使用langchain与你自己的数据对话(三):检索(Retrieval)

之前我已经完成了使用langchain与你自己的数据对话的前两篇博客,还没有阅读这两篇博客的朋友可以先阅读一下:
- 使用langchain与你自己的数据对话(一):文档加载与切割
- 使用langchain与你自己的数据对话(二):向量存储与嵌入
今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第四门课:检索(Retrieval)。
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
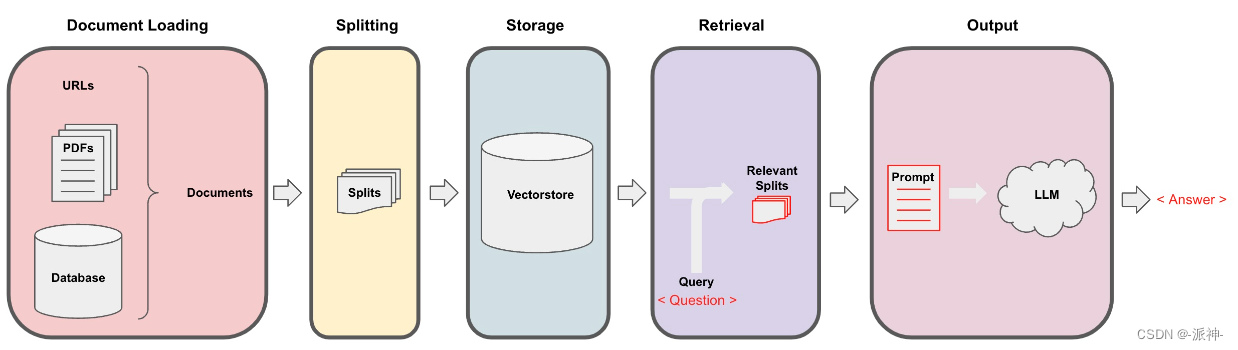
在上一篇博客:向量存储与嵌入中我们介绍了嵌入(Embeddings)和开源向量数据库Chroma的基本原理,当文档经过切割(splitting),嵌入(embedding)后存入向量数据库以后,接下来就来到了检索(retrieval)环节:
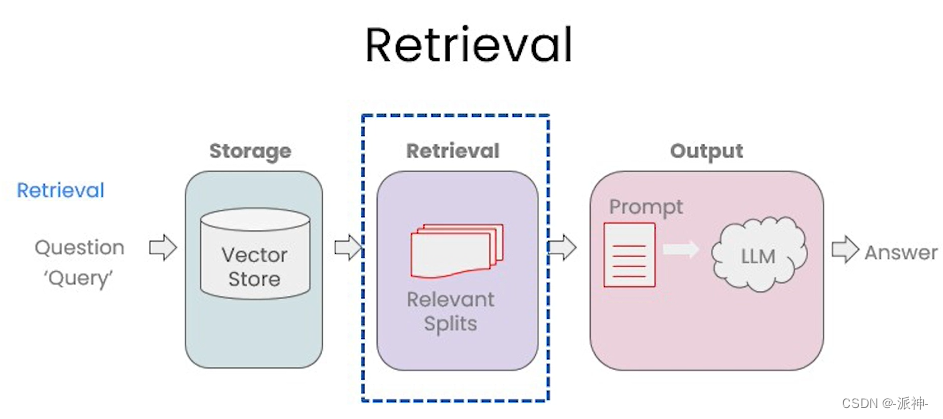
检索是指根据用户的问题去向量数据库中搜索与问题相关的文档内容,当我们访问和查询向量数据库时可能会运用到如下几种技术:
- 基本语义相似度(Basic semantic similarity)
- 最大边际相关性(Maximum marginal relevance,MMR)
- 过滤元数据
- LLM辅助检索
在讨论这些新技术之前,想让我们完成一些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']基本语义相似度(Basic semantic similarity)
下面我们来实现一下语义的相似度搜索,我们把三句英语的句子存入向量数据库Chroma中,然后我们提出问题让向量数据库根据问题来搜索相关答案:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings#创建open ai的embedding对象
embedding = OpenAIEmbeddings()#需要存入数据库的文本
texts = ["""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""","""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""","""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""",
]#创建向量数据库
smalldb = Chroma.from_texts(texts, embedding=embedding)
下面我们把代码中的三句英语的文本翻译为中文,这样便于大家更好的理解其含义:
- 1.“鹅膏菌具有巨大而雄伟的地上(地上)子实体(担子果)。”
- 2.“具有较大子实体的蘑菇是鹅膏菌。有些品种是全白色的。”
- 3.“鬼笔甲,又名死亡帽,是所有已知蘑菇中毒性最强的一种。”
我们可以看到前两句都是描述的是一种叫“鹅膏菌”的菌类,包括它们的特征:有较大的子实体,第三句描述的是“鬼笔甲”,一种已知的最毒的蘑菇,它的特征就是:含有剧毒。下面我们提出一个问题:“告诉我有关子实体大的全白蘑菇的信息”,然后让向量数据库用相似度(similarity)方法去搜索2个和问题最相关的答案:
#问题:告诉我有关子实体大的全白蘑菇的信息
question = "Tell me about all-white mushrooms with large fruiting bodies"smalldb.similarity_search(question, k=2)
我们看到向量数据库返回了2个文档,就是我们存入向量数据库中的第一句和第二句。这里我们很明显的就可以看到chroma的similarity_search方法可以根据问题的语义去数据库中搜索与之相关性最高的文档也就是搜索到了第一句和第二句的文本,但这似乎有存在一些问题,因为第一句和第二句的含义非常接近,他们都是描述“鹅膏菌”及其“子实体”的,所以假如只返回其中的一句就足以满足要求了,如果返回两句含义非常接近的文本感觉是一种资源的浪费,下面我们来看一下max_marginal_relevance_search的搜索结果:
smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)
这里我们看到 max_marginal_relevance_search返回了第二和第三句的文本,尽管第三句与我们的问题的相关性不太高,但是这样的结果其实应该是更加的合理,因为第一句和第二句文本本来就有着相似的含义,所以只需要返回其中的一句就可以了,另外再返回一个与问题相关性弱一点的答案(第三句文本),这样似乎增强了答案的多样性,相信用户也会更加偏爱max_marginal_relevance_search 的结果,因为它兼顾了答案的相关性和多样性,下面我们就来讨论“最大边际相关性(Maximum marginal relevance ,MMR)”的问题。
最大边际相关性(Maximum marginal relevance ,MMR)
最大边际相关性(Maximum marginal relevance ,MMR)在论文:《The Use of MMR, Diversity-Based Reranking for Reordering Documents and Production Summaries》中有详细的介绍,MMR 尝试减少结果的冗余,同时保持结果与查询条件相关性和多样性的平衡(。作者在论文中提出了如下的公式:
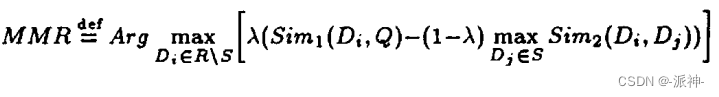
其中:
- Q: 查询条件
- R: 与查询Q相关的所有文档集
- D: 与查询条件相关的文档集
- S: R中已选择的文档子集
- R\S: R中未选择的文档子集
- λ:[0–1] 范围内的常数,用于结果的多样化
- Sim1,Sim2: 用来度量查询Q与文档相似度的指标,如余弦相似度等。

有兴趣的读者可以仔细研读该篇论文,幸运的是我们不需要手动去实现MMR算法,Langchain的内置方法max_marginal_relevance_search已经帮我们首先了该算法,在执行max_marginal_relevance_search方法时,我们需要设置fetch_k参数,用来告诉向量数据库我们最终需要k个结果,向量数据库在搜索时会获取一个和问题相关的文档集,该文档集中的文档数量大于k,然后从中过滤出k个具有相关性同时兼顾多样性的文档。

下面我们来测试一下max_marginal_relevance_search方法,还记得在上一篇博客(向量存储与嵌入)中我们介绍了两种向量数据在查询时的失败场景吗?当向量数据库中存在相同的文档时,而当用户的问题又与这些重复的文档高度相关时,向量数据库会出现返回重复的文档情况,现在我们就可以运用Langchain的max_marginal_relevance_search来解决这个问题,不过首先我们需要先加载一下上一篇博客中保存在本地的关于吴恩达老师的机器学习课程cs229课程讲义的向量数据库:
#向量数据库地址
persist_directory = 'docs/chroma/'embedding = OpenAIEmbeddings()vectordb = Chroma(persist_directory=persist_directory,embedding_function=embedding
)#打印向量数据库中的文档数量
print(vectordb._collection.count())
![]()
这里我们加载了之前保存在本地的向量数据库,并查询了数据库中的文档数量为209,这与我们之前创建该数据库时候的文档数量是一致的,接下来我们提出了和上篇博客中相同的问题,然后先用similarity_search方法来查询一下,它应该会返回两篇相同的文档:
question = "what did they say about matlab?"
docs_ss = vectordb.similarity_search(question,k=3)docs_ss 
这里我们看到向量数据库返回了两篇相同的文档,这是因为在上一篇博客中我们在创建向量数据库时加载了两篇相同的文档(Lecture01.pdf),所以这回通过similarity_search方法搜索相似文档时它们被同时搜索到并返回给了用户。下面我们使用max_marginal_relevance_search方法来搜索:
docs_mmr = vectordb.max_marginal_relevance_search(question,k=3)docs_mmr 这里我们看到向量数据库返回了3篇完全不同的文档,这是因为我们使用的是MMR搜索,它把搜索结果中相似度很高的文档做了过滤,所以它保留了结果的相关性又同时兼顾了结果的多样性。
这里我们看到向量数据库返回了3篇完全不同的文档,这是因为我们使用的是MMR搜索,它把搜索结果中相似度很高的文档做了过滤,所以它保留了结果的相关性又同时兼顾了结果的多样性。
过滤元数据
在上一篇博客中的“失败的应用场景”的章节中我们还提出了一个问题:我们要求向量数据库在第三篇原始文档(Lecture03.pdf)中搜索相关答案,结果向量数据库的返回结果中除了第三篇文档的结果以外还包含了第一篇(Lecture01.pdf)和第二篇文档(Lecture02.pdf)的内容,这是我们所不希望看到的结果,之所以产生这样的结果是因为当我们向向量数据库提出问题时,数据库并没有很好的理解问题的语义,所以返回的结果不如预期,要解决这个问题,我们可以通过过滤元数据的方式来实现精准搜索,当前很多向量数据库都支持对元数据的操作:
question = "what did they say about regression in the third lecture?"docs = vectordb.similarity_search(question,k=3,filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)for d in docs:print(d.metadata)
这里我们可以看到通过我们在代码中设置了filter过滤条件后,向量数据库返回的3个答案呢都是基于第三篇文档的(Lecture03.pdf),这就符合我们的要求了,通过在similarity_search方法中加入filter参数,就可以指定需要搜索的原始文档,因为所有原始文档的文件名信息都保存在切割后文档的元数据信息中,通过过滤元数据信息就可以使向量数据库在指定的文档中搜索和问题相关的答案了。
LLM辅助检索
上面我们使用的是手动设置元数据的过滤参数filter来实现过滤指定文档的功能,其实这也不是很方便,因为我们每次都需要手动去设置过滤条件,这会非常的麻烦。有没有方法可以准确识别问题中的语义(因为在用户的问题中已经指出了需要过滤的文档)从而自动实现元数据过滤呢?也就是说是否有一种方法可以从用户问题的语义中自动推断出需要过滤的元数据信息呢?Langchain为我们提供了这样的方法,我们可以使用 SelfQueryRetriever,它使用 LLM 从用户原始问题中抽取取:
- 用于向量搜索的查询字符串(search term)
- 用于过滤元数据的信息(Filter)
其原理如下图所示:

下面我们就来实现一下LLM辅助检索:
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo#定义元数据的过滤条件
metadata_field_info = [AttributeInfo(name="source",description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",type="string",),AttributeInfo(name="page",description="The page from the lecture",type="integer",),
]#创建SelfQueryRetriever
document_content_description = "Lecture notes"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm,vectordb,document_content_description,metadata_field_info,verbose=True
)这里我们首先定义了metadata_field_info ,它包含了元数据的过滤条件source和page, 其中source的作用是告诉LLM我们想要的数据来自于哪里,page告诉LLM我们还需要提取相关的内容在原始文档的第几页。有了metadata_field_info信息后,LLM会自动从用户的问题中提取出上图中的Filter和Search term两项,然后向量数据库基于这两项去搜索相关的内容。下面我们看一下查询结果:
#问题
question = "what did they say about regression in the third lecture?"#搜索相关文档
docs = retriever.get_relevant_documents(question)#打印结果中的元数据信息
for d in docs:print(d.metadata)
由于我们在定义SelfQueryRetriever时设置了verbose=True,所以我们可以看到一些SelfQueryRetriever执行的中间结果,从上面的返回结果中我们看到query和filter这两项,其中query=‘regression’就是从用户问题中提取出来的搜索项,搜索内容为“regression”, 而filter项是LLM根据metadata_field_info中定义的信息对向量数据库中的文档块的元数据进行过滤的条件。最后我们看到返回结果均来自于第三个文档(Lecture03.pdf),完全符合我们的要求。
附加技巧:压缩(compression)
所谓压缩是指提高文档检索质量的一种方法,当我们根据用户的问题使用检索器(Retriever)去检索向量数据库时,向量数据库一般会返回与问题相关文档块(chunks)中的所有内容,即把整个文档块的内容全部输出,这就可能会产生一些资源浪费的情况,因为和问题相关的文档内容可能只占该文档块的一小部分,可我们却输出了整个文档块的全部内容,这样会增加token成本,因为我们使用的openai的LLM不是免费的,它是根据token数量来收费的,因此输出整个文档块的内容其实是一种资源的浪费,幸运的是Langchain为我们提供给了ContextualCompressionRetriever,其原理如下图所示:
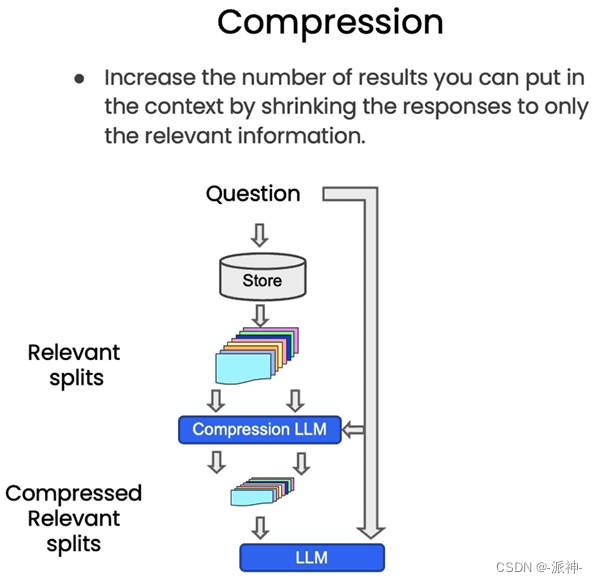
从上图中我们看到,当向量数据库返回了所有与问题相关的所有文档块的全部内容后,会有一个Compression LLM来负责对这些返回的文档块的内容进行压缩,所谓压缩是指仅从文档块中提取出和用户问题相关的内容,并舍弃掉那些不相关的内容。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractordef pretty_print_docs(docs):print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))# Wrap our vectorstore
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectordb.as_retriever()
)在上面的代码中我们定义了一个LLMChainExtractor,它是一个压缩器,它负责从向量数据库返回的文档块中提取相关信息,然后我们还定义了ContextualCompressionRetriever,它有两个参数:base_compressor和base_retriever,其中base_compressor为我们前面定义的LLMChainExtractor的实例,base_retriever为早前定义的vectordb产生的检索器。下面我们来看一下执行结果:
question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
从上面的返回结果中我们看到,返回结果并不是整个文档块的内容,而只是文档块中的部分内容,这些内容与用户的问题是直接相关的,文档块中与问题不相关的内容都已经被舍弃了,这样就大大节省了使用LLM的成本。
其他类型的检索
值得注意的是,vectordb 并不是Langchain中唯一的一种检索器 。LangChain还提供了其他检索文档的方式,例如TF-IDF或SVM。
from langchain.retrievers import SVMRetriever
from langchain.retrievers import TFIDFRetriever
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# Load PDF
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
all_page_text=[p.page_content for p in pages]
joined_page_text=" ".join(all_page_text)# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150)
splits = text_splitter.split_text(joined_page_text)# Retrieve
svm_retriever = SVMRetriever.from_texts(splits,embedding)
tfidf_retriever = TFIDFRetriever.from_texts(splits)这里我们定义了SVMRetriever,和TFIDFRetriever两个检索器,下面我们使用这两个检索器来检索向量数据库:
question = "What are major topics for this class?"
docs_svm=svm_retriever.get_relevant_documents(question)
docs_svm[0]
question = "what did they say about matlab?"
docs_tfidf=tfidf_retriever.get_relevant_documents(question)
docs_tfidf[0]
关于SVM和TF-IDF的相关技术不会在本文中讨论,读者可以执行查阅相关技术资料。
总结
今天我们学习了很多有用的新技术比如最大边际相关性(MMR),MMR可以让搜索结果保持相关性和多样性,这样可以避免出现冗余的搜索结果,除此之外我们可以定义元数据的过滤条件,这样向量数据库可以更加精准的搜索和问题相关的答案。另外我们还学习了LLM辅助检索,通过定义元数据字段信息metadata_field_info ,我们可以使用SelfQueryRetriever自动推断出用户问题中的搜索项和过滤项,这样可以避免手动设置元数据过滤条件带来的麻烦,后面我们还介绍了内容压缩检索器ContextualCompressionRetriever,通过ContextualCompressionRetriever我们可以从返回的整个文档块抽取和用户问题相关的内容,抛弃掉和问题无关的内容,这样可以大大节省LLM的使用成本。最后我们还简单介绍了SVM和TF-IDF检索器的使用方法,希望今天的内容对大家有所帮助!
参考资料
《The Use of MMR, Diversity-Based Reranking for Reordering Documents and Production Summaries》
Vector stores | 🦜️🔗 Langchain
Self-querying | 🦜️🔗 Langchain
Contextual compression | 🦜️🔗 Langchain
相关文章:
使用langchain与你自己的数据对话(三):检索(Retrieval)
之前我已经完成了使用langchain与你自己的数据对话的前两篇博客,还没有阅读这两篇博客的朋友可以先阅读一下: 使用langchain与你自己的数据对话(一):文档加载与切割使用langchain与你自己的数据对话(二):向量存储与嵌入 今天我们…...
DEVICENET转ETHERNET/IP网关devicenet协议
捷米JM-EIP-DNT,你听说过吗?这是一款自主研发的ETHERNET/IP从站功能的通讯网关,它能够连接DEVICENET总线和ETHERNET/IP网络,从而解决生产管理系统中协议不同造成的数据交换互通问题。 这款产品在工业自动化领域可谓是一大利器&…...
GPT一键化身「AI助理」——自定义指令功能
最近GPT又更新了一个超实用的功能——自定义指令,启用后,你可以给GPT设置一些固定指令,让它记住或扮演某个角色,比如客服、律师、投资管理师、老师、营养师...... 这样,我们就不再需要每次都要打开新的聊天,…...

深入理解Promise
原文合集地址如下,有需要的朋友可以关注 本文地址 合集地址 什么是Promise 当谈论 Promise 时,可以将其比喻为一种承诺或契约,用于处理异步操作的结果。异步操作是指那些不会立即完成的操作,比如从服务器获取数据、读取文件、发送网络请求等等。通常情况下,这些操作需…...
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析
2023 年第二届钉钉杯大学生大数据挑战赛 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析 相关链接 【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析 【2023 年…...

redis-cluster 创建及监控
集群命令 cluster info:打印集群的信息。 cluster nodes:列出集群当前已知的所有节点(node)的相关信息。 cluster meet <ip> <port>:将ip和port所指定的节点添加到集群当中。 cluster addslots <slot…...

vue+ivew model框 select校验遇到的问题
iview model 点击关闭,校验没有通过也会关闭 解决办法: 第一步:自定义页脚内容 <div slot"footer"><Button type"primary" click"confirmCarryOver()">确认</Button><Button click&qu…...
mybatis_分页
目的: 减少数据处理量,提高效率 普通sql: 语法:select * from user limit startIndex,pageSize; SELECT * from user limit 3; #[0,n] mybatis_sql: 接口: //分页查询List<User> getUserByLimit(Map<…...

轻量级Firefox Send替代方案Gokapi
想不到一个域名的变动会影响这么大,访问量出现断崖式下跌。由此可见,平时的访问应该只是一些 RSS 的访问而已。 上面是 Pageviews,下面是 Uniques 今天略有回升 难怪那些大公司要花钱买域名了,不过老苏是个佛系的人,一…...

多次发请求优化为发一次请求
优化 getUserInfo 请求 要求 getUserInfo 是个通用接口,在各个模块里面都有可能使用 requestUserInfo 模拟的是请求服务端真正获取用户信息的方法 业务背景 在一个页面有 A, B, C 等多个功能模块,A, B, C 模块渲染执行顺序不可控每个模块都会调用 get…...

彻底搞懂CPU的特权等级
x86 处理器中,提供了4个特权级别:0,1,2,3。数字越小,特权级别越高! 一般来说,操作系统是的重要性、可靠性是最高的,需要运行在 0 特权级; 应用程序工作在最上层,来源广泛、可靠性最低,工作在 3 特权级别。 中间的1 和 2 两个特权级别,一般很少使用。 理论上来讲,…...

JVM对象在堆内存中是否如何分配?
1:指针碰撞:内存规整的情况下 2:空闲列表: 内存不规整的情况下 选择那种分配方式 是有 java堆是否规整而决定的。而java堆是否规整是否对应的垃圾回收器是否带有空间压缩整理的能力决定的。 因此当使用Serial,ParNew等带有压缩整理过程的收…...

【小白慎入】还在手动撸浏览器?教你一招分分钟自动化操作浏览器(Python进阶)
大家好啊,辣条哥又来猛货了! 小白慎入! 目录 环境安装1 测试样例2 基本配置2.0 基本参数2.1 设置窗口2.2 添加头部2.3 网页截图2.4 伪装浏览器 绕过检测2.5案例演示 触发JS2.6 boss直聘cookie反爬绕过实践2. 7滚动到页面底部 3 进阶使用4 数…...
组件的介绍及使用)
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用
Unity UGUI的TouchInputModule (触摸输入模块)组件的介绍及使用 1. 什么是TouchInputModule组件? TouchInputModule是Unity中的一个UGUI组件,用于处理触摸输入事件。它可以让你的游戏在移动设备上实现触摸操作,如点击、滑动、缩放等。 2. …...
SpringMVC启动时非常缓慢,显示一直在部署中,网页也无法访问,,,Artifact is being deployed, please wait...
写了一个基本的SpringMVC程序进行测试,结果启动时一直显示在等待部署完毕,,, but这个地方一直显示转圈圈。。 后来通过url访问时网页一直转圈圈。。也就是等待响应。。 看了一会儿,也不知道哪儿错了,&…...

Docker 镜像操作
Docker镜像操作 我们已经介绍了容器操作,今天来了解下 Docker镜像 以及 镜像操作 。让我们一起开启镜像之旅吧。 Docker镜像 镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时、库…...

linux下有关mysql安装和登录的一些问题记录
1. 输入mysql -u root -p出现报错 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /var/run/mysqld/mysqld.sock (2) 前提:MySQL可执行文件位于/usr/local/mysql/bin目录中,如果MySQL安装路径不同,需要相应修改命令…...
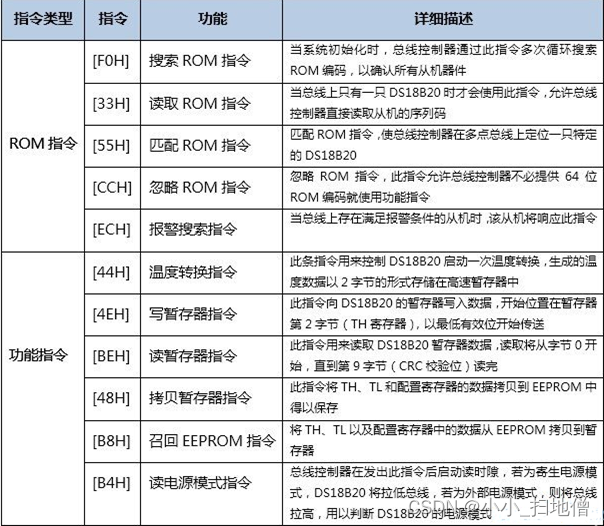
DS18B20的原理及实例代码(51单片机、STM32单片机)
一、DS18B20介绍 DS18B20数字温度传感器是DALLAS公司生产的单总线器件,用它来组成一个测温系统具有线路简单,体积小,在一根通信线上可以挂很多这样的数字温度传感器,十分方便。 温度传感器种类众多,应用在高精度、高可…...

两种单例模式
1.单例模式分为两种,饿汉模式和懒汉模式.以下是饿汉模式: public class SingleTonHungry {private static SingleTonHungry singleTonHungry new SingleTonHungry();private SingleTonHungry() {}public static SingleTonHungry getInstance() {return singleTonHungry;} }2.…...

List中交集的使用
前言 新增了一个需求,需要将所有药品和对应数量库存的药房查询出来,要求:‘所有药品该药房都要有,并且库存大于购药数量’; 这就得考虑一个问题,有的药房有该药品,有的药房没有该药品…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...