Tensorflow benchmark 实操指南
环境搭建篇见环境搭建-CentOS7下Nvidia Docker容器基于TensorFlow1.15测试GPU_东方狱兔的博客-CSDN博客
1. 下载Benchmarks源码
从 TensorFlow 的 Github 仓库上下载 TensorFlow Benchmarks,可以通过以下命令来下载
https://github.com/tensorflow/benchmarks
我的 - settings -SSH and GPG Keys 添加公钥id_rsa.pub
拉取代码 git clone git@github.com:tensorflow/benchmarks.git
git同步远程分支到本地,拉取tensorflow对应版本的分支
git fetch origin 远程分支名xxx:本地分支名xxx
使用这种方式会在本地仓库新建分支xxx,但是并不会自动切换到新建的分支xxx,需要手动checkout,当然了远程分支xxx的代码也拉取到了本地分支xxx中。采用这种方法建立的本地分支不会和远程分支建立映射关系
root@818d19092cdc:/gpu/benchmarks# git checkout -b tf1.15 origin/cnn_tf_v1.15_compatible

2. 运行不同模型
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks# pwd
/gpu/benchmarks/scripts/tf_cnn_benchmarks
root@818d19092cdc:/gpu/benchmarks/scripts/tf_cnn_benchmarks# python3 tf_cnn_benchmarks.py
真实操作:
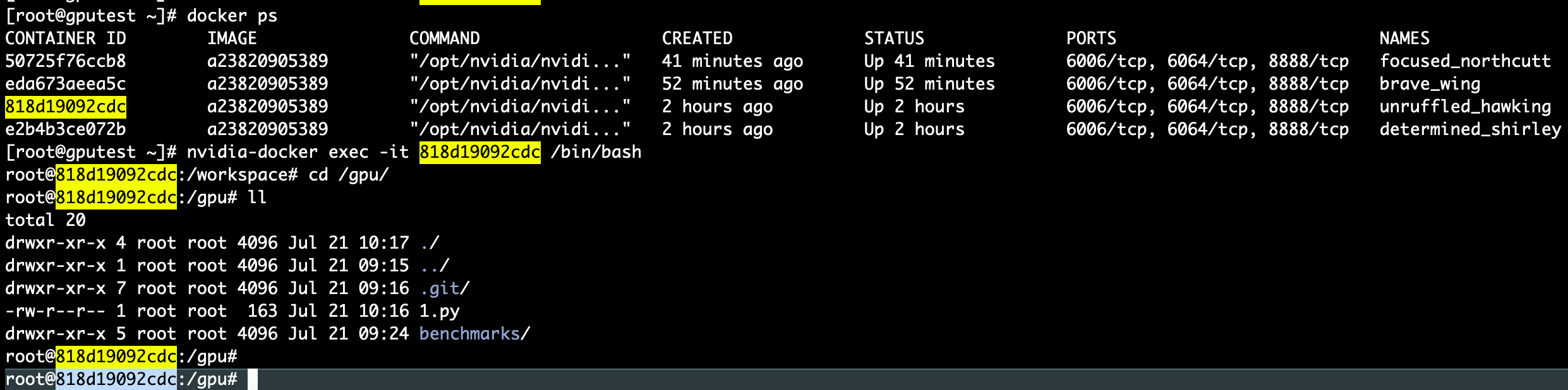
[root@gputest ~]# docker ps
进入CONTAINER ID containerid
[root@gputest ~]# nvidia-docker exec -it 818d19092cdc /bin/bash
新开窗口
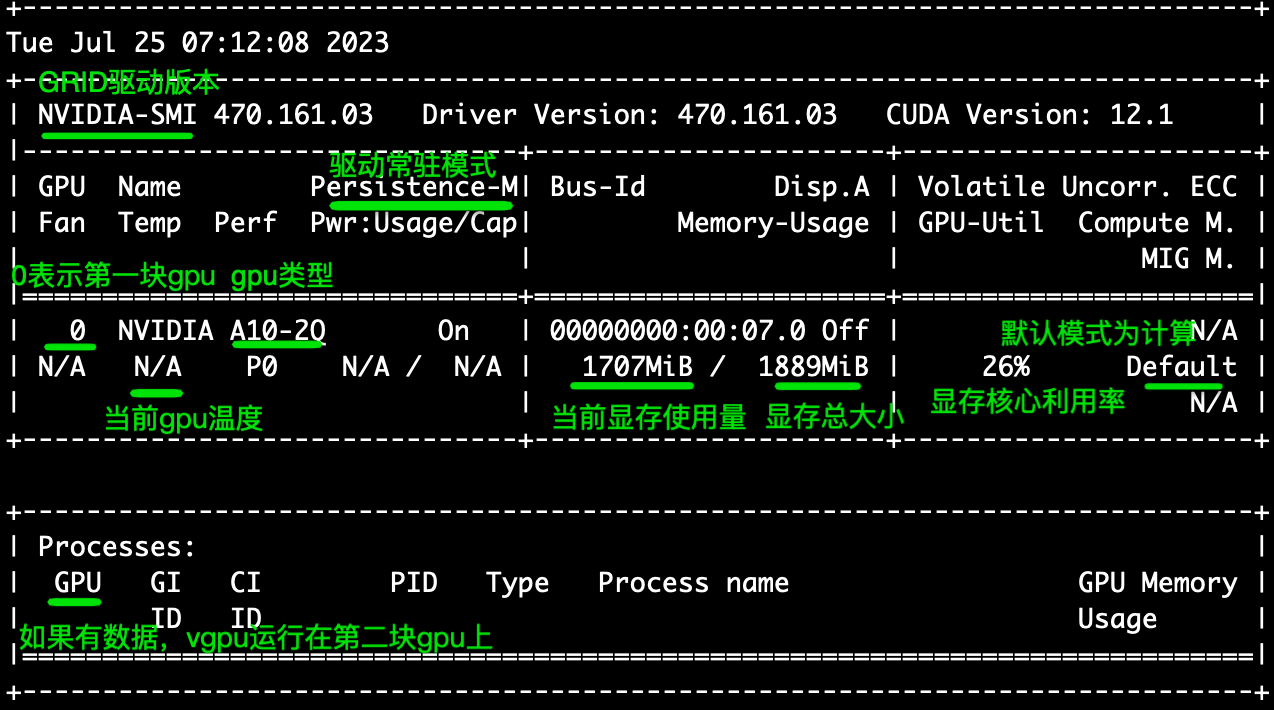
[root@gputest ~]# nvidia-smi -l 3
该命令将3秒钟输出一次GPU的状态和性能,可以通过查看输出结果来得出GPU的性能指标
一、resnet50模型
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2 --model=resnet50 --variable_update=parameter_server
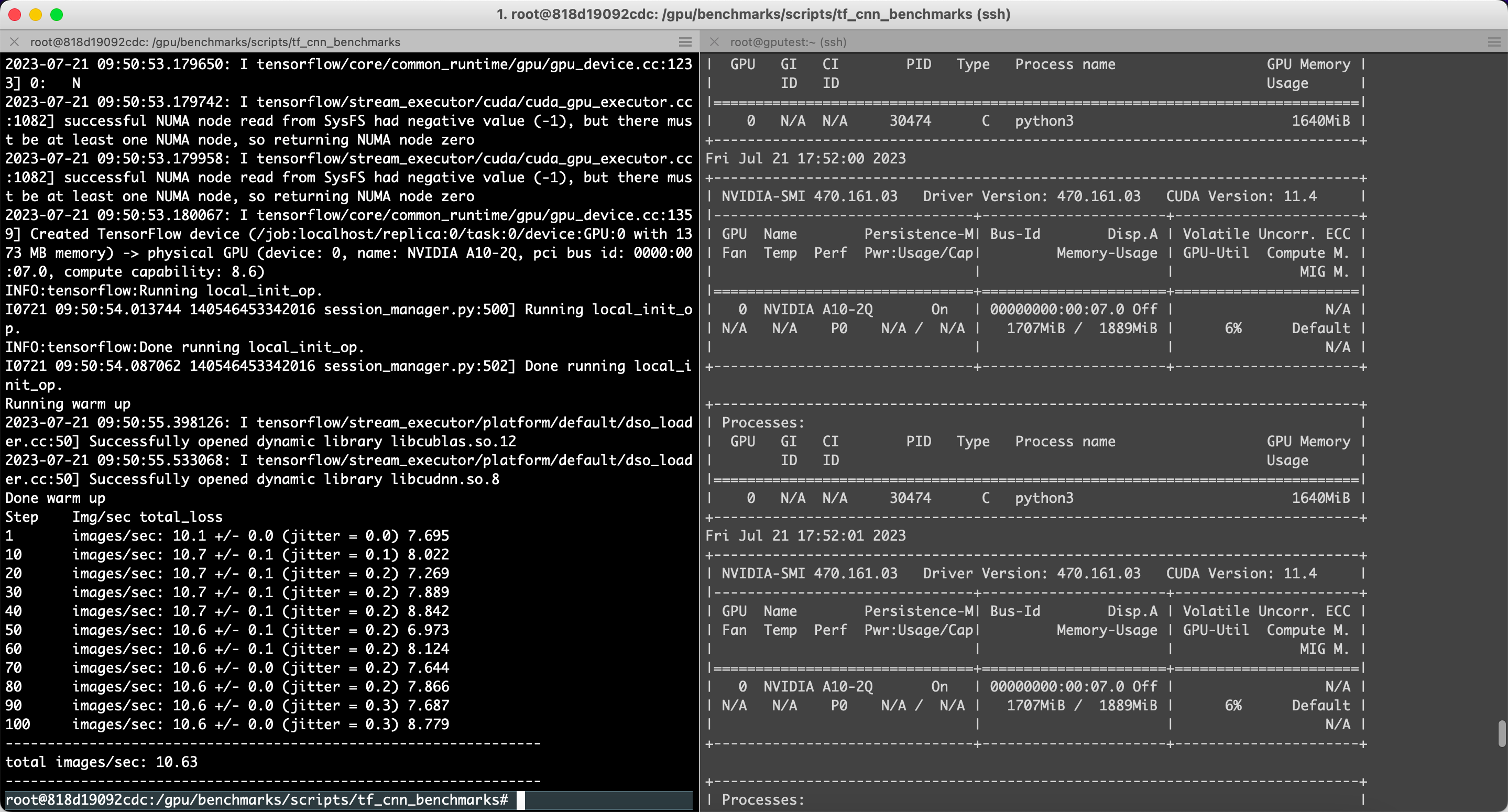
Running warm up
2023-07-21 09:50:55.398126: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcublas.so.12
2023-07-21 09:50:55.533068: I tensorflow/stream_executor/platform/default/dso_loader.cc:50] Successfully opened dynamic library libcudnn.so.8
Done warm up
Step Img/sec total_loss
1 images/sec: 10.1 +/- 0.0 (jitter = 0.0) 7.695
10 images/sec: 10.7 +/- 0.1 (jitter = 0.1) 8.022
20 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.269
30 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 7.889
40 images/sec: 10.7 +/- 0.1 (jitter = 0.2) 8.842
50 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 6.973
60 images/sec: 10.6 +/- 0.1 (jitter = 0.2) 8.124
70 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.644
80 images/sec: 10.6 +/- 0.0 (jitter = 0.2) 7.866
90 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 7.687
100 images/sec: 10.6 +/- 0.0 (jitter = 0.3) 8.779
----------------------------------------------------------------
total images/sec: 10.63
二、vgg16模型
python3 tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2 --model=vgg16 --variable_update=parameter_server

由于阿里云服务器申请的是2个G显存,所以只能跑size=1 2 和 4 ,超出会吐核
已放弃(吐核)--linux 已放弃(吐核) (core dumped) 问题分析
出现这种问题一般是下面这几种情况:
1.内存越界
2.使用了非线程安全的函数
3.全局数据未加锁保护
4.非法指针
5.堆栈溢出
也就是需要检查访问的内存、资源。
可以使用 strace 命令来进行分析
在程序的运行命令前加上 strace,在程序出现:已放弃(吐核),终止运行后,就可以通过 strace 打印在控制台的跟踪信息进行分析和定位问题
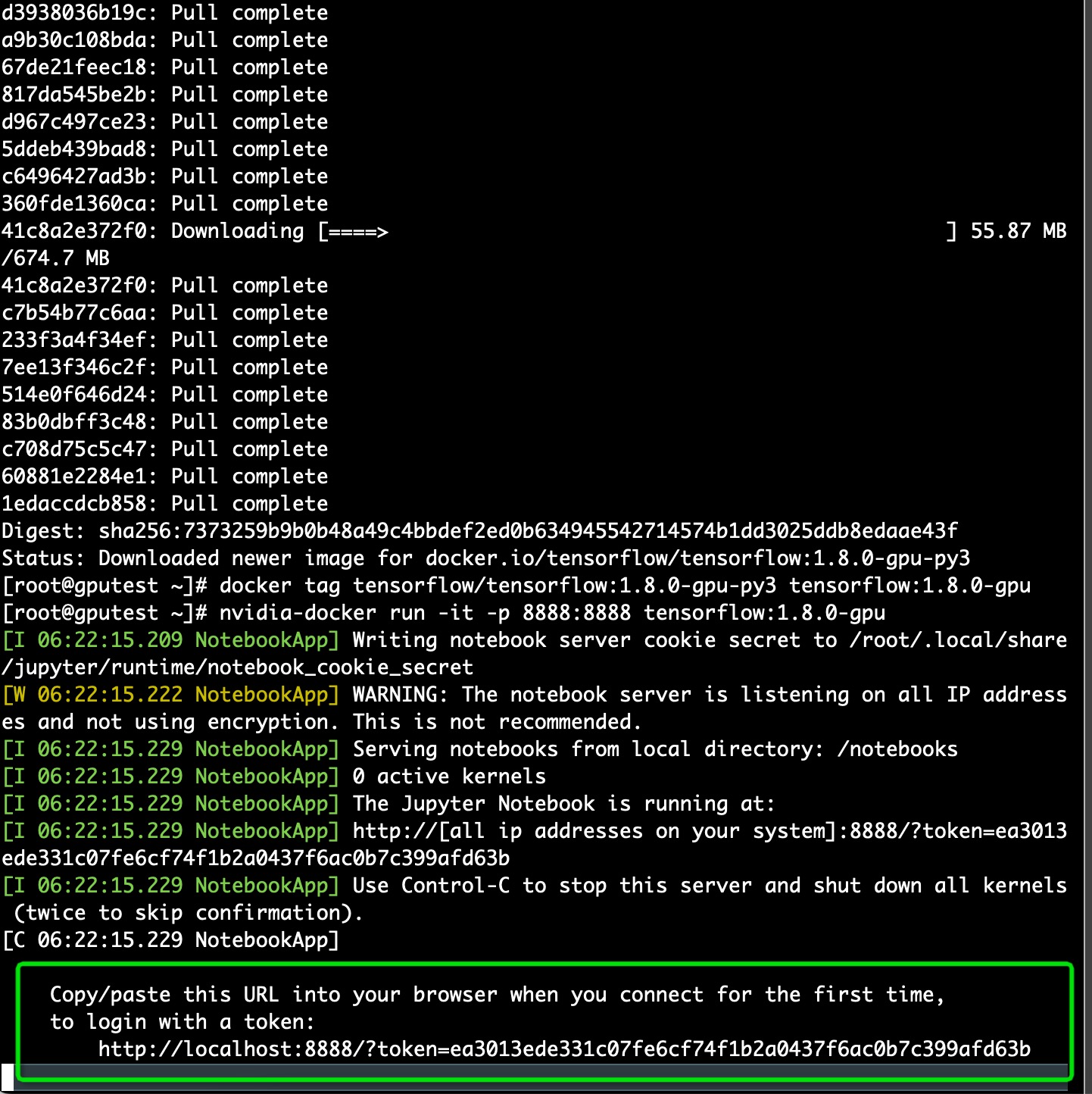
方法2:docker启动普通镜像的Tensorflow
$ docker pull tensorflow/tensorflow:1.8.0-gpu-py3
$ docker tag tensorflow/tensorflow:1.8.0-gpu-py3 tensorflow:1.8.0-gpu
# nvidia-docker run -it -p 8888:8888 tensorflow:1.8.0-gpu
$ nvidia-docker run -it -p 8033:8033 tensorflow:1.8.0-gpu
浏览器进入指定 URL(见启动终端回显) 就可以利用 IPython Notebook 使用 tensorflow
评测指标
-
训练时间:在指定数据集上训练模型达到指定精度目标所需的时间
-
吞吐:单位时间内训练的样本数
-
加速效率:加速比/设备数*100%。其中,加速比定义为多设备吞吐数较单设备的倍数
-
成本:在指定数据集上训练模型达到指定精度目标所需的价格
-
功耗:在指定数据集上训练模型达到指定精度目标所需的功耗
在初版评测指标设计中,我们重点关注训练时间、吞吐和加速效率三项
3. 保存镜像的修改
执行以下命令,保存TensorFlow镜像的修改
docker commit -m "commit docker" CONTAINER_ID nvcr.io/nvidia/tensorflow:18.03-py3
# CONTAINER_ID可通过docker ps命令查看。[root@gputest ~]# docker commit -m "commit docker" 818d19092cdc nvcr.io/nvidia/tensorflow:23.03-tf1-py3
sha256:fc14c7fdf361308817161d5d0cc018832575e7f2def99fe49876d2a41391c52c
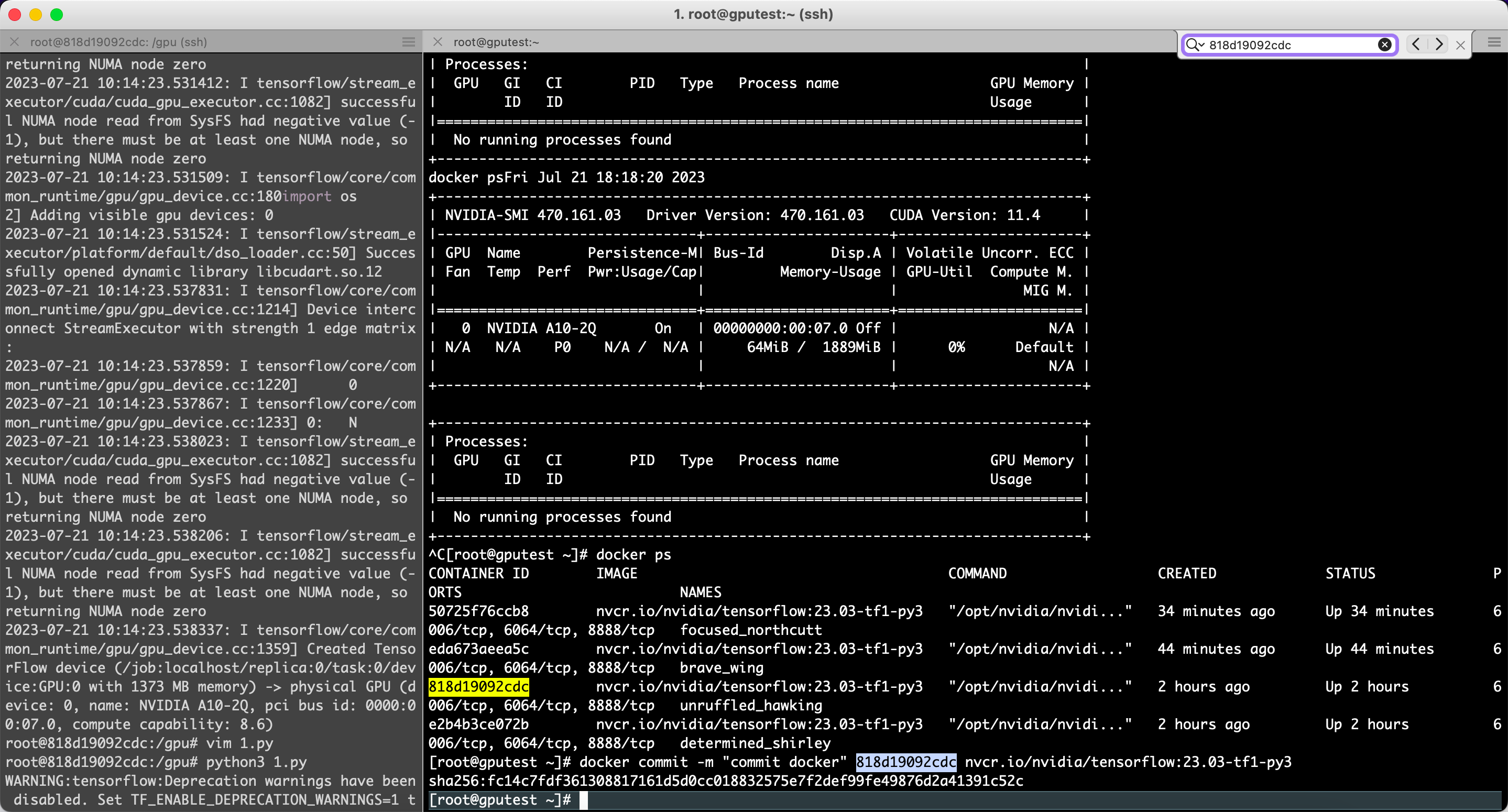
查看docker进程
[root@gputest ~]# docker ps
进入CONTAINER ID containerid
[root@gputest ~]# nvidia-docker exec -it 818d19092cdc /bin/bash
4. TensorFlow支持的所有参数
| 参数名称 | 描述 | 备注 |
| --help | 查看帮助信息 | |
| --backend | 使用的框架名称,如TensorFlow,PyTorch等,必须指定 | 当前只支持TensorFlow,后续会增加对PyTorch的支持 |
| --model | 使用的模型名称,如alexnet、resnet50等,必须指定 | 请查阅所有支持的模型 |
| --batch_size | batch size大小 | 默认值为32 |
| --num_epochs | epoch的数量 | 默认值为1 |
| --num_gpus | 使用的GPU数量。设置为0时,仅使用CPU。
| |
| --data_dir | 输入数据的目录,对于CV任务,当前仅支持ImageNet数据集;如果没有指定,表明使用合成数据 | |
| --do_train | 执行训练过程 | 这三个选项必须指定其中的至少一个,可以同时指定多个选项。 |
| --do_eval | 执行evaluation过程 | |
| --do_predict | 执行预测过程 | |
| --data_format | 使用的数据格式,NCHW或NHWC,默认为NCHW。
| |
| --optimizer | 所使用的优化器,当前支持SGD、Adam和Momentum,默认为SGD | |
| --init_learning_rate | 使用的初始learning rate的值 | |
| --num_epochs_per_decay | learning rate decay的epoch间隔 | 如果设置,这两项必须同时指定 |
| --learning_rate_decay_factor | 每次learning rate执行decay的因子 | |
| --minimum_learning_rate | 最小的learning rate值 | 如果设置,需要同时指定面的两项 |
| --momentum | momentum参数的值 | 用于设置momentum optimizer |
| --adam_beta1 | adam_beta1参数的值 | 用于设置Adam |
| --adam_beta2 | adam_beta2参数的值 | |
| --adam_epsilon | adam_epsilon参数的值 | |
| --use_fp16 | 是否设置tensor的数据类型为float16 | |
| --fp16_vars | 是否将变量的数据类型设置为float16。如果没有设置,变量存储为float32类型,并在使用时转换为fp16格式。 建议:不要设置 | 必须同时设置--use_fp16 |
| --all_reduce_spec | 使用的AllReduce方式 | |
| --save_checkpoints_steps | 间隔多少step存储一次checkpoint | |
| --max_chkpts_to_keep | 保存的checkpoint的最大数量 | |
| --ip_list | 集群中所有机器的IP地址,以逗号分隔 | 用于多机分布式训练 |
| --job_name | 任务名称,如‘ps'、’worker‘ | |
| --job_index | 任务的索引,如0,1等 | |
| --model_dir | checkpoint的存储目录 | |
| --init_checkpoint | 初始模型checkpoint的路径,用于在训练前加载该checkpoint,进行finetune等 | |
| --vocab_file | vocabulary文件 | 用于NLP |
| --max_seq_length | 输入训练的最大长度 | 用于NLP |
| --param_set | 创建和训练模型时使用的参数集。 | 用于Transformer |
| --blue_source | 包含text translate的源文件,用于计算BLEU分数 | |
| --blue_ref | 包含text translate的源文件,用于计算BLEU分数 | |
| --task_name | 任务的名称,如MRPC,CoLA等 | 用于Bert |
| --do_lower_case | 是否为输入文本使用小写 | |
| --train_file | 训练使用的SQuAD文件,如train-v1.1.json | 用于Bert模型,运行SQuAD, --run_squad必须指定 |
| --predict_file | 预测所使用的SQuAD文件,如dev-v1.1.json或test-v1.1.json | |
| --doc_stride | 当将长文档切分为块时,块之间取的间距大小 | |
| --max_query_length | 问题包含的最大token数。当问题长度超过该值时,问题将被截断到这一长度。 | |
| --n_best_size | nbest_predictions.json输出文件中生成的n-best预测的总数 | |
| --max_answer_length | 生成的回答的最大长度 | |
| --version_2_with_negative | 如果为True,表明SQuAD样本中含有没有答案(answer)的问题 | |
| --run_squad | 如果为True,运行SQUAD任务,否则,运行sequence (sequence-pair)分类任务 |
5. GPU机器学习调研tensorflow
如何在tensorflow中指定使用GPU资源
在配置好GPU环境的TensorFlow中 ,如果操作没有明确地指定运行设备,那么TensorFlow会优先选择GPU。在默认情况下,TensorFlow只会将运算优先放到/gpu:0上。如果需要将某些运算放到不同的GPU或者CPU上,就需要通过tf.device来手工指定
import tensorflow as tf# 通过tf.device将运算指定到特定的设备上。
with tf.device('/cpu:0'):a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
with tf.device('/gpu:1'):c = a + bsess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(c)相关文章:
Tensorflow benchmark 实操指南
环境搭建篇见环境搭建-CentOS7下Nvidia Docker容器基于TensorFlow1.15测试GPU_东方狱兔的博客-CSDN博客 1. 下载Benchmarks源码 从 TensorFlow 的 Github 仓库上下载 TensorFlow Benchmarks,可以通过以下命令来下载 https://github.com/tensorflow/benchmarks 我…...

【linux】调试工具介绍
文章目录 前言一、kdb二、ftrace三、gdb 前言 在Linux内核调试过程中,可以使用各种工具和技术来诊断和解决问题。以下是一些常用的Linux内核调试方法: printk:printk是Linux内核中的打印函数,可以在代码中插入打印语句来输出调试…...

2.获取DOM元素
获取DOM元素就是利用JS选择页面中的标签元素 2.1 根据CSS选择器来获取DOM元素(重点) 2.1.1选择匹配的第一个元素 语法: document.querySelector( css选择器 )参数: 包含一个或多个有效的CSS选择器 字符串 返回值: CSS选择器匹配的第一个元素,一个HTMLElement对象…...

flask中redirect、url_for、endpoint介绍
flask中redirect、url_for、endpoint介绍 redirect 在 Flask 中,redirect() 是一个非常有用的函数,可以使服务器发送一个HTTP响应,指示客户端(通常是浏览器)自动导航到新的 URL。基本上,它是用来重定向用…...

《MySQL》第十二篇 数据类型
目录 一. 整数类型二. 浮点类型三. 日期和时间类型四. 字符串类型五. 枚举值类型六. 二进制类型七. 小结 MySQL 支持多种数据类型,学习好数据类型,才能更好的学习 MySQL 表的设计,让表的设计更加合理。 一. 整数类型 类型大小SIGNED(有符号)…...

Python与OpenCV环境中,借助SIFT、单应性、KNN以及Ransac技术进行实现的图像拼接算法详细解析及应用
一、引言 在当今数字化时代,图像处理技术的重要性不言而喻。它在无人驾驶、计算机视觉、人脸识别等领域发挥着关键作用。作为图像处理的一个重要部分,图像拼接算法是实现广阔视野图像的重要手段。今天我们将会讲解在Python和OpenCV环境下,如何使用SIFT、单应性、KNN以及Ran…...

苍穹外卖Day01项目日志
1.软件开发流程和人员分工是怎样的? 软件开发流程 一个软件是怎么被开发出来的? 需求分析 先得知道软件定位人群、用户群体、有什么功能、要实现什么效果等。 需要得到需求规格说明书、产品原型。 需求规格说明书 其中前后端工程师要关注的就是产品原…...
)
Netty学习(二)
文章目录 二. Netty 入门1. 概述1.1 Netty 是什么?1.2 Netty 的作者1.3 Netty 的地位1.4 Netty 的优势 2. Hello World2.1 目标加入依赖 2.2 服务器端2.3 客户端2.4 流程梳理课堂示例服务端客户端 分析提示(重要) 3. 组件3.1 EventLoop事件循…...

ReactRouterv5在BrowserRouter和HashRouter模式下对location.state的支持
结论:HashRouter不支持location.state 文档:ReactRouter v5 从文档可看到history.push()方法支持2个参数:path, [state] state即是location.state,常用于隐式地传递状态参数 但文档未提的是,仅适用于BrowserRouter&am…...
运动设置命令Motion Setup Commands)
Aerotech系列文章(3)运动设置命令Motion Setup Commands
1.运动设置命令Motion Setup Commands 斜坡类型: 直线,S曲线,与正弦曲线 Enumerator: RAMPTYPE_Linear Linear-based ramp type. RAMPTYPE_Scurve S-curve-based ramp type. RAMPTYPE_Sine Sine-based ramp type. 函数原型&a…...

线性神经网络——softmax 回归随笔【深度学习】【PyTorch】【d2l】
文章目录 3.2、softmax 回归3.2.1、softmax运算3.2.2、交叉熵损失函数3.2.3、PyTorch 从零实现 softmax 回归3.2.4、简单实现 softmax 回归 3.2、softmax 回归 3.2.1、softmax运算 softmax 函数是一种常用的激活函数,用于将实数向量转换为概率分布向量。它在多类别…...
【Nodejs】Node.js开发环境安装
1.版本介绍 在命令窗口中输入 node -v 可以查看版本 0.x 完全不技术 ES64.x 部分支持 ES6 特性5.x 部分支持ES6特性(比4.x多些),属于过渡产品,现在来说应该没有什么理由去用这个了6.x 支持98%的 ES6 特性8.x 支持 ES6 特性 2.No…...
简介及Python实现)
梅尔频谱(Mel spectrum)简介及Python实现
梅尔频谱(Mel spectrum)简介及Python实现 1. 梅尔频谱(Mel spectrum)简介2. Python可视化测试3.频谱可视化3.1 Mel 频谱可视化3.2 STFT spectrum参考文献资料1. 梅尔频谱(Mel spectrum)简介 在信号处理上,声信号(噪声信号)是一种重要的传感监测手段。对于语音分类任务…...

【数据结构】实验六:队列
实验六 队列 一、实验目的与要求 1)熟悉C/C语言(或其他编程语言)的集成开发环境; 2)通过本实验加深对队列的理解,熟悉基本操作; 3) 结合具体的问题分析算法时间复杂度。 二、…...

【Linux线程】第一章||理解线程概念+创建一个线程(附代码加讲解)
线程概念 🌵什么是线程🌲线程和进程的关系🎄线程有以下特点:🌳 线程的优点🌴 线程的缺点🌱线程异常🌿线程用途 ☘️手动创建一个进程🍀运行 🌵什么是线程 在L…...

Android进阶之微信扫码登录
遇到新需求要搭建微信扫码登录功能,这篇文章是随着我的编码过程一并写的,希望能够帮助有需求的人和以后再次用到此功能的自己。 首先想到的就是百度各种文章,当然去开发者平台申请AppID和密钥是必不可少的,等注册好发现需要创建应用以及审核(要官网,流程图及其他信息),想着先写…...
macOS Monterey 12.6.8 (21G725) Boot ISO 原版可引导镜像
macOS Monterey 12.6.8 (21G725) Boot ISO 原版可引导镜像 本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Windows 和 Lin…...

Unity自定义后处理——用偏导数求图片颜色边缘
大家好,我是阿赵。 继续介绍屏幕后处理效果的做法。这次介绍一下用偏导数求图形边缘的技术。 一、原理介绍 先来看例子吧。 这个例子看起来好像是要给模型描边。之前其实也介绍过很多描边的方法,比如沿着法线方向放大模型,或者用Ndo…...
本地Git仓库和GitHub仓库SSH传输
SSH创建命令解释 ssh-keygen 用于创建密钥的程序 -m PEM 将密钥的格式设为 PEM -t rsa 要创建的密钥类型,本例中为 RSA 格式 -b 4096 密钥的位数,本例中为 4096 -C “azureusermyserver” 追加到公钥文件末尾以便于识别的注释。 通常以电子邮件地址…...
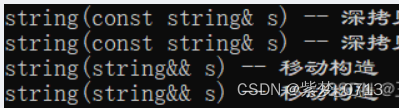
【C++11】——右值引用、移动语义
目录 1. 基本概念 1.1 左值与左值引用 1.2 右值和右值引用 1.3 左值引用与右值引用 2. 右值引用实用场景和意义 2.1 左值引用的使用场景 2.2 左值引用的短板 2.3 右值引用和移动语义 2.3.1 移动构造 2.3.2 移动赋值 2.3.3 编译器做的优化 2.3.4 总结 2.4 右值引用…...

跨平台终端工具cmatrix:打造震撼的数字雨可视化效果
跨平台终端工具cmatrix:打造震撼的数字雨可视化效果 【免费下载链接】cmatrix Terminal based "The Matrix" like implementation 项目地址: https://gitcode.com/gh_mirrors/cm/cmatrix 你是否曾幻想过在自己的终端中重现《黑客帝国》里令人着迷的…...
告别Transformer?手把手复现SegNeXt语义分割模型(附PyTorch代码)
从零实现SegNeXt:用纯卷积架构挑战Transformer的语义分割霸主地位 在计算机视觉领域,语义分割技术正经历着一场静默的革命。当大多数研究者将目光聚焦于Transformer架构时,SegNeXt却用纯粹的卷积神经网络(CNN)设计刷新…...

QLVideo终极指南:让macOS Finder完美预览所有视频格式
QLVideo终极指南:让macOS Finder完美预览所有视频格式 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcod…...
)
新手避坑指南:用MATLAB复现TI IWR1443雷达的距离与速度FFT处理(附完整代码)
新手避坑指南:用MATLAB复现TI IWR1443雷达的距离与速度FFT处理(附完整代码) 第一次拿到IWR1443毫米波雷达开发板时,看着官方文档里密密麻麻的英文术语和零散的代码片段,我对着电脑屏幕发呆了整整半小时。作为电子工程专…...

【信号处理】基于预设性能的无模型自适应分数阶快速终端滑模控制在MIMO非线性系统中的研究附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

vLLM-v0.17.1参数详解:--enforce-eager --disable-custom-all-reduce说明
vLLM-v0.17.1参数详解:--enforce-eager --disable-custom-all-reduce说明 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的吞吐量和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发ÿ…...

NsEmuTools:开源模拟器管理工具的质量保障与工程实践
NsEmuTools:开源模拟器管理工具的质量保障与工程实践 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 在开源项目的生命周期中,如何在快速迭代与代码质量之间找到平…...

JPEXS Free Flash Decompiler社区大使选拔流程:申请与评审完全指南
JPEXS Free Flash Decompiler社区大使选拔流程:申请与评审完全指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的Flash反编译…...

HP-Socket技术演讲视频描述撰写指南:关键词与吸引力
HP-Socket技术演讲视频描述撰写指南:关键词与吸引力 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket是一款高性能跨平台网络通信框架,专为…...
开箱即用)
清音刻墨镜像免配置亮点:内置10+中文领域词典(医疗/法律/IT)开箱即用
清音刻墨镜像免配置亮点:内置10中文领域词典(医疗/法律/IT)开箱即用 1. 为什么字幕对齐需要专业词典? 做视频字幕的朋友都知道,最头疼的不是生成文字,而是让文字和声音完美对齐。普通字幕工具遇到专业术语…...