【Kafka源码走读】Admin接口的客户端与服务端的连接流程
注:本文对应的kafka的源码的版本是trunk分支。写这篇文章的主要目的是当作自己阅读源码之后的笔记,写的有点凌乱,还望大佬们海涵,多谢!
最近在写一个Web版的kafka客户端工具,然后查看Kafka官网,发现想要与Server端建立连接,只需要执行
Admin.create(Properties props);
方法即可,但其内部是如何工作的,不得而知。鉴于此,该死的好奇心又萌动了起来,那我们今天就来看看,当执行Admin.create(Properties props)方法之后,client是如何与Server端建立连接的。
首先,我们看下Admin.create(Properties props)方法的实现:
static Admin create(Properties props) {return KafkaAdminClient.createInternal(new AdminClientConfig(props, true), null);}Admin是一个接口,create()是其静态方法,该方法内部又调用的是KafkaAdminClient.createInternal()方法,createInternal()源码如下:
static KafkaAdminClient createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory) {return createInternal(config, timeoutProcessorFactory, null);}
上述代码又调用了KafkaAdminClient类的另一个createInternal()方法
static KafkaAdminClient createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory,HostResolver hostResolver) {Metrics metrics = null;NetworkClient networkClient = null;Time time = Time.SYSTEM;String clientId = generateClientId(config);ChannelBuilder channelBuilder = null;Selector selector = null;ApiVersions apiVersions = new ApiVersions();LogContext logContext = createLogContext(clientId);try {// Since we only request node information, it's safe to pass true for allowAutoTopicCreation (and it// simplifies communication with older brokers)AdminMetadataManager metadataManager = new AdminMetadataManager(logContext,config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG),config.getLong(AdminClientConfig.METADATA_MAX_AGE_CONFIG));List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG),config.getString(AdminClientConfig.CLIENT_DNS_LOOKUP_CONFIG));metadataManager.update(Cluster.bootstrap(addresses), time.milliseconds());List<MetricsReporter> reporters = config.getConfiguredInstances(AdminClientConfig.METRIC_REPORTER_CLASSES_CONFIG,MetricsReporter.class,Collections.singletonMap(AdminClientConfig.CLIENT_ID_CONFIG, clientId));Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);MetricConfig metricConfig = new MetricConfig().samples(config.getInt(AdminClientConfig.METRICS_NUM_SAMPLES_CONFIG)).timeWindow(config.getLong(AdminClientConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS).recordLevel(Sensor.RecordingLevel.forName(config.getString(AdminClientConfig.METRICS_RECORDING_LEVEL_CONFIG))).tags(metricTags);JmxReporter jmxReporter = new JmxReporter();jmxReporter.configure(config.originals());reporters.add(jmxReporter);MetricsContext metricsContext = new KafkaMetricsContext(JMX_PREFIX,config.originalsWithPrefix(CommonClientConfigs.METRICS_CONTEXT_PREFIX));metrics = new Metrics(metricConfig, reporters, time, metricsContext);String metricGrpPrefix = "admin-client";channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);selector = new Selector(config.getLong(AdminClientConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),metrics, time, metricGrpPrefix, channelBuilder, logContext);networkClient = new NetworkClient(metadataManager.updater(),null,selector,clientId,1,config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),(int) TimeUnit.HOURS.toMillis(1),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),time,true,apiVersions,null,logContext,(hostResolver == null) ? new DefaultHostResolver() : hostResolver);return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient,timeoutProcessorFactory, logContext);} catch (Throwable exc) {closeQuietly(metrics, "Metrics");closeQuietly(networkClient, "NetworkClient");closeQuietly(selector, "Selector");closeQuietly(channelBuilder, "ChannelBuilder");throw new KafkaException("Failed to create new KafkaAdminClient", exc);}}
前面的都是构造参数,关注以下这行代码:
return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient,timeoutProcessorFactory, logContext);
KafkaAdminClient的构造方法如下:
private KafkaAdminClient(AdminClientConfig config,String clientId,Time time,AdminMetadataManager metadataManager,Metrics metrics,KafkaClient client,TimeoutProcessorFactory timeoutProcessorFactory,LogContext logContext) {this.clientId = clientId;this.log = logContext.logger(KafkaAdminClient.class);this.logContext = logContext;this.requestTimeoutMs = config.getInt(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG);this.defaultApiTimeoutMs = configureDefaultApiTimeoutMs(config);this.time = time;this.metadataManager = metadataManager;this.metrics = metrics;this.client = client;this.runnable = new AdminClientRunnable();String threadName = NETWORK_THREAD_PREFIX + " | " + clientId;this.thread = new KafkaThread(threadName, runnable, true);this.timeoutProcessorFactory = (timeoutProcessorFactory == null) ?new TimeoutProcessorFactory() : timeoutProcessorFactory;this.maxRetries = config.getInt(AdminClientConfig.RETRIES_CONFIG);this.retryBackoffMs = config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG);config.logUnused();AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());log.debug("Kafka admin client initialized");thread.start();}
上面的代码,大部分都是传递参数,但里面有个细节,不能忽略。最后一行代码是thread.start(),这里启动了一个线程,根据thread对象往前找,看看该对象是如何初始化的:
this.thread = new KafkaThread(threadName, runnable, true);
由此可知,thread是KafkaThread构造的对象,KafkaThread继承于Thread类。同时,上述代码中KafkaThread的构造方法中的第二个参数是runnable,该参数的定义如下:
this.runnable = new AdminClientRunnable();
既然runnable是类AdminClientRunnable构造的对象,那么,当thread.start()代码执行之后,类AdminClientRunnable的run()方法就开始执行了,我们看下run()方法的源码:
@Overridepublic void run() {log.debug("Thread starting");try {processRequests();} finally {closing = true;AppInfoParser.unregisterAppInfo(JMX_PREFIX, clientId, metrics);int numTimedOut = 0;TimeoutProcessor timeoutProcessor = new TimeoutProcessor(Long.MAX_VALUE);synchronized (this) {numTimedOut += timeoutProcessor.handleTimeouts(newCalls, "The AdminClient thread has exited.");}numTimedOut += timeoutProcessor.handleTimeouts(pendingCalls, "The AdminClient thread has exited.");numTimedOut += timeoutCallsToSend(timeoutProcessor);numTimedOut += timeoutProcessor.handleTimeouts(correlationIdToCalls.values(),"The AdminClient thread has exited.");if (numTimedOut > 0) {log.info("Timed out {} remaining operation(s) during close.", numTimedOut);}closeQuietly(client, "KafkaClient");closeQuietly(metrics, "Metrics");log.debug("Exiting AdminClientRunnable thread.");}}
在上述代码中,只需关注processRequests()方法,源码如下:
private void processRequests() {long now = time.milliseconds();while (true) {// Copy newCalls into pendingCalls.drainNewCalls();// Check if the AdminClient thread should shut down.long curHardShutdownTimeMs = hardShutdownTimeMs.get();if ((curHardShutdownTimeMs != INVALID_SHUTDOWN_TIME) && threadShouldExit(now, curHardShutdownTimeMs))break;// Handle timeouts.TimeoutProcessor timeoutProcessor = timeoutProcessorFactory.create(now);timeoutPendingCalls(timeoutProcessor);timeoutCallsToSend(timeoutProcessor);timeoutCallsInFlight(timeoutProcessor);long pollTimeout = Math.min(1200000, timeoutProcessor.nextTimeoutMs());if (curHardShutdownTimeMs != INVALID_SHUTDOWN_TIME) {pollTimeout = Math.min(pollTimeout, curHardShutdownTimeMs - now);}// Choose nodes for our pending calls.pollTimeout = Math.min(pollTimeout, maybeDrainPendingCalls(now));long metadataFetchDelayMs = metadataManager.metadataFetchDelayMs(now);if (metadataFetchDelayMs == 0) {metadataManager.transitionToUpdatePending(now);Call metadataCall = makeMetadataCall(now);// Create a new metadata fetch call and add it to the end of pendingCalls.// Assign a node for just the new call (we handled the other pending nodes above).if (!maybeDrainPendingCall(metadataCall, now))pendingCalls.add(metadataCall);}pollTimeout = Math.min(pollTimeout, sendEligibleCalls(now));if (metadataFetchDelayMs > 0) {pollTimeout = Math.min(pollTimeout, metadataFetchDelayMs);}// Ensure that we use a small poll timeout if there are pending calls which need to be sentif (!pendingCalls.isEmpty())pollTimeout = Math.min(pollTimeout, retryBackoffMs);// Wait for network responses.log.trace("Entering KafkaClient#poll(timeout={})", pollTimeout);List<ClientResponse> responses = client.poll(Math.max(0L, pollTimeout), now);log.trace("KafkaClient#poll retrieved {} response(s)", responses.size());// unassign calls to disconnected nodesunassignUnsentCalls(client::connectionFailed);// Update the current time and handle the latest responses.now = time.milliseconds();handleResponses(now, responses);}}
额,上面的代码,此时并未发现连接Server的过程,同时,我发现上述代码通过poll()方法在获取Server端的消息:
List<ClientResponse> responses = client.poll(Math.max(0L, pollTimeout), now);
按照我当时看这段代码的思路,由于这部分代码没有连接的过程,所以,我也就不进入poll()方法了,从方法名上看,它里面也应该没有连接的过程,所以转而回头看下client对象是如何定义的,在KafkaAdminClient.createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory, HostResolver hostResolver)方法中,定义如下:
networkClient = new NetworkClient(metadataManager.updater(),null,selector,clientId,1,config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),(int) TimeUnit.HOURS.toMillis(1),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),time,true,apiVersions,null,logContext,(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
再看下NetworkClient的构造函数:
public NetworkClient(MetadataUpdater metadataUpdater,Metadata metadata,Selectable selector,String clientId,int maxInFlightRequestsPerConnection,long reconnectBackoffMs,long reconnectBackoffMax,int socketSendBuffer,int socketReceiveBuffer,int defaultRequestTimeoutMs,long connectionSetupTimeoutMs,long connectionSetupTimeoutMaxMs,Time time,boolean discoverBrokerVersions,ApiVersions apiVersions,Sensor throttleTimeSensor,LogContext logContext,HostResolver hostResolver) {/* It would be better if we could pass `DefaultMetadataUpdater` from the public constructor, but it's not* possible because `DefaultMetadataUpdater` is an inner class and it can only be instantiated after the* super constructor is invoked.*/if (metadataUpdater == null) {if (metadata == null)throw new IllegalArgumentException("`metadata` must not be null");this.metadataUpdater = new DefaultMetadataUpdater(metadata);} else {this.metadataUpdater = metadataUpdater;}this.selector = selector;this.clientId = clientId;this.inFlightRequests = new InFlightRequests(maxInFlightRequestsPerConnection);this.connectionStates = new ClusterConnectionStates(reconnectBackoffMs, reconnectBackoffMax,connectionSetupTimeoutMs, connectionSetupTimeoutMaxMs, logContext, hostResolver);this.socketSendBuffer = socketSendBuffer;this.socketReceiveBuffer = socketReceiveBuffer;this.correlation = 0;this.randOffset = new Random();this.defaultRequestTimeoutMs = defaultRequestTimeoutMs;this.reconnectBackoffMs = reconnectBackoffMs;this.time = time;this.discoverBrokerVersions = discoverBrokerVersions;this.apiVersions = apiVersions;this.throttleTimeSensor = throttleTimeSensor;this.log = logContext.logger(NetworkClient.class);this.state = new AtomicReference<>(State.ACTIVE);}
事与愿违,有点尴尬,从NetworkClient的构造方法来看,也不涉及连接Server端的代码,那连接是在什么时候发生的呢?我想到快速了解NetworkClient类中都有哪些方法,以寻找是否有建立连接的方法。可喜的是,我找到了initiateConnect(Node node, long now)方法,见下图:

这个方法像是连接Server的,然后顺着这个方法,去查看是谁在调用它的,如下图所示:

调用栈显示,有两个方法调用了initiateConnect()方法,他们分别是ready()和maybeUpdate()方法,然后分别对ready()和maybeUpdate()方法又进行反向跟踪,看他们又分别被谁调用,中间的反向调用过程在这里就省略了,感兴趣的可以自己去研究下。
我们先从maybeUpdate()方法着手吧,通过该方法,最后可追踪到maybeUpdate()方法最终被poll()所调用。嗯?是不是前面我们也跟踪到poll()方法了。难道就是在调用poll方法之后,才实现连接Server的过程?下面是poll()方法的实现:
/*** Do actual reads and writes to sockets.** @param timeout The maximum amount of time to wait (in ms) for responses if there are none immediately,* must be non-negative. The actual timeout will be the minimum of timeout, request timeout and* metadata timeout* @param now The current time in milliseconds* @return The list of responses received*/@Overridepublic List<ClientResponse> poll(long timeout, long now) {ensureActive();if (!abortedSends.isEmpty()) {// If there are aborted sends because of unsupported version exceptions or disconnects,// handle them immediately without waiting for Selector#poll.List<ClientResponse> responses = new ArrayList<>();handleAbortedSends(responses);completeResponses(responses);return responses;}long metadataTimeout = metadataUpdater.maybeUpdate(now);try {this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));} catch (IOException e) {log.error("Unexpected error during I/O", e);}// process completed actionslong updatedNow = this.time.milliseconds();List<ClientResponse> responses = new ArrayList<>();handleCompletedSends(responses, updatedNow);handleCompletedReceives(responses, updatedNow);handleDisconnections(responses, updatedNow);handleConnections();handleInitiateApiVersionRequests(updatedNow);handleTimedOutConnections(responses, updatedNow);handleTimedOutRequests(responses, updatedNow);completeResponses(responses);return responses;}
由上述代码可知,maybeUpdate()方法是被metadataUpdater对象所调用,接下来我们就需要了解metadataUpdater对象属于哪个类。
回到NetworkClient的构造方法可看到这段代码:
if (metadataUpdater == null) {if (metadata == null)throw new IllegalArgumentException("`metadata` must not be null");this.metadataUpdater = new DefaultMetadataUpdater(metadata);} else {this.metadataUpdater = metadataUpdater;}
注意这里,如果metadataUpdater的值为null,则metadataUpdater = new DefaultMetadataUpdater(metadata),也就是说metadataUpdater对象属于DefaultMetadataUpdater类;
如果metadataUpdater的值不为null,则其值保持不变,也就是说,这个值是由调用者传入的。
现在我们需要跟踪调用者传入该值时是否为null,则需要回到KafkaAdminClient.createInternal()方法,下面对代码进行了精简,仅关注重点:
AdminMetadataManager metadataManager = new AdminMetadataManager(logContext,config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG),config.getLong(AdminClientConfig.METADATA_MAX_AGE_CONFIG));.......部分代码省略......networkClient = new NetworkClient(metadataManager.updater(),null,selector,clientId,1,config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),(int) TimeUnit.HOURS.toMillis(1),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),time,true,apiVersions,null,logContext,(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
由上述代码可知,在传入NetworkClient的构造方法时,metadataManager.updater()=AdminMetadataManager.updater(),而AdminMetadataManager的源码如下:
public AdminMetadataManager(LogContext logContext, long refreshBackoffMs, long metadataExpireMs) {this.log = logContext.logger(AdminMetadataManager.class);this.refreshBackoffMs = refreshBackoffMs;this.metadataExpireMs = metadataExpireMs;this.updater = new AdminMetadataUpdater();}public AdminMetadataUpdater updater() {return updater;}
由此可知,传入NetworkClient的构造方法时的metadataUpdater对象并不为null,且该对象属于AdminMetadataUpdater类。
好了,到这里我们已经把metadataUpdater的值搞清楚了,其值并不为null。但如果通过IDE的代码默认跟踪方式,会将metadataUpdater的值定位为DefaultMetadataUpdater类,如果是这样,那会有什么影响呢?
前面我们提到,NetworkClient.poll()方法会调用maybeUpdate()方法,即如下这行代码:
long metadataTimeout = metadataUpdater.maybeUpdate(now);
metadataUpdater对象如果为DefaultMetadataUpdater类,则调用上述maybeUpdate(now)方法时,会执行连接Server的过程,源码如下:
@Overridepublic long maybeUpdate(long now) {// should we update our metadata?long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);long waitForMetadataFetch = hasFetchInProgress() ? defaultRequestTimeoutMs : 0;long metadataTimeout = Math.max(timeToNextMetadataUpdate, waitForMetadataFetch);if (metadataTimeout > 0) {return metadataTimeout;}// Beware that the behavior of this method and the computation of timeouts for poll() are// highly dependent on the behavior of leastLoadedNode.Node node = leastLoadedNode(now);if (node == null) {log.debug("Give up sending metadata request since no node is available");return reconnectBackoffMs;}return maybeUpdate(now, node);}# maybeUpdate(now)再调用maybeUpdate(now, node)方法,代码如下:private long maybeUpdate(long now, Node node) {String nodeConnectionId = node.idString();if (canSendRequest(nodeConnectionId, now)) {Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;log.debug("Sending metadata request {} to node {}", metadataRequest, node);sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);return defaultRequestTimeoutMs;}// If there's any connection establishment underway, wait until it completes. This prevents// the client from unnecessarily connecting to additional nodes while a previous connection// attempt has not been completed.if (isAnyNodeConnecting()) {// Strictly the timeout we should return here is "connect timeout", but as we don't// have such application level configuration, using reconnect backoff instead.return reconnectBackoffMs;}if (connectionStates.canConnect(nodeConnectionId, now)) {// We don't have a connection to this node right now, make onelog.debug("Initialize connection to node {} for sending metadata request", node);# 这里就是连接Server端的入口了initiateConnect(node, now);return reconnectBackoffMs;}// connected, but can't send more OR connecting// In either case, we just need to wait for a network event to let us know the selected// connection might be usable again.return Long.MAX_VALUE;}
注意上述代码的中文注释部分,initiateConnect(node, now)方法就是连接Server端的入口,该方法的实现如下:
/*** Initiate a connection to the given node* @param node the node to connect to* @param now current time in epoch milliseconds*/private void initiateConnect(Node node, long now) {String nodeConnectionId = node.idString();try {connectionStates.connecting(nodeConnectionId, now, node.host());InetAddress address = connectionStates.currentAddress(nodeConnectionId);log.debug("Initiating connection to node {} using address {}", node, address);selector.connect(nodeConnectionId,new InetSocketAddress(address, node.port()),this.socketSendBuffer,this.socketReceiveBuffer);} catch (IOException e) {log.warn("Error connecting to node {}", node, e);// Attempt failed, we'll try again after the backoffconnectionStates.disconnected(nodeConnectionId, now);// Notify metadata updater of the connection failuremetadataUpdater.handleServerDisconnect(now, nodeConnectionId, Optional.empty());}}
所以,metadataUpdater对象如果为DefaultMetadataUpdater类,就会在调用poll()方法时,初始化连接Server的过程。但前面已知,metadataUpdater对象属于AdminMetadataUpdater类,他又是在哪里与Server进行连接的呢?
我们再回到之前已知悉的内容,有两个方法调用了initiateConnect()方法,他们分别是ready()和maybeUpdate()方法。通过上面的跟踪,目前可以排除maybeUpdate()方法了。接下来,通过ready()方法,我们再反向跟踪一下,哪些地方都调用了ready()方法。
通过层层筛选,发现KafkaAdminClient.sendEligibleCalls()方法调用了ready()方法,如下图所示:

通过sendEligibleCalls()方法又反向查找是谁在调用该方法,如下图所示:

由图可知,是KafkaAdminClient.processRequests()方法调用了sendEligibleCalls()方法,而processRequests()方法正是我们前面跟踪代码时,发现无法继续跟踪的地方。精简之后的代码如下:
private void processRequests(){long now=time.milliseconds();while(true){// Copy newCalls into pendingCalls.drainNewCalls();......部分代码省略......pollTimeout=Math.min(pollTimeout,sendEligibleCalls(now));......部分代码省略......// Wait for network responses.log.trace("Entering KafkaClient#poll(timeout={})",pollTimeout);List<ClientResponse> responses=client.poll(Math.max(0L,pollTimeout),now);log.trace("KafkaClient#poll retrieved {} response(s)",responses.size());......部分代码省略......}}
由上述代码可知,与Server端的连接是在poll()方法执行之前,隐藏在pollTimeout=Math.min(pollTimeout,sendEligibleCalls(now));代码中。如果想要验证自己的理解是否正确,则可以通过调试源码,增加断点来验证,这里就略过了。
现在回过头来,就会发现,为什么我之前读到这个processRequests()方法时,没有发现这个方法呢?因为没有注意到一些细节,所以忽略了这个方法,误以为连接发生在其他地方。
当然,这可能也和我的惯性思维有关,总是通过类名和方法名来猜测这个方法的大概意图,然后当找不到流程的时候,就通过反向查找调用栈的方式去梳理执行流程,也算是殊途同归吧。
最后,用一张时序图来总结下上面的内容:

相关文章:
【Kafka源码走读】Admin接口的客户端与服务端的连接流程
注:本文对应的kafka的源码的版本是trunk分支。写这篇文章的主要目的是当作自己阅读源码之后的笔记,写的有点凌乱,还望大佬们海涵,多谢! 最近在写一个Web版的kafka客户端工具,然后查看Kafka官网,…...

Windows API遍历桌面上所有文件
要获取桌面上的图标,可以使用Windows API中的Shell API。以下是遍历桌面上所有文件的示例代码: #include <Windows.h> #include <ShlObj.h> #include <iostream> #include <vector> using namespace std;int main() {// 获取桌…...
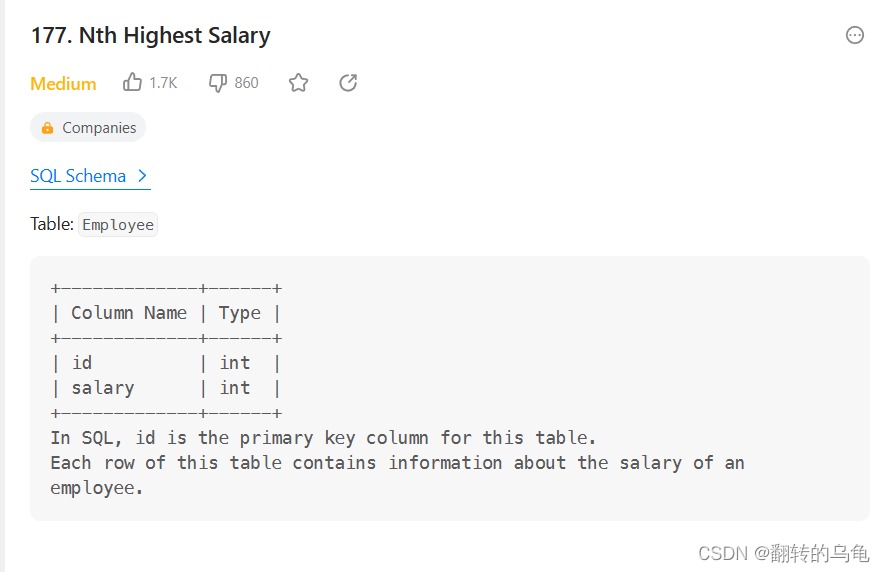
【MySQL】基本查询(插入查询结果、聚合函数、分组查询)
目录 一、插入查询结果二、聚合函数三、分组查询(group by & having)四、SQL查询的执行顺序五、OJ练习 一、插入查询结果 语法: INSERT INTO table_name [(column [, column ...])] SELECT ...案例:删除表中重复数据 --创建…...
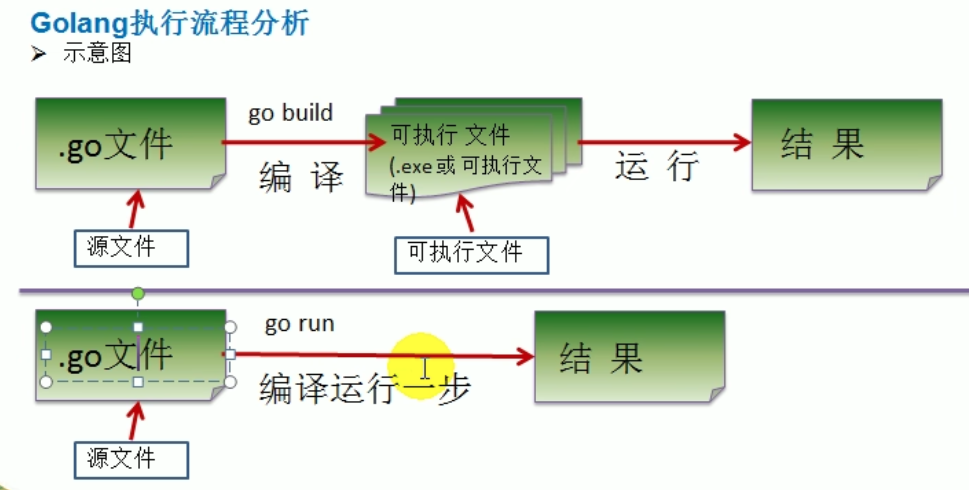
【Go语言】Golang保姆级入门教程 Go初学者介绍chapter1
Golang 开山篇 Golang的学习方向 区块链研发工程师: 去中心化 虚拟货币 金融 Go服务器端、游戏软件工程师 : C C 处理日志 数据打包 文件系统 数据处理 很厉害 处理大并发 Golang分布式、云计算软件工程师:盛大云 cdn 京东 消息推送 分布式文…...

mysql 自增长键值增量设置
参考文章 MySQL中auto_increment的初值和增量值设置_auto_increment怎么设置_linda公馆的博客-CSDN博客 其中关键语句 show VARIABLES like %auto_increment% set auto_increment_increment4; set auto_increment_offset2;...
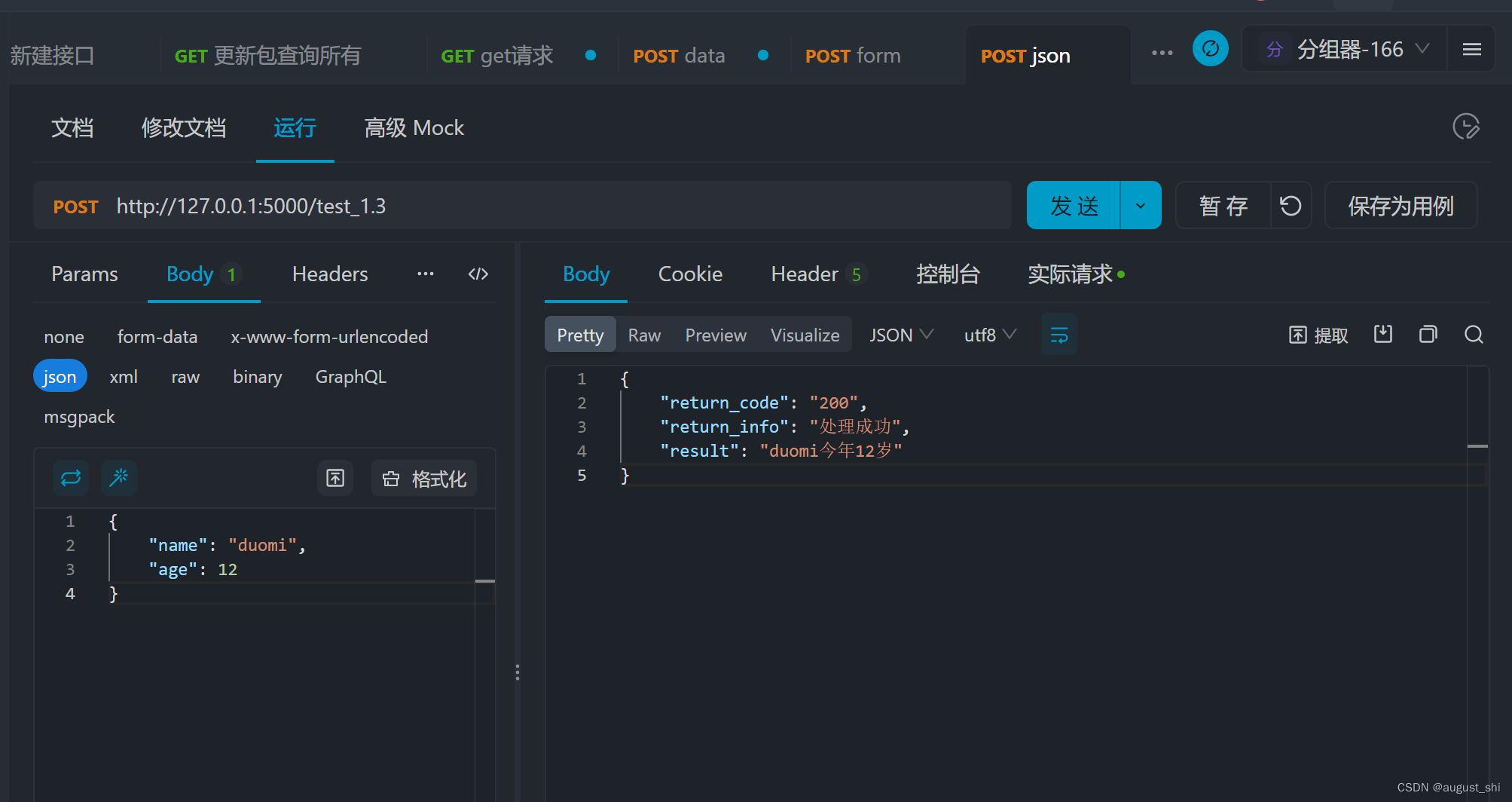
【pytho】request五种种请求处理为空和非空处理以及上传excel,上传图片处理
一、python中请求处理 request.args获取的是个字典,所以可以通过get方式获取请求参数和值 request.form获取的也是个字典,所以也可以通过get方式获取请求的form参数和值 request.data,使用过JavaScript,api调用方式进行掺入jso…...

【全面解析】Windows 如何使用 SSH 密钥远程连接 Linux 服务器
创建密钥 创建 linux 服务器端的终端中执行命令 ssh-keygen,之后一直按Enter即可,这样会在将在 ~/.ssh/ 路径下生成公钥(id_rsa.pub)和私钥(id_rsa) 注意:也可以在 windows 端生成密钥,只需要保证公钥在服务器端,私钥…...

解锁新技能《基于logback的纯java版本SDK实现》
开源SDK: <!--Java通用日志组件SDK--> <dependency><groupId>io.github.mingyang66</groupId><artifactId>oceansky-logger</artifactId><version>4.3.6</version> </dependency> <!-- Java基于logback的…...
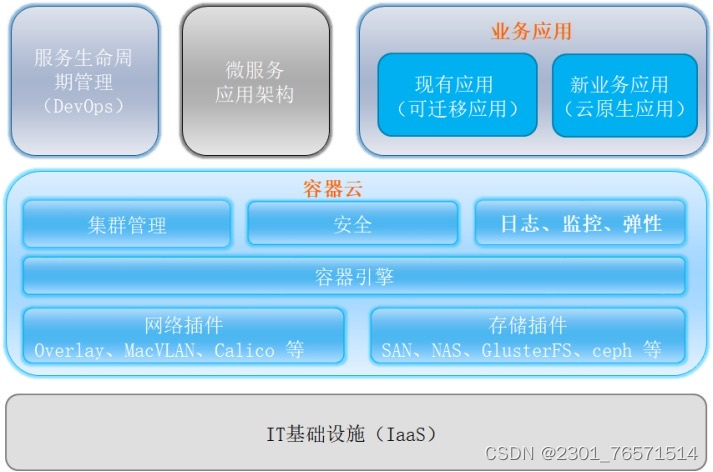
你需要知道的云原生架构体系内容
云原生(Cloud-Native)的概念在国内提及的越来越多,但大部分人对云原生的认识仅限于容器、微服务、DevOps等内容,把容器、微服务、 DevOps就等同于云原生,这显然是不对的。CNCF从其自身的角度定义了云原生技术ÿ…...
安全渗透--正则表达式
什么是正则表达式? 正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。 一个正则表达式是一种从左到右匹配主体字符串的模式。 “Regular expression”这个词比较拗口,我们常使用缩写的术语“regex…...
git如何撤销commit(未push)
文章目录 前言undo commitreset current branch to here Undo Commit,Revert Commit,Drop Commit的区别 是否删除对代码的修改是否删除Commit记录是否会新增Commit记录Undo Commit不会未Push会,已Push不会不会Revert Commit会不会会Drop Com…...

Vue数组与字符串互转
一、数组转换成字符串的方法 join() var arr [A, B, C]; var str arr.join(、); console.log(str); // 输出 A、B、C toString() var arr [A, B, C]; var str arr.toString(); console.log(str); // 输出 A, B, C JSON.stringify() var arr [A, B, C]; var str JSO…...

Java编程实现遍历两个MAC地址之间所有MAC的方法
Java编程实现遍历两个MAC地址之间所有MAC的方法 本文实例讲述了java编程实现遍历两个MAC地址之间所有MAC的方法。分享给大家供大http://家参考,具体如下: 在对发放的设备进行后台管理时,很多时候会用到设备MAC这个字段,它可以标识唯一一个设备。然而在数…...

用AXIS2发布WebService的方法
Axis2+tomcat6.0 实现webService 服务端发布与客户端的调用。 Aixs2开发webService的方法有很多,在此只介绍一种比较简单的实现方法。 第一步:首先要下载开发所需要的jar包 下载:axis2-1.6.1-war.zip http://www.apache.org/dist//axis/axis2/java/core/1.6.1/ 下载…...
嵌入式学习_Day 003
程序功能介绍 c #include <stdio.h> int main() {char c,ll;printf("please enter a capital letter:");cgetchar();getchar();if (c>A&& c<Z) {llc32;printf("Lowercase letter output:%c\n",ll);printf("ASCII value:%d\n"…...
常用的数据结构 JAVA
目录 1、线性表2、栈:3、队列: 1、线性表 List<Object> narnat new ArrayList<>();ArrayList:动态数组 1、可以嵌套使用 2、add(x)添加元素x,remove(index)删除某个位置的元素 3、注意list是指向性的,…...
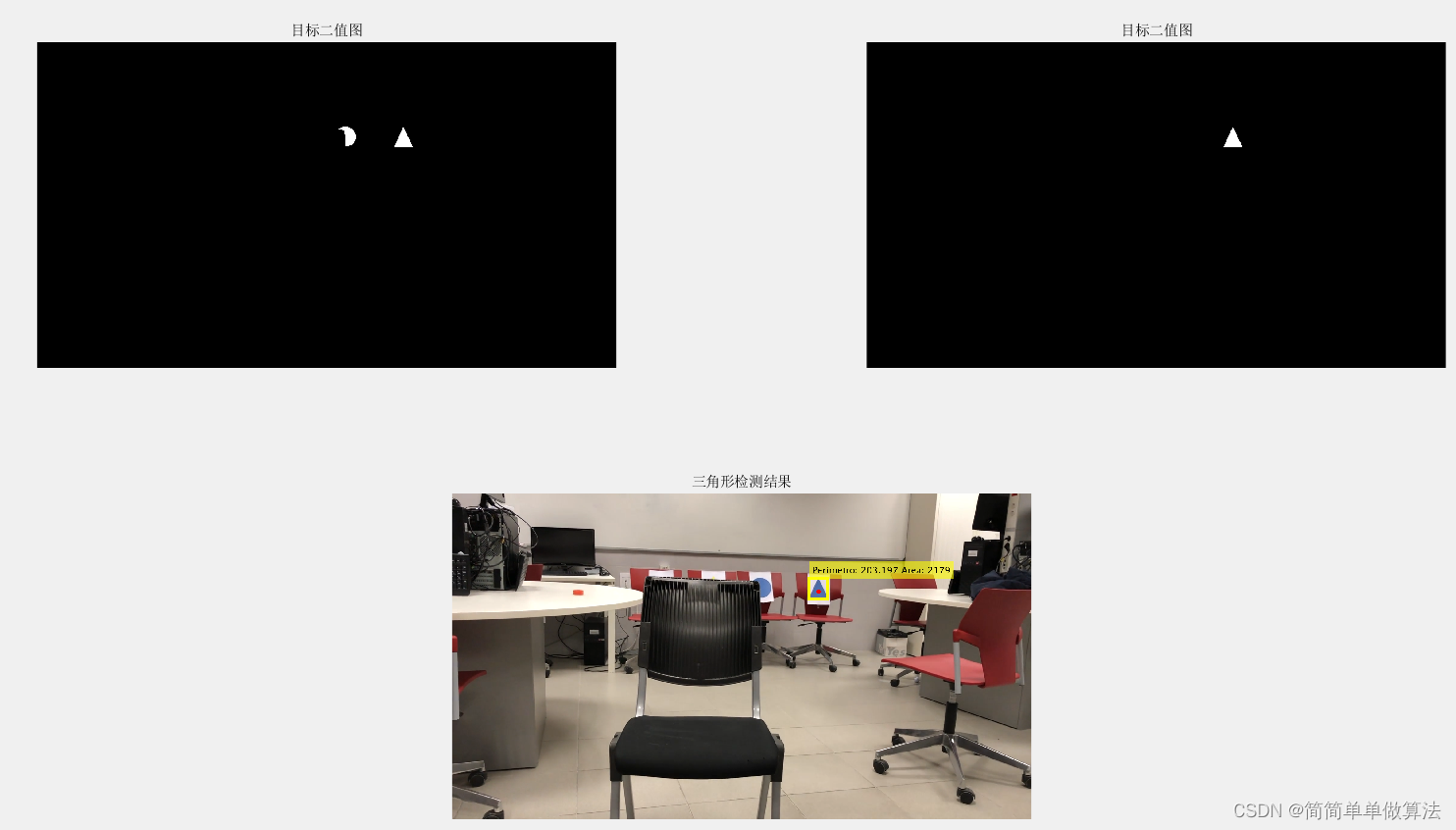
基于机器视觉工具箱和形态学处理的视频中目标形状检测算法matlab仿真
目录 1.算法理论概述 2.部分核心程序 3.算法运行软件版本 4.算法运行效果图预览 5.算法完整程序工程 1.算法理论概述 目标形状检测是计算机视觉领域的重要任务之一,旨在从视频序列中自动检测和识别特定目标的形状。本文介绍一种基于机器视觉工具箱和形态学处理…...
小白入门:sentence-transformer 提取embedding模型转onnx
文章目录 序言原理讲解哪些部分可转onnx 代码区0. 安装依赖1. 路径配置2. 测试数据3. 准备工作3.1迁移保存目标文件 4. model转onnx-gpu5. 测试一下是否出错以及速度5.1 测试速度是否OK5.2测试结果是否OK 6. tar 这些文件 序言 本文适合小白入门,以自己训练的句子e…...

数据库应用:Redis持久化
目录 一、理论 1.Redis 高可用 2.Redis持久化 3.RDB持久化 4.AOF持久化(支持秒级写入) 5.RDB和AOF的优缺点 6.RDB和AOF对比 7.Redis性能管理 8.Redis的优化 二、实验 1.RDB持久化 2.AOF持久化 3.Redis性能管理 4.Redis的优化 三、总结 一、…...
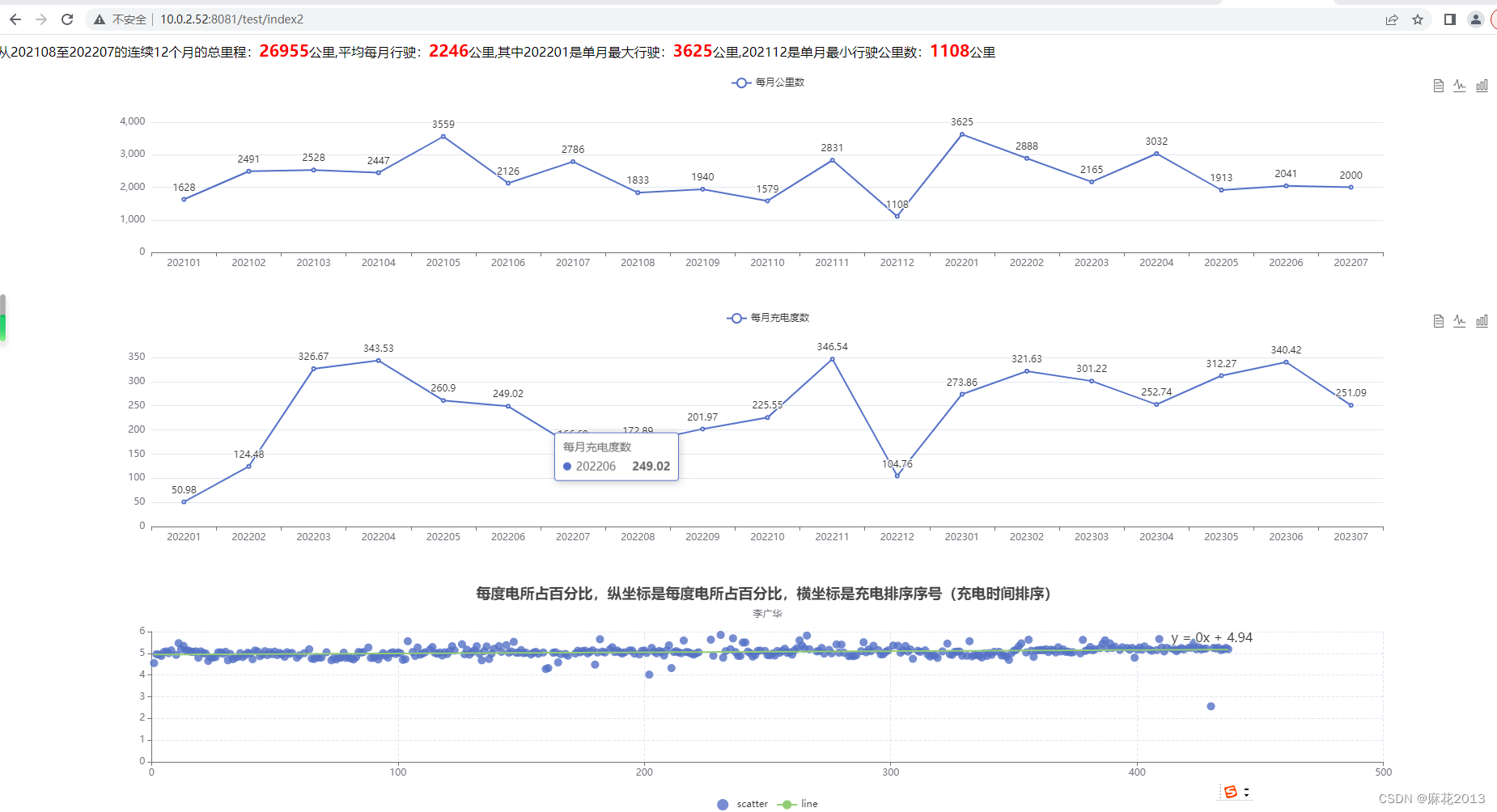
js版计算比亚迪行驶里程连续12个月计算不超3万公里改进版带echar
<!DOCTYPE html> <html lang"zh-CN" style"height: 100%"> <head> <meta charset"utf-8" /> <title>连续12个月不超3万公里计算LIGUANGHUA</title> <style> .clocks { …...

OpenArk:新一代Windows系统安全分析工具完整指南
OpenArk:新一代Windows系统安全分析工具完整指南 【免费下载链接】OpenArk The Next Generation of Anti-Rookit(ARK) tool for Windows. 项目地址: https://gitcode.com/GitHub_Trending/op/OpenArk 如果你正在寻找一款强大的Windows系统安全分析工具&#…...

python-flask-djangol框架的关爱空巢老人和孩子留守儿童管理系统的设计和实现
目录需求分析与规划技术选型核心模块设计数据安全与权限开发与测试计划社区与可持续性项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与规划 明确系统核心功能模块:空巢老人健康监测、留守儿童学习与心理辅…...

Dify工作流终极指南:3天从新手到专家的完整免费教程
Dify工作流终极指南:3天从新手到专家的完整免费教程 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Wo…...

Windows下RedisInsight保姆级安装教程:从下载到连接Redis全流程详解
Windows平台RedisInsight全流程实战指南:从零搭建高效Redis可视化环境 Redis作为当下最流行的内存数据库之一,其强大的性能与丰富的数据结构深受开发者青睐。但在日常开发中,仅通过命令行操作Redis难免效率低下——这正是RedisInsight的价值所…...

雷电模拟器装Magisk后,自带的文件管理器为啥打不开/data?用MT管理器一招搞定
雷电模拟器Magisk环境下文件管理器的权限困局与实战解决方案 当你在雷电模拟器中成功安装Magisk后,可能会遇到一个令人困惑的现象:原本可以自由访问系统目录的自带文件管理器,突然对/data和/system等关键路径"视而不见"。这并非模拟…...

别再瞎找了!AI论文软件2026最新测评与推荐
2026年真正好用的AI论文软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 一、…...

腾讯混元翻译模型实战:跨境电商多语言商品描述生成案例
腾讯混元翻译模型实战:跨境电商多语言商品描述生成案例 1. 项目背景与价值 跨境电商企业面临一个共同挑战:如何高效地将商品信息翻译成多种语言。传统人工翻译成本高、周期长,而通用翻译工具又难以满足电商场景的专业需求。 腾讯混元翻译模…...

STM32智能婴儿床系统设计与实现
基于STM32的智能婴儿床系统设计1. 项目概述1.1 系统架构本智能婴儿床系统采用模块化设计架构,以STM32F103RCT6微控制器为核心处理单元,集成多种传感器模块和执行机构。系统通过蓝牙与手机APP建立双向通信,实现环境参数监测、异常报警和远程控…...


STC89C52单片机+槽型光耦,手把手教你DIY一个低成本电机转速测量仪
STC89C52单片机槽型光耦DIY电机转速测量仪实战指南 从零搭建低成本测速系统的完整方案 电机转速测量在工业控制、机器人开发、智能小车等领域都是基础但关键的环节。市面上专业测速仪动辄上千元的价格让许多电子爱好者望而却步。其实,利用手头常见的STC89C52单片机…...