【推荐】排序模型的调优
【推荐】排序模型的调优
- 排序模型的选择
- 排序模型常见的训练方式
- 样本类别不均衡处理尝试
- 欠拟合
- 过拟合
- 其他问题
排序模型的选择
LR,GBDT,LR+GBDT,FM/FFM, 深度模型(wide & deep,DeepFM,DCN等等 )
排序模型常见的训练方式
| 方法 |
|---|
| 方法1:T+1训练(固定时间滑窗内的全量数据来训练) |
| 方法2:每天增量训练 |
| 方法3:综合方法1和方法2 即当天内做增量训练(比如小时级别的增量训练),当天结束的时候做T+1全量训练。 |
样本类别不均衡处理尝试
对于搜推广领域的排序任务数据集,正负样本严重的类别不均衡,也就是说负样本数量经常是正样本数量的几百倍或者几千倍。对于这么严重的样本类别不均衡,如果不采取任何方案来缓解这个问题,对于模型学习知识是很困难的。对于排序任务来说,常见的缓解类别不均衡的方法如下:
· 对负样本降采样: 目的是通过某种方法从海量的负样本中采样一些负样本出来,从而让负样本的比例减少。对负样本进行采样后,在计算广告领域的排序任务中,需要在最后计算排序公式的时候进行校准(校准发生在线上推理的时候,离线训练的时候不用考虑校准)。对于个性化搜索和推荐系统来说,他们只关注打分概率的相对顺序,而采样前后的打分概率的相对顺序不会改变,所以不需要校准。
对负样本进行采样,会浪费掉很多负样本。
· 对正样本过采样: 目的是通过某种方法把正样本的数量变多。如果把正样本过采样到和负样本差不多的量级,会导致总体训练样本量太大,训练时间相对于正样本过采样前的时间变长很多。对正样本如果进行了采样,在计算广告的排序任务中也需要对打分概率做校准,而个性化搜索和推荐系统中的排序任务不需要对打分概率做校准。
通过简单复制正样本把正样本数量变成与负样本差不多的样本量,模型的离线效果还不错,就是训练时间相对长,比如一个epoch单机跑都要4,5个小时。正因为这个原因,我们最终没有使用这个方案。
· 每个epoch对负样本采样出和正样本1:1的数量: 这样就不浪费负样本,epoch的数量可以根据负样本数量和训练时间来权衡。
做法是这样的,使用tf.keras + tf.data.experimental.sample_from_datasets API 从大量的负样本采样,并与正样本拼接为最终的训练集,结果发现每个epoch后的验证集的AUC不变化。如果说模型已经充分收敛也就是loss基本不变了从而模型参数基本不变化,这个时候验证集的AUC不变化是有可能的,但是模型在刚开始的那些epoch都应该能看到不同的负样本,应该会继续学习而不会收敛,因此在开始的几个epoch验证集AUC应该是变化的。推断可能是Tensorflow/TF的坑,可能每个epoch都拟合了一样的负样本并且基本上在第一个epoch以后模型就基本收敛了。
· 使用class weight或者sample weight: 目的是通过设置权重来让模型更关注正样本。这个方法在很多项目中都会使用,实际效果也是很不错。
· 使用Focal loss: Focal loss可以做困难样本学习和缓解类别样本不均衡。由于时间关系,这个项目没有尝试这个方案。
欠拟合
对于欠拟合,简单来说就是模型学习的不够充分。常见的处理方法如下:
用更多和更好的特征:
连续特征的特征缩放处理(深度模型对于连续特征的幅度变化很敏感,所以用深度模型建模的话一定要对连续特征做特征缩放处理)。特征缩放的方法有很多,常见的比如Z-score标准化,MinMax归一化,取log,平滑方法(比如贝叶斯平滑)等等。对于历史ctr这样的比率特征,在排序任务中经常会考虑对该特征做平滑,目的是为了让那些历史ctr相等但是曝光次数多且点击次数也多的item经过平滑后得到的值与那些长尾的item区别开来(比如7天内点击1次,曝光2次的item与7天内点击50次,曝光100次的item,虽然他们的点击率相同,但是他们的受欢迎度差别很大,因此这个时候直接用7天内的ctr作为特征对他们来说没有辨识度,这个时候做ctr平滑就很有意义)。
还可以根据业务语义逐渐加入更多的设备侧和广告侧的交叉特征。在项目中我们也尝试了这个方法,欠拟合得到进一步的缓解。
增加模型复杂度/容量:
在当前使用的wide & deep排序模型的情况下,增加模型容量可以通过下面两种方式,方法1是把全连接层层数变多或者每层的神经元数量变多,方法2是把embedding向量的长度变大。业界一般做排序模型用到的全连接层常见都是3层,这个项目也是用的3层,我们尝试了把每层的神经元变多。另外,看到很多文章对于排序模型中用到的itemid/usrid embedding table的embedding向量的维度一般都是设置为8或者10(算是一个经验值)。
除了上面提到的这些缓解欠拟合的方法,调整学习率和batch size大小,以及样本类别不均衡的处理方法都可能缓解欠拟合。因此可以看到,缓解欠拟合的组合因素有很多。建议的方式是每次调试只是改变一个因素来进行训练后效果对比。特征缩放肯定是要先做的,除了学习率,batch size以及样本类别不均衡处理这三个因素外,我们可以循序渐进的尝试下面的方法来缓解欠拟合:挖掘一些好的特征(不包含交叉特征,比如一些历史统计特征),接着增加模型复杂度(主要是增加层数或者神经元个数),最后逐渐增加有意义的交叉特征。
过拟合
过拟合指的是模型在训练集上的效果/表现不错,但是在验证集上的表现与训练集上的差距很大。在实际生产项目中,我们更关心模型在训练集上效果不错,在验证集上的效果也不错,在这样的情况下即使过拟合我们也不关心,比如训练集上的AUC是0.95,验证集上的AUC是0.8,那这种情况是属于过拟合了,但是验证集的AUC也足够高了,所以这个情况我们能接受;如果是训练集上的AUC是0.95,验证集上的AUC是0.6,这种过拟合就是我们需要关心的了。欠拟合到过拟合,有时候就是一瞬间的事情(比如特征一下子加多了就容易从欠拟合变成过拟合)。对于使用深度模型做排序任务的场景,过拟合常见的处理方式如下:
收集更多的数据 : 目的是让模型能更多的见到不同的数据分布,从而学习到不同的知识。比如T+1训练中的T常见的是7天的数据作为训练集(当然这个T取多少和训练集中的正样本量有多少有很大关系),在我们这个项目中,T取的是30天的数据,因此能获得更多的样本尤其是正样本。
减少模型复杂度/容量: 也就是使用小一点的神经网络,包括小一点的embedding table,目的是让神经网络和embedding table的容量变小。在实际的项目中,见到过把itemid/userid embedding table的embedding向量的长度设置为几百几千的,不建议这样,太容易过拟合了,就像前面提到的,设置为8左右就是一个不错的起点。注意这里的embedding指的是input embedding,而关于output embedding以及文本embedding向量长度的选择可以参考我的github中的文章推荐系统概览。
使用BatchNormalization (简称BN,本质是对神经元的激活值进行整形,它在Deep Learning中非常有用,建议尽量用):使用BN的话,batch size不能太小,而batch size的调整一般伴随着同方向的learning rate的调整(也就是把batch size调大的话,learning rate可以适当调大一点点)。虽然BN主要是在CNN卷积层用的比较多,但是MLP层也可以用,RNN的话要用LayerNormalization(简称LN)。在当前项目中,使用BN后的离线效果提升很明显。
使用Early stopping早停: 监控模型在验证集的metric,并early stopping早停。Early stopping并不是必须的,如果设定模型固定跑的epoch数量,之后选择一个表现最好的epoch的checkpoint也是可以的,这个情况下就不需要early stopping。
正则化方法: 在深度学习中,常用的正则化方法是Dropout,L1/L2正则,Label标签平滑等。当前项目使用了dropout和L1/L2正则。Dropout的比率以及L1/L2正则的超参数在调试的时候,都要小步调整,大幅调整很容易一下子就从过拟合到了欠拟合了。
使用更少的特征: 在这个项目中,一下子增加了几种交叉特征后,模型从欠拟合到了过拟合。然后在去掉了几个交叉特征之后,过拟合得到缓解。因此加入新的特征要一点点加,小步走。
在使用深度模型发生过拟合的时候,首先要检查验证集的数据分布(比如每个连续特征的统计分布,每个离散特征的覆盖度,和训练集中的数据分布做一下对比)。如果训练集和验证集的数据分布相差很多,考虑如何重新构造训练集和验证集;否则,建议尝试按照如下的顺序来缓解(每做完一步就训练看效果,如果验证集的效果能接受了,就先打住;否则继续下一步):使用BN(基本上是标配)——使用更少的特征(如果特征本身就不多,可以跳过;主要关注交叉特征是否很多)——收集更多的数据(如果正样本量已经足够多,可以跳过这步)——使用正则化方法——减少模型复杂度/容量(尤其要注意embedding table中embedding向量的长度)
其他问题
数据集变了,模型的离线评估AUC变化很大:
数据集变大可能会导致容量小的模型效果变差,发生欠拟合。对于CTR/CVR任务,训练流程跑通以后,用固定滑窗的数据集来训练调试模型;而一般固定滑窗内的数据集的量级差不多。数据集的清洗和预处理每天都要保证一致性的行为,否则出问题调试很花时间。
要尽量保证特征的线上线下一致性。
同样的数据集和同样的模型,两个实验对比,发现对验证集的评估指标AUC有差别:
ML带入的随机性很多,所以最好在上下文尽量一致的情况下对比,包括超参数的设置,训练任务的相关参数和随机种子fix(这个非常重要,包括python random seed和tensorflow.random rseed都需要fix)。
经常发现在分布式训练中模型的评估指标比单机训练的评估指标要差:
这个是很常见的。使用分布式训练甚至只是单机多卡的时候,学习率可能不适合还用单机单卡训练的学习率,适当需要调整。对于horovod分布式训练方式,一般来说,把学习率变大一点就好,不能完全按照horovod官网建议的那样即用worker数量乘以之前单机单卡的学习率作为调整后的学习率(这个可能会得到很大的学习率,从而导致模型学习效果不好)。对于parameter server分布式训练的异步梯度更新方式,可能需要把学习率调小,为了让最慢那个stale model replica的更新对整体的影响小一些。
特征的覆盖度问题:
如果某些离散特征的特征值的样本出现频率很低比如少于10次,那么可以考虑特征向上合并或者把那些小类别统一归并为”Other”。
相关文章:

【推荐】排序模型的调优
【推荐】排序模型的调优 排序模型的选择 排序模型常见的训练方式 样本类别不均衡处理尝试 欠拟合 过拟合 其他问题 排序模型的选择 LR,GBDT,LRGBDT,FM/FFM, 深度模型(wide & deep,DeepFM&#x…...

负载均衡安装配置详解
负载均衡(Load Balancing)是一种将网络流量分布到多个服务器上的技术,以提高系统的性能、可靠性和可扩展性。 在负载均衡中,有一个负载均衡器(Load Balancer),它充当了传入请求的前置接收器。当…...

Java-逻辑控制
目录 一、顺序结构 二、分支结构 1.if语句 2.swich语句 三、循环结构 1.while循环 2.break 3.continue 4.for循环 5.do while循环 四、输入输出 1.输出到控制台 2.从键盘输入 一、顺序结构 按照代码的书写结构一行一行执行。 System.out.println("aaa"); …...

UE 透明渲染次序
附加顺序 用最外面的球, 依次附加里面的球 最后附加的物体优先级最高 附加顺序 用最里面的球, 依次附加外面的球 这样渲染顺序就对了...

【C++】多态原理剖析,Visual Studio开发人员工具使用查看类结构cl /d1 reportSingleClassLayout
author:&Carlton tag:C topic:【C】多态原理剖析,Visual Studio开发人员工具使用查看类结构cl /d1 reportSingleClassLayout website:黑马程序员C tool:Visual Studio 2019 date:2023年7月24日 目…...

vue实现flv格式视频播放
公司项目需要实现摄像头实时视频播放,flv格式的视频。先百度使用flv.js插件实现,但是两个摄像头一个能放一个不能放,没有找到原因。(开始两个都能放,后端更改地址后不有一个不能放)但是在另一个系统上是可以…...

iptables安全技术和防火墙
防火墙:隔离功能 位置:部署在网络边缘或主机边缘,在工作中,防火墙的主要作用是决定哪些数据可以被外网访问以及哪些数据可以进入内网访问,主要在网络层工作 其他类型的安全技术:1、入侵检测系统 2、入侵…...

微信小程序开发5
一、自定义组件-插槽 1.1、什么是插槽 在自定义组件的wxml结构中,可以提供一个<slot>节点(插槽),用于承载组件使用者提供的wxml结构 1.2、单个插槽 在小程序中,默认每个自定义组件中允许使用一个<slot>进行占位,这种…...

【算法题】2681. 英雄的力量
题目: 给你一个下标从 0 开始的整数数组 nums ,它表示英雄的能力值。如果我们选出一部分英雄,这组英雄的 力量 定义为: i0 ,i1 ,… ik 表示这组英雄在数组中的下标。那么这组英雄的力量为 max(nums[i0],n…...

fastutil简单测试下性能
前言 简单测试一下fastutil的实现和Java类库实现的速率。 使用jmh进行测试。 简单解释一下,每轮测试预热2次,每次1s;实测2次,每次1秒。 进行5轮测试。数组大小3种。 package fastutil;import it.unimi.dsi.fastutil.ints.IntArr…...
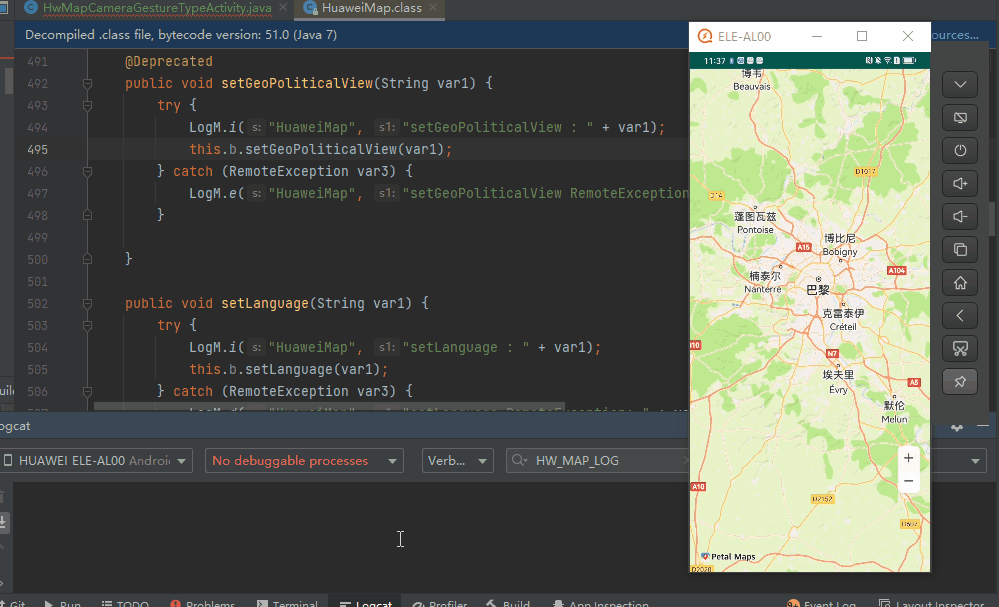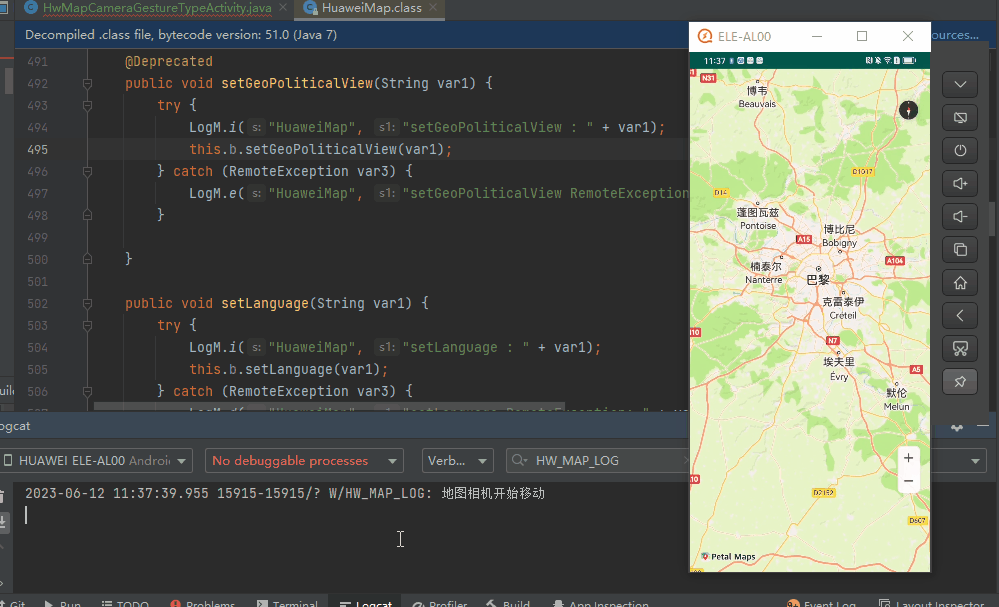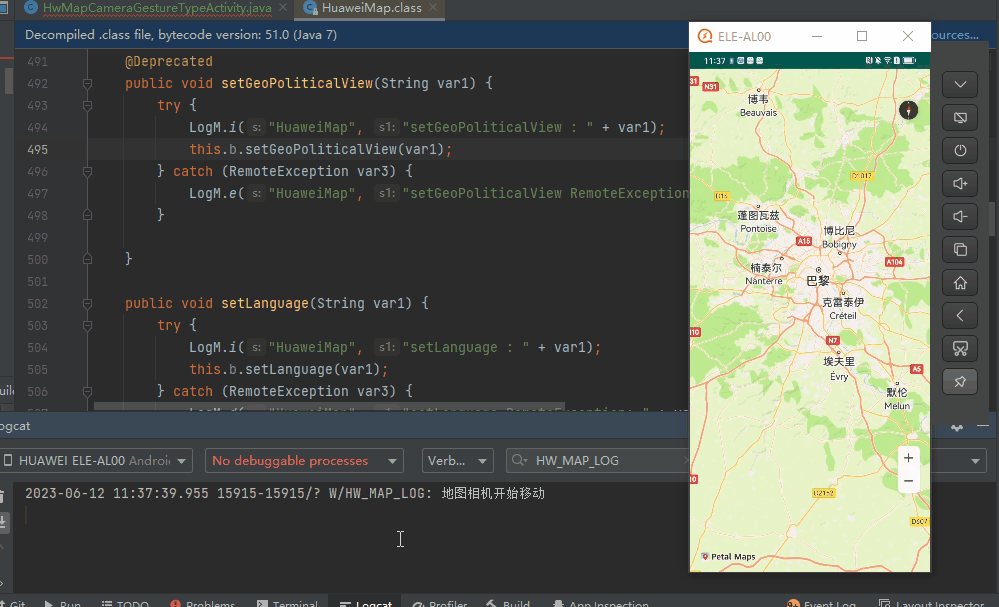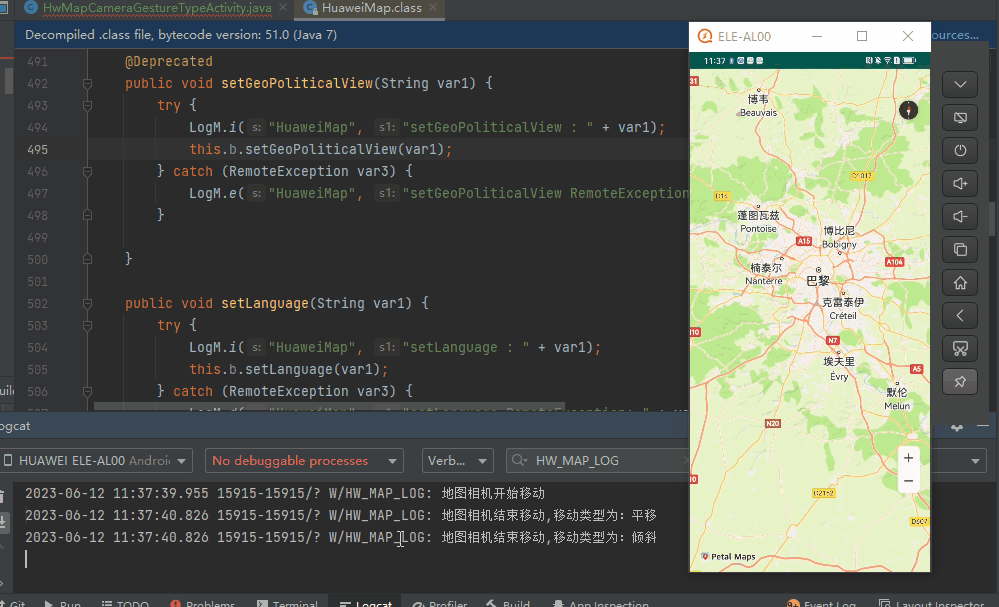
【FAQ】关于无法判断和区分用户与地图交互手势类型的解决办法
一. 问题描述 当用户通过缩放手势、平移手势、倾斜手势和旋转手势与地图交互,控制地图移动改变其可见区域时,华为地图SDK没有提供直接获取用户手势类型的API。 二. 解决方案 华为地图SDK的地图相机有提供CameraPosition类&…...

腾讯云裸金属服务器CPU型号处理器主频说明
腾讯云裸金属服务器CPU型号是什么?标准型BMSA2裸金属服务器CPU采用AMD EPYC ROME处理器,BMS5实例CPU采用Intel Xeon Cooper Lake处理器,腾讯云服务器网分享落进书房武器CPU型号、处理器主频说明: 裸金属服务器CPU处理器说明 腾讯…...

工程安全监测无线振弦采集仪在建筑物中的应用
工程安全监测无线振弦采集仪在建筑物中的应用 工程安全监测无线振弦采集仪是一种用于建筑物结构安全监测的设备,它采用了无线传输技术,具有实时性强、数据精度高等优点,被广泛应用于建筑物结构的实时监测和预警。下面将从设备的特点、应用场…...
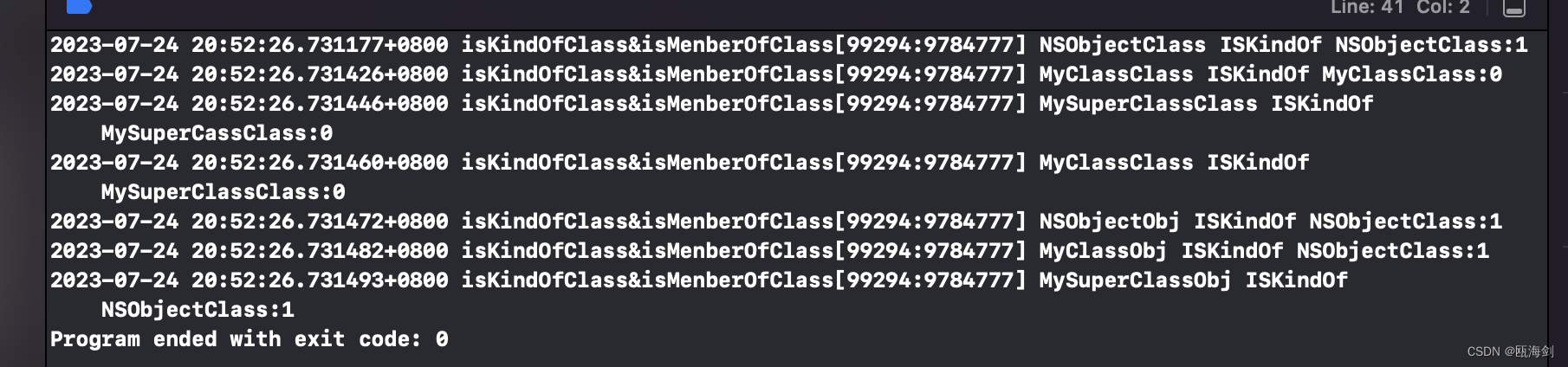
【iOS】isKindOfClass和isMemberOfClass方法
前言 这个归根结底还是在考察我们对isa走向图和类的继承的理解,也就是苹果官方这幅图: 接下来的函数调用流程请参考这张图。 1 isKindOfClass方法 1.1 objc_opt_isKindOfClass C函数 查看源码可发现,无论是谁调用isKindOfClass方法都会…...

李飞飞「具身智能」VoxPoser:0预训练完成复杂指令
机器人接入大模型听懂人话 论文地址: https://voxposer.github.io/voxposer.pdf 项目主页: https://voxposer.github.io/ 参考链接: [1]https://twitter.com/wenlong_huang/status/1677375515811016704 [1]https://www.amacad.org/publicatio…...

前端八股文
info 毕业设计(课题、方向 本科毕业设计:家庭医生签约管理系统后台开发(微信小程序) 硕士课题:医学图像分割(婴儿脑分割) 51062319991129351X 邮编 重庆市南岸区 400000 13183849783 // 18728097929 // 13158442955 中国广电四川网络股份有限公司中江…...

前端年度工作述职报告优秀
前端年度工作述职报告优秀篇1 尊敬的各位领导、各位同仁: 大家好!按照20__年度我公司就职人员工作评估的安排和要求,我认真剖析、总结了自己的工作情况,现将本人工作开展情况向各位领导、同仁做以汇报,有不妥之处,希…...

【MyBatis 学习一】认识MyBatis 第一个MyBatis查询
目录 一、认识MyBatis 1、MyBatis是什么? 2、为什么要学习MyBatis? 二、配置MyBatis环境 1、建库与建表 2、创建新项目 3、xml文件配置 (1)配置数据库连接 (2)配置 MyBatis 中的 XML 路径 三、测试&#x…...

TCP 和 UDP
TCP(Transmission Control Protocol,传输控制协议) 是面向连接的协议,即在收发数据前,必须和对方建立可靠的连接,TCP的头部为20个字节。 UDP(User Datagram Protocol,用户数据报协…...
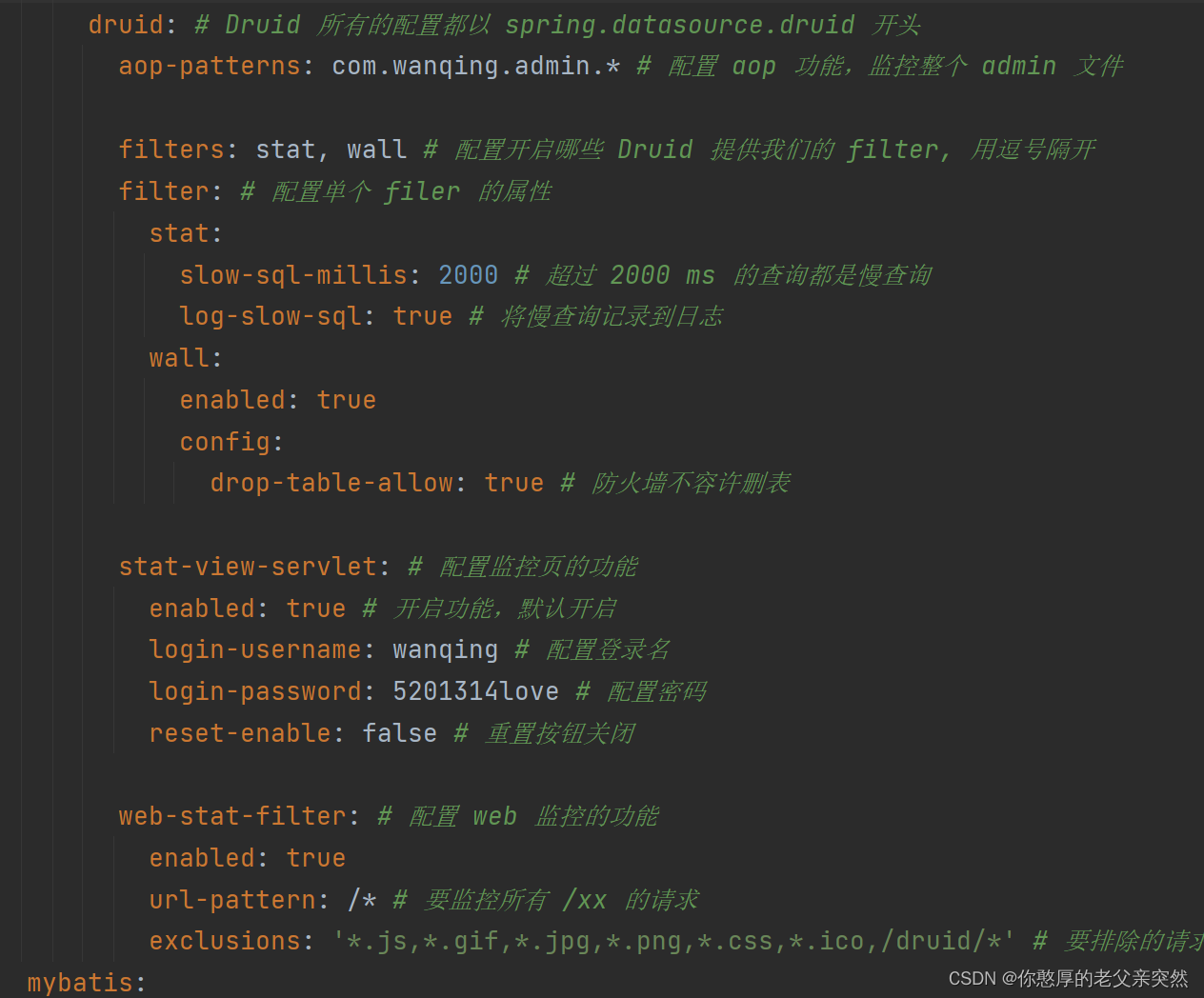
springboot配置自定义数据源(Druid德鲁伊)的步骤。
今天和大家分享下在Springboot中配置自定义数据源Druid的两种方法及步骤。 方法一: 1.在pom.xml配置依赖(注释里面的内容) 2.配置自己的数据源设置,我是在yaml文件中配置的,顺便提醒一下,在配置yaml文件的时候缩进问题一定要注意…...

Python高频面试题:python里面模块和包之间有什么区别?
大家好,我是锋哥。今天分享关于【Python高频面试题:python里面模块和包之间有什么区别?】面试题 。希望对大家有帮助; Python高频面试题:python里面模块和包之间有什么区别? 在 Python 里,**模…...

多核通信中的环形缓冲区设计与实现
1. 核间通信与环形缓冲区基础在现代多核处理器系统中,核间通信(IPC)是实现并行计算和任务协同的关键技术。共享内存是最常用的核间通信方式之一,它允许多个处理器核心通过访问同一块物理内存区域来交换数据。这种方式的优势在于避免了数据拷贝࿰…...

OpenClaw飞书机器人配置:Qwen3.5-9B-AWQ-4bit对话触发图片分析
OpenClaw飞书机器人配置:Qwen3.5-9B-AWQ-4bit对话触发图片分析 1. 为什么选择OpenClaw飞书Qwen3.5组合? 去年我负责一个小型研发团队的知识管理时,发现成员们经常在飞书群聊里分享截图和技术文档照片,但后续讨论需要手动输入大量…...

yaml-cpp性能基准测试全解析:C++ YAML解析器速度与内存占用深度分析
yaml-cpp性能基准测试全解析:C YAML解析器速度与内存占用深度分析 【免费下载链接】yaml-cpp A YAML parser and emitter in C 项目地址: https://gitcode.com/gh_mirrors/ya/yaml-cpp yaml-cpp是一个功能强大的C YAML解析器和发射器库,它完全遵循…...

020、深度学习入门:神经网络基础与反向传播
昨天调一个三层的全连接网络,loss死活不降。打印梯度发现第一层的权重全是零——反向传播根本没传过去。同事凑过来看了一眼:“你激活函数梯度写错了吧?”一查代码,果然在tanh求导的地方少了个平方。这种低级错误让我想起刚入门时…...

低成本搭建方案:树莓派运行OpenClaw连接千问3.5-9B云接口
低成本搭建方案:树莓派运行OpenClaw连接千问3.5-9B云接口 1. 为什么选择树莓派OpenClaw组合 去年冬天,我在整理个人知识库时被重复的文件归档工作折磨得苦不堪言。当时尝试过各种自动化工具,要么需要昂贵的云服务订阅,要么对硬件…...

VLC安卓版隐藏功能大揭秘:这些options参数让你的播放体验飞起
VLC安卓版隐藏功能大揭秘:这些options参数让你的播放体验飞起 作为安卓平台上最强大的开源播放器,VLC的潜力远不止表面看到的那些基础功能。许多用户不知道的是,通过调整options参数,可以彻底改变播放体验——解决卡顿、优化画质、…...

Claude Code 源码泄露,拿来改造 OpenClaw
一场意外的源码泄露,意外地给开源AI助手社区带来了一份珍贵的“研究素材”。Claude Code近51万行源码的暴露,正好可以为OpenClaw的下一阶段发展,提供一个明确的架构升级蓝图。核心功能:自动化定时任务 (Cron)两者都将“时间管理”…...

UBANTU安装Duckietown细节操作与错误记录
一,安装 1.虚拟机安装VM,安装UBUNTU系统,按照VMware虚拟机安装Ubuntu教程(超详细)_vmware安装ubuntu-CSDN博客 去操作就可以,绝对详细,而且不坑。 2.个人建议使用搜狗输入法。 3.打开系统文件夹 例如我的叫tuoni&a…...

抖音视频下载终极实战指南:一键无水印批量下载免费工具
抖音视频下载终极实战指南:一键无水印批量下载免费工具 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...