【小白慎入】还在手动撸浏览器?教你一招分分钟自动化操作浏览器(Python进阶)
大家好啊,辣条哥又来猛货了!
小白慎入!

目录
- 环境安装
- 1 测试样例
- 2 基本配置
- 2.0 基本参数
- 2.1 设置窗口
- 2.2 添加头部
- 2.3 网页截图
- 2.4 伪装浏览器 绕过检测
- 2.5案例演示 触发JS
- 2.6 boss直聘cookie反爬绕过实践
- 2. 7滚动到页面底部
- 3 进阶使用
- 4 数据提取
- 5 获取属性
- 6 登录案例
- 7 综合案例
Puppeteer 是 Google 基于 Node.js 开发的一个工具,而 Pyppeteer 又是什么呢?它实际上是Puppeteer 的 Python 版本的实现,但它不是Google 开发的,是一位来自于日本的工程师依据Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。

总的来说,两款浏览器的内核是一样的,实现方式也是一样的,可以认为是开发版和正式版的区别,功能上基本是没有太大区别的。
环境安装
pip install pyppeteer
注意: 支持异步需要3.5以上的解释器
import pyppeteer
print(pyppeteer.__chromium_revision__) # 查看版本号
print(pyppeteer.executablePath()) # 查看 Chromium 存放路径
# pyppeteer-install 帮助你去安装谷歌
如果无法启动,需要手动改文件路径
官方网站:https://miyakogi.github.io/pyppeteer/reference.html

1 测试样例
from pyppeteer import launch
import asyncio
import time
async def main():
# 启动一个浏览器
browser = await launch(headless=False,args=['--disable-infobars','--windowsize=1920,1080'])
# 创建一个页面
page = await browser.newPage()
# 跳转到百度
await page.goto("http://www.baidu.com/")
# 输入要查询的关键字,type 第一个参数是元素的selector,第二个是要输入的关键字
await page.type('#kw','pyppeteer')
# 点击提交按钮 click 通过selector点击指定的元素
await page.click('#su')
time.sleep(3)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
2 基本配置
2.0 基本参数
params={
# 关闭无头浏览器
"headless": False,
'dumpio':'True', # 防止浏览器卡住
r'userDataDir':'./cache-data', # 用户文件地址
"args": [
'--disable-infobars', # 关闭自动化提示框
'--window-size=1920,1080', # 窗口大小
'--log-level=30', # 日志保存等级, 建议设置越小越好,要不然生成的日志占用的空间会
很大 30为warning级别
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
'--proxy-server=http://localhost:1080' # 代理
],
}
2.1 设置窗口
# UI模式 频闭警告
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.setViewport({'width': 1200, 'height': 800})
2.2 添加头部
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML,
like Gecko) Chrome/19.0.1084.36 Safari/536.5")
2.3 网页截图
page.screenshot(path='example.png')
2.4 伪装浏览器 绕过检测
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并
返回此对象。
# 伪装
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } })}')
await page.goto('https://intoli.com/blog/not-possible-to-block-chromeheadless/chrome-headless-test.html')
2.5案例演示 触发JS
async def run():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': 1200, 'height': 800})
await page.goto('https://www.zhipin.com/job_detail/?
query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=')
dimensions = await page.evaluate('''() => {
return {
cookie: window.document.cookie,
}
}''')
print(dimensions,type(dimensions))
asyncio.get_event_loop().run_until_complete(run())
2.6 boss直聘cookie反爬绕过实践
import asyncio,requests
from pyppeteer import launch
async def run():
browser = await launch()
page = await browser.newPage()
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5
(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5")
await page.setViewport(viewport={'width': 1536, 'height': 768})
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')
await page.goto('https://www.zhipin.com/job_detail/?
query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=')
dimensions = await page.evaluate('''() => {
return {
cookie: window.document.cookie,
}
}''')
headets = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'cookie': dimensions.get('cookie')
}
res = requests.get(
'https://www.zhipin.com/job_detail/?
query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=',
headers=headets)
print(res.text)
注:boss主要是cookie token反爬还有IP监测
2. 7滚动到页面底部
await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')
接下来看看它的参数简介:
- ignoreHTTPSErrors (bool):是否要忽略 HTTPS 的错误,默认是 False。
- headless (bool):是否启用 Headless 模式,即无界面模式,如果devtools 这个参数是 True 的 话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
- executablePath (str):可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可 以指定为已有的 Chrome 或 Chromium。
- slowMo (int|float):通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。
- args (List[str]):在执行过程中可以传入的额外参数。
- ignoreDefaultArgs (bool):不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。
- handleSIGINT (bool):是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认 是 True。
- handleSIGTERM (bool):是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。
- handleSIGHUP (bool):是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。
- dumpio (bool):是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默 认是 False。
- userDataDir (str):即用户数据文件夹,即可以保留一些个性化配置和操作记录。
- env (dict):环境变量,可以通过字典形式传入。
- devtools (bool):是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为True,那么 headless 参数就会无效,会被强制设置为 False。
- logLevel (int|str):日志级别,默认和 root logger 对象的级别相同。
- autoClose (bool):当一些命令执行完之后,是否自动关闭浏览器,默认是 True。
- loop (asyncio.AbstractEventLoop):事件循环对象。
3 进阶使用
import asyncio from pyppeteer import launch from pyquery import PyQuery as pq async def main(): browser = await launch(headless=False) # 打开浏览器 page = await browser.newPage() # 开启选项卡 # 输入地址访问页面 await page.goto('https://careers.tencent.com/search.html?keyword=python') # 调用选折器 await page.waitForXPath('//div[@class="recruit-wrap recruit-margin"]/div') # 获取网页源代码 doc = pq(await page.content()) # 提取数据 title = [item.text() for item in doc('.recruit-title').items()] print('title:', title) # 关闭浏览器 await browser.close() # 启动异步方法 asyncio.get_event_loop().run_until_complete(main())4 数据提取
# 在页面内执行 document.querySelector。如果没有元素匹配指定选择器,返回值是 None J = querySelector # 在页面内执行 document.querySelector,然后把匹配到的元素作为第一个参数传给 pageFunction Jeval = querySelectorEval # 在页面内执行 document.querySelectorAll。如果没有元素匹配指定选择器,返回值是 [] JJ = querySelectorAll # 在页面内执行 Array.from(document.querySelectorAll(selector)),然后把匹配到的元素数组 作为第一个参数传给 pageFunction JJeval = querySelectorAllEval # XPath表达式 Jx = xpath # Pyppeteer 三种解析方式 Page.querySelector() # 选择器 css 选择器 Page.querySelectorAll() Page.xpath() # xpath 表达式 # 简写方式为: Page.J(), Page.JJ(), and Page.Jx()5 获取属性
提取目标地址:https://pic.netbian.com/4kmeinv/index.html 所有的图片资源
async def mains1(): browser = await launch(headless=False, args=['--disable-infobars']) page = await browser.newPage() await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5") await page.setViewport(viewport={'width': 1536, 'height': 768}) await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,' '{ webdriver:{ get: () => false } }) }') await page.goto('https://pic.netbian.com/4kmeinv/index.html') elements = await page.querySelectorAll(".clearfix li a img") for item in elements: # 获取连接 title_link = await (await item.getProperty('src')).jsonValue() print(title_link) await browser.close() asyncio.get_event_loop().run_until_complete(mains1())6 登录案例
import asyncio from pyppeteer import launch async def mains2(): browser = await launch({'headless': False, 'args': ['--disable-infobars', '- -window-size=1920,1080']}) page = await browser.newPage() await page.setViewport({'width': 1920, 'height': 1080}) await page.goto('https://www.captainbi.com/amz_login.html') await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,' '{ webdriver:{ get: () => false } }) }') await page.type('#username', '13555553333') # 账号 await page.type('#password', '123456') # 密码 await asyncio.sleep(2) await page.click('#submit',{'timeout': 3000}) import time # await browser.close() print('登录成功') asyncio.get_event_loop().run_until_complete(mains2())7 综合案例
# encoding: utf-8 """ @author: 夏洛 @QQ: 1972386194 @site: https://www.tulingxueyuan.cn/ @file: 唯品会.py """ import requests from lxml import etree from loguru import logger import pandas as pd from utils import ua import asyncio from pyppeteer import launch class Wph(object): def __init__(self,url,name): self.url = url self.name = name self.headers = { 'user-agent': ua.get_random_useragent() } self.session = requests.session() self.hadlnone = lambda x:x[0] if x else '' async def main(self,url): global browser browser = await launch() page = await browser.newPage() await page.goto(url) text = await page.content() # 返回页面html return text def spider(self): df = pd.DataFrame(columns=['品牌', '标题', '原价', '现价', '折扣']) # 发起HTTP请求 # https://category.vip.com/suggest.php? keyword=%E5%8F%A3%E7%BA%A2&brand_sn=10000359 res = self.session.get(self.url,params={'keyword':self.name},headers = self.headers,verify=False) html = etree.HTML(res.text) url_list = html.xpath('//div[@class="c-filter-groupcontent"]/div[contains(@class,"c-filter-group-scroll-brand")]/ul/li/a/@href') # 迭代品牌URL地址 for i in url_list: ua.wait_some_time() # 驱动浏览器 请求 page_html = asyncio.get_event_loop().run_until_complete(self.main('http:' + i)) # 获取网页源代码 page = etree.HTML(page_html) htmls = page.xpath('//section[@id="J_searchCatList"]/div') # 迭代商品URL列表 for h in htmls[1:]: # 评判 pingpai = self.hadlnone(h.xpath('//div[contains(@class,"cbreadcrumbs-cell-title")]/span/text()')) # 标题 title = self.hadlnone(h.xpath('.//div[contains(@class,"cgoods-item__name")]/text()')) # 价格 原价 y_price = self.hadlnone(h.xpath('.//div[contains(@class,"cgoods-item__market-price")]/text()')) # 卖价 x_price = self.hadlnone(h.xpath('.//div[contains(@class,"cgoods-item__sale-price")]/text()')) # 折扣 zk = self.hadlnone(h.xpath('.//div[contains(@class,"c-goodsitem__discount")]/text()')) logger.info(f'品牌{pingpai},标题{title},原价{y_price},现价 {x_price},折扣{zk}') # 构造字典 pro = { '品牌':pingpai, '标题':title, '原价':y_price, '现价':x_price, '折扣':zk } df = df.append([pro]) df.to_excel('唯品会数据2.xlsx',index=False) return df def __del__(self): browser.close() if __name__ == '__main__': url = 'https://category.vip.com/suggest.php' name = '香水' w = Wph(url,name) w.spider()
相关文章:
【小白慎入】还在手动撸浏览器?教你一招分分钟自动化操作浏览器(Python进阶)
大家好啊,辣条哥又来猛货了! 小白慎入! 目录 环境安装1 测试样例2 基本配置2.0 基本参数2.1 设置窗口2.2 添加头部2.3 网页截图2.4 伪装浏览器 绕过检测2.5案例演示 触发JS2.6 boss直聘cookie反爬绕过实践2. 7滚动到页面底部 3 进阶使用4 数…...
组件的介绍及使用)
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用 1. 什么是TouchInputModule组件? TouchInputModule是Unity中的一个UGUI组件,用于处理触摸输入事件。它可以让你的游戏在移动设备上实现触摸操作,如点击、滑动、缩放等。 2. …...
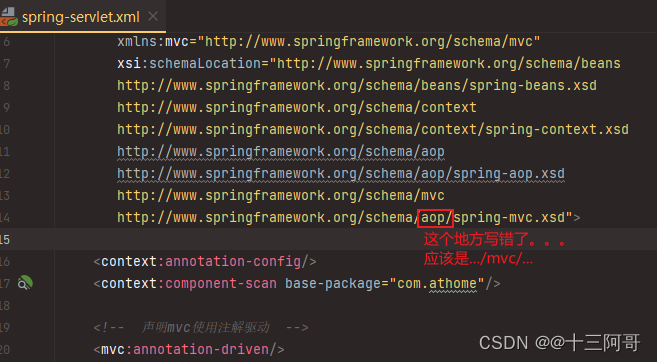
SpringMVC启动时非常缓慢,显示一直在部署中,网页也无法访问,,,Artifact is being deployed, please wait...
写了一个基本的SpringMVC程序进行测试,结果启动时一直显示在等待部署完毕,,, but这个地方一直显示转圈圈。。 后来通过url访问时网页一直转圈圈。。也就是等待响应。。 看了一会儿,也不知道哪儿错了,&…...

Docker 镜像操作
Docker镜像操作 我们已经介绍了容器操作,今天来了解下 Docker镜像 以及 镜像操作 。让我们一起开启镜像之旅吧。 Docker镜像 镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时、库…...

linux下有关mysql安装和登录的一些问题记录
1. 输入mysql -u root -p出现报错 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /var/run/mysqld/mysqld.sock (2) 前提:MySQL可执行文件位于/usr/local/mysql/bin目录中,如果MySQL安装路径不同,需要相应修改命令…...
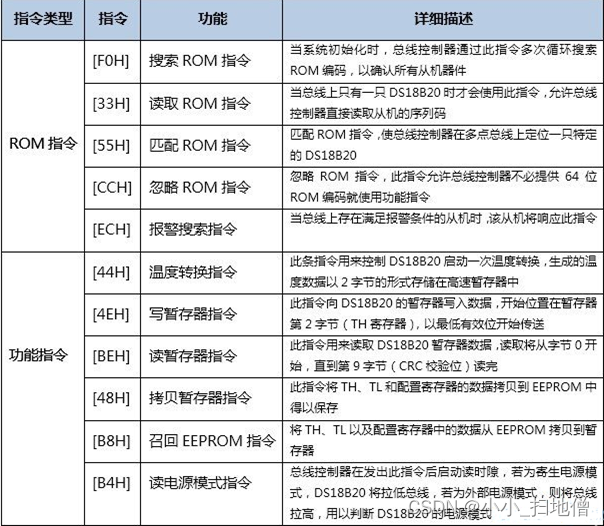
DS18B20的原理及实例代码(51单片机、STM32单片机)
一、DS18B20介绍 DS18B20数字温度传感器是DALLAS公司生产的单总线器件,用它来组成一个测温系统具有线路简单,体积小,在一根通信线上可以挂很多这样的数字温度传感器,十分方便。 温度传感器种类众多,应用在高精度、高可…...

两种单例模式
1.单例模式分为两种,饿汉模式和懒汉模式.以下是饿汉模式: public class SingleTonHungry {private static SingleTonHungry singleTonHungry new SingleTonHungry();private SingleTonHungry() {}public static SingleTonHungry getInstance() {return singleTonHungry;} }2.…...

List中交集的使用
前言 新增了一个需求,需要将所有药品和对应数量库存的药房查询出来,要求:‘所有药品该药房都要有,并且库存大于购药数量’; 这就得考虑一个问题,有的药房有该药品,有的药房没有该药品…...

TypeScript基础篇 - TS的函数
目录 构造函数表达 泛型和函数 泛型函数 Contextual Typing【上下文映射,上下文类型】 泛型约束 手动指定类型 泛型的使用规范 对比 可选参数 思考:onClick中e的设计 函数重载 修改办法 操作符重载 THIS void【空返回值】 思考为什么这样…...
Vue项目如何生成树形目录结构
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、有兴趣的可以关注一手。 前言 项目的目录结构清晰、可以帮助我们更快理顺项目的整体构成。在写文档之类的时候也比较方便。生成树形目录的方式有多种,我这里简单介绍其中一种较为简单的实现 过…...
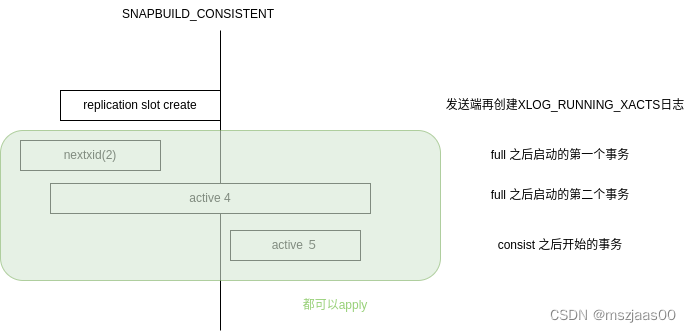
postgresql四种逻辑复制的状态
准备 CreateCheckpoint,或者bgwriter启动时,或者创建logicalreplicationslot时都会调用LogStandbySnapshot 记录一个XLOG_RUNNING_XACTS类型的日志。日志中记录了所有提交的事务的xid(HistoricSnapshot) 启动(SNAPBUILD_BUILDING_SNAPSHOT&…...
梯度下降法和牛顿法
梯度下降法和牛顿法都是优化方法。 梯度下降法 梯度下降法和相关知识可以参考导数、偏导数、梯度、方向导数、梯度下降、二阶导数、二阶方向导数一文。梯度下降法是一种迭代地每次沿着与梯度相反方向前进的不断降低损失函数的优化方法。梯度下降只用到一阶导数的信息…...
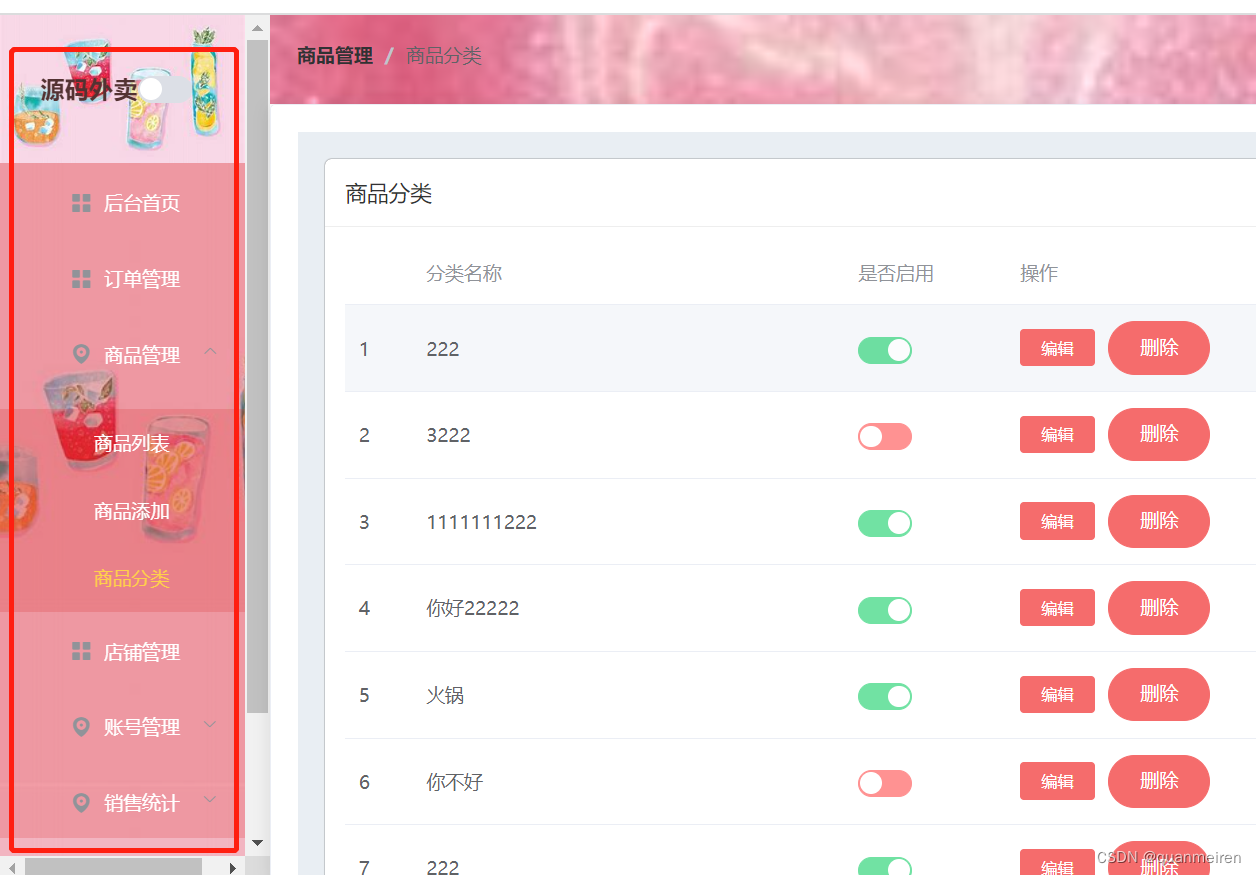
elment-ui的侧边栏 开关及窗口联动
<template><div class"asders"><el-aside width"200px"><div class"boxbody"><div>源码外卖</div><el-switch v-model"isCollapse" :active-value"true" :inactive-value"fals…...

【从零开始学习JAVA | 第三十二篇】 异常(下)新手必学!
目录 前言: Exceptions(异常): 异常的两大作用: 异常的处理方式: 1.JVM默认处理 2.自己捕获异常 3.抛出处理 自定义异常: 异常的优点: 总结: 前言: 前…...

onnxruntime (C++/CUDA) 编译安装
一、克隆及编译 git clone --recursive https://github.com/Microsoft/onnxruntime cd onnxruntime/ git checkout v1.8.0如果克隆的时候报错: 执行以下: apt-get install gnutls-bin git config --global http.sslVerify false git config --global h…...

第三篇-Tesla P40+CentOS-7+CUDA 11.7 部署实践
第一篇-ChatGLM-webui-Windows安装部署-CPU版 第二篇-二手工作站配置 第三篇-Tesla P40CentOS-7CUDA 11.7 部署实践 硬件环境 系统:CentOS-7 CPU: 14C28T 显卡:Tesla P40 24G 准备安装 驱动: 515 CUDA: 11.7 cuDNN: 8.9.2.26 安装依赖 yum clean al…...
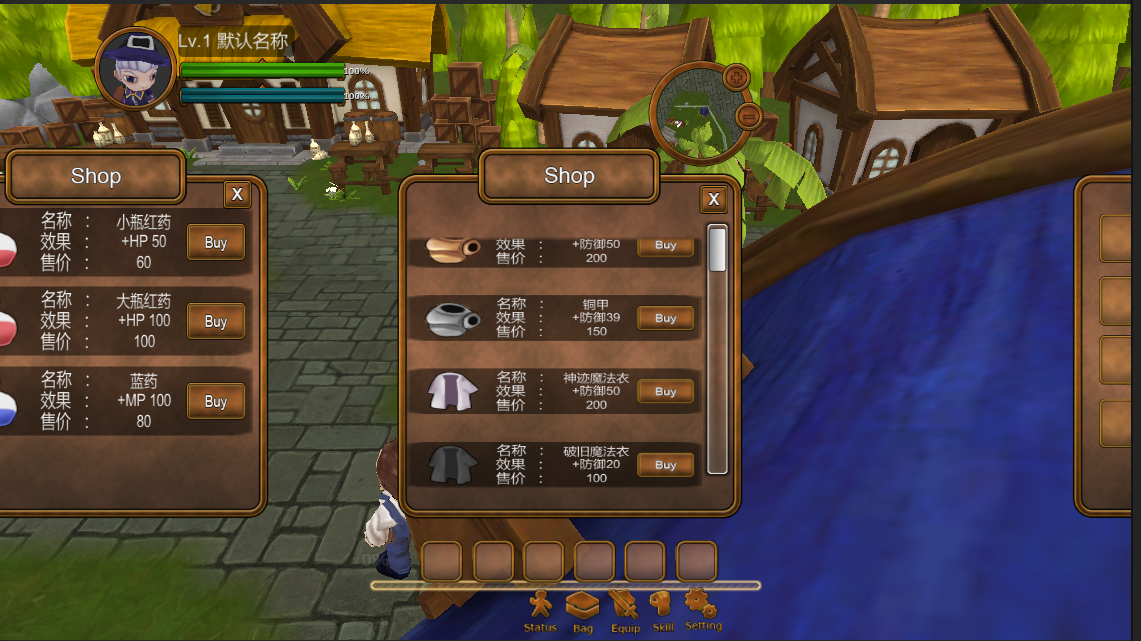
Unity游戏源码分享-ARPG游戏Darklight.rar
Unity游戏源码分享-ARPG游戏Darklight.rar 玩法 项目地址:https://download.csdn.net/download/Highning0007/88105464...

类型转换运算符
当我们想要将自定义类的对象转换为目标类型时,我们可以通过重载类型转换运算符(conversion operator)来实现。 以下是一个示例代码,展示了如何在 C 中定义一个自定义类,并重载类型转换运算符将对象转换为目标类型&…...

Kafka 入门到起飞系列 - 消费者组管理、位移管理
消费者组 - Consumer Group 上文我们已经讲过消费者组了,我们知道消费组的存在可以保证一个主题下一个分区的消息只会被组内一个消费者消费,从而避免了消息的重复消费 什么是消费组 - Consumer Group? 消费者组是Kafka 提供的可扩展且具有容…...

SpringBoot——数据层三组件之间的关系
简单介绍 在之前的文章中,我们介绍了一下SpringBoot中内置的几种数据层的解决方案,在数据层由三部分组成,分别是数据库,持久化技术以及数据源,但是我今天写着写着,突然就想不起来这三部分到底是干什么的了…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...