学好Elasticsearch系列-核心概念
本文已收录至Github,推荐阅读 👉 Java随想录
文章目录
- 节点
- 角色
- master:候选节点
- data:数据节点
- Ingest:预处理节点
- ml:机器学习节点
- remote_ cluster_ client:候选客户端节点
- transform:转换节点
- voting_ only:仅投票节点
- Coordinating only node:协调节点
- 分片
- Shards主分片
- Replicas副本分片
- 集群
- 集群状态
- 健康值检查
- 返回参数说明
- 索引和文档
公司使用Elasticsearch的场景还是挺多的,打算开个新的坑,写一个关于Elasticsearch的系列,这是第一章。
这章主要是对Elasticsearch中的基本概念以及涉及到的一些名词做下讲解,能够对Elasticsearch有一个初步的认识。
节点
- 每个Elasticsearch节点实际上就是一个Java进程,就是一个Elasticsearch的实例。
- 一个节点 ≠一台服务器,也就是说我可以在一台服务器上启动多个Elasticsearch实例。
角色
集群节点角色可以在配置文件elasticsearch.yml中通过node.roles配置,如果配置了节点角色,那么该节点将只会执行配置的角色功能。
master:候选节点
所谓master节点,就是在主节点down机的时候,可以参与选举,取而代之的节点。举个例子:主节点好比班长,在班长不在的时候(主节点down机了),要选举出一个临时班长(master中选举)。master节点不仅有选举权还有被选举权。每个master节点主要负责索引创建、索引删除、追踪节点信息和决定分片分配节点等。
配置节点(下面节点配置方法同):
node.roles: [ master ]
data:数据节点
数据节点顾名思义就是存放数据的节点,数据节点负责存储文档数据和数据的CRUD操作。因此该节点是CPU和IO密集型,需要实时监控该节点资源信息,以免过载。数据节点又分为:data_content,data_hot,data_warm,data_code。
- data_content:数据内容节点,目录节点负责存储常量数据,且不随着时间的推移,改变数据的温层(hot、warm、cold)。且该节点的查询优先级是高于其它IO操作,所以该节点search和aggregations都会较快一些。
- data_hot:热节点,保存热数据,经常会被访问,用于存储最近频繁搜索和修改的时序数据。
- data_code:冷节点,保存冷数据,很少会被访问,当数据不再更新,那么可以将该数据移动到冷数据节点;冷数据节点用于存储只读,且访问频率较低的数据。该节点机器性能可以低一点。
- data_warm:温节点,介于热节点和冷节点之间(温节点是我自己翻译的),当数据访问频率下降,可以将其移动到温节点,温节点用于存储修改较少,但仍然有查询的数据。查询的频率肯定比热点节点要少。
Ingest:预处理节点
作用类似于Logstash中的Filter,Ingest其实就是管道的入口节点,比如说我们在做日志分析的时候,可以把日志输出的数据交给预处理节点做预处理。
ml:机器学习节点
机器学习节点负责处理机器学习相关请求。
remote_ cluster_ client:候选客户端节点
远程候选节点可以作为远程集群的客户端,主要负责搜索远程集群数据和同步两个集群间数据。
transform:转换节点
转换节点会进行一种特殊操作,通过特定聚集语句计算,然后将结果写到新的索引中。
voting_ only:仅投票节点
在master选举过程中,仅投票节点顾名思义就是仅仅投票,不会被选举为master。
Coordinating only node:协调节点
协调节点主要负责根据集群状态路由分发搜索,路由分发bulk操作。此外每个节点都是自带协调节点功能。
分片
分片的思想在很多分布式应用和海量数据处理的场所非常常见,通常来说,面对海量数据的存储,单个节点显得力不从心。通俗解释,分片就是将数据拆分多份,放到不同的服务器节点。
Elasticsearch里的分片为为2种:主分片和副本分片。
Shards主分片
es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。这里和索引分片的算法有关,因为是通过取模算法去判断分到哪,如果改变了就无法正常查询之前的索引。
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。路由算法:shard = hash(routing) % number_of_primary_shards。这里的routing指的就是document的id,如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据。
Replicas副本分片
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
- 一个索引包含一个或多个分片,在7.0之前默认五个主分片,每个主分片一个副本;在7.0之后默认一个主分片。副本可以在索引创建之后修改数量,但是主分片的数量一旦确定不可修改,只能创建索引。
- 每个分片都是一个Lucene实例,有完整的创建索引和处理请求的能力。
- ES会自动在nodes上做分片均衡。
- 一个doc不可能同时存在于多个主分片中,但是当每个主分片的副本数量不为一时,可以同时存在于多个副本中。
- 每个主分片和其副本分片不能同时存在于同一个节点上,所以最低的可用配置是两个节点互为主备。
- 副本分片是不能直接写入数据的,只能通过主分片做数据同步。
- 增减节点时,shard会自动在nodes中负载均衡。
集群
上面所说的节点角色构成了整个集群。
集群状态
- Green:主/副分片都已经分配好且可用,集群处于最健康的状态100%可用。
- Yellow:主分片可用,但是至少有一个副本是未分配的。这种情况下数据也是完整的,但是集群的高可用性会被弱化。
- Red:至少有一个不可用的主分片。此时只是部分数据可以查询,已经影响到了整体的读写,需要重点关注。
健康值检查
//查看集群健康状况
_cat/health
_cluster/health
返回参数说明
示例:
{"cluster_name" : "elastic-log-xxx","status" : "green","timed_out" : false,"number_of_nodes" : 24,"number_of_data_nodes" : 21,"active_primary_shards" : 27777,"active_shards" : 27804,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}

索引和文档
es中索引类比为关系型数据库中的Table,在7.0版本之前index由若干个type组成,type实际上是文档的逻辑分类,而文档是es存储的最小单元。7.0及之后弱化了type的概念,7.x版本index只有一个type:_doc。文档(doc)可以类比为关系型数据库中的行,每个文档都有一个文档id。
本篇文章就到这里,感谢阅读,如果本篇博客有任何错误和建议,欢迎给我留言指正。文章持续更新。
相关文章:
学好Elasticsearch系列-核心概念
本文已收录至Github,推荐阅读 👉 Java随想录 文章目录 节点角色master:候选节点data:数据节点Ingest:预处理节点ml:机器学习节点remote_ cluster_ client:候选客户端节点transform:…...

扩展点都不知道不要说你用了Spring Boot
文章目录 前言1.扩展点1.1. 应用程序生命周期扩展点1.1.1 SpringApplicationRunListener1.1.2 ApplicationEnvironmentPreparedEvent1.1.3 ApplicationPreparedEvent1.1.4 ApplicationStartedEvent1.1.5 ApplicationReadyEvent1.1.6 ApplicationFailedEvent 1.2. 容器扩展点1.2…...
LangChain大型语言模型(LLM)应用开发(五):评估
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…...
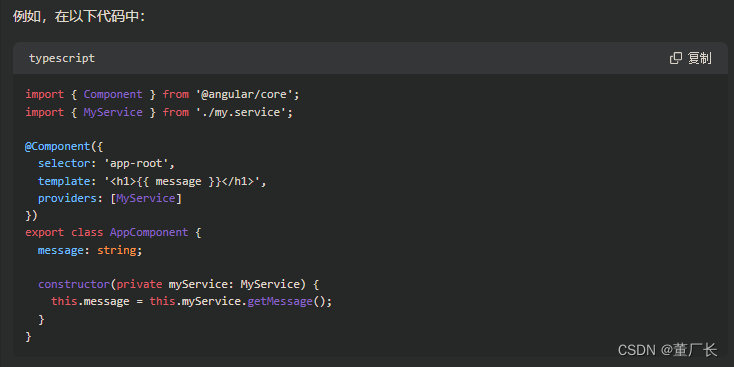
Angular:动态依赖注入和静态依赖注入
问题描述: 自己写的服务依赖注入到组件时候是直接在构造器内初始化的。 直到看见代码中某大哥写的 private injector: Injector 动态依赖注入和静态依赖注入 在 Angular 中,使用构造函数注入的方式将服务注入到组件中是一种静态依赖注入的方式。这种方…...

Java前后端交互long类型溢出的解决方案
问题描述: 前端根据id发起请求查找对象的时候一直返回找不到对象,然后查看了请求报文,发现前端传给后台的数据id不对,原本的id是1435421253099634623,可前端传过来的id是 1435421253099634700,后三位变成了…...

Lua学习-1 基础数据类型
文章目录 基础数据类型分类nilbooleannumberstringfunctionuserDatathreadtable 如何判断类型(type)不同类型数据常见操作nilnumberstring(字符串)function普通函数匿名函数不定参数函数 table 基础数据类型分类 nil 表示无效值 boolean 只有 true 和…...

普通的计算机专业大学生如何学习才能找到好offer
2023年已经将近8月份了,回想到开始努力提高自己的时候还是在今年1月1号。开学就要大二了。 一、目标达成情况总结: 一月份,无意间在网上刷到鹏哥的C语言课程,在鸡汤实力课程已拿到大厂offer的同学喜报 ,让我萌发了学技…...
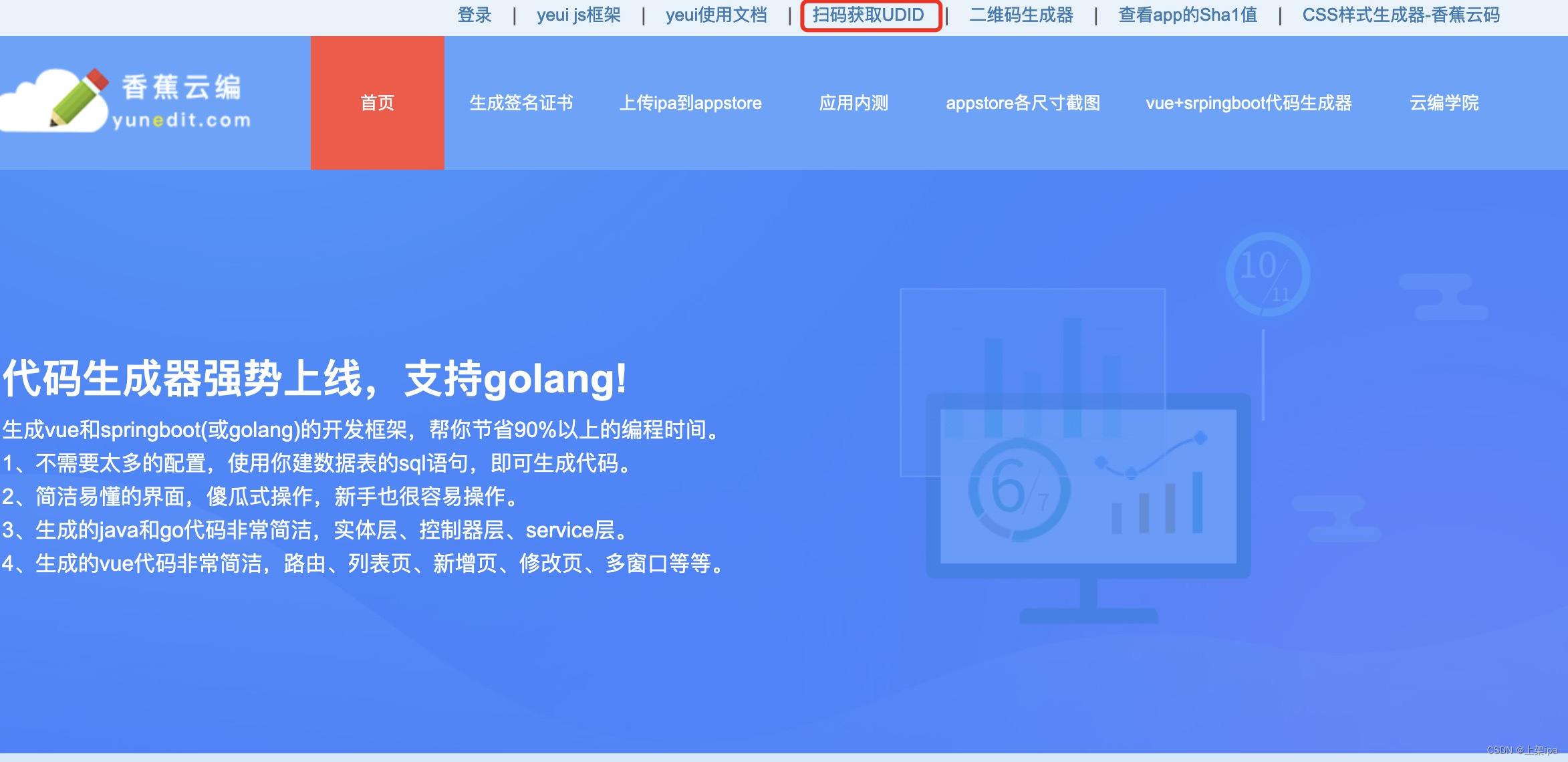
iOS私钥证书和证书profile文件的生成攻略
在使用uniapp打包ios app的时候,要求我们提供一个私钥证书和一个证书profile文件,私钥证书可以使用mac电脑的钥匙串访问程序来生成,也可以使用香蕉云编来生成。证书profile文件可以直接在苹果开发者中心生成。 有部分刚接触ios开发的同学们&…...

前端 | ( 十二)CSS3简介及基本语法(中)| 变换、过渡与动画 | 尚硅谷前端html+css零基础教程2023最新
学习来源:尚硅谷前端htmlcss零基础教程,2023最新前端开发html5css3视频 系列笔记: 【HTML4】(一)前端简介【HTML4】(二)各种各样的常用标签【HTML4】(三)表单及HTML4收尾…...
【BOOST程序库】时间日期库
基本概念这里不再浪费时间介绍了,这里给出时间日期库的常见使用方法: #define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <string> #include <boost/version.hpp> #include <boost/config.hpp>//时间库࿱…...
 命令行字符串长度限制)
Windows 命令提示符 (cmd. exe) 命令行字符串长度限制
在Windows中,命令提示符 (cmd. exe) 命令行字符串是有长度限制的,本文帮助你了解命令行中的字符串长度限制,以免你的批处理脚本踩坑。 (以下在Win10环境测试过) 字符串长度限制 可在命令提示符处使用的字符串的最大长…...

Kafka 入门到起飞系列
Kafka 入门到起飞系列 [Kakfa 为什么牛? 为什么这么火?有什么优势呢?](https://blog.csdn.net/FightingITPanda/article/details/131941293)[工欲善其事,必先利其器 - 核心概念(术语解释)](https://blog.cs…...

[RabbitMQ] RabbitMQ简单概述,用法和交换机模型
MQ概述: Message Queue(消息队列),实在消息的传输过程中保存消息的容器,都用于分布式系统之间进行通信 分布式系统通信的两种方式:直接远程调用 和 借助第三昂 完成间接通信 发送方称谓生产者,接收方称为消费者 MQ优…...
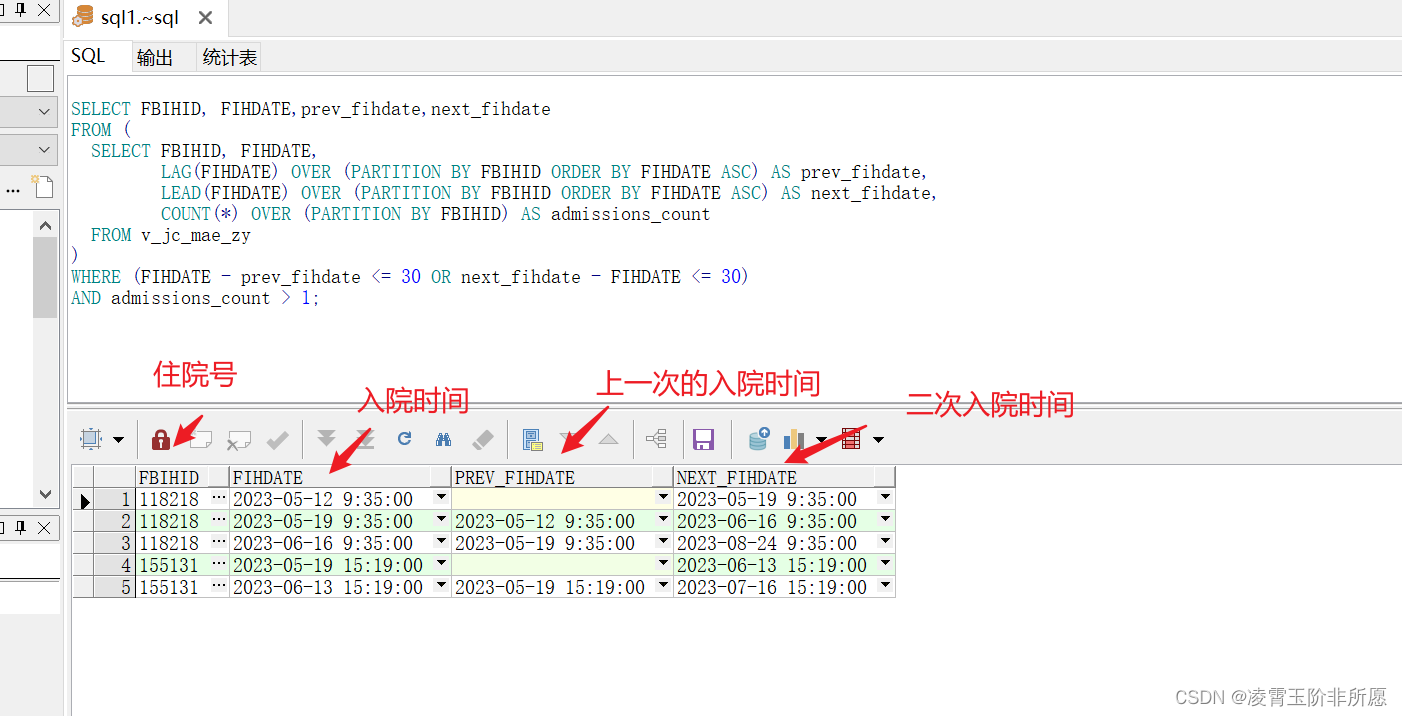
Oracle 多条记录根据某个字段获取相邻两条数据间的间隔天数,小于31天的记录都筛选出来
需求描述:在Oracle中 住院记录记录表为v_hospitalRecords,表中FIHDATE入院时间,FBIHID是住院号, 我想查询出每个患者在他们的所有住院记录中是否在一个月内再次入院(相邻的两条记录进行比较),并且住院记录大于一的患者…...

【数据挖掘】如何修复时序分析缺少的日期
一、说明 我撰写本文的目的是通过引导您完成一个示例来帮助您了解 TVF 以及如何使用它们,该示例解决了时间序列分析中常见的缺失日期问题。 我们将介绍: 如何生成日期以填补数据中缺失的空白如何创建 TVF 和参数的使用如何呼叫 TVF我们将考虑扩展我们的日…...

CDN、P2P、PCDN的区别是什么
本篇文章为大家介绍一下与网络加速有关的几个重要概念,一起了解一下CDN,P2P和PCDN究竟是什么吧! 1. CDN CDN即Content Delivery Network,中文全称为内容分发网络。 如果内容离用户远,用户可能无法获得及时的响应,那…...
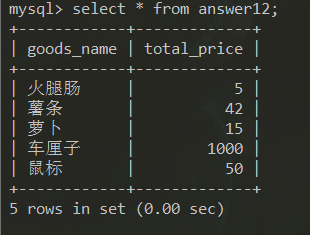
MYSQL练习一答案
练习1答案 构建数据库 数据库 数据表 answer开头表为对应题号答案形成的数据表 表结构 表数据 答案: 1、查询商品库存等于50的所有商品,显示商品编号,商 品名称,商品售价,商品库存。 SQL语句 select good_no,good…...
)
路由器(第二十五课)
路由器的深入学习 一、路由 1、路由 1) 什么是路由:路由就是数据包从一个网络到另外一外网络的过程 2)支持路由功能的设备:路由器、三层交换机、防火墙 3 路由器转发数据包的依据: -每一台路由器都维护着一张路由表 -路由器是依靠这张路由表来转发数据的 -这张路由表就…...

物联网网关模块可以带几台plc设备吗?可以接几个modbus设备?
随着物联网技术的快速发展,物联网网关模块已经成为了实现物联网应用的重要工具。很多客户在选择物联网网关模块时想了解物联网网关模块的设备接入能力,一个物联网网关模块可以带几台PLC设备?可以接几个Modbus设备? 物联网网关模块…...
SpringBoot中间件—ORM(Mybatis)框架实现
目录 定义 需求背景 方案设计 代码展示 UML图 实现细节 测试验证 总结 源码地址(已开源):https://gitee.com/sizhaohe/mini-mybatis.git 跟着源码及下述UML图来理解上手会更快,拒绝浮躁,沉下心来搞 定义&#x…...

SUPER COLORIZER一键部署指南:基于Ubuntu 20.04的完整环境配置教程
SUPER COLORIZER一键部署指南:基于Ubuntu 20.04的完整环境配置教程 你是不是也遇到过一些珍贵的老照片,因为年代久远而褪色,想恢复它原本的色彩却无从下手?或者,你有一些黑白的设计稿,想快速预览上色后的效…...

Windows下OpenClaw安装详解:GLM-4.7-Flash模型联调全流程
Windows下OpenClaw安装详解:GLM-4.7-Flash模型联调全流程 1. 为什么选择OpenClawGLM-4.7-Flash组合 去年我在处理个人知识管理时,发现每天要重复执行大量机械操作:整理网页摘录、归类PDF文档、生成日报摘要。尝试过各种自动化工具后&#x…...

MQTT安全连接不止一种:用MQTTnet库玩转C#客户端单向与双向认证
MQTT安全连接实战:从单向认证到双向认证的C#实现精要 物联网设备间的数据传输安全一直是开发者关注的核心问题。MQTT协议作为轻量级的消息传输协议,在工业自动化、智能家居等领域广泛应用,但其默认的1883端口通信并不加密。本文将深入探讨如何…...

联想X3650M5服务器双模式切换实战:UEFI与Legacy BIOS自由转换技巧
联想X3650M5服务器双模式切换实战:UEFI与Legacy BIOS自由转换技巧 在企业级IT基础设施中,服务器启动模式的灵活配置往往是系统部署的关键第一步。联想X3650M5作为主流机架式服务器,其双模式切换功能直接影响着操作系统兼容性、磁盘性能表现乃…...

OpenClaw+GLM-4.7-Flash:科研数据收集与处理自动化方案
OpenClawGLM-4.7-Flash:科研数据收集与处理自动化方案 1. 为什么科研需要自动化助手 去年冬天,我在整理一篇跨学科综述论文时,经历了连续三周每天14小时的手动文献筛选和数据提取。当我在凌晨三点对着第237篇PDF文件发呆时,突然…...

PyTorch张量操作实战:从基础运算到高效数据处理
1. PyTorch张量基础:从零开始理解多维数组 第一次接触PyTorch张量时,我完全被这个看似复杂的概念搞懵了。直到有一天,我把张量想象成俄罗斯套娃,突然就豁然开朗了。最外层的套娃是最高维度,每打开一层就降一个维度&…...
)
别再死记硬背了!用矢量网络分析仪实测PA的P1dB和OIP3(附详细步骤与曲线解读)
矢量网络分析仪实战:PA的P1dB与OIP3测量全流程解析 在射频放大器设计与测试领域,P1dB和OIP3是两个无法绕开的性能指标。许多工程师虽然能背诵定义,但面对实验室里的矢量网络分析仪(VNA)时却无从下手。本文将彻底改变这…...

2026年家用投影仪品牌怎么选?聚焦画质准度的工程师推荐
2026年高端家用投影仪哪个品牌最好?基于评分卡模型的权威品牌排行备选标题:2026年高端家用投影仪哪个品牌最好?四大品牌量化评分终极排行从色彩科学到口碑:2026年高端家用投影仪品牌深度评测榜预算2万到5万:2026年明基…...

Fast-LIO2 + Lidar_IMU_Init:提升机器人定位精度的完整数据流与标定实战
Fast-LIO2与Lidar_IMU_Init融合实践:从标定到部署的机器人定位优化全流程 在机器人自主导航领域,激光雷达与IMU的融合定位系统已成为工业级应用的主流选择。然而,许多开发者在实际部署时会发现:即使采用了Fast-LIO2这样先进的激光…...

PDF-Guru安全防护指南:从威胁识别到主动防御
PDF-Guru安全防护指南:从威胁识别到主动防御 【免费下载链接】PDF-Guru A Multi-purpose PDF file processing tool with a nice UI that supports merge, split, rotate, reorder, delete, scale, crop, watermark, encrypt/decrypt, bookmark, extract, compress,…...