【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析
2023 年第二届钉钉杯大学生大数据挑战赛 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析

相关链接
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题二Python代码分析
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析
1 题目
Citi Bike是纽约市在2013年启动的一项自行车共享出行计划,由“花旗银行”(Citi Bank)赞助并取名为“花旗单车”(Citi Bike)。在曼哈顿,布鲁克林,皇后区和泽西市有8,000辆自行车和500个车站。为纽约的居民和游客提供一种 方便快捷,并且省钱的自行车出行方式。人们随处都能借到Citi Bank,并在他们的目的地归还。本案例的数据有两部分:第一部分是纽约市公共自行车的借还交易流水表。Citi Bik自行车与共享单车不同,不能使用手机扫码在任意地点借还车,而需要使用固定的自行车桩借还车,数据集包含2013年7月1日至2016年8 月31日共38个月(1158天)的数据,每个月一个文件。其中2013年7月到2014年8 月的数据格式与其它年月的数据格式有所差别,具体体现在变量starttime和stoptime的存储格式不同。
第二部分是纽约市那段时间的天气数据,并存储在weather_data_NYC.csv文 件中,该文件包含2010年至2016年的小时级别的天气数据。
公共自行车数据字段表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | trip duration | 旅行时长 | 骑行时间,数值型,秒 |
| 2 | start time | 出发时间 | 借车时间,字符串,m/d/YYY HH:MM:SS |
| 3 | stop time | 结束时间 | 还车时间,字符串,m/d/YYY HH:MM:SS |
| 4 | start station id | 借车站点编号 | 定性变量,站点唯一编号 |
| 5 | start station name | 借车站点名称 | 字符串 |
| 6 | start station latitude | 借车站点维度 | 数值型 |
| 7 | start station longtude | 借车站点经度 | 数值型 |
| 8 | end station id | 还车站点编号 | 定性变量,站点唯一编号 |
| 9 | end station name | 还车站点名称 | 字符串 |
| 10 | end station latitude | 还车站点纬度 | 数值型 |
| 11 | end station longitude | 还车站点经度 | 数值型 |
| 12 | bile id | 自行车编号 | 定性变量,自行车唯一编号 |
| 13 | Use type | 用户类型 | Subscriber:年度用户; Customer:24小时或者7天的临时用户 |
| 14 | birth year | 出生年份 | 仅此列存在缺失值 |
| 15 | gender | 性别 | 0:未知 1:男性 2:女性 |
天气数据字段简介表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | date | 日期 | 字符串 |
| 2 | time | 时间 | EDT(Eastern Daylight Timing)指美国东部夏令单位 |
| 3 | temperature | 气温 | 单位:℃ |
| 4 | dew_poit | 露点 | 单位:℃ |
| 5 | humidity | 湿度 | 百分数 |
| 6 | pressure | 海平面气压 | 单位:百帕 |
| 7 | visibility | 能见度 | 单位:千米 |
| 8 | wind_direction | 风向 | 离散型,类别包括west,calm等 |
| 9 | wind_speed | 风速 | 单位:千米每小时 |
| 10 | moment_wind_speed | 瞬间风速 | 单位:千米每小时 |
| 11 | precipitation | 降水量 | 单位:毫米,存在缺失值 |
| 12 | activity | 活动 | 离散型,类别包括snow等 |
| 13 | conditions | 状态 | 离散型,类别包括overcast,light snow等 |
| 14 | WindDirDegrees | 风向角 | 连续型,取值为0~359 |
| 15 | DateUTC | 格林尼治时间 | YYY/m/d HH:MM |
二、解决问题
- 自行车借还情况功能实现:
实现各个站点在一天的自行车借还情况网络图,该网络图是有向图,箭头从借车站点指向还车站点(很多站点之间同时有借还记录,所以大部分站点两两之间是双向连接)。
(一)以2014年8月3日为例进行网络分析,实现自行车借还网络图,计算网络图的节点数,边数,网络密度(表示边的个数占所有可能的连接比例数),给出计算过程和画图结果。
(二)使用上述的网络分析图,对经度位于40.695~40.72,纬度位于- 74.023~-73.973之间的局域网区域进行分析,计算出平均最短路径长度(所有点 两两之间的最短路径长度进行算数平均)和网络直径(被定义网络中最短路径的 最大值)。
- 聚类分析
对于2013年7月1日至2015年8月31日数据集的自行车数据进行聚类分析,选 择合适的聚类数量K值,至少选择两种聚类算法进行聚类,并且比较不同的聚类 方法以及分析聚类结果。
- 站点借车量的预测分析:
对所有站点公共自行车的借车量预测,预测出未来的单日借车量。将2013年 7月-2015年7月数据作为训练集,2015年8月1-31日的数据作为测试集,预测2015 年8月1-31日每天的自行车单日借车量。给出每个站点预测结果的MAPE,并且给 出模型的参数数量,最后算出所有站点的MAPE的均值(注:测试集不能参与到训 练和验证中,否则作违规处理)。
M A P E = 1 n ∑ ∣ y i − y i ^ y i ∣ × 100 % MAPE = \frac{1}{n} \sum{|\frac{y_i-\hat{y_i}}{y_i}|} \times 100\% MAPE=n1∑∣yiyi−yi^∣×100%
data.csv是纽约市公共自行车的借还交易流水信息,格式如下表,请使用python对数据预处理和特征工程后,聚类分析:
公共自行车数据字段表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | trip duration | 旅行时长 | 骑行时间,数值型,秒 |
| 2 | start time | 出发时间 | 借车时间,字符串,m/d/YYY HH:MM:SS |
| 3 | stop time | 结束时间 | 还车时间,字符串,m/d/YYY HH:MM:SS |
| 4 | start station id | 借车站点编号 | 定性变量,站点唯一编号 |
| 5 | start station name | 借车站点名称 | 字符串 |
| 6 | start station latitude | 借车站点维度 | 数值型 |
| 7 | start station longtude | 借车站点经度 | 数值型 |
| 8 | end station id | 还车站点编号 | 定性变量,站点唯一编号 |
| 9 | end station name | 还车站点名称 | 字符串 |
| 10 | end station latitude | 还车站点纬度 | 数值型 |
| 11 | end station longitude | 还车站点经度 | 数值型 |
| 12 | bile id | 自行车编号 | 定性变量,自行车唯一编号 |
| 13 | Use type | 用户类型 | Subscriber:年度用户; Customer:24小时或者7天的临时用户 |
| 14 | birth year | 出生年份 | 仅此列存在缺失值 |
| 15 | gender | 性别 | 0:未知 1:男性 2:女性 |
2 问题分析
2.1 问题一
- 绘制有向图
a. 读入数据并分别提取“起始站点编号”和“结束站点编号”两列数据,构建自行车借还网络图。
b. 对于第一步构建的网络图,我们需要计算网络图的节点数,边数,网络密度。节点数即为站点数,边数为借还次数。网络密度为边的数量占所有可能的连接比例。
c. 画出自行车借还网络图。
e. 计算平均最短路径长度和网络直径
首先选出符合条件(经度位于40.695~40.72,纬度位于- 74.023~-73.973之间)的借车站点和还车站点,并以它们为节点构建一个子图进行分析。然后可以直接使用networkx库中的函数来计算平均最短路径长度和网络直径。
2.2 问题二
-
数据预处理:对进行数据清洗和特征提取。可以使用PCA、LDA算法进行降维,减小计算复杂度。
-
聚类算法:
a. K-means: 进行数据聚类时,选择不同的K值进行多次试验,选取最优的聚类结果。可以使用轮廓系数、Calinski-Harabaz指数等评价指标进行比较和选择。
b. DBSCAN: 利用密度对数据点进行聚类,不需要预先指定聚类的数量。使用基于密度的聚类算法时,可以通过调整半径参数和密度参数来得到不同聚类效果。
c. 层次聚类:可分为自顶向下和自底向上两种方式。通过迭代计算每个数据点之间的相似度,将数据点逐渐合并,最后得到聚类结果。d.改进的聚类算法
e. 深度聚类算法
-
聚类结果分析:选择最优的聚类结果后,对不同类别骑车的用户进行画像。分析每个类别的用户行为特征。
2.3 问题三
- 导入数据并进行数据预处理,整合以站点为单位的借车数据。
- 对数据进行时间序列分析,使用ARIMA模型进行单日借车量预测。
- 使用时间序列交叉验证方法进行模型评估,计算每个站点预测结果的MAPE。
- 计算所有站点的MAPE的均值,给出模型的参数数量。
3 Python代码实现
3.1 问题一
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析
3.2 问题二
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题二Python代码分析
3.3 问题三
(1)合并天气数据
import pandas as pd
import os
# 加载数据
# 合并数据
folder_path = '初赛数据集/问题3数据集'
dfs = []
for filename in os.listdir(folder_path):if filename.endswith('.csv'):csv_path = os.path.join(folder_path, filename)tempdf = pd.read_csv(csv_path)[0:5000]dfs.append(tempdf)
bike_data = pd.concat(dfs,axis=0)
weather_data = pd.read_csv('初赛数据集/weather_data_NYC(3).csv')# 查看数据格式及之间的关联
print(bike_data.head())
print(weather_data.head())# 将“start time”列和“stop time”列转换为datetime格式
bike_data['starttime'] = pd.to_datetime(bike_data['starttime'])
bike_data['stoptime'] = pd.to_datetime(bike_data['stoptime'])
weather_data['date'] = pd.to_datetime(weather_data['date'])# 在每张表格中加入一个“day”列,代表日期
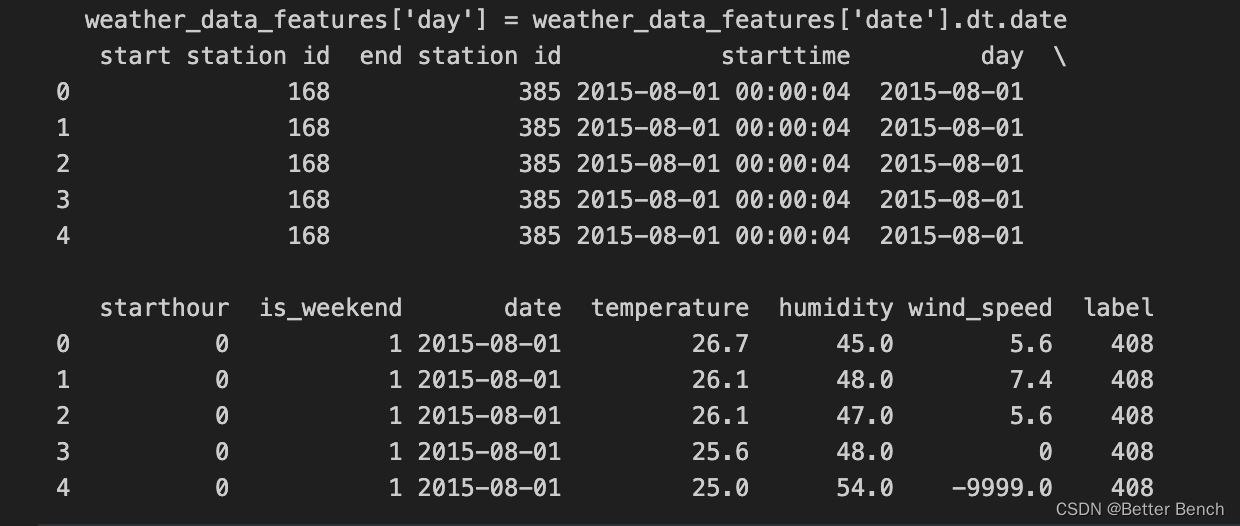
bike_data['day'] = bike_data['starttime'].dt.date
weather_data['day'] = weather_data['date'].dt.dateprint(bike_data.head())
print(weather_data.head())(2)特征工程
从两个数据集提取用于建模的特征。
-
对于公共自行车的使用情况,考虑借车站、还车站、借车时间等。
-
对于天气条件,还可以考虑温度、湿度、风速等因素。
# 对于公共自行车的使用情况,提取用于建模的特征
bike_data_features = bike_data[['start station id', 'end station id', 'starttime', 'day']]
...略# 对天气条件进行处理,提取用于建模的特征
weather_data_features = weather_data[['date', 'temperature', 'humidity', 'wind_speed']]
...略# 接下来,需要将两个数据集进行合并,以创建一个数据集来训练模型。我们可以通过将bike_data_features和weather_data_features根据日期(day)合并来实现:model_data = pd.merge(bike_data_features, weather_data_features, on='day', how='left')
# 类别特征编码
...略# 测试集:打标签,计算每天的借车数量
BorrowCounts = model_data.groupby(['day', 'start station id']).size().reset_index()
BorrowCounts = BorrowCounts.rename(columns={0: 'count'})
model_data = pd.merge(model_data, BorrowCounts, on=['day', 'start station id'], how='left')
...略print(model_data.head())
(3)模型训练
回归预测问题,可以采用回归模型,比如XGB、LGB、线性回归、神经网络回归等模型,常用的时间序列预测模型ARIMA模型、GARCH模型、LSTM等。以下是XGB为例。
# 将数据集拆分为训练集和测试集,建立模型并对它进行训练:import xgboost as xgb
from sklearn.metrics import mean_absolute_percentage_error, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()# 拆分数据集
train_data = model_data[model_data['day'] < pd.to_datetime('2015-08-01').date()]
test_data = model_data[model_data['day'] >= pd.to_datetime('2015-08-01').date()]# 定义输入特征以及输出
data_train = train_data[['start station id', 'end station id', 'starthour', 'is_weekend', 'temperature', 'humidity', 'wind_speed']]
Y_train = train_data['label']# 测试集:打标签,计算每天的借车数量
data_test = test_data[['start station id', 'end station id', 'starthour', 'is_weekend', 'temperature', 'humidity', 'wind_speed']]
Y_test = test_data['label']X_train = scaler.fit_transform(data_train)
X_test = scaler.transform(data_test)
# # 定义模型并训练
# XGBoost回归模型,还可以使用线性回归、决策树回归、神经网络回归
model = xgb.XGBRegressor(objective='reg:squarederror',n_jobs=-1,n_estimators=1000,max_depth=7,subsample=0.8,learning_rate=0.05,gamma=0,colsample_bytree=0.9,random_state=2023, max_features=None, alpha=0.3)
model.fit(X_train, Y_train)
(4) 模型评价与检验
# 计算每个站点的MAPE:
# 对测试集进行预测
Y_pred = model.predict(X_test)def calculate_mape(row):return mean_absolute_percentage_error([row['pred']],[row['true']])
# 计算每个站点的MAPE
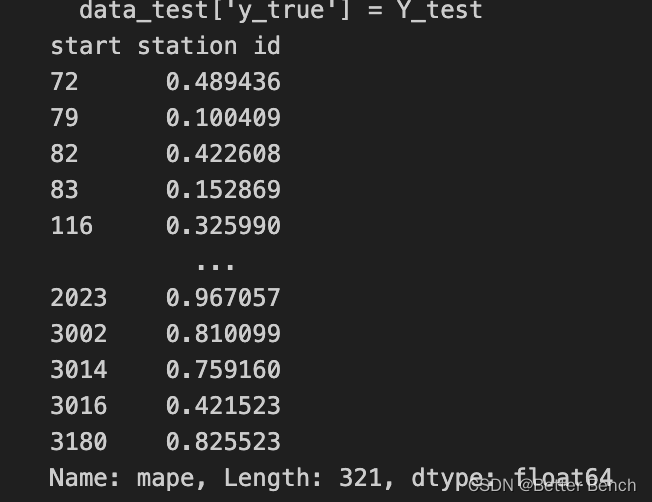
data_test['pred'] = Y_pred
data_test['y_true'] = Y_test
data_test['mape'] = data_test.apply(calculate_mape, axis=1)
mape_by_station = data_test.groupby('start station id')['mape'].mean()
print(mape_by_station)
# 计算所有站点的MAPE的均值
mape_mean = mean_absolute_percentage_error(Y_test,Y_pred)
print(mape_mean)
0.47444156668192194
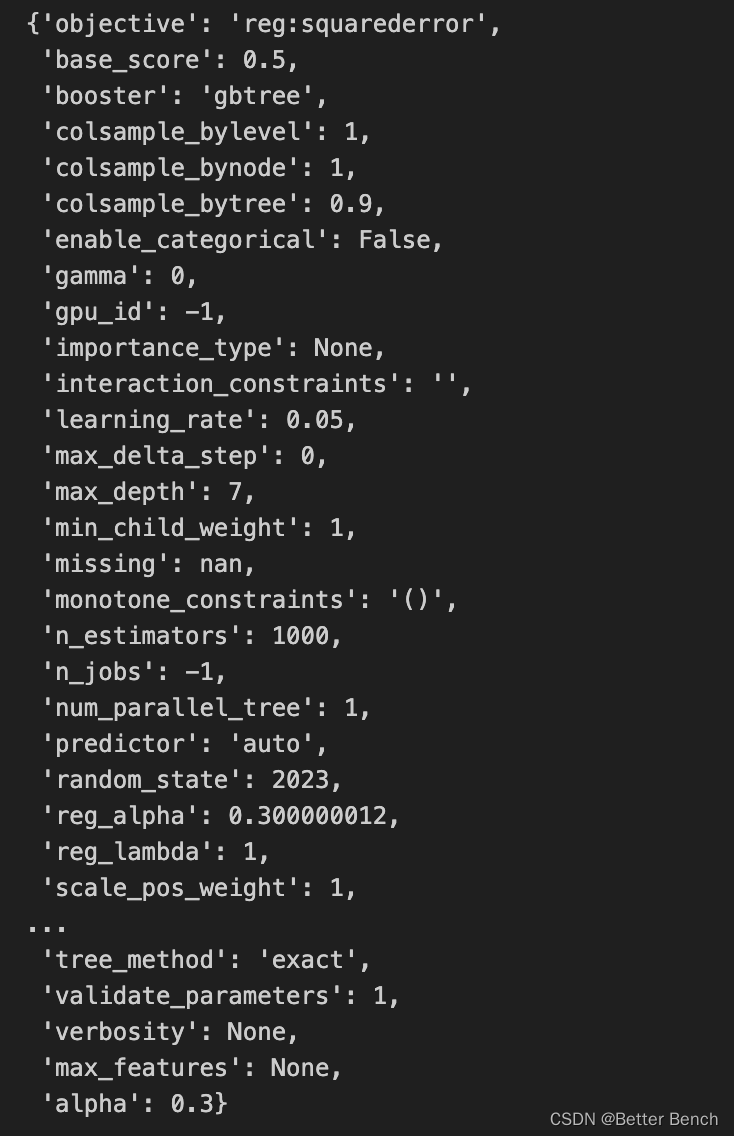
# 计算XGB模型的参数数量:
model.get_params()
完整代码
见知乎文章底部链接,下载包括所有问题的全部代码
zhuanlan.zhihu.com/p/643865954
相关文章:
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析
2023 年第二届钉钉杯大学生大数据挑战赛 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析 相关链接 【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析 【2023 年…...

redis-cluster 创建及监控
集群命令 cluster info:打印集群的信息。 cluster nodes:列出集群当前已知的所有节点(node)的相关信息。 cluster meet <ip> <port>:将ip和port所指定的节点添加到集群当中。 cluster addslots <slot…...

vue+ivew model框 select校验遇到的问题
iview model 点击关闭,校验没有通过也会关闭 解决办法: 第一步:自定义页脚内容 <div slot"footer"><Button type"primary" click"confirmCarryOver()">确认</Button><Button click&qu…...
mybatis_分页
目的: 减少数据处理量,提高效率 普通sql: 语法:select * from user limit startIndex,pageSize; SELECT * from user limit 3; #[0,n] mybatis_sql: 接口: //分页查询List<User> getUserByLimit(Map<…...

轻量级Firefox Send替代方案Gokapi
想不到一个域名的变动会影响这么大,访问量出现断崖式下跌。由此可见,平时的访问应该只是一些 RSS 的访问而已。 上面是 Pageviews,下面是 Uniques 今天略有回升 难怪那些大公司要花钱买域名了,不过老苏是个佛系的人,一…...

多次发请求优化为发一次请求
优化 getUserInfo 请求 要求 getUserInfo 是个通用接口,在各个模块里面都有可能使用 requestUserInfo 模拟的是请求服务端真正获取用户信息的方法 业务背景 在一个页面有 A, B, C 等多个功能模块,A, B, C 模块渲染执行顺序不可控每个模块都会调用 get…...

彻底搞懂CPU的特权等级
x86 处理器中,提供了4个特权级别:0,1,2,3。数字越小,特权级别越高! 一般来说,操作系统是的重要性、可靠性是最高的,需要运行在 0 特权级; 应用程序工作在最上层,来源广泛、可靠性最低,工作在 3 特权级别。 中间的1 和 2 两个特权级别,一般很少使用。 理论上来讲,…...

JVM对象在堆内存中是否如何分配?
1:指针碰撞:内存规整的情况下 2:空闲列表: 内存不规整的情况下 选择那种分配方式 是有 java堆是否规整而决定的。而java堆是否规整是否对应的垃圾回收器是否带有空间压缩整理的能力决定的。 因此当使用Serial,ParNew等带有压缩整理过程的收…...

【小白慎入】还在手动撸浏览器?教你一招分分钟自动化操作浏览器(Python进阶)
大家好啊,辣条哥又来猛货了! 小白慎入! 目录 环境安装1 测试样例2 基本配置2.0 基本参数2.1 设置窗口2.2 添加头部2.3 网页截图2.4 伪装浏览器 绕过检测2.5案例演示 触发JS2.6 boss直聘cookie反爬绕过实践2. 7滚动到页面底部 3 进阶使用4 数…...
组件的介绍及使用)
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用 1. 什么是TouchInputModule组件? TouchInputModule是Unity中的一个UGUI组件,用于处理触摸输入事件。它可以让你的游戏在移动设备上实现触摸操作,如点击、滑动、缩放等。 2. …...
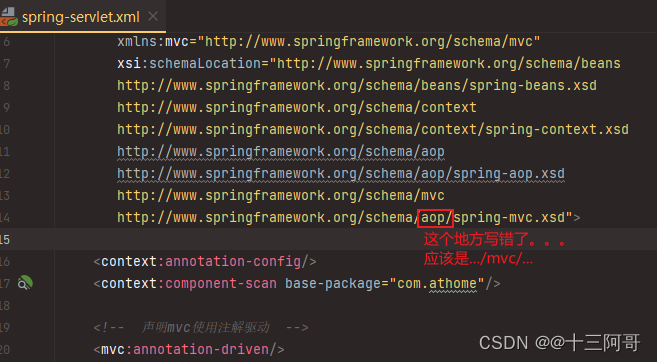
SpringMVC启动时非常缓慢,显示一直在部署中,网页也无法访问,,,Artifact is being deployed, please wait...
写了一个基本的SpringMVC程序进行测试,结果启动时一直显示在等待部署完毕,,, but这个地方一直显示转圈圈。。 后来通过url访问时网页一直转圈圈。。也就是等待响应。。 看了一会儿,也不知道哪儿错了,&…...

Docker 镜像操作
Docker镜像操作 我们已经介绍了容器操作,今天来了解下 Docker镜像 以及 镜像操作 。让我们一起开启镜像之旅吧。 Docker镜像 镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时、库…...

linux下有关mysql安装和登录的一些问题记录
1. 输入mysql -u root -p出现报错 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /var/run/mysqld/mysqld.sock (2) 前提:MySQL可执行文件位于/usr/local/mysql/bin目录中,如果MySQL安装路径不同,需要相应修改命令…...
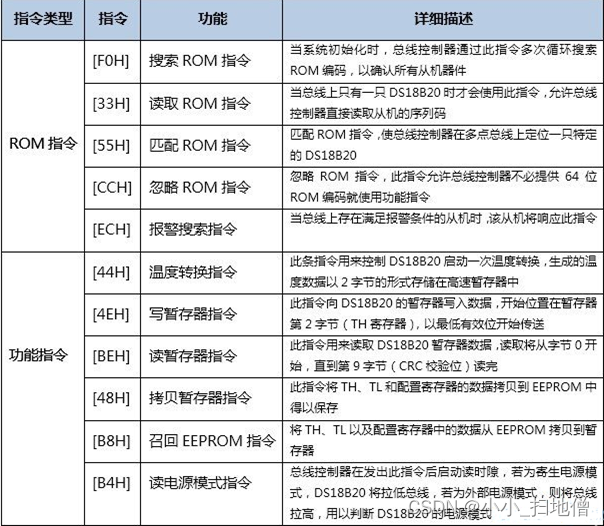
DS18B20的原理及实例代码(51单片机、STM32单片机)
一、DS18B20介绍 DS18B20数字温度传感器是DALLAS公司生产的单总线器件,用它来组成一个测温系统具有线路简单,体积小,在一根通信线上可以挂很多这样的数字温度传感器,十分方便。 温度传感器种类众多,应用在高精度、高可…...

两种单例模式
1.单例模式分为两种,饿汉模式和懒汉模式.以下是饿汉模式: public class SingleTonHungry {private static SingleTonHungry singleTonHungry new SingleTonHungry();private SingleTonHungry() {}public static SingleTonHungry getInstance() {return singleTonHungry;} }2.…...

List中交集的使用
前言 新增了一个需求,需要将所有药品和对应数量库存的药房查询出来,要求:‘所有药品该药房都要有,并且库存大于购药数量’; 这就得考虑一个问题,有的药房有该药品,有的药房没有该药品…...

TypeScript基础篇 - TS的函数
目录 构造函数表达 泛型和函数 泛型函数 Contextual Typing【上下文映射,上下文类型】 泛型约束 手动指定类型 泛型的使用规范 对比 可选参数 思考:onClick中e的设计 函数重载 修改办法 操作符重载 THIS void【空返回值】 思考为什么这样…...
Vue项目如何生成树形目录结构
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、有兴趣的可以关注一手。 前言 项目的目录结构清晰、可以帮助我们更快理顺项目的整体构成。在写文档之类的时候也比较方便。生成树形目录的方式有多种,我这里简单介绍其中一种较为简单的实现 过…...
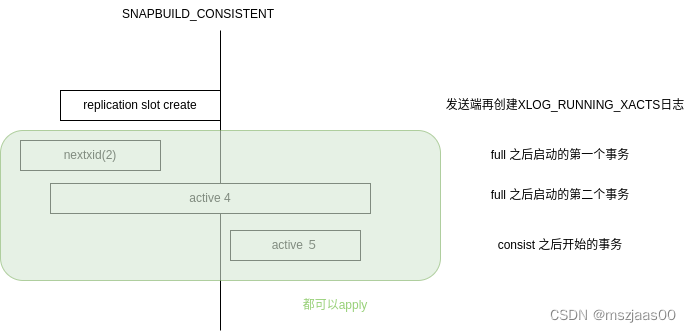
postgresql四种逻辑复制的状态
准备 CreateCheckpoint,或者bgwriter启动时,或者创建logicalreplicationslot时都会调用LogStandbySnapshot 记录一个XLOG_RUNNING_XACTS类型的日志。日志中记录了所有提交的事务的xid(HistoricSnapshot) 启动(SNAPBUILD_BUILDING_SNAPSHOT&…...
梯度下降法和牛顿法
梯度下降法和牛顿法都是优化方法。 梯度下降法 梯度下降法和相关知识可以参考导数、偏导数、梯度、方向导数、梯度下降、二阶导数、二阶方向导数一文。梯度下降法是一种迭代地每次沿着与梯度相反方向前进的不断降低损失函数的优化方法。梯度下降只用到一阶导数的信息…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户告别封号与Token焦虑,无缝切换至Taotoken平台 对于依赖Claude Code进行编程辅助的开发者而言ÿ…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...