计算机内存中的缓存Cache Memories
这篇写一下计算机系统中的缓存Cache应用场景和实现方式介绍。
Memory hierarchy
在讲缓存之前,首先要了解计算机中的内存结构层次Memory hierarchy。也就是下图金字塔形状的结构。

从上到下,内存层次结构如下:
-
寄存器:这是计算机中最快速的存储区域。它们位于处理器内,用于存储即将被处理器执行的指令和数据。
-
高速缓存(Cache):位于处理器和主内存之间,用于存储最近或频繁访问的数据和指令。高速缓存有多级(L1、L2、L3),其中L1最接近处理器且速度最快,但也最小。
-
主内存(RAM):当计算机运行程序时,程序的代码和数据被加载到主内存中。
-
硬盘驱动器(HDD)或固态硬盘(SSD):这些是非易失性的存储设备,用于长期存储数据和程序。
-
网络存储和云存储:这些存储设备位于本地计算机之外,数据通常通过网络进行访问。
从上到下离CPU就越来越远,越往下的部分,容量往往越大,价格也越便宜;而越靠近CPU的部分,速度越快但是价格高且容量小。
Locality
局部性原理 (Locality of Reference) 是设计内存层次结构时需要考虑的重要因素,也是后面缓存为什么能够起作用的原因。
-
时间局部性(Temporal Locality):如果一个数据或指令在某个时间点被访问,那么在未来的一段时间内,这个数据或指令可能会被再次访问。这是由于程序的执行往往具有重复性,例如循环和递归。高速缓存就是基于时间局部性设计的,将最近访问过的数据和指令存储在快速访问的缓存中。
-
空间局部性(Spatial Locality):如果一个数据或指令被访问,那么在未来的一段时间内,其附近的数据或指令也可能会被访问。这是由于程序的执行通常具有连续性,例如顺序执行的指令和数组的元素。内存管理系统会将整个块(包含了访问数据或指令的附近地址)加载到高速缓存或主内存中,以利用空间局部性。
缓存Cache
如果我们把用过地址放在CPU里的存储单元,或者说一个更接近CPU、更能快速获取的地方,就有了我们广义概念上的“Cache”了。虽然这个地方很小,但基于locality的原理,程序倾向于使用之前的地址或者之前地址附近地址,每次CPU像访问数据,它都会优先从cache里查找(因为离得更近),如果是那种多次反复需要的数据,就可以直接让cache来提前处理了,提高数据获取速度。

当然,毕竟cache的位置有限,如果请求的数据没有在cache里(这叫做cache miss),就只能把cache中的数据删掉(比如最久没用的那个),然后把新数据从下面更慢的内存结构中获取后替换上去。
几种Cache miss
Cache miss主要有以下三种:
-
冷(强制)未命中(Cold or Compulsory Miss)
冷未命中是因为缓存开始时是空的,而这是对该块的第一次引用。换句话说,这是无法避免的未命中,因为当你第一次访问一个数据块时,它不可能已经在缓存中。 -
容量未命中(Capacity Miss)
当活动的缓存块集合(工作集)大于缓存的容量时,就会发生容量未命中。即使数据块之前已在缓存中,但由于缓存空间有限,可能已经被其他更近期访问的数据块替换出去。 -
冲突未命中(Conflict Miss)
前两个都比较好理解,这个冲突未命中比较复杂,我用通俗的语言讲大概是这样:比如我们教室有三排学生,每排都有一个椅子当作cache,那么我们cache一共有3个,学生有3排。这个时候如果规定每排学生只能用对应的一把椅子,就会发生conflict miss。比如第一排第一个同学有了一个行为,他被存储在了第一个椅子上;这个时候第一排第二个同学又有一个行为,我们只会用第二个同学去换下第一个同学——即使这个时候还有两把椅子是空的。当最后再次访问第一个同学时,你会发现明明第一个同学之前访问过,明明cache里有空位,但就是在cache里找不到他,这种情况下的miss就叫做conflict miss。
Cache的参数和大小表示
高速缓存(Cache)的总大小可以由以下三个参数描述:
- S:缓存的集数(Set)。
- E:每个集中的线数(Line),也就是每个集中的缓存块数量(Cache blocks per set)。
- B:每个缓存块的大小(Size of each block)。
而Cache set就等于 S × E × B。

Cache的结构看起来这么麻烦,如何存储数据呢?对于一个数据,如cache会根据它的地址来划分和存储。

如上图所示,通常地址会被划分成3部分:块偏移量(block offset)、集索引(set index)和标签(tag)。
-
块偏移量(Block Offset):这部分的位数取决于每个cache块(或行)的大小。例如,如果一个块的大小是16字节,那么块偏移量就需要4位(因为2^4 = 16),用于确定一个字节在其块中的位置。
-
集索引(Set Index):这部分的位数取决于cache的集数。例如,如果有64个集,集索引就需要6位(因为2^6 = 64),用于确定一个块应该存储在哪个集中。
-
标签(Tag):地址中剩下的位被用作标签,用于在cache查找过程中区分不同的内存块。
所以对于一个地址,大致的查找流程是这样的:首先进行地址分割,就像上面说的那样分成三部分;其次拿着集索引去cache中找到对应的集,拿到了这个集(可以理解成图里的一整行蓝色背景,包含很多line),我们查找所有line(通常会并行查找来提高速度),找到那个line,which有效位(valid bit)是1以及tag标签和地址划分出来的tag部分一样,如果找到了,则使用块偏移量从这个集中取出所需的数据。

再举个例子,在上面这个图中, block块大小是8,因此我们需要3个位作为block offset,这里offset是100也就是4,那么数据到时候会从第4位开始,也就是图中绿色块部分;集的个数不知道,集索引的位数也不确定,但这里0...01不管中间几个0,都是1,表示对应第一个集。在剩下的部分就是两个红色部分的tag比较了。
用这句话来检查一下你是否理解:这里虽然得到的块偏移量是4,但是你可以发现我们把4往后的部分也都放在cache里了(绿色部分)。因为这样的话如果下次访问这个同样的地址+1,按找那套流程算下来其实直接就对应块偏移量为5的部分,直接就在cache里了!这就是cache对Spatial Locality也友好的地方——不止是之前访问过的我有,之前访问过的邻居我也有!
Cache的写操作
当我们讨论写操作(write operations)在缓存系统中的行为时,我们需要考虑两种基本的情况:写命中(write hit)和写未命中(write miss)。在处理这两种情况时,有几种常见的策略:
-
1 写命中(Write Hit):当我们试图写入的数据已在缓存中时,我们有两种基本策略:
-
写直达(Write-Through):这种策略立即将更改写入到主存储器和缓存中。这种策略的优点是它保持了主存储器和缓存中的数据一致性,但缺点是每次写操作都需要访问主存储器,这可能会带来较大的性能开销。
-
写回(Write-Back):这种策略仅将更改写入到缓存中,并将缓存行标记为"dirty"(通过设置一个"dirty bit")。只有当缓存行被替换出缓存时,更改才会被写回到主存储器。这里的dirty bit就是替换时用来判断的,如果是1,那么就需要把整个缓存行(包含2^b字节的数据块)写回(write-back)到主内存。这种策略的优点是减少了对主存储器的访问次数,从而提高了性能。但是,这也可能会导致主存储器与缓存之间的数据不一致。
-

-
2 写未命中(Write Miss):当我们试图写入的数据不在缓存中时,我们有两种基本策略:
-
不写分配(No-Write-Allocate):这种策略直接将数据写入主存储器,而不将其加载到缓存中。这种策略适用于不希望单次写操作污染缓存的情况。
-
写分配(Write-Allocate):这种策略在写入数据之前,先将相关的缓存行加载到缓存中,再将新的写操作应用到这个缓存行。如果预计将来会有更多对同一位置的写操作,这种策略可能会很有用。
-
在实际的系统中,可能会组合使用这些策略。比如,一种常见的组合是使用写直达和不写分配策略,这种组合可以保持数据的一致性,而且适合处理散列的、非连续的写操作。另一种常见的组合是使用写回和写分配策略,这种组合可以减少对主存储器的访问次数,从而提高性能,尤其是在处理连续的、集中的写操作时。
小结
这篇文章写了下cache的概念以及读写过程中的读取策略。cache的缓存命中是非常有用和关键的,可以为程序或许数据节省下非常多时间。一个有趣的观点是,99%的命中率可能比97%的命中率好两倍。比如假设缓存命中的时间为1个周期,未命中的惩罚为100个周期。那么:
- 对于97%的命中率,平均访问时间为:1个周期(命中时间) + 0.03(未命中率) * 100个周期(未命中惩罚) = 4个周期。
- 对于99%的命中率,平均访问时间为:1个周期(命中时间) + 0.01(未命中率) * 100个周期(未命中惩罚) = 2个周期。
因此,尽管两者的命中率只相差2%,但是平均访问时间却差了一倍。
所以对于程序员来说,尽量写出“缓存友好”的代码也是能很好提升程序的效率。通过理解缓存的工作方式,我们可以编写出更有效地利用缓存的代码,一些常见方式有:
-
重复引用变量:这是好的(利用时间局部性Temporal Locality):如果一个变量被反复引用,它可能会留在缓存中,这样每次引用都会命中缓存,从而提高性能。
-
使用跨度为1的引用模式:这是好的(利用空间局部性Spatial Locality)。如果你的代码按顺序访问数据(例如,遍历数组),那么缓存系统可能会预先加载你即将访问的数据,从而提高缓存命中率。这就是为什么我们一行一行地遍历二维数组要比一列一列地遍历快很多,因为数组在内存中是按行存储,缓存可以帮助我们提前加载到接下来的数据。
结束!
相关文章:
计算机内存中的缓存Cache Memories
这篇写一下计算机系统中的缓存Cache应用场景和实现方式介绍。 Memory hierarchy 在讲缓存之前,首先要了解计算机中的内存结构层次Memory hierarchy。也就是下图金字塔形状的结构。 从上到下,内存层次结构如下: 寄存器:这是计算机…...
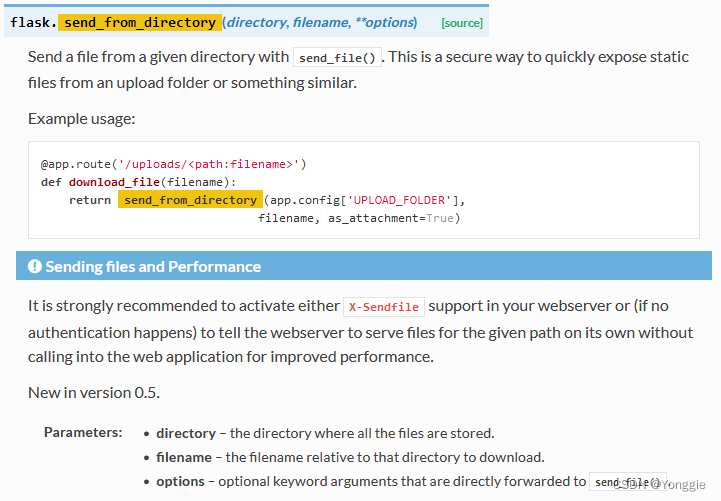
Flask的send file和send_from_directory的区别
可以自行查看flask 文档。 send file高效; send from directory安全,且适用于静态资源交互。 都是实现相同的功能的。 send_file send_from_directory...

Java 队列
基本介绍 数组模拟队列 思路分析 代码实现 import java.util.Scanner;public class Test {public static void main(String[] args) {// 创建一个队列ArrayQueue queue new ArrayQueue(3);int select;Scanner scanner new Scanner(System.in);boolean loop true;while (lo…...

【算法基础:搜索与图论】3.6 二分图(染色法判定二分图匈牙利算法)
文章目录 二分图介绍染色法判定二分图例题:860. 染色法判定二分图 匈牙利匹配二分图最大匹配匈牙利匹配算法思想例题:861. 二分图的最大匹配 二分图介绍 https://oi-wiki.org/graph/bi-graph/ 二分图是图论中的一个概念,它的所有节点可以被…...

SpringMVC 怎么和 AJAX 相互调用的
通过 Jackson 框架就可以把 Java 里面的对象直接转化成 Js 可以识别的 Json 对象。 步骤如下 : a、加入 Jackson.jar b、在配置文件中配置 json 的映射 c、在接受 Ajax 方法里面可以直接返回 Object,List 等,但方法前面要加上ResponseBody 详细步骤: …...
UCDOS和WPS推动计算机领域的汉字化发展,中文编程该谁力扛大旗?
你还记得UCDOS吗? 从DOS时代过来的人,还知道UCDOS的,现在可能已经是中年人了! 当时,鲍岳桥的UCDOS可以称得上是中国的国产操作系统。 在Windows还没来得及进入中国市场时,UCDOS可以说是走向了巅峰时刻&a…...

golang+layui提升界面美化度--[推荐]
一、背景 golanglayui提升界面美化度--[推荐]; golang后端写的页面很难看,如何好看点呢,那就是layui https://layui.dev/ 也是一个简单上手容易使用的框架,类似jquery,对于后端开发来说满足使用需求 二、使用注意点…...

42. 接雨水
题目介绍 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3…...

Python学习阶段路线和内容
Python学习阶段路线和内容 这是我的看法和认识,供参考。 Python学习路线主要分为三个阶段:入门阶段、提高阶段和深入阶段。 入门阶段 入门阶段需要学习Python的基本语法,掌握变量和数据类型、条件语句和循环语句、函数和模块等内容。并通过…...
RocketMQ教程-安装和配置
Linux系统安装配置 64位操作系统,推荐 Linux/Unix/macOS 64位 JDK 1.8 Maven3.0 yum 安装jdk8 yum 安装maven 1.下载安装Apache RocketMQ RocketMQ 的安装包分为两种,二进制包和源码包。 点击这里 下载 Apache RocketMQ 5.1.3的源码包。你也可以从这…...

【LeetCode】55.跳跃游戏
题目 给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标。 示例 1: 输入:nums [2,3,1,1,4] 输出:true 解释:可以…...

Docker学习路线12:开发者体验
到目前为止,我们只讨论了使用Docker来部署应用程序。然而,Docker也是一个极好的用于开发应用程序的工具。可以采用一些不同的建议来改善开发体验。 在应用程序中使用docker-compose以方便开发。使用绑定挂载将本地代码挂载到容器文件系统中,…...

后端服务迁移方案及过程记录
阶段时序动作双写数据对比1新rdb集群上线双写数据对比2新服务上线,无流量双写数据对比2后端自己发起的流程比如job,新服务上线一份新的,独立运行双写数据对比2消费二方mq,新服务使用新的消费组消费原有消息双写数据对比3新旧服务比…...

StAX解析
StAX解析 StAX解析介绍 StAX解析与SAX解析类似,也是基于事件驱动的,不同之处在于StAX采用的是拉模式,应用程序通过调用解析器推进解析的进程,可以调用next()方法来获取下一个解析事件(开始文档,结束文档,开…...

[MCU]AUTOSAR COM STACK - CAN协议栈
各层PDU PDU:Protocal Data Unit,协议数据单元,由SDU和PCI组成; I-PDU:Interaction Layer PDU,数据交互层PDU;N-PDU:NetWork Layer PDU,网络层PDU,通常用的…...

React:从 npx开始
使用 npm 来创建第一个 recat 文件( react-demo 是文件名,可以自定义) npx create-react-app react-demo npx是 npm v5.2 版本新添加的命令,用来简化 npm 中工具包的使用 原始: 全局安装npm i -g create-react-app 2 …...
力扣热门100题之接雨水【困难】
题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3…...

Stable-Diffusion-Webui部署SDXL0.9报错参数shape不匹配解决
问题 已经在model/stable-diffusion文件夹下放进去了sdxl0.9的safetensor文件,但是在切换model的时候,会报错model的shape不一致。 解决方法 git pullupdate一些web-ui项目就可以,因为当前项目太老了,没有使用最新的版本。...

Springboot @Async 多线程获取返回值
Springboot Async 多线程获取返回值 需求背景 最近需要用到多线程, 自己维护线程池很麻烦, 正好看到Springboot集成线程池的例子, 这里自己做了个尝试和总结, 记录一下, 也分享给需要的朋友; 不考虑事务的情况下, 这个多线程实现比较简单, 主要有以下几点: 在启动类加上Enab…...

怎样接入chatGPT
官网链接: OpenAI platform...

SparkFun I2C GPIO扩展库:Arduino兼容的PCA/TCA系列驱动
1. SparkFun I2C Expander Arduino 库概述SparkFun I2C Expander Arduino 库是一个专为嵌入式系统设计的轻量级、高兼容性 GPIO 扩展驱动库,面向基于 Arduino 架构(含 ESP32、RP2040、STM32 Core for Arduino 等兼容平台)的硬件开发场景。该库…...

无障碍技术实践:OpenClaw+Phi-3-vision-128k-instruct为视障用户描述图片
无障碍技术实践:OpenClawPhi-3-vision-128k-instruct为视障用户描述图片 1. 项目背景与动机 去年冬天的一次地铁站经历让我萌生了这个想法。当时我看到一位视障朋友在站台反复用盲杖试探前方障碍物,而墙上明明贴着"施工绕行"的警示海报。这个…...

Kuikly动态化跨端框架的多维特性与选型实践
Kuikly,是指基于Kotlin MultiPlatform(KMP)构建的跨端开发框架,利用KMP的逻辑跨平台能力,抽象通用跨平台UI渲染接口,复用平台UI组件,实现UI跨平台,具备轻量、高性能、可动态化优势;其核心特点是…...

Halcon卡尺直线检测避坑指南:参数设置与常见错误排查
Halcon卡尺直线检测避坑指南:参数设置与常见错误排查 在工业视觉检测领域,直线边缘的精准定位是许多项目的基础需求。Halcon作为行业标杆工具,其卡尺直线检测功能看似简单,却暗藏诸多参数陷阱。不少开发者在初次接触时࿰…...

如何将iCloud/iTunes备份恢复到新的iPhone?
刚买了一部新 iPhone,不知道如何恢复所有旧数据?无论您的备份存储在 iTunes 还是 iCloud,都有多种方法可以将备份恢复到新 iPhone。本指南将逐步指导您完成所有可靠的方法,以便您快速将旧设备上的所有内容传输到新设备并从上次中断…...

Claude Code 最佳实践:构建可验证、可治理、可扩展的生产级分布式系统
Claude Code 最佳实践:构建可验证、可治理、可扩展的生产级分布式系统 在很多团队的第一印象里,Claude Code 只是“更强一点的命令行编码助手”。但一旦进入中大型研发场景,你很快会发现,真正决定它价值上限的,不是单次补全能力,而是它是否能够被纳入一套可验证、可治理…...

【AI】Datadog
Datadog是当前全球范围内最主流的商业可观测性平台,是一个将监控、安全与AI分析深度整合的SaaS服务。 作为业界公认的领军者,其核心价值在于提供了一个 “大一统”的中央控制台,帮助企业技术团队全面洞察其整个技术栈的运行状况。在AI快速发展…...
)
从被攻击到防御:一个创业公司的DDoS生存实录(含流量清洗实战)
从被攻击到防御:一个创业公司的DDoS生存实录 凌晨3点15分,我们的电商平台突然陷入瘫痪。客服电话瞬间被打爆,技术团队在睡梦中被紧急召回——这不是系统升级,而是一场蓄谋已久的DDoS攻击。作为技术负责人,我永远记得那…...

新手入门指南:在快马平台上用openclaw重启版本实现首个爬虫项目
最近在学习网络爬虫,发现openclaw重启版本对新手特别友好,于是尝试在InsCode(快马)平台上做了一个简单的新闻头条抓取项目。整个过程比想象中顺利,分享下我的学习路径和踩坑经验。 环境准备与库安装 传统爬虫项目最头疼的就是环境配置&#x…...

如何将数据从小米传输到三星?完整教程
从小米手机换到三星设备似乎很麻烦,尤其是在传输所有重要数据的时候。好在有几种可靠的方法可供选择,包括三星的智能切换功能。但是三星智能切换功能能兼容小米吗? 在本指南中,我们将解答这个问题,并探索如何轻松高效…...