kafka第三课-可视化工具、生产环境问题总结以及性能优化
一、可视化工具
https://pan.baidu.com/s/1qYifoa4 密码:el4o
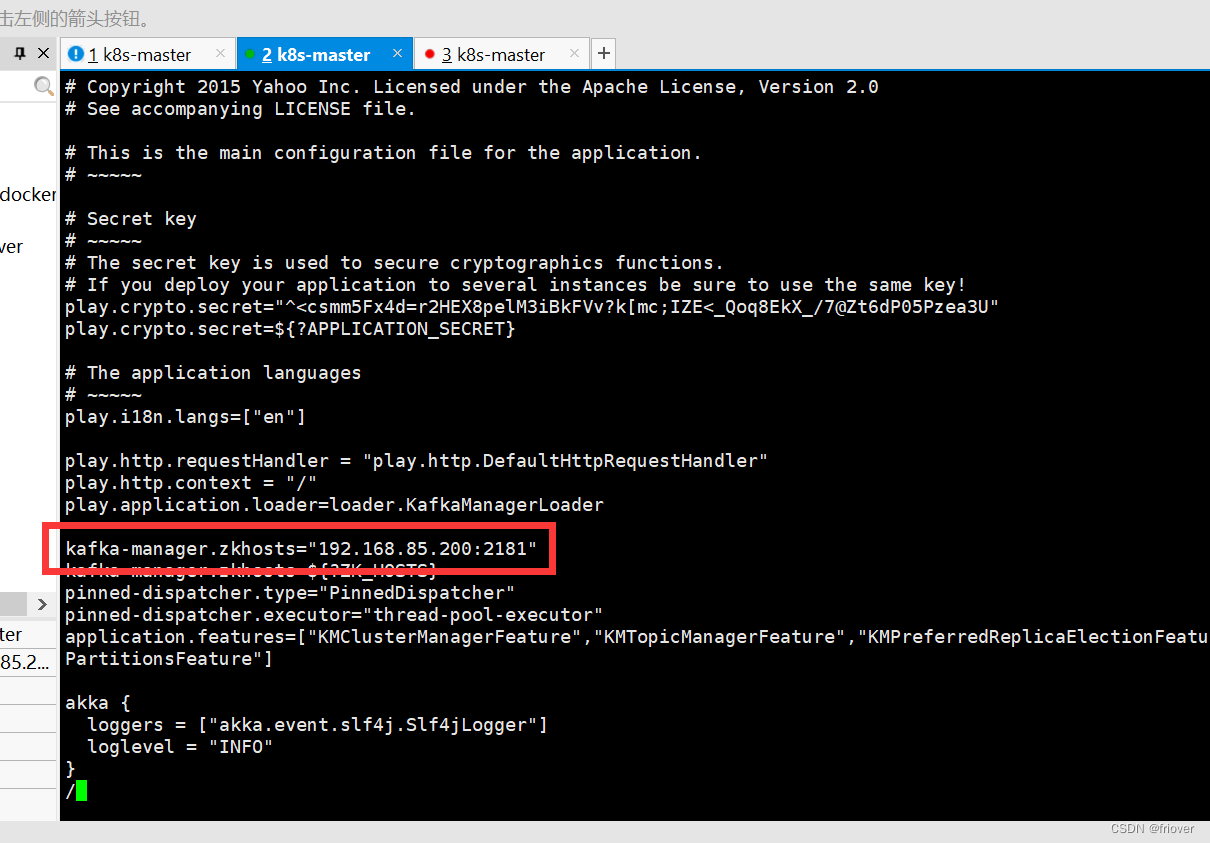
- 下载解压之后,编辑该文件,修改zookeeper地址,也就是kafka注册的zookeeper的地址,如果是zookeeper集群,以逗号分开
vi conf/application.conf
- 启动命令
bin/kafka-manager
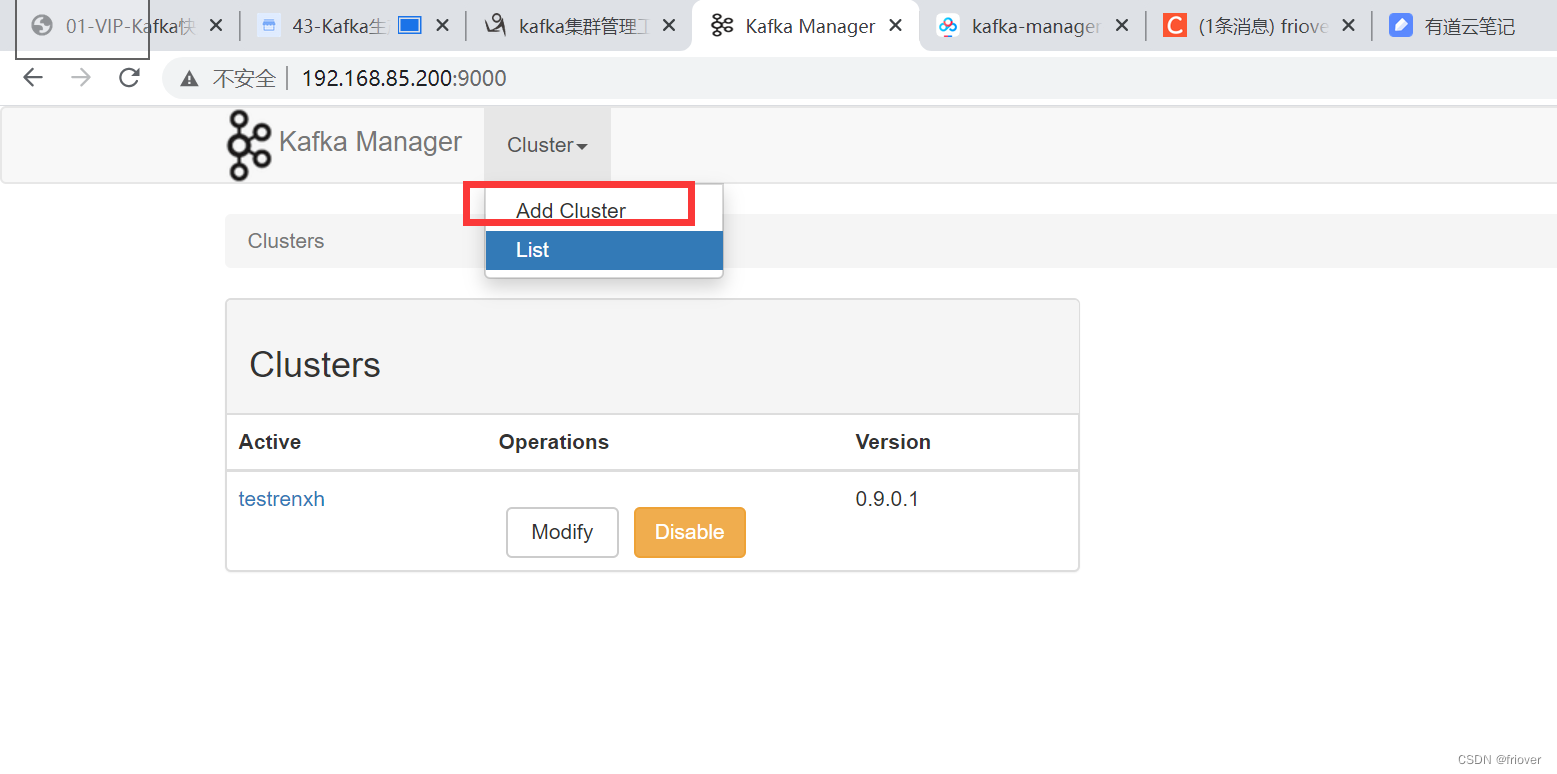
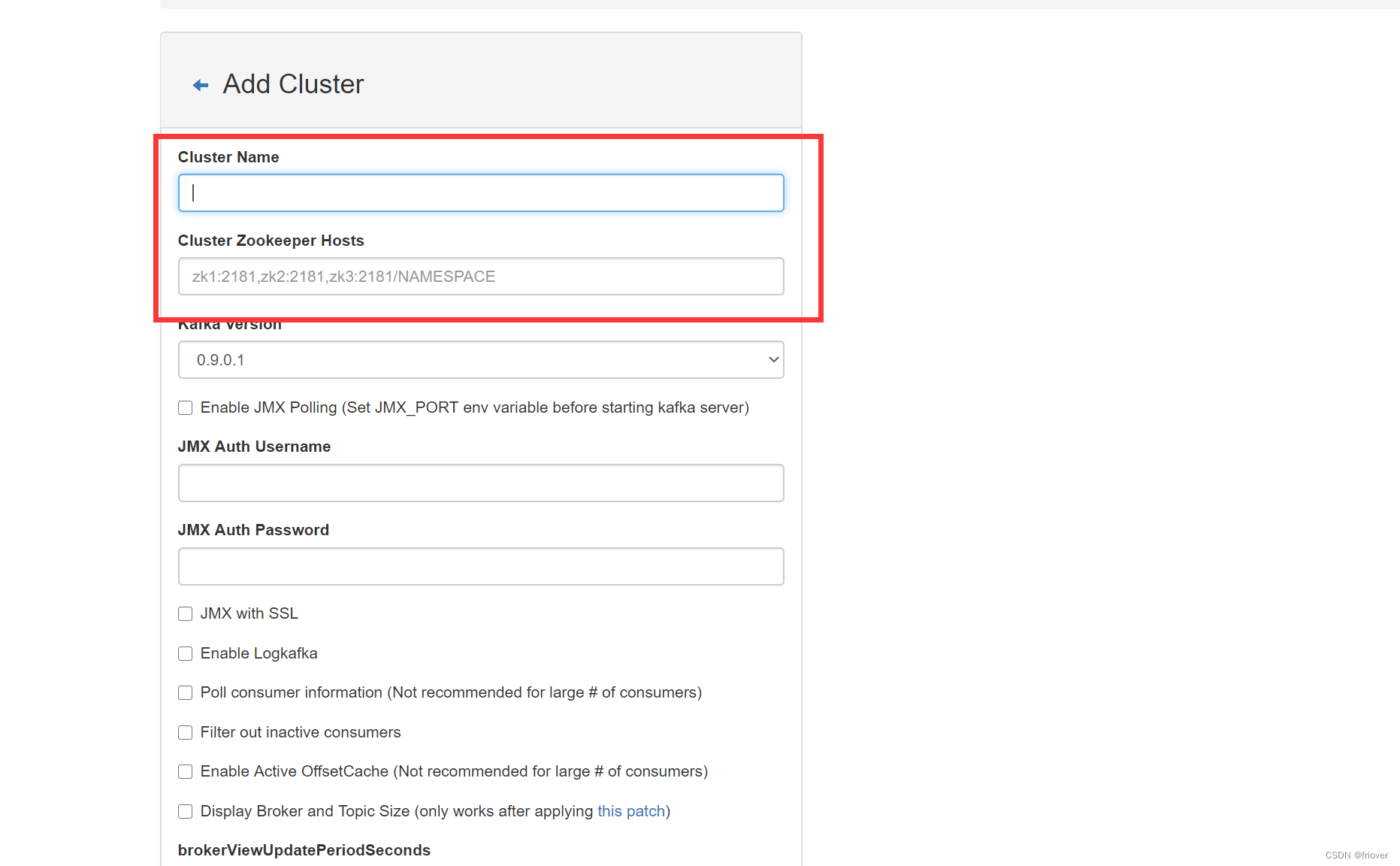
- 默认9000端口,直接访问,添加一个名字,名字只是方便开发者使用,随便起,地址是zookeeper的地址和端口
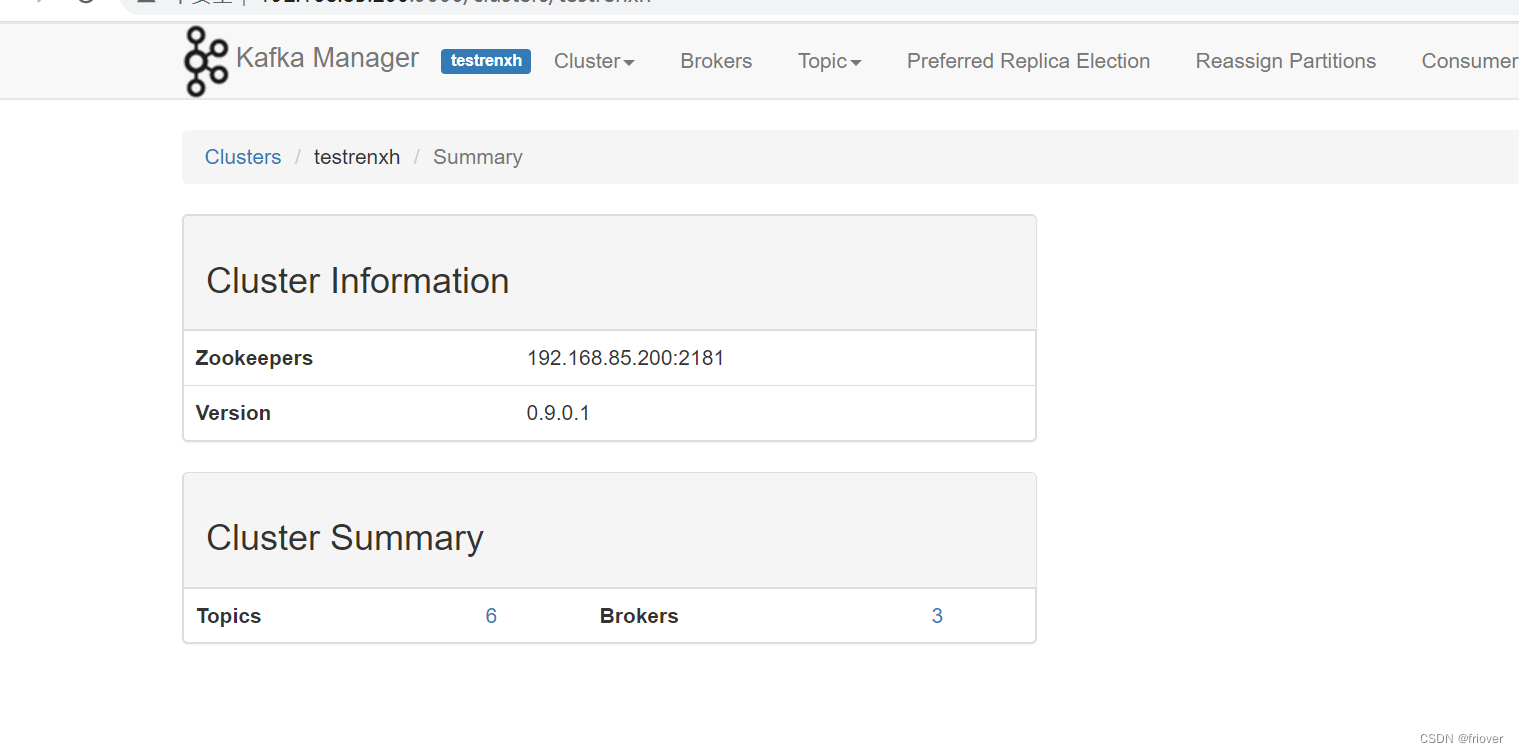
- 点进去可以看到对应的主体以及kafka的集群节点信息
二、线上环境规划
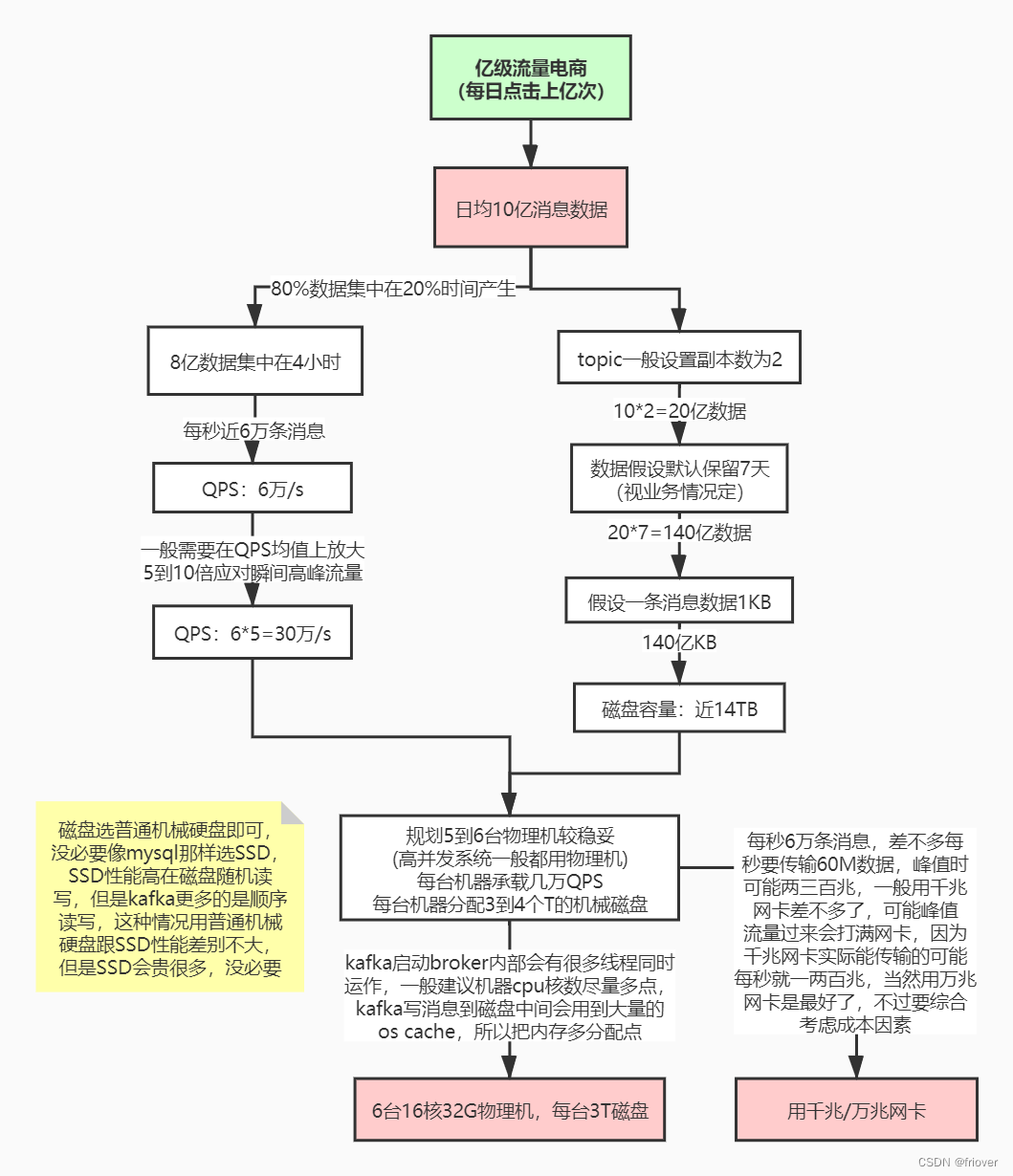
JVM参数设置
kafka是scala语言开发,运行在JVM上,需要对JVM参数合理设置,参看JVM调优专题
修改bin/kafka-start-server.sh中的jvm设置,假设机器是32G内存,可以如下设置:
export KAFKA_HEAP_OPTS="-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M"
这种大内存的情况一般都要用G1垃圾收集器,因为年轻代内存比较大,用G1可以设置GC最大停顿时间,不至于一次minor gc就花费太长时间,当然,因为像kafka,rocketmq,es这些中间件,写数据到磁盘会用到操作系统的page cache,所以JVM内存不宜分配过大,需要给操作系统的缓存留出几个G。
这种大内存的情况一般都要用G1垃圾收集器,因为年轻代内存比较大,用G1可以设置GC最大停顿时间,不至于一次minor gc就花费太长时间,当然,因为像kafka,rocketmq,es这些中间件,写数据到磁盘会用到操作系统的page cache,所以JVM内存不宜分配过大,需要给操作系统的缓存留出几个G。
三、线上问题及优化
1、消息丢失情况:
消息发送端:
(1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
(2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
(3)acks=-1或all: 这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果min.insync.replicas配置的是1则也可能丢消息,跟acks=1情况类似。
消息消费端:
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据丢失了,下次也消费不到了。
2、消息重复消费
消息发送端:
发送消息如果配置了重试机制,比如网络抖动时间过长导致发送端发送超时,实际broker可能已经接收到消息,但发送方会重新发送消息
消息消费端:
如果消费这边配置的是自动提交,刚拉取了一批数据处理了一部分,但还没来得及提交,服务挂了,下次重启又会拉取相同的一批数据重复处理
一般消费端都是要做消费幂等处理的。
3、消息乱序
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了
所以,是否一定要配置重试要根据业务情况而定。也可以用同步发送的模式去发消息,当然acks不能设置为0,这样也能保证消息发送的有序。
kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消息。
4、消息积压
1)线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。
此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分区),然后再启动多个消费者同时消费新主题的不同分区。
2)由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。
此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
5、延时队列
延时队列存储的对象是延时消息。所谓的“延时消息”是指消息被发送以后,并不想让消费者立刻获取,而是等待特定的时间后,消费者才能获取这个消息进行消费,延时队列的使用场景有很多, 比如 :
1)在订单系统中, 一个用户下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单将进行异常处理,这时就可以使用延时队列来处理这些订单了。
2)订单完成1小时后通知用户进行评价。
实现思路:发送延时消息时先把消息按照不同的延迟时间段发送到指定的队列中(topic_1s,topic_5s,topic_10s,…topic_2h,这个一般不能支持任意时间段的延时),然后通过定时器进行轮训消费这些topic,查看消息是否到期,如果到期就把这个消息发送到具体业务处理的topic中,队列中消息越靠前的到期时间越早,具体来说就是定时器在一次消费过程中,对消息的发送时间做判断,看下是否延迟到对应时间了,如果到了就转发,如果还没到这一次定时任务就可以提前结束了。
6、消息回溯
如果某段时间对已消费消息计算的结果觉得有问题,可能是由于程序bug导致的计算错误,当程序bug修复后,这时可能需要对之前已消费的消息重新消费,可以指定从多久之前的消息回溯消费,这种可以用consumer的offsetsForTimes、seek等方法指定从某个offset偏移的消息开始消费,参见上节课的内容。
当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费latest(默认) :只消费自己启动之后发送到主题的消息earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费)*///props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
7、分区数越多吞吐量越高吗
可以用kafka压测工具自己测试分区数不同,各种情况下的吞吐量
# 往test里发送一百万消息,每条设置1KB
# throughput 用来进行限流控制,当设定的值小于 0 时不限流,
#当设定的值大于 0 时,当发送的吞吐量大于该值时就会被阻塞一段时间
#一条消息1024个字节,也就是1kb
#acks=1 参考上满
bin/kafka-producer-perf-test.sh --topic test --num-records 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=192.168.85.200:9092 acks=1
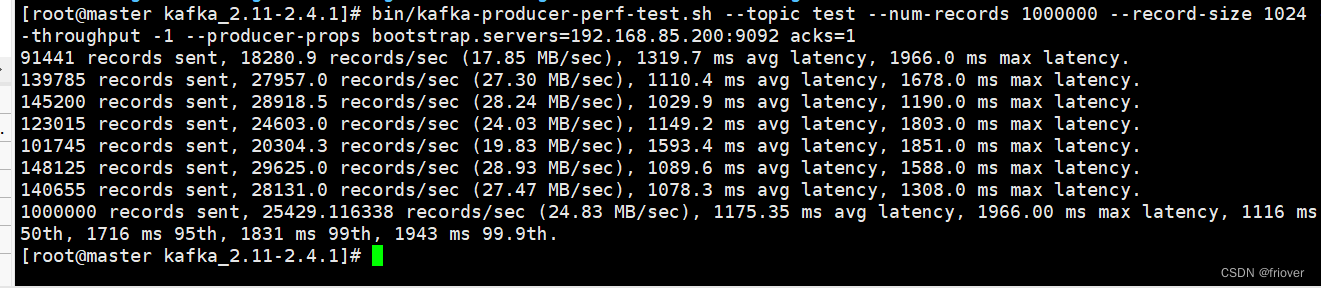
平均值是1秒多,最大发送时间是1.9秒,不过这个时间都是一批消息的时间,百万数据kafka是分批发的,具体参考上一个文档,看他的缓存区和bash区
网络上很多资料都说分区数越多吞吐量越高 , 但从压测结果来看,分区数到达某个值吞吐量反而开始下降,实际上很多事情都会有一个临界值,当超过这个临界值之后,很多原本符合既定逻辑的走向又会变得不同。一般情况分区数跟集群机器数量相当就差不多了。
当然吞吐量的数值和走势还会和磁盘、文件系统、 I/O调度策略等因素相关。
注意:如果分区数设置过大,比如设置10000,可能会设置不成功,后台会报错"java.io.IOException : Too many open files"。
异常中最关键的信息是“ Too many open flies”,这是一种常见的 Linux 系统错误,通常意味着文件描述符不足,它一般发生在创建线程、创建 Socket、打开文件这些场景下 。 在 Linux系统的默认设置下,这个文件描述符的个数不是很多 ,通过 ulimit -n 命令可以查看:一般默认是1024,可以将该值增大,比如:ulimit -n 65535
8、消息传递保障
- at most once(消费者最多收到一次消息,0–1次):acks = 0 可以实现。
- at least once(消费者至少收到一次消息,1–多次):ack = all 可以实现。
- exactly once(消费者刚好收到一次消息):at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实现。
kafka生产者的幂等性:因为发送端重试导致的消息重复发送问题,kafka的幂等性可以保证重复发送的消息只接收一次,只需在生产者加上参数 props.put(“enable.idempotence”, true) 即可,默认是false不开启。
具体实现原理是,kafka每次发送消息会生成PID和Sequence Number,并将这两个属性一起发送给broker,broker会将PID和Sequence Number跟消息绑定一起存起来,下次如果生产者重发相同消息,broker会检查PID和Sequence Number,如果相同不会再接收。
PID:每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个PID 对用户完全是透明的。生产者如果重启则会生成新的PID。
Sequence Number:对于每个 PID,该 Producer 发送到每个 Partition 的数据都有对应的序列号,这些序列号是从0开始单调递增的。
9、kafka的事务(了解)
Kafka的事务不同于Rocketmq,Rocketmq是保障本地事务(比如数据库)与mq消息发送的事务一致性,Kafka的事务主要是保障一次发送多条消息的事务一致性(要么同时成功要么同时失败),一般在kafka的流式计算场景用得多一点,比如,kafka需要对一个topic里的消息做不同的流式计算处理,处理完分别发到不同的topic里,这些topic分别被不同的下游系统消费(比如hbase,redis,es等),这种我们肯定希望系统发送到多个topic的数据保持事务一致性。Kafka要实现类似Rocketmq的分布式事务需要额外开发功能。
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("transactional.id", "my-transactional-id");Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());//初始化事务producer.initTransactions();try {//开启事务producer.beginTransaction();for (int i = 0; i < 100; i++){//发到不同的主题的不同分区producer.send(new ProducerRecord<>("hdfs-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("es-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("redis-topic", Integer.toString(i), Integer.toString(i)));}//提交事务producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// We can't recover from these exceptions, so our only option is to close the producer and exit.producer.close();} catch (KafkaException e) {// For all other exceptions, just abort the transaction and try again.//回滚事务producer.abortTransaction();}producer.close();
10、kafka高性能的原因
- 磁盘顺序读写:kafka消息不能修改以及不会从文件中间删除保证了磁盘顺序读,kafka的消息写入文件都是追加在文件末尾,不会写入文件中的某个位置(随机写)保证了磁盘顺序写。
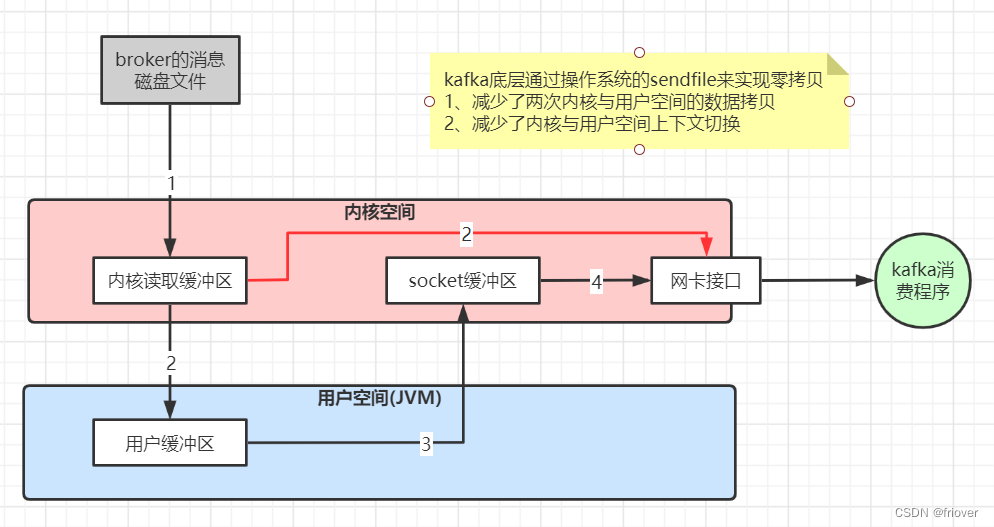
- 数据传输的零拷贝
- 读写数据的批量batch处理以及压缩传输
数据传输零拷贝原理:
相关文章:
kafka第三课-可视化工具、生产环境问题总结以及性能优化
一、可视化工具 https://pan.baidu.com/s/1qYifoa4 密码:el4o 下载解压之后,编辑该文件,修改zookeeper地址,也就是kafka注册的zookeeper的地址,如果是zookeeper集群,以逗号分开 vi conf/application.conf 启…...

2_Apollo4BlueLite中断控制器NVIC
1.概述 Apollo4BlueLite 的中断控制器是采用 ARM Cortex-M4 内核,并集成了 NVIC(Nested Vectored Interrupt Controller,嵌套向量中断控制器)作为其中断控制器。 NVIC 是 ARM Cortex-M 系列处理器中常用的中断控制器,…...

WAIC2023:图像内容安全黑科技助力可信AI发展
目录 0 写在前面1 AI图像篡改检测2 生成式图像鉴别2.1 主干特征提取通道2.2 注意力模块2.3 纹理增强模块 3 OCR对抗攻击4 助力可信AI向善发展总结 0 写在前面 2023世界人工智能大会(WAIC)已圆满结束,恰逢全球大模型和生成式人工智能蓬勃兴起之时,今年参…...
微信小程序quickstartFunctions中云函数的应用
1、在quickstartFunctions文件中新建文件夹和文件 2、index.js 文件书写 const cloud require(wx-server-sdk);cloud.init({env: cloud.DYNAMIC_CURRENT_ENV }); const db cloud.database();// 链表查询试卷和对应的题库 exports.main async (event, context) > {retu…...

Go学习 2、程序结构
2、程序结构 2.1 命名 一个名字必须以一个字母或下划线开头,后面可以跟任意数量的字母、数字或下划线。 大写字母和小写字母是不同的。 GO语言有25个关键字,关键字不能用于自定义名字。 还有大约30多个预定义名字,对应内建的常量、类型和函…...

SpringBoot整合JavaMail
SpringBoot整合JavaMail 简单使用-发送简单邮件 介绍协议 导入坐标 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-mail</artifactId></dependency>添加配置 spring:mail:host: smtp.qq.co…...
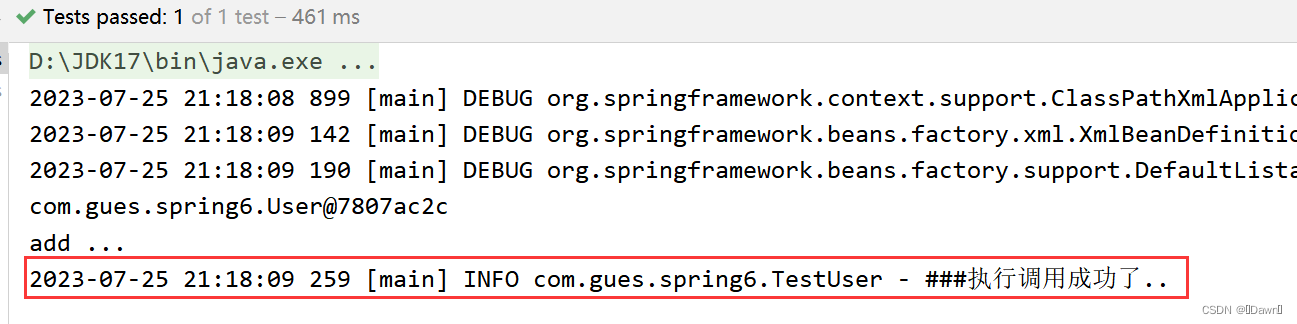
Spring6——入门
文章目录 入门环境要求构建模块程序开发引入依赖创建java类创建配置文件创建测试类运行测试程序 程序分析启用Log4j2日志框架Log4j2日志概述引入Log4j2依赖加入日志配置文件测试使用日志 入门 环境要求 JDK:Java17(Spring6要求JDK最低版本是Java17&…...

【计算机视觉 | 目标检测 | 图像分割】arxiv 计算机视觉关于目标检测和图像分割的学术速递(7 月 17 日论文合集)
文章目录 一、检测相关(5篇)1.1 TALL: Thumbnail Layout for Deepfake Video Detection1.2 Cloud Detection in Multispectral Satellite Images Using Support Vector Machines With Quantum Kernels1.3 Multimodal Motion Conditioned Diffusion Model for Skeleton-based Vi…...

为什么需要GP(Global Platform)认证?
TEE之GP(Global Platform)认证汇总 一、为什么需要认证? 二、为什么是GP? 参考: GlobalPlatform Certification - GlobalPlatform...

eclipse 格式化代码 快捷键
在Eclipse中,可以使用以下快捷键来格式化代码: Windows/Linux快捷键:Ctrl Shift FMac快捷键:Command Shift F 按下相应的快捷键后,Eclipse将自动根据您的代码格式化偏好设置对代码进行格式化。请确保已经选择和配…...

深入探索Socks5代理与网络安全
简介 Socks5代理是一种网络协议,用于在客户端和服务器之间进行数据传输,它可以在网络层和传输层实现代理功能。与其他代理协议相比,Socks5代理更加灵活和安全,为爬虫任务和网络安全提供了重要支持。 Socks5代理的工作原理 Socks5…...
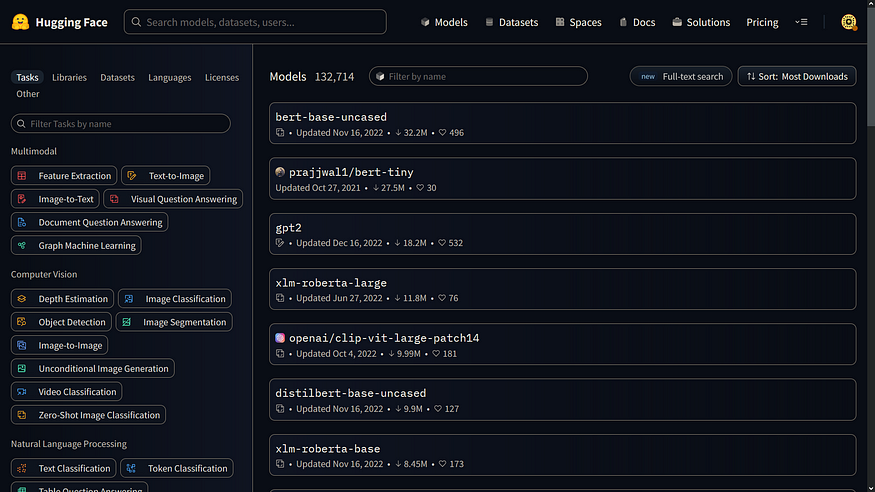
【NLP】如何使用Hugging-Face-Pipelines?
一、说明 随着最近开发的库,执行深度学习分析变得更加容易。其中一个库是拥抱脸。Hugging Face 是一个平台,可为 NLP 任务(如文本分类、情感分析等)提供预先训练的语言模型。 本博客将引导您了解如何使用拥抱面部管道执行 NLP 任务…...

网络安全(黑客)自学笔记
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一是市场需求量高; 二则是发展相对成熟入门…...

spring数据校验
数据校验 概述 在开发中,会存在参数校验的情况,如:注册时,校验用户名不能为空、用户名长度不超过20个字符,手机号格式合法等。如果使用普通方式,会将校验代码和处理逻辑耦合在一起,在需要新增一…...

因材施教,有道发布“子曰”教育大模型,落地虚拟人口语教练等六大应用
因材施教的教育宗旨下,大模型浪潮中,网易有道凭借其对教育场景的深入理解和对商业化的理性思考,为行业树立了垂直大模型的典范。 7月26日,教育科技公司网易有道举办了“powered by 子曰”教育大模型应用成果发布会。会上重磅推出了…...
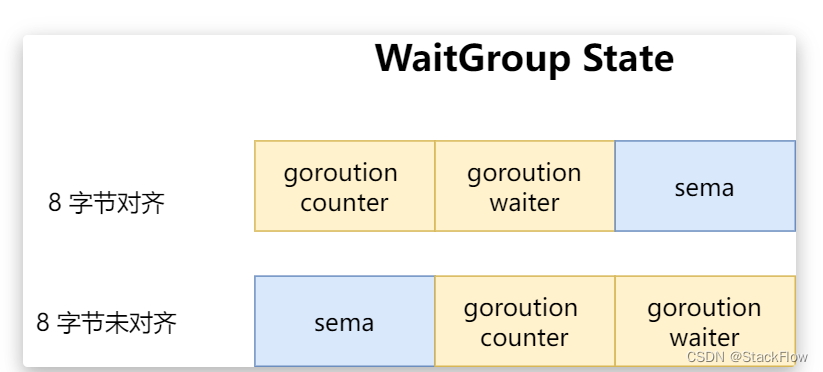
golang waitgroup
案例 WaitGroup 可以解决一个 goroutine 等待多个 goroutine 同时结束的场景,这个比较常见的场景就是例如 后端 worker 启动了多个消费者干活,还有爬虫并发爬取数据,多线程下载等等。 我们这里模拟一个 worker 的例子 package mainimport (…...

单列模式多学两遍
单例模式 单例模式(Singleton Pattern,也称为单件模式),使用最广泛的设计模式之一。其意图是保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。 定义单例类 ● 私有化它的构造函数,…...
Spring Cloud【SkyWalking网络钩子Webhooks、SkyWalking钉钉告警、SkyWalking邮件告警】(十六)
目录 分布式请求链路追踪_SkyWalking网络钩子Webhooks 分布式请求链路追踪_SkyWalking钉钉告警 分布式请求链路追踪_SkyWalking邮件告警 分布式请求链路追踪_SkyWalking网络钩子Webhooks Wbhooks网络钩子 Webhok可以简单理解为是一种Web层面的回调机制。告警就是一个事件&a…...
【力扣每日一题】2023.7.25 将数组和减半的最少操作次数
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 题目给我们一个数组,我们每次可以将任意一个元素减半,问我们操作几次之后才可以将整个数组的和减半&…...

Docker-Compose 轻松搭建 Grafana+InfluxDb 实用 Jmeter 监控面板
目录 前言: 1、背景 2、GranfanaInfluxDB 配置 2.1 服务搭建 2.2 配置 Grafana 数据源 2.3 配置 Grafana 面板 3、Jmeter 配置 3.1 配置 InfluxDB 监听器 3.2 实际效果 前言: Grafana 和 InfluxDB 是两个非常流行的监控工具,它们可…...

Akagi:麻将智能决策的创新辅助方法——从牌局困境到战术精通的实践指南
Akagi:麻将智能决策的创新辅助方法——从牌局困境到战术精通的实践指南 【免费下载链接】Akagi A helper client for Majsoul 项目地址: https://gitcode.com/gh_mirrors/ak/Akagi Akagi作为一款专为雀魂玩家设计的AI辅助工具,通过实时牌局分析与…...

统信UOS安装踩坑实录:Win7老用户用balenaEtcher制作启动盘的那些事儿
统信UOS安装实战:Win7环境下避坑指南与工具选择 作为一个长期使用Windows 7的老用户,最近尝试安装统信UOS操作系统时,遇到了不少意料之外的挑战。特别是在制作启动盘这个看似简单的环节,各种问题接踵而至——U盘无法识别、烧录后启…...

钕铁硼磁铁性能参数详解:选型、使用与注意事项
在实际选型过程中,钕铁硼磁铁的参数表常常让人困惑:N35和N42有什么区别?SH、UH、EH后缀代表什么?剩磁、矫顽力这些参数怎么看?本文将系统梳理钕铁硼磁铁的核心性能参数,帮助读者快速掌握选型要点。一、先搞…...

C# 爬虫抓图遇到TLS 1.3报错?.NET Framework 4.7 的终极自救指南
C# 爬虫抓图遇到TLS 1.3报错?.NET Framework 4.7 的终极自救指南 当你的C#爬虫在.NET Framework 4.7环境下突然开始报错"未能创建 SSL/TLS 安全通道",而昨天还能正常运行——这很可能是因为目标服务器升级到了TLS 1.3协议。作为一个长期维护企…...
)
嵌入式开发必知:如何通过.text、.data和.bss段优化内存使用(附实例分析)
嵌入式开发实战:从.text到.bss的内存优化策略与案例分析 在资源受限的嵌入式系统中,内存优化从来不是可选项,而是生存法则。当你的MCU只有几十KB RAM,而产品功能需求却在不断膨胀时,对内存分区的深入理解就成为了区分普…...

OpCore-Simplify:黑苹果EFI配置的认知负荷解决方案
OpCore-Simplify:黑苹果EFI配置的认知负荷解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 诊断认知负荷:黑苹果配置的…...

从海报生成实战出发:深度解析Canvas文本绘制的那些“坑”与高效解决方案
从海报生成实战出发:深度解析Canvas文本绘制的那些“坑”与高效解决方案 在数字化营销盛行的今天,一张精美的海报往往能成为内容传播的"门面担当"。无论是文章分享、活动推广还是品牌展示,视觉化呈现的效果直接影响用户点击意愿。…...

终极CoreUI Bootstrap管理模板:5个导航组件实战技巧提升用户体验
终极CoreUI Bootstrap管理模板:5个导航组件实战技巧提升用户体验 【免费下载链接】coreui-free-bootstrap-admin-template coreui/coreui-free-bootstrap-admin-template: CoreUI-Free-Bootstrap-Admin-Template 是一套免费的Bootstrap 4/5管理模板,包含…...

SillyTavern角色系统全解析:从基础构建到高级定制
SillyTavern角色系统全解析:从基础构建到高级定制 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 引言:当AI角色拥有"灵魂" 想象一下,你正在…...

国内免费AI编程工具推荐
DeepSeek Code 由深度求索公司开发,支持代码生成、补全和错误检测,涵盖Python、Java等多种语言,提供网页版和插件形式。CodeGeeX 清华大学团队推出的多语言代码生成工具,支持VS Code等IDE插件,具备代码翻译和解释功能。…...