NoSQL之 Redis 部署,配置与优化
文章目录
- NoSQL之 Redis配置与优化
- 一.关系数据库与非关系型数据库
- 1.关系型数据库
- 2.非关系型数据库
- 3.关系型数据库和非关系型数据库区别
- 4.非关系型数据库产生背景
- 二.Redis简介
- 1.了解Redis
- 2.Redis 具有以下几个优点
- 3.Redis为何这么快
- 三.Redis 安装及应用
- 1.Redis 安装部署
- 2.Redis 命令工具
- 2.1 redis-cli 命令行工具
- 2.2 redis-benchmark 测试工具
- 3.Redis 数据库常用命令
- 3.1 keys 命令可以取符合规*或?等选项来使用
- 3.2 exists 命令可以判断键值是否存在
- 3.3 del 命令可以删除当前数据库的指定 key
- 3.4 type 命令可以获取 key 对应的 value 值类型
- 3.5 rename 命令是对已有 key 进行重命名。(覆盖)
- 3.6 renamenx 命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
- 3.7 dbsize 命令的作用是查看当前数据库中 key 的数目。
- 3.8 使用config set requirepass yourpassword命令给redis数据库设置密码
- 4.Redis 多数据库常用命令
- 4.1 多数据库间切换
- 4.2 多数据库间移动数据
- 4.3 清除数据库内数据
- 总
NoSQL之 Redis配置与优化
一.关系数据库与非关系型数据库
1.关系型数据库
(1)结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
(2)SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
(3) 主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostgreSQL 等。
2.非关系型数据库
(1)除了主流的关系型数据库外的数据库,都认为是非关系型。
(2)不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
(3)主流的 NoSQL 数据库有 Redis、MongBD、Hbase、Memcached 等。
3.关系型数据库和非关系型数据库区别
(1)数据存储方式不同
- 关系型数据天然就是表格式的,存储在数据表的行和列中。数据表关联协作存储,容易提取数据。
- 非关系型数据不适合存储在数据表的行和列中,大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)扩展方式不同
因为要支持日益增长的需求当然要扩展。要支持更多并发量,
-
SQL数据库是纵向扩展,提高处理能力,使用速度更快速的计算机,处理相同的数据集更快。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多克服。虽然SQL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限个表,这都需要通过提高计算机性能来。
-
NoSQL数据库是横向扩展的。非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
总:
关系:纵向 比如说硬件中添加内存
非关:横向 天然分布式
(3)对事务性的支持不同
如果计数据操作需要高事务性或者复杂数据查询需要控制执行划,
- SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
- NoSQL数据库也可以使用事务操作,稳定性方面比关系型数据库低,因在操作的扩展性和大数据量处理方面。
4.非关系型数据库产生背景
可用于应对 Web2.0 纯动态网站类型的三高问题。
(1)High performance——对数据库高并发读写需求
(2)Huge Storage——对海量数据高效存储与访问需求
(3)High Scalability && High Availability——对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给Web2.0的数据库发展带来新的思路。
关系数据库关注在关系上,非关系型数据库关注在存储上。
例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
Mysql 高热数据——redis
web——redis——mysql
CPU——内存/缓存—磁盘
二.Redis简介
1.了解Redis
(1)Redis是一个开源的、使用 C 语言编写的 NoSQL 数据库。
(2)基于内存运行并支持持久化,采用key-value(键值对)的存储形式。
(3)单进程模型,一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。
即:在实际生产环境中,需根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程。
2.Redis 具有以下几个优点
(1)具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
(2)支持丰富的数据类型:支持 key-value(键值)、Strings(字符串)、Lists(列表)、Hashes(哈希散列值)、Sets(有序) 及 Sorted Sets(无序排序) 等数据类型操作。
(3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性:Redis 所有操作都是原子性的。
(5)支持数据备份:即 master-salve 模式的数据备份。
Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录。
3.Redis为何这么快
(1)Redis是一款纯内存结构,避免了磁盘I/o等耗时操作。
(2)Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
(3)采用了 I/O 多路复用机制,大大提升了并发效率。
注:在 Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的。
三.Redis 安装及应用
1.Redis 安装部署
#关闭防火墙、安全机制
systemctl stop firewalld
setenforce 0
#安装编译 C 和 C++ 程序所需的工具和库
yum install -y gcc gcc-c++ make
#将redis移到/opt下,解压
tar zxvf redis-5.0.7.tar.gz -C /opt/
#编译安装
cd /opt/redis-5.0.7/
make -j2 && make install
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
#执行软件包提供的 install_server.sh 脚本文件设置 Redis 服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
./install_server.sh
...... #一直回车
Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server #需要手动修改为 /usr/local/redis/bin/redis-server ,注意要一次性正确输入
注:
Selected config:
#默认侦听端口为6379
Port : 6379
#配置文件路径
Config file : /etc/redis/6379.conf
#日志文件路径
Log file : /var/log/redis_6379.log
#数据文件路径
Data dir : /var/lib/redis/6379
#可执行文件路径
Executable : /usr/local/redis/bin/redis-server
#客户端命令工具
Cli Executable : /usr/local/bin/redis-cli
#把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/
#当 install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认监听端口为 6379
netstat -natp | grep redis

#Redis 服务控制
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #启动
/etc/init.d/redis_6379 restart #重启
/etc/init.d/redis_6379 status #状态
#修改配置 /etc/redis/6379.conf 参数
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.186.10 #70行,添加 监听的主机地址
port 6379 #93行,Redis默认的监听端口
daemonize yes #137行,启用守护进程
pidfile /var/run/redis_6379.pid #159行,指定 PID 文件
loglevel notice #167行,日志级别
logfile /var/log/redis_6379.log #172行,指定日志文件
/etc/init.d/redis_6379 restart
2.Redis 命令工具
| 命令工具 | 注解 |
|---|---|
| redis-server | 用于启动 Redis 的工具 |
| redis-benchmark | 用于检测 Redis 在本机的运行效率 |
| redis-check-aof | 修复 AOF 持久化文件 |
| redis-check-rdb | 修复 RDB 持久化文件 |
| redis-cli | Redis 命令行工具 |
2.1 redis-cli 命令行工具
(1)语法
redis-cli -h host -p port -a password
| 命令 | 注释 |
|---|---|
| -h | 指定远程主机 |
| -p | 指定 Redis 服务的端口号 |
| -a | 指定密码,未设置数据库密码可以省略-a 选项 |
若不添加任何选项表示,则使用 127.0.0.1:6379 连接本机上的 Redis 数据库
(2)示例
redis-cli -h 192.168.186.10 -p 6379
#默认本虚拟机上的redis数据库
redis-cli -h 127.0.0.1 -p 6379
2.2 redis-benchmark 测试工具
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
(1)基本的测试语法
redis-benchmark [选项] [选项值]。
| 命令 | 注释 |
|---|---|
| -h | 指定服务器主机名。 |
| -p | 指定服务器端口。 |
| -s | 指定服务器 socket |
| -c | 指定并发连接数。 |
| -n | 指定请求数。 |
| -d | 以字节的形式指定 SET/GET 值的数据大小。 |
| -k | 1=keep alive 0=reconnect 。 |
| -r | SET/GET/INCR 使用随机 key, SADD 使用随机值。 |
| -P | 通过管道传输请求。 |
| -q | 强制退出 redis。仅显示 query/sec 值。 |
| –csv | 以 CSV 格式输出。 |
| -l | 生成循环,永久执行测试。 |
| -t | 仅运行以逗号分隔的测试命令列表。 |
| -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
(2)示例
#向 IP 地址为 192.168.186.10、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
[root@test3 bin]# redis-benchmark -h 192.168.186.10 -p 6379 -c 100 -n 100000注释:
====== MSET (10 keys) ======100000 requests completed in 0.61 seconds100 parallel clients3 bytes payloadkeep alive: 197.77% <= 1 milliseconds
100.00% <= 1 milliseconds
163132.14 requests per secondMSET(10个键)
0.61秒内完成100000次请求100个并行客户端
3字节负载保持活力:1
97.77%<=1毫秒
每秒100.00%<=1毫秒163132.14个请求
#测试存取大小为 100 字节的数据包的性能
redis-benchmark -h 192.168.186.10 -p 6379 -q -d 100注释:
MSET (10 keys): 153139.36 requests per secondMSET(十个键):每秒15313936次请求
#测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能
redis-benchmark -t set,lpush -n 100000 -q注释:
SET: 184162.06 requests per second
LPUSH: 190114.06 requests per second设置:每秒184162.06次请求
LPUSH:每秒190114.06次请求
3.Redis 数据库常用命令
(1)语法格式
set:存放数据,命令格式为 set key value
get:获取数据,命令格式为 get key
(2)示例
[root@test3 bin]# redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> set test zjf
OK
127.0.0.1:6379> get test
"zjf"
3.1 keys 命令可以取符合规*或?等选项来使用
#准备测试数据
127.0.0.1:6379> set h1 1
127.0.0.1:6379> set h2 2
127.0.0.1:6379> set h3 3
127.0.0.1:6379> set c1 4
127.0.0.1:6379> set c5 5
127.0.0.1:6379> set c66 5
127.0.0.1:6379> set c88 8
#查看当前数据库中所有键
127.0.0.1:6379> keys *1) "myset:__rand_int__"2) "h3"3) "c5"4) "key:__rand_int__"5) "mylist"6) "h1"7) "c1"8) "c88"9) "c66"
10) "h2"
11) "counter:__rand_int__"
12) "test"
#查看当前数据库中以 c 开头的数据
127.0.0.1:6379> keys c*
1) "c5"
2) "c1"
3) "c88"
4) "c66"
5) "counter:__rand_int__"
#查看当前数据库中以 c 开头后面包含任意一位的数据
127.0.0.1:6379> keys c?
1) "c5"
2) "c1"
#查看当前数据库中以 c 开头后面包含任意两位的数据
127.0.0.1:6379> keys c??
1) "c88"
2) "c66"
3.2 exists 命令可以判断键值是否存在
#判断 test 键是否存在
127.0.0.1:6379> exists test
# 1 表示 teacher 键是存在
(integer) 1
127.0.0.1:6379> exists test1
# 0 表示 tea 键不存在
(integer) 0
3.3 del 命令可以删除当前数据库的指定 key
#查看库
127.0.0.1:6379> keys *1) "myset:__rand_int__"2) "h3"3) "c5"4) "key:__rand_int__"5) "mylist"6) "h1"7) "c1"8) "c88"9) "c66"
10) "h2"
11) "counter:__rand_int__"
12) "test"
#删除c1
127.0.0.1:6379> del c1
(integer) 1
127.0.0.1:6379> get c1
#空值,删除成功
(nil)
3.4 type 命令可以获取 key 对应的 value 值类型
127.0.0.1:6379> type h3
string
3.5 rename 命令是对已有 key 进行重命名。(覆盖)
(1)命令格式
rename 源key 目标key
使用rename命令进行重命名时,无论目标key是否存在都进行重命名,且源key的值会覆盖目标key的值。
在实际使用过程中,建议先用 exists 命令查看目标 key 是否存在,然后再决定是否执行 rename 命令,以避免覆盖重要数据。
127.0.0.1:6379> keys h*
1) "h3"
2) "h1"
3) "h2"127.0.0.1:6379> rename h2 h22
OK
127.0.0.1:6379> keys h*
1) "h3"
2) "h1"
3) "h22"
127.0.0.1:6379> get c66
"5"
127.0.0.1:6379> get c88
"8"
127.0.0.1:6379> rename c66 c88
OK
127.0.0.1:6379> get c66
(nil)
127.0.0.1:6379> get c88
"5"
3.6 renamenx 命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
(1)格式
renamenx 源key 目标key
(2)示例
127.0.0.1:6379> get test
"hh"
127.0.0.1:6379> get c88
"5"
127.0.0.1:6379> rename c88 text
OK
127.0.0.1:6379> get text
"5"
127.0.0.1:6379> get c88
(nil)
127.0.0.1:6379> rename test text
OK
127.0.0.1:6379> get text
"hh"
127.0.0.1:6379> get test
(nil)
3.7 dbsize 命令的作用是查看当前数据库中 key 的数目。
127.0.0.1:6379> dbsize
(integer) 8
127.0.0.1:6379> keys *
1) "myset:__rand_int__"
2) "h3"
3) "key:__rand_int__"
4) "mylist"
5) "h1"
6) "h22"
7) "text"
8) "counter:__rand_int__"
3.8 使用config set requirepass yourpassword命令给redis数据库设置密码
127.0.0.1:6379> config set requirepass 123456
OK
#使用config get requirepass命令查看密码(一旦设置密码,必须先验证通过密码,否则所有操作不可用)
[root@test3 bin]# redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"
4.Redis 多数据库常用命令
Redis 支持多数据库,Redis 默认情况下包含 16 个数据库,数据库名称是用数字 0-15 来依次命名的。
多数据库相互独立,互不干扰。
4.1 多数据库间切换
(1)命令格式
select 序号
使用 redis-cli 连接 Redis 数据库后,默认使用的是序号为 0 的数据库。
(2)示例
#切换至序号为 10 的数据库
127.0.0.1:6379> select 10
OK
#切换至序号为 15 的数据库
127.0.0.1:6379[10]> select 15
OK
#切换至序号为 0 的数据库
127.0.0.1:6379[15]> select 0
OK4.2 多数据库间移动数据
(1)格式
move 键值 序号
(2)示例
127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> get k1
"100"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get k1
(nil)
#切换至目标数据库 0
127.0.0.1:6379[1]> select 0
OK
#查看目标数据是否存在
127.0.0.1:6379> get k1
"100"
#将数据库 0 中 k1 移动到数据库 1 中
127.0.0.1:6379> move k1 1
(integer) 1
#切换至目标数据库 1
127.0.0.1:6379> select 1
OK
#查看被移动数据
127.0.0.1:6379[1]> get k1
"100"
127.0.0.1:6379[1]> select 0
OK
#在数据库 0 中无法查看到 k1 的值
127.0.0.1:6379> get k1
(nil)
4.3 清除数据库内数据
FLUSHDB :清空当前数据库数据
FLUSHALL :清空所有数据库的数据,慎用!——需仔细确认
#FLUSHDB只会清除当前在的数据库
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty list or set)#其他的数据库中未被清楚
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> keys *
1) "k1"
127.0.0.1:6379[1]> get k1
"100"
#FLUSHALL清除所有
127.0.0.1:6379[4]> keys *
1) "4"
127.0.0.1:6379[4]> select 2
OK
127.0.0.1:6379[2]> keys *
1) "4"
2) "2"
127.0.0.1:6379[2]> flushall
OK
127.0.0.1:6379[2]> keys *
(empty list or set)
127.0.0.1:6379[2]> select 4
OK
127.0.0.1:6379[4]> keys *
(empty list or set)
总
总结
非关系数据库
1、数据保存在缓存中,利于读取速度/查询数据
2、架构位置灵活
3、分布式、扩展性高
关系数据库
1、安全性高(持久化)
2、事务处理能力强
3、任务控制能力强
4、可以做日志备份、恢复、容灾的能力更强一点
关系数据库
实例-----》 数据库-----》表(table)----》记录行(row)、数据字段(column)—》存储数据
非关系型数据库
实例—》数据库—》 集合(collection)—》键值对(key-value)
OK
127.0.0.1:6379[1]> keys *
- “k1”
127.0.0.1:6379[1]> get k1
“100”
#FLUSHALL清除所有
127.0.0.1:6379[4]> keys *
- “4”
127.0.0.1:6379[4]> select 2
OK
127.0.0.1:6379[2]> keys * - “4”
- “2”
127.0.0.1:6379[2]> flushall
OK
127.0.0.1:6379[2]> keys *
(empty list or set)
127.0.0.1:6379[2]> select 4
OK
127.0.0.1:6379[4]> keys *
(empty list or set)
# 总总结
非关系数据库
1、数据保存在缓存中,利于读取速度/查询数据
2、架构位置灵活
3、分布式、扩展性高关系数据库
1、安全性高(持久化)
2、事务处理能力强
3、任务控制能力强
4、可以做日志备份、恢复、容灾的能力更强一点关系数据库
实例-----》 数据库-----》表(table)----》记录行(row)、数据字段(column)---》存储数据非关系型数据库
实例---》数据库---》 集合(collection)---》键值对(key-value)
注:非关系型数据库不需要手动建数据库和集合
相关文章:
NoSQL之 Redis 部署,配置与优化
文章目录 NoSQL之 Redis配置与优化一.关系数据库与非关系型数据库1.关系型数据库2.非关系型数据库3.关系型数据库和非关系型数据库区别4.非关系型数据库产生背景 二.Redis简介1.了解Redis2.Redis 具有以下几个优点3.Redis为何这么快 三.Redis 安装及应用1.Redis 安装部署2.Redi…...
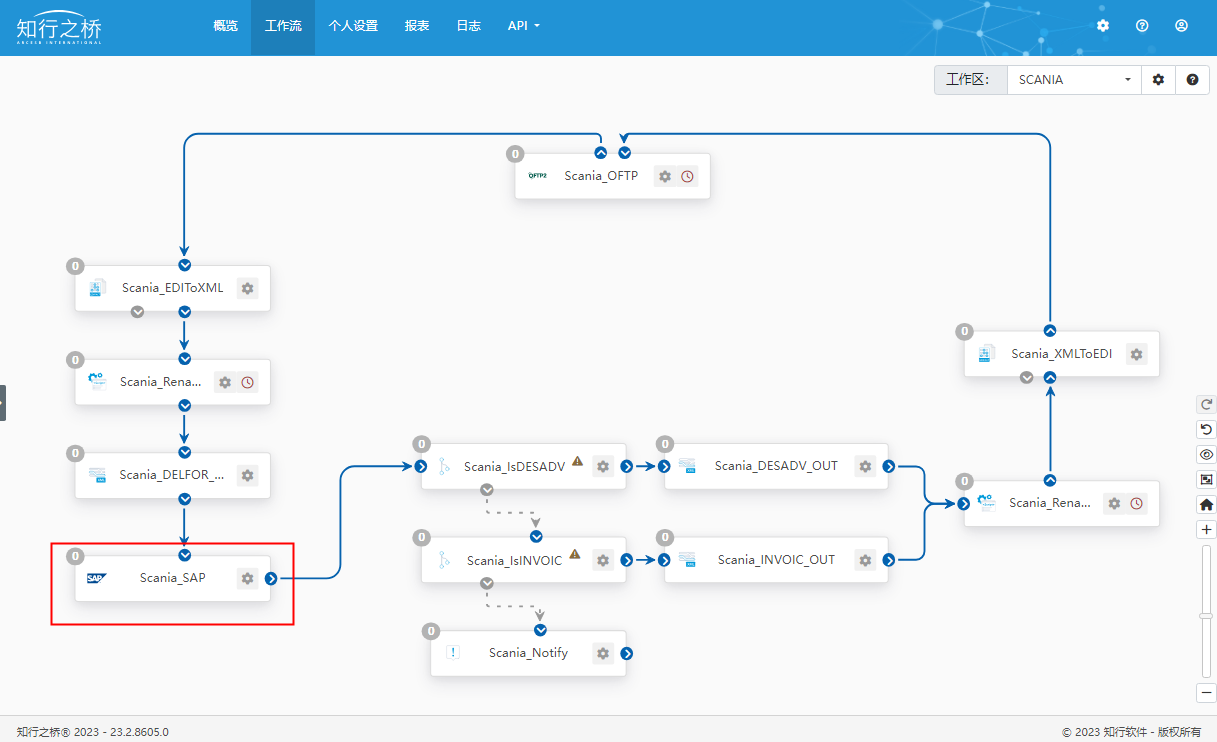
汽车行业 Y 公司对接斯堪尼亚 SCANIA EDI 项目案例
斯堪尼亚是一家来自瑞典的重型车辆制造公司,成立于1891年,总部位于斯德哥尔摩,主要专注于生产卡车、客车和工业发动机,以及相应的服务与解决方案。斯堪尼亚的产品以其高品质、可靠性和先进技术而闻名。其卡车广泛应用于货运和运输…...
)
mysql到doris踩坑记录(如果有问题希望大家帮忙指出问题)
1安装mysql(该步骤晚上很多,不做记录) 2安装docker(同上) 3安装并部署doris(下载镜像步骤省略) sudo docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 \-itd starrocks.docker.scarf.sh/starrocks/allin1-ubuntu 官网地址从 Apache Flink 持续导入 Flink-c…...
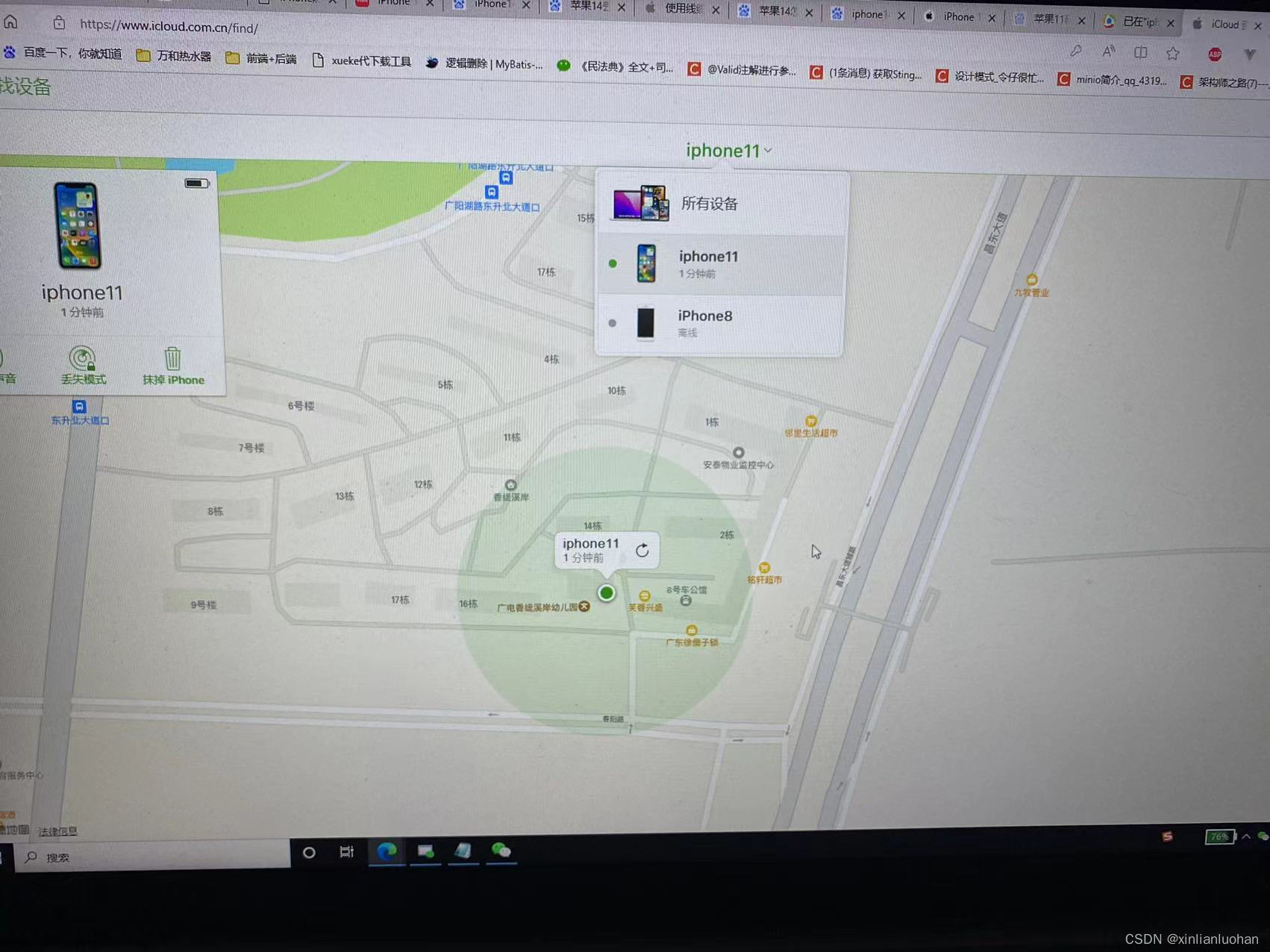
苹果11手机设置手机跟踪功能
苹果11手机设置手机跟踪功能,就算是手机丢了,也能通过查询手机定位在哪里。 第一步:点击Apple ID进入详情 第二步:点击“查找” 第三步: 第四步: 到了这步,就算是设置成功。 下面需要到官方查询…...
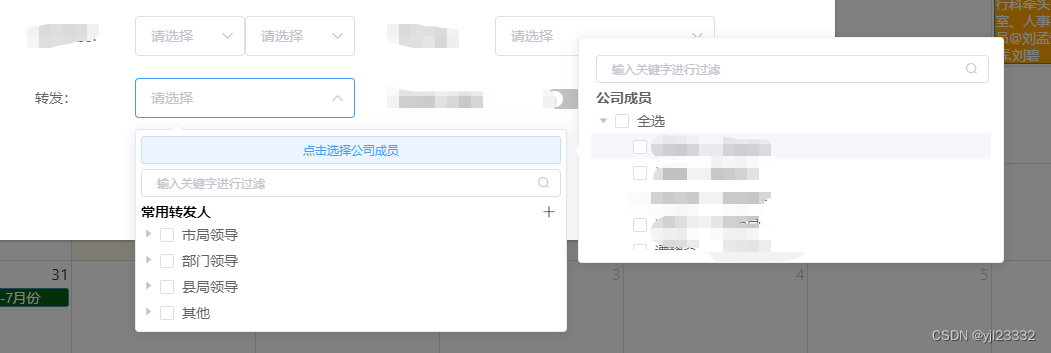
下拉框可筛选可树状多选组件
实际效果图片 父页面 <el-form-item label"转发:" :label-width"formLabelWidth" class"formflex_item"><el-select ref"select" :clearable"true" clear"clearSelect" remove-tag"r…...

【LeetCode】70.爬楼梯
题目 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. 2 阶 示例 2…...
和Math.Round())
c#中的Math.Ceiling和Math.floor()和Math.Round()
Math.Ceiling(),只要有小数就加1(小数部分不为0) 例如: Math.Ceiling(0.0) -> 0 Math.Ceiling(0.1) -> 1 Math.Ceiling(0.2) -> 1 Math.Ceiling(0.3) -> 1 Math.Ceiling(0.4) -> 1 Math.Ceiling(0.5) -> 1 Math.Ceiling(0.6) -> 1…...
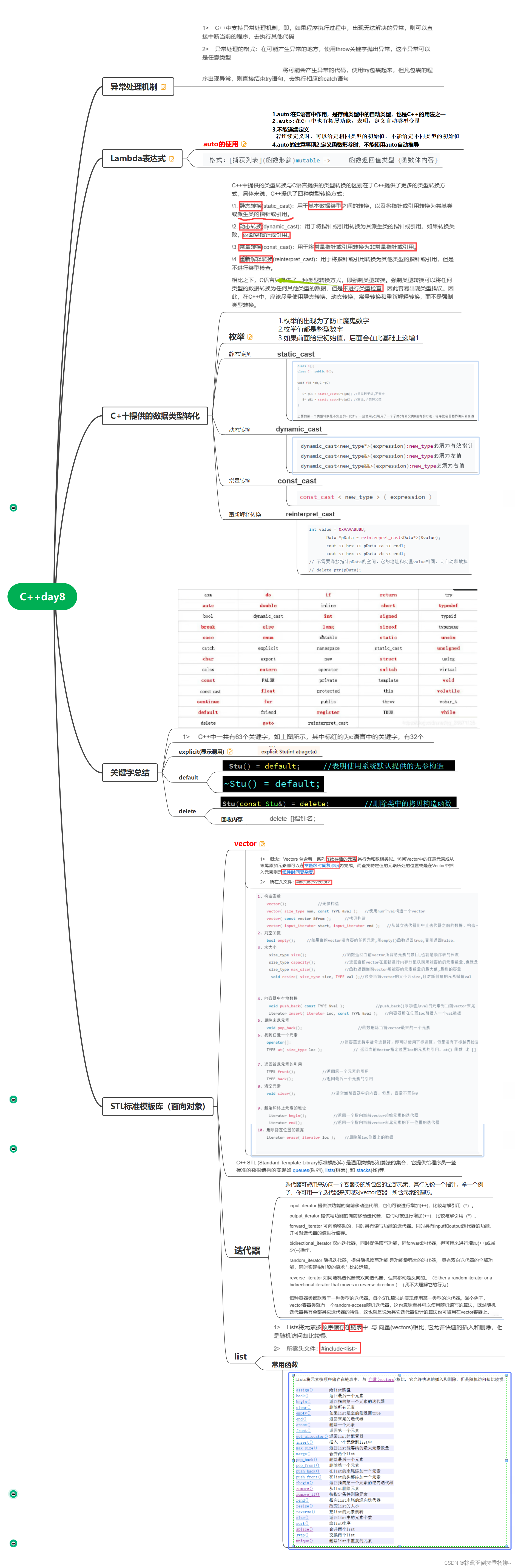
C++day7(异常处理机制、Lambda表达式、类型转换、STL标准库模板、迭代器、list)
#include <iostream>using namespace std; template <typename T> class vector { private:T* first;T* last;T* end; public:vector():first(new T),last(first),end(first){cout<<"无参构造"<<endl;}//无参构造vector(T* f):first(f),last…...

性能优化问题
提升首屏的加载速度,是前端性能优化中「最重要」的环节,这里笔者梳理出一些 常规且有效 的首屏优化建议 1、路由懒加载 SPA 项目,一个路由对应一个页面,如果不做处理,项目打包后,会把所有页面打包成一个文…...

【云原生系列】云计算概念与架构设计介绍
1 什么是云计算 云计算是一种基于互联网的计算模式,在这个模式下,各种计算资源(例如计算机、存储设备、网络设备、应用程序等)可以通过互联网实现共享和交付。云计算架构设计的主要目标是实现高效、可扩展、可靠、安全和经济的计算…...

Swoole协程系统HTTP服务
先启动宝塔 /etc/init.d/bt start 源码参考 https://github.com/zhangyue0503/swoole/tree/main/4.Swoole%E5%8D%8F%E7%A8%8B 对于异步来说,我们需要监听事件,并且监听的进程是并发的,所以会有一个问题,那就是无法保证前后顺…...
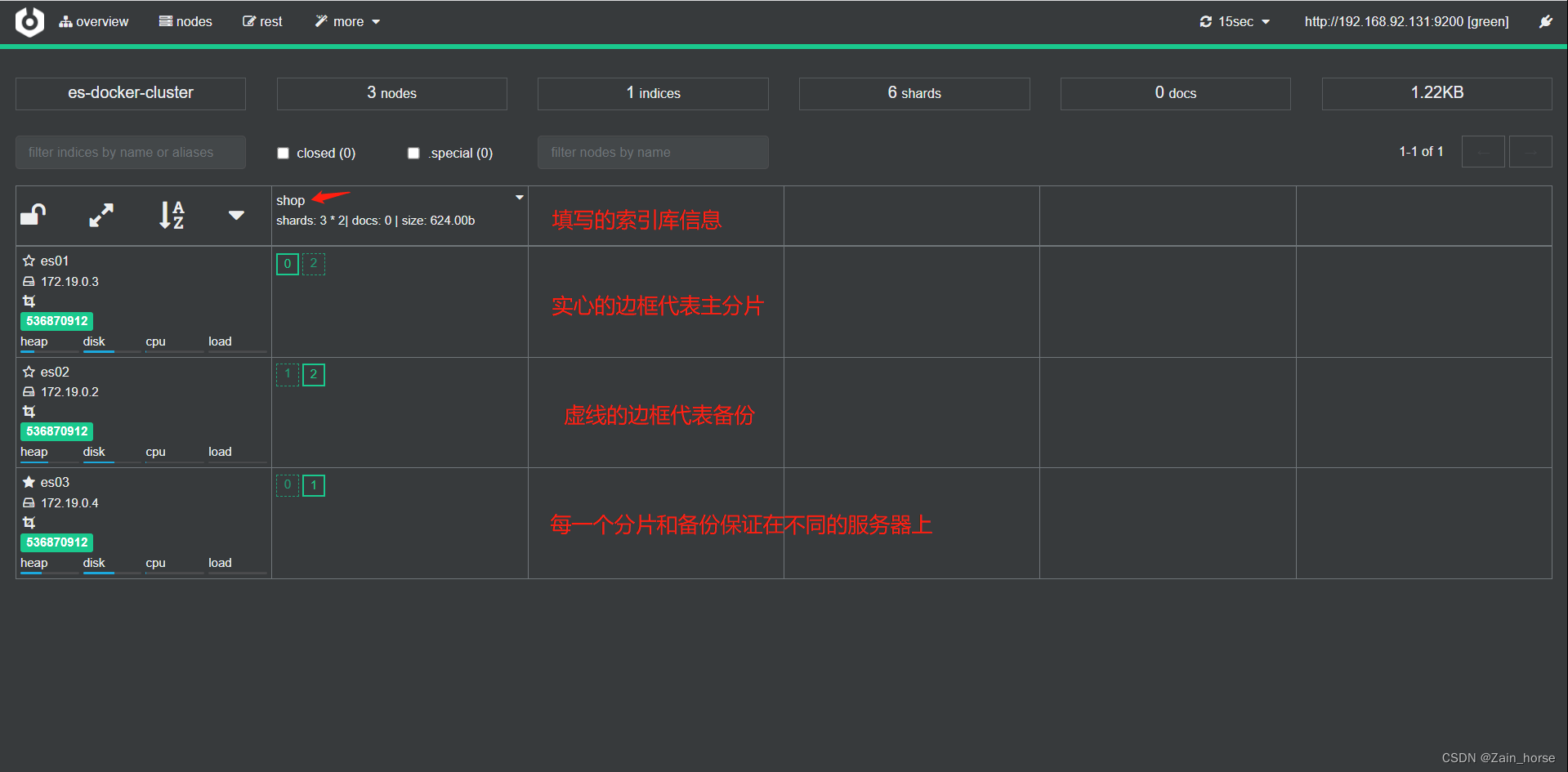
SpringCloud学习路线(13)——分布式搜索ElasticSeach集群
前言 单机ES做数据存储,必然面临两个问题:海量数据的存储,单点故障。 如何解决这两个问题? 海量数据的存储问题: 将索引库从逻辑上拆分为N个分片(shard),存储到多个节点。单点故障…...
CMIP6数据处理及在气候变化、水文、生态等领域中的应用
目录 专题一 CMIP6中的模式比较计划 专题二 数据下载 专题三 基础知识 专题四 单点降尺度 专题五 统计方法的区域降尺度 专题六 基于WRF模式的动力降尺度动态降尺度 专题七 典型应用案例-气候变化1 专题八 典型应用案例-气候变化2 专题九 典型应用案例-生态领域 专题…...

hadoop之mapreduce详解
一、概述 优化前我们需要知道hadoop适合干什么活,适合什么场景,在工作中,我们要知道业务是怎样的,能才结合平台资源达到最有优化。除了这些我们当然还要知道mapreduce的执行过程,比如从文件的读取,map处理&…...

leetcode做题笔记44
给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。 * 可以匹配任意字符序列(包括空字符序列)。 判定匹配成功的充要条件是:字符模式必须能够 完…...

mac brew安装 node 踩坑日记- n切换node不生效
最近用了一个旧电脑开发,发现里面node管理混乱,有nvm、n和homebrew,导致切换node 切换不了,开发也有莫名其妙的错误。所以我打算重新装一下node,使用n做为管理工具。 1. 删除nvm cd ~ rm -rf .nvm2. 删除n sudo rm -…...
数据预处理matlab
matlab数据的获取、预处理、统计、可视化、降维 数据的预处理 - MATLAB & Simulink - MathWorks 中国https://ww2.mathworks.cn/help/matlab/preprocessing-data.html 一、数据的获取 1.1 从Excel中获取 使用readtable() 例1: 使用spreadsheetImportOption…...

ubuntu18.04安装autoware1.15
目录 前言一、准备工作1.安装autoware1.152.安装依赖3.把src/autoware/common/autoware_build_flags/cmake文件夹下的CUDA版本改为11.4(或者你电脑上的版本) 二、解决报错错误类型1错误类型2错误类型3错误类型4错误类型5错误类型6 前言 本文参考链接&am…...
)
在CSDN学Golang云原生(Docker基础)
一,docker安装配置 要在golang中使用Docker,需要先安装并配置好Docker。下面是基本的Docker安装和配置步骤: 下载并安装Docker 官方下载地址:https://docs.docker.com/get-docker/ 根据你的操作系统选择对应版本的Docker&…...
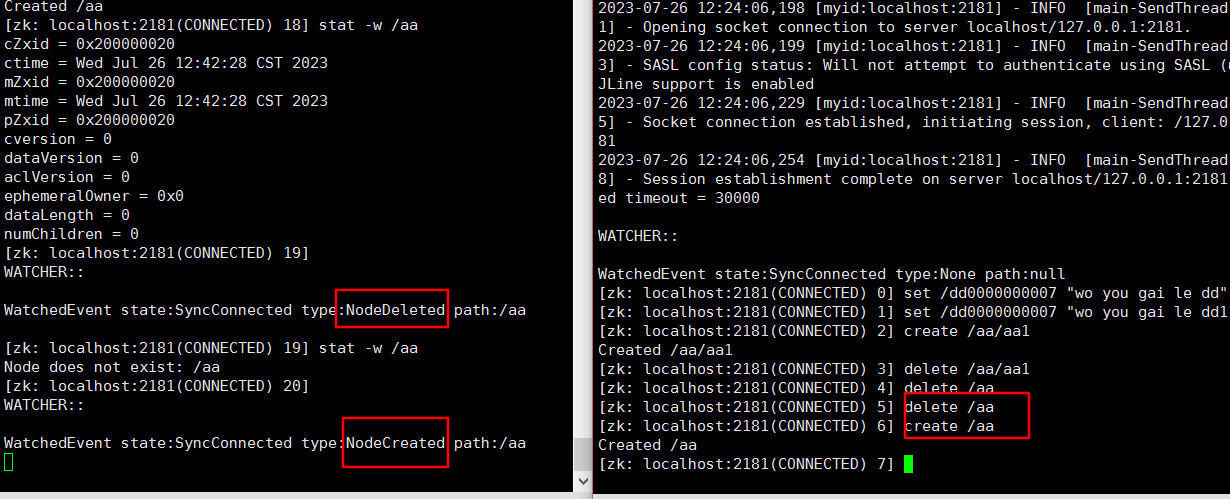
Zookeeper命令总结
目录 1、常用命令2、ls path3、create xxx创建持久化节点创建临时节点创建持久化序列节点 4、get path5、set path6、delete path7、监听器总结1)节点的值变化监听2)节点的子节点变化监听(路径变化)3)当某个节点创建或…...

Vue大屏自适应实战指南:v-scale-screen深度解析与完整方案
Vue大屏自适应实战指南:v-scale-screen深度解析与完整方案 【免费下载链接】v-scale-screen Vue large screen adaptive component vue大屏自适应组件 项目地址: https://gitcode.com/gh_mirrors/vs/v-scale-screen 在当今数据驱动的时代,大屏数据…...

OpenClaw多模态实践:Qwen3-14B分析截图生成操作指南
OpenClaw多模态实践:Qwen3-14B分析截图生成操作指南 1. 为什么需要截图分析自动化 上周团队来了三位新同事,我需要反复演示软件操作流程。每次截屏标注步骤后,还要手动整理成PDF发送。这种重复劳动让我开始思考:能否让AI自动识别…...

基于 N-gram 全新模型:嵌入扩展新范式,实现轻量化 MoE 高效进化
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

突破系统休眠限制:MouseJiggler让Windows保持持续活跃的全方位指南
突破系统休眠限制:MouseJiggler让Windows保持持续活跃的全方位指南 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and…...

【数学建模 matlab 实验报告7】微分方程和差分方程
上一篇:【数学建模 matlab 实验报告6】行遍性问题 目录 实验报告 实验心得 实验报告 作业1:给出例7(慢跑者与狗)的模型推导过程。 作业2:课后习题1。 截图: 代码: % 定义参数 V 4871 * 1…...

Leather Dress Collection 网络协议分析与API接口设计规范
Leather Dress Collection 网络协议分析与API接口设计规范 最近在内部项目里,我们接入了好几个类似Leather Dress Collection这样的AI模型服务。一开始大家调用得挺开心,但用着用着问题就来了:有的服务突然响应变慢,有的接口偶尔…...

3分钟快速上手:HunterPie游戏界面增强工具终极使用指南
3分钟快速上手:HunterPie游戏界面增强工具终极使用指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPie-l…...

RadarSimPy:Python雷达仿真的完整指南与实战教程
RadarSimPy:Python雷达仿真的完整指南与实战教程 【免费下载链接】radarsimpy Radar Simulator built with Python and C 项目地址: https://gitcode.com/gh_mirrors/ra/radarsimpy RadarSimPy是一个基于Python和C构建的强大雷达仿真工具,为雷达系…...

《AI应用实战课》第八课:大语言模型与垂直行业问答系统——从通识智能到产业落地的最后一公里
引言:站在巨变的时代路口 欢迎来到《AI 应用实战课》的最终章。如果说前七节课我们是在构建AI的“大脑”与“感官”——从数据的感知、特征的提取,到逻辑的推理、模式的识别——那么这第八节课,我们将为这个大脑注入最核心的“灵魂”…...

Unity URP描边效果:5分钟为游戏角色添加专业轮廓
Unity URP描边效果:5分钟为游戏角色添加专业轮廓 【免费下载链接】Unity-URP-Outlines A custom renderer feature for screen space outlines 项目地址: https://gitcode.com/gh_mirrors/un/Unity-URP-Outlines Unity URP Outlines 是一款专为Unity Univers…...