每天100w次登陆请求, 8G 内存该如何设置JVM参数?
一、新系统上线如何规划容量?
1.套路总结
任何新的业务系统在上线以前都需要去估算服务器配置和JVM的内存参数,这个容量与资源规划并不仅仅是系统架构师的随意估算的,需要根据系统所在业务场景去估算,推断出来一个系统运行模型,评估JVM性能和GC频率等等指标。以下是我结合大牛经验以及自身实践来总结出来的一个建模步骤:
- 计算业务系统每秒钟创建的对象会佔用多大的内存空间,然后计算集群下的每个系统每秒的内存佔用空间(对象创建速度)
- 设置一个机器配置,估算新生代的空间,比较不同新生代大小之下,多久触发一次
MinorGC。 - 为了避免频繁GC,就可以重新估算需要多少机器配置,部署多少台机器,给JVM多大内存空间,新生代多大空间。
- 根据这套配置,基本可以推算出整个系统的运行模型,每秒创建多少对象,1s以后成为垃圾,系统运行多久新生代会触发一次GC,频率多高。
2.套路实战——以登录系统为例
有些同学看到这些步骤还是发憷,说的好像是那么回事,一到实际项目中到底怎麽做我还是不知道!
光说不练假把式,以登录系统为例模拟一下推演过程:
- 假设每天100w次登陆请求,登陆峰值在早上,预估峰值时期每秒100次登陆请求。
- 假设部署3台服务器,每台机器每秒处理30次登陆请求,假设一个登陆请求需要处理1秒钟,JVM新生代里每秒就要生成30个登陆对象,1s之后请求完毕这些对象成为了垃圾。
- 一个登陆请求对象假设20个字段,一个对象估算500字节,30个登陆佔用大约15kb,考虑到RPC和DB操作,网络通信、写库、写缓存一顿操作下来,可以扩大到20-50倍,大约1s产生几百k-1M数据。
- 假设2C4G机器部署,分配2G堆内存,新生代则只有几百M,按照1s1M的垃圾产生速度,几百秒就会触发一次MinorGC了。
- 假设4C8G机器部署,分配4G堆内存,新生代分配2G,如此需要几个小时才会触发一次MinorGC。
所以,可以粗略的推断出来一个每天100w次请求的登录系统,按照4C8G的3实例集群配置,分配4G堆内存、2G新生代的JVM,可以保障系统的一个正常负载。
基本上把一个新系统的资源评估了出来,所以搭建新系统要每个实例需要多少容量多少配置,集群配置多少个实例等等这些,并不是拍拍脑袋和胸脯就可以决定的下来的。
二、该如何进行垃圾回收器的选择?
吞吐量还是响应时间
首先引入两个概念:吞吐量和低延迟
吞吐量 = CPU在用户应用程序运行的时间 / (CPU在用户应用程序运行的时间 + CPU垃圾回收的时间)
响应时间 = 平均每次的GC的耗时
通常,吞吐优先还是响应优先这个在JVM中是一个两难之选。
堆内存增大,gc一次能处理的数量变大,吞吐量大;但是gc一次的时间会变长,导致后面排队的线程等待时间变长;相反,如果堆内存小,gc一次时间短,排队等待的线程等待时间变短,延迟减少,但一次请求的数量变小(并不绝对符合)。
无法同时兼顾,是吞吐优先还是响应优先,这是一个需要权衡的问题。
垃圾回收器设计上的考量
- JVM在GC时不允许一边垃圾回收,一边还创建新对象(就像不能一边打扫卫生,还在一边扔垃圾)。
- JVM需要一段Stop the world的暂停时间,而STW会造成系统短暂停顿不能处理任何请求;
- 新生代收集频率高,性能优先,常用复制算法;老年代频次低,空间敏感,避免复制方式。
- 所有垃圾回收器的涉及目标都是要让GC频率更少,时间更短,减少GC对系统影响!
CMS和G1
目前主流的垃圾回收器配置是新生代采用ParNew,老年代采用CMS组合的方式,或者是完全采用G1回收器,
从未来的趋势来看,G1是官方维护和更为推崇的垃圾回收器。

业务系统:
延迟敏感的推荐CMS;
大内存服务,要求高吞吐的,采用G1回收器!
CMS垃圾回收器的工作机制
CMS主要是针对老年代的回收器,老年代是标记-清除,默认会在一次FullGC算法后做整理算法,清理内存碎片。
| CMSGC | 描述 | Stop the world | 速度 |
|---|---|---|---|
| 1.开始标记 | 初始标记仅标记GCRoots能直接关联到的对象,速度很快 | Yes | 很快 |
| 2.并发标记 | 并发标记阶段就是进行GCRoots Tracing的过程 | No | 慢 |
| 3.重新标记 | 重新标记阶段则是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录。 | Yes | 很快 |
| 4.垃圾回收 | 并发清理垃圾对象(标记清除算法) | No | 慢 |
优点:
并发收集、主打“低延时” 。在最耗时的两个阶段都没有发生STW,而需要STW的阶段都以很快速度完成。
缺点:
1、消耗CPU;2、浮动垃圾;3、内存碎片
适用场景:
重视服务器响应速度,要求系统停顿时间最短。
总之:
业务系统,延迟敏感的推荐CMS;
大内存服务,要求高吞吐的,采用G1回收器!
三、如何对各个分区的比例、大小进行规划
一般的思路为:
首先,JVM最重要最核心的参数是去评估内存和分配,第一步需要指定堆内存的大小,这个是系统上线必须要做的,-Xms 初始堆大小,-Xmx 最大堆大小,后台Java服务中一般都指定为系统内存的一半,过大会佔用服务器的系统资源,过小则无法发挥JVM的最佳性能。
其次,需要指定-Xmn新生代的大小,这个参数非常关键,灵活度很大,虽然sun官方推荐为3/8大小,但是要根据业务场景来定,针对于无状态或者轻状态服务(现在最常见的业务系统如Web应用)来说,一般新生代甚至可以给到堆内存的3/4大小;而对于有状态服务(常见如IM服务、网关接入层等系统)新生代可以按照默认比例1/3来设置。服务有状态,则意味著会有更多的本地缓存和会话状态信息常驻内存,应为要给老年代设置更大的空间来存放这些对象。
最后,是设置-Xss栈内存大小,设置单个线程栈大小,默认值和JDK版本、系统有关,一般默认512~1024kb。一个后台服务如果常驻线程有几百个,那麽栈内存这边也会佔用了几百M的大小。
| JVM参数 | 描述 | 默认 | 推荐 |
|---|---|---|---|
| -Xms | Java堆内存的大小 | OS内存64/1 | OS内存一半 |
| -Xmx | Java堆内存的最大大小 | OS内存4/1 | OS内存一半 |
| -Xmn | Java堆内存中的新生代大小,扣除新生代剩下的就是老年代的内存大小了 | 默认堆的1/3 | sun推荐3/8 |
| -Xss | 每个线程的栈内存大小 | 和idk有关 | sun |
对于8G内存,一般分配一半的最大内存就可以了,因为机器本上还要占用一定内存,一般是分配4G内存给JVM,
引入性能压测环节,测试同学对登录接口压至1s内60M的对象生成速度,采用ParNew+CMS的组合回收器,
正常的JVM参数配置如下:
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
这样设置可能会由于动态对象年龄判断原则 导致频繁full gc。为啥呢?
压测过程中,短时间(比如20S后)Eden区就满了,此时再运行的时候对象已经无法分配,会触发MinorGC,
假设在这次GC后S1装入100M,马上过20S又会触发一次MinorGC,多出来的100M存活对象+S1区的100M已经无法顺利放入到S2区,此时就会触发JVM的动态年龄机制,将一批100M左右的对象推到老年代保存,持续运行一段时间,系统可能一个小时候内就会触发一次FullGC。
按照默认8:1:1的比例来分配时, survivor区只有 1G的 10%左右,也就是几十到100M,
如果 每次minor GC垃圾回收过后进入survivor对象很多,并且survivor对象大小很快超过 Survivor 的 50% , 那么会触发动态年龄判定规则,让部分对象进入老年代.
而一个GC过程中,可能部分WEB请求未处理完毕, 几十兆对象,进入survivor的概率,是非常大的,甚至是一定会发生的.
如何解决这个问题呢?为了让对象尽可能的在新生代的eden区和survivor区, 尽可能的让survivor区内存多一点,达到200兆左右,
于是我们可以更新下JVM参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8 说明:
‐Xmn2048M ‐XX:SurvivorRatio=8
年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
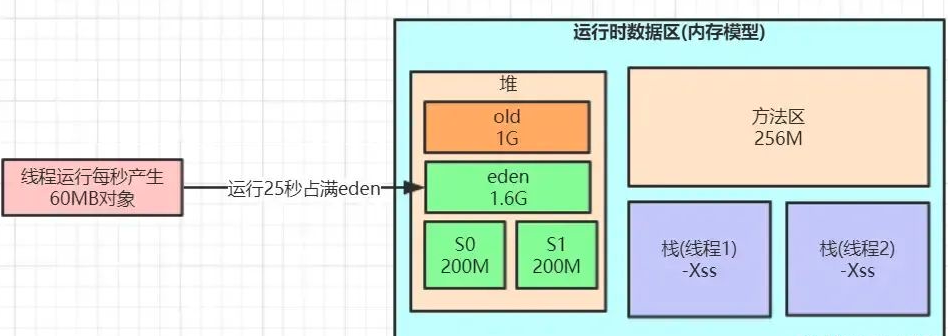
survivor达到200m,如果几十兆对象到底survivor, survivor 也不一定超过 50%
这样可以防止每次垃圾回收过后,survivor对象太早超过 50% ,
这样就降低了因为对象动态年龄判断原则导致的对象频繁进入老年代的问题,
什么是JVM动态年龄判断规则呢?
对象进入老年代的动态年龄判断规则 (动态晋升年龄计算阈值):Minor GC 时,Survivor 中年龄 1 到 N 的对象大小超过 Survivor 的 50% 时,则将大于等于年龄 N 的对象放入老年代。
核心的优化策略是:是让短期存活的对象尽量都留在survivor里,不要进入老年代,这样在minor gc的时候这些对象都会被回收,不会进到老年代从而导致full gc 。
应该如何去评估新生代内存和分配合适?
这里特别说一下,JVM最重要最核心的参数是去评估内存和分配,
第一步需要指定堆内存的大小,这个是系统上线必须要做的,-Xms 初始堆大小,-Xmx 最大堆大小,
后台Java服务中一般都指定为系统内存的一半,过大会占用服务器的系统资源,过小则无法发挥JVM的最佳性能。
其次需要指定-Xmn新生代的大小,这个参数非常关键,灵活度很大,虽然sun官方推荐为3/8大小,但是要根据业务场景来定:
- 针对于无状态或者轻状态服务(现在最常见的业务系统如Web应用)来说,一般新生代甚至可以给到堆内存的3/4大小;
- 而对于有状态服务(常见如IM服务、网关接入层等系统)新生代可以按照默认比例1/3来设置。服务有状态,则意味著会有更多的本地缓存和会话状态信息常驻内存,应为要给老年代设置更大的空间来存放这些对象。
四、栈内存大小多少比较合适?
-Xss栈内存大小,设置单个线程栈大小,默认值和JDK版本、系统有关,一般默认512~1024kb。一个后台服务如果常驻线程有几百个,那麽栈内存这边也会佔用了几百M的大小。
五、对象年龄应该为多少才移动到老年代比较合适?
假设一次minor gc要间隔二三十秒,并且,大多数对象一般在几秒内就会变为垃圾,
如果对象这么长时间都没被回收,比如2分钟没有回收,可以认为这些对象是会存活的比较长的对象,从而移动到老年代,而不是继续一直占用survivor区空间。
所以,可以将默认的15岁改小一点,比如改为5,
那么意味着对象要经过5次minor gc才会进入老年代,整个时间也有一两分钟了(5*30s= 150s),和几秒的时间相比,对象已经存活了足够长时间了。
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5
六、多大的对象,可以直接到老年代比较合适?
对于多大的对象直接进入老年代(参数-XX:PretenureSizeThreshold),一般可以结合自己系统看下有没有什么大对象 生成,预估下大对象的大小,一般来说设置为1M就差不多了,很少有超过1M的大对象,
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M
七、垃圾回收器CMS老年代的参数优化
JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),
如果内存较大(超过4个G,只是经验 值),还是建议使用G1.
这里是4G以内,又是主打“低延时” 的业务系统,可以使用下面的组合:
ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC)
新生代的采用ParNew回收器,工作流程就是经典复制算法,在三块区中进行流转回收,只不过采用多线程并行的方式加快了MinorGC速度。
老生代的采用CMS。再去优化老年代参数 :比如老年代默认在标记清除以后会做整理,还可以在CMS的增加GC频次还是增加GC时长上做些取舍,
如下是响应优先的参数调优:
XX:CMSInitiatingOccupancyFraction=70
设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)
XX:+UseCMSInitiatinpOccupancyOnly
和上面搭配使用,否则只生效一次
-XX:+AlwaysPreTouch
强制操作系统把内存真正分配给IVM,而不是用时才分配。
综上,只要年轻代参数设置合理,老年代CMS的参数设置基本都可以用默认值,如下所示:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC ‐XX:CMSInitiatingOccupancyFraction=70 ‐XX:+UseCMSInitiatingOccupancyOnly ‐XX:+AlwaysPreTouch
参数解释
1.‐Xms3072M ‐Xmx3072M 最小最大堆设置为3g,最大最小设置为一致防止内存抖动
2.‐Xss1M 线程栈1m
3.‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
4.-XX:MaxTenuringThreshold=5 年龄为5进入老年代
5.‐XX:PretenureSizeThreshold=1M 大于1m的大对象直接在老年代生成
6.‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC 使用ParNew+cms垃圾回收器组合
7.‐XX:CMSInitiatingOccupancyFraction=70 老年代中对象达到这个比例后触发fullgc
8.‐XX:+UseCMSInitiatinpOccupancyOnly 老年代中对象达到这个比例后触发fullgc,每次
9.‐XX:+AlwaysPreTouch 强制操作系统把内存真正分配给IVM,而不是用时才分配。
八、配置OOM时候的内存dump文件和GC日志
额外增加了GC日志打印、OOM自动dump等配置内容,帮助进行问题排查
-XX:+HeapDumpOnOutOfMemoryError
在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件。
不然开发很多时候还真不知道怎么重现错误。
路径只指向目录,JVM会保持文件名的唯一性,叫java_pid${pid}.hprof。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${LOGDIR}/
因为如果指向特定的文件,而文件已存在,反而不能写入。
输出4G的HeapDump,会导致IO性能问题,在普通硬盘上,会造成20秒以上的硬盘IO跑满,
需要注意一下,但在容器环境下,这个也会影响同一宿主机上的其他容器。
GC的日志的输出也很重要:
-Xloggc:/dev/xxx/gc.log
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
GC的日志实际上对系统性能影响不大,打日志对排查GC问题很重要。
九、一份通用的JVM参数模板
一般来说,大企业或者架构师团队,都会为项目的业务系统定制一份较为通用的JVM参数模板,但是许多小企业和团队可能就疏于这一块的设计,如果老板某一天突然让你负责定制一个新系统的JVM参数,你上网去搜大量的JVM调优文章或博客,结果发现都是零零散散的、不成体系的JVM参数讲解,根本下不了手,这个时候你就需要一份较为通用的JVM参数模板了,不能保证性能最佳,但是至少能让JVM这一层是稳定可控的,
在这里给大家总结了一份模板:
基于4C8G系统的ParNew+CMS回收器模板(响应优先),新生代大小根据业务灵活调整!
-Xms4g
-Xmx4g
-Xmn2g
-Xss1m
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=10
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+AlwaysPreTouch
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
如果是GC的吞吐优先,推荐使用G1,基于8C16G系统的G1回收器模板:
G1收集器自身已经有一套预测和调整机制了,因此我们首先的选择是相信它,
即调整-XX:MaxGCPauseMillis=N参数,这也符合G1的目的——让GC调优尽量简单!
同时也不要自己显式设置新生代的大小(用-Xmn或-XX:NewRatio参数),
如果人为干预新生代的大小,会导致目标时间这个参数失效。
-Xms8g
-Xmx8g
-Xss1m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=150
-XX:InitiatingHeapOccupancyPercent=40
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
| G1参数 | 描述 | 默认值 |
|---|---|---|
| XX:MaxGCPauseMillis=N | 最大GC停顿时间。柔性目标,JVM满足90%,不保证100%。 | 200 |
| -XX:nitiatingHeapOccupancyPercent=n | 当整个堆的空间使用百分比超过这个值时,就会融发MixGC | 45 |
针对-XX:MaxGCPauseMillis来说,参数的设置带有明显的倾向性:调低↓:延迟更低,但MinorGC频繁,MixGC回收老年代区减少,增大Full GC的风险。调高↑:单次回收更多的对象,但系统整体响应时间也会被拉长。
针对InitiatingHeapOccupancyPercent来说,调参大小的效果也不一样:调低↓:更早触发MixGC,浪费cpu。调高↑:堆积过多代回收region,增大FullGC的风险。
调优总结
系统在上线前的综合调优思路:
1、业务预估:根据预期的并发量、平均每个任务的内存需求大小,然后评估需要几台机器来承载,每台机器需要什么样的配置。
2、容量预估:根据系统的任务处理速度,然后合理分配Eden、Surivior区大小,老年代的内存大小。
3、回收器选型:响应优先的系统,建议采用ParNew+CMS回收器;吞吐优先、多核大内存(heap size≥8G)服务,建议采用G1回收器。
4、优化思路:让短命对象在MinorGC阶段就被回收(同时回收后的存活对象<Survivor区域50%,可控制保留在新生代),长命对象尽早进入老年代,不要在新生代来回复制;尽量减少Full GC的频率,避免FGC系统的影响。
5、到目前为止,总结到的调优的过程主要基于上线前的测试验证阶段,所以我们尽量在上线之前,就将机器的JVM参数设置到最优!
JVM调优只是一个手段,但并不一定所有问题都可以通过JVM进行调优解决,大多数的Java应用不需要进行JVM优化,我们可以遵循以下的一些原则:
- 上线之前,应先考虑将机器的JVM参数设置到最优;
- 减少创建对象的数量(代码层面);
- 减少使用全局变量和大对象(代码层面);
- 优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
- 分析GC情况优化代码比优化JVM参数更好(代码层面);
通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
相关文章:
每天100w次登陆请求, 8G 内存该如何设置JVM参数?
一、新系统上线如何规划容量? 1.套路总结 任何新的业务系统在上线以前都需要去估算服务器配置和JVM的内存参数,这个容量与资源规划并不仅仅是系统架构师的随意估算的,需要根据系统所在业务场景去估算,推断出来一个系统运行模型&…...

Fiddler Everywhere(TTP调试抓包工具) for Mac苹果电脑版
Fiddler Everywhere for Mac版是Mac电脑上的一款跨平台的HTTP调试抓包工具,Fiddler Everywhere for Mac能够记录客户端与服务器之间的所有HTTP(S)通信,支持对包进行监视、分析、设置断点、甚至修改请求/响应数据等操作。 适用于任…...

Paragon NTFS2023最新版Mac读写NTFS磁盘工具
Paragon NTFS for Mac是Mac平台上一款非常优秀的读写工具,可以在Mac OS X中完全读写、修改、访问NTFS硬盘、U盘等外接设备的文件。这款软件最大的亮点简书可以让我们读写 NTFS 分区,因为在Mac OS X 系统上,默认状态下我们只能读取NTFS 分区&a…...
vs2013 32位 编译的 dll,重新用vs2022 64位编译,所遇问题记录
目录 一、vs2013 32 DLL 转 VS2022 64 DLL 所遇问题 1、 LNK2038: 检测到“_MSC_VER”的不匹配项: 值“1800”不匹配值“1900” 2、原先VS2013 现在 VS2022 导致的vsnprintf 重定义问题 3、 无法解析的外部符号 __vsnwprintf_s 4、无法解析的外部符号__imp__CertFreeC…...
Linux_CentOS_7.9部署Docker以及镜像加速配置等实操验证全过程手册
前言:实操之前大家应该熟悉一个新的名词DevOps 俗称开发即运维、新一代开发工程师(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障&…...

强引用和弱引用
什么是弱引用和强引用 强引用: JavaScript 中强引用:对象的引用在 JavaScript 中是强引用,也就是将一个引用对象通过变量或常量保存时,那么这个变量或常量就是强引用,这个对象就不会被回收。 弱引用: JavaS…...
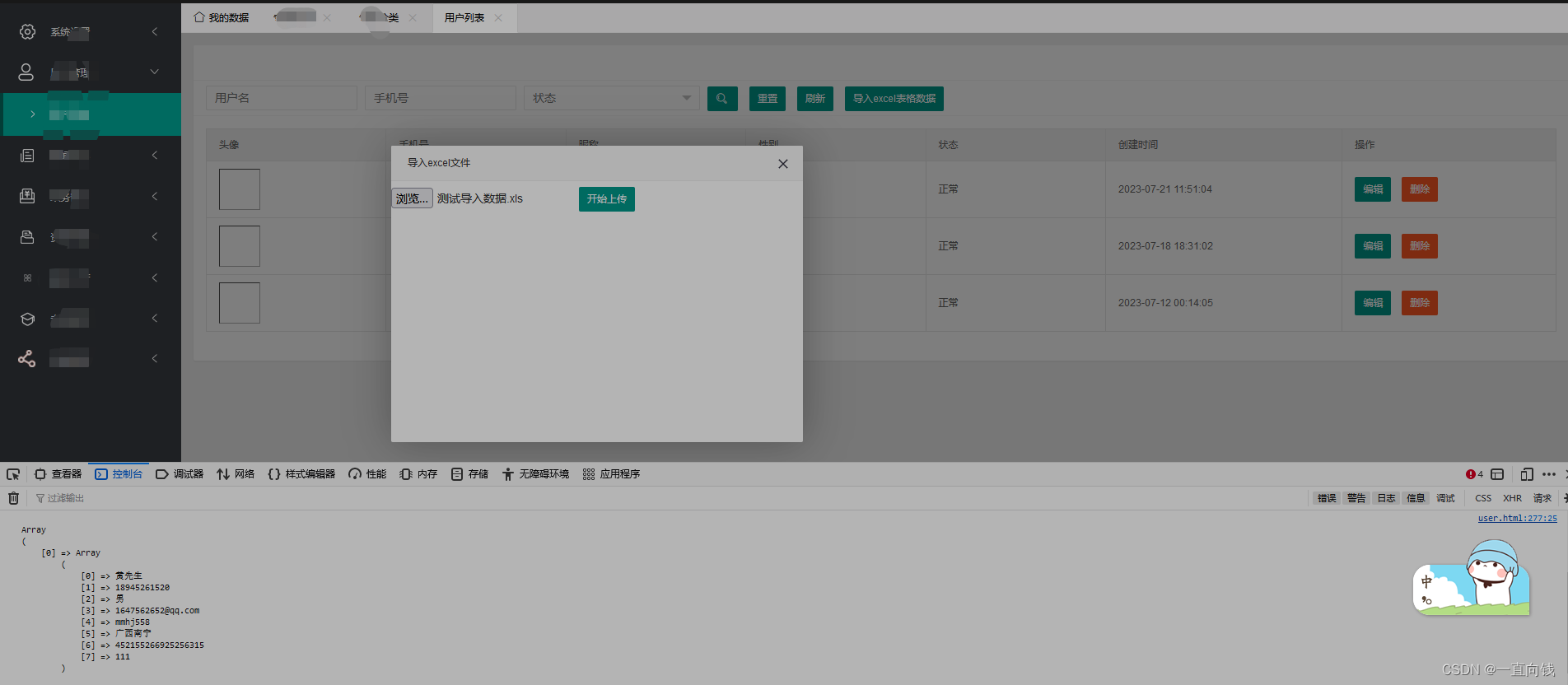
tp6 实现excel 导入功能
在项目根目录安装 composer require phpoffice/phpspreadsheet 我们看一下郊果图,如下 点击导入excel表格数据 出现弹窗选择文件,控制台打开输出文档内容 前端layui代码 <form id"uploadForm" class"form-horizontal" encty…...
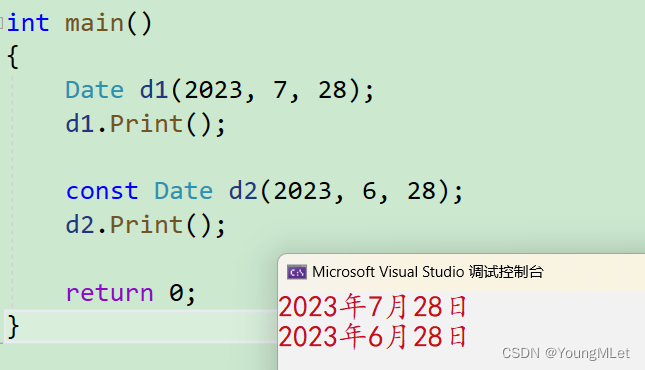
【C++】类和对象(中篇)
类和对象 类的六大默认成员函数一、构造函数1. 构造函数的概念2. 构造函数的特性 二、析构函数1. 析构函数的概念2. 析构函数的特性 三、拷贝构造函数1. 拷贝构造函数的概念2. 拷贝构造函数的特征 四、赋值运算符重载1. 运算符重载2. 赋值运算符重载 五、取地址及 const 取地址…...
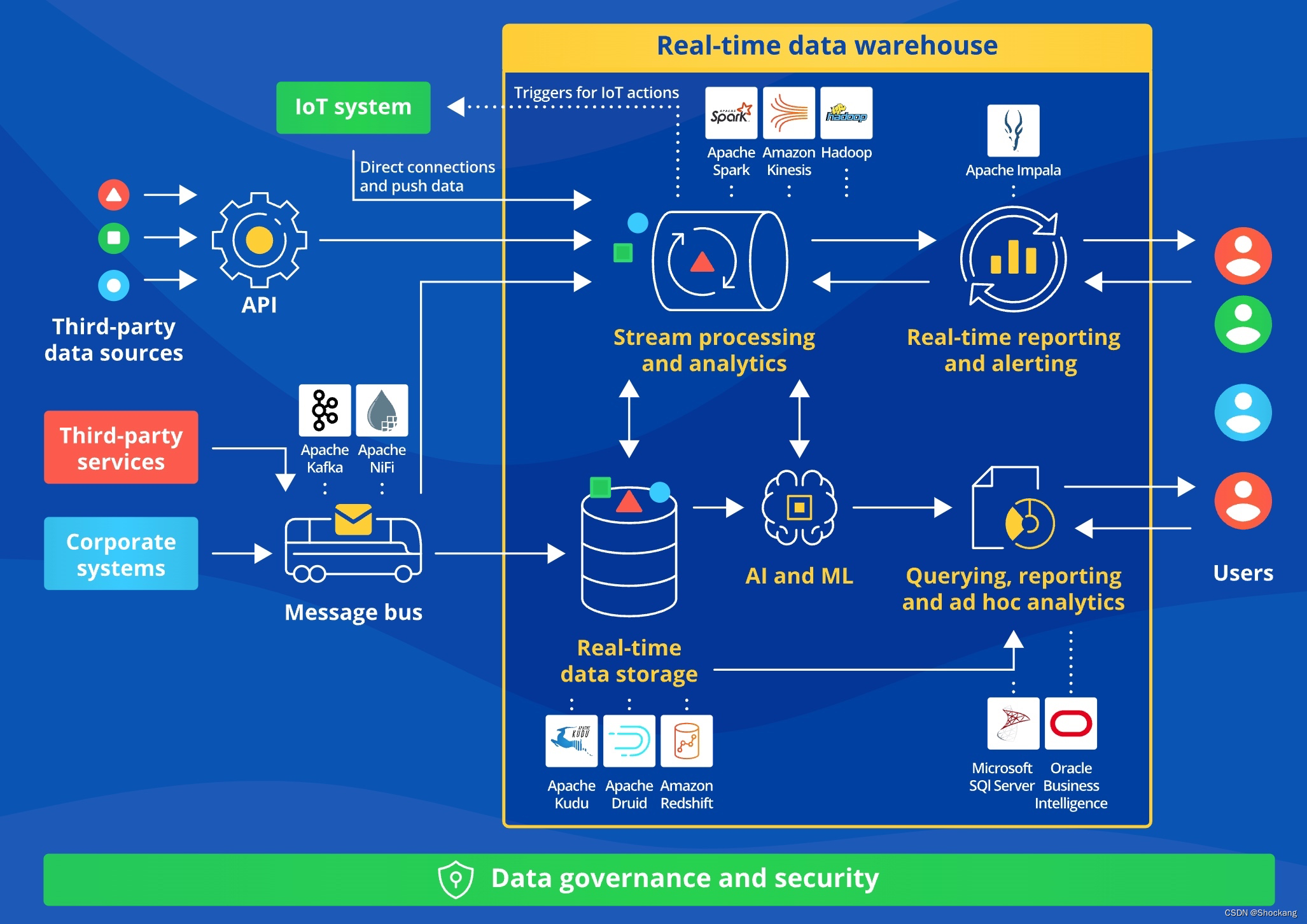
大数据处理架构详解:Lambda架构、Kappa架构、流批一体、Dataflow模型、实时数仓
前言 本文隶属于专栏《大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据理论体系 姊妹篇 《分布式数据模型详解:OldSQL &…...

双指针解决n数之和问题
1. 两数之和 1. 两数之和 将时间复杂度降到O(n); class Solution {// 双指针public int[] twoSum(int[] nums, int target) {int nnums.length;int l0;while(l<n){int rn-1;// 找到第一个可能nums[l]nums[r]target的位置while(r>l){if(nums[l]nums[r]targe…...
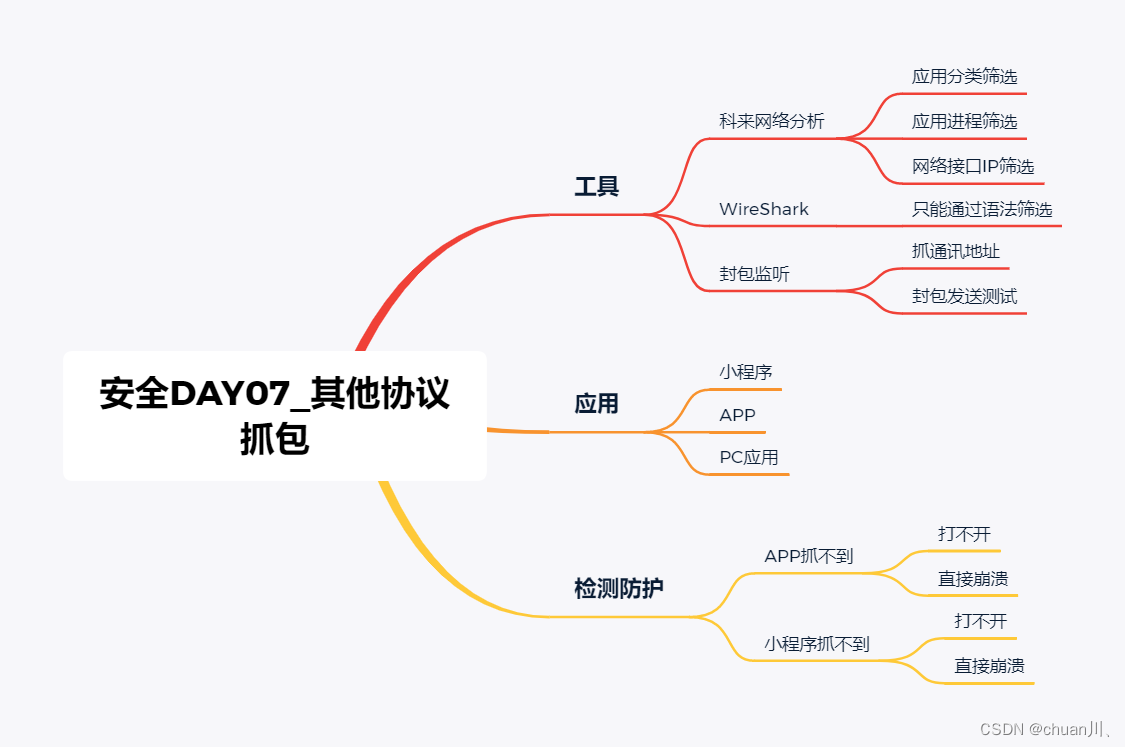
安全学习DAY07_其他协议抓包技术
协议抓包技术-全局-APP&小程序&PC应用 抓包工具-Wireshark&科来分析&封包 TCPDump: 是可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用…...
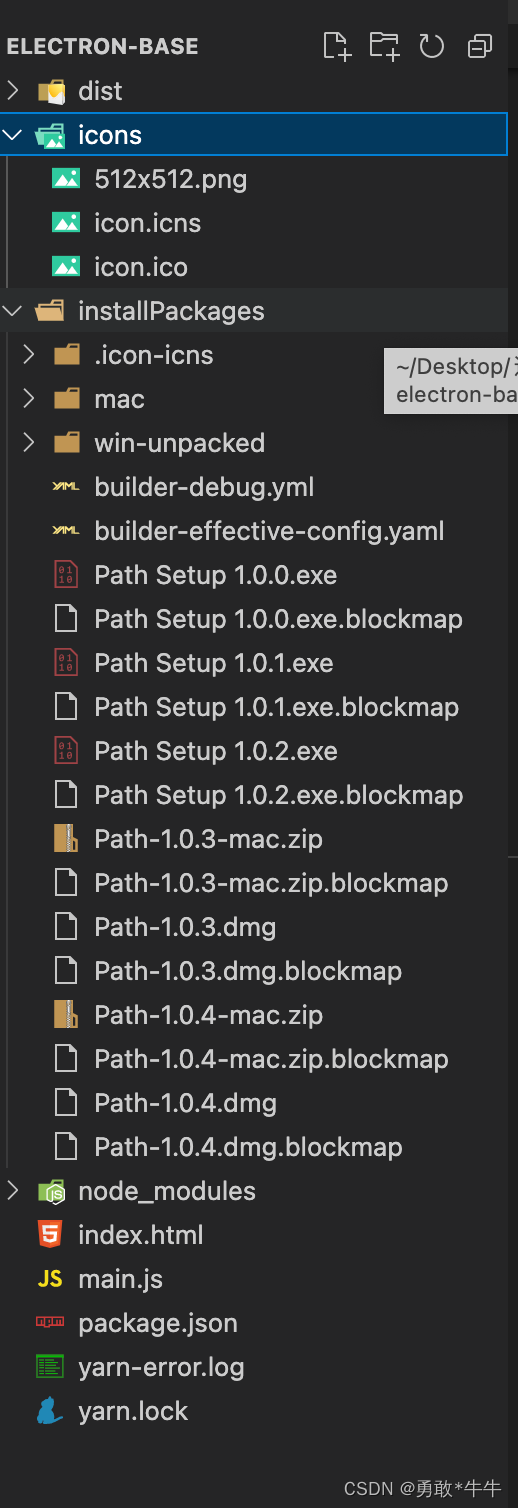
electron的electron-packager打包运行和electron-builder生产安装包过程,学透 Electron 自定义 Dock 图标
electron的electron-packager打包运行和electron-builder生产安装包过程 开发electron客户端程序,打包是绕不开的问题。 macOS 应用构建,看似近在咫尺,实则坑坑致命。 场景:mac笔记本打包,以及生产出可交付的软件安装…...

【无标题】深圳卫视专访行云创新马洪喜:拥抱AI与云原生,深耕云智一体化创新
人工智能(AI)是引领新一轮科技革命和产业变革的重要驱动力。因此,深圳出台相关行动方案,统筹设立规模1,000亿元的人工智能基金群,引导产业集聚培育企业梯队,积极打造国家新一代人工智能创新发展试验区和国家…...

jenkins通过流水线进行构建jar包
前言 最近项目上需要进行CICD,本篇博客主要分享各种骚操作 目录 前言操作如下:构建触发器测试哈哈操作如下: 1.下载Jenkins.war包上传到服务器上面,然后在同级目录下面创建如下脚本: #!/bin/bash# Jenkins安装目录 JENKINS_HOME=/usr/local/jenkins# Jenkins日志文件 LO…...

Android开发:通过Tesseract第三方库实现OCR
一、引言 什么是OCR?OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。简单地说&#…...

合并两个有序链表——力扣21
题目描述 法一 递归 class Solution { public:ListNode* mergeTwoLists(ListNode *l1, ListNode*l2){if(l1 nullptr){return l2;} else if (l2nullptr){return l1;} else if (l1->val<l2->val){l1->next mergeTwoLists(l1->next, l2);return l1;} else {l2-&g…...
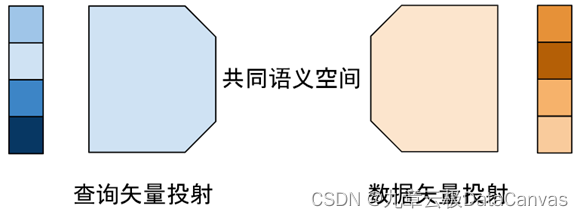
企业数据,大语言模型和矢量数据库
随着ChatGPT的推出,通用人工智能的时代缓缓拉开序幕。我们第一次看到市场在追求人工智能开发者,而不是以往的开发者寻找市场。每一个企业都有大量的数据,私有的用户数据,自己积累的行业数据,产品数据,生产线…...
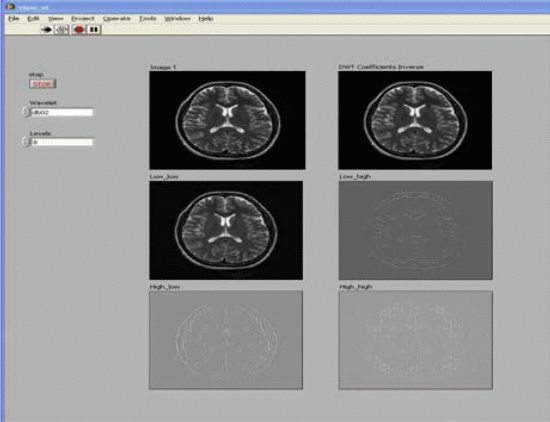
LabVIEW使用支持向量机对脑磁共振成像进行图像分类
LabVIEW使用支持向量机对脑磁共振成像进行图像分类 医学成像是用于创建人体解剖学图像以进行临床研究、诊断和治疗的技术和过程。它现在是医疗技术发展最快的领域之一。通常用于获得医学图像的方式是X射线,计算机断层扫描(CT),磁…...
kafka面试题
kafka基本概念 Producer 生产者:负责将消息发送到 BrokerConsumer 消费者:从 Broker 接收消息Consumer Group 消费者组:由多个 Consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费&am…...
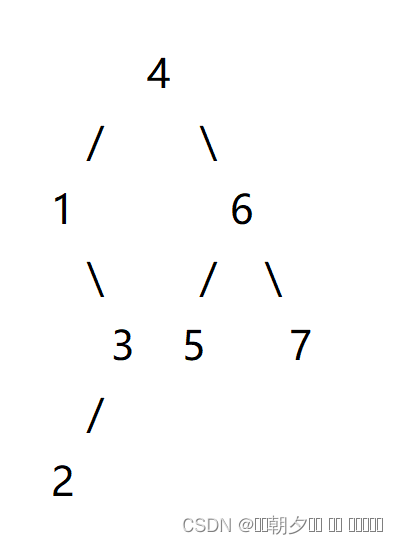
树的遍历(一题直接理解中序、后序、层序遍历,以及树的存储)
题目如下: 一个二叉树,树中每个节点的权值互不相同。 现在给出它的后序遍历和中序遍历,请你输出它的层序遍历。 输入格式 第一行包含整数 N,表示二叉树的节点数。 第二行包含 N 个整数,表示二叉树的后序遍历。 第…...

基于相关分析法与M序列的系统脉冲响应抗噪辨识技术
1. 噪声环境下的系统辨识挑战 在工业控制和信号处理领域,系统辨识就像给一个黑箱系统做"体检"。想象一下医生通过观察病人对各种刺激的反应来判断病情,工程师们也是通过分析系统对输入信号的响应来了解系统特性。但现实世界从来不是安静的实验…...

终极foobox-cn配置指南:如何打造专业级音乐播放体验
终极foobox-cn配置指南:如何打造专业级音乐播放体验 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn foobox-cn作为foobar2000的DUI(自定义用户界面)配置方案&#…...

全面解析数据库锁机制:从行锁到死锁的深度剖析
锁是数据库并发控制的核心机制,也是面试中绕不开的高频考点。很多开发者对锁的理解停留在“加锁就行了”,但遇到死锁、锁等待超时、性能骤降等问题时往往束手无策。本文将系统讲解数据库锁的分类、实现原理、锁与事务隔离级别的关系,并结合 M…...

AtlasOS系统性能优化指南:从诊断到维护的全方位解决方案
AtlasOS系统性能优化指南:从诊断到维护的全方位解决方案 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and security. 项目地址: https://gitcode.com/GitHub_Trending/atl…...
)
基于SpringBoot + Vue的新农村信息平台建设(角色:企业村民村委会管理员)
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

3分钟快速上手ComfyUI:零基础掌握节点式AI绘图终极指南
3分钟快速上手ComfyUI:零基础掌握节点式AI绘图终极指南 【免费下载链接】ComfyUI 最强大且模块化的具有图形/节点界面的稳定扩散GUI。 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI 你是否曾幻想过,如果AI绘图能像搭积木一样直观灵…...
Linux 输入子系统实战教程 —— 02设备信息查询 + 输入事件读取(阻塞 / 非阻塞模式))
(新手)Linux 输入子系统实战教程 —— 02设备信息查询 + 输入事件读取(阻塞 / 非阻塞模式)
Linux 输入子系统实战教程 —— 设备信息查询 输入事件读取(阻塞 / 非阻塞模式)完整学习文档本文档基于Linux 输入设备事件读取程序编写,包含完整注释源码、核心原理、逐模块解析、真实实验现象、错误原因分析,专为嵌入式 Linux …...

为什么AI提示工程可持续发展需要“数据驱动”?提示工程架构师的决策逻辑
《数据驱动:AI提示工程可持续发展的底层逻辑——提示工程架构师的决策密码》 一、引言:从“碰运气”到“做科学”,提示工程的必经之路 你有没有过这样的经历? 为了让大语言模型(LLM)生成符合需求的内容&…...

技术数据解析 | CALCE圆柱电池数据集:SOC估计的OCV测试基准
1. CALCE圆柱电池数据集的核心价值 CALCE电池数据集由马里兰大学先进生命周期工程中心发布,是目前全球最权威的公开电池测试数据之一。这个数据集最吸引我的地方在于它提供了完整的实验环境记录和标准化的测试流程,这对于电池状态估计算法的开发简直是雪…...

【RS】ENVI5.6 栅格数据坐标转换实战:从加载到参数设置的完整指南
1. ENVI5.6坐标转换入门指南 第一次打开ENVI5.6时,面对密密麻麻的工具栏确实有点懵。记得去年处理一批无人机影像时,就遇到了坐标系不匹配的问题。当时折腾了半天才找到这个隐藏的坐标转换功能,今天就把完整的操作流程分享给大家。 ENVI5.6…...