kafka消费者api和分区分配和offset消费
kafka消费者
消费者的消费方式为主动从broker拉取消息,由于消费者的消费速度不同,由broker决定消息发送速度难以适应所有消费者的能力
拉取数据的问题在于,消费者可能会获得空数据
消费者组工作流程
Consumer Group(CG):消费者组
- 由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
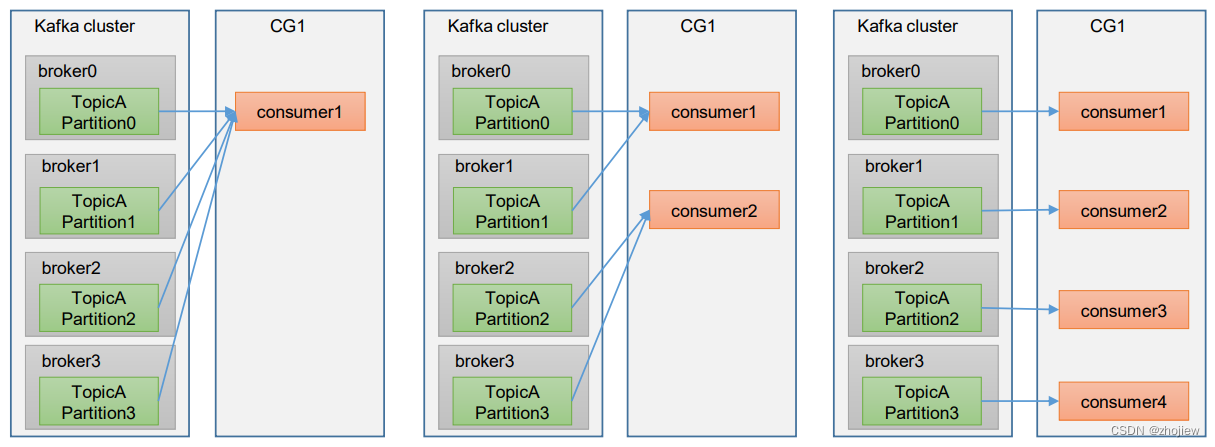
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组(即使只有一个消费者),即消费者组是逻辑上的一个订阅者
- 分区和消费者的分配取决于具体的分配策略
- 如果消费者组中的消费者数量超过分区数量,则会由部分消费者处于空闲状态,不会接受任何消息
初始化流程
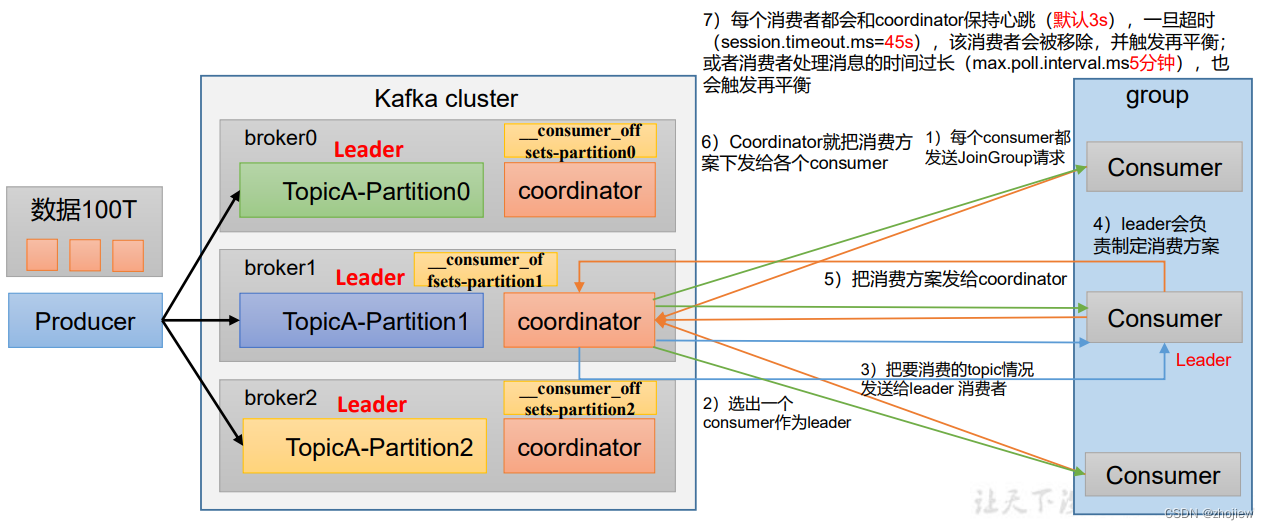
- 每个broker上都有coordinator
- 选择coordinator作为消费者组的初始化和分区分配的协调者,使用消费者组的**groupid的hashcode%50(即__consumer_offsets的分区数量)**得到对应的broker id。该broker将作为整个消费者组的协调者。消费者组中的消费者向该分区提交offset
- 所有消费者向coordinator发送请求加入消费者组
- coordinator随机选择一个consumer作为leader
- 将要消费的topic情况发送给leader消费者
- leader制定消费方案,并将方案发送到coordinator
- coordinator把消费方案分发给哥哥消费者
- 每个消费者都会和coordinator保持心跳(默认3s)
- 一旦超时 (
session.timeout.ms=45s),该消费者会被移除,并触发再平衡; - 或者消费者处理消息的时间过长(
max.poll.interval.ms5分钟),也会触发再平衡
- 一旦超时 (
- 尽量避免消费者组的再平衡,非常消耗性能
消费流程
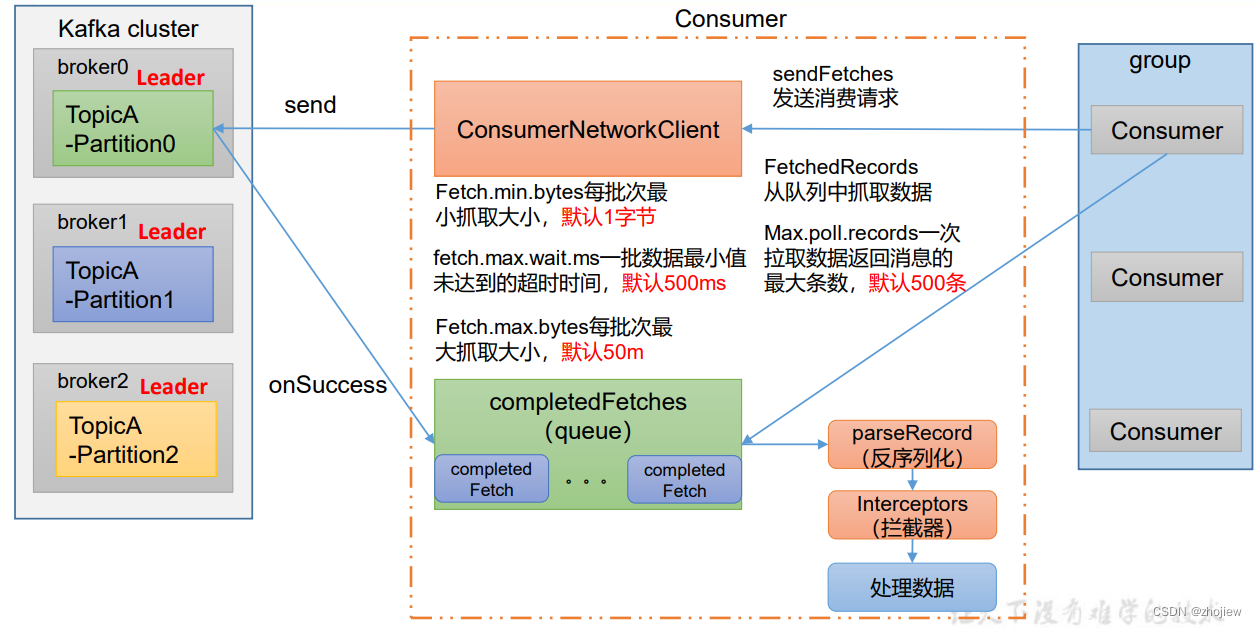
- 消费者创建
ConsumerNetworkClient,用于和kafka集群进行通信 - 消费者开始初始化抓取数据的参数
fetch.min.bytes,每批次最小抓取大小,默认1字节fetch.max.wait.ms,超时时间即使数据批次未达到大小也会抓取,默认500msfetch.max.bytes,每批次最大抓取大小,默认50m
- 参数初始化完成后,开始调用send方法发送请求
- 通过onSuccess回调拉取数据,存放在消息队列中
- 消费者开始拉取数据(
max.poll.records,一次拉取数据返回消息的最大值,默认500条) - 将消息进行反序列化和拦截器(kafka本身并不处理数据)
消费者相关参数
bootstrap.servers向 Kafka 集群建立初始连接用到的 host/port 列表。key.deserializer 和 value.deserializer指定接收消息的 key 和 value 的反序列化类型。一定要写全类名。group.id标记消费者所属的消费者组。enable.auto.commit默认值为 true,消费者会自动周期性地向服务器提交偏移量auto.commit.interval.ms如果设置了enable.auto.commit的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5sauto.offset.reset当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在 (如,数据被删除了),该如何处理?earliest:自动重置偏移量到最早的偏移量。latest:默认,自动重置偏移量为最新的偏移量。none:如果消费组原来的(previous)偏移量 不存在,则向消费者抛异常。anything:向消费者抛异常
offsets.topic.num.partitions,即__consumer_offsets的分区数,默认是 50 个分区。heartbeat.interval.msKafka 消费者和 coordinator 之间的心跳时间,默认 3s。 该条目的值必须小于session.timeout.ms(45s),也不应该高于session.timeout.ms的 1/3。session.timeout.msKafka 消费者和 coordinator 之间连接超时时间,默认 45s。 超过该值,该消费者被移除,消费者组执行再平衡
消费者API
创建topic
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic first --create --partitions 3 --replication-factor 3
独立消费者
- 即使只有单独的消费者,也必须配置消费者组id
- kafka命令行启动消费者,如果不填写消费者组id,则会被自动填充随机的消费者组id
订阅主题进行消费
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;public class SimpleConsumer {public static void main(String[] args) {// configureProperties properties = new Properties();// connectproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// key,value反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// create consumerproperties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);ArrayList<String> topics = new ArrayList<String>();topics.add("first");kafkaConsumer.subscribe(topics);while (true) {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> ConsumerRecord : consumerRecords) {System.out.println(ConsumerRecord);}}}
}
output:
ConsumerRecord(topic = test, partition = 0, leaderEpoch = 2,offset = 3, CreateTime = 1629169606820, serialized key size = -1,serialized value size = 8, headers = RecordHeaders(headers = [],isReadOnly = false), key = null, value = hello1)
ConsumerRecord(topic = test, partition = 1, leaderEpoch = 3,offset = 2, CreateTime = 1629169609524, serialized key size = -1,serialized value size = 6, headers = RecordHeaders(headers = [],isReadOnly = false), key = null, value = hello2)
订阅分区进行消费
...
ArrayList<TopicPartition> topics = new ArrayList<TopicPartition>();
topics.add(new TopicPartition("test", 0)); // 指定消费分区0的数据
kafkaConsumer.assign(topics);
消费者组消费数据
- 只需要启动多个消费者即可,消费者按照消费者组的id自动归属于同一个消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
ArrayList<String> topics = new ArrayList<String>();
topics.add("first");
kafkaConsumer.subscribe(topics);
分区的分配和再平衡
分区的分配设计到同一个topic中的partition由那个consumer来消费的问题
Kafka有四种主流的分区分配策略(所谓的分区分配策略就是消费方案):
-
Range -
RoundRobin -
Sticky -
CooperativeSticky
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用 多个分区分配策略
range策略
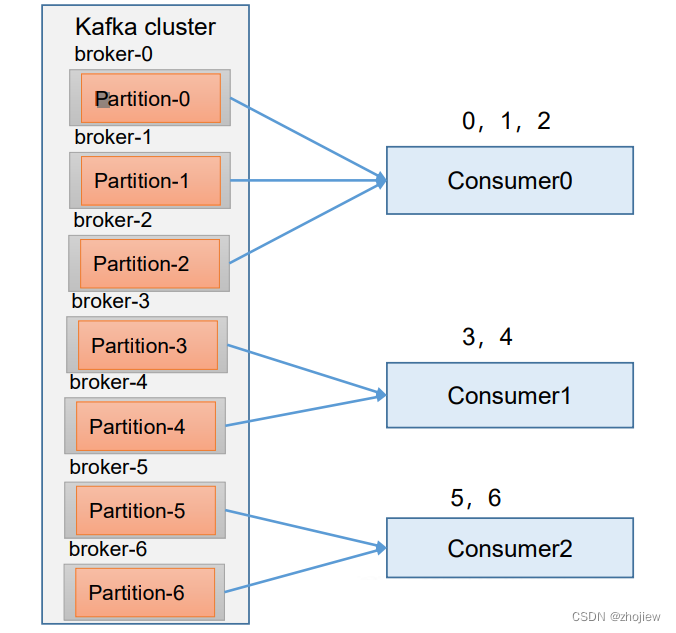
Range 是对每个 topic 而言的。
- 对同一个 topic 里面的分区按照序号进行排序,假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6
- 对消费者按照字母顺序进行排序。 消费者排序完之后将会是C0,C1,C2。
- 通过 partitions数/consumer数 来决定每个消费者应该 消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
注意:如果只是针对 1 个 topic 而言,C0消费者多消费1 个分区影响不是很大。但是如果有 N 个 topic,那么针对每 个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。 容易产生数据倾斜
注意:
-
修改主题的分区数,只能增加不能减少
-
如果在消费过程中某个consumer挂掉,当超出45s后,则该consumer消费的所有分区都会整体分配给某一个其他消费者
-
消费者被移出消费者组,消费策略按照存活的消费者重新分配分区
-
Kafka 默认的分区分配策略是 Range + CooperativeSticky
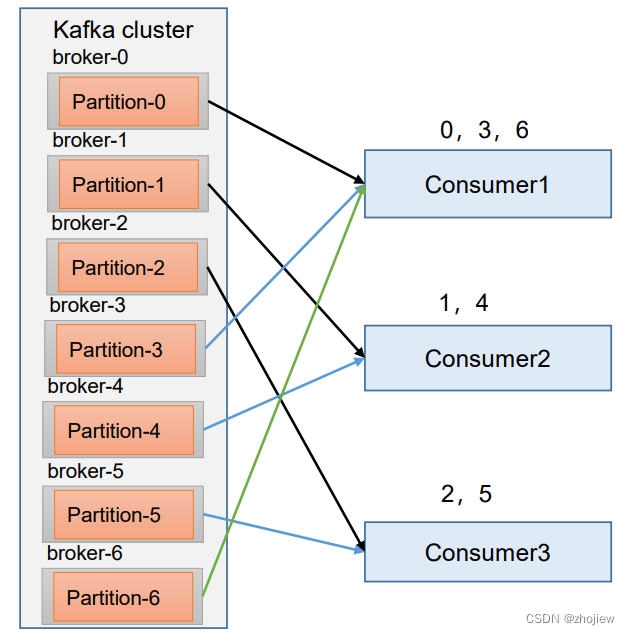
RoundRobin策略
针对所有topic而言
- 把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序
- 按照轮询算法将partition分配给消费者
注意
-
需要修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor"); -
如果在消费过程中某个consumer挂掉,超过45s后,该消费者的分区会重新按照轮询的方式在其他消费者中分配
-
消费者被移出消费者组,消费策略按照存活的消费者重新分配分区
Sticky策略
在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化
如果有0,1,2,3,4,5,6分区和C0,C1,C2消费者,则最终分配比例仍旧是223,但是每个消费者分配中的partition是随机的
注意
-
需要修改分区分配策略
ArrayList<String> startegys = new ArrayList<>(); startegys.add("org.apache.kafka.clients.consumer.StickyAssignor"); properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,startegys); -
如果在消费过程中某个consumer挂掉,超过45s后,该消费者的分区会按照粘性规则,尽可能均衡分配给其他的消费者
-
消费者被移出消费者组,消费策略按照存活的消费者重新分配分区
offset位移
offset维护的位置在不同版本的kafka中存在区别
- 0.9版本之前存储在zk中,如果client和zk之前存在大量网络通信,则会导致性能我呢提
- 0.9版本后存储在kafka集群中的
_consumer_offsets主题中
在内部主题中采用kv的方式存储offset
- key的值为,group.id+topic+ 分区号
- value的值为,当前offset
- 每隔一段时间,kafka对主题中的数据进行compact
默认内部主题不可消费
-
修改config/comsumer.properties文件中的参数
exclude.internal.topics=false, 默认是 true,表示不能消费系统主题 -
查看消费者消费主题
kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server 127.0.0.1:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
自动提交offset
kafka提供了自动提交offset的功能,使用户专注于自身的业务逻辑
enable.auto.commit:是否开启自动提交offset功能,默认是trueauto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
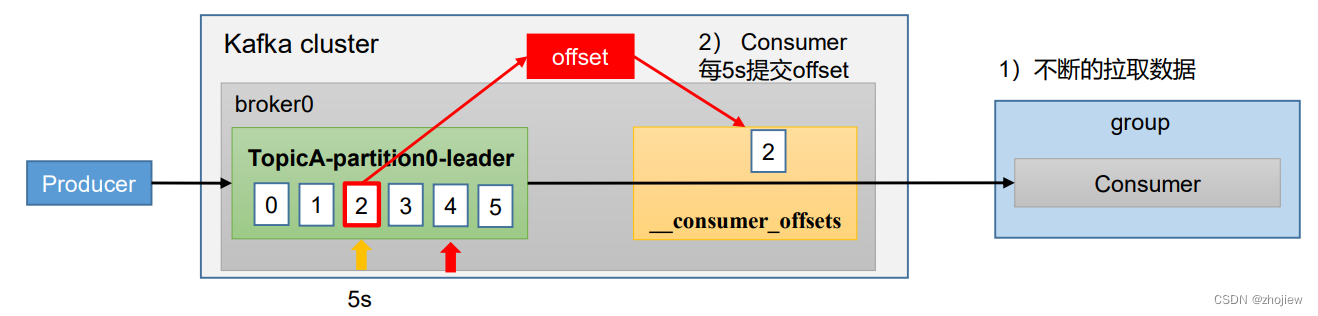
在java消费者中添加消费者参数
// 是否自动提交 offset,实际上不用设置此参数,默认为true
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 提交 offset 的时间周期 1000ms,默认 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
手动提交offset
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)
相同点:都会将本次提交的一批数据最高的偏移量提交
不同点:同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故 有可能提交失败
commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据
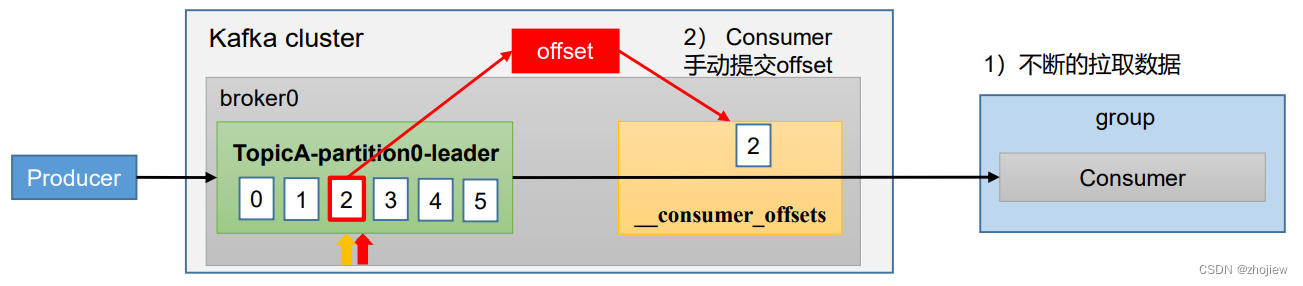
在java消费者中添加消费者参数
- 同步提交存在重试机制,因此更加可靠,但是由于阻塞提交效率较低(吞吐量低)
// 是否自动提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);//4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("first"));//5. 消费数据
while (true){// 读取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 输出消息for (ConsumerRecord<String, String> consumerRecord :
consumerRecords) {System.out.println(consumerRecord.value());}// 同步提交 offsetconsumer.commitSync();// 异步提交 offset// consumer.commitAsync();}
指定offset消费
在命令行中创建消费者指定--from-beginning,表示从头开始消费。
当消费者组首次消费(没有初始偏移量时),根据以下参数进行消费行为
-
earliest,将偏移量重置为从头开始消费
-
latest(默认值),自动将偏移量重置为最新偏移量
-
none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
如何在java消费者中指定offset进行消费
// 1 创建一个消费者
KafkaConsumer<String, String> kafkaConsumer = new
KafkaConsumer<>(properties);// 订阅主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment= new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();
}// 遍历所有分区,并指定 offset 从 1700 的位置开始消费
for (TopicPartition tp: assignment) {kafkaConsumer.seek(tp, 1700);
}// 开始消费
while (true) {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}
}
指定时间开始消费
逻辑上可以通过指定某个时刻的offset来实现
Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();
}
HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>();// 封装集合存储,每个分区对应一天前的数据
for (TopicPartition topicPartition : assignment) {timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
}// 获取从 1 天前开始消费的每个分区的 offset
Map<TopicPartition, OffsetAndTimestamp> offsets = kafkaConsumer.offsetsForTimes(timestampToSearch);// 遍历每个分区,对每个分区设置消费时间。
for (TopicPartition tp : assignment) {OffsetAndTimestamp offsetAndTimestamp = offsets.get(tp);// 根据时间指定开始消费的位置if (offsetAndTimestamp != null){kafkaConsumer.seek(tp, offsetAndTimestamp.offset());}
}
漏消费和重复消费问题
重复消费问题,当前一次自动提交offset后,消费者开始消费数据2s后挂掉。此时重启consumer会从上一次自动提交的offset开始消费,导致重复消费的问题
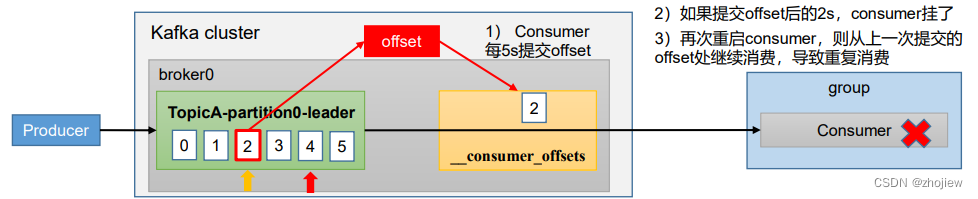
漏消费问题,在手动提交offset模式下,当提交offset后如果消费者数据还未落盘出现宕机,则这部分未落盘的数据由于offset已经更新无法再次消费
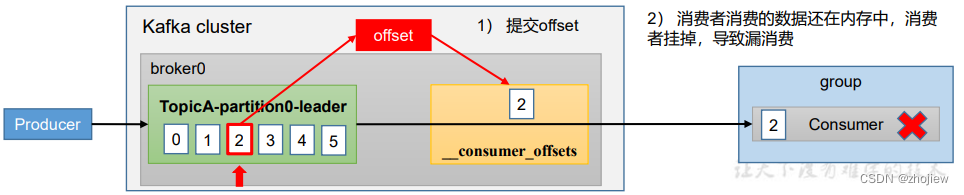
生产环境的消费者
消费者事务
控制consumer端精准消费同样需要事务支持(要Kafka消费端将消费过程和提交offset 过程做原子绑定)
此时需要将offset保存到支持事务的介质中
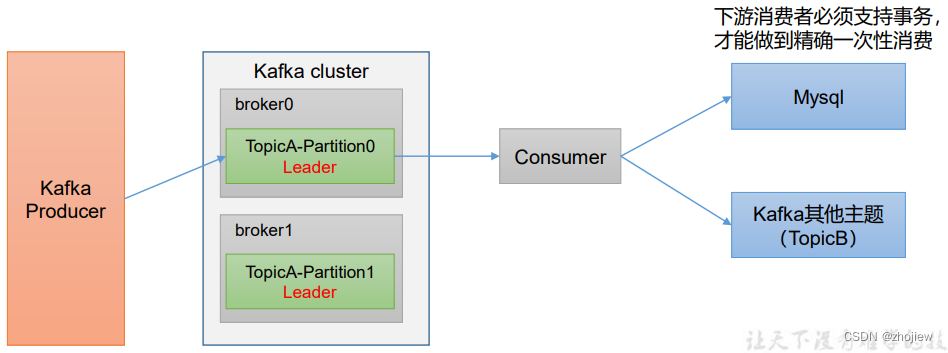
数据积压问题
消费者能力不足造成积压(考虑扩充消费者数量)
下游数据处理不及时导致数据积压,提升每批次拉取数据的量
相关参数
fetch.max.bytes默认 Default: 52428800(50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批次的大小受message.max.bytes(broker config)or max.message.bytes (topic config)影响。 max.poll.records 一次 poll 拉取数据返回消息的最大条数,默认是 500 条
相关文章:
kafka消费者api和分区分配和offset消费
kafka消费者 消费者的消费方式为主动从broker拉取消息,由于消费者的消费速度不同,由broker决定消息发送速度难以适应所有消费者的能力 拉取数据的问题在于,消费者可能会获得空数据 消费者组工作流程 Consumer Group(CG&#x…...
【驱动开发day4作业】
头文件代码 #ifndef __HEAD_H__ #define __HEAD_H__ typedef struct{unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t; #define PHY_LED1_ADDR 0X50006000 #define PHY_LED2_ADDR 0X50007000 #…...

Ubuntu 20.04 Ubuntu18.04安装录屏软件Kazam
1.在Ubuntu Software里面输入Kazam,就可以找不到这个软件,直接点击install就可以了 2.使用方法: 选择Screencast(录屏) Fullscreen(全屏)-----Windows(窗口)--------Ar…...

ADC 的初识
ADC介绍 Q: ADC是什么? A: 全称:Analog-to-Digital Converter,指模拟/数字转换器 ADC的性能指标 量程:能测量的电压范围分辨率:ADC能辨别的最小模拟量,通常以输出二进制数的位数表示,比如&am…...

MMdetection框架速成系列 第07部分:数据增强的N种方法
MMdetection框架实现数据增强的N种方法 1 为什么要进行数据增强2 数据增强的常见误区3 常见的六种数据增强方式3.1 随机翻转(RandomFlip)3.2 随机裁剪(RandomCrop)3.3 随机比例裁剪并缩放(RandomResizedCrop࿰…...

基于Kitti数据集的智能驾驶目标检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于Kitti数据集的智能驾驶目标检测系统可用于日常生活中检测与定位行人(Pedestrian)、面包车(Van)、坐着的人(Person Sitting)、汽车(Car)、卡车(Truck…...

4.4. 深拷贝 vs 浅拷贝
文章目录 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为…...
网络安全(黑客)自学建议笔记
前言 网络安全,顾名思义,无安全,不网络。现如今,安全行业飞速发展,我们呼吁专业化的 就职人员与大学生 ,而你,认为自己有资格当黑客吗? 本文面向所有信息安全领域的初学者和从业人员…...
Linux CentOS快速安装VNC并开启服务
以下是在 CentOS 上安装并开启 VNC 服务的步骤: 安装 VNC 服务器软件包。运行以下命令: sudo yum install tigervnc-server 输出 $ sudo yum install tigervnc-server Loaded plugins: fastestmirror, langpacks Repository epel is missing name i…...
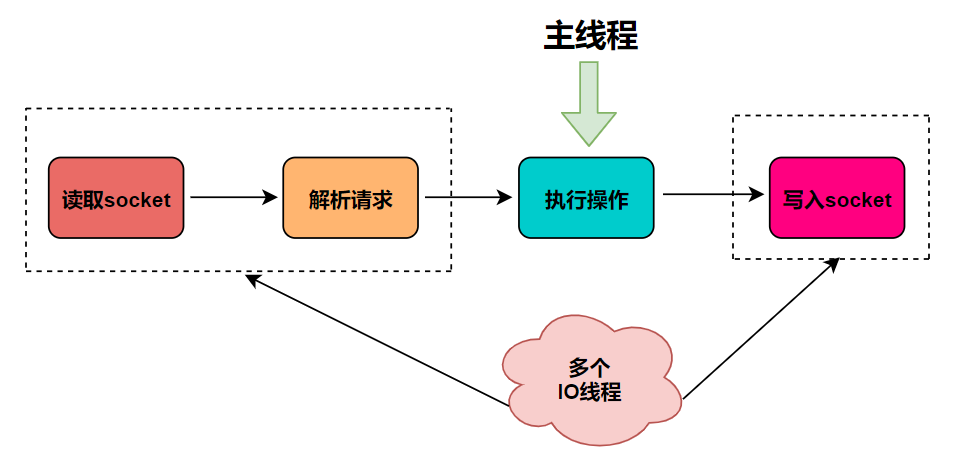
redis到底几个线程?
通常我们说redis是单线程指的是从接收客户端请求->解析请求->读写->响应客户端这整个过程是由一个线程来完成的。这并不意味着redis在任何场景、任何版本下都只有一个线程 为何用单线程处理数据读写? 内存数据储存已经很快了 redis相比于mysql等数据库是…...

mysql修改UUID
mysql修改UUID 问题描述:集群搭建时克隆主服务的镜像导致所有节点的服务UUID都一致,此时在集群中添加节点时会提示UUID冲突报错。 解决方案 1、利用uuid函数生成新的uuid mysql> select uuid(); -------------------------------------- | uuid() …...
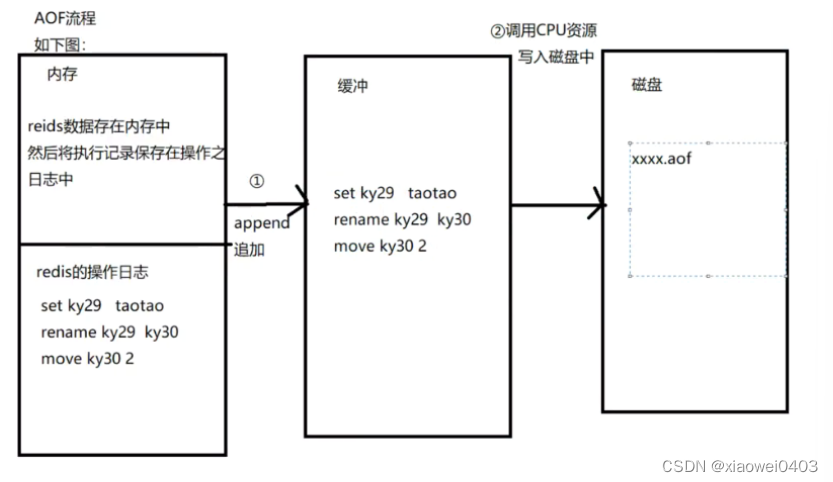
NoSQL之redis配置与优化
NoSQL之redis配置与优化 高可用持久化功能Redis提供两种方式进行持久化1.触发条件手动触发自动触发 执行流程优缺点缺点:优势AOF出发规则: AOF流程AOF缺陷和优点 NoSQL之redis配置与优化 mysql优化 1线程池优化 2硬件优化 3索引优化 4慢查询优化 5内…...

Python单例模式介绍、使用
一、单例模式介绍 概念:单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供访问该实例的全局访问点。 功能:单例模式的主要功能是确保在应用程序中只有一个实例存在。 优势: 节省系统资源:由…...
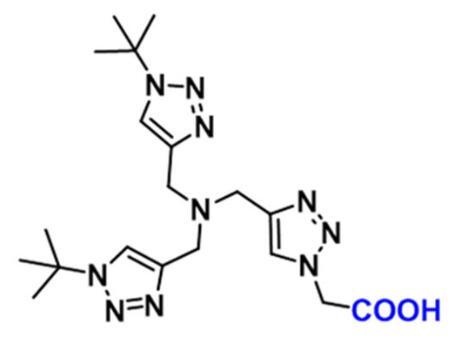
1334179-85-9,BTTAA,是各种化学生物学实验中生物偶联所需
资料编辑|陕西新研博美生物科技有限公司小编MISSwu BTTAA试剂 | 基础知识概述(部分): 中文名称:2-[4-({双[(1-叔丁基-1H-1,2,3-三唑-4-基)甲基]氨基}甲基)-1H-1,2,3-三唑-1-基]乙酸 英文名称:BTTAA CAS号:1334179-8…...

Linux系统中的SQL语句
本节主要学习,SQL语句的语句类型,数据库操作,数据表操作,和数据操作等。 文章目录 一、SQL语句类型 DDL DML DCL DQL 二、数据库操作 1.查看 2.创建 默认字符集 指定字符集 3.进入 4.删除 5.更改 库名称 字符集 6…...

力扣27 26 283 844 977 移除数组
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的…...

【沐风老师】3DMAX自动材质插件使用方法教程
3DMAX自动材质插件使用方法教程 3DMAX自动材质工具用于在将纹理加载到3dsax中时快速创建简单的材质,并具有一些很酷的材质功能。 这个插件可以根据真正制造商的纹理(通常比例为2:1)快速创建简单的木材材质,并根据板材的长度自动对…...
让你 React 组件水平暴增的 5 个技巧
目录 透传 className、style 通过 forwardRef 暴露一些方法 useCallback、useMemo 用 Context 来跨组件传递值 React.Children、React.cloneElement 总结 最近看了一些 Ant Design 的组件源码,学到一些很实用的技巧,这篇文章来分享一下。 首先&am…...

阿里云部署 ChatGLM2-6B 与 langchain+ChatGLM
1.ChatGLM2-6B 部署 更新系统 apt-get update 安装git apt-get install git-lfs git init git lfs install 克隆 ChatGLM2-6B 源码 git clone https://github.com/THUDM/ChatGLM2-6B.git 克隆 chatglm2-6b 模型 #进入目录 cd ChatGLM2-6B #创建目录 mkdir model #进入目录 cd m…...
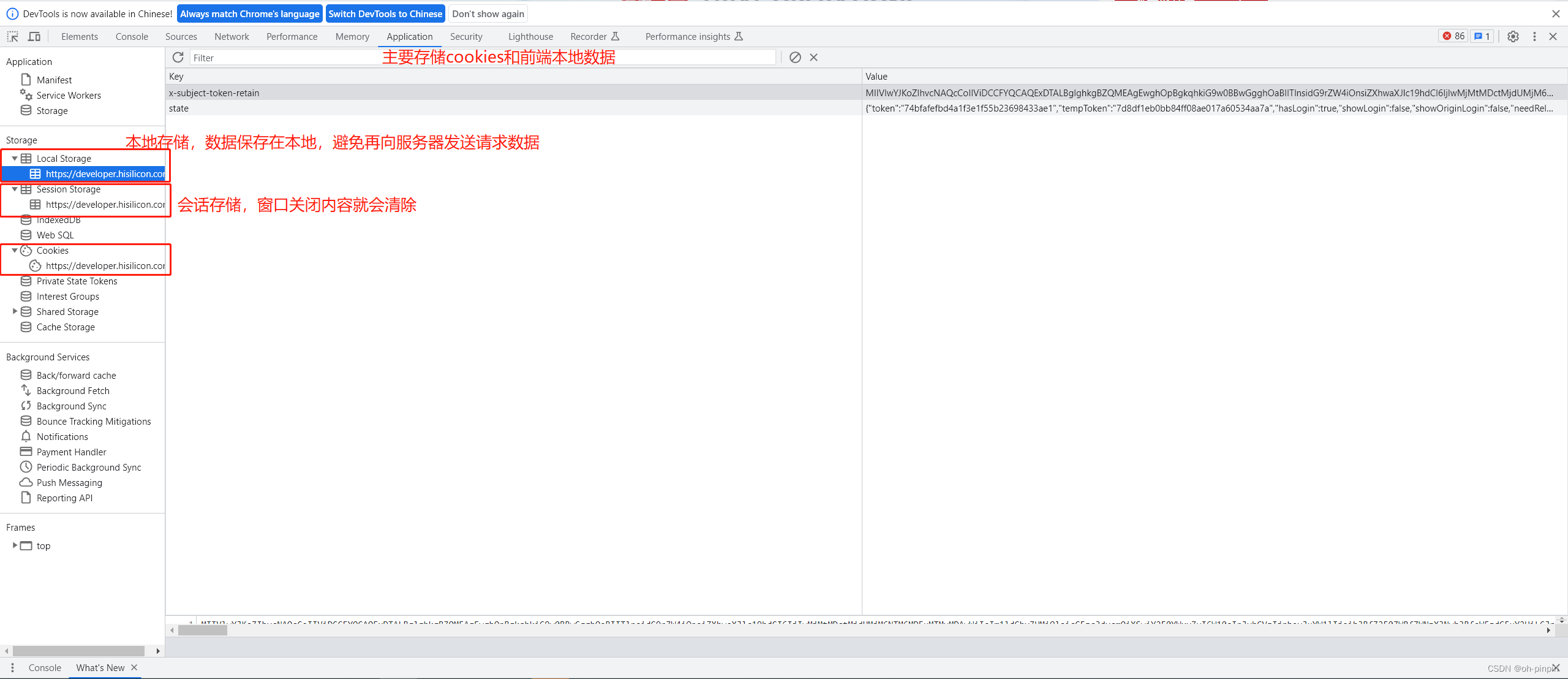
F12开发者工具的简单应用
目录 elements 元素 1、元素的定位和修改 2、UI自动化应用 console 控制台 sources 源代码 network 网络 1、定位问题 2、接口测试 3、弱网测试 performance 性能 memory 存储 application 应用 recorder 记录器 界面展示如下(设置中可以切换中英文&am…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

3PEAK思瑞浦 TPA6531-S5TR SOT23-5 运算放大器
特性 供电电压:1.75V至5.5V 偏移电压:1.5mV(最大值) 最大可调工作频率:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1赫兹至10赫兹电压噪声:1伏峰值 开关电源时无显著输出抖动 低功耗:每通道最大25安培 工作温度范围:-40C至125C...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...