Pytorch深度学习-----DataLoader的用法
系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
本文目录
- 系列文章目录
- 一、DataLoader是什么?
- 二、使用步骤
- 1.相关参数
- 2.引入库
- 3.创建数据(使用CIFAR10为例)
- 4.创建DataLoader实例
- 5.在Tensorboard中显示即完整代码如下
一、DataLoader是什么?
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),如果把Dataset比作一副扑克牌,则DataLoader就是每次手中处理的某一批扑克牌,然后每一批取多少张,总共能取多少批,用不用打乱顺序等,都可以在创建DataLoader时从参数自行设定。
二、使用步骤
1.相关参数
class DataLoader(Generic[T_co]):r"""Data loader. Combines a dataset and a sampler, and provides an iterable overthe given dataset.The :class:`~torch.utils.data.DataLoader` supports both map-style anditerable-style datasets with single- or multi-process loading, customizingloading order and optional automatic batching (collation) and memory pinning.See :py:mod:`torch.utils.data` documentation page for more details.Args:dataset (Dataset): dataset from which to load the data.batch_size (int, optional): how many samples per batch to load(default: ``1``).shuffle (bool, optional): set to ``True`` to have the data reshuffledat every epoch (default: ``False``).sampler (Sampler or Iterable, optional): defines the strategy to drawsamples from the dataset. Can be any ``Iterable`` with ``__len__``implemented. If specified, :attr:`shuffle` must not be specified.batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, butreturns a batch of indices at a time. Mutually exclusive with:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,and :attr:`drop_last`.num_workers (int, optional): how many subprocesses to use for dataloading. ``0`` means that the data will be loaded in the main process.(default: ``0``)collate_fn (Callable, optional): merges a list of samples to form amini-batch of Tensor(s). Used when using batched loading from amap-style dataset.pin_memory (bool, optional): If ``True``, the data loader will copy Tensorsinto device/CUDA pinned memory before returning them. If your data elementsare a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,see the example below.drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,if the dataset size is not divisible by the batch size. If ``False`` andthe size of dataset is not divisible by the batch size, then the last batchwill be smaller. (default: ``False``)timeout (numeric, optional): if positive, the timeout value for collecting a batchfrom workers. Should always be non-negative. (default: ``0``)worker_init_fn (Callable, optional): If not ``None``, this will be called on eachworker subprocess with the worker id (an int in ``[0, num_workers - 1]``) asinput, after seeding and before data loading. (default: ``None``)generator (torch.Generator, optional): If not ``None``, this RNG will be usedby RandomSampler to generate random indexes and multiprocessing to generate`base_seed` for workers. (default: ``None``)prefetch_factor (int, optional, keyword-only arg): Number of batches loadedin advance by each worker. ``2`` means there will be a total of2 * num_workers batches prefetched across all workers. (default value dependson the set value for num_workers. If value of num_workers=0 default is ``None``.Otherwise if value of num_workers>0 default is ``2``).persistent_workers (bool, optional): If ``True``, the data loader will not shutdownthe worker processes after a dataset has been consumed once. This allows tomaintain the workers `Dataset` instances alive. (default: ``False``)pin_memory_device (str, optional): the data loader will copy Tensorsinto device pinned memory before returning them if pin_memory is set to true.
在上述中共有15个参数,我们常用的有如下5个参数
dataset (Dataset)– 表示要读取的数据集
batch_size (python:int, optional)– 表示每次从数据集中取多少个数据
shuffle (bool, optional)–表示是否为乱序取出
num_workers (python:int, optional)– 表示是否多进程读取数据(默认为0);
drop_last (bool, optional)– 表示当样本数不能被batchsize整除时(即总数据集/batch_size 不能除尽,有余数时),最后一批数据(余数)是否舍弃(default:
False)
pin_memory(bool, optional)- 如果为True会将数据放置到GPU上去(默认为false)
2.引入库
from torch.utils.data import DataLoader
3.创建数据(使用CIFAR10为例)
创建CIFAR10的测试集
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
4.创建DataLoader实例
# 创建DataLoader实例
test_loader = DataLoader(dataset=test_set, # 引入数据集batch_size=4, # 每次取4个数据shuffle=True, # 打乱顺序num_workers=0, # 非多进程drop_last=False # 最后数据(余数)不舍弃
)
几点解释
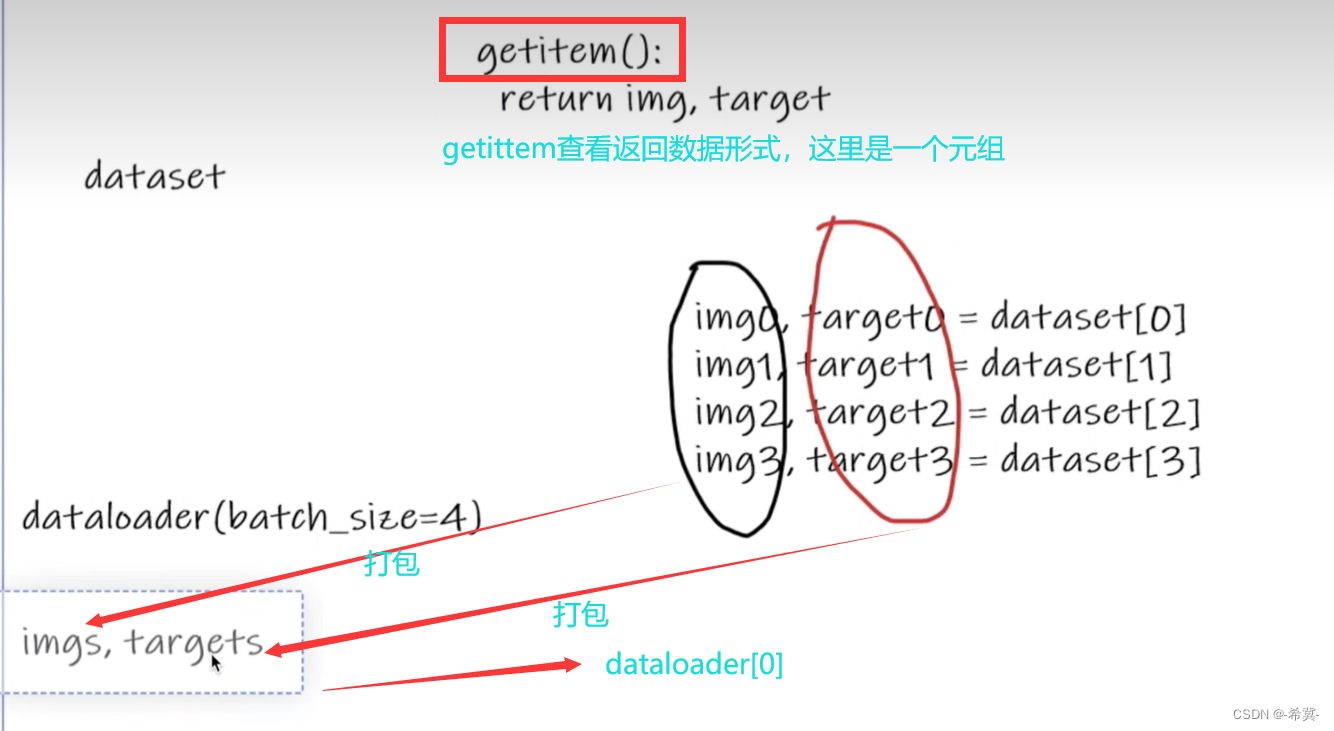
以此次一批数据为4为例
一个批次dataloader[0]就是
img0,target0 = dateset[0] . . . img3,target3 = dateset[3]
总共4个数据
故,
dataloader会将上面的img0……img3进行打包成imgs
target0……target3进行打包成target
如下小土堆的图所示
5.在Tensorboard中显示即完整代码如下
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备测试集
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 创建test_loader实例
test_loader = DataLoader(dataset=test_set, # 引入数据集batch_size=4, # 每次取4个数据shuffle=True, # 打乱顺序num_workers=0, # 非多进程drop_last=False # 最后数据(余数)不舍弃
)img,index = test_set[0]
print(img.shape) # 查看图片大小 torch.Size([3, 32, 32]) C h w,即三通道 32*32
print(index) # 查看图片标签
# 遍历test_loader
for data in test_loader:img,target = dataprint(img.shape) # 查看图片信息torch.Size([4, 3, 32, 32])表示一次4张图片,图片为3通道RGB,大小为32*32print(target) # tensor([4, 9, 8, 8])表示4张图片的target
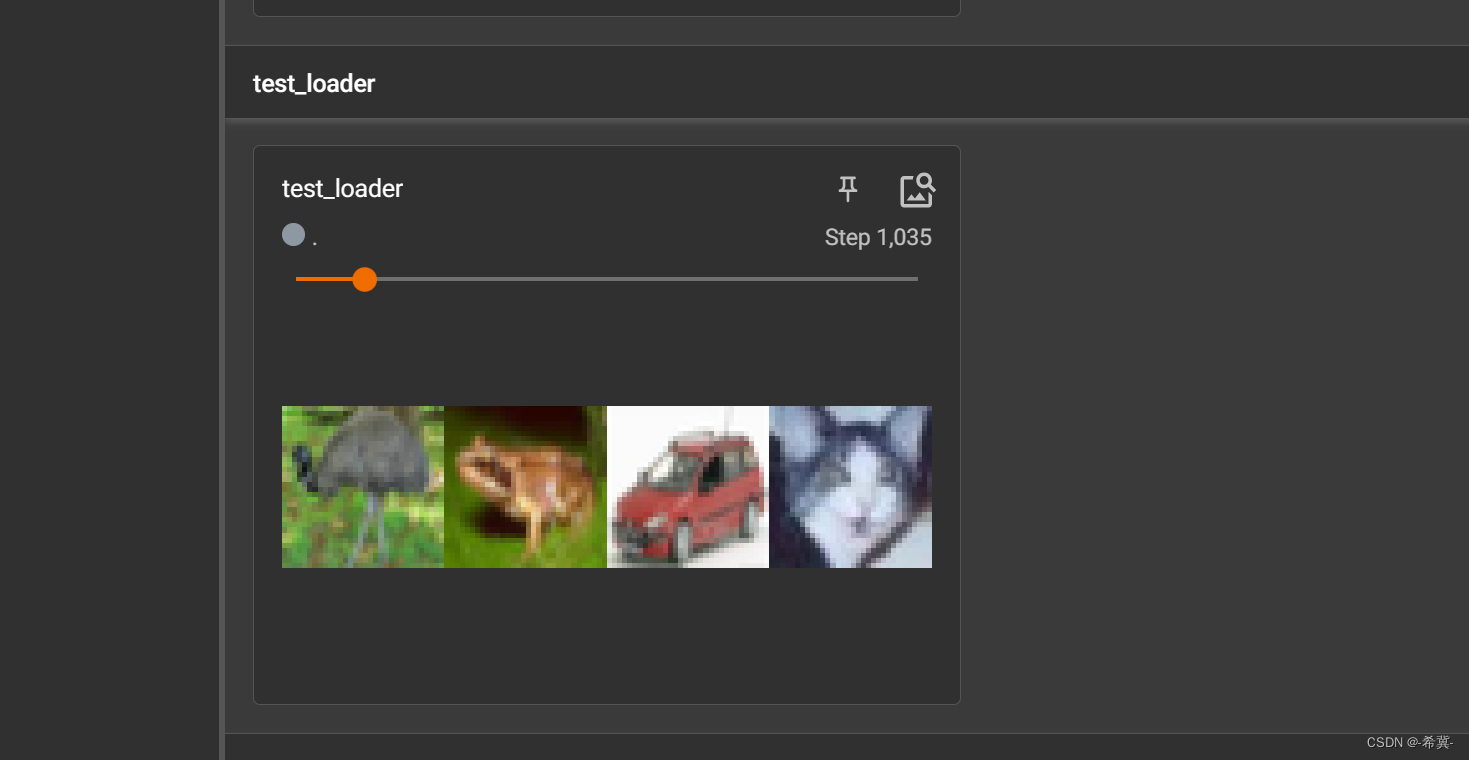
# 在tensorboard 中显示
writer = SummaryWriter("logs")
step = 0
for data in test_loader:img, target = datawriter.add_images("test_loader",img,step)step = step+1
writer.close()
相关文章:
Pytorch深度学习-----DataLoader的用法
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...

macOS Ventura 13.5 (22G74) Boot ISO 原版可引导镜像下载
macOS Ventura 13.5 (22G74) Boot ISO 原版可引导镜像下载 本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Windows 和 Lin…...

【机器学习】 奇异值分解 (SVD) 和主成分分析 (PCA)
一、说明 在机器学习 (ML) 中,一些最重要的线性代数概念是奇异值分解 (SVD) 和主成分分析 (PCA)。收集到所有原始数据后,我们如何发现结构?例如,通过过去 6 天…...
如何用logging记录python实验结果?
做python实验有时候需要打印很多信息在控制台(console),但是控制台的信息不方便回顾和保存,故而可以采用logging将信息存储起来。 先新建一个文件message.log代码如下: import logging logging.basicConfig(filename"messa…...

C语言假期作业 DAY 03
目录 题目 一、选择题 1、已知函数的原型是: int fun(char b[10], int *a); ,设定义: char c[10];int d; ,正确的调用语句是( ) 2、请问下列表达式哪些会被编译器禁止【多选】( ) 3、…...

使用serverless实现从oss下载文件并压缩
公司之前开发一个网盘系统, 可以上传文件, 打包压缩下载文件, 但是在处理大文件的时候, 服务器遇到了性能问题, 主要是这个项目是单机部署.......(离谱), 然后带宽只有100M, 现在用户比之前多很多, 然后所有人的压缩下载请求都给到这一台服务器了, 比如多个人下载的时候带宽问…...

从上到下打印二叉树
题目描述 从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。 例如: 给定二叉树: [3,9,20,null,null,15,7], 返回: [3,9,20,15,7] 算法思想 建立一个vector数组ret用来当做返回的结果数组,建立一个队列用来接收二叉树…...

【推荐】排序模型的调优
【推荐】排序模型的调优 排序模型的选择 排序模型常见的训练方式 样本类别不均衡处理尝试 欠拟合 过拟合 其他问题 排序模型的选择 LR,GBDT,LRGBDT,FM/FFM, 深度模型(wide & deep,DeepFM&#x…...

负载均衡安装配置详解
负载均衡(Load Balancing)是一种将网络流量分布到多个服务器上的技术,以提高系统的性能、可靠性和可扩展性。 在负载均衡中,有一个负载均衡器(Load Balancer),它充当了传入请求的前置接收器。当…...

Java-逻辑控制
目录 一、顺序结构 二、分支结构 1.if语句 2.swich语句 三、循环结构 1.while循环 2.break 3.continue 4.for循环 5.do while循环 四、输入输出 1.输出到控制台 2.从键盘输入 一、顺序结构 按照代码的书写结构一行一行执行。 System.out.println("aaa"); …...

UE 透明渲染次序
附加顺序 用最外面的球, 依次附加里面的球 最后附加的物体优先级最高 附加顺序 用最里面的球, 依次附加外面的球 这样渲染顺序就对了...

【C++】多态原理剖析,Visual Studio开发人员工具使用查看类结构cl /d1 reportSingleClassLayout
author:&Carlton tag:C topic:【C】多态原理剖析,Visual Studio开发人员工具使用查看类结构cl /d1 reportSingleClassLayout website:黑马程序员C tool:Visual Studio 2019 date:2023年7月24日 目…...

vue实现flv格式视频播放
公司项目需要实现摄像头实时视频播放,flv格式的视频。先百度使用flv.js插件实现,但是两个摄像头一个能放一个不能放,没有找到原因。(开始两个都能放,后端更改地址后不有一个不能放)但是在另一个系统上是可以…...

iptables安全技术和防火墙
防火墙:隔离功能 位置:部署在网络边缘或主机边缘,在工作中,防火墙的主要作用是决定哪些数据可以被外网访问以及哪些数据可以进入内网访问,主要在网络层工作 其他类型的安全技术:1、入侵检测系统 2、入侵…...

微信小程序开发5
一、自定义组件-插槽 1.1、什么是插槽 在自定义组件的wxml结构中,可以提供一个<slot>节点(插槽),用于承载组件使用者提供的wxml结构 1.2、单个插槽 在小程序中,默认每个自定义组件中允许使用一个<slot>进行占位,这种…...

【算法题】2681. 英雄的力量
题目: 给你一个下标从 0 开始的整数数组 nums ,它表示英雄的能力值。如果我们选出一部分英雄,这组英雄的 力量 定义为: i0 ,i1 ,… ik 表示这组英雄在数组中的下标。那么这组英雄的力量为 max(nums[i0],n…...

fastutil简单测试下性能
前言 简单测试一下fastutil的实现和Java类库实现的速率。 使用jmh进行测试。 简单解释一下,每轮测试预热2次,每次1s;实测2次,每次1秒。 进行5轮测试。数组大小3种。 package fastutil;import it.unimi.dsi.fastutil.ints.IntArr…...
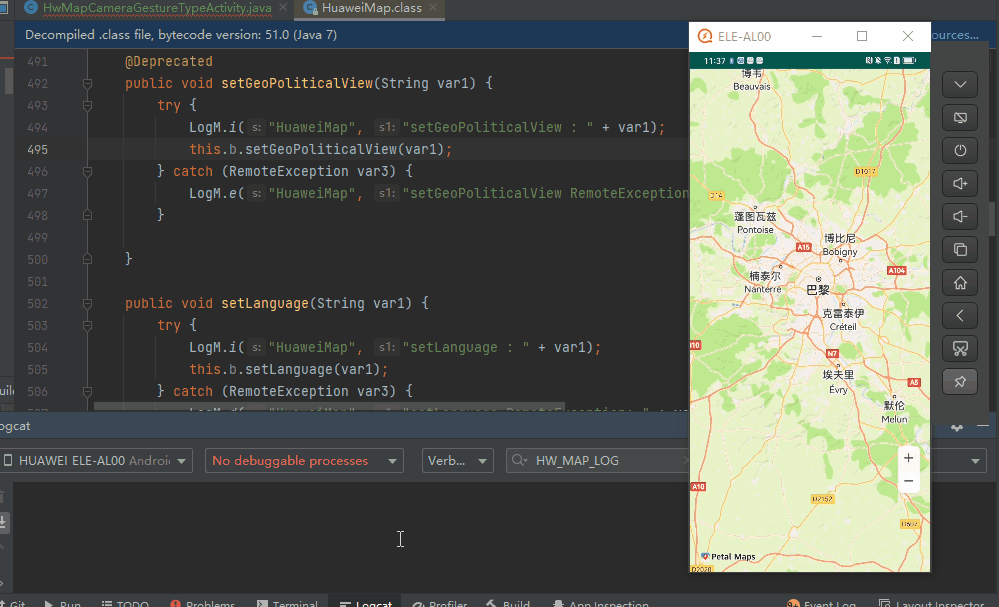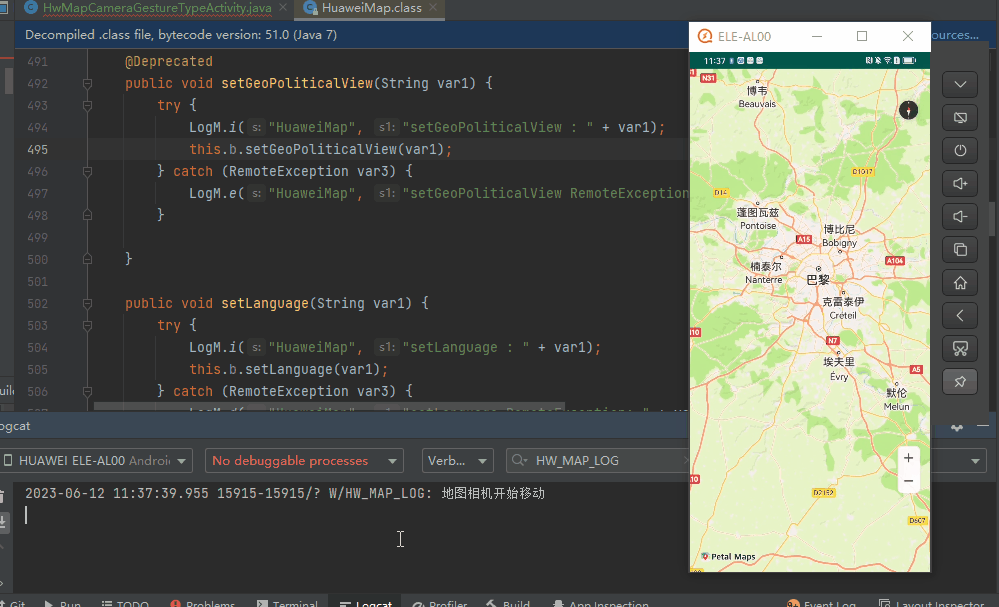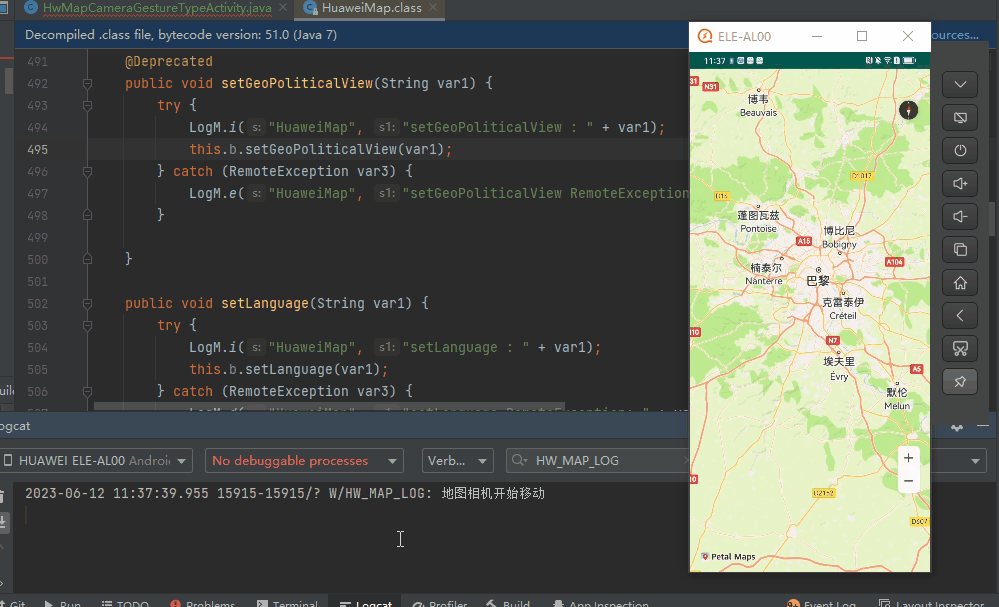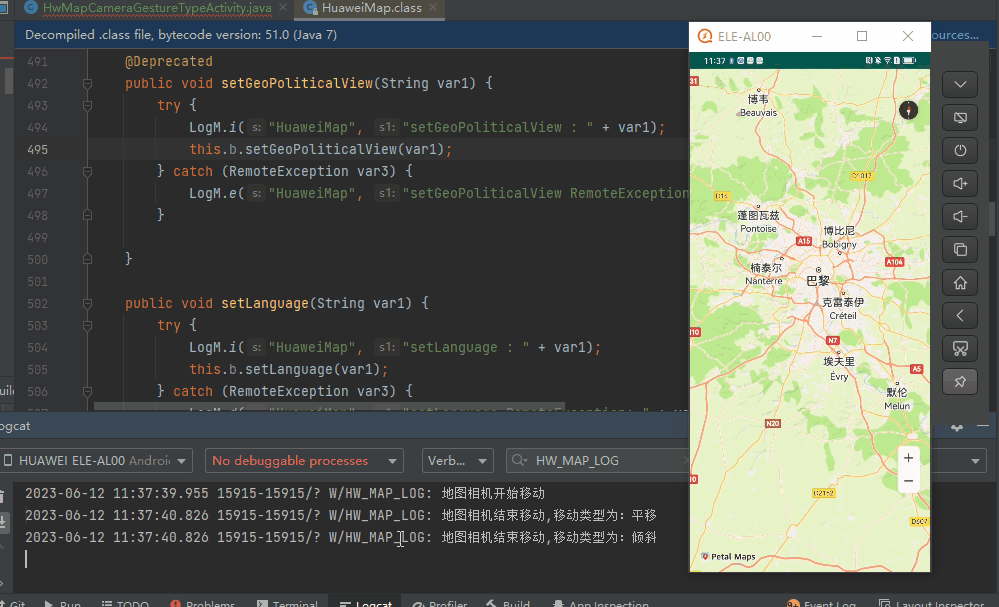
【FAQ】关于无法判断和区分用户与地图交互手势类型的解决办法
一. 问题描述 当用户通过缩放手势、平移手势、倾斜手势和旋转手势与地图交互,控制地图移动改变其可见区域时,华为地图SDK没有提供直接获取用户手势类型的API。 二. 解决方案 华为地图SDK的地图相机有提供CameraPosition类&…...

腾讯云裸金属服务器CPU型号处理器主频说明
腾讯云裸金属服务器CPU型号是什么?标准型BMSA2裸金属服务器CPU采用AMD EPYC ROME处理器,BMS5实例CPU采用Intel Xeon Cooper Lake处理器,腾讯云服务器网分享落进书房武器CPU型号、处理器主频说明: 裸金属服务器CPU处理器说明 腾讯…...

工程安全监测无线振弦采集仪在建筑物中的应用
工程安全监测无线振弦采集仪在建筑物中的应用 工程安全监测无线振弦采集仪是一种用于建筑物结构安全监测的设备,它采用了无线传输技术,具有实时性强、数据精度高等优点,被广泛应用于建筑物结构的实时监测和预警。下面将从设备的特点、应用场…...

OmX Hooks完全指南:轻松扩展你的AI助手功能
OmX Hooks完全指南:轻松扩展你的AI助手功能 【免费下载链接】oh-my-codex OmX - Oh My codeX: Your codex is not alone. Add hooks, agent teams, HUDs, and so much more. 项目地址: https://gitcode.com/GitHub_Trending/oh/oh-my-codex OmX(O…...

通义千问3-VL-Reranker-8B多场景落地:生物医药论文+实验图+临床视频
通义千问3-VL-Reranker-8B多场景落地:生物医药论文实验图临床视频 多模态重排序服务 Web UI,支持文本、图像、视频的混合检索与排序。 在生物医药领域,研究人员每天需要处理海量的学术论文、实验图像和临床视频。传统的关键词搜索往往难以精准…...

seo网站诊断的步骤是什么
SEO网站诊断的步骤是什么? 在当今数字化时代,网站的SEO优化(搜索引擎优化)是提升网站流量和品牌知名度的关键。进行SEO网站诊断是一个系统性的过程,通过这一过程,可以发现并解决网站在搜索引擎上的表现问题…...

Ubuntu 24.04裸机部署Home Assistant避坑指南:从Python源码编译到HACS插件全流程
Ubuntu 24.04裸机部署Home Assistant全栈实战:从Python环境构建到智能生态整合 当智能家居逐渐成为现代生活的标配,如何打造一个高度定制化的控制中心成为技术爱好者的新追求。Home Assistant作为开源家庭自动化平台,以其强大的兼容性和灵活性…...

超越序列:让AI以“面向对象”的方式理解与规划物理世界
从下一个token预测到下一个对象预测,我们如何重新思考AI生成与机器人控制 引言:大模型的“顺序陷阱” 在人工智能领域,以GPT为代表的大语言模型通过预测下一个token(文本片段)的方式,展现了令人惊叹的文本理解和生成能力。然而,这种自回归生成范式本质上是一种顺序处理…...

数据库SQL中的IN, NOT IN和NULL
一. 首先SQL中有一个原则: NULL与任何值比较都没结果 二. 假定有以下两个表: 表t1:idname1A2B3NULL表t2:idname1A2C3NULL1. 当使用 IN 查询 select * from t1 where t1.name in (select t2.name from t2);等价于 (t1.name1 t2.name1 or t1.name1 t2.name2 or ... ) or (t1.na…...

BilibiliDown:开源视频下载工具的批量处理与高效下载指南
BilibiliDown:开源视频下载工具的批量处理与高效下载指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirror…...

别再用默认源了!Ubuntu22.04换源后软件下载速度提升10倍的秘密
别再用默认源了!Ubuntu22.04换源后软件下载速度提升10倍的秘密 当你在Ubuntu终端里输入apt update后盯着缓慢爬升的进度条发呆时,有没有想过这背后隐藏着一个影响开发效率的关键因素?作为长期使用Ubuntu的开发老鸟,我发现90%的用户…...

Claude Code凯神实战指南-第六章:Plugins全攻略——一键安装海量扩展,还能自己造轮子
第六章:Plugins全攻略——一键安装海量扩展,还能自己造轮子 📖 项目简介 这是由凯神精心打造的一套完整的 Claude Code 实战教程系列,从零基础环境安装,到企业级安全合规,全面系统地覆盖 Claude Code 的所…...

2026年专升本论文降AI率工具推荐:选题和写作难点解决方案
2026年专升本论文降AI率工具推荐:选题和写作难点解决方案 导师发消息说论文AI率超标的时候,我正在食堂吃饭。筷子都差点拿不稳。 后来用了三天时间研究专升本论文降AI,踩了不少坑但总算搞定了。最后稳定在用的就是嘎嘎降AI(www.…...