SQL基础语法 | 增删改查、分组、排序、limit
Shell命令框和Navicat联合使用
一、数据库层面
-
创建数据库
postgres=# CREATE DATABASE runoobdb; -
查看数据库
postgres=# \l -
选择数据库
postgres=# \c runoobdb -
删除数据库
postgres=# DROP DATABASE runoobdb;
二、表格层面
-
创建表格
CREATE TABLE table_name(字段名称 字段数据类型,column2 datatype,column3 datatype,.....columnN datatype,PRIMARY KEY( 一个或多个列 ) ); -
删除表格
DROP TABLE table_name; -
创建schema模式
CREATE SCHEMA myschema.表名(ID INT NOT NULL,NAME VARCHAR (20) NOT NULL,AGE INT NOT NULL,ADDRESS CHAR (25),SALARY DECIMAL (18, 2),PRIMARY KEY (ID) ); -
删除schema模式
-
删除一个空模式
DROP SCHEMA myschema; -
删除一个模式及包含的所有对象
DROP SCHEMA myschema CASCADE;
-
三、增删改查
-
增insert into
❤
INSERT INTO TABLE_NAME (字段名1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN)INSERT INTO TABLE_NAME (字段名1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN); // 举例 INSERT INTO book(id,name,age)VALUES(1,'张一山',24); INSERT INTO book values (2,'王祖蓝',23); INSERT INTO book values (3,'李晓非'); INSERT INTO book values (4,'吴晓非'); INSERT INTO book values (5); INSERT INTO book values (6,24); // 遵循顺序对应 // 下面是结果 1 张一山 24 2 王祖蓝 23 3 李晓非 null 4 吴晓非 null 5 null null 6 24 -
查询select
SELECT column1, column2,...columnN FROM table_name; // 查询所有字段使用*; SELECT * FROM book // 查询系统当前时间 SELECT CURRENT_TIMESTAMP; -
聚合函数
- avg() : 返回一个表达式的平均值
- sum() : 返回指定字段的总和
- count() : 返回查询的记录总数
-
where子句
我们可以在 WHERE 子句中使用比较运算符或逻辑运算符,
例如 >, <, =, LIKE, NOT,AND,BETWEEN, 等等。
-
UPDATE 改
❤
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];// 修改name=lcy字段的年龄age为16
UPDATE company SET age=16 WHERE name='lcy';// 若不加where条件则 修改某个字段下的所有内容
UPDATE company set salary=13000, age=181 paul 18 加拿大 13000.00 2023-07-05
2 allen 18 纽约 13000.00 2023-07-20
3 teddy 18 加利福尼亚 13000.00 2023-07-06
4 mark 18 旧金山 13000.00 2023-07-07
5 ming 18 曼彻斯特 13000.00 2023-07-08
8 zy 18 北京 13000.00 2023-07-15
7 lcy 18 陕西 13000.00 2023-07-10
6 james 18 曼哈顿 13000.00 2023-07-09// 和IN连用
UPDATE company set salary=19000,age=19 WHERE id IN(1,2,3)// 和like连用
UPDATE company set salary=700,age=19 WHERE name like '%y'5 ming 18 曼彻斯特 13000.00 2023-07-08
6 james 18 曼哈顿 13000.00 2023-07-09
1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06 -
DELETE 删除
delete删除表的内容,drop删除表的结构DROP TABLE 表名
语法:
DELETE FROM table_name WHERE [condition];// 条件删除
DELETE FROM company WHERE name='james'// 删除表里所有内容
DELETE FROM company- 使用
TRUNCATE TABLE 表名=DELETE FROM company但是前者不会产生日志
- 使用
-
关键字
-
AND 表示多个条件必须同时成立
找出 AGE(年龄) 字段大于等于 25,并且 SALARY(薪资) 字段大于等于 16000 的数据:
SELECT * FROM company WHERE age>=25 AND salary >= 16000 -
OR 表示示多个条件中只需满足其中任意一个即可
找出 AGE(年龄) 字段大于等于 25,或者 SALARY(薪资) 字段大于等于 26000 的数据:
SELECT * FROM company WHERE age>=25 OR salary >= 26000 -
NOT NULL 和 NULL
在公司表中找出 AGE(年龄) 字段不为空的记录:
SELECT * FROM company WHERE age IS NOT NULL;SELECT * FROM company WHERE age IS NULL; -
LIKE 模糊查询
-
模糊查询就需要用到like操作符。另外还有两个通配符。
①%通配符。%表示出现任意字符,出现的字符数可以是0,1,无数。
②_ 通配符。_ 表示出现有且仅有一次字符。
-
如果没有使用以上两种通配符,LIKE 子句和等号 = 得到的结果是一样的。
-
在 PostgreSQL 中,LIKE 子句是只能用于对字符进行比较,因此在下面例子中,我们要将整型数据类型转化为字符串数据类型。
实例 描述 WHERE SALARY::text LIKE ‘200%’ 找出 SALARY 字段中以 200 开头的数据。 WHERE SALARY::text LIKE ‘%200%’ 找出 SALARY 字段中含有 200 字符的数据。 WHERE SALARY::text LIKE ‘_00%’ 找出 SALARY 字段中在第二和第三个位置上有 00 的数据。 WHERE SALARY::text LIKE ‘2_%_%’ 找出 SALARY 字段中以 2 开头的字符长度大于 3 的数据。 WHERE SALARY::text LIKE ‘%2’ 找出 SALARY 字段中以 2 结尾的数据 WHERE SALARY::text LIKE ‘_2%3’ 找出 SALARY 字段中 2 在第二个位置上并且以 3 结尾的数据 WHERE SALARY::text LIKE ‘2___3’ 找出 SALARY 字段中以 2 开头,3 结尾并且是 5 位数的数据 - 如:在 COMPANY 表中找出 NAME(名字) 字段中以 Pa 开头的的数据:
SELECT * FROM company WHERE name like 'pa%';//以pa开头的SELECT * FROM company WHERE name like '%l%';// name中含有字母l的SELECT * FROM company WHERE name like '%l';//以字母l结尾的当我们大概知道name后面有一个字符,前面有一个字符的时候,我们就可使用_
SELECT * FROM company WHERE name like '_z_';like查找非字符类型
// 查询年龄=19的
SELECT * FROM company WHERE age::TEXT like '19'1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06// 查询年龄以2开头的
SELECT * FROM company WHERE age::TEXT like '2_'// 查询工资以19开头的
SELECT * FROM company WHERE salary::TEXT like '19%' -
-
IN 包含
比如使用or时:薪水在where salary = 10000 or 20000时,就可以使用in子句
SELECT * FROM company WHERE salary=17000 OR salary=19000;现在我们可以直接使用IN子句:可以是1个或多个
SELECT * FROM company WHERE salary in(17000,19000,12000);SELECT * FROM company WHERE salary in(28000); -
NOT IN
刚好和IN相反
-
BETWEEN 和 AND 的联合使用 包含两个端点值
// 找出工资在4500到9000之间的
SELECT * FROM "company" WHERE salary BETWEEN 4500 AND 9000; -
LIMIT 主要用于分页查询 一般分页关键字放在最后的
-
limit 子句用于限制 SELECT 语句中查询的数据的数量。
-
基本语法:
SELECT column1, column2 FROM table_name LIMIT [no of rows]
// 返回四个数据并按照id排序
SELECT * FROM company ORDER BY id LIMIT 4// 返回四个数据
SELECT * FROM company LIMIT 4 -
-
OFFSET 偏移量(初始偏移量为0)offset 1 :意思就是从第2行开始
❤注:LIMIT x OFFSET y 是为了与PostgreSQL兼容, 查询出的数据结果集为 [y+1,x+y]。
-
offset使用:offset x
// 从x+1行开始 取数据
SELECT * FROM "company" OFFSET 1从第二行开始取数据 含x+1行的数据1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06
6 ljj 28 shanxi 900.00 2023-07-19 -
配合limit使用
// 全部数据
5 ming 18 曼彻斯特 13000.00 2023-07-08
1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06
6 ljj 28 shanxi 900.00 2023-07-19// 从第2行开始,取4行数据
SELECT * FROM "company" LIMIT 4 OFFSET 11 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
-
-
ORDER BY :排序, 一般配合where子句一起使用
-
基础语法
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC]; -
默认是升序排序 即
order by column asc,若想改成降序则使用desc// 按照id降序排序
SELECT * FROM company ORDER BY id desc
-
-
GROUP BY :分组,配合select使用 和聚合函数使用
GROUP BY子句通常与聚合函数一起用于统计数据。
GROUP BY子句将行排列成组,聚合函数返回每个组的统计量。
-
概念:
目的: GROUP BY 语句和 SELECT 语句一起使用,用来对相同的数据进行分组。
位置:GROUP BY 在一个 SELECT 语句中,放在 WHRER 子句的后面,ORDER BY 子句的前面。
SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME; -
语法:
SELECT column-list FROM table_name WHERE [ conditions ] GROUP BY column1, column2....columnN -
使用 group by 时 只能select 出
分组字段和聚合函数 -
举例
// 全部
5 ming 18 曼彻斯特 13000.00 2023-07-08
1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06
6 ljj 28 shanxi 900.00 2023-07-19// 根据name进行分组,并且找出每个人的工资总额
SELECT name,SUM(salary) FROM company GROUP BY nameteddy 700.00
allen 19000.00
ljj 900.00
lcy 700.00
paul 19000.00
ming 13000.00
mark 11000.00
zy 700.00何为分组:目前我们表中的数据人名都是一个,我们现在往表中加入几条数据
1 paul 19 加拿大 19000.00 2023-07-05
2 allen 19 纽约 19000.00 2023-07-20
4 mark 21 旧金山 11000.00 2023-07-07
7 lcy 19 陕西 700.00 2023-07-10
8 zy 19 北京 700.00 2023-07-15
3 teddy 19 加利福尼亚 700.00 2023-07-06
6 ljj 28 shanxi 900.00 2023-07-19
9 paul 24 Houston 20000.00 2023-07-11
10 James 44 Norway 5000.00 2023-07-19
11 James 45 Texas 5000.00 2023-07-20再次进行一次分组看
SELECT name,SUM(salary) FROM company GROUP BY nameteddy 700.00
allen 19000.00
James 10000.00
ljj 900.00
lcy 700.00
paul 39000.00
ming 13000.00
mark 11000.00
zy 700.00发现james和paul已经进行了合并相加
// 根据name进行分组,并且找出每个人的工资总额,根据工资总额进行排序
SELECT name,SUM(salary) FROM company GROUP BY name ORDER BY SUM(salary)teddy 700.00
lcy 700.00
zy 700.00
ljj 900.00
mark 11000.00
ming 13000.00
paul 19000.00
allen 19000.00// 根据name进行分组,并且找出每个人的工资总额,且筛选出年龄大于20的数据,最后根据工资总额进行排序
SELECT name,SUM(salary) FROM company WHERE age>20 GROUP BY name ORDER BY SUM(salary)ljj 900.00
mark 11000.00
-
-
HAVING 用来筛选分组后的各项数据
-
基础语法:HAVING 是在由 GROUP BY 子句创建的分组基础上设置条件,所以要放在group by后面
SELECT column1, column2 FROM table1 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2 -
位置:
AVING 子句必须放置于 GROUP BY 子句后面,ORDER BY 子句前面
-
举例
// 找出根据 NAME 字段值进行分组,并且 name(名称) 字段的计数少于 2 数据
select name from company group by name having count(name) < 2teddy
allen
ljj
lcy
ming
mark
zy// 找出根据 NAME 字段值进行分组,并且 name(名称) 字段的计数大于 1 数据
select name from company group by name having count(name) > 1James
paul//
SELECT id,salary FROM company GROUP BY salary,id HAVING MAx(age)>23 ORDER BY id
-
-
DISTINCT 去重复 与select连用
-
概念:
DISTINCT 关键字与 SELECT 语句一起使用,用于去除重复记录,只获取唯一的记录
-
基础语法
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition] -
举例
// 剔除company中重复的name 我们可以在结果中看到去掉了重复的james和paul
SELECT DISTINCT name FROM companyteddy
allen
James
ljj
lcy
paul
ming
mark
zy
-
-
相关文章:

SQL基础语法 | 增删改查、分组、排序、limit
Shell命令框和Navicat联合使用 一、数据库层面 创建数据库 postgres# CREATE DATABASE runoobdb;查看数据库 postgres# \l选择数据库 postgres# \c runoobdb删除数据库 postgres# DROP DATABASE runoobdb;二、表格层面 创建表格 CREATE TABLE table_name(字段名称 字段数据类型…...
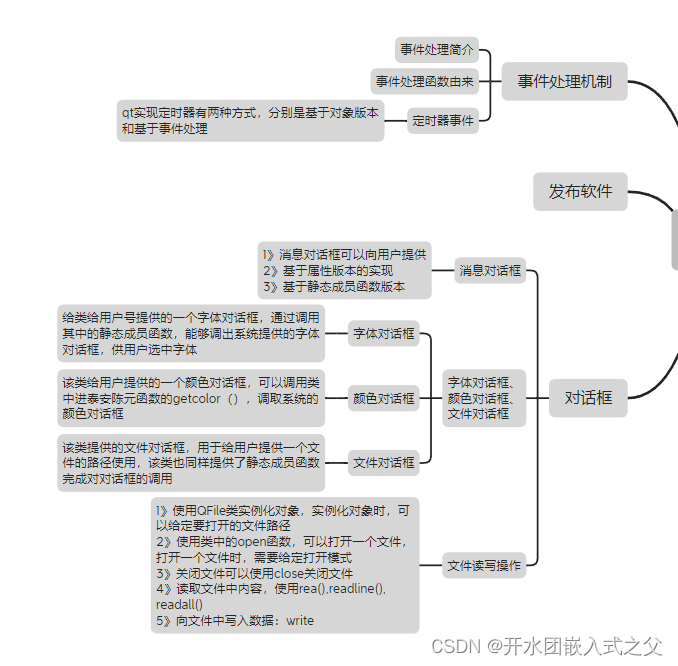
QT: 用定时器完成闹钟的实现
闹钟项目: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTimerEvent> #include <QTime> #include <QDebug> #include <QTextToSpeech> #include <QMessageBox> #include <QTimer>QT_BEGIN…...
Boyer-Moore 投票算法
这里先贴题目: Boyer-Moore 投票算法: 通俗点来讲,就是占领据点,像攻城那样,对消。 当你的据点有人时对消,无人时就占领。 这道题使用该算法可实现时间复杂度为O(n),空间复杂度为O(1),接下来看…...

C# 翻转二叉树
226 翻转二叉树 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] 示例 2: 输入:root [2,1,3] 输出:…...
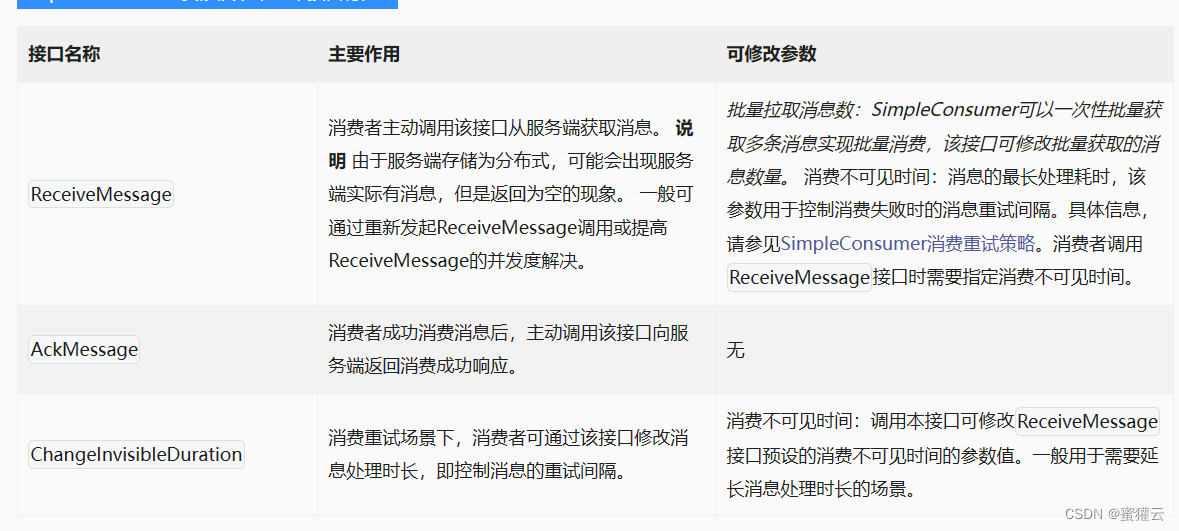
RocketMQ教程-(5)-功能特性-消费者分类
Apache RocketMQ 支持 PushConsumer 、 SimpleConsumer 以及 PullConsumer 这三种类型的消费者,本文分别从使用方式、实现原理、可靠性重试和适用场景等方面为您介绍这三种类型的消费者。 背景信息 Apache RocketMQ 面向不同的业务场景提供了不同消费者类型&…...
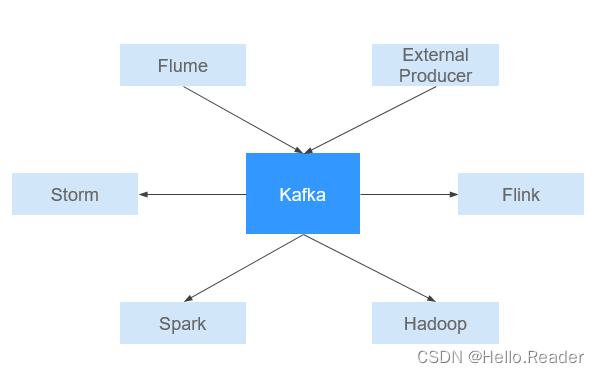
Kafka原理剖析
一、简介 Kafka是一个分布式的、分区的、多副本的消息发布-订阅系统,它提供了类似于JMS的特性,但在设计上完全不同,它具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的…...
word怎么转换成pdf?分享几种转换方法
word怎么转换成pdf?将Word文档转换成PDF文件有几个好处。首先,PDF文件通常比Word文档更容易在不同设备和操作系统上查看和共享。其次,PDF文件通常比Word文档更难以修改,这使得它们在需要保护文件内容的情况下更加安全可靠。最后&a…...

基于XDMA 中断模式的 PCIE3.0 QT上位机与FPGA数据交互架构 提供工程源码和QT上位机源码
目录 1、前言2、我已有的PCIE方案3、PCIE理论4、总体设计思路和方案图像产生、发送、缓存数据处理XDMA简介XDMA中断模式图像读取、输出、显示QT上位机及其源码 5、vivado工程详解6、上板调试验证7、福利:工程代码的获取 1、前言 PCIE(PCI Express&#…...
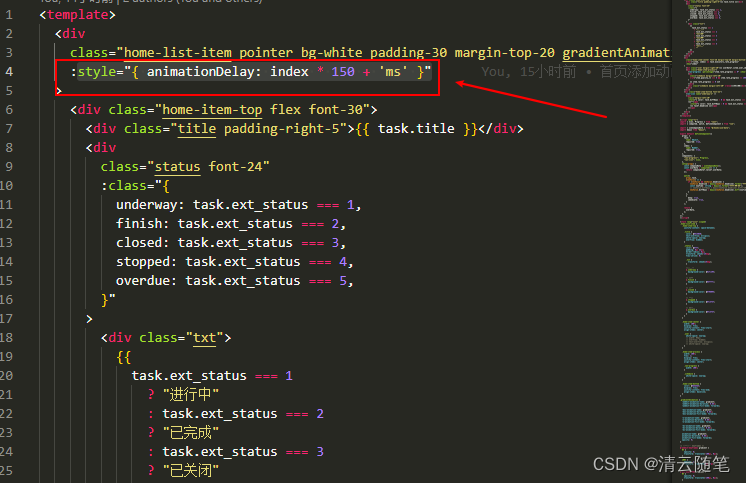
Vue 中通用的 css 列表入场动画效果
css 代码 .gradientAnimation {animation-name: gradient;animation-duration: 0.85s;animation-fill-mode: forwards;opacity: 0; }/* 不带前缀的放到最后 */ keyframes gradient {0% {opacity: 0;transform: translate(-100px, 0px);}100% {opacity: 1;transform: translate…...

微分流形2:流形上的矢量场和张量场
来了来了,切向量,切空间。流形上的所有的线性泛函的集合,注意是函数的集合。然后取流形上的某点p,它的切向量为,线性泛函到实数的映射。没错,是函数到实数的映射,是不是想到了求导。我们要逐渐熟…...
C++数组、向量和列表的练习
运行代码: //C数组、向量和列表的练习 #include"std_lib_facilities.h"int main() try {int ii[10] { 0,1,2,3,4,5,6,7,8,9 };for (int i 0; i < 10; i)//把数组中的每个元素值加2ii[i] 2;vector<int>vv(10);for (int i 0; i < 10; i)vv…...
视频剪辑矩阵分发系统Unable to load FFProbe报错技术处理?
问题一 报错处理 对于视频剪辑矩阵分发系统中出现的“Unable to load FFProbe”报错问题,可以采取以下技术处理措施进行解决。 1.检查系统中是否正确安装了FFProbe工具,并确保其路径正确配置。 2.检查系统环境变量是否正确设置,包括FFPr…...
Docker轻量级可视化工具Portainer
Portainer是一个轻量级的管理UI界面,用于管理Docker容器、镜像、卷和网络。它支持端口映射、容器启动、停止、删除、日志查看等功能,同时也提供了可视化的监控和统计功能,可以快速轻松的管理多个Docker主机。Portainer不需要额外安装依赖&…...

功率放大器在电光调制中的应用有哪些
电光调制是一种利用光电效应将电信号转化为光信号的技术。在实现电光调制的过程中,功率放大器作为一个重要的组件,具有对输入电信号进行放大和控制的功能。本文将介绍功率放大器的基本原理、特点以及在电光调制中的应用。 基本原理 功率放大器是一种能够…...

MyBatis入门程序
1.MyBatis 入门程序开发步骤 SqlSession:代表Java程序和数据库之间的会话。(HttpSession是Java程序和浏览器之间的会话) SqlSessionFactory:是“生产”SqlSession的“工厂”。 工厂模式:如果创建某一个对象ÿ…...

C++快速切换 头文件和源文件
有没有一种快速的方法 , 将头文件中的声明 直接在源文件中自动写出来, 毕竟头文件中已经有声明了, 我只需要写具体实现就行了,没有必要把声明的部分再敲一遍在 Visual Studio 中,你可以使用快速生成函数定义的功能来实…...
对原型、原型链的理解
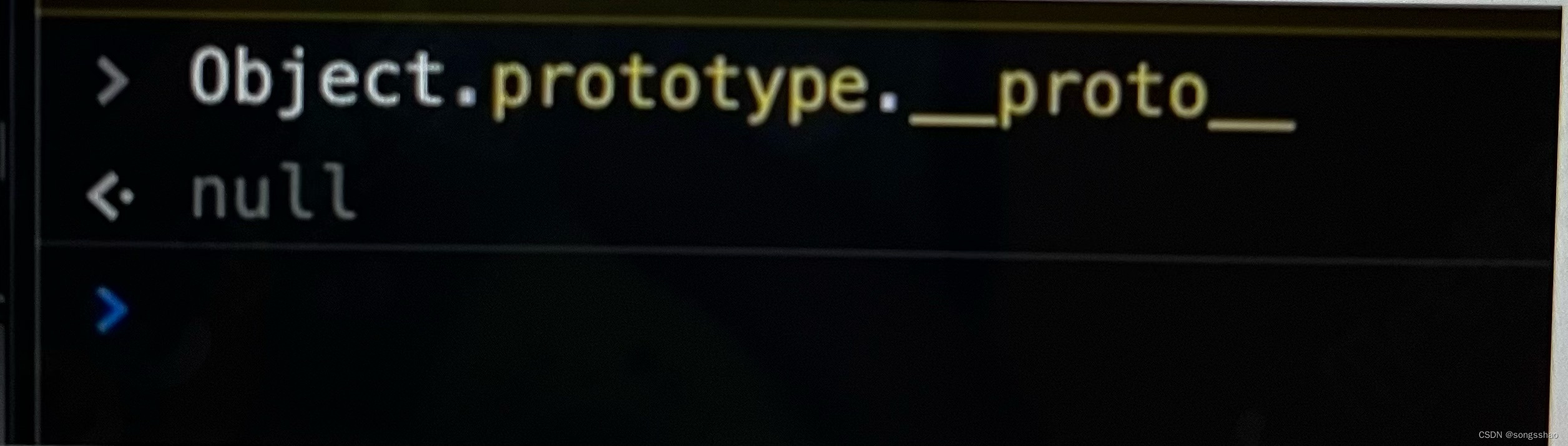
在 JavaScript 中是使用构造两数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性,它的属性值是一个对象,这个对象包含了可以由该构造西数的所有实例共享的属性和方法。当使用构造函数新建一个对象后,在这个对象的内…...

7月26日,每日信息差
1、日本经产省将讨论让消费者负担核电站重启费。若被采用,那么即便是与把源自可再生能源作为卖点的新电力公司签约的消费者,也将负担重启核电站的费用 2、国家发改委:电厂存煤和出力均达历史同期最高水平 3、国家深改委:全国统调…...

git修改已经push后的commit注释
回到倒数第8次提交 git rebase -i HEAD~8修改注释,然后把最前面的pick改成edit 修改注释 git commit --amendrebase确认 git rebase --continue强制提交 git push -f origin master参考:https://blog.csdn.net/qq_16942727/article/details/1260355…...

网络云存储服务器,数据库服务器|PetaExpress
云存储服务器是什么? 云存储服务器是一种在线存储(英语:Cloud storage)该模式是将数据存储在通常由第三方托管的多个虚拟服务器上,而不是独家服务器上。 云存储服务器有几种结构 架构方法分为两类:一类是通过服务进行架构&…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

PDF差异对比神器diff-pdf:告别文档核对烦恼,提升工作效率的智能解决方案
PDF差异对比神器diff-pdf:告别文档核对烦恼,提升工作效率的智能解决方案 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 你是否曾在核对PDF文档时感到头疼…...