是脑力,这里的脑力不是指智力,而是结构化思维。 随着你在职场中不断成长和进阶,级…...
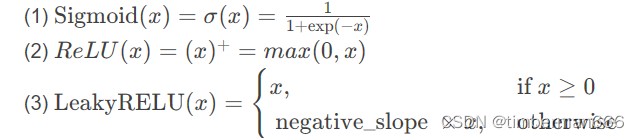
Pytorch个人学习记录总结 07
目录 神经网络-非线性激活 神经网络-线形层及其他层介绍 神经网络-非线性激活 官方文档地址:torch.nn — PyTorch 2.0 documentation 常用的:Sigmoid、ReLU、LeakyReLU等。 作用:为模型引入非线性特征,这样才能在训练过程中…...

Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能
Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能 1. 引言:为什么你需要关注这个0.6B的小模型? 如果你用过搜索引擎,肯定有过这样的体验:输入一个问题,搜出来一堆结果,但真…...

PasteMD模板功能详解:创建个性化转换规则
PasteMD模板功能详解:创建个性化转换规则 你是不是经常从AI对话或者网页上复制内容到Word时,格式总是乱七八糟?公式变成乱码,表格错位,代码块失去高亮?PasteMD就是专门解决这个问题的神器,而它…...

Z-Image-GGUF中文支持实测:古风建筑、水墨山水、国潮设计等本土化效果展示
Z-Image-GGUF中文支持实测:古风建筑、水墨山水、国潮设计等本土化效果展示 1. 引言:当AI绘画遇上东方美学 最近在测试各种文生图模型时,我发现了一个挺有意思的现象:很多国外开发的AI绘画工具,在处理中国传统文化元素…...

Qwen2-VL-2B-Instruct一键部署教程:基于Ubuntu 20.04的GPU环境快速搭建
Qwen2-VL-2B-Instruct一键部署教程:基于Ubuntu 20.04的GPU环境快速搭建 你是不是也遇到过这种情况?看到一个很酷的多模态大模型,想立刻上手试试,结果被复杂的依赖安装、环境配置、驱动适配搞得头大,折腾半天还没跑起来…...

STM32F767串口接收不定长数据实战:超时中断与空闲中断的配置与性能对比
1. STM32F767串口接收不定长数据的痛点与解决方案 在嵌入式开发中,处理串口不定长数据就像在餐厅等一份不知道有多少道菜的套餐——你永远不知道下一口是什么,也不知道什么时候结束。STM32F767作为高性能MCU,面对RS485、Modbus等协议时&#…...
)
Mojo嵌入Python项目的4种架构模式(含GIL绕过实测数据+内存安全验证报告)
第一章:Mojo嵌入Python项目的4种架构模式(含GIL绕过实测数据内存安全验证报告)Mojo 作为兼具 Python 兼容性与系统级性能的新兴语言,其嵌入 Python 项目的能力已通过多种生产就绪架构得到验证。以下四种主流集成模式均在 macOS Ve…...

图图的嗨丝造相-Z-Image-Turbo保姆级教学:提示词中‘蓝色校服’‘黑色低帮鞋’等实体关联
图图的嗨丝造相-Z-Image-Turbo保姆级教学:提示词中‘蓝色校服’‘黑色低帮鞋’等实体关联 你是不是也遇到过这种情况:想用AI生成一张特定风格的图片,比如一个穿着蓝色校服、黑色低帮鞋,搭配渔网袜的校园少女,但写出来…...

汽车智能制造如何落地?从“黑灯工厂”看AI赋能的关键路径
一、当工厂学会在黑暗中自行运转偌大的汽车生产车间里,灯光熄灭,只有AGV小车穿梭的微光和机械臂有节奏的运作声。没有工人的手电筒,也没有巡检的脚步,一切生产、检测、调度都在黑灯状态下有条不紊地进行。这并非科幻电影ÿ…...

Windows 11 离线部署 WSL2 与 Ubuntu:绕过商店限制的完整实战
1. 为什么需要离线部署 WSL2 与 Ubuntu 很多开发者在 Windows 11 上使用 WSL2 时都会遇到一个头疼的问题:微软商店经常无法正常访问或下载速度极慢。我自己就遇到过好几次,明明网络连接正常,但就是卡在下载环节,进度条一动不动。这…...

5分钟搞定!Clipy剪贴板管理神器让Mac效率翻倍
5分钟搞定!Clipy剪贴板管理神器让Mac效率翻倍 【免费下载链接】Clipy Clipboard extension app for macOS. 项目地址: https://gitcode.com/gh_mirrors/cl/Clipy 还在为macOS只能记住最后一次复制内容而烦恼吗?Clipy是一款专为Mac用户设计的剪贴板…...