【LangChain】检索器之上下文压缩
LangChain学习文档
- 【LangChain】检索器(Retrievers)
- 【LangChain】检索器之MultiQueryRetriever
- 【LangChain】检索器之上下文压缩
上下文压缩
- LangChain学习文档
- 概要
- 内容
- 使用普通向量存储检索器
- 使用 LLMChainExtractor 添加上下文压缩(Adding contextual compression with an LLMChainExtractor)
- 更多内置压缩机:过滤器(More built-in compressors: filters)
- LLMChainFilter
- EmbeddingsFilter
- 将压缩器和文档转换器串在一起(Stringing compressors and document transformers together)
- 总结
概要
检索的一项挑战是,通常我们不知道:当数据引入系统时,文档存储系统会面临哪些特定查询。
这意味着与查询最相关的信息可能被隐藏在包含大量不相关文本的文档中。
通过我们的应用程序传递完整的文件可能会导致更昂贵的llm通话和更差的响应。
上下文压缩旨在解决这个问题。
这个想法很简单:我们可以使用给定查询的上下文来压缩它们,以便只返回相关信息,而不是立即按原样返回检索到的文档。
这里的“压缩”既指压缩单个文档的内容,也指批量过滤文档。
要使用上下文压缩检索器,我们需要:
- 基础检索器
- 文档压缩器
上下文压缩检索器将查询传递给基础检索器,获取初始文档并将它们传递给文档压缩器。文档压缩器获取文档列表并通过减少文档内容或完全删除文档来缩短它。
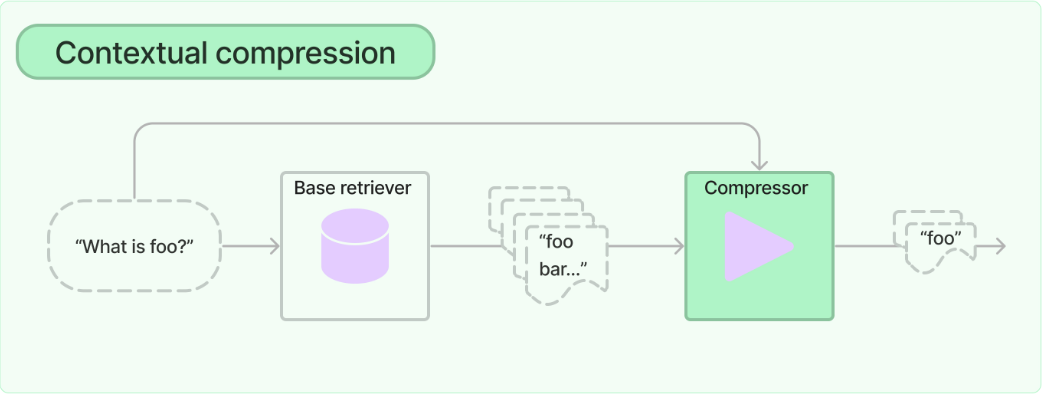
内容
# 打印文档的辅助功能def pretty_print_docs(docs):print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
使用普通向量存储检索器
让我们首先初始化一个简单的向量存储检索器并存储 2023 年国情咨文演讲(以块的形式)。我们可以看到,给定一个示例问题,我们的检索器返回一两个相关文档和一些不相关的文档。甚至相关文档中也有很多不相关的信息。
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
# 加载文档
documents = TextLoader('../../../state_of_the_union.txt').load()
# 拆分器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
# 拆分文档
texts = text_splitter.split_documents(documents)
# 构建索引,并构建检索器
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
# 运行
docs = retriever.get_relevant_documents("What did the president say about Ketanji Brown Jackson")
# 美化打印
pretty_print_docs(docs)
结果:
Document 1:Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.----------------------------------------------------------------------------------------------------Document 2:A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.----------------------------------------------------------------------------------------------------Document 3:And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong. As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice. And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. First, beat the opioid epidemic.----------------------------------------------------------------------------------------------------Document 4:Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers. And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up. That ends on my watch. Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect. We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees. Let’s pass the Paycheck Fairness Act and paid leave. Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty. Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
使用 LLMChainExtractor 添加上下文压缩(Adding contextual compression with an LLMChainExtractor)
现在让我们用 ContextualCompressionRetriever 包装我们的基本检索器。我们将添加一个 LLMChainExtractor,它将迭代最初返回的文档,并从每个文档中仅提取与查询相关的内容。
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 构建大模型
llm = OpenAI(temperature=0)
# 从大模型中构建LLMChainExtractor
compressor = LLMChainExtractor.from_llm(llm)
# 构建压缩检索器
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
# 运行
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
# 美化打印
pretty_print_docs(compressed_docs)
结果:
Document 1:"One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence."----------------------------------------------------------------------------------------------------Document 2:"A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
更多内置压缩机:过滤器(More built-in compressors: filters)
LLMChainFilter
LLMChainFilter 是稍微简单但更强大的压缩器,它使用 LLM Chain来决定过滤掉最初检索到的文档中的哪些文档以及返回哪些文档,而无需操作文档内容。
from langchain.retrievers.document_compressors import LLMChainFilter# 构建LLMChainFilter
_filter = LLMChainFilter.from_llm(llm)
# 构建上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(base_compressor=_filter, base_retriever=retriever)
# 运行
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
# 美化打印
pretty_print_docs(compressed_docs)
Document 1:Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
EmbeddingsFilter
对每个检索到的文档进行额外的 LLM 调用既昂贵又缓慢。 EmbeddingsFilter 通过嵌入文档和查询并仅返回那些与查询具有足够相似嵌入的文档来提供更便宜且更快的选项。
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers.document_compressors import EmbeddingsFilter
# 构建嵌入
embeddings = OpenAIEmbeddings()
# 构建EmbeddingsFilter
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
# 构建上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(base_compressor=embeddings_filter, base_retriever=retriever)
# 运行
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
# 美化打印
pretty_print_docs(compressed_docs)
结果:
Document 1:Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.----------------------------------------------------------------------------------------------------Document 2:A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.----------------------------------------------------------------------------------------------------Document 3:And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong. As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice. And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. First, beat the opioid epidemic.
将压缩器和文档转换器串在一起(Stringing compressors and document transformers together)
使用 DocumentCompressorPipeline 我们还可以轻松地按顺序组合多个压缩器。除了压缩器之外,我们还可以将 BaseDocumentTransformers 添加到管道中,它不执行任何上下文压缩,而只是对一组文档执行一些转换。
例如,TextSplitters 可以用作文档转换器,将文档分割成更小的部分,而 EmbeddingsRedundantFilter 可以用于根据文档之间嵌入的相似性来过滤掉冗余文档。
下面我们创建一个压缩器管道,首先将文档分割成更小的块,然后删除冗余文档,然后根据与查询的相关性进行过滤。
from langchain.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.text_splitter import CharacterTextSplitter
# 构建拆分器
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
# 构建EmbeddingsRedundantFilter
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
# 构建嵌入过滤器:EmbeddingsFilter
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
# 构建文档管道
pipeline_compressor = DocumentCompressorPipeline(transformers=[splitter, redundant_filter, relevant_filter]
)
# 构建上下文检索器
compression_retriever = ContextualCompressionRetriever(base_compressor=pipeline_compressor, base_retriever=retriever)
# 运行
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
# 美化打印
pretty_print_docs(compressed_docs)
结果:
Document 1:One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson----------------------------------------------------------------------------------------------------Document 2:As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year----------------------------------------------------------------------------------------------------Document 3:A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder
总结
我们在进行文档搜索的时候,正相关的文档是少部分,大部分都是不相关的文档。
我们可以使用上下文压缩检索器,只返回正相关的那部分文档。
主要步骤:
- 构建一个普通检索器:
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever() - 构建一个上下文压缩检索器:
ContextualCompressionRetriever(base_compressor=embeddings_filter, base_retriever=retriever)
特别是第二步骤:构建上下文压缩器的第一个参数,有很多花样:
① LLMChainExtractor 提取,精炼
② LLMChainFilter 普通过滤
③ EmbeddingsFilter 嵌入过滤
④ DocumentCompressorPipeline 文档管道,可以将多个过滤器组合在一起。
参考地址:
https://python.langchain.com/docs/modules/data_connection/retrievers/how_to/contextual_compression/
相关文章:
【LangChain】检索器之上下文压缩
LangChain学习文档 【LangChain】检索器(Retrievers)【LangChain】检索器之MultiQueryRetriever【LangChain】检索器之上下文压缩 上下文压缩 LangChain学习文档 概要内容使用普通向量存储检索器使用 LLMChainExtractor 添加上下文压缩(Adding contextual compression with an…...
uniapp 语音文本播报功能
最近uniapp项目上遇到一个需求 就是在接口调用成功的时候加上语音播报 , ‘创建成功’ ‘开始成功’ ‘结束成功’ 之类的。 因为是固定的文本 ,所以我先利用工具生成了 文本语音mp3文件,放入项目中,直接用就好了。 这里用到的工…...

腾讯云高IO型云服务器CPU型号处理器主频性能
腾讯云服务器高IO型CVM实例CPU处理器主频性能说明,高IO型云服务器具有高随机IOPS、高吞吐量、低访问延时等特点,适合对硬盘读写和时延要求高的高性能数据库等I/O密集型应用,腾讯云服务器网分享高IO型云服务器IT5和IT3的CPU处理器说明…...
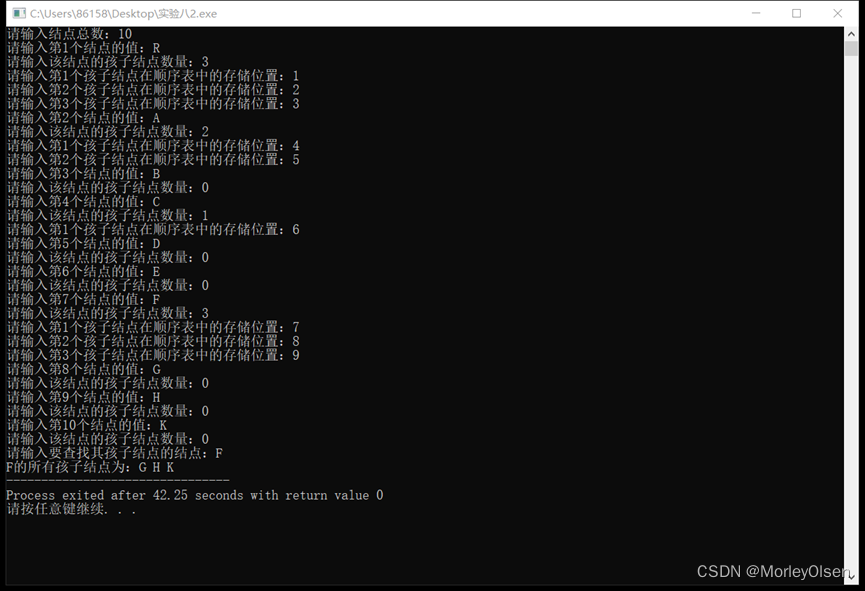
【数据结构】实验八:树
实验八 树 一、实验目的与要求 1)理解树的定义; 2)掌握树的存储方式及基于存储结构的基本操作实现; 二、 实验内容 题目一:采用树的双亲表示法根据输入实现以下树的存储,并实现输入给定结点的双亲结点…...
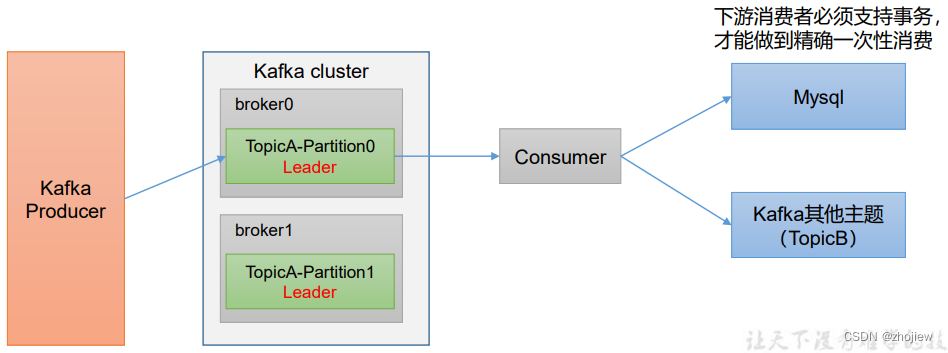
kafka消费者api和分区分配和offset消费
kafka消费者 消费者的消费方式为主动从broker拉取消息,由于消费者的消费速度不同,由broker决定消息发送速度难以适应所有消费者的能力 拉取数据的问题在于,消费者可能会获得空数据 消费者组工作流程 Consumer Group(CG&#x…...
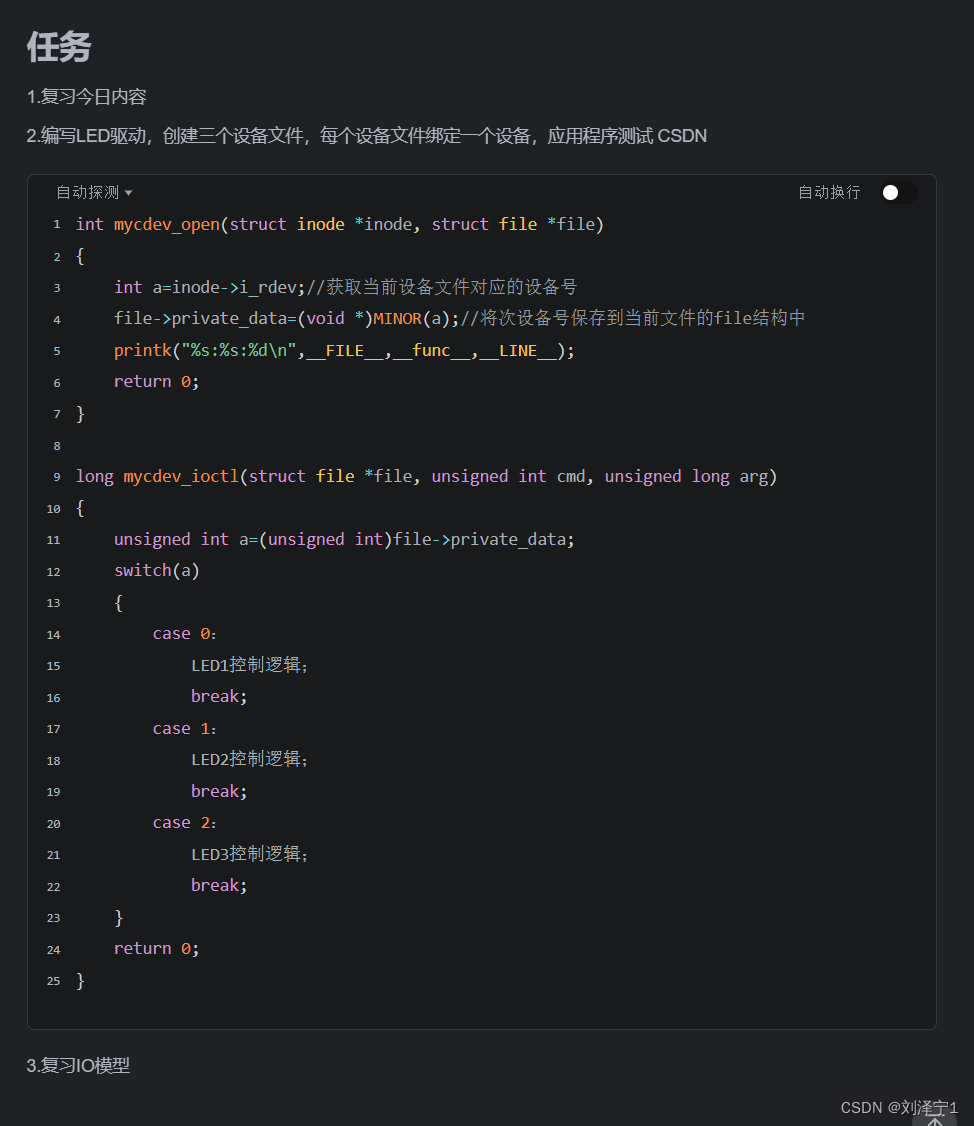
【驱动开发day4作业】
头文件代码 #ifndef __HEAD_H__ #define __HEAD_H__ typedef struct{unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t; #define PHY_LED1_ADDR 0X50006000 #define PHY_LED2_ADDR 0X50007000 #…...

Ubuntu 20.04 Ubuntu18.04安装录屏软件Kazam
1.在Ubuntu Software里面输入Kazam,就可以找不到这个软件,直接点击install就可以了 2.使用方法: 选择Screencast(录屏) Fullscreen(全屏)-----Windows(窗口)--------Ar…...

ADC 的初识
ADC介绍 Q: ADC是什么? A: 全称:Analog-to-Digital Converter,指模拟/数字转换器 ADC的性能指标 量程:能测量的电压范围分辨率:ADC能辨别的最小模拟量,通常以输出二进制数的位数表示,比如&am…...

MMdetection框架速成系列 第07部分:数据增强的N种方法
MMdetection框架实现数据增强的N种方法 1 为什么要进行数据增强2 数据增强的常见误区3 常见的六种数据增强方式3.1 随机翻转(RandomFlip)3.2 随机裁剪(RandomCrop)3.3 随机比例裁剪并缩放(RandomResizedCrop࿰…...

基于Kitti数据集的智能驾驶目标检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于Kitti数据集的智能驾驶目标检测系统可用于日常生活中检测与定位行人(Pedestrian)、面包车(Van)、坐着的人(Person Sitting)、汽车(Car)、卡车(Truck…...

4.4. 深拷贝 vs 浅拷贝
文章目录 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为…...
网络安全(黑客)自学建议笔记
前言 网络安全,顾名思义,无安全,不网络。现如今,安全行业飞速发展,我们呼吁专业化的 就职人员与大学生 ,而你,认为自己有资格当黑客吗? 本文面向所有信息安全领域的初学者和从业人员…...
Linux CentOS快速安装VNC并开启服务
以下是在 CentOS 上安装并开启 VNC 服务的步骤: 安装 VNC 服务器软件包。运行以下命令: sudo yum install tigervnc-server 输出 $ sudo yum install tigervnc-server Loaded plugins: fastestmirror, langpacks Repository epel is missing name i…...
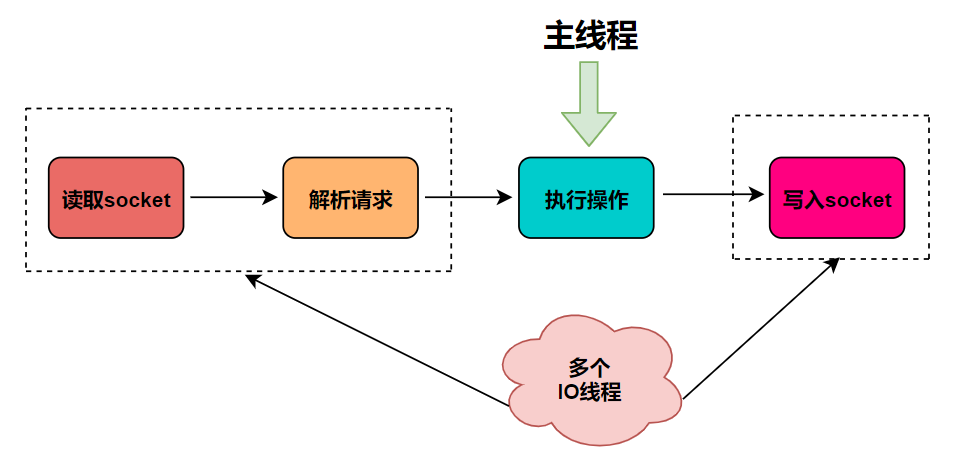
redis到底几个线程?
通常我们说redis是单线程指的是从接收客户端请求->解析请求->读写->响应客户端这整个过程是由一个线程来完成的。这并不意味着redis在任何场景、任何版本下都只有一个线程 为何用单线程处理数据读写? 内存数据储存已经很快了 redis相比于mysql等数据库是…...

mysql修改UUID
mysql修改UUID 问题描述:集群搭建时克隆主服务的镜像导致所有节点的服务UUID都一致,此时在集群中添加节点时会提示UUID冲突报错。 解决方案 1、利用uuid函数生成新的uuid mysql> select uuid(); -------------------------------------- | uuid() …...
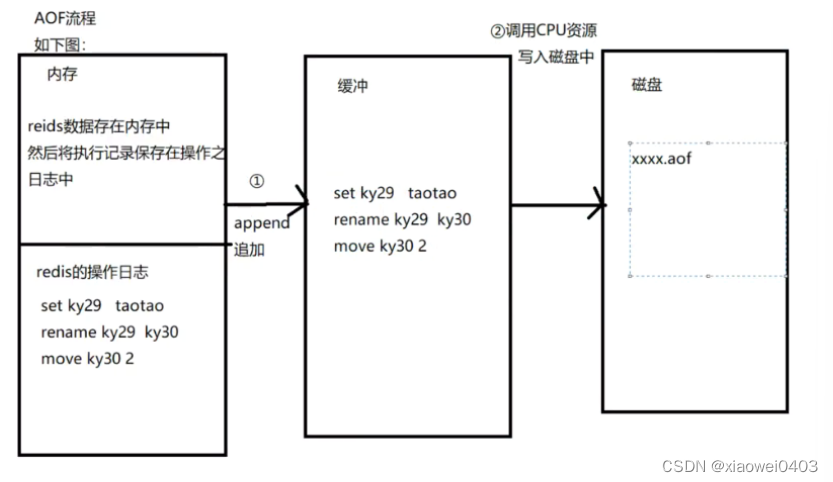
NoSQL之redis配置与优化
NoSQL之redis配置与优化 高可用持久化功能Redis提供两种方式进行持久化1.触发条件手动触发自动触发 执行流程优缺点缺点:优势AOF出发规则: AOF流程AOF缺陷和优点 NoSQL之redis配置与优化 mysql优化 1线程池优化 2硬件优化 3索引优化 4慢查询优化 5内…...

Python单例模式介绍、使用
一、单例模式介绍 概念:单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供访问该实例的全局访问点。 功能:单例模式的主要功能是确保在应用程序中只有一个实例存在。 优势: 节省系统资源:由…...
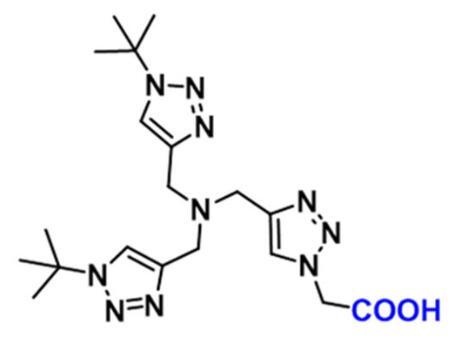
1334179-85-9,BTTAA,是各种化学生物学实验中生物偶联所需
资料编辑|陕西新研博美生物科技有限公司小编MISSwu BTTAA试剂 | 基础知识概述(部分): 中文名称:2-[4-({双[(1-叔丁基-1H-1,2,3-三唑-4-基)甲基]氨基}甲基)-1H-1,2,3-三唑-1-基]乙酸 英文名称:BTTAA CAS号:1334179-8…...

Linux系统中的SQL语句
本节主要学习,SQL语句的语句类型,数据库操作,数据表操作,和数据操作等。 文章目录 一、SQL语句类型 DDL DML DCL DQL 二、数据库操作 1.查看 2.创建 默认字符集 指定字符集 3.进入 4.删除 5.更改 库名称 字符集 6…...

力扣27 26 283 844 977 移除数组
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...