【数据结构】实验八:树
实验八 树
一、实验目的与要求
1)理解树的定义;
2)掌握树的存储方式及基于存储结构的基本操作实现;
二、 实验内容
题目一:采用树的双亲表示法根据输入实现以下树的存储,并实现输入给定结点的双亲结点的查找。
双亲表示法的存储结构描述如下:
#define MaxSize 100 //树中最多结点数
typedef struct{ //树的结点定义
char data; //数据元素
int parent; //双亲位置域
}PTNode;
typedef struct{ //树的类型定义
PTNode nodes[MaxSize]; //双亲表示
int n; //结点数
}PTree;
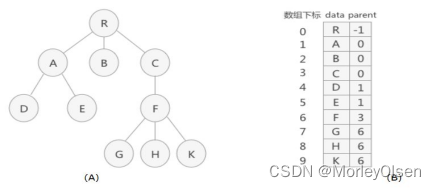
提示:一组连续空间来存储每个结点,同时在每个结点中增设一个伪指针,指示其双亲结点在数组中的位置。根结点的下标为0,其伪指针域为-1。
示列:
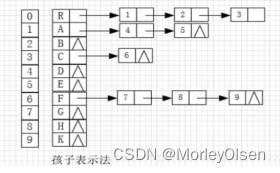
题目二:采用树的孩子表示法,实现以上树的存储,要求实现输入结点查找输出该结点的所有孩子结点,没有孩子结点输出-1。(选做)
存储结构描述
#define MaxSize 100
typedef struct ChildNode{ //链表中每个结点的定义
//链表中每个结点存储的不是数据本身,而是数据在数组中存储的位置下标
int child;
struct ChildNode *next;
}ChildNode;
typedef struct{ //树中每个结点的定义
char data; //结点的数据类型
ChildNode *firstchild; //孩子链表头指针
}CHNode;
typedef struct{
CHNode nodes[MaxSize]; //存储结点的数组
int n;
}CTree;
示列:
三、实验结果
1)请将调试通过的运行结果截图粘贴在下面,并说明测试用例和运行过程。
2)请将源代码cpp文件和实验报告一起压缩上传。
第一题:
运行结果:
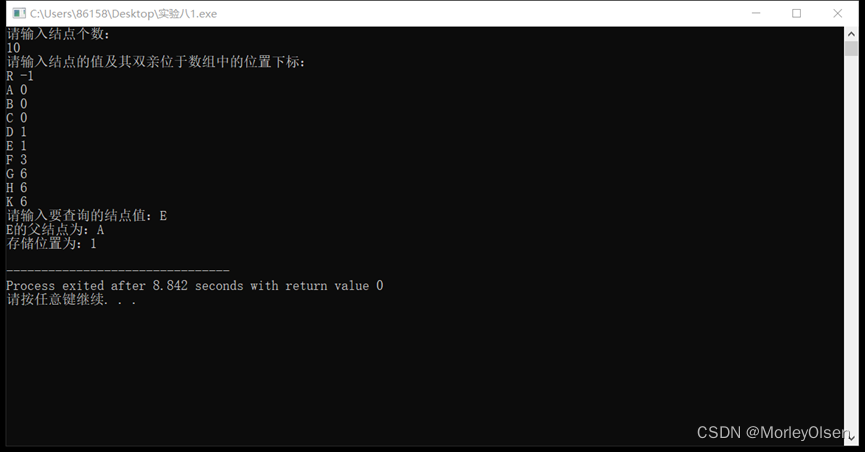
测试用例和运行过程:
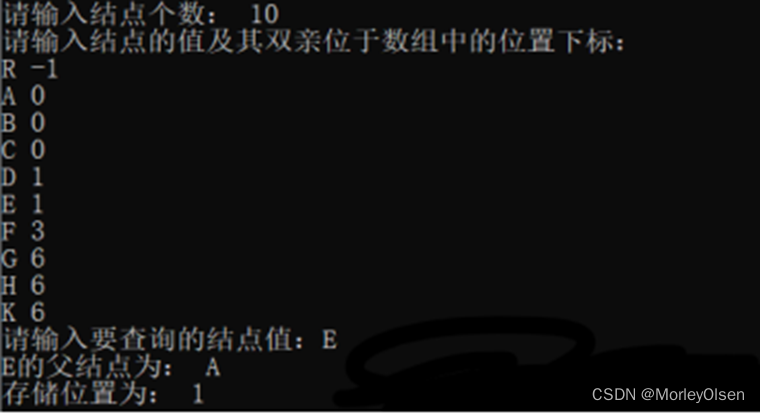
如第一题A图和B图所示,测试用例为该树,各个结点对应的data和parent分别为{ (R,-1) , (A,0) , (B,0) , (C,0) , (D,1) , (E,1) , (F,3) , (G,6) , (H,6) , (K,6) }。
主函数首先创建一个树,通过构造树函数CreateTree依次录入结点的值及其双亲位于数组中的位置下标,再输入需要查询的结点值,通过查找结点函数SearchNode中的for循环遍历各个结点,当且仅当结点值匹配时,输出其父结点和存储位置,然后跳出循环。
最终结果如运行截图所示。
实验代码:
#include <iostream>
#include <cstdio>
using namespace std;#define MaxSize 100 //树中最多结点数
typedef struct{ //树的结点定义char data; //数据元素int parent; //双亲位置域
}PTNode;typedef struct{ //树的类型定义PTNode nodes[MaxSize]; //双亲表示int n; //结点数
}PTree;//构造树
void CreateTree(PTree *T){int i=0;cout<<"请输入结点个数:"<<endl;cin>>T->n ;cout<<"请输入结点的值及其双亲位于数组中的位置下标:"<<endl;for( ;i<T->n ;i++){ cin>>T->nodes[i].data>>T->nodes[i].parent ;}return;
}//查找结点信息
void SearchNode(PTree *T,char e){int i=0,flag=0;for( ;i<T->n ;i++){if(T->nodes[i].data ==e){flag=1;cout<<e<<"的父结点为:"<<T->nodes[T->nodes[i].parent].data<<endl;cout<<"存储位置为:"<<T->nodes[i].parent <<endl;break;}}if(flag==0){cout<<"NOT FOUND"<<endl;}
}int main(){PTree T;CreateTree(&T);cout<<"请输入要查询的结点值:";char element;cin>>element;SearchNode(&T,element);return 0;
}
第二题:
运行结果:
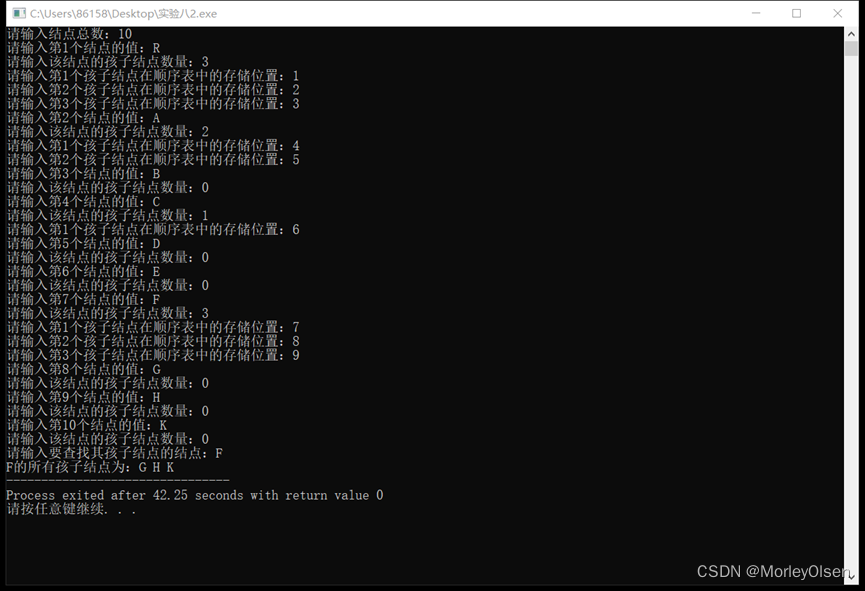
测试用例和运行过程:
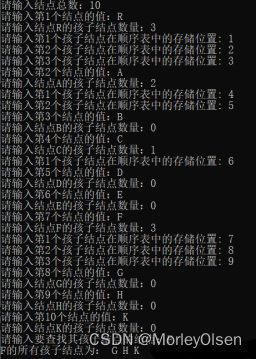
如第二题的图所示,测试用例为该树,只有R,A,C,F结点具有孩子结点,其余均为叶子结点。
主函数首先创建一个树,通过构造树函数CreateTree,首先录入结点的总数,再通过外层for循环依次输入每一个结点的值、当前结点的孩子结点数量,紧接着通过内层for循环依次输入当前结点的孩子结点在顺序表中存储的位置,最终完成树的创建。然后通过查找孩子结点函数SearchChild,输入要查找其孩子结点的结点,通过for循环查找元素一致的结点,确定之后判断孩子是否为空,若非空则通过while循环输出每一个非空的孩子结点。
最终结果如运行截图所示。
实验代码:
#include <iostream>
#include <cstdio>
#include <malloc.h>
using namespace std;#define MaxSize 100
typedef struct ChildNode{ //链表中每个结点的定义//链表中每个结点存储的不是数据本身,而是数据在数组中存储的位置下标int child;struct ChildNode *next;
}ChildNode;typedef struct{ //树中每个结点的定义char data; //结点的数据类型ChildNode *firstchild; //孩子链表头指针
}CHNode;typedef struct{CHNode nodes[MaxSize]; //存储结点的数组int n;
}CTree;//实现输入结点查找输出该结点的所有孩子结点,没有孩子结点输出-1//创建树
void CreateTree(CTree *T){cout<<"请输入结点总数:";cin>>T->n;int i=0;for( ;i<T->n;i++){cout<<"请输入第"<<i+1<<"个结点的值:";cin>>T->nodes[i].data;cout<<"请输入该结点的孩子结点数量:";int num;cin>>num;ChildNode *m=NULL;int j=0;for( ;j<num;j++){ChildNode *s=(ChildNode *)malloc(sizeof(ChildNode)); cout<<"请输入第"<<j+1<<"个孩子结点在顺序表中的存储位置:";cin>>s->child;s->next = NULL;if(j==0){T->nodes[i].firstchild = s;m=s;}else{m->next = s;m=s;}}}
}//查找孩子结点
void SearchChild(CTree *T){char e;cout<<"请输入要查找其孩子结点的结点:";cin>>e;int flag=-1,i=0;for( ;i<T->n ;i++){if(T->nodes[i].data == e){flag=i;break;}} if(flag==-1){cout<<"Not Found"<<endl;return;}ChildNode *p=T->nodes[flag].firstchild;if(p==NULL){cout<<"此结点为叶子结点"<<endl;return;}cout<<e<<"的所有孩子结点为:";while(p!=NULL){cout<<T->nodes[p->child].data<<" ";p=p->next;}
}int main(){CTree T;int i=0;CreateTree(&T);SearchChild(&T);return 0;
}
其他:
#include<iostream>
using namespace std;#define MaxSize 100 //树中最多结点数typedef struct{ //树的结点定义char data; //数据元素int parent; //双亲位置域
}PTNode;typedef struct{ //树的类型定义PTNode nodes[MaxSize]; //双亲表示int n; //结点数
}PTree;void Parent_PT(PTree &ptree,char m){int i;for(i=0;(i<ptree.n)&&(ptree.nodes[i].data!=m);i++);if(i>=ptree.n) cout<<"Node -"<<m<<" is not exist!"<<endl;else{int j=ptree.nodes[i].parent;if(j==-1)cout<<"Node -"<<m<<" has not parent!"<<endl;else{cout<<m<<"的父结点为:"<<ptree.nodes[j].data<<endl;cout<<ptree.nodes[j].data<<"的储存位置为:"<<j<<endl;}}
}int main(){PTree ptree;cout<<"请输入结点个数:";int num;cin>>num;ptree.n=num;cout<<"请输入结点的值以及双亲位于数组中的位置下标:"<<endl;char m;int q; for(int i=0;i<num;i++){cin>>m;cin>>q;ptree.nodes[i].data=m;ptree.nodes[i].parent=q;}while(1){cout<<"请输入要查询的结点值:";cin>>m;if(m=='#'){cout<<"查询结束!";break; } Parent_PT(ptree,m); } return 0;
} #include<iostream>
using namespace std;#define MaxSize 100typedef struct ChildNode{ //链表中每个结点的定义//链表中每个结点存储的不是数据本身,而是数据在数组中存储的位置下标int child;struct ChildNode *next;
}ChildNode;typedef struct{ //树中每个结点的定义char data; //结点的数据类型ChildNode *firstchild; //孩子链表头指针
}CHNode;typedef struct{CHNode nodes[MaxSize]; //存储结点的数组int n;
}CTree;void Init_tree(CTree &ctree){cout<<"请输入结点总数:";int num;cin>>num;ctree.n=num;for(int i=0;i<num;i++){cout<<"请输入第"<<i+1<<"个结点的值:";char m;cin>>m;ctree.nodes[i].data=m;ctree.nodes[i].firstchild=NULL;cout<<"请输入结点"<<m<<"的孩子结点数:";int cnum;cin>>cnum;if(cnum==0) continue;cout<<"请输入第1个孩子结点在顺序表中的存储位置:";int l;cin>>l;ChildNode *p=new ChildNode;p->child=l;p->next=NULL;ctree.nodes[i].firstchild=p;for(int j=1;j<cnum;j++){cout<<"请输入第"<<j+1<<"孩子结点在顺序表中的存储位置:";cin>>l;ChildNode *q=new ChildNode;q->child=l;q->next=NULL;p->next=q;p=q;}}
}void Children(CTree &ctree,char f){int j;for(j=0;(j<ctree.n)&&(ctree.nodes[j].data!=f);j++);if(j>=ctree.n) cout<<"Node -"<<f<<" is not exist!";else{ChildNode *p=ctree.nodes[j].firstchild;if(!p) cout<<"Node -"<<f<<" has not children!";else{cout<<f<<"的所有孩子结点为: ";cout<<ctree.nodes[p->child].data<<" ";while(p->next!=NULL){p=p->next;cout<<ctree.nodes[p->child].data<<" ";}}}
}void Destroy(CTree &ctree){for(int i=0;i<ctree.n;i++){ChildNode *p=ctree.nodes[i].firstchild;ChildNode *q;if(!p) continue;while(p){q=p;p=p->next;q->next=NULL;delete q;}ctree.nodes[i].firstchild=NULL;}
} int main(){CTree ctree;Init_tree(ctree);//初始化 while(1){cout<<"--------------------------------------"<<endl;cout<<"请输入要查找其孩子结点的结点:"; char f;cin>>f;if(f=='#'){cout<<"查询结束!";break; } Children(ctree,f); cout<<endl;}Destroy(ctree);//释放new出的空间 return 0;
}
相关文章:
【数据结构】实验八:树
实验八 树 一、实验目的与要求 1)理解树的定义; 2)掌握树的存储方式及基于存储结构的基本操作实现; 二、 实验内容 题目一:采用树的双亲表示法根据输入实现以下树的存储,并实现输入给定结点的双亲结点…...
kafka消费者api和分区分配和offset消费
kafka消费者 消费者的消费方式为主动从broker拉取消息,由于消费者的消费速度不同,由broker决定消息发送速度难以适应所有消费者的能力 拉取数据的问题在于,消费者可能会获得空数据 消费者组工作流程 Consumer Group(CG&#x…...
【驱动开发day4作业】
头文件代码 #ifndef __HEAD_H__ #define __HEAD_H__ typedef struct{unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t; #define PHY_LED1_ADDR 0X50006000 #define PHY_LED2_ADDR 0X50007000 #…...

Ubuntu 20.04 Ubuntu18.04安装录屏软件Kazam
1.在Ubuntu Software里面输入Kazam,就可以找不到这个软件,直接点击install就可以了 2.使用方法: 选择Screencast(录屏) Fullscreen(全屏)-----Windows(窗口)--------Ar…...

ADC 的初识
ADC介绍 Q: ADC是什么? A: 全称:Analog-to-Digital Converter,指模拟/数字转换器 ADC的性能指标 量程:能测量的电压范围分辨率:ADC能辨别的最小模拟量,通常以输出二进制数的位数表示,比如&am…...

MMdetection框架速成系列 第07部分:数据增强的N种方法
MMdetection框架实现数据增强的N种方法 1 为什么要进行数据增强2 数据增强的常见误区3 常见的六种数据增强方式3.1 随机翻转(RandomFlip)3.2 随机裁剪(RandomCrop)3.3 随机比例裁剪并缩放(RandomResizedCrop࿰…...

基于Kitti数据集的智能驾驶目标检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于Kitti数据集的智能驾驶目标检测系统可用于日常生活中检测与定位行人(Pedestrian)、面包车(Van)、坐着的人(Person Sitting)、汽车(Car)、卡车(Truck…...

4.4. 深拷贝 vs 浅拷贝
文章目录 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为…...
网络安全(黑客)自学建议笔记
前言 网络安全,顾名思义,无安全,不网络。现如今,安全行业飞速发展,我们呼吁专业化的 就职人员与大学生 ,而你,认为自己有资格当黑客吗? 本文面向所有信息安全领域的初学者和从业人员…...
Linux CentOS快速安装VNC并开启服务
以下是在 CentOS 上安装并开启 VNC 服务的步骤: 安装 VNC 服务器软件包。运行以下命令: sudo yum install tigervnc-server 输出 $ sudo yum install tigervnc-server Loaded plugins: fastestmirror, langpacks Repository epel is missing name i…...
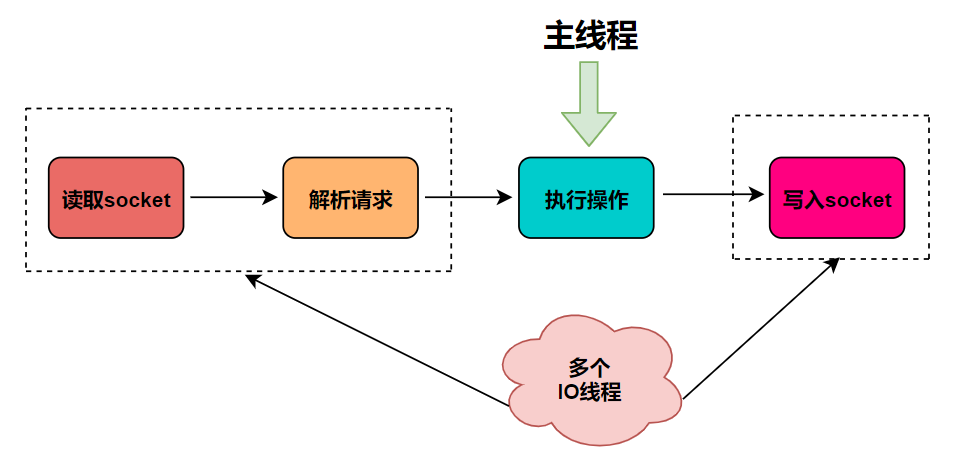
redis到底几个线程?
通常我们说redis是单线程指的是从接收客户端请求->解析请求->读写->响应客户端这整个过程是由一个线程来完成的。这并不意味着redis在任何场景、任何版本下都只有一个线程 为何用单线程处理数据读写? 内存数据储存已经很快了 redis相比于mysql等数据库是…...

mysql修改UUID
mysql修改UUID 问题描述:集群搭建时克隆主服务的镜像导致所有节点的服务UUID都一致,此时在集群中添加节点时会提示UUID冲突报错。 解决方案 1、利用uuid函数生成新的uuid mysql> select uuid(); -------------------------------------- | uuid() …...
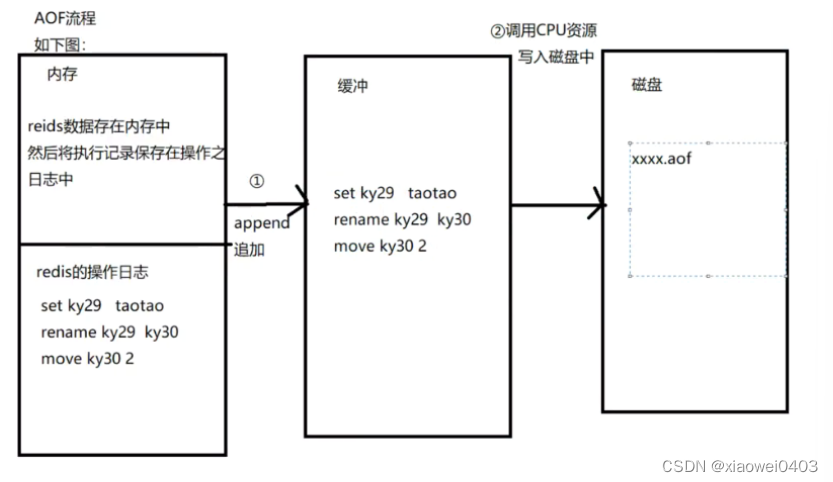
NoSQL之redis配置与优化
NoSQL之redis配置与优化 高可用持久化功能Redis提供两种方式进行持久化1.触发条件手动触发自动触发 执行流程优缺点缺点:优势AOF出发规则: AOF流程AOF缺陷和优点 NoSQL之redis配置与优化 mysql优化 1线程池优化 2硬件优化 3索引优化 4慢查询优化 5内…...

Python单例模式介绍、使用
一、单例模式介绍 概念:单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供访问该实例的全局访问点。 功能:单例模式的主要功能是确保在应用程序中只有一个实例存在。 优势: 节省系统资源:由…...
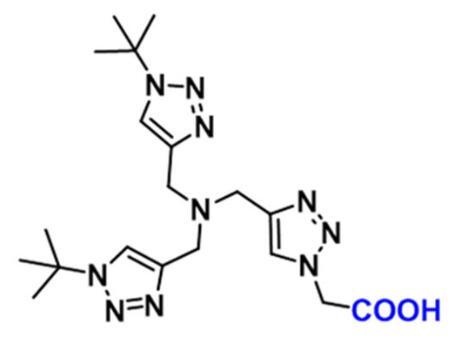
1334179-85-9,BTTAA,是各种化学生物学实验中生物偶联所需
资料编辑|陕西新研博美生物科技有限公司小编MISSwu BTTAA试剂 | 基础知识概述(部分): 中文名称:2-[4-({双[(1-叔丁基-1H-1,2,3-三唑-4-基)甲基]氨基}甲基)-1H-1,2,3-三唑-1-基]乙酸 英文名称:BTTAA CAS号:1334179-8…...

Linux系统中的SQL语句
本节主要学习,SQL语句的语句类型,数据库操作,数据表操作,和数据操作等。 文章目录 一、SQL语句类型 DDL DML DCL DQL 二、数据库操作 1.查看 2.创建 默认字符集 指定字符集 3.进入 4.删除 5.更改 库名称 字符集 6…...

力扣27 26 283 844 977 移除数组
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的…...

【沐风老师】3DMAX自动材质插件使用方法教程
3DMAX自动材质插件使用方法教程 3DMAX自动材质工具用于在将纹理加载到3dsax中时快速创建简单的材质,并具有一些很酷的材质功能。 这个插件可以根据真正制造商的纹理(通常比例为2:1)快速创建简单的木材材质,并根据板材的长度自动对…...
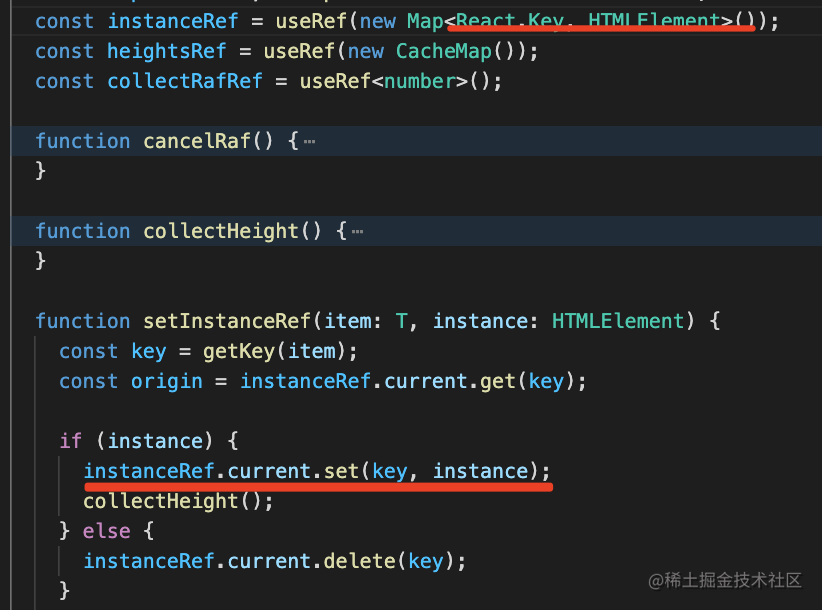
让你 React 组件水平暴增的 5 个技巧
目录 透传 className、style 通过 forwardRef 暴露一些方法 useCallback、useMemo 用 Context 来跨组件传递值 React.Children、React.cloneElement 总结 最近看了一些 Ant Design 的组件源码,学到一些很实用的技巧,这篇文章来分享一下。 首先&am…...

阿里云部署 ChatGLM2-6B 与 langchain+ChatGLM
1.ChatGLM2-6B 部署 更新系统 apt-get update 安装git apt-get install git-lfs git init git lfs install 克隆 ChatGLM2-6B 源码 git clone https://github.com/THUDM/ChatGLM2-6B.git 克隆 chatglm2-6b 模型 #进入目录 cd ChatGLM2-6B #创建目录 mkdir model #进入目录 cd m…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...