【多模态】19、RegionCLIP | 基于 Region 来实现视觉语言模型预训练

文章目录
- 一、背景
- 二、方法
- 2.1 Region-based Language-Image Pretraining
- 2.2 目标检测的迁移学习
- 三、效果
- 3.1 数据集
- 3.2 实现细节
- 3.3 结果
论文: RegionCLIP: Region-based Language-Image Pretraining
代码:https://github.com/microsoft/RegionCLIP
出处:CVPR2022 Oral | 微软 | 张鹏川
一、背景
近期,视觉-语言模型取得了很大的突破,如 CLIP 和 ALIGN,这些模型使用了极大的图文对儿来学习图像和文本的匹配,并且在很多无手工标签的情况下也取得了很好的效果。
为了探索这种思路能否在 region-caption 的情况下起作用,作者基于预训练好的 CLIP 模型构建了一个 R-CNN 形式的目标检测器。
主要思路:
- 先从输入图像中抠出候选区域
- 然后使用 CLIP 模型将抠出的区域和 text embedding 进行匹配

- 图 1 a-b 展示了在 LVIS 上的结果,当使用 proposal 作为输入时,CLIP 的得分无法代码定位的质量,可以看出不准的框得分为 65%,较准的框得分为 55%。
- 图 1b 中对比了使用 gt 框作为输入,CLIP 在 LVIS 框上的分类准确率只有 19%
- 所以,直接将预训练好的 CLIP 拿来用于对 region 的分类不太适合
作者想探索一下这种差别来源于哪里?
- 首先可以想到,CLIP 模型的训练是使用整个 image 作为输入的,使用的是 image-level 的文本描述来训练的,所以,模型学习到的是整张图的特征
- 所以这种模型无法将文本概念和图像中的区域联系起来
本文如何解决 image 和 region 之间的差距:
- 作者通过使用 vision-language 预训练的模型来探索如何学习 region 的表达
- 主要思想是在预训练过程中,将 image region 和 text token 进行对齐
面临的问题:
- image-text pairs 中不包含 image region 和 text token 的对齐关系
- 整张图的文本描述是不全的,也就是图中的有些目标是没有体现在文本描述中的
二、方法
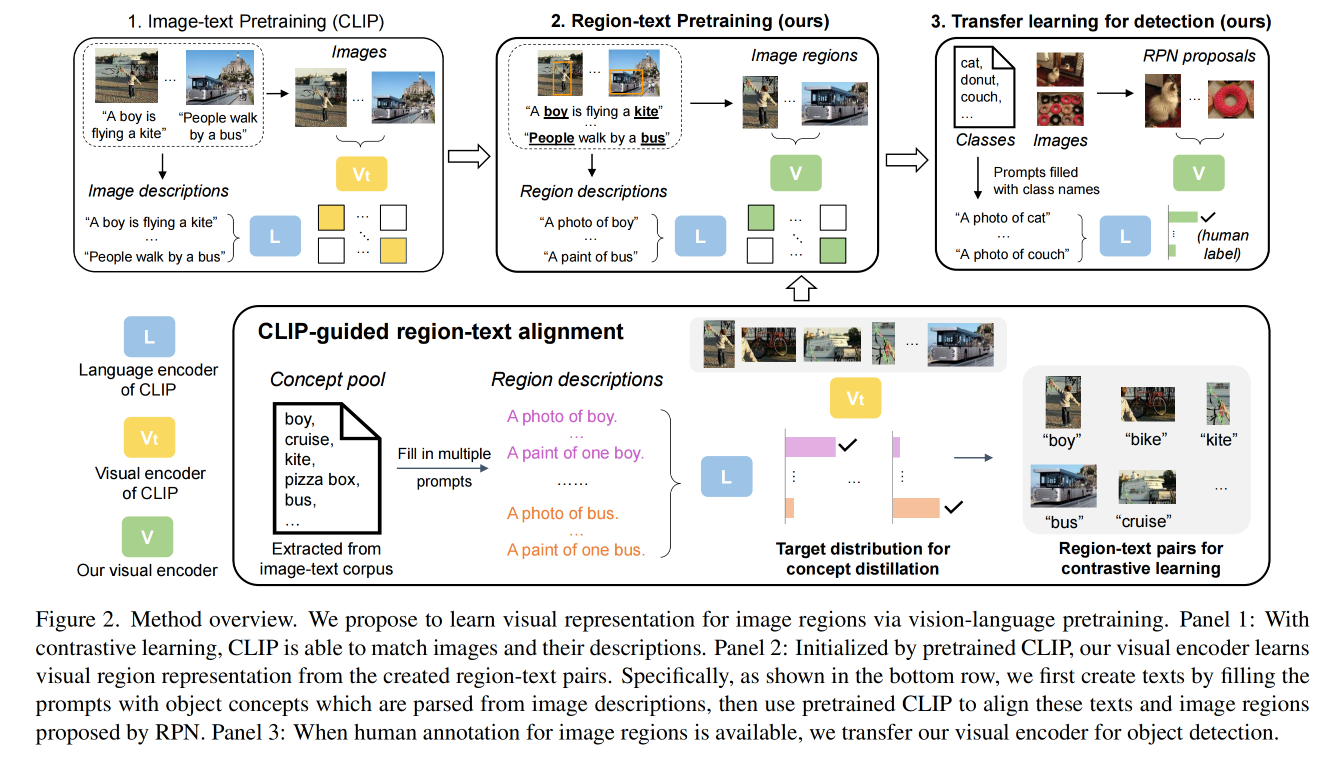
本文的目标是学习一个区域级别的视觉-语义空间,能够覆盖足够丰富的目标词汇且用于开放词汇目标检测
- 假设文本描述 t 能够描述图像 I 中的区域 r
- 在视觉-语义空间,从 r 中抽取到的 visual region representation 能够和 text representation 很好的匹配上
总体框架图如图 2:
- V t V_t Vt :CLIP 的 visual encoder, L L L :CLIP 的 language encoder
- V V V:本文需要训练的 visual encoder,使用 V t V_t Vt 进行初始化,
- 我们的目标是训练一个 visual encoder V V V 类实现对 image region 的编码,并且将这些编码和 language encoder 输出的语言编码对齐
- 为了克服缺少大规模 region 描述的问题,如图 2 底部,作者构建了一个目标词汇池,通过将词汇填入 prompt 来构建 region 的描述,并且借助 teacher encoder V t V_t Vt 来将这些描述和使用图像定位网络得到的图像区域进行对齐
- 通过使用这些创建的 region-text pairs,visual encoder V V V 就需要通过对比学习和词汇整理来学习将这些 pairs 对齐
2.1 Region-based Language-Image Pretraining
1、Visual region representation
可以使用现有的目标定位器(如 RPN)或密集滑动窗口 来进行图像区域的生成
作者使用经过人工标注 bbox 训练过的 RPN 来生成,这里不对 bbox 的类别进行区分
- 对于一个输入 batch,使用 RPN 产生 N 个 image regions
- 使用 visual encoder V V V 进行视觉特征抽取,并使用 RoIAlign 来 pooling,且 V V V 的权重是使用 teacher V t V_t Vt 的来进行初始化的
2、Semantic region representation
一个单个的图像通常会包含丰富的语义信息,多个不同类别的目标,且人工标注这么大规模哦对数据也不太可行
所以,作者首先构建了一个大的词汇池,来尽可能的覆盖所有区域词汇,如图 2 所示,而且建立的词汇池是从文本语料库中解析得来的
有了词汇池后,按照如下的方式来构建每个区域的语义表达:
- 第一步,将 concept 填入 prompt 模版(a photo of a kite)
- 第二步,使用预训练的 language encoder L 来得到语义特征表达
- 最后,使用语义编码就能表达每个区域词汇的特征表达 { l j } j = 1 , . . . , C \{l_j\}_{j=1,...,C} {lj}j=1,...,C
3、visual-semantic alignment for regions
① 如何对齐 region-text pairs:使用 CLIP 来构建伪标签,即使用 teacher model CLIP 预测的得分最大的 concept 作为该区域的描述
-
作者借用 teacher visual encoder 来建立 region-text 之间的关系,这里的 text 表示语义编码,区域 r i r_i ri 的 visual representation v i t v_i^t vit 是从 teacher visual encoder V t V_t Vt 中抽取的
-
然后,计算 v i t v_i^t vit 和 { l j } \{l_j\} {lj} 的匹配得分,得分最高的就和区域进行关联起来,然后就能得到每个区域的伪标签: { v i , l m } \{v_i, l_m\} {vi,lm}
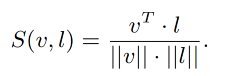
② 如何预训练:
-
同时使用来自网络的 region-text pairs 和 image-text pairs
-
region-text pairs 就是通过 ① 的方法来创建的
-
拿到上述 region-text pairs { v i , l m } \{v_i, l_m\} {vi,lm},使用对比学习 loss 和蒸馏 loss 来训练 visual decoder,总共包含 3 部分
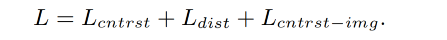
-
region-text 的对比学习 loss 如下, τ \tau τ 是预定义的温度参数, N r i N_{ri} Nri 是 region r i r_i ri 的 negative textual samples,也就是在一个 batch 中和 region r i r_i ri 不匹配但和其他区域匹配的
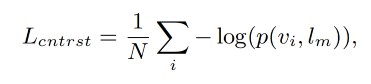
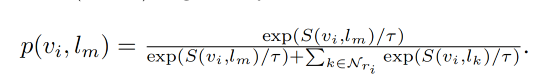
-
除了对比学习 loss 以外,还有考虑每个图像区域的知识蒸馏,蒸馏 loss 如下, q i t q_i^t qit 是从 teacher model 得到的 soft target, q i q_i qi 是 student model 得到的预测
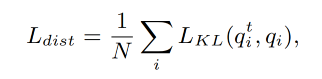
-
image-text 的对比学习 loss L c n t r s t − i m g L_{cntrst-img} Lcntrst−img 可以从 region level 扩展而来,也就是特殊情况,即 ① 一个 box 覆盖了整张图,② 文本描述来源于网络,③ negative samples 是从其他图像而来的文本描述
-
零样本推理
预训练之后,训练得到的 visual encoder 可以直接用于 region reasoning 任务,比如从 RPN 获得区域,从训练的 visual encoder 得到该区域的视觉表达,然后和文本词汇表达进行匹配,得到相似度最高的文本
实验证明使用 RPN score 能够提升 zero-shot 推理的效果,所以作者也使用了 RPN objectness score + category confidence score 的均值来作为最终的得分,用于匹配。
2.2 目标检测的迁移学习
预训练中,本文的 visual encoder 是从 teacher model 提供的 region-text alignment 中学习的,不需要人为一些操作,所以也会有一个噪声,当引入更强的监督信号(如人为标注 label)时,可以进一步 fine-tuning visual encoder,如图 2
如何将预训练网络迁移到目标检测器呢,作者通过初始化目标检测器的 visual backbone 来实现,先使用现有的 RPN 网络来进行目标区域的定位,然后将区域和文本匹配
开放词汇目标检测:
- 对基础类别,使用类似于 focal loss 的加权权重 ( 1 − p b ) γ (1-p^b) \gamma (1−pb)γ, p b p^b pb 是预测的概率, γ \gamma γ 是超参数,该加权权重能缓解模型对预训练中的知识的遗忘,尤其是当数据集中有很少的基础类时(如 coco),作者猜测如果基础类别很少,模型可能会对基础类别过拟合,对新类的泛化能力会降低
- 对背景类别,作者使用固定的 all-zero 编码方式,并且使用预定义的权重
三、效果
3.1 数据集
预训练时,作者使用:
- 来自于 Conceptual Caption dataset (CC3M) 的 image-text pairs,包括 300 万来自网络的 pairs
- COCO Caption(COCO Cap),包含 118k images,每个 images 约有 5 个人工标注的 captions
- 作者从 COCO/CC3M 中抽取了目标词汇,过滤掉了出现频次小于 100 的词汇,得到了 4764/6790 个词汇
为了开放词汇目标检测的迁移学习,作者使用 COCO 数据集和 LVIS 数据集的基础类来训练。
- COCO:48 个基础类,17 个新类
- LVIS:866 个基础类,337 个新类
作者使用目标检测标准测评:AP 和 AP50
- COCO:使用 AP50 测评新类、基础类、所有类
- LVIS:rare 类也就是 novel 类,即测评新类的 AP (APr)、基础类的 AP (APc/APf)、所有类的 AP (mAP)
3.2 实现细节
1、预训练
- teacher model 和 student model :都是预训练的 CLIP(ResNet50)
- RPN:使用 LVIS 的基础类别训练
- 默认模型:使用 CC3M 数据集,使用从 COCO Cap 解析出来的词汇
- 优化器: SGD、batch = 96、learning rate = 0.002, maximum iteration = 600k、 100 regions per image.
2、目标检测迁移
- 使用 detectron2 基于 Faster RCNN [42] with ResNet50-C4 结构作为检测器
- RPN:使用目标数据集的基础类别来训练
- SGD:batch=16,initial learning = 0.002,1x schedule
- focal scaling: γ = 0.5 \gamma=0.5 γ=0.5
3、目标检测零样本推理
- RPN:使用 LVIS 的基础类别训练得到的 RPN
- NMS:threshold=0.9
- τ = 0.01 \tau=0.01 τ=0.01
3.3 结果
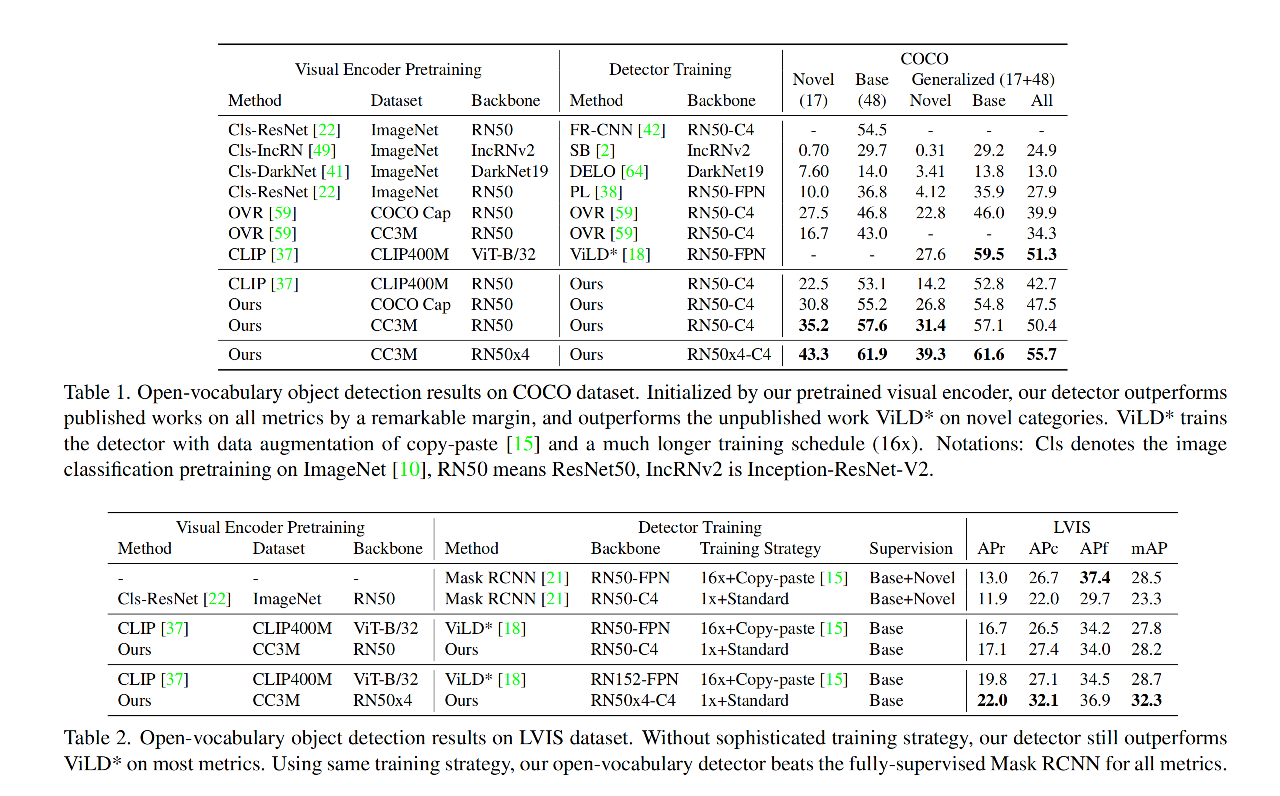
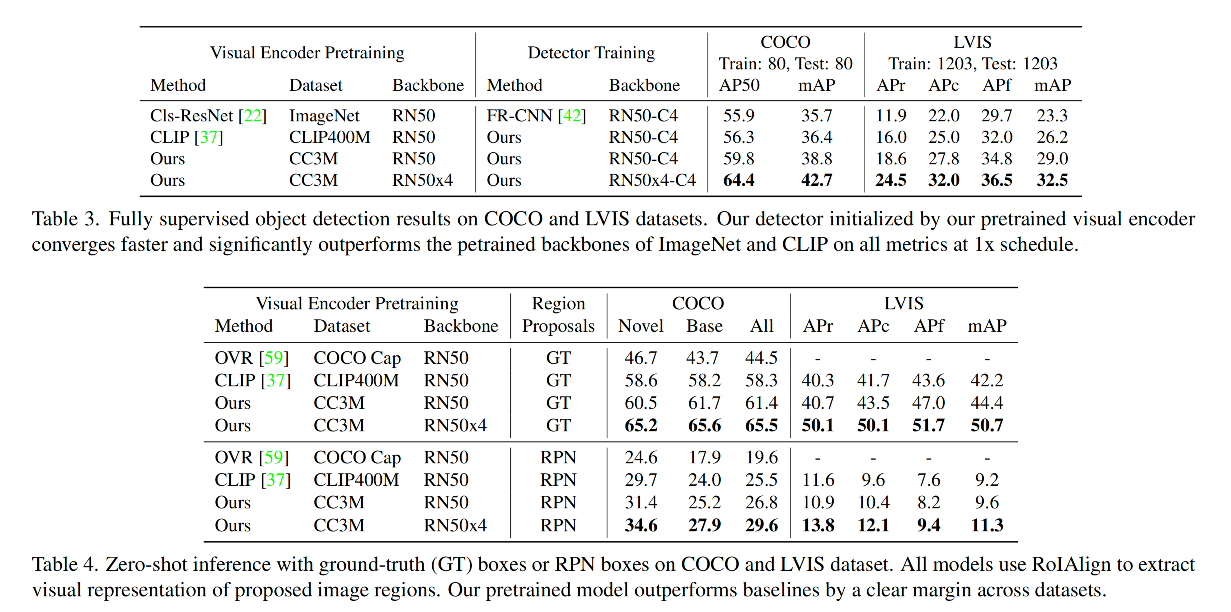

相关文章:
【多模态】19、RegionCLIP | 基于 Region 来实现视觉语言模型预训练
文章目录 一、背景二、方法2.1 Region-based Language-Image Pretraining2.2 目标检测的迁移学习 三、效果3.1 数据集3.2 实现细节3.3 结果 论文: RegionCLIP: Region-based Language-Image Pretraining 代码:https://github.com/microsoft/RegionCLIP …...
本地文件夹上传到Github
本地文件夹上传到Github 步骤1. 下载git步骤2. 在github中新建一个库(Repository)步骤3. 设置SSH key步骤4. 添加SSH keys步骤5. 本地文件上传到github参考 步骤1. 下载git 下载git客户端,并在本地安装完成。 步骤2. 在github中新建一个库&a…...
云原生|kubernetes|kubernetes集群部署神器kubekey安装部署高可用k8s集群(半离线形式)
前言: 云原生|kubernetes|kubernetes集群部署神器kubekey的初步使用(centos7下的kubekey使用)_晚风_END的博客-CSDN博客 前面利用kubekey部署了一个简单的非高可用,etcd单实例的kubernetes集群,经过研究,…...

Vite + Vue3 +TS 项目router配置踩坑记录! ===>“找不到模块“vue-router”或其相应的类型声明。“<===
目录 第一个坑:"找不到模块“vue-router”或其相应的类型声明。" 解决 第二个坑:Cannot read properties of undefined (reading push) 解决:将useRouter()方法的执行位置尽量放靠上一点就行了。 最近在使用vite vue3 types…...
windows安装npm, 命令简介
安装步骤 要在Windows上安装npm,按照以下步骤操作: 首先,确保您已经在计算机上安装了Node.js。可以从Node.js官方网站(Node.js)下载并安装Node.js。完成Node.js的安装后,打开命令提示符(Command…...
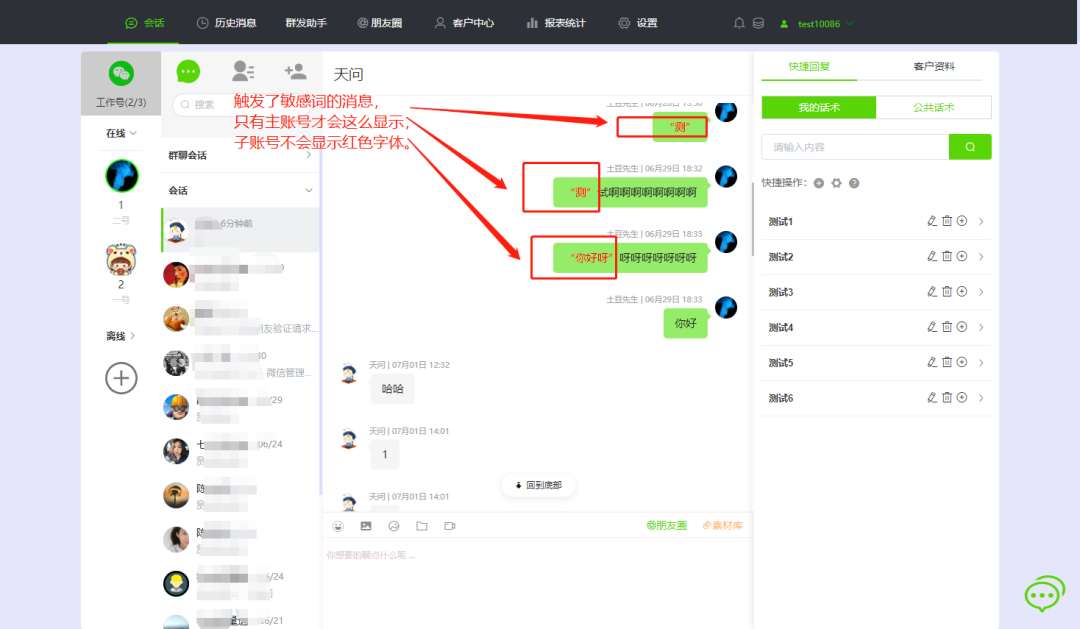
微信聊天记录监管有多重要?
在现代企业中,微信成为了主流的沟通工具。越来越多企业开始关注员工聊天记录的监管问题,因为这直接关系到信息泄露的风险。监管员工聊天记录可以保障公司形象、保护员工的安全,并有助于提高员工的工作效率。 监管员工聊天记录到底有多重要&am…...
【数据结构】实验十:哈夫曼编码
实验十 哈夫曼编码 一、实验目的与要求 1)掌握树、森林与二叉树的转换; 2)掌握哈夫曼树和哈夫曼编码算法的实现; 二、 实验内容 1. 请编程实现如图所示的树转化为二叉树。 2. 编程实现一个哈夫曼编码系统,系统功能…...

Linux-head
Linux命令:head命令详解 概述:head命令用于显示文件文字区块 1、格式 head 【参数】【文件】 2、参数 -q 隐藏文件名 -v 显示文件名 -c<字节> 显示字节数 -n<行数> 显示的行数 [rootwww ~]# head [-n number] 文件 选项与参…...

HHDESK便捷功能介绍三
1 连接便捷显示 工作中,往往需要设置很多资源连接。而过多的连接设,往往很容易混淆。 在HHDESK中,当鼠标点击连接时,会在下方显示本连接的参数,方便用户查看。 2 日志查看 实际工作中,查看日志是一件很…...

小试梯度下降算法
参考资料: 随机梯度下降法_通俗易懂讲解梯度下降法_weixin_39653442的博客-CSDN博客 梯度下降(Gradient Descent)_AI耽误的大厨的博客-CSDN博客 梯度下降法_踢开新世界的大门的博客-CSDN博客 仅做学习笔记 #给定样本求最佳 w 与 b import matplotlib.pyplot as…...
【React】版本正确安装echarts-liquidfill(水球图表)包引入不成功问题
目标效果图: 安装: npm install echarts npm install echarts-liquidfill 引入: Import:import * as echarts from echarts; import echarts-liquidfill 或 import echarts-liquidfill/src/liquidFill.jsOr:import * as echarts from…...
)
Debian 11 编译安装 git 2.42.0(基于 OpenSSL)
git 克隆远程仓库时默认使用 gnutls,正常情况下没有任何问题。当使用 gitlab 时,如果把 gitlab 放在代理后面(如:放在 nginx 后面),则可能会出问题。例如报错:gnutls_handshake() failed: Hands…...

将Linux init进程设置为systemd
在Linux操作系统中,init进程是系统启动的第一个进程。然而,随着系统的发展,新的init进程systemd已经逐渐取代了旧的init进程。如果想要将Linux init进程设置为systemd,可以按照以下步骤操作: 首先,需要检查…...

element-ui form表单的动态rules校验
在vue 项目中,有时候可能会用到element-ui form表单的动态rules校验,比如说选择了哪个选项,然后动态显示或者禁用等等。 我们可以巧妙的运用element-ui form表单里面form-item想的校验规则来处理(每一个form-item项都可以单独校验…...

AGI如何提高智力水平
AGI(Artificial General Intelligence)是一种新型的人工智能系统,具有人类智能的多个方面,能够在各种不同的任务和环境中进行决策和执行。要提高AGI的智力水平,需要从多个方面进行研究和改进。 改进算法和模型&#x…...

【广州华锐互动】无人值守变电站AR虚拟测控平台
无人值守变电站AR虚拟测控平台是一种基于增强现实技术的电力设备巡检系统,它可以利用增强现实技术将虚拟信息叠加在真实场景中,帮助巡检人员更加高效地完成巡检任务。这种系统的出现,不仅提高了巡检效率和准确性,还降低了巡检成本…...
【C语言】文件操作(二)
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

Kotlin小节
1、Kotlin只提供引用类型这一种数据类型。 2、和!的含义 计算两个实例是否指向同一引用 ! 计算两个实例是否不指向同一引用 3、条件表达式给变量赋值 var healthstr if(health 100)"It is excellent" else "It is awful" 4、when表达式 是Kotlin的另…...

西安电子科技大学
前言 本篇文章投稿与以下活动 【西安城市开发者社区】探索西安高校:展现历史与创新的魅力 资料参考与百度百科 学校简介 西安电子科技大学(Xidian University),简称“西电”,位于陕西省西安市,是中央部…...
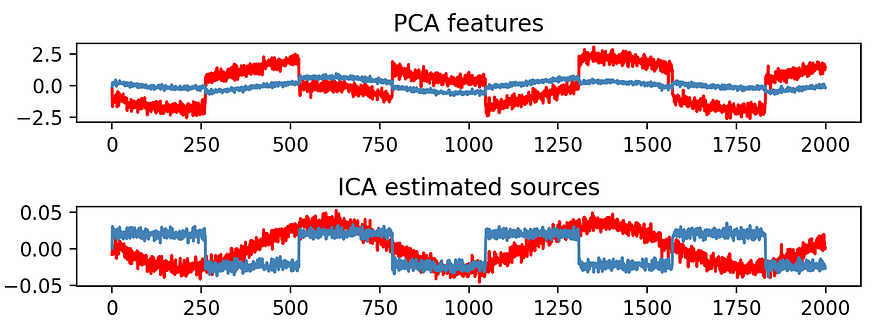
【数据挖掘】PCA/LDA/ICA:A成分分析算法比较
一、说明 在深入研究和比较算法之前,让我们独立回顾一下它们。请注意,本文的目的不是深入解释每种算法,而是比较它们的目标和结果。 如果您想了解更多关于PCA和ZCA之间的区别,请查看我之前基于numpy的帖子: PCA 美白与…...

vLLM-v0.17.1应用场景:智能硬件语音助手离线LLM推理部署
vLLM-v0.17.1应用场景:智能硬件语音助手离线LLM推理部署 1. 技术背景与需求分析 智能硬件语音助手正在经历从云端依赖向本地化处理的转变。传统方案面临三大痛点: 网络延迟问题:云端API调用导致响应速度受限隐私安全顾虑:用户对…...

OpenH264:开源H.264编解码库的技术实现与工程实践
OpenH264:开源H.264编解码库的技术实现与工程实践 【免费下载链接】openh264 Open Source H.264 Codec 项目地址: https://gitcode.com/gh_mirrors/op/openh264 OpenH264作为Cisco维护的开源H.264编解码库,在实时视频通信、流媒体传输和嵌入式设…...

终极指南:OpCore Simplify如何让你零基础打造完美黑苹果系统
终极指南:OpCore Simplify如何让你零基础打造完美黑苹果系统 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore EFI配置…...

大致说一下spring bean的生命周期
面试 1、实例化 Bean 2、给 Bean 属性赋值 3、初始化 Bean 4、使用 Bean 5、销毁 Bean package com.example.demo.bean;import jakarta.annotation.PostConstruct; import jakarta.annotation.PreDestroy; import org.springframework.beans.factory.annotation.Value; import …...
)
flbook电子书下载神器!用这招把网页变PDF(Python+JS双解法)
从网页到PDF:PythonJS双引擎实现FlBook电子书高效归档方案 在数字阅读时代,电子书平台已成为获取知识的重要渠道,但许多优质内容往往缺乏便捷的下载选项。对于技术从业者和数字内容管理者而言,掌握将在线电子书转化为可离线保存的…...
)
从555到正弦波:手把手教你用立创EDA仿真+打样一个2KHz波形发生器(附完整工程)
从555到正弦波:立创EDA全流程打造2KHz波形发生器实战指南 在电子设计领域,波形发生器是最基础却又最考验设计功底的经典项目之一。想象一下,当你亲手设计的电路板输出完美的正弦波时,那种成就感绝非购买现成模块可比。本文将带你用…...

PyTorch 2.8镜像保姆级教程:RTX 4090D下模型量化工具AutoGPTQ实操
PyTorch 2.8镜像保姆级教程:RTX 4090D下模型量化工具AutoGPTQ实操 1. 环境准备与快速部署 在开始使用AutoGPTQ进行模型量化之前,我们需要确保PyTorch 2.8镜像环境已经正确部署。本镜像专为RTX 4090D 24GB显卡优化,预装了CUDA 12.4和所有必要…...

cv_unet_image-colorization模型压缩与量化:面向移动端的部署优化
cv_unet_image-colorization模型压缩与量化:面向移动端的部署优化 想把那个能把黑白照片变彩色的AI模型塞进手机里?这听起来挺酷,但实际操作起来,你会发现它又大又慢,手机根本跑不动。这就像你想把一台高性能游戏电脑…...

STM32 GPIO模式实战:开漏输出与推挽输出的5个常见应用场景解析
STM32 GPIO模式实战:开漏输出与推挽输出的5个常见应用场景解析 在嵌入式开发中,GPIO(通用输入输出)是最基础也是最常用的外设之一。STM32系列微控制器提供了多种GPIO模式,其中开漏输出(Open-Drainÿ…...

基于STM32F103与HAL库的总线舵机多模式运动控制实战
1. STM32F103与HAL库开发环境搭建 第一次接触STM32F103和HAL库的朋友可能会觉得有点懵,其实搭建开发环境比你想象中简单多了。我当初用STM32CubeMX配置项目时踩过不少坑,现在把这些经验都分享给你。 首先得准备好硬件,你需要一块STM32F103开发…...