NLP(六十二)HuggingFace中的Datasets使用
Datasets库是HuggingFace生态系统中一个重要的数据集库,可用于轻松地访问和共享数据集,这些数据集是关于音频、计算机视觉、以及自然语言处理等领域。Datasets 库可以通过一行来加载一个数据集,并且可以使用 Hugging Face 强大的数据处理方法来快速准备好你的数据集。在 Apache Arrow 格式的支持下,通过 zero-copy read 来处理大型数据集,而没有任何内存限制,从而实现最佳速度和效率。
当需要微调模型的时候,需要对数据集进行以下操作:
- 数据集加载:下载、加载数据集
- 数据集预处理:使用Dataset.map() 预处理数据
- 数据集评估指标:加载和计算指标
可以在HuggingFace官网来搜共享索数据集:https://huggingface.co/datasets 。本文中使用的主要数据集为squad数据集,其在HuggingFace网站上的数据前几行如下:

加载数据
- 加载Dataset数据集
Dataset数据集可以是HuggingFace Datasets网站上的数据集或者是本地路径对应的数据集,也可以同时加载多个数据集。
以下是加载英语阅读理解数据集squad, 该数据集的网址为:https://huggingface.co/datasets/squad ,也是本文中使用的主要数据集。
import datasets# 加载单个数据集
raw_datasets = datasets.load_dataset('squad')
# 加载多个数据集
raw_datasets = datasets.load_dataset('glue', 'mrpc')
- 从文件中加载数据
支持csv, tsv, txt, json, jsonl等格式的文件
from datasets import load_datasetdata_files = {"train": "./data/sougou_mini/train.csv", "test": "./data/sougou_mini/test.csv"}
drug_dataset = load_dataset("csv", data_files=data_files, delimiter=",")
- 从Dataframe中加载数据
import pandas as pd
from datasets import Dataset my_dict = {"a": [1, 2, 3], "b": ['A', 'B', 'C']}
dataset1 = Dataset.from_dict(my_dict) df = pd.DataFrame(my_dict)
dataset2 = Dataset.from_pandas(df)
查看数据
- 数据结构
数据结构包括:
- 数据集的划分:train,valid,test数据集
- 数据集的数量
- 数据集的feature
squad数据的数据结构如下:
DatasetDict({train: Dataset({features: ['id', 'title', 'context', 'question', 'answers'],num_rows: 87599})validation: Dataset({features: ['id', 'title', 'context', 'question', 'answers'],num_rows: 10570})
})
- 数据切分
import datasetsraw_dataset = datasets.load_dataset('squad')# 获取某个划分数据集,比如train
train_dataset = raw_dataset['train']
# 获取前10条数据
head_dataset = train_dataset.select(range(10))
# 获取随机10条数据
shuffle_dataset = train_dataset.shuffle(seed=42).select(range(10))
# 数据切片
slice_dataset = train_dataset[10:20]
更多特性
- 数据打乱(shuffle)
shuffle的功能是打乱datasets中的数据,其中seed是设置打乱的参数,如果设置打乱的seed是相同的,那我们就可以得到一个完全相同的打乱结果,这样用相同的打乱结果才能重复的进行模型试验。
import datasetsraw_dataset = datasets.load_dataset('squad')
# 打乱数据集
shuffle_dataset = train_dataset.shuffle(seed=42)
- 数据流(stream)
stream的功能是将数据集进行流式化,可以不用在下载整个数据集的情况下使用该数据集。这在以下场景中特别有用:
- 你不想等待整个庞大的数据集下载完毕
- 数据集大小超过了你计算机的可用硬盘空间
- 你想快速探索数据集的少数样本
from datasets import load_datasetdataset = load_dataset('oscar-corpus/OSCAR-2201', 'en', split='train', streaming=True)
print(next(iter(dataset)))
- 数据列重命名(rename columns)
数据集支持对列重命名。下面的代码将squad数据集中的context列重命名为text:
from datasets import load_datasetsquad = load_dataset('squad')
squad = squad.rename_column('context', 'text')
- 数据丢弃列(drop columns)
数据集支持对列进行丢弃,在删除一个或多个列时,向remove_columns()函数提供要删除的列名。单个列删除传入列名,多个列删除传入列名的列表。下面的代码将squad数据集中的id列丢弃:
from datasets import load_datasetsquad = load_dataset('squad')
# 删除一个列
squad = squad.remove_columns('id')
# 删除多个列
squad = squad.remove_columns(['title', 'text'])
- 数据新增列(add new columns)
数据集支持新增列。下面的代码在squad数据集上新增一列test,内容全为字符串111:
from datasets import load_datasetsquad = load_dataset('squad')
# 新增列
new_train_squad = squad['train'].add_column("test", ['111'] * squad['train'].num_rows)
- 数据类型转换(cast)
cast()函数对一个或多个列的特征类型进行转换。这个函数接受你的新特征作为其参数。
from datasets import load_datasetsquad = load_dataset('squad')
# 新增列
new_train_squad = squad['train'].add_column("test", ['111'] * squad['train'].num_rows)
print(new_train_squad.features)
# 转换test列的数据类型
new_features = new_train_squad.features.copy()
new_features["test"] = Value("int64")
new_train_squad = new_train_squad.cast(new_features)
# 输出转换后的数据类型
print(new_train_squad.features)
- 数据展平(flatten)
针对嵌套结构的数据类型,可使用flatten()函数将子字段提取到它们自己的独立列中。
from datasets import load_datasetsquad = load_dataset('squad')
flatten_dataset = squad['train'].flatten()
print(flatten_dataset)
输出结果为:
Dataset({features: ['id', 'title', 'context', 'question', 'answers.text', 'answers.answer_start'],num_rows: 87599
})
- 数据合并(Concatenate Multiple Datasets)
如果独立的数据集有相同的列类型,那么它们可以被串联起来。用concatenate_datasets()来连接不同的数据集。
from datasets import concatenate_datasets, load_datasetsquad = load_dataset('squad')
squad_v2 = load_dataset('squad_v2')
# 合并数据集
squad_all = concatenate_datasets([squad['train'], squad_v2['train']])
- 数据过滤(filter)
filter()函数支持对数据集进行过滤,一般采用lambda函数实现。下面的代码对squad数据集中的训练集的question字段,过滤掉split后长度小于等于10的数据:
from datasets import load_datasetsquad = load_dataset('squad')
filter_dataset = squad['train'].filter(lambda x: len(x["question"].split()) > 10)
输出结果如下:
Dataset({features: ['id', 'title', 'context', 'question', 'answers'],num_rows: 34261
})
- 数据排序(sort)
使用sort()对列值根据其数值进行排序。下面的代码是对squad数据集中的训练集按照标题长度进行排序:
from datasets import load_datasetsquad = load_dataset('squad')
# 新增列, title_length, 标题长度
new_train_squad = squad['train'].add_column("title_length", [len(_) for _ in squad['train']['title']])
# 按照title_length排序
new_train_squad = new_train_squad.sort("title_length")
- 数据格式(set_format)
set_format()函数改变了一个列的格式,使之与一些常见的数据格式兼容。在类型参数中指定你想要的输出和你想要格式化的列。格式化是即时应用的。支持的数据格式有:None, numpy, torch, tensorflow, pandas, arrow, 如果选择None,就会返回python对象。
下面的代码将新增标题长度列,并将其转化为numpy格式:
from datasets import load_datasetsquad = load_dataset('squad')
# 新增列, title_length, 标题长度
new_train_squad = squad['train'].add_column("title_length", [len(_) for _ in squad['train']['title']])
# 转换为numpy支持的数据格式
new_train_squad.set_format(type="numpy", columns=["title_length"])
- 数据指标(load metrics)
HuggingFace Hub上提供了一系列的评估指标(metrics),前20个指标如下:
from datasets import list_metrics
metrics_list = list_metrics()
print(', '.join(metric for metric in metrics_list[:20]))
输出结果如下:
accuracy, bertscore, bleu, bleurt, brier_score, cer, character, charcut_mt, chrf, code_eval, comet, competition_math, coval, cuad, exact_match, f1, frugalscore, glue, google_bleu, indic_glue
从Hub中加载一个指标,使用 datasets.load_metric() 命令,比如加载squad数据集的指标:
from datasets import load_metric
metric = load_metric('squad')
输出结果如下:
Metric(name: "squad", features: {'predictions': {'id': Value(dtype='string', id=None), 'prediction_text': Value(dtype='string', id=None)}, 'references': {'id': Value(dtype='string', id=None), 'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None)}}, usage: """
Computes SQuAD scores (F1 and EM).
Args:predictions: List of question-answers dictionaries with the following key-values:- 'id': id of the question-answer pair as given in the references (see below)- 'prediction_text': the text of the answerreferences: List of question-answers dictionaries with the following key-values:- 'id': id of the question-answer pair (see above),- 'answers': a Dict in the SQuAD dataset format{'text': list of possible texts for the answer, as a list of strings'answer_start': list of start positions for the answer, as a list of ints}Note that answer_start values are not taken into account to compute the metric.
Returns:'exact_match': Exact match (the normalized answer exactly match the gold answer)'f1': The F-score of predicted tokens versus the gold answer
Examples:>>> predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]>>> references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]>>> squad_metric = datasets.load_metric("squad")>>> results = squad_metric.compute(predictions=predictions, references=references)>>> print(results){'exact_match': 100.0, 'f1': 100.0}
""", stored examples: 0)
load_metric还支持分布式计算,本文不再详细讲述。
load_metric现在已经是老版本了,新版本将用evaluate模块代替,访问网址为:https://github.com/huggingface/evaluate 。
- 数据映射(map)
map就是映射,它接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset。常见的map函数的应用是对文本进行tokenize:
from datasets import load_dataset
from transformers import AutoTokenizersquad_dataset = load_dataset('squad')checkpoint = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)def tokenize_function(sample):return tokenizer(sample['context'], truncation=True, max_length=256)tokenized_dataset = squad_dataset.map(tokenize_function, batched=True)
输出结果如下:
DatasetDict({train: Dataset({features: ['id', 'title', 'context', 'question', 'answers', 'input_ids', 'token_type_ids', 'attention_mask'],num_rows: 87599})validation: Dataset({features: ['id', 'title', 'context', 'question', 'answers', 'input_ids', 'token_type_ids', 'attention_mask'],num_rows: 10570})
})
- 数据保存/加载(save to disk/ load from disk)
使用save_to_disk()来保存数据集,方便在以后重新使用它,使用 load_from_disk()函数重新加载数据集。我们将上面map后的tokenized_dataset数据集进行保存:
tokenized_dataset.save_to_disk("squad_tokenized")
保存后的文件结构如下:
squad_tokenized/
├── dataset_dict.json
├── train
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
└── validation├── data-00000-of-00001.arrow├── dataset_info.json└── state.json
加载数据的代码如下:
from datasets import load_from_disk
reloaded_dataset = load_from_disk("squad_tokenized")
总结
本文可作为dataset库的入门,详细介绍了数据集的各种操作,这样方便后续进行模型训练。
参考文献
- Datasets: https://www.huaxiaozhuan.com/工具/huggingface_transformer/chapters/2_datasets.html
- Huggingface详细入门介绍之dataset库:https://zhuanlan.zhihu.com/p/554678463
- Stream: https://huggingface.co/docs/datasets/stream
- HuggingFace教程 Datasets基本操作: Process: https://zhuanlan.zhihu.com/p/557032513
相关文章:
NLP(六十二)HuggingFace中的Datasets使用
Datasets库是HuggingFace生态系统中一个重要的数据集库,可用于轻松地访问和共享数据集,这些数据集是关于音频、计算机视觉、以及自然语言处理等领域。Datasets 库可以通过一行来加载一个数据集,并且可以使用 Hugging Face 强大的数据处理方法…...
Windows下基于VSCode搭建C++开发环境(包含整合MinGW64、CMake的详细流程)
最近想写写C,装了VisualStudio 2022,折腾半天。对于一个用惯VSCode的人来说,总感觉IDE太笨重。于是自己网上各种查资料,自己琢磨,搭建了一套Windows下基于VSCode和CMake的C轻量级开发环境。 具体搭建步骤 1. 下载并安…...
springboot+mybatis-plus+vue+element+vant2实现短视频网站,模拟西瓜视频移动端
目录 一、前言 二、管理后台 1.登录 2.登录成功,进入欢迎页 编辑 3.视频分类管理 4. 视频标签管理 5.视频管理 6.评论管理 编辑 7.用户管理 8.字典管理 (类似于后端的枚举) 9.参数管理(富文本录入) 10.管…...

MySQL学习-第二部分
文章目录 MySQL数据库学习1 表1.1 表中的数据类型1.2 表的创建1.3 表的删除1.4 default设置字段默认值1.5 表结构的修改1.5.1 表名的修改1.5.2 字段名的修改1.5.3 修改字段类型1.5.4 添加字段1.5.5 删除字段1.5.6 表的复制 1.6 表的约束1.6.1 什么是约束?1.6.2 not …...

TortoiseGit 入门指南17:使用子模块
如果你想在自己的代码仓库中嵌入其它仓库,这称为引入子模块(Submodule)。使用右键菜单TortoiseGit - Submodules Add 选项,弹出添加子模块对话框,可以将一个外部仓库嵌入到源代码树的专用子目录中。 Repository&#x…...
谷粒商城篇章5 ---- P173-P192 ---- 检索服务【分布式高级篇二】
目录 1 检索服务 1.1 搭建页面环境 1.1.1 引入依赖 1.1.2 将检索页面放到gulimall-search的src/main/resources/templates/目录下 1.1.3 调整搜索页面 1.1.4 将静态资源放到linux的nginx相关映射目录下/root/docker/nginx/html/static/ search/ 1.1.5 SwitchHosts配置域…...

N位分频器的实现
N位分频器的实现 一、 目的 使用verilog实现n位的分频器,可以是偶数,也可以是奇数 二、 原理 FPGA中n位分频器的工作原理可以简要概括为: 分频器的作用是将输入时钟频率分频,输出低于输入时钟频率的时钟信号。n位分频器可以将输入时钟频率分频2^n倍…...

华为OD真题--分苹果-带答案
有A,B两个同学想要分苹果。A的想法是使用二进制进行,1 1相加不进一位,如(9 5 1001 101 12)。B同学的想法是使用十进制进行,并且进一位。会输入两组数据,一组是苹果总数,一组分别…...
【前端实习评审】对小说详情模块更新的后端接口压力流程进行了人群优化
大家好,本篇文章分享一下【校招VIP】免费商业项目“推推”第一期书籍详情模块 前端同学的开发文档周最佳作品。该同学来自安徽科技学院土木工程专业。本项目亮点难点: 1.热门书籍在更新点的访问压力; 2.书籍更新通知的及时性和有效性…...
)
Factorization Machines(论文笔记)
样例一: 一个简单的例子,train是一个字典,先将train进行“one-hot” coding,然后输入相关特征向量,可以预测相关性。 from pyfm import pylibfm from sklearn.feature_extraction import DictVectorizer import numpy as np tra…...
——使用QTimer定时触发槽函数)
Qt开发(5)——使用QTimer定时触发槽函数
实现效果 软件启动之后,开始计时,到达预定时间后,调用其他类的某个函数。 类的分工 BaseType:软件初始化的调用类 FuncType: 功能函数所在类 具体函数 // FuncType.h class FuncType: public QObject {Q_OBJECT public: publ…...
2023年JAVA最新面试题
2023年JAVA最新面试题 1 JavaWeb基础1.1 HashMap的底层实现原理?1.2 HashMap 和 HashTable的异同?1.5 Collection 和 Collections的区别?1.6 Collection接口的两种区别1.7 ArrayList、LinkedList、Vector者的异同?1.8 String、Str…...
(四)RabbitMQ高级特性(消费端限流、利用限流实现不公平分发、消息存活时间、优先级队列
Lison <dreamlison163.com>, v1.0.0, 2023.06.23 RabbitMQ高级特性(消费端限流、利用限流实现不公平分发、消息存活时间、优先级队列 文章目录 RabbitMQ高级特性(消费端限流、利用限流实现不公平分发、消息存活时间、优先级队列消费端限流利用限流…...
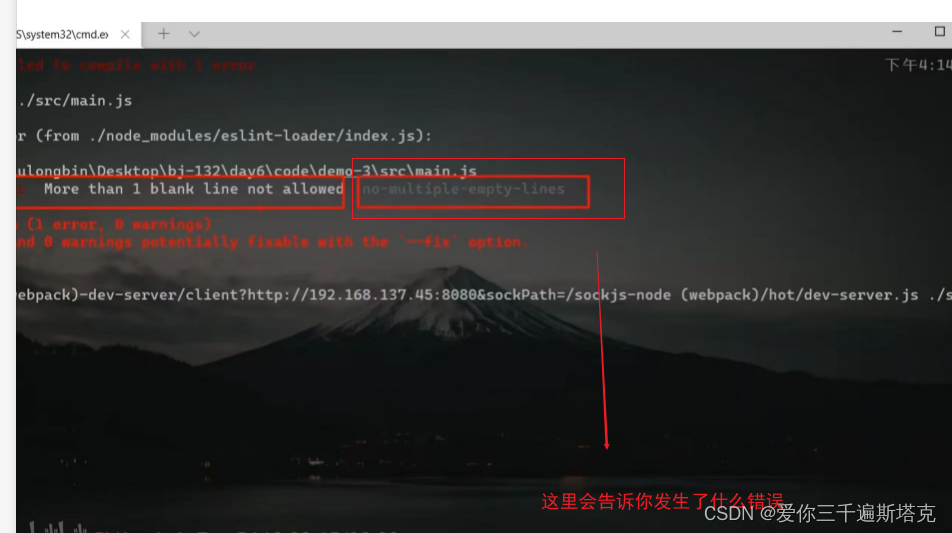
Vue如何配置eslint
eslint官网: eslint.bootcss.com eslicate如何配置 1、选择新的配置: 2、选择三个必选项 3、再选择Css预处理器 4、之后选择处理器 5、选择是提交的时候就进行保存模式 6、放到独立的配置文件上去 7、最后一句是将自己的数据存为预设 8、配合console不要出现的规则…...

Elasticsearch查询文档
GET查询索引单个文档 GET /索引/_doc/ID GET /ffbf/_doc/123返回结果如下,查到了有数据"found" : true表示 {"_index" : "ffbf","_type" : "_doc","_id" : "123","_version" : 2...

面向对象编程:多态性的理论与实践
文章目录 1. 修饰词和访问权限2. 多态的概念3. 多态的使用现象4. 多态的问题与解决5. 多态的意义 在面向对象编程中,多态是一个重要的概念,它允许不同的对象以不同的方式响应相同的消息。本文将深入探讨多态的概念及其应用,以及在Java中如何实…...

linux:filezilla root密码登陆
问题: 如题 参考: 亚马逊服务器FileZilla登录失败解决办法_亚马逊云 ssh链接秘钥认证不了 ubuntu拒绝root用户ssh远程登录解决办法 总结: vi /etc/ssh/sshd_config,修改配置: PermitRootLogin yes PasswordAuthenticat…...
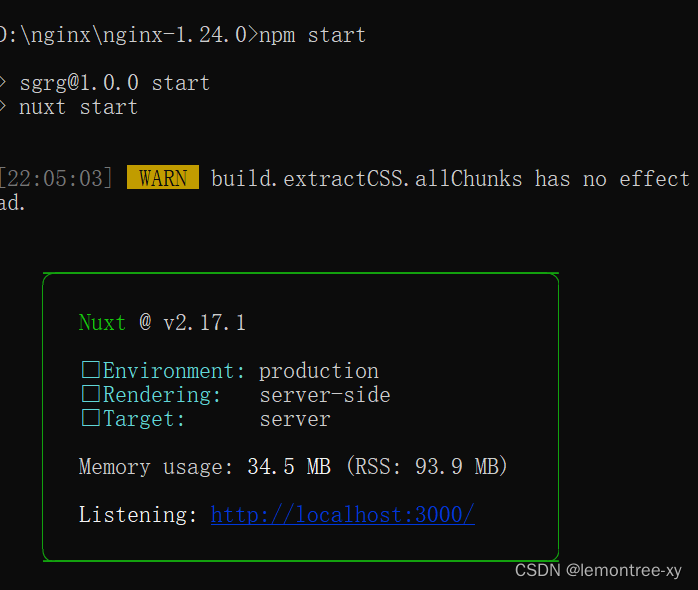
在nginx上部署nuxt项目
先安装Node.js 我安的18.17.0。 安装完成后,可以使用cmd,winr然cmd进入,测试是否安装成功。安装在哪个盘都可以测试。 测试 输入node -v 和 npm -v,(中间有空格)出现下图版本提示就是完成了NodeJS的安装…...
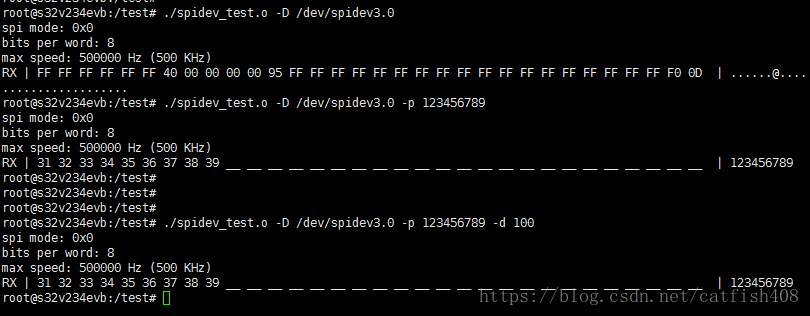
嵌入式linux通用spi驱动之spidev使用总结
Linux内核集成了spidev驱动,提供了SPI设备的用户空间API。支持用于半双工通信的read和write访问接口以及用于全双工通信和I/O配置的ioctl接口。使用时,只需将SPI从设备的compatible属性值添加到spidev区动的spidev dt ids[]数组中,即可将该SP…...

【Nodejs】Puppeteer\爬虫实践
puppeteer 文档:puppeteer.js中文文档|puppeteerjs中文网|puppeteer爬虫教程 Puppeteer本身依赖6.4以上的Node,但是为了异步超级好用的async/await,推荐使用7.6版本以上的Node。另外headless Chrome本身对服务器依赖的库的版本要求比较高,c…...

网络原理视角下的CasRel模型分布式部署与通信优化
网络原理视角下的CasRel模型分布式部署与通信优化 最近在帮一个团队落地一个关系抽取项目,他们用的就是CasRel模型。模型本身效果不错,但一到线上高并发场景,单实例就扛不住了,响应延迟飙升,还时不时挂掉。这让我意识…...

GME-Qwen2-VL-2B-Instruct数据库集成应用:电商评论图片情感分析系统
GME-Qwen2-VL-2B-Instruct数据库集成应用:电商评论图片情感分析系统 1. 引言:当图片开始“说话” 你有没有想过,电商平台上海量的商品评论图片,其实是一笔被严重低估的数据财富?用户拍下的照片,无论是展示…...

环保EPC工程企业如何选型工程项目管理系统
环保EPC工程(设计-采购-施工一体化)具有项目周期长、场景复杂、合规要求高、多参与方协同难度大等核心特点,涵盖烟气处理、水处理、环保设备安装等细分场景,其项目管理涉及设计、采购、施工、安全、环保合规、成本管控等多个环节&…...

IDEA Services窗口:一站式掌控多服务启动与端口监控
1. 为什么你需要Services窗口 作为一个常年和微服务打交道的开发者,我最头疼的就是同时管理五六个服务模块。每次启动项目都要开一堆终端窗口,查看日志得像玩连连看一样在不同窗口间切换。更崩溃的是,当某个服务启动失败时,往往要…...

Qwen3-ASR-1.7B效果展示:中英混合技术文档讲解音频精准转写案例
Qwen3-ASR-1.7B效果展示:中英混合技术文档讲解音频精准转写案例 专业级语音识别模型在实际技术场景中的表现究竟如何?本文通过真实的中英混合技术文档讲解音频测试,带你全面了解Qwen3-ASR-1.7B的精准转写能力。 1. 测试背景与场景选择 在技术…...
)
区域电网含风光火储多类型联合调度与 IEEE39 系统潮流及电能质量分析研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

C/C++变量初始化实践与内存管理技巧
1. 变量初始化的核心价值与常见误区在C/C开发中,变量初始化是每个程序员每天都要面对的基础操作,但很多人对其理解停留在表面。我曾参与过多个大型嵌入式项目,亲眼见过因为初始化不当导致的系统崩溃案例。比如在某工业控制器项目中࿰…...

Seaborn 绘图基础
在 Python 的数据可视化生态中,Seaborn 是建立在 Matplotlib 之上的高级统计绘图库。它面向数据分析任务提供了更直接的绘图接口,能够围绕变量的分布、关系与结构组织图形表达,因此特别适合教学入门与探索性数据分析。与只关注“如何画出线、…...

TOPMAX嵌入式Top-N最大值追踪库详解
1. TOPMAX库概述:嵌入式系统中的Top-N最大值追踪引擎TOPMAX是一个专为资源受限嵌入式平台设计的轻量级Arduino库,其核心功能是实时、高效地维护一个动态数据流中的前N个最大值。该库并非简单的排序容器,而是一种经过工程优化的“滑动窗口最大…...

嵌入式开发必备硬件知识解析与应用
1. 嵌入式开发与硬件的关系解析作为一名在嵌入式领域摸爬滚打多年的工程师,我经常被新人问到一个经典问题:"做嵌入式软件开发是不是可以完全不懂硬件?"我的回答永远是:你可以选择不精通,但绝对不能完全不懂。…...