在自定义数据集上微调Alpaca和LLaMA
本文将介绍使用LoRa在本地机器上微调Alpaca和LLaMA,我们将介绍在特定数据集上对Alpaca LoRa进行微调的整个过程,本文将涵盖数据处理、模型训练和使用流行的自然语言处理库(如Transformers和hugs Face)进行评估。此外还将介绍如何使用grado应用程序部署和测试模型。

配置
首先,alpaca-lora1 GitHub存储库提供了一个脚本(finetune.py)来训练模型。在本文中,我们将利用这些代码并使其在Google Colab环境中无缝地工作。
首先安装必要的依赖:
!pip install -U pip!pip install accelerate==0.18.0!pip install appdirs==1.4.4!pip install bitsandbytes==0.37.2!pip install datasets==2.10.1!pip install fire==0.5.0!pip install git+https://github.com/huggingface/peft.git!pip install git+https://github.com/huggingface/transformers.git!pip install torch==2.0.0!pip install sentencepiece==0.1.97!pip install tensorboardX==2.6!pip install gradio==3.23.0
安装完依赖项后,继续导入所有必要的库,并为matplotlib绘图配置设置:
import transformersimport textwrapfrom transformers import LlamaTokenizer, LlamaForCausalLMimport osimport sysfrom typing import Listfrom peft import (LoraConfig,get_peft_model,get_peft_model_state_dict,prepare_model_for_int8_training,)import fireimport torchfrom datasets import load_datasetimport pandas as pdimport matplotlib.pyplot as pltimport matplotlib as mplimport seaborn as snsfrom pylab import rcParams%matplotlib inlinesns.set(rc={'figure.figsize':(10, 7)})sns.set(rc={'figure.dpi':100})sns.set(style='white', palette='muted', font_scale=1.2)DEVICE = "cuda" if torch.cuda.is_available() else "cpu"DEVICE
数据
我们这里使用BTC Tweets Sentiment dataset4,该数据可在Kaggle上获得,包含大约50,000条与比特币相关的tweet。为了清理数据,删除了所有以“转发”开头或包含链接的推文。
使用Pandas来加载CSV:
df = pd.read_csv("bitcoin-sentiment-tweets.csv")df.head()
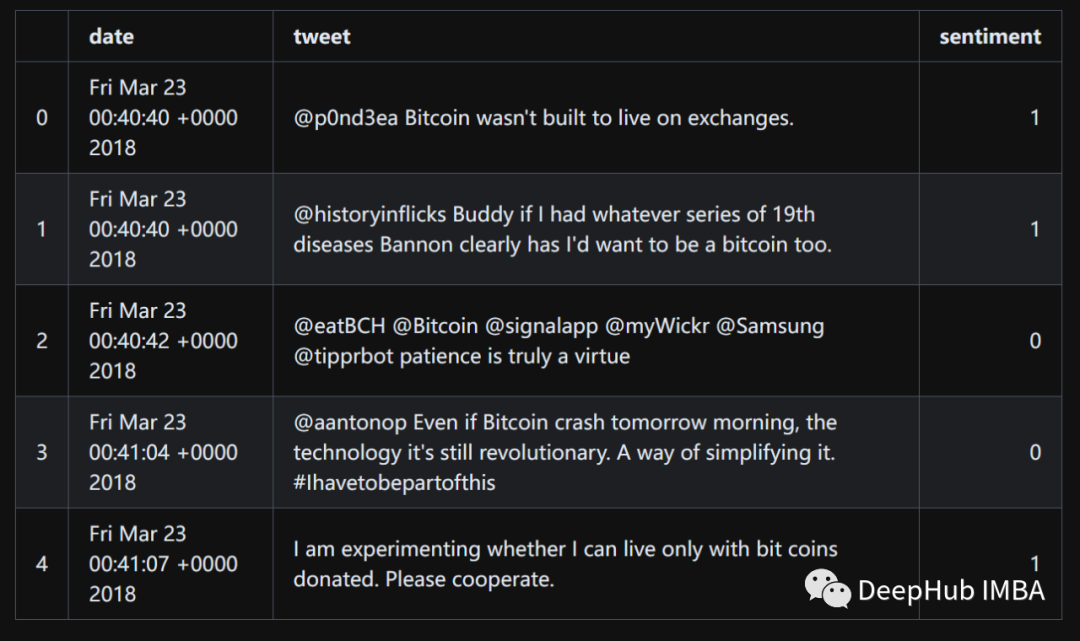
通过清理的数据集有大约1900条推文。
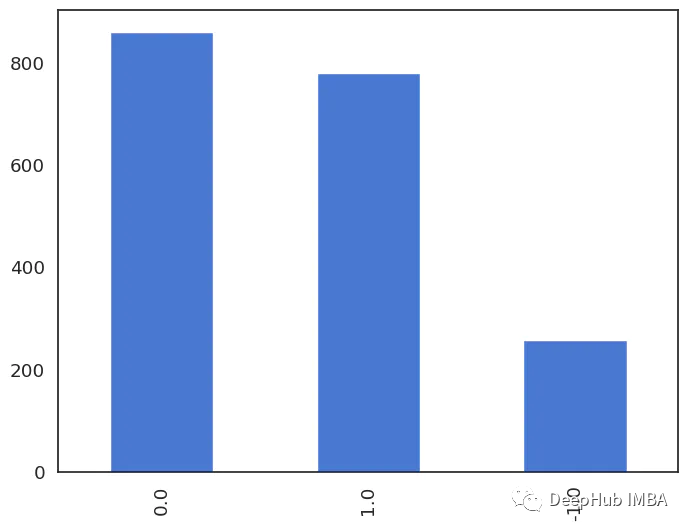
情绪标签用数字表示,其中-1表示消极情绪,0表示中性情绪,1表示积极情绪。让我们看看它们的分布:
df.sentiment.value_counts()# 0.0 860# 1.0 779# -1.0 258# Name: sentiment, dtype: int64
数据量差不多,虽然负面评论较少,但是可以简单的当成平衡数据来对待:
df.sentiment.value_counts().plot(kind='bar');
构建JSON数据集
原始Alpaca存储库中的dataset5格式由一个JSON文件组成,该文件具有具有指令、输入和输出字符串的对象列表。
让我们将Pandas的DF转换为一个JSON文件,该文件遵循原始Alpaca存储库中的格式:
def sentiment_score_to_name(score: float):if score > 0:return "Positive"elif score < 0:return "Negative"return "Neutral"dataset_data = [{"instruction": "Detect the sentiment of the tweet.","input": row_dict["tweet"],"output": sentiment_score_to_name(row_dict["sentiment"])}for row_dict in df.to_dict(orient="records")]dataset_data[0]
结果如下:
{"instruction": "Detect the sentiment of the tweet.","input": "@p0nd3ea Bitcoin wasn't built to live on exchanges.","output": "Positive"}
然后就是保存生成的JSON文件,以便稍后使用它来训练模型:
import jsonwith open("alpaca-bitcoin-sentiment-dataset.json", "w") as f:json.dump(dataset_data, f)
模型权重
虽然原始的Llama模型权重不可用,但它们被泄露并随后被改编用于HuggingFace Transformers库。我们将使用decapoda-research6:
BASE_MODEL = "decapoda-research/llama-7b-hf"model = LlamaForCausalLM.from_pretrained(BASE_MODEL,load_in_8bit=True,torch_dtype=torch.float16,device_map="auto",)tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)tokenizer.pad_token_id = (0 # unk. we want this to be different from the eos token)tokenizer.padding_side = "left"
这段代码使用来自Transformers库的LlamaForCausalLM类加载预训练的Llama 模型。load_in_8bit=True参数使用8位量化加载模型,以减少内存使用并提高推理速度。
代码还使用LlamaTokenizer类为同一个Llama模型加载标记器,并为填充标记设置一些附加属性。具体来说,它将pad_token_id设置为0以表示未知的令牌,并将padding_side设置为“left”以填充左侧的序列。
数据集加载
现在我们已经加载了模型和标记器,下一步就是加载之前保存的JSON文件,使用HuggingFace数据集库中的load_dataset()函数:
data = load_dataset("json", data_files="alpaca-bitcoin-sentiment-dataset.json")data["train"]
结果如下:
Dataset({features: ['instruction', 'input', 'output'],num_rows: 1897})
接下来,我们需要从加载的数据集中创建提示并标记它们:
def generate_prompt(data_point):return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. # noqa: E501### Instruction:{data_point["instruction"]}### Input:{data_point["input"]}### Response:{data_point["output"]}"""def tokenize(prompt, add_eos_token=True):result = tokenizer(prompt,truncation=True,max_length=CUTOFF_LEN,padding=False,return_tensors=None,)if (result["input_ids"][-1] != tokenizer.eos_token_idand len(result["input_ids"]) < CUTOFF_LENand add_eos_token):result["input_ids"].append(tokenizer.eos_token_id)result["attention_mask"].append(1)result["labels"] = result["input_ids"].copy()return resultdef generate_and_tokenize_prompt(data_point):full_prompt = generate_prompt(data_point)tokenized_full_prompt = tokenize(full_prompt)return tokenized_full_prompt
第一个函数generate_prompt从数据集中获取一个数据点,并通过组合指令、输入和输出值来生成提示。第二个函数tokenize接收生成的提示,并使用前面定义的标记器对其进行标记。它还向输入序列添加序列结束标记,并将标签设置为与输入序列相同。第三个函数generate_and_tokenize_prompt结合了前两个函数,生成并标记提示。
数据准备的最后一步是将数据集分成单独的训练集和验证集:
train_val = data["train"].train_test_split(test_size=200, shuffle=True, seed=42)train_data = (train_val["train"].map(generate_and_tokenize_prompt))val_data = (train_val["test"].map(generate_and_tokenize_prompt))
我们还需要数据进行打乱,并且获取200个样本作为验证集。generate_and_tokenize_prompt()函数应用于训练和验证集中的每个示例,生成标记化的提示。
训练
训练过程需要几个参数,这些参数主要来自原始存储库中的微调脚本:
LORA_R = 8LORA_ALPHA = 16LORA_DROPOUT= 0.05LORA_TARGET_MODULES = ["q_proj","v_proj",]BATCH_SIZE = 128MICRO_BATCH_SIZE = 4GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZELEARNING_RATE = 3e-4TRAIN_STEPS = 300OUTPUT_DIR = "experiments"
下面就可以为训练准备模型了:
model = prepare_model_for_int8_training(model)config = LoraConfig(r=LORA_R,lora_alpha=LORA_ALPHA,target_modules=LORA_TARGET_MODULES,lora_dropout=LORA_DROPOUT,bias="none",task_type="CAUSAL_LM",)model = get_peft_model(model, config)model.print_trainable_parameters()#trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
我们使用LORA算法初始化并准备模型进行训练,通过量化可以减少模型大小和内存使用,而不会显着降低准确性。
LoraConfig7是一个为LORA算法指定超参数的类,例如正则化强度(lora_alpha)、dropout概率(lora_dropout)和要压缩的目标模块(target_modules)。
然后就可以直接使用Transformers库进行训练:
training_arguments = transformers.TrainingArguments(per_device_train_batch_size=MICRO_BATCH_SIZE,gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,warmup_steps=100,max_steps=TRAIN_STEPS,learning_rate=LEARNING_RATE,fp16=True,logging_steps=10,optim="adamw_torch",evaluation_strategy="steps",save_strategy="steps",eval_steps=50,save_steps=50,output_dir=OUTPUT_DIR,save_total_limit=3,load_best_model_at_end=True,report_to="tensorboard")
这段代码创建了一个TrainingArguments对象,该对象指定用于训练模型的各种设置和超参数。这些包括:
- gradient_accumulation_steps:在执行向后/更新之前累积梯度的更新步数。
- warmup_steps:优化器的预热步数。
- max_steps:要执行的训练总数。
- learning_rate:学习率。
- fp16:使用16位精度进行训练。
DataCollatorForSeq2Seq是transformer库中的一个类,它为序列到序列(seq2seq)模型创建一批输入/输出序列。在这段代码中,DataCollatorForSeq2Seq对象用以下参数实例化:
data_collator = transformers.DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True)
pad_to_multiple_of:表示最大序列长度的整数,四舍五入到最接近该值的倍数。
padding:一个布尔值,指示是否将序列填充到指定的最大长度。
以上就是训练的所有代码准备,下面就是训练了
trainer = transformers.Trainer(model=model,train_dataset=train_data,eval_dataset=val_data,args=training_arguments,data_collator=data_collator)model.config.use_cache = Falseold_state_dict = model.state_dictmodel.state_dict = (lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())).__get__(model, type(model))model = torch.compile(model)trainer.train()model.save_pretrained(OUTPUT_DIR)
在实例化训练器之后,代码在模型的配置中将use_cache设置为False,并使用get_peft_model_state_dict()函数为模型创建一个state_dict,该函数为使用低精度算法进行训练的模型做准备。
然后在模型上调用torch.compile()函数,该函数编译模型的计算图并准备使用PyTorch 2进行训练。
训练过程在A100上持续了大约2个小时。我们看一下Tensorboard上的结果:
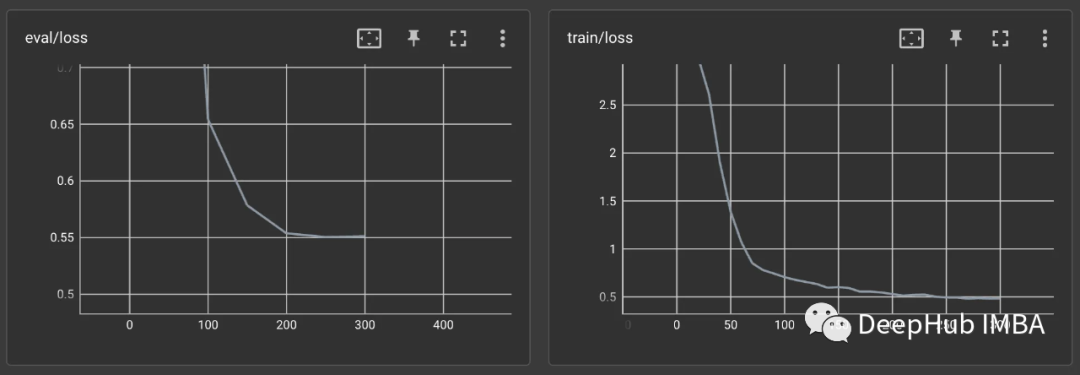
训练损失和评估损失呈稳步下降趋势。看来我们的微调是有效的。
如果你想将模型上传到Hugging Face上,可以使用下面代码,
from huggingface_hub import notebook_loginnotebook_login()model.push_to_hub("curiousily/alpaca-bitcoin-tweets-sentiment", use_auth_token=True)
推理
我们可以使用generate.py脚本来测试模型:
!git clone https://github.com/tloen/alpaca-lora.git%cd alpaca-lora!git checkout a48d947
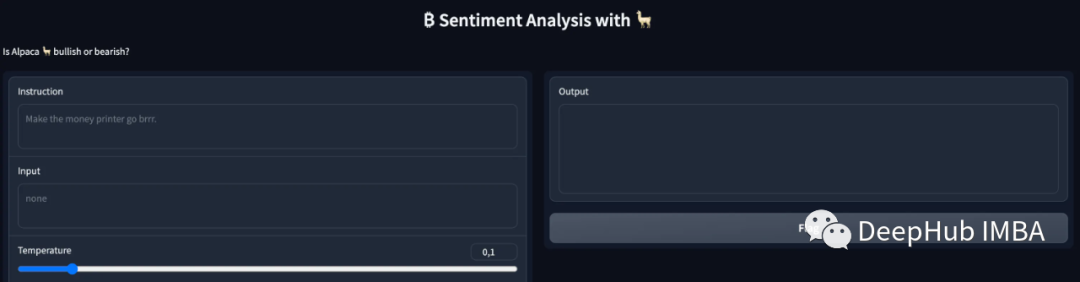
我们的脚本启动的gradio应用程序
!python generate.py \--load_8bit \--base_model 'decapoda-research/llama-7b-hf' \--lora_weights 'curiousily/alpaca-bitcoin-tweets-sentiment' \--share_gradio
简单的界面如下:
总结
我们已经成功地使用LoRa方法对Llama 模型进行了微调,还演示了如何在Gradio应用程序中使用它。
如果你对本文感兴趣,请看原文:
https://avoid.overfit.cn/post/34b6eaf7097a4929b9aab7809f3cfeaa
相关文章:
在自定义数据集上微调Alpaca和LLaMA
本文将介绍使用LoRa在本地机器上微调Alpaca和LLaMA,我们将介绍在特定数据集上对Alpaca LoRa进行微调的整个过程,本文将涵盖数据处理、模型训练和使用流行的自然语言处理库(如Transformers和hugs Face)进行评估。此外还将介绍如何使用grado应用程序部署和…...
)
Python 实现接口类的两种方式+邮件提醒+动态导入模块+反射(参考Django中间件源码)
实现抽象类的两种方式 方式一 from abc import ABCMeta from abc import abstractmethodclass BaseMessage(metaclassABCMeta):abstractmethoddef send(self,subject,body,to,name):pass 方式二 class BaseMessage(object):def send(self, subject, body, to, name):raise …...
Solr原理剖析
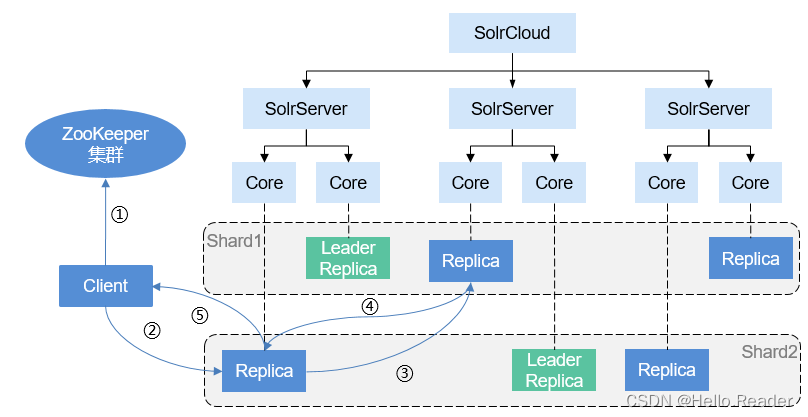
一、简介 Solr是一个高性能、基于Lucene的全文检索服务器。Solr对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,并实现了强大的全文检索功能、高亮显示、动态集群,具有高度的可扩展性。同时从Solr 4.0版本开始,支持SolrCl…...

解决 “无法将 ‘npm‘ 项识别为 cmdlet、函数、脚本文件或可运行程序的名称“ 错误的方法
系列文章目录 文章目录 系列文章目录前言一、错误原因:二、解决方法:三、注意事项:总结 前言 在使用 npm 进行前端项目开发时,有时会遇到错误信息 “无法将 ‘npm’ 项识别为 cmdlet、函数、脚本文件或可运行程序的名称”&#x…...

Python 电商API 开发最佳实践
一、简介 当你打卡了一家北京最具有地中海特色的餐厅,当我们在餐厅点餐时,服务员会给我们一份菜单,菜单上列出了所有可供选择的菜品和饮料。我们可以在菜单上选择我们想要的食物和饮料,然后告诉服务员我们的选择。服务员会根据我…...
JAVA基础-集合(List与Map)
目录 引言 一,Collection集合 1.1,List接口 1.1.1,ArrayList 1.1.1.1,ArrayList的add()添加方法 1.1.1.2,ArrayList的remove()删除方法 1.1.1.3,ArrayList的contai…...
19 QListWidget控件
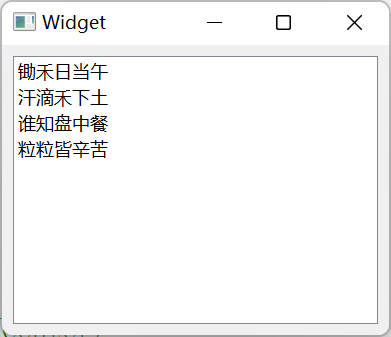
Tips: 对于列表式数据可以使用QStringList进行左移一块输入。 代码: //listWidget使用 // QListWidgetItem * item new QListWidgetItem("锄禾日当午"); // QListWidgetItem * item2 new QListWidgetItem("汗滴禾下土"); // ui->…...

手动安装docsify
安装docsify详见:docsify 1、下载 wget https://codeload.github.com/docsifyjs/docsify/zip/refs/heads/master -o docsify-master.zip 2、解压 unzip docsify-master.zip 3、移动文件到nginx的html所在目录【略】 4、配置nginx,示例如下 locati…...
yaml语法详解
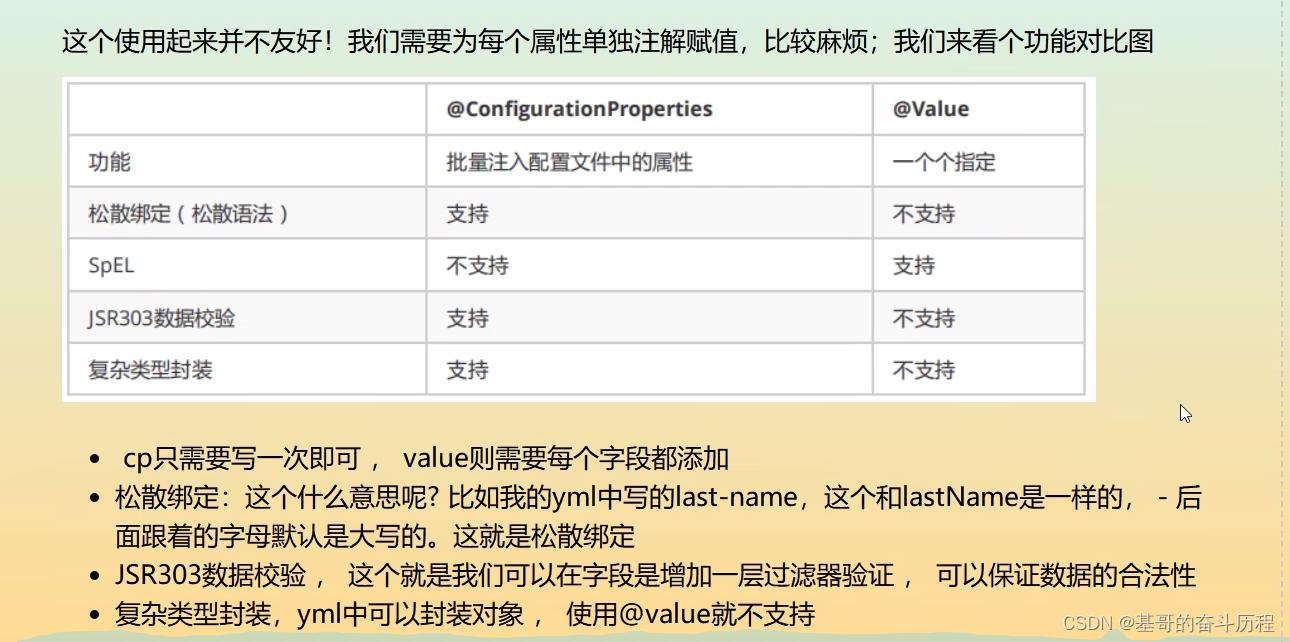
#kv #对空格的严格要求十分高 #注入到我们的配置类中 #普通的keyvalue name: qinjiang#对象 student:name: qingjiangage: 3#行内写法 student1: {name: qinjiang,age: 3}#数组 pets:- cat- dog- pigpet: [cat,dog,pig]yaml可以给实体类赋值 person:name: kuangshenage: 19happ…...

ubuntu下tmux安装
目录 0. 前言1. Tmux介绍2. 安装3. 验证安装 0. 前言 本节安装tmux终端复用工具,在Ubuntu中运行一些服务或脚本的时候往往不能退出终端,需要一直挂着。在有图形界面的linux中你还可以新开一个终端去做别的事,但是在无界面linux中,…...
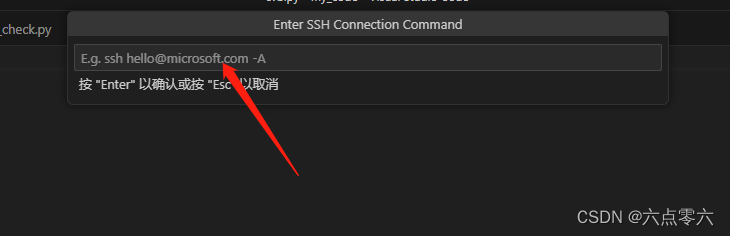
ssh打开远程vscode
如果想要远程打开其他终端的vscode,首先要知道远程终端的ip地址和用户名称以及用户密码 1、打开本地vscode 2、点击左下角蓝色区域 3、页面上部出现如下图,点击ssh,我这里已经连接,所以是connect to host 4、选择Add New SSH Host…...

Socket发送数据---winsock库和boost库
一个是通过winsock库提供的api实现,一个是boost库实现,两个方法都可以,因为项目是vc++6.0实现的,不支持boost库,只能使用winsock库,vc++6.0太老,局限性大。 通过Winsock库提供的API 通过UDP #include<winsock2.h> #include<vector> #include<WS2tcpip.h…...

Qt Core学习日记——第七天QMetaObject(上)
每一个声明Q_OBJECT的类都具有QMetaObject对象 Q_OBJECT宏源代码: #define Q_OBJECT \ public: \ QT_WARNING_PUSH \ Q_OBJECT_NO_OVERRIDE_WARNING \ static const QMetaObject staticMetaObject; \ virtual const QMetaObject *metaObject() const; \ vir…...
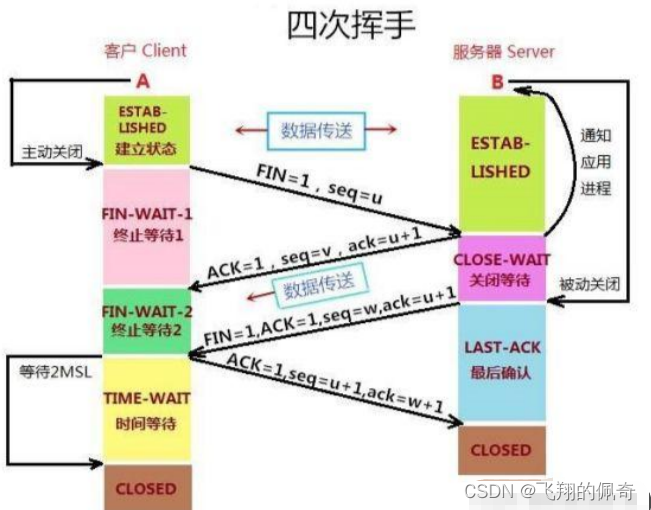
100、用简洁的语言描述一下:TCP的三次握手和四次挥手(不需要长篇大论)
TCP的三次握手和四次挥手 TCP协议是7层网络协议中的传输层协议,负责数据的可靠传输。 1、三次握手 在建立TCP连接时,需要通过三次握手来建立,过程是: 客户端向服务端发送一个SYN服务端接收到SYN后,给客户端发送一个SYN_ACK客户…...

中南大学硕士论文latex版本全指导
要毕业了,闲下点时间写的东西。之前一直收益与师兄师姐流传下来的latex版本,用起来很舒服,希望后面的学弟学妹也能完美用上。latex功能很强大,不需要自己排版,只管内容即可,但是安装流程会多一丢丢。 目录 …...

RFC8470在HTTP中使用早期数据
摘要 使用TLS早期数据会暴露出重放攻击的可能性。本文定义了允许客户端与服务器就早期数据中发送的HTTP请求进行通信的机制。描述了使用这些机制来减轻重放风险的技术。 1. 介绍 TLS 1.3[TLS13]引入了早期数据(也称为零往返时间(0-RTT)数…...
macOS Big Sur 11.7.9 (20G1426) 正式版 ISO、PKG、DMG、IPSW 下载
macOS Big Sur 11.7.9 (20G1426) 正式版 ISO、PKG、DMG、IPSW 下载 本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Window…...
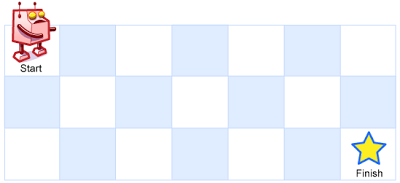
【LeetCode】62.不同路径
题目 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径? …...

使用序列化和反序列化函数archivedDataWithRootObject和unarchivedObjectOfClasses的使用和遇到问题及解决方案
为何archiveRootObject和unarchiveObjectWithFile正常,而archivedDataWithRootObject和unarchivedObjectOfClasses一直报错。 [NSKeyedArchiver archiveRootObject:account toFile:path];和c PPAccountModel *account [NSKeyedUnarchiver unarchiveObjectWithFile:…...

python获取鼠标出颜色
import pyautogui as pg import keyboarddef rgb2hex(r, g, b):return #{:02x}{:02x}{:02x}.format(r, g, b)try:width, height pg.size()print(f"Display resolution: {width} * {height}\n") # 打印屏幕分辨率print(按下shift键打印出鼠标所指位置的颜色......)w…...
)
从医院呼叫器到智能家居:用Multisim 14.2复刻经典八路呼叫器(附完整仿真文件)
从医院呼叫器到智能家居:用Multisim 14.2复刻经典八路呼叫器(附完整仿真文件) 在电子技术发展的历史长河中,经典电路设计往往蕴含着跨越时代的智慧。八路呼叫器作为数字电子技术的经典教学案例,其核心模块——编码、锁…...
)
KV260视觉AI套件到手后,我跳过了图形界面,直接用SSH搞定了网络配置(附详细命令)
KV260视觉AI套件极简配置指南:从串口到SSH的全命令行实战 拿到KV260开发板的第一天,我就决定抛弃图形界面——毕竟在嵌入式开发领域,真正的效率永远来自命令行。本文将分享如何通过纯命令行完成从开箱到网络配置的全过程,包括串口…...

n8n通过MCP调用RAGFlow知识库
n8n通过MCP调用RAFFlow知识库一、搭建RAGFlow知识库1、进入官网下载ZIP包文件2、解压ZIP包到本地3、修改ragflow项目下配置文件1、修改docker/.env文件2、修改docker/docker-compose.yml文件4、启动容器登录首页1、进入登陆页面2、注册用户3、登录用户4、进入首页创建知识库1、…...

终极指南:如何使用gosu实现容器运行时权限管理的标准化方案
终极指南:如何使用gosu实现容器运行时权限管理的标准化方案 【免费下载链接】gosu Simple Go-based setuidsetgidsetgroupsexec 项目地址: https://gitcode.com/gh_mirrors/go/gosu 在容器化应用的世界里,权限管理是确保安全性和稳定性的关键环节…...

GSE-Advanced-Macro-Compiler:重新定义魔兽世界技能自动化的开发实践
GSE-Advanced-Macro-Compiler:重新定义魔兽世界技能自动化的开发实践 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. It uses Travis for UnitTests, Coveralls to report on test …...

FFTW实战指南:从编译优化到音频信号处理
1. FFTW库简介与核心优势 FFTW(Fastest Fourier Transform in the West)是当前公认性能最优异的快速傅里叶变换开源库,其名称直译为"西方最快的傅里叶变换"。我在音频信号处理项目中首次接触这个库时,就被它惊人的运算…...

YOLOv9镜像实测:无需配置环境,快速实现目标检测全流程
YOLOv9镜像实测:无需配置环境,快速实现目标检测全流程 1. 开箱即用的YOLOv9体验 对于目标检测开发者来说,最头疼的往往不是算法本身,而是环境配置这个"拦路虎"。不同版本的CUDA、PyTorch、Python之间的兼容性问题&…...
)
告别官方镜像!手把手教你将自编译Android系统刷入AVD(基于Android Studio 4.2+)
告别官方镜像!手把手教你将自编译Android系统刷入AVD(基于Android Studio 4.2) 在Android开发领域,模拟器(AVD)一直是开发者调试和测试应用的重要工具。然而,大多数开发者仅限于使用Google提供的…...

如何快速掌握NoteGen AI笔记:新手入门完整指南
如何快速掌握NoteGen AI笔记:新手入门完整指南 【免费下载链接】note-gen 一款专注于记录和写作的跨端 AI 笔记应用。 项目地址: https://gitcode.com/GitHub_Trending/no/note-gen 在信息爆炸的时代,高效记录和管理知识已成为现代人的刚需。Note…...

从F1 90到62 F1 90:用Wireshark和CANoe‘解剖’一次完整的UDS 0x22数据读取会话
从F190到62F190:用Wireshark和CANoe解剖UDS 0x22数据读取会话 当你第一次在Wireshark中看到22服务请求和62响应报文时,那些十六进制字节可能就像天书一样难以理解。但正是这些看似杂乱的数据流,承载着现代汽车电子系统最核心的诊断信息交换。…...