2023年的深度学习入门指南(20) - LLaMA 2模型解析
2023年的深度学习入门指南(20) - LLaMA 2模型解析
上一节我们把LLaMA 2的生成过程以及封装的过程的代码简单介绍了下。还差LLaMA 2的模型部分没有介绍。这一节我们就来介绍下LLaMA 2的模型部分。
这一部分需要一些深度神经网络的基础知识,不懂的话不用着急,后面的文章我们都会介绍到。
均平方根标准化
RMSNorm是一种改进的LayerNorm技术,LayerNorm是Layer normalization,意思是层归一化。。层归一化用于帮助稳定训练并促进模型收敛,因为它具备处理输入和权重矩阵的重新居中和重新缩放的能力。
RMSNorm是2019年的论文《Root Mean Square Layer Normalization》中提出的。它假设LayerNorm中的重新居中性质并不是必需的,于是RMSNorm根据均方根(RMS)对某一层中的神经元输入进行规范化,赋予模型重新缩放的不变性属性和隐式学习率自适应能力。相比LayerNorm,RMSNorm在计算上更简单,因此更加高效。
理解了之后,我们来看下RMSNorm的代码实现。我把注释直接写在代码里。
class RMSNorm(torch.nn.Module):# 类的构造函数,它接受两个参数:dim和eps。dim是希望标准化的特征维度,eps是一个非常小的数,用于防止除以零的错误。def __init__(self, dim: int, eps: float = 1e-6):super().__init__()# 设置类的属性。eps是构造函数传入的参数。self.eps = eps# weight是一个可学习的参数,它是一个由1填充的张量,尺寸为dim。self.weight = nn.Parameter(torch.ones(dim))def _norm(self, x):# 首先,对输入x求平方并计算最后一个维度的平均值,然后加上一个非常小的数self.eps防止出现零,接着对结果开平方根并求倒数,最后将结果与原始输入x相乘。return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x):# 首先,它将输入x转化为浮点数并进行标准化,然后将标准化的结果转化回x的类型。最后,将结果与权重self.weight相乘,得到最终的输出。output = self._norm(x.float()).type_as(x)return output * self.weight
位置编码
我们复习下第3讲曾经介绍过的Transformer结构。
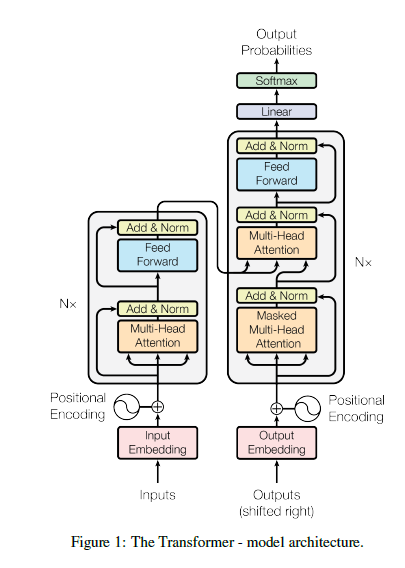
位置编码是Transformer中的一个重要组成部分,它的作用是为输入序列中的每个位置提供一个位置向量,以便Transformer能够区分不同位置的单词。
Transformer中的位置编码是通过将正弦和余弦函数的值作为位置向量的元素来实现的。这些函数的周期是不同的,因此它们的值在不同的位置是不同的。这样,Transformer就可以通过位置编码来区分不同位置的单词。
LLaMA并没有使用正弦函数。
# dim是特征的维度,end应该是预计算的时序位置的数量,theta是一个常数,用于调整频率的尺度
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):# 首先生成一个从0到dim的步长为2的整数序列,然后取前dim // 2个元素,将这些元素转换为浮点类型,然后除以dim# 得到的结果再次被用作theta的指数,最后取其倒数,得到一组频率freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))# 生成一个从0到end的整数序列,这个序列在同一个设备上创建,这个设备是freqs的设备t = torch.arange(end, device=freqs.device) # type: ignore# 计算t和freqs的外积,然后将结果转换为浮点类型freqs = torch.outer(t, freqs).float() # type: ignore# 将freqs从直角坐标系转换为极坐标系# torch.polar(r, theta)的功能是根据极径r和极角theta生成复数,这里的r是freqs的形状的全1张量,theta则是freqs。freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64return freqs_cis
将位置坐标计算出来之后,我们还需要将其变型成与输入的形状一致。
我们来看下是如何实现的:
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):# 获取输入张量x的维度数ndim = x.ndimassert 0 <= 1 < ndimassert freqs_cis.shape == (x.shape[1], x.shape[-1])# 对于每个维度,如果它是第二个维度或最后一个维度,则保留原来的大小;否则,将其设置为 1shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]# 将freqs_cis调整为shape指定的形状,并返回结果return freqs_cis.view(*shape)
然后,将矩阵和位置编码相乘起来:
def apply_rotary_emb(xq: torch.Tensor,xk: torch.Tensor,freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:# 将 xq 和 xk 转换为复数张量,并将它们的形状调整为最后一个维度为 2 的形状xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))# 调用刚刚讲过的 reshape_for_broadcast 函数来将 freqs_cis 调整为与 xq_ 兼容的形状freqs_cis = reshape_for_broadcast(freqs_cis, xq_)# 将xq_和xk_与freqs_cis进行逐元素的复数乘法,然后将得到的结果视为实数,最后将最后两个维度合并为一个维度xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)# 使用 type_as 方法将其转换回与输入相同的数据类型return xq_out.type_as(xq), xk_out.type_as(xk)
LLaMA的注意力机制
解释下面代码:
class Attention(nn.Module):def __init__(self, args: ModelArgs):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_headsmodel_parallel_size = fs_init.get_model_parallel_world_size()self.n_local_heads = args.n_heads // model_parallel_sizeself.n_local_kv_heads = self.n_kv_heads // model_parallel_sizeself.n_rep = self.n_local_heads // self.n_local_kv_headsself.head_dim = args.dim // args.n_headsself.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,bias=False,input_is_parallel=True,init_method=lambda x: x,)self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()
代码虽然多,但是都是实现head和q,k,v,很好理解:
- 初始化时定义了n_kv_heads, n_local_heads等表示head数量的变量。
- wq,wk,wv三个线性层分别用于生成query,key和value。采用ColumnParallelLinear实现分布并行。
- wo线性层对多头attention的输出做融合,采用RowParallelLinear实现分布并行。
- cache_k和cache_v用于缓存key和value,加速自注意力的计算。
- 并行线性层的使用以及caching机制,可以加速自注意力在大batch大小场景下的训练和推理。
- 整体设计实现了高效的分布式并行自注意力计算,可以扩展到大规模多GPU/机器环境,处理长序列任务。
然后,我们将各注意力的子模块集成起来:
def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):bsz, seqlen, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)self.cache_k = self.cache_k.to(xq)self.cache_v = self.cache_v.to(xq)self.cache_k[:bsz, start_pos : start_pos + seqlen] = xkself.cache_v[:bsz, start_pos : start_pos + seqlen] = xvkeys = self.cache_k[:bsz, : start_pos + seqlen]values = self.cache_v[:bsz, : start_pos + seqlen]# repeat k/v heads if n_kv_heads < n_headskeys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)keys = keys.transpose(1, 2)values = values.transpose(1, 2)scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)if mask is not None:scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)scores = F.softmax(scores.float(), dim=-1).type_as(xq)output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)return self.wo(output)
主要流程如下:
- 计算query、key、value的线性映射表示xq、xk、xv
- 对xq和xk应用位置参数
- 将xk、xv写入cache
- 从cache读取key和value,重复其head维度以匹配query的head数
- 计算query和key的点积获得相关度得分
- 对scores加mask并softmax归一化
- 将scores与value做权重和,得到多头自注意力输出
- 将多头输出拼接并线性映射,即是Self-Attention的结果
其中用到了一个函数repeat_kv,它的作用是将key和value的head维度重复n_rep次,以匹配query的head数。
解释下面代码:
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""bs, slen, n_kv_heads, head_dim = x.shapeif n_rep == 1:return xreturn (x[:, :, :, None, :].expand(bs, slen, n_kv_heads, n_rep, head_dim).reshape(bs, slen, n_kv_heads * n_rep, head_dim))
repeat_kv函数使用 expand 方法将输入张量在第四个维度上扩展 n_rep 次,并使用 reshape 方法将其调整为适当的形状。
LLaMA的Transformer结构
核心的自注意力模块实现了之后,我们就可以像搭积木一样,将其组装成Transformer结构了。
首先我们看看全连接网络:
class FeedForward(nn.Module):def __init__(self,dim: int,hidden_dim: int,multiple_of: int,ffn_dim_multiplier: Optional[float],):super().__init__()hidden_dim = int(2 * hidden_dim / 3)# custom dim factor multiplierif ffn_dim_multiplier is not None:hidden_dim = int(ffn_dim_multiplier * hidden_dim)hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)self.w1 = ColumnParallelLinear(dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x)self.w2 = RowParallelLinear(hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x)self.w3 = ColumnParallelLinear(dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x)def forward(self, x):return self.w2(F.silu(self.w1(x)) * self.w3(x))
LLaMA的前馈神经网络主要是立足于并行化。
主要顺序为:
- 初始化时构建了3个线性层w1,w2,w3。其中w1和w3使用ColumnParallelLinear实现分布式并行,w2使用RowParallelLinear。
- forward时,先过w1做第一次线性投影,然后使用SiLU激活函数。
- 跟一个w3对原输入做的线性投影加起来,实现残差连接。
- 最后过w2线性层输出。
这样的结构形成了一个带残差连接的两层前馈网络。它结合并行计算和残差连接,使模型对长序列任务拟合效果更佳。
然后,我们将前馈全连接网络和之前讲的自注意力机制结合起来,构建Transformer块:
class TransformerBlock(nn.Module):def __init__(self, layer_id: int, args: ModelArgs):super().__init__()self.n_heads = args.n_headsself.dim = args.dimself.head_dim = args.dim // args.n_headsself.attention = Attention(args)self.feed_forward = FeedForward(dim=args.dim,hidden_dim=4 * args.dim,multiple_of=args.multiple_of,ffn_dim_multiplier=args.ffn_dim_multiplier,)self.layer_id = layer_idself.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)out = h + self.feed_forward.forward(self.ffn_norm(h))return out
我们来分块讲解一下。
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
首先,从参数对象中获取必要的参数,然后创建一个Attention对象。
self.feed_forward = FeedForward(dim=args.dim,hidden_dim=4 * args.dim,multiple_of=args.multiple_of,ffn_dim_multiplier=args.ffn_dim_multiplier,
)
然后,创建一个FeedForward对象,这个对象实现了前馈神经网络。
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
接着,保存层的ID,并创建两个用于归一化的RMSNorm对象。
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
最后,通过注意力机制和前馈神经网络,计算出输出数据。在注意力机制和前馈神经网络的前后,都使用了归一化操作,这有助于改善模型的训练稳定性。
最终,我们将上面所有的集成在一起,构建出LLaMA的Transformer结构:
class Transformer(nn.Module):def __init__(self, params: ModelArgs):super().__init__()self.params = paramsself.vocab_size = params.vocab_sizeself.n_layers = params.n_layersself.tok_embeddings = ParallelEmbedding(params.vocab_size, params.dim, init_method=lambda x: x)self.layers = torch.nn.ModuleList()for layer_id in range(params.n_layers):self.layers.append(TransformerBlock(layer_id, params))self.norm = RMSNorm(params.dim, eps=params.norm_eps)self.output = ColumnParallelLinear(params.dim, params.vocab_size, bias=False, init_method=lambda x: x)self.freqs_cis = precompute_freqs_cis(self.params.dim // self.params.n_heads, self.params.max_seq_len * 2)@torch.inference_mode()def forward(self, tokens: torch.Tensor, start_pos: int):_bsz, seqlen = tokens.shapeh = self.tok_embeddings(tokens)self.freqs_cis = self.freqs_cis.to(h.device)freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]mask = Noneif seqlen > 1:mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)for layer in self.layers:h = layer(h, start_pos, freqs_cis, mask)h = self.norm(h)output = self.output(h).float()return output
到了大结局阶段,可解释的就不用了。
最终的模块唯一增加的组件就是词嵌入部分:
self.tok_embeddings = ParallelEmbedding(params.vocab_size, params.dim, init_method=lambda x: x)
然后把Transformer块打包在一起:
self.layers = torch.nn.ModuleList()for layer_id in range(params.n_layers):self.layers.append(TransformerBlock(layer_id, params))
加上归一化:
self.norm = RMSNorm(params.dim, eps=params.norm_eps)self.output = ColumnParallelLinear(params.dim, params.vocab_size, bias=False, init_method=lambda x: x)
最后,所有层都走一遍,再来一遍归一化,大功告成:
for layer in self.layers:h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
小结
至此,LLaMA2的主要代码我们就走马观花地学习了一遍。哪怕有些细节还不能理解,起码我们掌握了一个真正的大模型代码的地图。
大家有不理解的地方也不要紧。一方面,后面我们会针对框架的通用技术再进行一些介绍。另一方面,我们还要解析多个其它的开源大模型的源代码。量变引起质变,大家多思考,多试验,就一定能理解大模型的代码。
相关文章:
2023年的深度学习入门指南(20) - LLaMA 2模型解析
2023年的深度学习入门指南(20) - LLaMA 2模型解析 上一节我们把LLaMA 2的生成过程以及封装的过程的代码简单介绍了下。还差LLaMA 2的模型部分没有介绍。这一节我们就来介绍下LLaMA 2的模型部分。 这一部分需要一些深度神经网络的基础知识,不懂的话不用着急…...
智能安全配电装置应用场景有哪些?
安科瑞 华楠 一、应用背景 电力作为一种清洁能源,给人们带来了舒适、便捷的电气化生活。与此同时,由于使用不当,维护不及时等原因引发的漏电触电和电气火灾事故,也给人们的生命和财产带来了巨大的威胁和损失。 为了防止低压配电…...

Rust vs Go:常用语法对比(四)
题图来自 Go vs. Rust performance comparison: The basics 61. Get current date 获取当前时间 package mainimport ( "fmt" "time")func main() { d : time.Now() fmt.Println("Now is", d) // The Playground has a special sandbox, so you …...

c++ 派生类 文本查询程序再探
Query_base类和Query类 //这是一个抽象基类,具体的查询类型从中派生,所有成员都是private的 class Query_base {friend class Query;protected:using line_no TextQuery::line_no;//用于level函数virtual ~Query_base() default;private://eval返回与…...

17. 电话号码的字母组合
题目描述 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits "23" …...

Redis 基础知识和核心概念解析:理解 Redis 的键值操作和过期策略
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...
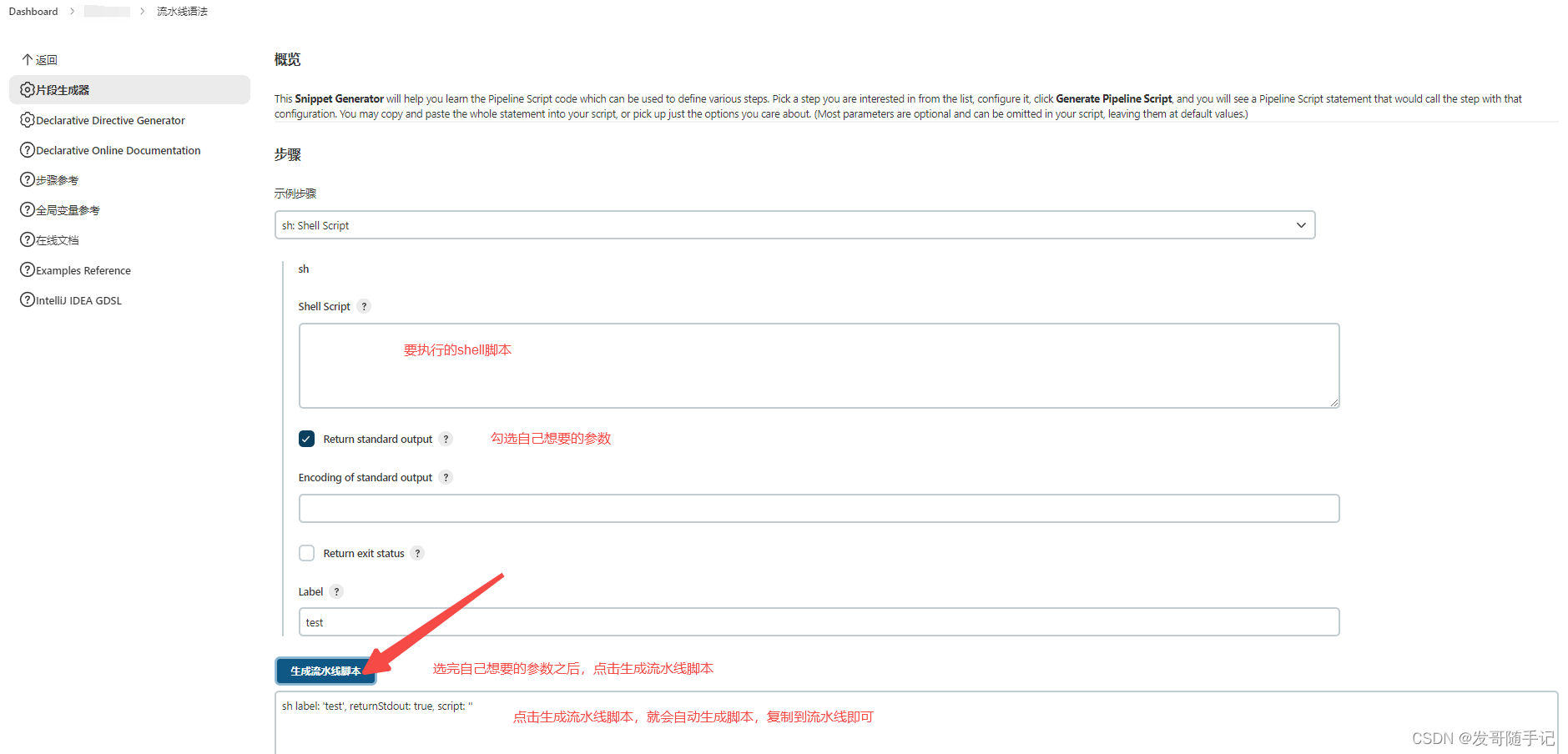
Jenkins中sh函数的用法
在Jenkins的Pipeline中,sh函数的用法 用法一 单个命令字符串包括使用,示例如下: sh echo "Hello, Jenkins!"用法二 多个命令字符串包括命令列表使用,示例如下: sh echo "Step 1" echo "…...
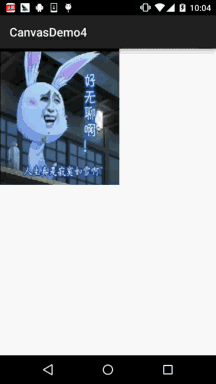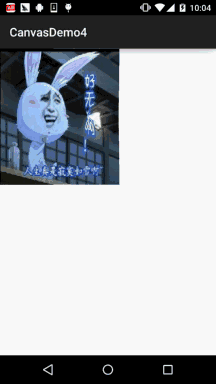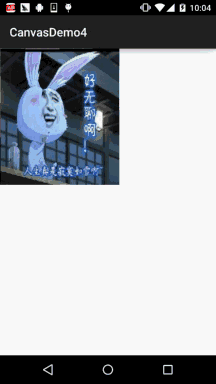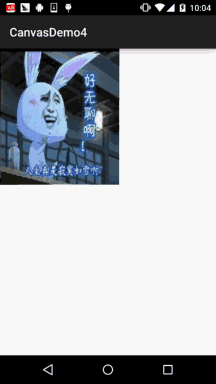
Android 之 Canvas API 详解 (Part 3) Matrix 和 drawBitmapMesh
本节引言: 在Canvas的API文档中,我们看到这样一个方法:drawBitmap(Bitmap bitmap, Matrix matrix, Paint paint) 这个Matrix可是有大文章的,前面我们在学Paint的API中的ColorFilter中曾讲过ColorMatrix 颜色矩阵,一个4…...
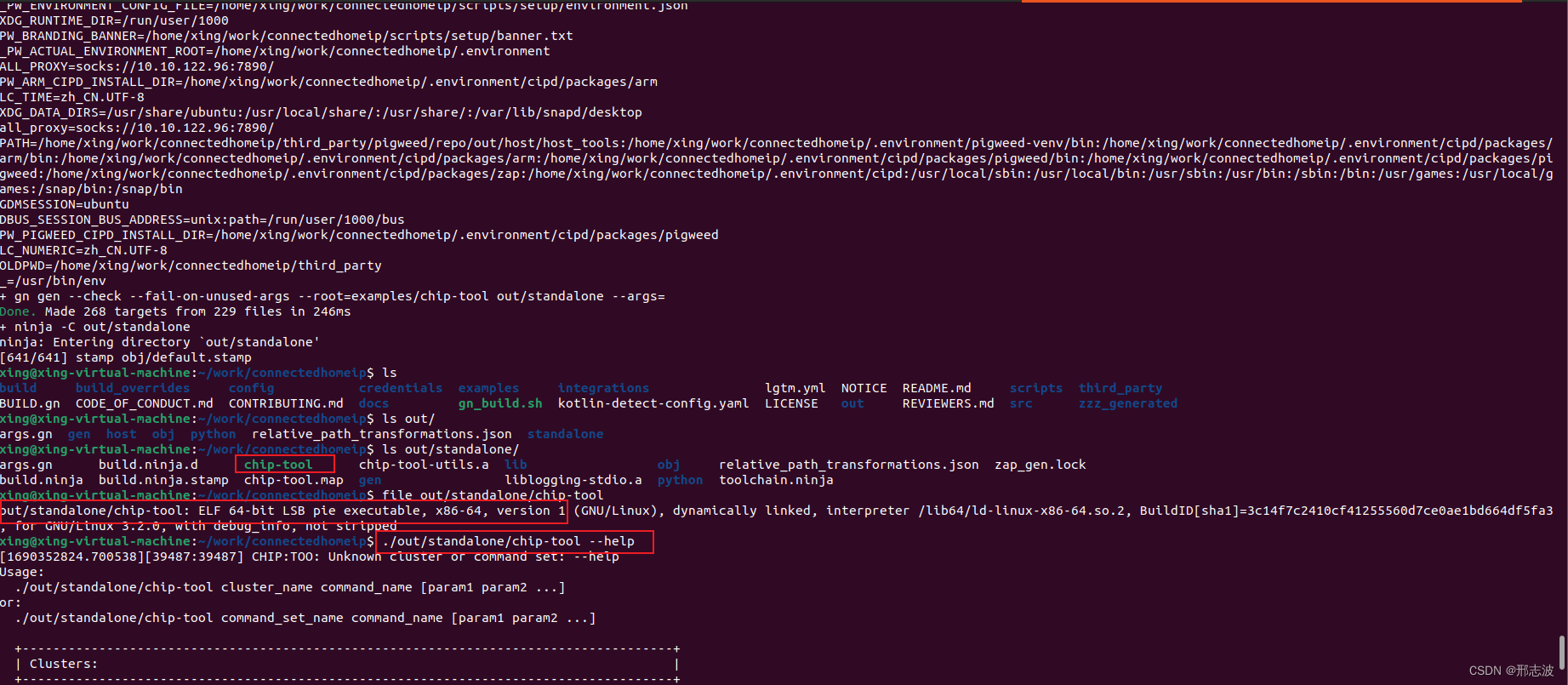
基于Ubuntu 22.04 编译chip-tool工具
前言 编译过程有点曲折,做下记录,过程中,有参考别人写的博客,也看github 官方介绍,终于跑通了~ 环境说明: 首先需要稳定的梯子,可以访问“外网”ubuntu 环境,最终成功实验在Ubunt…...

opencv-17 脸部打码及解码
使用掩模和按位运算方式实现的对脸部打码、解码实例 代码如下: import cv2 import numpy as np #读取原始载体图像 lenacv2.imread("lena.png",0) #读取原始载体图像的 shape 值 r,clena.shape masknp.zeros((r,c),dtypenp.uint8) mask[220:400,250:350…...

JVM分享
JVM分享 官网:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html Java代码的执行流程 我们编写完之后的java文件如果要运行,java文件会编译成class文件,在jvm中运行时ClassLoader会加载class文件,加载进来之后&a…...
Apache Dubbo CVE-2021-36162 挖掘过程
01 漏洞背景 发现该漏洞的起因是在分析 CVE-2021-30181 的脚本注入补丁的时候,意外发现了几个已被修复的 yaml 反序列化漏洞,还以为是未公开的Nday,查询后发现其实对应的是 CVE-2021-30180 漏洞的修复代码。通过查看补丁可以知道,…...

开源框架面试题目整理
目录 SpringIOC SpringAOP Spring的生命周期 Spring Bean作用域 Spring Bean作用域并发安全 Spring循环依赖...
Mr. Cappuccino的第52杯咖啡——Mybatis环境搭建与使用
Mybatis环境搭建与使用 Mybatis介绍Mybatis环境搭建与使用基于XML方式-原生方式开发创建数据库表项目准备项目结构项目代码实体类中添加有参构造方法产生的问题 基于XML方式-mapper代理开发项目准备项目结构项目代码SQL映射文件中namespace未设置为接口全限定名产生的问题 基于…...
了解Unity编辑器之组件篇Tilemap(五)
Tilemap:用于创建和编辑2D网格地图的工具。Tilemap的主要作用是简化2D游戏中地图的创建、编辑和渲染过程。以下是一些Tilemap的主要用途: 2D地图绘制:Tilemap提供了一个可视化的编辑器界面,可以快速绘制2D地图,例如迷…...

Linux字符设备操作函数
Linux字符设备操作函数是指对字符设备进行打开、关闭、读取、写入、控制等基本操作的函数,它们通过字符设备结构体中的 file_operations 结构体来定义。常用的字符设备操作函数包括: 1、open: 当一个进程试图打开设备文件时,调用这个函数。开…...

吉林大学计算机软件考研经验贴
文章目录 简介政治英语数学专业课 简介 本人23考研,一战上岸吉林大学软件工程专硕,政治72分,英一71分,数二144分,专业课967综合146分,总分433分,上图: 如果学弟学妹需要专业课资料…...

2023-07-26力扣每日一题-区间翻转线段树
链接: 2569. 更新数组后处理求和查询 题意: 给两个等长数组nums1和nums2,三个操作: 操作1:将nums1的[l,r]翻转(0变1,1变0) 操作2:将nums2[any]变成nums2[any]nums1[any]*p&…...

Java设计模式之 -- 桥接模式
什么是桥接模式 桥接模式是一种结构型设计模式,也被称为“Handle/Body”。这种设计模式主要用于将抽象部分与它的实现部分分离,使它们可以独立地变化。这种方式有助于减少系统中的耦合性,增加了扩展性。 主要解决什么问题 桥接模式主要解决…...

【node.js】02-path模块
目录 1. path.join() 2. path.basename() 3. path.extname() 1. path.join() 使用 path.join() 方法,可以把多个路径片段拼接为完整的路径字符串,语法格式如下: path.join([...paths]) 例子: const path require(path)co…...

告别‘电音’:用WaveRNN和FFTNet给你的AI语音合成项目选个又快又好的声码器
神经声码器选型实战:从WaveRNN到FFTNet的高效语音合成方案 语音合成技术正在经历一场由深度学习驱动的革命,而声码器(Vocoder)作为将频谱特征转换为自然波形的关键组件,其性能直接影响着合成语音的质量和效率。面对市…...

B站成分检测器深度解析:5大革新特性重塑评论区交互体验
B站成分检测器深度解析:5大革新特性重塑评论区交互体验 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分油猴脚本,主要为原神玩家识别 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-comment-checker 在B站的海量评论互…...

ESP32开发板选型指南:从Arduino到NodeMCU,哪款更适合你的项目?
ESP32开发板选型指南:从Arduino到NodeMCU,哪款更适合你的项目? 在物联网和嵌入式开发领域,ESP32系列开发板凭借其出色的性价比和丰富的功能,已经成为众多开发者的首选。面对市场上琳琅满目的ESP32开发板型号࿰…...

Navicat连接PostgreSQL常见问题排查指南
1. Navicat连接PostgreSQL的典型问题场景 第一次用Navicat连PostgreSQL的朋友,八成会遇到这个报错画面——输入完账号密码点连接,结果弹个红叉提示"无法连接到服务器"。这种情况我见得太多了,特别是连接远程服务器或者虚拟机里的数…...

2026年4月OpenClaw怎么安装?阿里云高效方法:搭建及大模型API、Skill集成流程
2026年4月OpenClaw怎么安装?阿里云高效方法:搭建及大模型API、Skill集成流程。OpenClaw作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊、个人工作流中自…...

TMSpeech:完全免费开源的Windows实时语音转文字工具终极指南
TMSpeech:完全免费开源的Windows实时语音转文字工具终极指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录而烦恼吗?TMSpeech是一款完全免费、开源的Windows实时语音转文字工…...

3个维度解析Helix Toolkit:跨平台3D渲染框架的技术突破与商业价值
3个维度解析Helix Toolkit:跨平台3D渲染框架的技术突破与商业价值 【免费下载链接】helix-toolkit Helix Toolkit is a collection of 3D components for .NET. 项目地址: https://gitcode.com/gh_mirrors/he/helix-toolkit Helix Toolkit是一套功能完备的.N…...

Qwen3-TTS-Tokenizer-12Hz优化技巧:如何提升语音压缩与重建速度?
Qwen3-TTS-Tokenizer-12Hz优化技巧:如何提升语音压缩与重建速度? 1. 理解Qwen3-TTS-Tokenizer-12Hz的核心优势 1.1 超低采样率带来的效率革命 Qwen3-TTS-Tokenizer-12Hz最显著的特点是12Hz的超低采样率。这意味着: 传统音频处理通常使用1…...

Whisper-large-v3语音识别Web服务灾备方案:双机热备与自动故障转移配置
Whisper-large-v3语音识别Web服务灾备方案:双机热备与自动故障转移配置 1. 引言:为什么语音识别服务需要高可用? 想象一下,你正在使用一个语音转文字服务处理重要的会议录音,突然服务中断了,所有上传的音…...
FD-LLM:将振动信号编码为文本表示来将振动信号与大型语言模型进行对齐)
(论文速读)FD-LLM:将振动信号编码为文本表示来将振动信号与大型语言模型进行对齐
论文题目:Large language models for explainable fault diagnosis of machines(用于机器可解释故障诊断的大型语言模型)期刊:Engineering Applications of Artificial Intelligence(EAAI)摘要:…...