Python爬虫+数据可视化:分析唯品会商品数据
目录
- 前言
- 数据来源分析
- 1. 明确需求
- 2. 抓包分析:通过浏览器自带工具: 开发者工具
- 代码实现步骤: 发送请求 -> 获取数据 -> 解析数据 -> 保存数据
- 发送请求
- 解析数据
- 保存数据
- 数据可视化
- 先读取数据
- 泳衣商品性别占比
- 商品品牌分布占比
- 各大品牌商品售价平均价格
- 各大品牌商品原价平均价格
- 唯品会泳衣商品售价价格区间
前言
唯品会是中国领先的在线特卖会电商平台之一,它以“品牌特卖会”的模式运营,为会员提供品牌折扣商品。唯品会的商品包括服装、鞋类、箱包、美妆、家居、母婴、食品等各类品牌产品。
这就是今天的受害者,我们要拿取上面的泳衣数据,然后可以做些数据可视化
数据来源分析
1. 明确需求
- 明确采集网站以及数据
网址: https://category.vip.com/suggest.php?keyword=%E6%B3%B3%E8%A1%A3&ff=235|12|1|1
数据: 商品信息
2. 抓包分析:通过浏览器自带工具: 开发者工具
- 打开开发者工具: F12 / 右键点击检查选择network
- 刷新网页: 让网页数据重新加载一遍
- 搜索关键字: 搜索数据在哪里
找到数据包: 50条商品数据信息
整页数据内容: 120条 --> 分成三个数据包
1. 前50条数据 --> 前50个商品ID
2. 中50条数据 --> 中50个商品ID
3. 后20条数据 --> 后20个商品ID
已知: 数据分为三组 --> 对比三组数据包请求参数变化规律
请求参数变化规律: 商品ID
分析找一下 是否存在一个数据包, 包含所有商品ID
如果想要获取商品信息 --> 先获取所有商品ID --> ID存在数据包
代码实现步骤: 发送请求 -> 获取数据 -> 解析数据 -> 保存数据
发送请求
我们定义了要爬取的URL地址,并设置了User-Agent请求头,以模拟浏览器发送请求。
使用requests.get方法发送GET请求,并将响应保存在response变量中。
headers = {# 防盗链 告诉服务器请求链接地址从哪里跳转过来'Referer': 'https://category.vip.com/',# 用户代理, 表示浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
}
# 请求链接
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank'
data = {# 回调函数# 'callback': 'getMerchandiseIds','app_name': 'shop_pc','app_version': '4.0','warehouse': 'VIP_HZ','fdc_area_id': '104103101','client': 'pc','mobile_platform': '1','province_id': '104103','api_key': '70f71280d5d547b2a7bb370a529aeea1','user_id': '','mars_cid': '1689245318776_e2b4a7b51f99b3dd6a4e6d356e364148','wap_consumer': 'a','standby_id': 'nature','keyword': '泳衣','lv3CatIds': '','lv2CatIds': '','lv1CatIds': '','brandStoreSns': '','props': '','priceMin': '','priceMax': '','vipService': '','sort': '0','pageOffset': '0','channelId': '1','gPlatform': 'PC','batchSize': '120','_': '1689250387620',
}
# 发送请求 --> <Response [200]> 响应对象
response = requests.get(url=url, params=data, headers=headers)
解析数据
然后,我们定义了起始标签和结束标签,通过循环的方式遍历文本,并提取每个商品的名称和价格。
# 商品ID -> 120个
products = [i['pid'] for i in response.json()['data']['products']]
# 把120个商品ID 分组 --> 切片 起始:0 结束:50 步长:1
# 列表合并成字符串
product_id_1 = ','.join(products[:50]) # 提取前50个商品ID 0-49
product_id_2 = ','.join(products[50:100]) # 提取中50个商品ID 50-99
product_id_3 = ','.join(products[100:]) # 提取后20个商品ID 100到最后
product_id_list = [product_id_1, product_id_2, product_id_3]for product_id in product_id_list:# 请求链接link = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2'# 请求参数params = {# 'callback': 'getMerchandiseDroplets2','app_name': 'shop_pc','app_version': '4.0','warehouse': 'VIP_HZ','fdc_area_id': '104103101','client': 'pc','mobile_platform': '1','province_id': '104103','api_key': '70f71280d5d547b2a7bb370a529aeea1','user_id': '','mars_cid': '1689245318776_e2b4a7b51f99b3dd6a4e6d356e364148','wap_consumer': 'a','productIds': product_id,'scene': 'search','standby_id': 'nature','extParams': '{"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2","exclusivePrice":"1","iconSpec":"2x","ic2label":1,"superHot":1,"bigBrand":"1"}','context': '','_': '1689250387628',}# 发送请求json_data = requests.get(url=link, params=params, headers=headers).json()for index in json_data['data']['products']:# 商品信息attr = ','.join([j['value'] for j in index['attrs']])# 创建字典dit = {'标题': index['title'],'品牌': index['brandShowName'],'原价': index['price']['marketPrice'],'售价': index['price']['salePrice'],'折扣': index['price']['mixPriceLabel'],'商品信息': attr,'详情页': f'https://detail.vip.com/detail-{index["brandId"]}-{index["productId"]}.html',}csv_writer.writerow(dit)print(dit)
保存数据
然后,我们使用open函数创建一个CSV文件,并指定文件名、写入模式、编码方式等参数。然后使用csv.DictWriter初始化一个写入器对象,并指定表头。
我们使用writer.writeheader()来写入CSV文件的表头,然后遍历items列表,使用writer.writerow()将每个商品的数据写入CSV文件中。
f = open('商品.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题','品牌','原价','售价','折扣','商品信息','详情页',
])
csv_writer.writeheader()
数据可视化
先读取数据
df = pd.read_csv('商品.csv')
df.head()

泳衣商品性别占比
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Fakerc = (Bar().add_xaxis(sex_type).add_yaxis("", sex_num).set_global_opts(title_opts=opts.TitleOpts(title="泳衣商品性别占比", subtitle=""),brush_opts=opts.BrushOpts(),)
)
c.load_javascript()

from pyecharts import options as opts
from pyecharts.charts import Piec = (Pie().add("", [list(z) for z in zip(sex_type, sex_num)]).set_global_opts(title_opts=opts.TitleOpts(title="泳衣商品性别占比")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()

商品品牌分布占比
shop_num = df['品牌'].value_counts().to_list()
shop_type = df['品牌'].value_counts().index.to_list()
c = (Pie().add("",[list(z)for z in zip(shop_type, shop_num)],center=["40%", "50%"],).set_global_opts(title_opts=opts.TitleOpts(title="商品品牌分布占比"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()

各大品牌商品售价平均价格
# 按城市分组并计算平均薪资
avg_salary = df.groupby('品牌')['售价'].mean()
ShopType = avg_salary.index.tolist()
ShopNum = [int(a) for a in avg_salary.values.tolist()]
# 创建柱状图实例
c = (Bar().add_xaxis(ShopType).add_yaxis("", ShopNum).set_global_opts(title_opts=opts.TitleOpts(title="各大品牌商品售价平均价格"),visualmap_opts=opts.VisualMapOpts(dimension=1,pos_right="5%",max_=30,is_inverse=True,),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度).set_series_opts(label_opts=opts.LabelOpts(is_show=False),markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="min", name="最小值"),opts.MarkLineItem(type_="max", name="最大值"),opts.MarkLineItem(type_="average", name="平均值"),]),)
)c.render_notebook()

各大品牌商品原价平均价格
# 按城市分组并计算平均薪资
avg_salary = df.groupby('品牌')['原价'].mean()
ShopType_1 = avg_salary.index.tolist()
ShopNum_1 = [int(a) for a in avg_salary.values.tolist()]
# 创建柱状图实例
c = (Bar().add_xaxis(ShopType_1).add_yaxis("", ShopNum_1).set_global_opts(title_opts=opts.TitleOpts(title="各大品牌商品原价平均价格"),visualmap_opts=opts.VisualMapOpts(dimension=1,pos_right="5%",max_=30,is_inverse=True,),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度).set_series_opts(label_opts=opts.LabelOpts(is_show=False),markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="min", name="最小值"),opts.MarkLineItem(type_="max", name="最大值"),opts.MarkLineItem(type_="average", name="平均值"),]),)
)c.render_notebook()

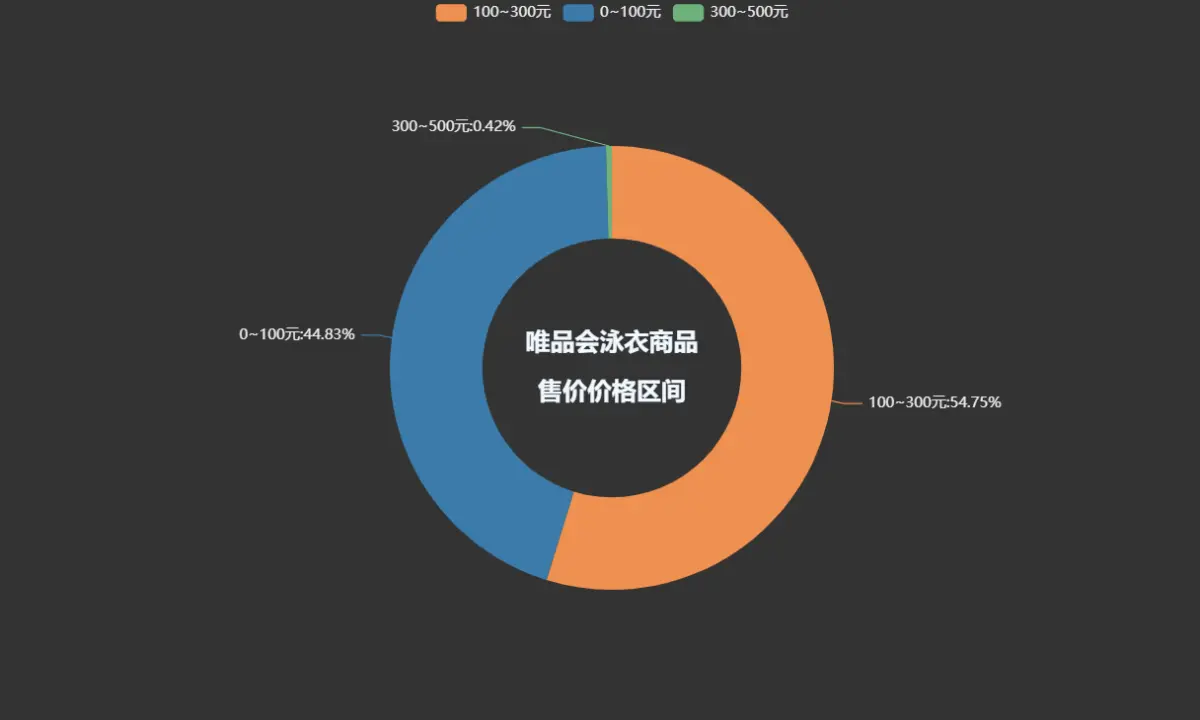
唯品会泳衣商品售价价格区间
pie1 = (Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px')).add('', datas_pair_2, radius=['35%', '60%']).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="唯品会泳衣商品\n\n售价价格区间", pos_left='center', pos_top='center',title_textstyle_opts=opts.TextStyleOpts(color='#F0F8FF', font_size=20, font_weight='bold'),)).set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()
👇问题解答 · 源码获取 · 技术交流 · 抱团学习请联系👇
相关文章:
Python爬虫+数据可视化:分析唯品会商品数据
目录 前言数据来源分析1. 明确需求2. 抓包分析:通过浏览器自带工具: 开发者工具 代码实现步骤: 发送请求 -> 获取数据 -> 解析数据 -> 保存数据发送请求解析数据保存数据 数据可视化先读取数据泳衣商品性别占比商品品牌分布占比各大品牌商品售价平均价格各…...
el-tree数据渲染超出省略
el-tree数据渲染超出省略 问题 <el-tree:data"deptOptions":props"defaultProps":expand-on-click-node"false":filter-node-method"filterNode"ref"tree"default-expand-allhighlight-currentnode-click"handleNo…...

若依vue -【 44】
44 服务监控讲解 1 需求 显示CPU、内存、服务器信息、Java虚拟机信息、磁盘状态的信息 2 前端 RuoYi-Vue\ruoyi-ui\src\views\monitor\server\index.vue <script> import { getServer } from "/api/monitor/server";export default {name: "Server&quo…...
)
React 基础篇(一)
💻 React 基础篇(一)🏠专栏:React 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享方向:目前主攻…...
Bean 的作用域和生命周期
目录 什么是 Bean 的作用域 ?Bean 的六种作用域Spring 的执行流程Bean 的生命周期 什么是 Bean 的作用域 ? Bean 的作⽤域是指 Bean 在 Spring 整个框架中的某种⾏为模式,⽐如 singleton 单例作⽤域,就表示 Bean 在整个 Spring 中只有⼀份,…...
)
STP和MTP(第二十二课)
2、如何实现 1)在MSTP网络种,引入了域的概念,称为MST域 2)每一个MST域中包含一个或多个“生成树”称为“实例” 3)每个“实例生成树”都可以绑定vlan,实现vlan数据流的负载分担/负载均衡 4)默认情况下,所有的vlan都属于“实例树0:即:instance 0” 5)不同的“实例…...

Java-WebSocket
请点击下面工程名称,跳转到代码的仓库页面,将工程 下载下来 Demo Code 里有详细的注释 TestWebSocket...

elementui的el-date-picker选择日期范围第二个不能早于第一个
选择日期范围第二个不能早于第一个 <el-form-item label"预计施工时间:" required><el-form:model"form":rules"constructionDateRules"ref"constructionRef"inline:hide-required-asterisk"false"><el-form…...

【NLP】无服务器问答系统
一、说明 在NLP的眼见的应用,就是在“ 当你在谷歌上提出一个问题并立即得到答案时会发生什么?例如,如果我们在谷歌搜索中询问谁是美国总统,我们会得到以下回答:Joe Biden;这是一个搜索问题,同时…...
Dubbo
Dubbo 简介Dubbo的快速入门Dubbo的基本架构安装DubboAdmin入门案例Dubbo的最佳实践 Dubbo的高级特性启动检查多版本超时与重试负载均衡SpringCloud整合Dubbo案例 简介 Dubbo是阿里巴巴公司开源的一个高性能、轻量级的Java RPC框架。 致力于提高性能和透明化的RPC远程服务调用方…...
模式)
Java设计模式之策略(Strategy)模式
策略(Strategy)设计模式定义了一系列算法,将它们封装起来,并且可以相互替换使用,从而使得算法可以独立于使用它的客户而变化。 什么是策略模式 策略(Strategy)设计模式是一种行为型设计模式&a…...

Vue引入CDN JS或本地JS文件之后 使用报错
加载问题 正常情况 在public引入script - js文件加载 - 写入内存 - 使用 但使用之前 有可能这个文件还没执行写入内存或者还未加载完毕 此时 需要一个promiss解决 1. 引入script 在 public / index.html 文件内引入你的script标签 <script type"text/javascript"…...

NRF52832-扩展广播
nordic论坛 我想要设置广播名称为 “一二三四五”,当广播名称为FULL_NAME时,但是广播显示还是“一?”,“?”是乱码,后来打开nrf connect观察广播,在没连接的时候,点击一下࿰…...
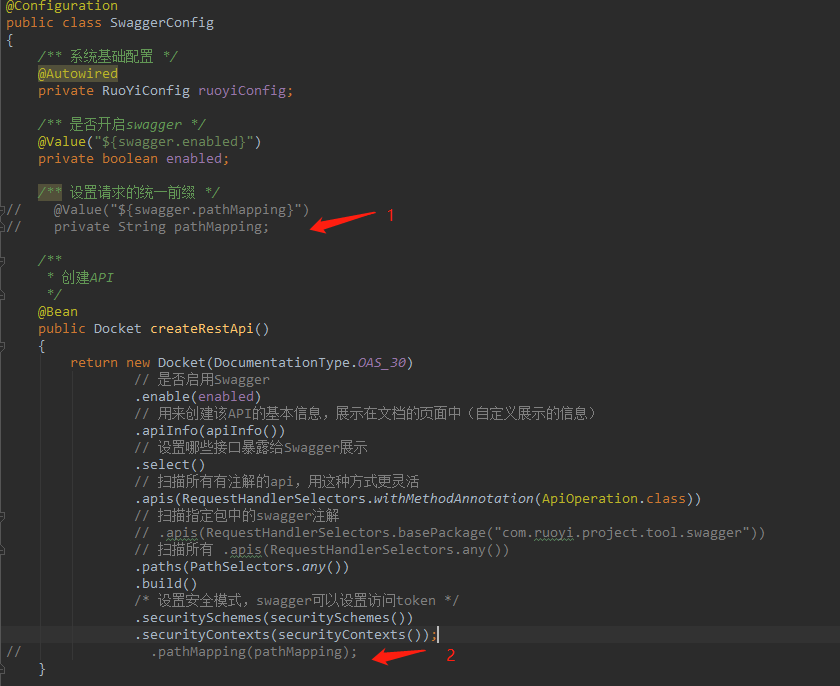
springboot项目新增子module
1. 拉取项目 2. file-new-module 3. 选择版本 4. 1-2-3-4 5. 注释请求统一前缀 (SwaggerConfig.java)...
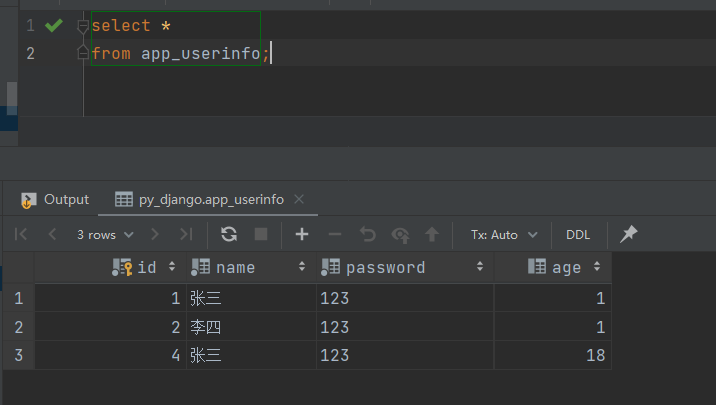
Python Web 开发及 Django 总结
title: Python Web 开发及 Django 总结 date: 2023-07-24 17:26:26 tags: PythonWeb categories:Python cover: https://cover.png feature: false Python 基础部分见:Python 基础总结 1. 创建项目 1.1 命令行 1、下载安装 Django 在终端输入 pip install djan…...

《向量数据库指南》:向量数据库Pinecone故障排除
目录 无法pip安装 空闲后索引丢失 上传缓慢或延迟高 批处理带来的高查询延迟 使用gRPC客户端进行Upsert限流 Pods已满 安全问题 CORS错误 本节介绍常见问题以及如何解决它们。需要帮助吗?在我们的支持论坛中提问。标准、企业和专用客户还可以联系支持人员寻求帮助。...

[86] 分割链表
题目链接:86. 分隔链表 - 力扣(LeetCode) 第一种方法:类似双指针 自己想的,不知道读者是否能看懂,参考注释 ListNode* partition(ListNode* head, int x) {ListNode* bigpos nullptr;ListNode* littlep…...

【python】 清空socket缓冲区
在Python中使用Socket进行网络通信时,可以通过调用socket.recv()函数来接收数据,数据会被存储在缓冲区中。有时候,可能想要先清空缓冲区,以便后续的数据不会被之前的数据影响。以下是一种清空Python Socket缓冲区的方法࿱…...
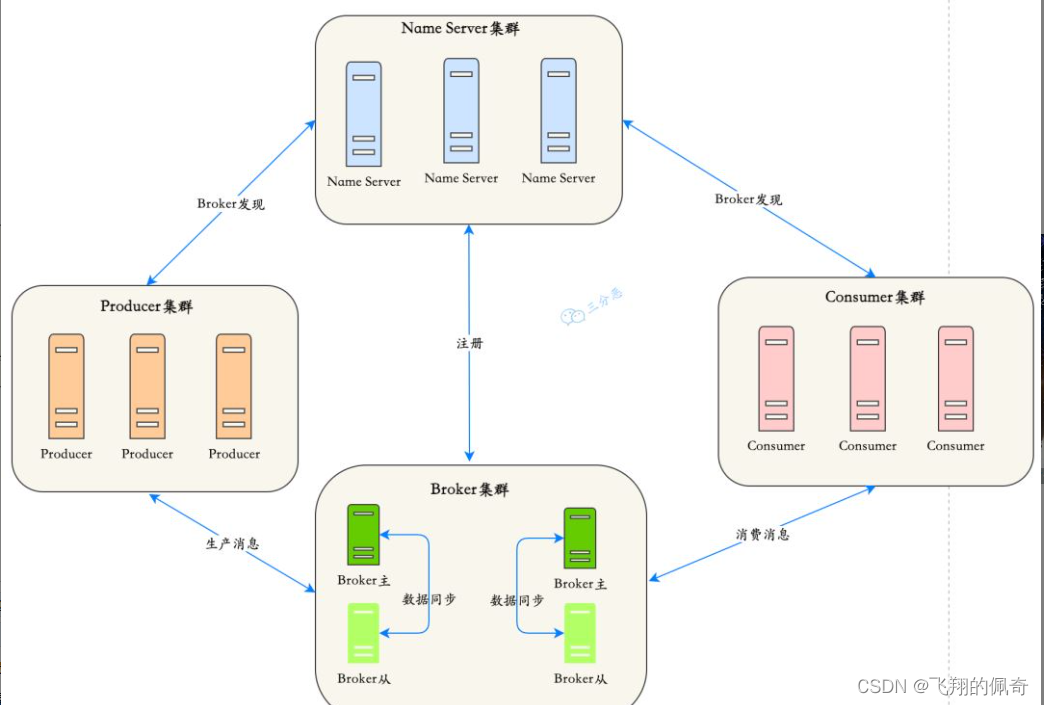
108、RocketMQ的底层实现原理(不需要长篇大论)
RocketMQ的底层实现原理 RocketMQ由NameServer集群、Producer集群、Consumer集群、Broker集群组成,消息生产和消费的大致原理如下: Broker在启动的时候向所有的NameServer注册,并保持长连接,每30s发送一次心跳Producer在发送消息的时候从Na…...

怎么把PDF转为word?1分钟解决难题
PDF文件在我们的电脑上应用非常广泛,由于其较高的安全性和兼容性,得到了广泛的认可。然而,对于一些人来说,PDF文件不能直接进行编辑和修改可能是一个问题。因此,通常我们需要将其转换为Word格式,以便在Word…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...