【计算机网络】socket编程基础
文章目录
- 1. 源IP地址和目的IP地址
- 2. 理解MAC地址和目的MAC地址
- 3. 理解源端口号和目的端口号
- 4. PORT与PID
- 5. 认识TCP协议和UDP协议
- 6. 网络字节序
- 7. socket编程接口
- 7.1 socket常见API
- 7.2 sockaddr结构
1. 源IP地址和目的IP地址
因特网上的每台计算机都有一个唯一的IP地址,如果一台主机上的数据要传输到另一台主机,那么对端主机的IP地址就应该作为该数据传输时的目的IP地址。但仅仅知道目的IP地址是不够的,当对端主机收到数据后,对端还需要对该主机作出相应,因此对端主机也需要发送数据给该主机,此时对端主机就需要知道该主机的IP地址。因此一个传输的数据中应该涵盖其IP地址和目的IP地址,目的IP地址表明该数据传输的目的,源IP地址作为对端主机相应时的目的IP地址。
在数据传输之前,会先自顶向下贯穿网络贯穿数据协议栈完成数据的封装,其中在网络层封装的IP报头当中就涵盖了就涵盖了源IP地址和目的IP地址。
2. 理解MAC地址和目的MAC地址
大部分数据的传输都是跨局域网的,数据在传输过程中会经过若干个路由器,最终才能到达对端主机。
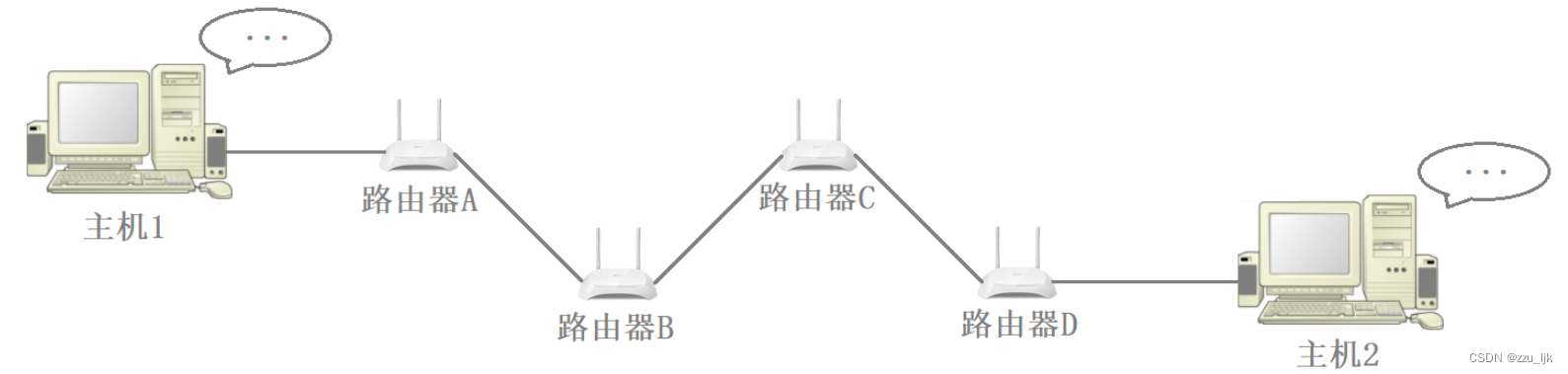
源MAC地址和目的MAC地址是包含在链路层的报头当中的,而MAC地址实际只在当前局域网内有效。因此当数据跨网络到达另一个局域网时,也就是数据到达路由器时,路由器会将该数据当中链路层的报头去掉,然后再封装一个报头,此时该数据的源MAC地址和目的MAC地址就发生了变化。
因此数据在传输的过程中是有两套地址:
- 一套是源IP地址和目的IP地址,这两个地址在数据传输过程中基本是不会发生变化的(存在一些特殊情况,比如使用了NET技术,其源IP地址会发生变化,但是目的IP地址不会发生变化)
- 另一套就是源MAC地址和目的MAC地址,这两个地址是会发生变化的,因为在数据传输的过程中会路由器会进行解包和重新封装。
3. 理解源端口号和目的端口号
套接字通信的本质
首先我们需要理解的是,两个主机之间进行通信,不仅仅是为了将数据发给对端主机,而是为了访问对端主机上的某个服务。比如我们在使用百度搜索引擎时,我们不仅仅将我们的请求发给对端服务器,而是想访问对端服务器上部署的百度相关的搜索服务。
我们可以通过IP地址和MAC地址将数据发给对端主机,但实际上我们是要发给对端数据上的某个进程,此外,数据的发送者也不是主机,而是主机上的某个进程。比如,当我们用浏览器访问网站时,实际也就是浏览器进程向对端服务器进程发起请求。
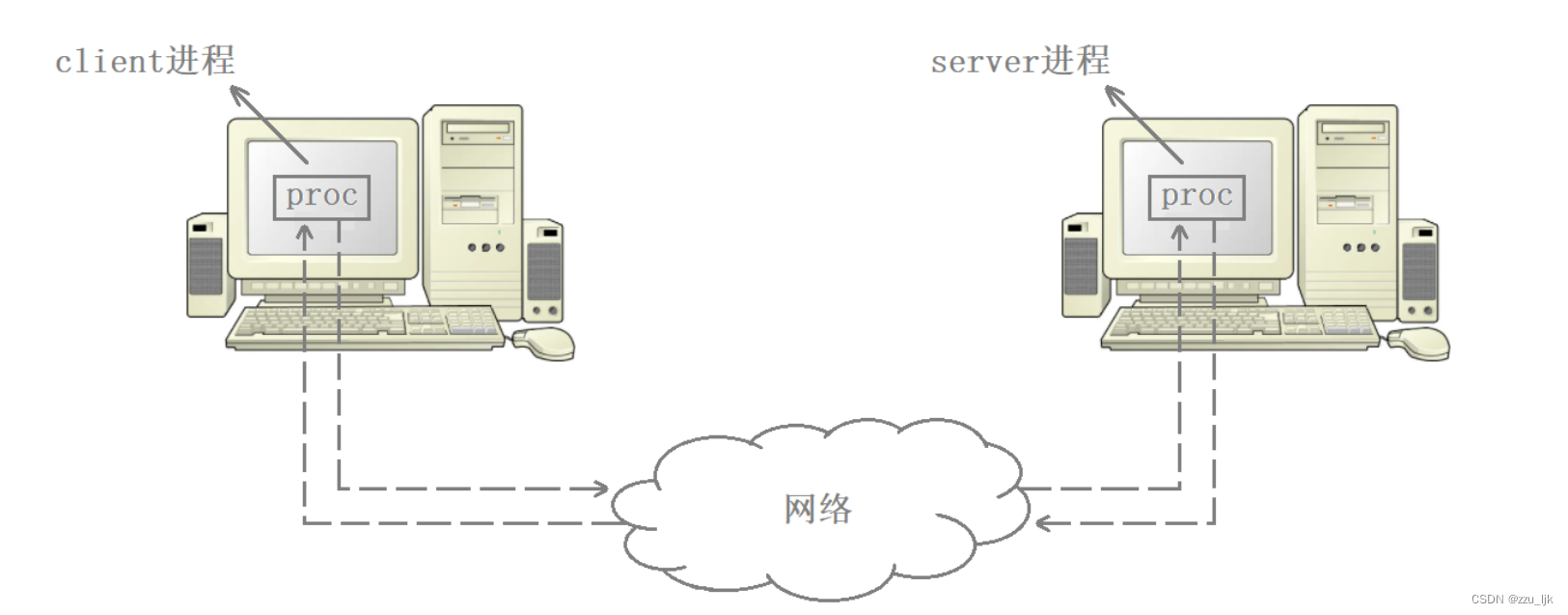
也就是说,套接字通信的本质就是两个进程之间在进行通信,只不过这里是跨网络的进程间通信。比如我们刷抖音的时候,其实就是我们手机上的抖音进程在于对端服务器主机上的抖音服务器进程在进行通信。
因此进程间通信的方式除了管道,共享内存,消息队列,信号量之外,还有套接字,只不过套接字是跨网络的。
认识端口号
实际在两台主机上,可能会存在许多进行网络通信的进程,当数据发送到该主机之后,需要将数据交给指定的进程。而当进程处理完数据之后还要对发送端进行相应,因此对端主机也需要知道是发送端上哪一个进程向它发起请求。
端口号(port)的作用就是标识一台主机上的一个进程。
- 端口号是传输层协议的内容
- 端口号是一个2字节16位的整数
- 端口号用来表示一个进程,告诉操作系统,当前这个数据要交给哪个进程处理
- 一个端口号只能被一个进程占有
由于IP地址可以标识公网内的某一台主机,而端口号又可以标识主机上的某一个进程,因此用IP地址+端口号就可以标识网络上某一台主机的某一进程了。
当数据在传输层进行封装时,就会添加上对应源端口号和目的端口号的信息,在网络层又会添加上对应源IP地址和目的IP地址,这样一来,通过源端口号和源IP地址就能在网络上标识发送数据的进程,通过目的端口号和目的ID地址就可以在网络上标识接收数据的进程,这就实现了跨网络的进程间通信。
注意:因为端口号是属于某台主机的,所以端口号可以在两台不同的主机当中重复,但是在同一台主机上进行网络通信的端口号不能重复。此外,一个进程可以绑定多个端口号,但是一个端口号只能被一个进程绑定。
理解“套接字”这个名字
套接字源自于单词socket,套接字编程实际上就是socket编程。socket在英文上也有插座的意思,在进行网络通信的时候,客户端就相当于接口,服务端就相当于一个插座,但服务端上可能会有许多不同的服务进程(多个插孔),因此当我们在访问服务时需要指明服务进程端口号(对应规则的插孔),才能得到对应服务进程的服务。
而套接字,我们也可以姑且理解为一套用于连接的文字。
4. PORT与PID
端口号(port)的作用是表示主机上的某个进程,进程PID的作用也是表示主机上的某个进程,那为什么在进行网络通信的时候不直接使用PID来代替port呢?
进程PID是用来表示系统内进程的唯一性的,属于系统级别的概念。而端口号是在网络通信时标识进程的唯一性的,属于网络级别的概念。
每个人都有自己的身份证号,但是为了方便管理,到了学习会有学号,到了公司会有工号。网络通信使用port同理。
且在网络中使用port,在系统中使用PID,可以使网络和系统很好地解耦。
底层是如何通过port找到进程的? 实际底层采用哈希的方式建立了端口号和进程PID或PCB之间的映射关系,当底层拿到端口号时就可以直接执行对应的哈希算法,然后就能找到该端口号对应的进程。
5. 认识TCP协议和UDP协议
当我们使用系统调用接口实现网络数据通信时,不得不面对的协议层就是传输层,而传输层最经典的两种协议就是TCP协议和UDP协议。
TCP协议
TCP协议叫做传输控制协议(Transmission Control Protocol),TCP是一种面向连接的,可靠的,基于字节流的传输层控制协议。
TCP是面向连接的,如果两台主机之间要进行数据传输,必须先建立连接,在连接建立完成之后才可以进行数据传输。其次,TCP是保证可靠的协议,数据在传输过程中如果出现了丢包、乱序等情况,TCP都有对应的解决方案。
UDP协议
UDP协议叫做用户数据报协议(User Datagram Protocol),UDP是一种无需建立连接的、不可靠的、面向数据报的传输层通信协议。
使用UDP协议进行通信时无需建立连接,如果两台主机之间想要进行数据传输,那么直接将数据发给对端主机就行了,但这也就意味着UDP协议是不可靠的,数据在传输过程中如果出现了丢包、乱序等情况,UDP协议本身是不知道的。
既然UDP协议是不可靠的,那为什么还要有UDP协议的存在?
TCP协议是一种可靠的传输协议,使用TCP协议可以保证数据传输时的可靠性,而UDP协议是一种不可靠的传输协议,它的存在有什么意义呢?
首先,可靠是需要我们更多的工作的,TCP协议虽然是一种可靠的传输协议,但这意味着TCP协议在底层一定要做更多的工作,因此TCP协议底层的实现是比较复杂的,我们不能只看到TCP协议面向连接这个优点。还要看到TCP协议对应的缺点。
同样的,UDP协议虽然是一种不可靠的传输协议,但这一定意味着UDP协议在底层不需要做过多的工作,因此UDP协议底层的实现一定比TCP协议要简单的多,UDP协议虽然不可靠,但是它能把数据快速地发给对方,虽然数据在传输的过程中可能会出错。
编写网络通信代码时具体采用TCP协议还是UDP协议,完全取决于上层的应用场景。如果应用场景严格要求数据在传输过程中的可靠性,我们就必须采用TCP协议,如果应用场景允许数据在传输出现少量丢包,那么我们肯定优先选择UDP协议,因为UDP协议足够简单。
一些网站在设计网络通信算法时,会同时采用TCP协议和UDP协议,当网络流畅时就使用UDP协议进行数据传输,当网络不好时就使用TCP协议进行数据传输,此时就可以动态地调整后台通信算法。
6. 网络字节序
网络中的大小端问题
计算机在存储数据时是有大小端的概念的:
- 大端模式:数据的高字节内容保存在内存的低地址处,数据的低字节内容保存在内存的高地址处。
- 小端模式:数据的高字节内容保存在内存的高地址处,数据的低字节内容保存在内存的低地址处。
如果编写的程序只在本地机器上运行,那么是不需要考虑大小端问题的,因为同一台机器上采用的存储方式都是一样的,要么采用大端存储模式,要么采用小端存储模式。但如果设计网络通信,那就必须考虑大小端的问题,否则对端主机识别出来的数据可能与发送端想要发送的数据是不一致的。
例如,现在两台主机在进行网络通信,其中发送端是小端机,而接收端是大端机。发送端将发送缓冲区内的数据按内存地址从低到高的顺序发出后,接收端从网络中获取数据一次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存的。
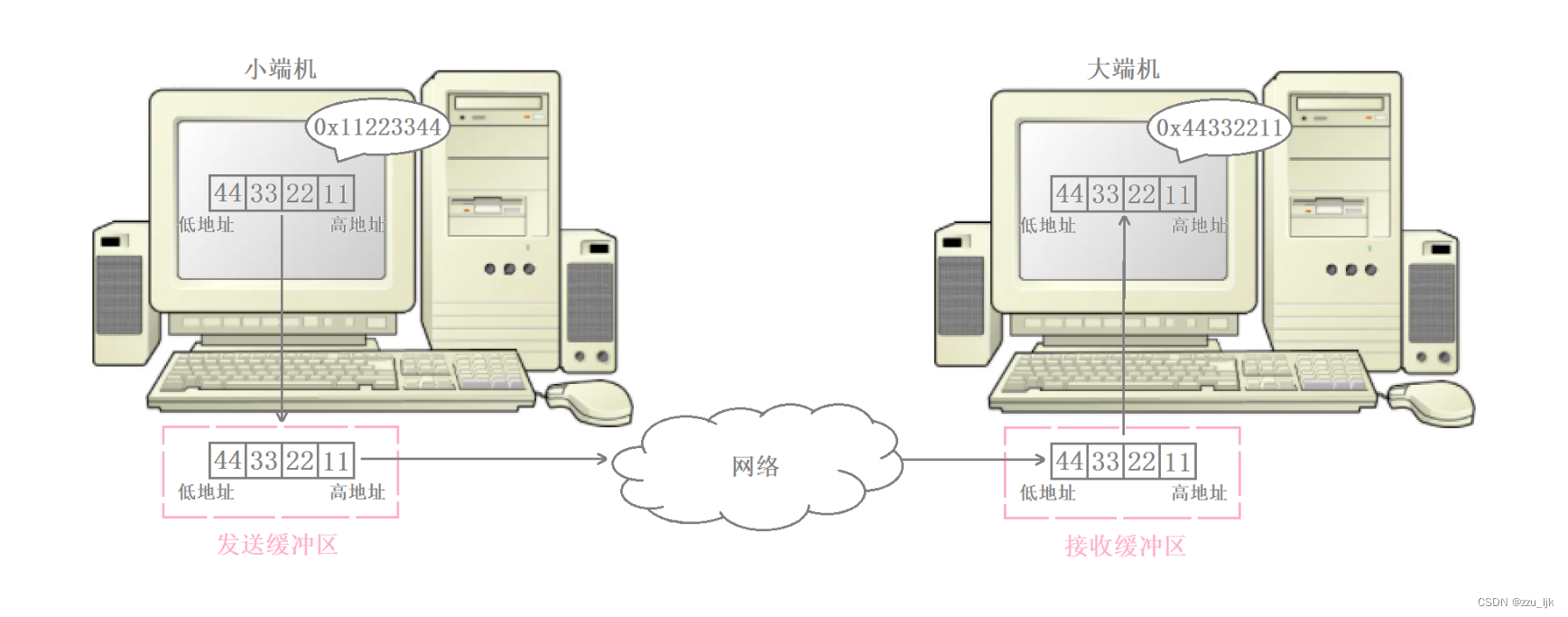
但由于发送端和接收端采用的分别是小端存储和大端存储,此时对于内存地址从低到高为 44332211 的序列,发送端按小端的方式识别出来的是 0x11223344,但是接收端按大端的方式识别的是 0x44332211,此时接收端接收到的数据就与发送端原本想要发送的数据就不一样了,这就是由于大小端的偏差导致数据识别出现了错误。
由于我们不能保证通信双方存储数据的方式是一样的,因此网络当中传输的数据必须考虑大小端问题。因此TCP/IP协议规定,网络数据流采用大端字节序,即低地址高字节。无论是大端机还是小端机,都必须按照TCP/IP协议当中规定的网络字节序来发送和接收数据。
- 如果发送端是小端,需要先将数据转成大端,然后再发送到网络当中
- 如果发送端是大端,则可以直接进行发送
- 如果接收端是小端,需要先将数据转换成小端后再进行数据识别
- 如果接收端是大端,则可以直接进行数据识别。
主机字节序和网络字节序直接的转换接口
为了使网络程序具有可移植性,使同样的C代码在大端和小端机器上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序直之间的转换:
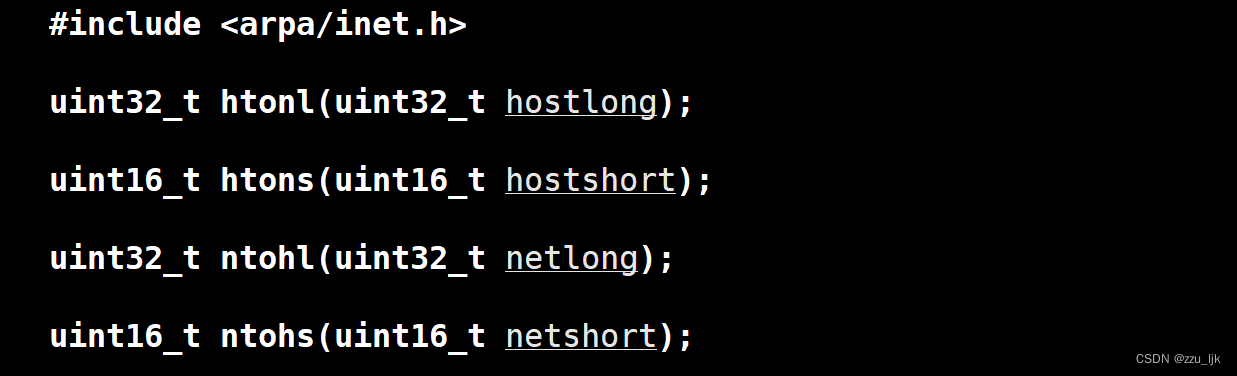
- 函数名中的h表示host,n表示network,l表示32位长整数,s表示16位短整数
- 例如htonl表示将32位长整数从主机字节序转换为网络字节序
- 如果主机是小端字节序,则这些函数将参数做相应的大小端转换然后返回
- 如果主机是大端字节序,则这些函数不做任何转换,将参数原封不动地返回
7. socket编程接口
7.1 socket常见API
创建套接字:(TCP/UDP,客户端+服务端)

绑定端口号:(TCP/UDP,服务器)

监听套接字:(TCP,服务器)
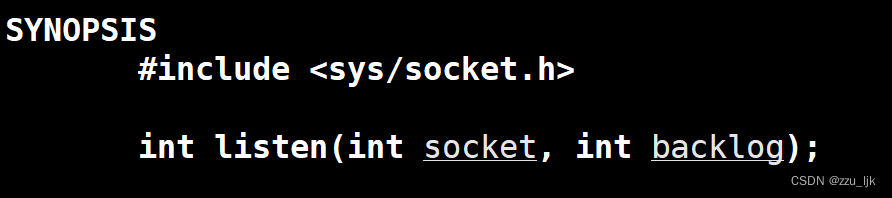
接收请求:(TCP,服务器)

建立连接:(TCP,客户端)

7.2 sockaddr结构
sockaddr结构的出现
套接字不仅支持跨网络的进程间通信,还支持本地的进程间通信(域间套接字)。在进行跨网络通信时我们需要传递的端口号和IP地址,而本地通信则不需要,因此套接字提供了sockaddr_in结构体和sockaddr_un结构体,其中sockaddr_in结构体是用于跨网络通信的,而sockaddr_un结构体是用于本地通信的。
为了让套接字的网络通信和本地通信能够使用同一套函数接口,于是就出现了sockaddr结构体,该结构体与sockaddr_in结构体和sockaddr_un的结构都不相同,但这三个结构体头部的16个比特位都是一样的,这个字段叫做协议家族。
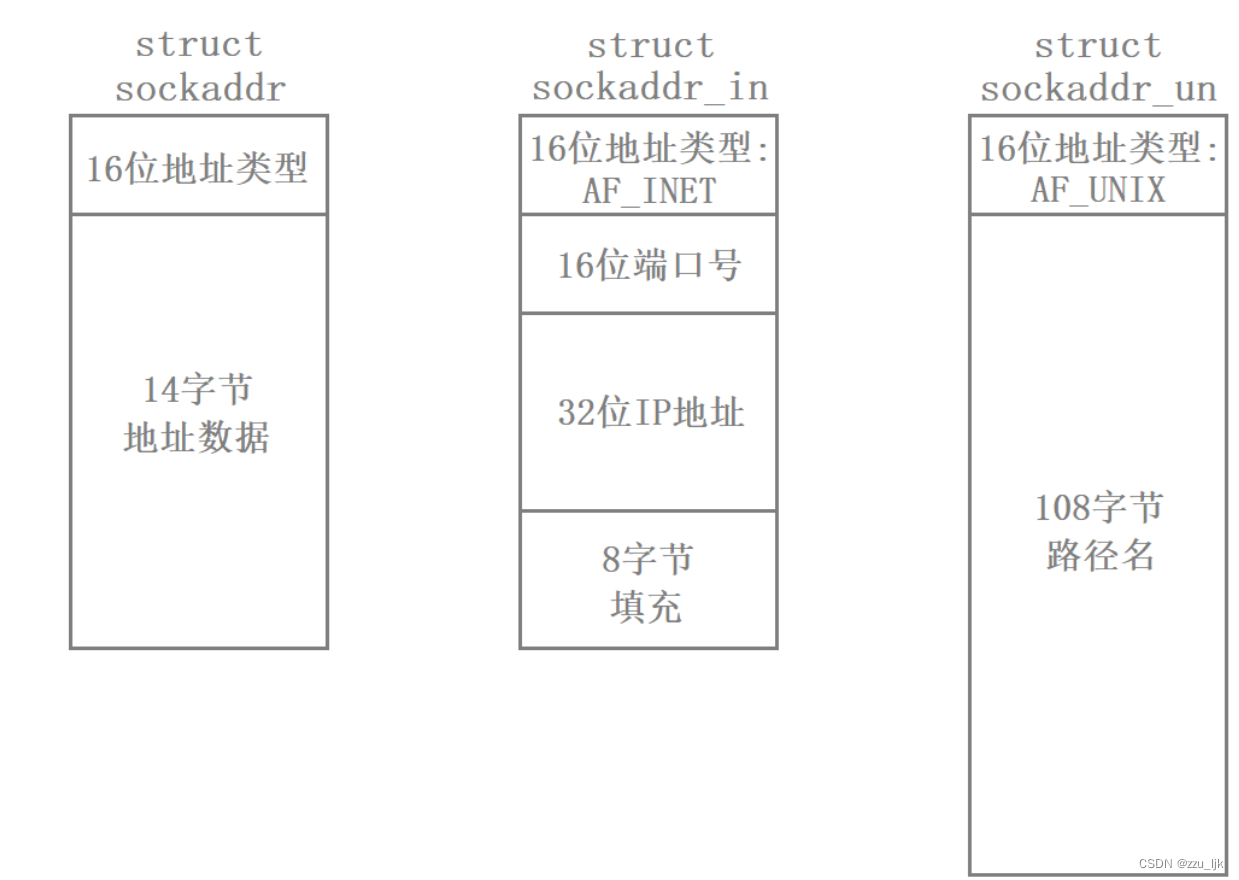
此时当我们在传参时,就不用传入sockaddr_in或者sockaddr_un这样的结构体,而统一传入sockaddr这样的结构体。在设置参数时就可以通过设置协议家族这个字段,来表明我们是要进行网络通信还是本地通信,在这些API内部就可以提取sockaddr结构体的16位头部进行识别,进而得出我们是要进行网络通信还是本地通信,然后执行对应的操作。这样我们通过sockaddr结构,就将套接字网络通信和本地通信的参数类型实现了统一。
注意:实际我们在进行网络通信的时候,定义的还是sockaddr_in这样的结构体,只不过在传参时需要将该结构体的地址类型进行强转为==sockaddr*==罢了。
为什么不用 void* 代替 struct sockaddr* 类型呢
我们可以将这些函数接口形参的struct sockaddr参数改为void,此时在函数背部也可以直接提取头部的16个比特位进行识别,最终也能够判断是需要进行网络通信还是本地通信,那为什么还要设计出sockaddr这样的结构呢?
实际在设计这一套网络接口的时候C语言还不支持void* ,于是就设计出了sockaddr这样的解决方案。
相关文章:
【计算机网络】socket编程基础
文章目录 1. 源IP地址和目的IP地址2. 理解MAC地址和目的MAC地址3. 理解源端口号和目的端口号4. PORT与PID5. 认识TCP协议和UDP协议6. 网络字节序7. socket编程接口7.1 socket常见API7.2 sockaddr结构 1. 源IP地址和目的IP地址 因特网上的每台计算机都有一个唯一的IP地址&#…...
学C的第三十天【自定义类型:结构体、枚举、联合】
相关代码gitee自取:C语言学习日记: 加油努力 (gitee.com) 接上期: 学C的第二十九天【字符串函数和内存函数的介绍(二)】_高高的胖子的博客-CSDN博客 1 . 结构体 (1). 结构体的基础知识: 结构…...
:通过noVNC实现网页访问vnc)
Ubuntu(20.04):通过noVNC实现网页访问vnc
VNC vnc是日常工作和生产环境中常用的远程桌面控制工具。 通常需要在被访问的系统中安装vncserver。 然后在发起访问端,安装客户端软件,比如VNC Viewer。 noVNC noVNC提供了一种方案,就是通过web浏览器直接访问vnc server。 其实现的基本原理是: 1.已经安装好的vncse…...

OpenAI的Function calling 和 LangChain的Search Agent
OpenAI的Function calling openai最近发布的gpt-3.5-turbo-0613 和 gpt-4-0613版本模型增加了function calling的功能,该功能通过定义功能函数,gpt通过分析问题和函数功能描述来决定是否调用函数,并且生成函数对应的入参。函数调用的功能可以…...

【mysql数据库】MySQL7在Centos7的环境安装
说明: 安装与卸载中,用户全部切换成为root,⼀旦安装,普通用户就能使用。初期练习,mysql不进行用户管理,全部使⽤root进⾏,尽快适应mysql语句,后⾯学了用户管理,在考虑新…...

基于vue+element 分页的封装
目录标题 项目场景:认识分页1.current-page2.page-sizes3.page-size4.layout5.total6.size-change7.current-change 封装分页:创建paging:进行封装 页面中使用:引入效果 项目场景: 分页也是我们在实际应用当中非常常见…...

面试题模拟
C# 装箱和拆箱是什么? 装箱是指用堆空间来存放值类型数据 拆箱是指将存放在堆空间的值类型数据转换到栈空间 值和引用类型在变量赋值时的区别是什么? 值类型的数据赋值的时候是指向同一块内存区域,当前一个改变的时候后一个也会跟着改变。 引…...
Linux6.13 Docker LNMP项目搭建
文章目录 计算机系统5G云计算第四章 LINUX Docker LNMP项目搭建一、项目环境1.环境描述2.容器ip地址规划3.任务需求 二、部署过程1.部署构建 nginx 镜像2.部署构建 mysql 镜像3.部署构建 php 镜像4.验证测试 计算机系统 5G云计算 第四章 LINUX Docker LNMP项目搭建 一、项目…...

数据包协议栈处理
看了两个不错的帖子,记录一下。 4.2 TCP Segmentation Offload(TSO)_Remy的学习记录-CSDN博客_tcp-segmentation-offload Linux内核参数之rp_filter - 萝卜1992 - 博客园...

html刷新图片
文章目录 前言网页整体刷新改变图像的url 备注 前言 海思3516的一个开发板,不断的采集图像编码为jpeg,保存为同一个文件。打算用网页实现查看视频的效果,需要前端能够自动刷新。 目前找到了两个方法,一个是网页的不断刷新&#…...

PHP反序列化漏洞之魔术方法
一、魔术方法 PHP魔术方法(Magic Methods)是一组特殊的方法,它们在特定的情况下会被自动调用,用于实现对象的特殊行为或提供额外功能。这些方法的名称都以双下划线开头和结尾,例如: __construct()、__toString()等。 …...
2023年的深度学习入门指南(20) - LLaMA 2模型解析
2023年的深度学习入门指南(20) - LLaMA 2模型解析 上一节我们把LLaMA 2的生成过程以及封装的过程的代码简单介绍了下。还差LLaMA 2的模型部分没有介绍。这一节我们就来介绍下LLaMA 2的模型部分。 这一部分需要一些深度神经网络的基础知识,不懂的话不用着急…...
智能安全配电装置应用场景有哪些?
安科瑞 华楠 一、应用背景 电力作为一种清洁能源,给人们带来了舒适、便捷的电气化生活。与此同时,由于使用不当,维护不及时等原因引发的漏电触电和电气火灾事故,也给人们的生命和财产带来了巨大的威胁和损失。 为了防止低压配电…...

Rust vs Go:常用语法对比(四)
题图来自 Go vs. Rust performance comparison: The basics 61. Get current date 获取当前时间 package mainimport ( "fmt" "time")func main() { d : time.Now() fmt.Println("Now is", d) // The Playground has a special sandbox, so you …...

c++ 派生类 文本查询程序再探
Query_base类和Query类 //这是一个抽象基类,具体的查询类型从中派生,所有成员都是private的 class Query_base {friend class Query;protected:using line_no TextQuery::line_no;//用于level函数virtual ~Query_base() default;private://eval返回与…...

17. 电话号码的字母组合
题目描述 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits "23" …...

Redis 基础知识和核心概念解析:理解 Redis 的键值操作和过期策略
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...
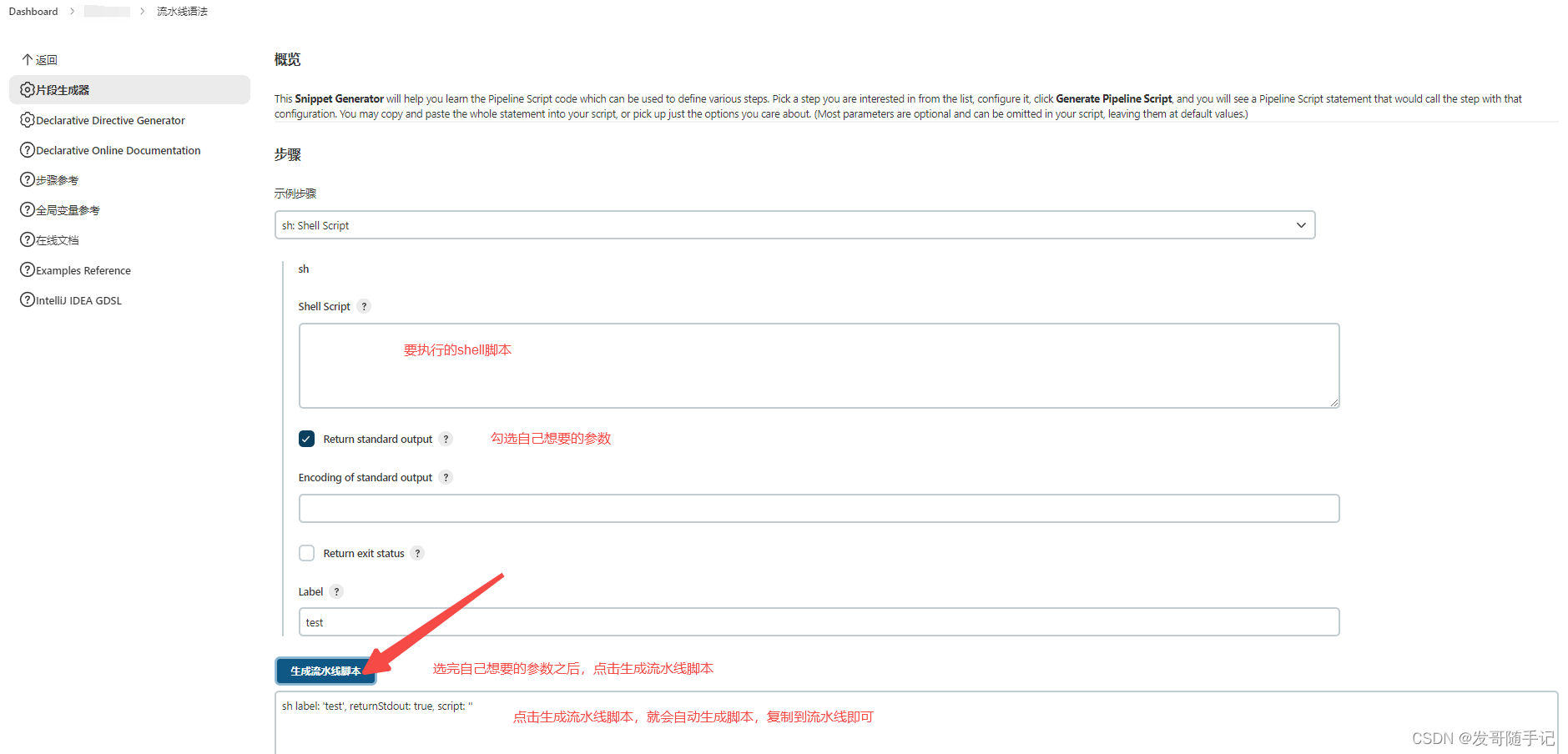
Jenkins中sh函数的用法
在Jenkins的Pipeline中,sh函数的用法 用法一 单个命令字符串包括使用,示例如下: sh echo "Hello, Jenkins!"用法二 多个命令字符串包括命令列表使用,示例如下: sh echo "Step 1" echo "…...
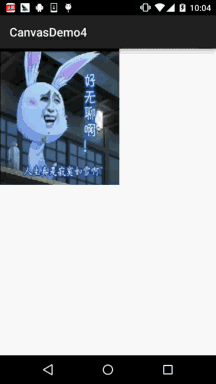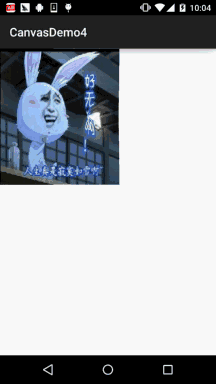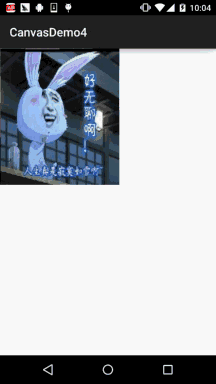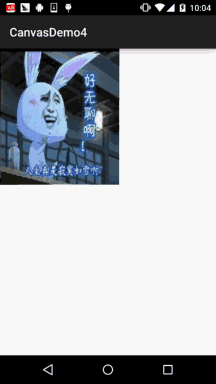
Android 之 Canvas API 详解 (Part 3) Matrix 和 drawBitmapMesh
本节引言: 在Canvas的API文档中,我们看到这样一个方法:drawBitmap(Bitmap bitmap, Matrix matrix, Paint paint) 这个Matrix可是有大文章的,前面我们在学Paint的API中的ColorFilter中曾讲过ColorMatrix 颜色矩阵,一个4…...
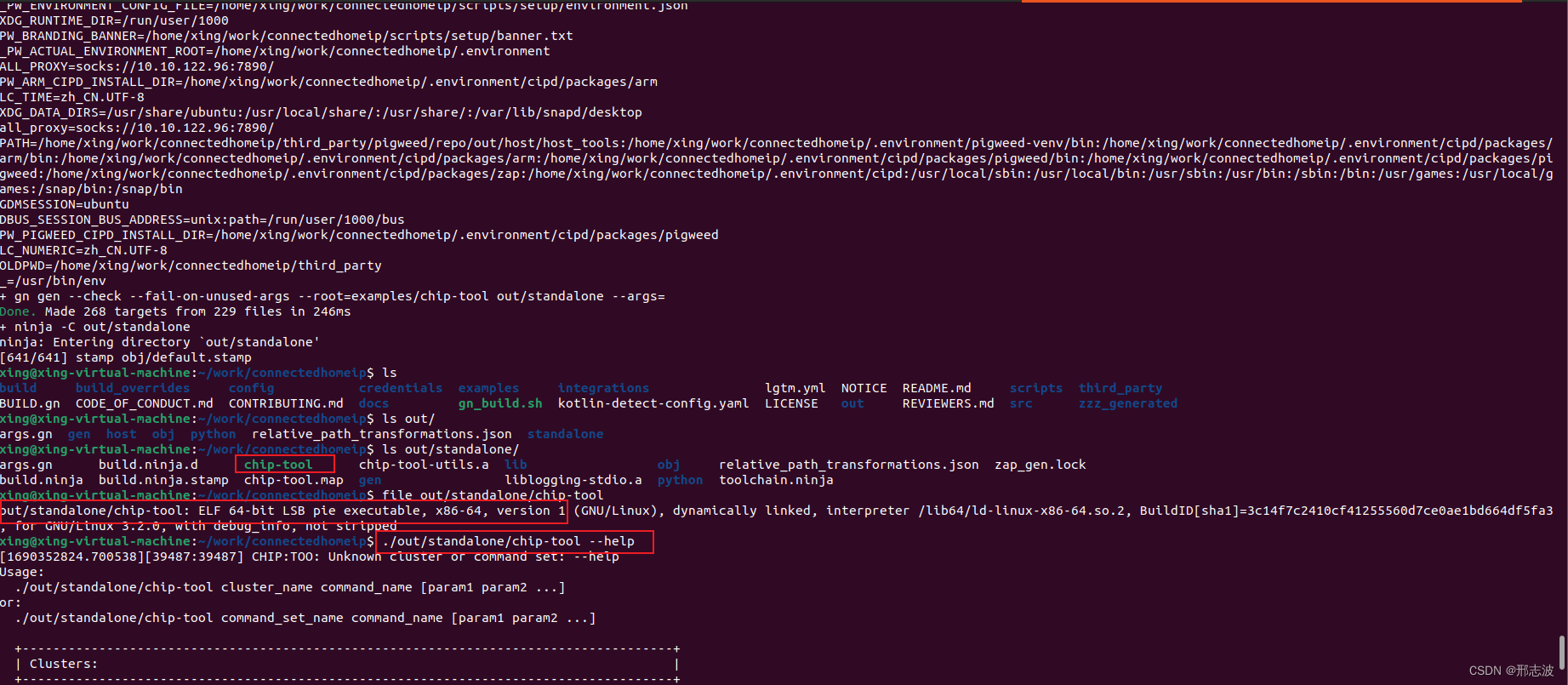
基于Ubuntu 22.04 编译chip-tool工具
前言 编译过程有点曲折,做下记录,过程中,有参考别人写的博客,也看github 官方介绍,终于跑通了~ 环境说明: 首先需要稳定的梯子,可以访问“外网”ubuntu 环境,最终成功实验在Ubunt…...

实战指南:基于快马平台生成vscode电商后台管理项目脚手架
最近在做一个电商后台管理系统的前端项目,正好尝试了用InsCode(快马)平台来生成项目脚手架,整个过程比我预想的要顺畅很多。作为一个经常用VSCode开发的前端工程师,这次体验让我发现原来项目初始化可以这么高效。下面分享下具体实现过程和几点…...

Python CGI编程:从历史原理到现代启示
1. CGI技术的前世今生 我第一次接触CGI是在2005年维护一个老旧的图书管理系统时。那时候Apache服务器上跑着一堆Perl脚本,每次修改都要小心翼翼地处理文件权限和环境变量。这种看似"古老"的技术,其实正是现代Web开发的基石。 CGI全称Common Ga…...

2026降AI降重工具实测:高效过审首选方案推荐
2026年学术写作辅助工具的选择核心看四个维度:降重精准度、去AI痕迹效果、格式保留能力、学科适配性。经过多场景实测,SpeedAI科研小助手、飞降AI、超能降AI、快降AI、思笔AI是当前覆盖全需求的第一梯队工具,能满足从专科到硕博、从中文到英文…...

攻克高并发场景:基于快马平台生成黑马点评秒杀与缓存实战代码
今天想和大家分享一个实战项目经验——如何用InsCode(快马)平台快速搭建高并发场景下的黑马点评系统核心模块。这个项目最吸引我的地方在于,它完美复现了电商系统中那些让人头疼的高并发场景,比如秒杀、缓存一致性等问题。 秒杀功能的核心逻辑 优惠券秒…...

Selenoid源码深度剖析:理解容器化测试平台的实现原理
Selenoid源码深度剖析:理解容器化测试平台的实现原理 【免费下载链接】selenoid Selenium Hub successor running browsers within containers. Scalable, immutable, self hosted Selenium-Grid on any platform with single binary. 项目地址: https://gitcode.…...

新手避坑指南:当npm报错128时,如何用快马AI轻松完成第一个项目
最近在帮朋友入门Node.js开发时,发现很多新手卡在环境配置这一步就放弃了。特别是遇到npm error code 128这种报错时,往往连错误说明都看不懂。今天分享一个用InsCode(快马)平台快速搭建第一个Node.js项目的避坑指南,特别适合零基础开发者。 …...

SR8201F以太网PHY断连问题排查:从电源到MDIO时序的实战记录
SR8201F以太网PHY断连问题深度排查:从硬件设计到时序优化的完整解决方案 1. 问题现象与初步分析 最近在调试基于SR8201F的以太网接口时,遇到了一个棘手的问题:设备在冷启动约75分钟后首次出现断连,随后断连频率逐渐增加。这种周期…...
)
自我即自感:一种极简存在论(四篇)
第一篇:自我即自感:一种极简存在论我们早已知道我们总是知道“我是我”。这不是谁告诉我们的,也不是推理出来的。从最原初的体验开始,我们就已经知道:正在感受的这个,就是我。这个“知道”不是反思。你不必…...

qmc-decoder:QMC加密音乐格式转换工具的全方位应用指南
qmc-decoder:QMC加密音乐格式转换工具的全方位应用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 一、问题引入:当音乐文件被"锁住"…...

突破式百度网盘直链解析工具:革新性高速下载解决方案
突破式百度网盘直链解析工具:革新性高速下载解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字化资源爆炸的时代,百度网盘作为国内领先的云…...