如何高效实现文件传输:小文件采用零拷贝、大文件采用异步io+直接io
一般会如何实现文件传输?
服务器提供文件传输功能,需要将磁盘上的文件读取出来,通过网络协议发送到客户端。如果需要你自己编码实现这个文件传输功能,你会怎么实现呢?
通常,你会选择最直接的方法:从网络请求中找出文件在磁盘中的路径后,如果这个文件比较大,假设有 320MB,可以在内存中分配 32KB 的缓冲区,再把文件分成一万份,每份只有 32KB,这样,从文件的起始位置读入 32KB 到缓冲区,再通过网络 API 把这 32KB 发送到客户端。接着重复一万次,直到把完整的文件都发送完毕。如下图所示:

不过这个方案性能并不好,主要有两个原因。
上下文切换:
首先,它至少经历了 4 万次用户态与内核态的上下文切换。因为每处理 32KB 的消息,就需要一次 read 调用和一次 write 调用,每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。可见,每处理 32KB,就有 4 次上下文切换,重复 1 万次后就有 4 万次切换。
上下文切换的成本并不小,虽然一次切换仅消耗几十纳秒到几微秒,但高并发服务会放大这类时间的消耗。
内存拷贝:
其次,这个方案做了 4 万次内存拷贝,对 320MB 文件拷贝的字节数也翻了 4 倍,到了 1280MB。很显然,过多的内存拷贝无谓地消耗了 CPU 资源,降低了系统的并发处理能力。
所以要想提升传输文件的性能,需要从降低上下文切换的频率和内存拷贝次数两个方向入手。
零拷贝如何提升文件传输性能?
首先,我们来看如何降低上下文切换的频率。
为什么读取磁盘文件时,一定要做上下文切换呢?这是因为,读取磁盘或者操作网卡都由操作系统内核完成。内核负责管理系统上的所有进程,它的权限最高,工作环境与用户进程完全不同。只要我们的代码执行 read 或者 write 这样的系统调用,一定会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
因此,如果想减少上下文切换次数,就一定要减少系统调用的次数。解决方案就是把 read、write 两次系统调用合并成一次,在内核中完成磁盘与网卡的数据交换。
其次,我们应该考虑如何减少内存拷贝次数。
每周期中的 4 次内存拷贝,其中与物理设备相关的 2 次拷贝是必不可少的,包括:把磁盘内容拷贝到内存,以及把内存拷贝到网卡。但另外 2 次与用户缓冲区相关的拷贝动作都不是必需的,因为在把磁盘文件发到网络的场景中,用户缓冲区没有必须存在的理由。
如果内核在读取文件后,直接把 PageCache 中的内容拷贝到 Socket 缓冲区,待到网卡发送完毕后,再通知进程,这样就只有 2 次上下文切换,和 3 次内存拷贝。

如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术,还可以再去除 Socket 缓冲区的拷贝,这样一共只有 2 次内存拷贝。
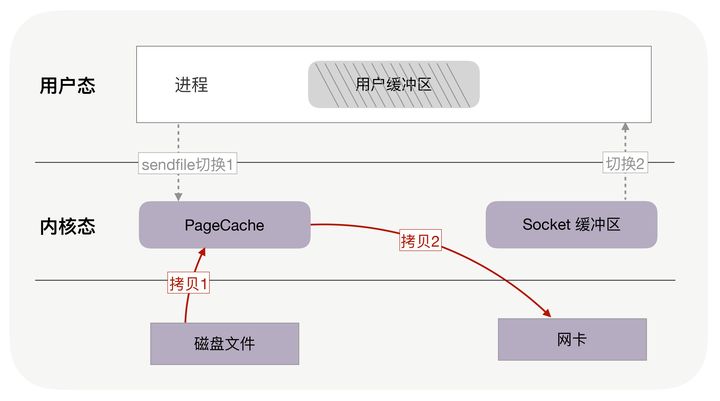
实际上,这就是零拷贝技术。
相关视频推荐
手写用户态协议栈以及零拷贝的实现
服务器性能优化,异步处理有哪些不一样的
用户态网络缓冲区设计-ringbuffer、chainbuffer
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

它是操作系统提供的新函数,同时接收文件描述符和 TCP socket 作为输入参数,这样执行时就可以不需要用户层缓存,完全在内核态完成内存拷贝,既减少了内存拷贝次数,也降低了上下文切换次数。
而且,零拷贝取消了用户缓冲区后,不只降低了用户内存的消耗,还通过最大化利用 socket 缓冲区中的内存,间接地再一次减少了系统调用的次数,从而带来了大幅减少上下文切换次数的机会!
你可以回忆下,没用零拷贝时,为了传输 320MB 的文件,在用户缓冲区分配了 32KB 的内存,把文件分成 1 万份传送,然而,这 32KB 是怎么来的?为什么不是 32MB 或者 32 字节呢?这是因为,在没有零拷贝的情况下,我们希望内存的利用率最高。如果用户缓冲区过大,它就无法一次性把消息全拷贝给 socket 缓冲区;如果用户缓冲区过小,则会导致过多的 read/write 系统调用。
那用户缓冲区为什么不与 socket 缓冲区大小一致呢?这是因为,socket 缓冲区的可用空间是动态变化的,它既用于 TCP 滑动窗口,也用于应用缓冲区,还受到整个系统内存的影响。尤其在长肥网络中,它的变化范围特别大。
零拷贝使我们不必关心 socket 缓冲区的大小。比如,调用零拷贝发送方法时,尽可以把发送字节数设为文件的所有未发送字节数,例如 320MB,也许此时 socket 缓冲区大小为 1.4MB,那么一次性就会发送 1.4MB 到客户端,而不是只有 32KB。这意味着对于 1.4MB 的 1 次零拷贝,仅带来 2 次上下文切换,而不使用零拷贝且用户缓冲区为 32KB 时,经历了 176 次(4 * 1.4MB/32KB)上下文切换。
综合上述各种优点,零拷贝可以把性能提升至少一倍以上!对文章开头提到的 320MB 文件的传输,当 socket 缓冲区在 1.4MB 左右时,只需要 4 百多次上下文切换,以及 4 百多次内存拷贝,拷贝的数据量也仅有 640MB,这样,不只请求时延会降低,处理每个请求消耗的 CPU 资源也会更少,从而支持更多的并发请求。
此外,零拷贝还使用了 PageCache 技术,通过它,零拷贝可以进一步提升性能,我们接下来看看 PageCache 是如何做到这一点的。
PageCache,磁盘高速缓存
回顾上文中的几张图,你会发现,读取文件时,是先把磁盘文件拷贝到 PageCache 上,再拷贝到进程中。为什么这样做呢?有两个原因所致。
第一,由于磁盘比内存的速度慢许多,所以我们应该想办法把读写磁盘替换成读写内存,比如把磁盘中的数据复制到内存中,就可以用读内存替换读磁盘。但是,内存空间远比磁盘要小,内存中注定只能复制一小部分磁盘中的数据。
选择哪些数据复制到内存呢?通常,刚被访问的数据在短时间内再次被访问的概率很高(这也叫“时间局部性”原理),用 PageCache 缓存最近访问的数据,当空间不足时淘汰最久未被访问的缓存(即 LRU 算法)。读磁盘时优先到 PageCache 中找一找,如果数据存在便直接返回,这便大大提升了读磁盘的性能。
第二,读取磁盘数据时,需要先找到数据所在的位置,对于机械磁盘来说,就是旋转磁头到数据所在的扇区,再开始顺序读取数据。其中,旋转磁头耗时很长,为了降低它的影响,PageCache 使用了预读功能。
也就是说,虽然 read 方法只读取了 0-32KB 的字节,但内核会把其后的 32-64KB 也读取到 PageCache,这后 32KB 读取的成本很低。如果在 32-64KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。这一讲的传输文件场景中这是必然发生的。
从这两点可以看到 PageCache 的优点,它在 90% 以上场景下都会提升磁盘性能,但在某些情况下,PageCache 会不起作用,甚至由于多做了一次内存拷贝,造成性能的降低。在这些场景中,使用了 PageCache 的零拷贝也会损失性能。
具体是什么场景呢?就是在传输大文件的时候。比如,你有很多 GB 级的文件需要传输,每当用户访问这些大文件时,内核就会把它们载入到 PageCache 中,这些大文件很快会把有限的 PageCache 占满。
然而,由于文件太大,文件中某一部分内容被再次访问到的概率其实非常低。这带来了 2 个问题:首先,由于 PageCache 长期被大文件占据,热点小文件就无法充分使用 PageCache,它们读起来变慢了;其次,PageCache 中的大文件没有享受到缓存的好处,但却耗费 CPU 多拷贝到 PageCache 一次。
所以,高并发场景下,为了防止 PageCache 被大文件占满后不再对小文件产生作用,大文件不应使用 PageCache,进而也不应使用零拷贝技术处理。
异步 IO + 直接 IO
高并发场景处理大文件时,应当使用异步 IO 和直接 IO 来替换零拷贝技术。
仍然回到本讲开头的例子,当调用 read 方法读取文件时,实际上 read 方法会在磁盘寻址过程中阻塞等待,导致进程无法并发地处理其他任务,如下图所示:
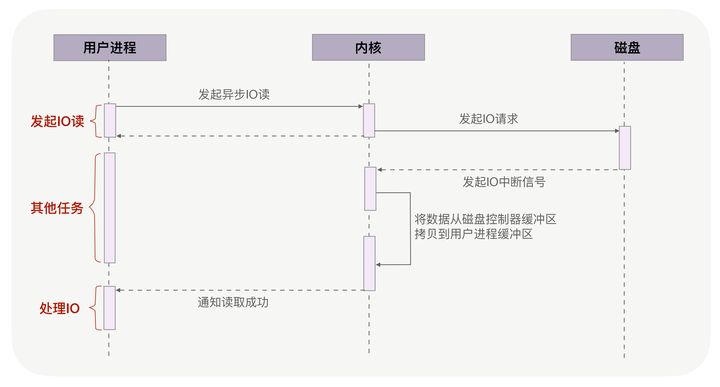
异步 IO(异步 IO 既可以处理网络 IO,也可以处理磁盘 IO,这里我们只关注磁盘 IO)可以解决阻塞问题。它把读操作分为两部分,前半部分向内核发起读请求,但不等待数据就位就立刻返回,此时进程可以并发地处理其他任务。当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据,这是异步 IO 的后半部分。如下图所示:

从图中可以看到,异步 IO 并没有拷贝到 PageCache 中,这其实是异步 IO 实现上的缺陷。经过 PageCache 的 IO 我们称为缓存 IO,它与虚拟内存系统耦合太紧,导致异步 IO 从诞生起到现在都不支持缓存 IO。
绕过 PageCache 的 IO 是个新物种,我们把它称为直接 IO。对于磁盘,异步 IO 只支持直接 IO。
直接 IO 的应用场景并不多,主要有两种:第一,应用程序已经实现了磁盘文件的缓存,不需要 PageCache 再次缓存,引发额外的性能消耗。比如 MySQL 等数据库就使用直接 IO;第二,高并发下传输大文件,我们上文提到过,大文件难以命中 PageCache 缓存,又带来额外的内存拷贝,同时还挤占了小文件使用 PageCache 时需要的内存,因此,这时应该使用直接 IO。
当然,直接 IO 也有一定的缺点。除了缓存外,内核(IO 调度算法)会试图缓存尽量多的连续 IO 在 PageCache 中,最后合并成一个更大的 IO 再发给磁盘,这样可以减少磁盘的寻址操作;另外,内核也会预读后续的 IO 放在 PageCache 中,减少磁盘操作。直接 IO 绕过了 PageCache,所以无法享受这些性能提升。
有了直接 IO 后,异步 IO 就可以无阻塞地读取文件了。现在,大文件由异步 IO 和直接 IO 处理,小文件则交由零拷贝处理,至于判断文件大小的阈值可以灵活配置(参见 Nginx 的 directio 指令)。
相关文章:
如何高效实现文件传输:小文件采用零拷贝、大文件采用异步io+直接io
一般会如何实现文件传输? 服务器提供文件传输功能,需要将磁盘上的文件读取出来,通过网络协议发送到客户端。如果需要你自己编码实现这个文件传输功能,你会怎么实现呢? 通常,你会选择最直接的方法…...

Docker运行MySQL5.7
步骤如下: 1.获取镜像: docker pull mysql:5.7 2.创建挂载目录: mkdir /home/mydata/data mkdir /home/mydata/log mkdir /home/mydata/conf 3.先启动docker把配置文件拷贝出来: docker run -it --name temp mysql:5.7 /bi…...

-jar和 javaagent命令冲突吗?
当使用 -jar 命令运行 Java 应用程序时,Java 虚拟机 (JVM) 会忽略任何设置的 -javaagent 命令。这是因为 -jar 命令会覆盖其他命令行选项,包括 -javaagent。 这是因为 -jar 命令是用于运行打包为 JAR 文件的 Java 应用程序的快捷方式。它会忽略其他命令…...

LLC和MAC子层的应用
计算机局域网标准IEEE802 由于局域网只是一个计算机通信网,而且局域网不存在路由选择问题,因此它不需要网络层,而只有最低的两个层次。然而局域网的种类繁多,其媒体接入控制的方法也各不相同。 为了使局域网中的数据链路层不致过…...
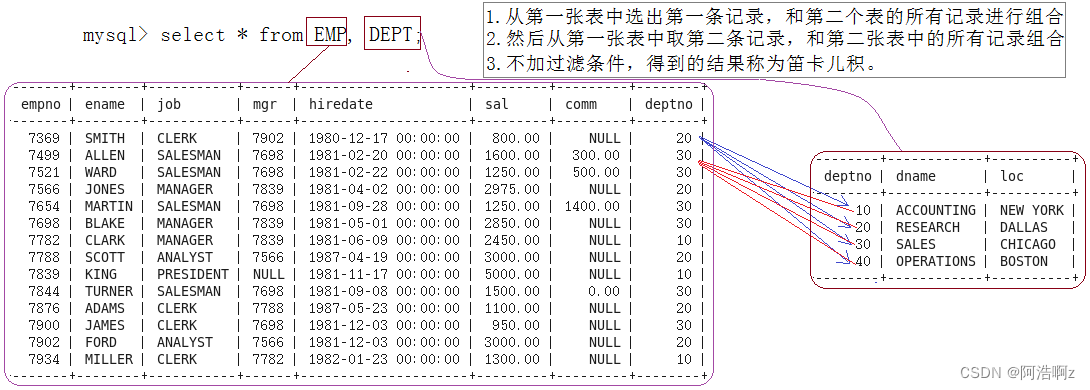
【MySQL】之复合查询
【MySQL】之复合查询 基本查询多表查询笛卡尔积自连接子查询单行子查询多行子查询多列子查询在from子句中使用子查询 合并查询小练习 基本查询 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J按照部门号升序而雇员的工资降序排序使用…...
Vue系列第五篇:Vue2(Element UI) + Go(gin框架) + nginx开发登录页面及其校验登录功能
本篇使用Vue2开发前端,Go语言开发服务端,使用nginx代理部署实现登录页面及其校验功能。 目录 1.部署结构 2.Vue2前端 2.1代码结构 2.1源码 3.Go后台服务 3.2代码结构 3.2 源码 3.3单测效果 4.nginx 5.运行效果 6.问题总结 1.部署结构 2.Vue2…...
u盘里的数据丢失怎么恢复 u盘数据丢失怎么恢复
在使用U盘的时候不知道大家有没有经历过数据丢失或者U盘提示格式化的情况呢?U盘使用久了就会遇到各种各样的问题,而关于U盘数据丢失,大家又知道多少呢?当数据丢失了,我们应该怎样恢复数据?这个问题困扰了很…...

Mysql-约束
约束 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。 目的:保证数据库中数据的正确、有效性和完整性。 分类: 约束描述关键字非空约束限制该字段的数据不能为nullNOT NULL唯一约束保证该字段的所有数据都是唯一…...

数据结构问答7
1. 图的定义和相关术语 答: 定义:图是由顶点集V和边集E组成,其中V为有限非空集。 相关术语:n个顶点,e条边,G=(V,E) ① 邻接点和端点:无向图中,若存在一条边(i, j),则称i,j为该边的端点,且它们互为邻接点;在有向图中,若存在一条边<i, j>,则称i,j分别为…...

[Spark] 大纲
1、Spark任务提交流程 2、SparkSQL执行流程 2.1 RBO,基于规则的优化 2.2 CBO,基于成本的优化 3、Spark性能调优 3.1 固定资源申请和动态资源分配 3.2 数据倾斜常见解决方法 3.3 小文件优化 4、Spark 3.0 4.1 动态分区裁剪(Dynamic Partition Pr…...
【NLP】使用 Keras 保存和加载深度学习模型
一、说明 训练深度学习模型是一个耗时的过程。您可以在训练期间和训练后保存模型进度。因此,您可以从上次中断的地方继续训练模型,并克服漫长的训练挑战。 在这篇博文中,我们将介绍如何保存模型并使用 Keras 逐步加载它。我们还将探索模型检查…...

视频标注是什么?和图像数据标注的区别?
视频数据标注是对视频剪辑进行标注的过程。进行标注后的视频数据将作为训练数据集用于训练深度学习和机器学习模型。这些预先训练的神经网络之后会被用于计算机视觉领域。 自动化视频标注对训练AI模型有哪些优势 与图像数据标注类似,视频标注是教计算机识别对象…...
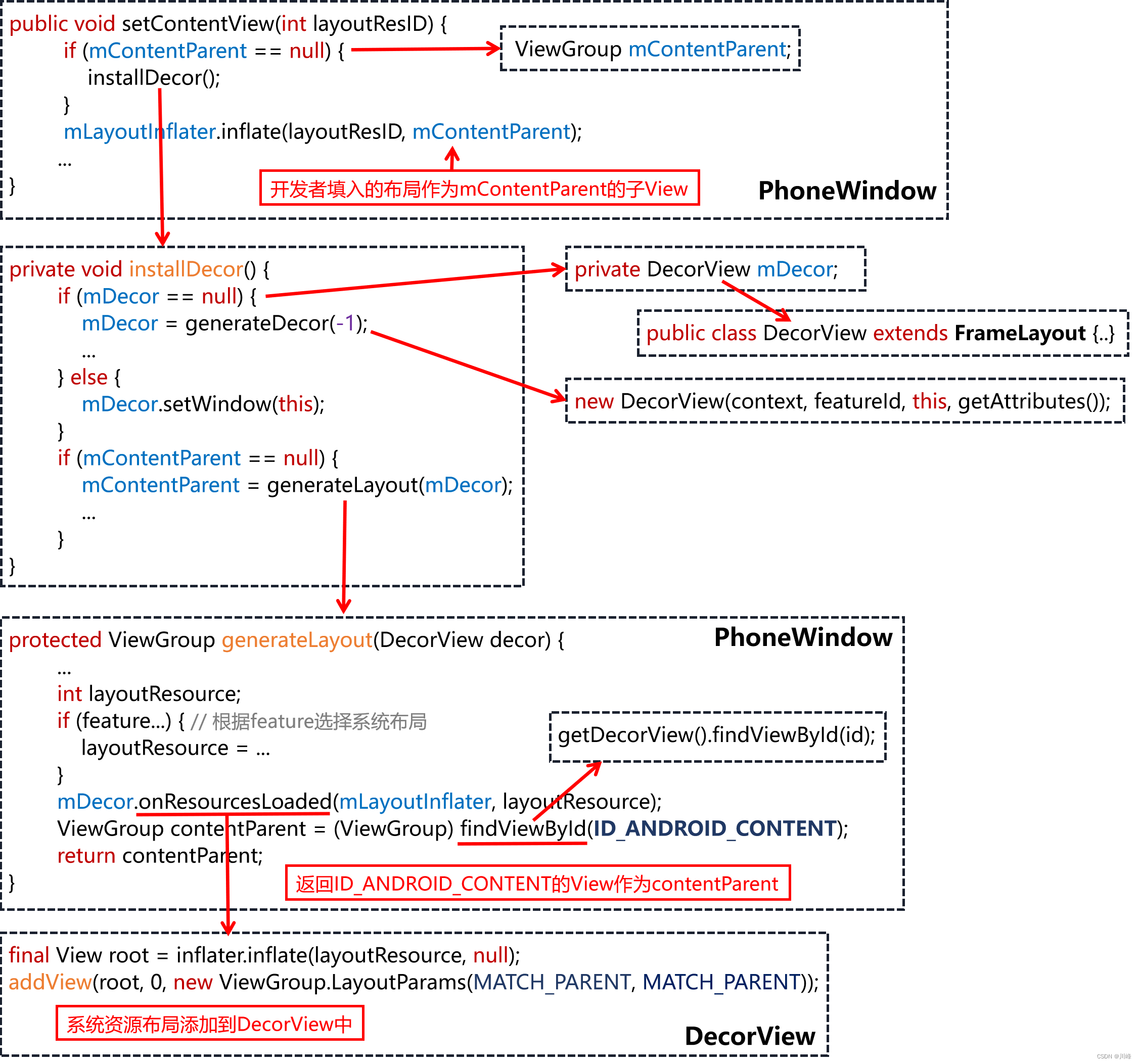
【Android知识笔记】UI体系(一)
Activity的显示原理 setContentView 首先开发者Activity的onCreate方法中通常调用的setContentView会委托给Window的setContentView方法: 接下来看Window的创建过程: 可见Window的实现类是PhoneWindow,而PhoneWindow是在Activity创建过程中执行attach Context的时候创建的…...

SpringBoot 整合Docker Compose
Docker Compose是一种流行的技术,可以用来定义和管理你的应用程序所需的多个服务容器。通常在你的应用程序旁边创建一个 compose.yml 文件,它定义和配置服务容器。 使用 Docker Compose 的典型工作流程是运行 docker compose up,用它连接启动…...
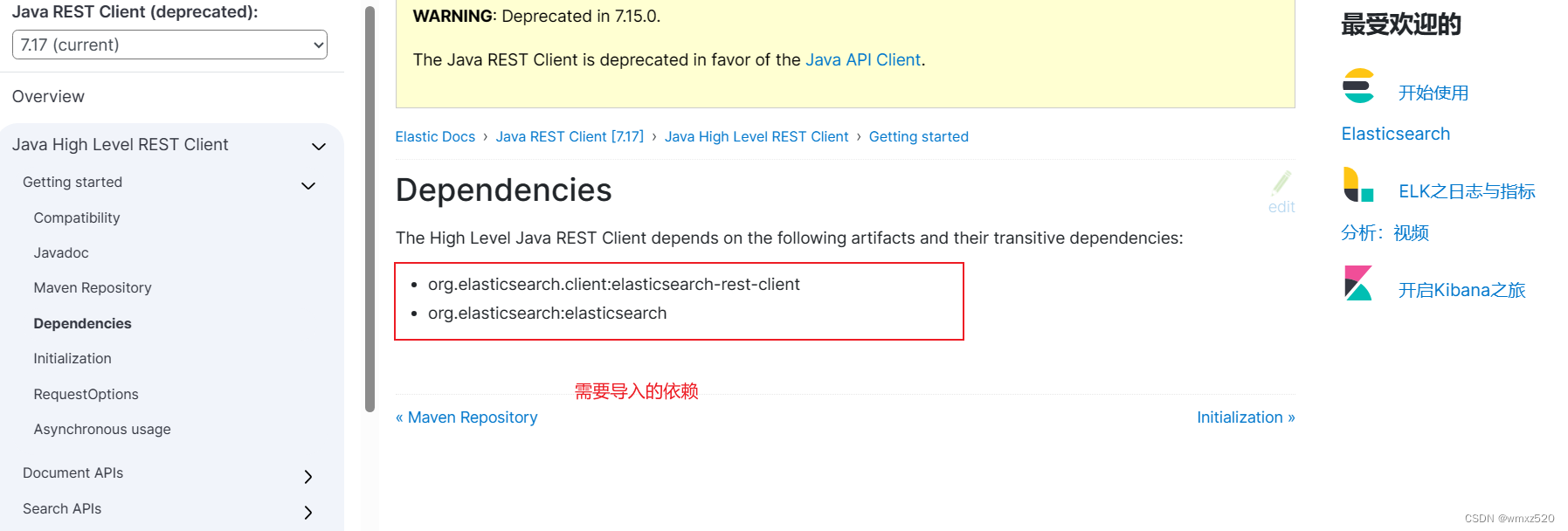
SpringBoot整合Elasticsearch
SpringBoot整合Elasticsearch SpringBoot整合Elasticsearch有以下几种方式: 使用官方的Elasticsearch Java客户端进行集成 通过添加Elasticsearch Java客户端的依赖,可以直接在Spring Boot应用中使用原生的Elasticsearch API进行操作。参考文档 使用Sp…...

【R3F】0.9添加 shadow
开启使用shadow 在 canvas 设置属性shadows 在对应的 mesh 中设置 产生阴影castShadow和接收阴影receiveShadow 设置完成之后,即可实现阴影 ...<Canvas shadows > <mesh castShadow ><boxGeometry /><meshStandardMaterial color="mediumpurple&qu…...
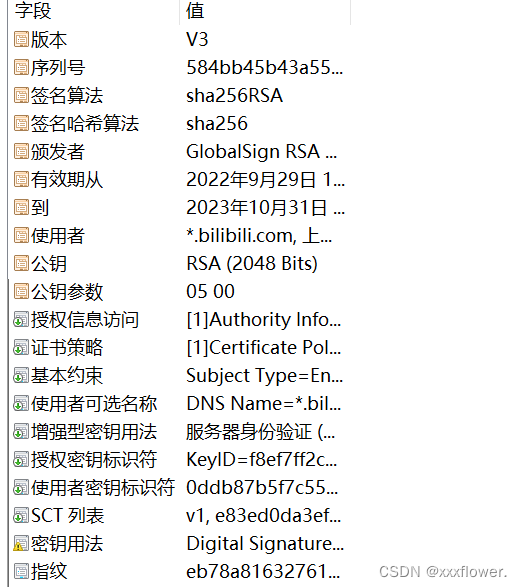
【JavaEE初阶】HTTP请求的构造及HTTPS
文章目录 1.HTTP请求的构造1.1 from表单请求构造1.2 ajax构造HTTP请求1.3 Postman的使用 2. HTTPS2.1 什么是HTTPS?2.2 HTTPS中的加密机制(SSL/TLS)2.2.1 HTTP的安全问题2.2.2 对称加密2.2.3 非对称加密2.2.3 中间人问题2.2.5 证书 1.HTTP请求的构造 常见的构造HTTP 请求的方…...

探索和实践:基于Python的TD-PSOLA语音处理算法应用与优化
今天我将和大家分享一个非常有趣且具有挑战性的主题:TD-PSOLA语音处理算法在Python中的应用。作为一种在语音合成和变换中广泛使用的技术,TD-PSOLA (Time-Domain Pitch-Synchronous Overlap-Add) 提供了一种改变语音音高和时间长度而不产生显著失真的有效方法。在本篇博客中,…...
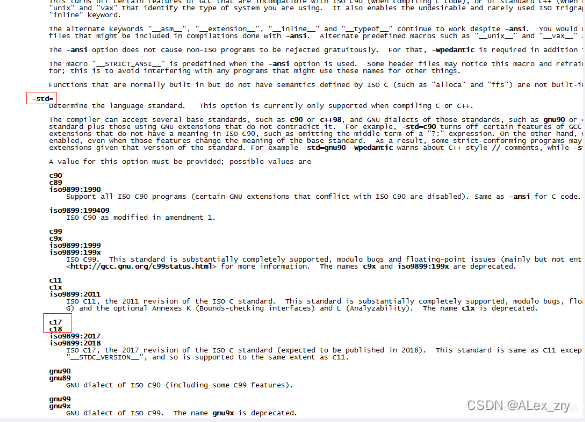
Linux 下centos 查看 -std 是否支持 C17
实际工作中,可能会遇到c的一些高级特性,例如std::invoke,此函数是c17才引入的,如何判断当前的gcc是否支持c17呢,这里提供两种办法。 1.根据gcc的版本号来推断 gcc --version,可以查看版本号,笔者…...

【算法训练营】字符串转成整数
字符串转成整数 题目题解代码 题目 点击跳转: 把字符串转换为整数 题解 【题目解析】: 本题本质是模拟实现实现C库函数atoi,不过参数给的string对象 【解题思路】: 解题思路非常简单,就是上次计算的结果10,相当于10…...

OpCore Simplify:智能化系统定制的突破与实践
OpCore Simplify:智能化系统定制的突破与实践 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 为什么超过68%的开发者在首次配置OpenCore E…...

3大维度掌握Ryujinx:Switch模拟器从配置到优化的全流程指南
3大维度掌握Ryujinx:Switch模拟器从配置到优化的全流程指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx作为一款用C#编写的开源Switch模拟器,为玩家…...

如何彻底告别网盘下载烦恼:八大主流网盘直链下载助手完全指南
如何彻底告别网盘下载烦恼:八大主流网盘直链下载助手完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

`android.hardware.camera2.params` 是 Android Camera2 API 中用于封装相机参数配置的包
android.hardware.camera2.params 是 Android Camera2 API 中用于封装相机参数配置的包,主要包含与相机捕获请求(CaptureRequest)和输出结果(CaptureResult)相关的参数类。这些类定义了各种可配置的相机控制参数&#…...

Nano-Banana Studio效果展示:针织帽微观结构拆解与纹理还原
Nano-Banana Studio效果展示:针织帽微观结构拆解与纹理还原 1. 引言:当AI成为你的产品设计师 想象一下,你手里有一顶普通的针织帽。你能看到它的颜色、款式,甚至能摸到它的质感。但如果我让你把这顶帽子“拆开”,把每…...

kys-cpp代码规范与最佳实践:如何编写高质量的C++游戏代码
kys-cpp代码规范与最佳实践:如何编写高质量的C游戏代码 【免费下载链接】kys-cpp 《金庸群侠传》c复刻版,已完工 项目地址: https://gitcode.com/gh_mirrors/ky/kys-cpp kys-cpp作为《金庸群侠传》的C复刻版项目,其代码质量直接影响游…...

AWPortrait-Z问题解决:图像模糊、速度慢?常见问题一键搞定
AWPortrait-Z问题解决:图像模糊、速度慢?常见问题一键搞定 1. 快速诊断:你的问题属于哪一类? 在使用AWPortrait-Z生成人像时,最常见的问题可以归纳为三类: 图像质量问题:模糊、失真、细节不足…...

终极指南:5步彻底解决显卡驱动残留问题
终极指南:5步彻底解决显卡驱动残留问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller 你是否曾经…...

3分钟快速破解:百度网盘提取码智能获取工具终极指南
3分钟快速破解:百度网盘提取码智能获取工具终极指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到加密资源都要手动搜索,既耗时又低效。…...

AI头像生成器效果展示:支持‘敦煌飞天纹样+半透明纱衣+暖光侧逆光’复杂提示
AI头像生成器效果展示:支持敦煌飞天纹样半透明纱衣暖光侧逆光复杂提示 当传统艺术遇见AI技术,会碰撞出怎样的视觉奇迹? 1. 惊艳开场:从想象到现实的艺术跨越 你有没有遇到过这样的困扰:心中有一个绝美的头像创意&…...