神经数据库:用于使用 ChatGPT 构建专用 AI 代理的下一代上下文检索系统 — (第 2/3 部分)
书接上回理解构建LLM驱动的聊天机器人时的向量数据库检索的局限性 - (第1/3部分)_阿尔法旺旺的博客-CSDN博客
其中我们强调了(1)嵌入生成,然后(2)使用近似近邻(ANN)搜索进行矢量搜索的解耦架构的缺点。我们讨论了生成式 AI 模型生成的向量嵌入之间的余弦相似性可能不是获取相关内容以进行提示的正确指标。我们还强调,在生产环境中,通过向量数据库存储、更新和维护嵌入非常昂贵。
在这篇文章中,我们将讨论使用学习索引的现代神经数据库学习如何缓解在嵌入和搜索相关的大多数问题方面提供对矢量数据库的重大升级。最后,我们将简要介绍我们正在构建的用于解决ThirdAI这些问题的神经数据库技术,我们将在下一篇文章中深入探讨。
维护、存储和搜索嵌入的痛点
为了说明工程挑战,让我们考虑使用 Pubmed 35M 数据集构建 AI 代理的示例,这是一个符合行业标准的小型存储库。该数据集由大约 35 万个摘要组成,转化为大约 100 万个块,需要 100 万个嵌入。假设每个区块平均有 250 个代币,我们做出以下观察:
- 嵌入是非常重的对象:像 Ada-02 这样更简单的 OpenAI 模型为每个文本块生成大约 1500 维的嵌入。文本块约为 250 个标记(每个标记平均 4 个字符)。存储 100 万个 Pubmed 块大约需要 600GB 来存储嵌入。相比之下,未压缩的原始文本的完整数据只有200GB。更精确的LLM模型的嵌入维度超过12000,这将需要大约5.5 TB的存储空间,仅用于处理嵌入向量。
- 具有高维嵌入的近似近邻搜索(ANN)要么慢要么不准确:三十多年来,人们已经认识到,高维近邻搜索,即使是近似形式,从根本上也是困难的。大多数ANN算法,包括流行的基于图形的HNSW,都需要重量级的数据结构管理,以确保可靠的高速搜索。任何ANN专家都知道,搜索的相关性和性能在很大程度上取决于向量嵌入的分布,这使得它非常不可预测。此外,随着嵌入维度的增加,维护ANN、其搜索相关性和延迟可能会面临重大挑战。
- ANN索引的更新和删除存在问题:大多数现代向量数据库和ANN系统都是基于HNSW或其他图遍历算法构建的,其中嵌入向量是节点。由于这些图形索引的构造方式的性质,基于文档内容中的更改更新节点可能是一个非常缓慢的操作,因为它需要更新图形的边缘。出于同样的原因,删除文档也可能很慢。嵌入更新的动态性质甚至会影响检索的整体准确性。因此,对数据库的增量更新非常脆弱。从头开始重建通常成本太高。
- 检索失败很难评估和修复:当给定的文本查询无法检索相关的基础上下文,而是提供不相关或垃圾文本时,此失败可能有三个原因:a) 数据库中不存在相关的文本块,b) 嵌入质量很差,因此无法使用余弦相似性匹配两个相关文本,c) 嵌入很好, 但由于嵌入的分布,近似近邻算法无法检索到正确的嵌入。虽然原因 (a) 是可以接受的,因为问题似乎与数据集无关,但区分原因 (b) 和 (c) 可能是一个乏味的调试过程。此外,我们无法控制ANN搜索,并且优化嵌入可能无法解决问题。因此,即使在确定问题后,我们也可能无法修复它。
臭名昭著的维度诅咒:大量高维向量的ANN从根本上来说是困难和不可预测的。如果可以的话,避免整个过程。
持续自适应领域特定检索系统:无嵌入神经数据库
事实证明,有一个简单的AI系统可以进行端到端的训练,而无需昂贵,繁重和复杂的高维嵌入。关键概念是完全绕过嵌入过程,将检索问题作为可以端到端学习的神经预测系统来处理。在这种方法中,神经网络用于将给定的查询文本直接映射到相关文本。此过程需要数据结构以提高效率。每年都会在ICML,NeurIPS和ICLR等会议上发表大量论文,探讨这些想法。我们的设计是NeurIPS论文的简化版本,随后的研究在ICLR和KDD上发表。
神经数据库同样也涉及两个阶段,如下所述。
训练和插入(或索引)阶段:系统的前向工作流程如下图所示。
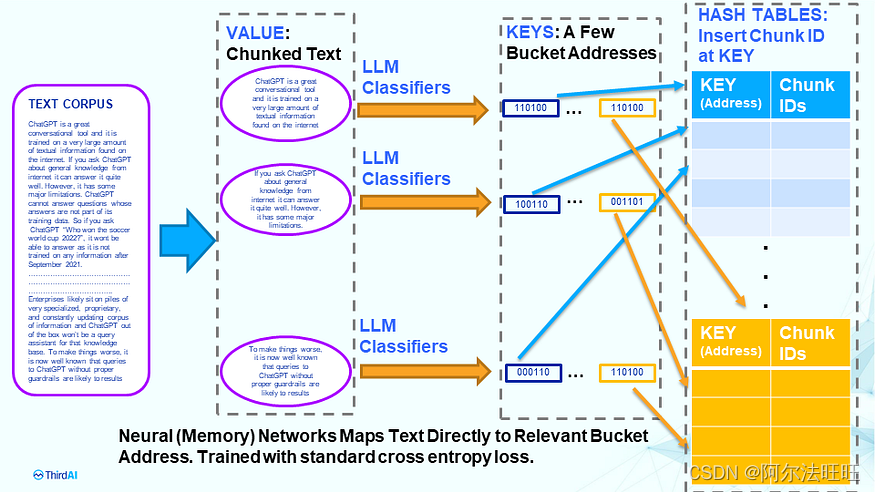
该系统利用强大的大型神经网络生成将文本映射到离散键的内存位置。这些预测键充当存储桶,用于插入和稍后检索相关文本块。从本质上讲,这是一个很好的旧哈希图,其中哈希函数是一个大型神经网络,经过训练来预测指针。为了训练网络,我们需要“语义相关”的文本对和标准的交叉熵损失。有关更多详细信息,请参阅 2019 年 NeurIPS 论文和随后的 KDD 2022 论文中提供的理论和实验比较。从数学上讲,可以证明模型的大小随文本块的数量以对数方式缩放,从而导致运行时间和内存的指数级改进。此方法不需要嵌入管理。
查询或检索阶段: 查询或检索阶段同样简单,如下图所示。
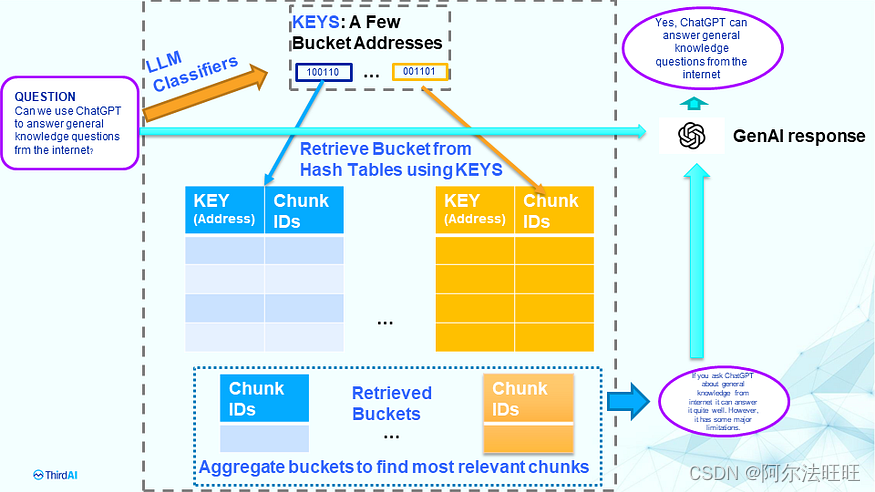
给定一个问题,我们使用经过训练的神经网络分类器来计算排名前几个桶的概率。然后,我们累积与这些顶级存储桶关联的所有 ChunkID。然后,对与问题相关的顶级存储桶及其相关相关性分数进行聚合和排序,以返回候选文本块的小型排名列表。然后,这些文本块被用作生成 AI 的提示,以生成最终的接地响应。
神经网络数据库相对于嵌入和ANN的主要优势
我们通过相同的Pubmed 35M AI-Agents应用程序来说明神经数据库的优势。
- 没有嵌入导致指数压缩:我们的方法所需的额外内存仅在于存储神经网络的参数。我们发现,一个 25 亿参数的神经网络足以训练和索引完整的 Pubmed 35M 数据集。训练纯粹是自我监督的,因为我们不需要任何标记的样本。即使有所有的开销,我们只有不到 20GB 的存储空间用于完整索引。相比之下,使用矢量数据库存储 1500 维嵌入模型的数量至少为 600GB。这并不奇怪,因为使用嵌入模型,计算和内存随块数线性扩展。相比之下,我们的神经数据库仅随块的数量进行对数缩放,正如我们的NeurIPS论文所证明的那样。
- 像管理传统数据库一样管理插入和删除: 与基于图的近邻索引不同,神经数据库具有简单的 KEY、VALUE 类型哈希表,其中插入、删除、并行化、分片等都很简单,而且很容易理解。
- 超快速推理和显著降低成本: 推理延迟仅包括运行神经网络推理,然后是哈希表查找。最后,只有选定的区块只需要对少数候选者进行简单的加权聚合和排序。与嵌入和矢量数据库相比,您可能会看到检索速度快 10-100 倍。此外,借助ThirdAI突破性的稀疏神经网络训练算法,我们可以在普通CPU上训练和部署这些模型。
- 使用持续学习进行增量式的学习索引:可以使用语义含义相似的任何文本对来训练神经索引。这意味着,对专门针对任何理想的任务或领域,检索系统可以不断训练。获取用于训练的文本对并不难。首先,它们可以很容易地以自我监督的方式生成。此外,它们自然可用于任何具有用户交互的生产系统。
ThirdAI的亮点
在本系列的下一篇也是最后一篇博客文章(第 3/3 部分)中,我们将讨论 ThirdAI 的神经数据库生态系统,以及如何通过“动态稀疏性”来驯服像LLM这样的庞然大物,以便在任何数据处理系统中运行,无论是在云上还是在本地。我们还将介绍一组简单的自动调优 Python API。这些 API 使你能够在设备上利用下一代学习索引的强大功能。此外,我们将解释如何使用简单的CPU和几行Python代码创建一个接地气的Pubmed Q&A AI-Agent,同时通过本地环境(不需要互联网)保持隐私。如上一篇文章所示,使用标准的OpenAI嵌入和矢量数据库生态系统构建这样的AI代理通常需要花费数十万美元。您可以使用ThirdAI在您的个人设备上基本上免费获得所有这些。
相关文章:
神经数据库:用于使用 ChatGPT 构建专用 AI 代理的下一代上下文检索系统 — (第 2/3 部分)
书接上回理解构建LLM驱动的聊天机器人时的向量数据库检索的局限性 - (第1/3部分)_阿尔法旺旺的博客-CSDN博客 其中我们强调了(1)嵌入生成,然后(2)使用近似近邻(ANN)搜索…...

一文6个概念从0到1带你成功入门自动化测试【0基础也能看懂系列】
自动化测试有以下几个概念: 单元测试集成测试E2E 测试快照测试测试覆盖率TDD 以及 BDD 等 简述 项目开发过程中会有几个经历。 版本发布上线之前,会有好几个小时甚至是更长时间对应用进行测试,这个过程非常枯燥而痛苦代码的复杂度达到了一…...
C++OpenCV(5):图像模糊操作(四种滤波方法)
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 🔆 OpenCV项目地址及源代码:点击这里 文章目录 图像模糊操作均值滤波高斯滤波中值滤波双边滤波 图像模糊操作 关于图片的噪声:指的是图片中存在的不必要或者多余的干扰数…...

关于质数筛——数论
埃式筛法 #include <bits/stdc.h> using namespace std; bool vis[100000010]; //标记数组 int n; int main(){scanf("%d",&n);vis[0]vis[1]1;for(int i2;i*i<n;i){ //优化1 if(vis[i]!1){for(int ji*i;j<n;ji){ //优化2 vis[j]1; //0是质数&#…...

Spring Boot 应用程序生命周期扩展点妙用
文章目录 前言1. 应用程序生命周期扩展点2. 使用场景示例2.1 SpringApplicationRunListener2.2 ApplicationEnvironmentPreparedEvent2.3 ApplicationPreparedEvent2.4 ApplicationStartedEvent2.5 ApplicationReadyEvent2.6 ApplicationFailedEvent2.7 ApplicationRunner 3. 参…...
【Nodejs】操作mongodb数据库
1.简介 Mongoose是一个让我们可以通过Node来操作MongoDB的模块。Mongoose是一个对象文档模型(ODM)库,它对Node原生的MongoDB模块进行了进一步的优化封装,并提供了更多的功能。在大多数情况下,它被用来把结构化的模式应用到一个MongoDB集合,并…...
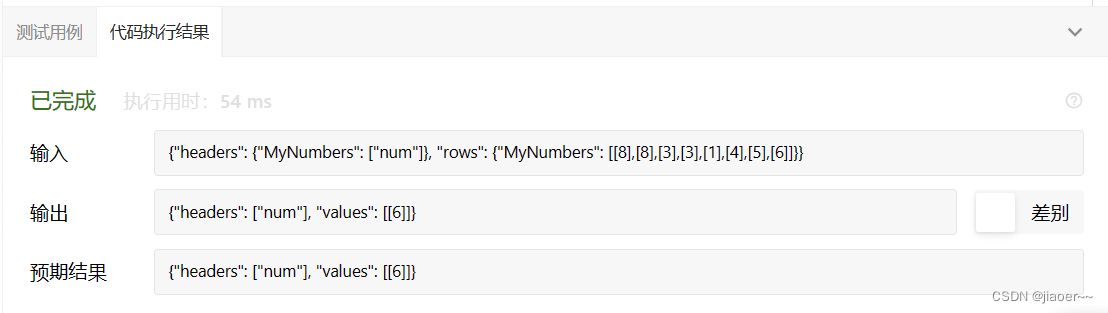
SQL-每日一题【619.只出现一次的最大数字】
题目 MyNumbers 表: 单一数字 是在 MyNumbers 表中只出现一次的数字。 请你编写一个 SQL 查询来报告最大的 单一数字 。如果不存在 单一数字 ,查询需报告 null 。 查询结果如下例所示。 示例 1: 示例 2: 解题思路 1.题目要求我…...
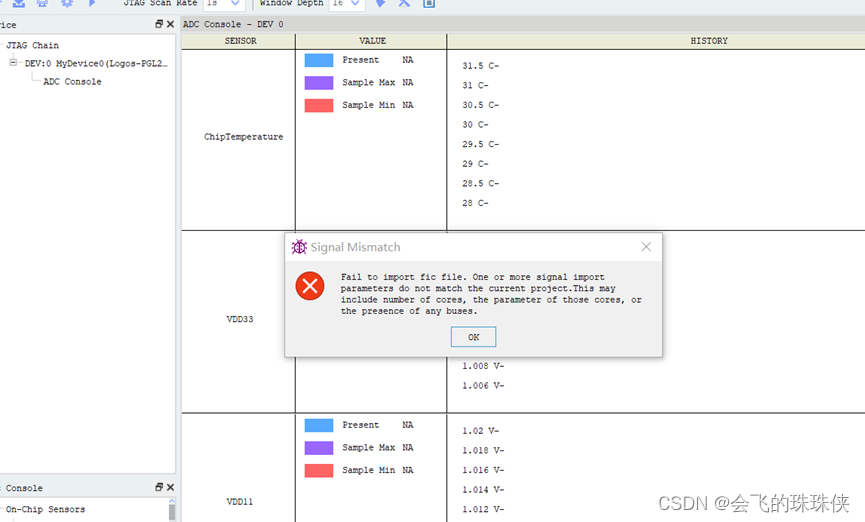
紫光FPGA试用--软件篇
目录 一 软件安装启动 二 如何打开IP核?查看/修改现有IP核参数? 三 如何定义引脚? 四 如何下载code进入FPGA? 1. 下载到FPGA芯片内: 2.下载到外部FLASH中 五 如何进入在线调试模式,调试步骤 操作步骤ÿ…...
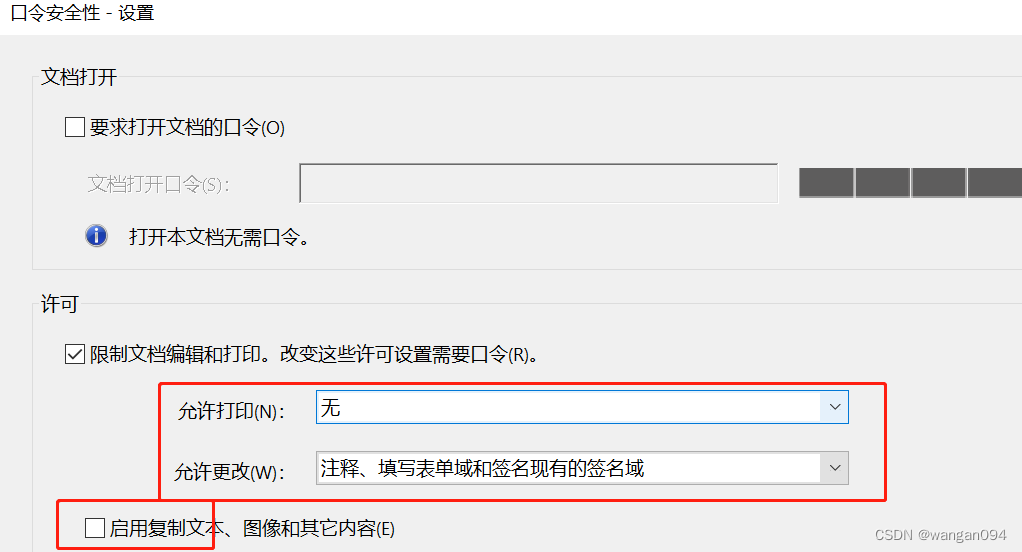
PDF添加水印以及防止被删除、防止编辑与打印
方法记录如下: 1、添加水印; 2、打印输出成一个新的pdf; 3、将pdf页面输出成一张张的图片:(福昕pdf操作步骤如下) 4、将图片组装成一个新的pdf:(福昕pdf操作步骤如下)…...

el-tree转换为表格样式的记录2
上一篇文章记录的是自己将树状数据转换为表格形式。但是出现了一个小bug,点击子节点时候会选中父节点,这个是正常需求没问题。但是我点击父节点时候取消所有子节点,父节点 选择也会失去,这是我不想要执行的。例如一个页面里面有主…...

MS1826B HDMI 1进4出 视频拼接芯片
MS1826B 是一款多功能视频处理器,包含 4 路独立 HDMI 音视频输出通道、1 路 HDMI 音视 频输入通道以及 1 路独立可配置为输入或者输出的 SPDIF、I2S 音频信号。支持 4 个独立的字库定 制型 OSD;可处理隔行和逐行视频或者图形输入信号;有四路独…...

Spring之注解
SpringIOC注解 组件添加标记注解: Component:该注解标记类表示该类为一个普通类,表示为IOC中的一个组件bean Repository:该注解用于将数据访问层(Dao层)的类标识为Spring中的Bean Service&…...

【UniApp开发小程序】悬浮按钮+出售闲置商品+商品分类选择【基于若依管理系统开发】
文章目录 界面效果界面实现悬浮按钮实现商品分类选择界面使元素均匀分布 闲置商品描述信息填写界面价格校验 界面效果 【悬浮按钮】 【闲置商品描述信息填写界面】 【商品分类选择界面】 【分类选择完成】 界面实现 悬浮按钮实现 悬浮按钮漂浮于页面之上,等页面…...
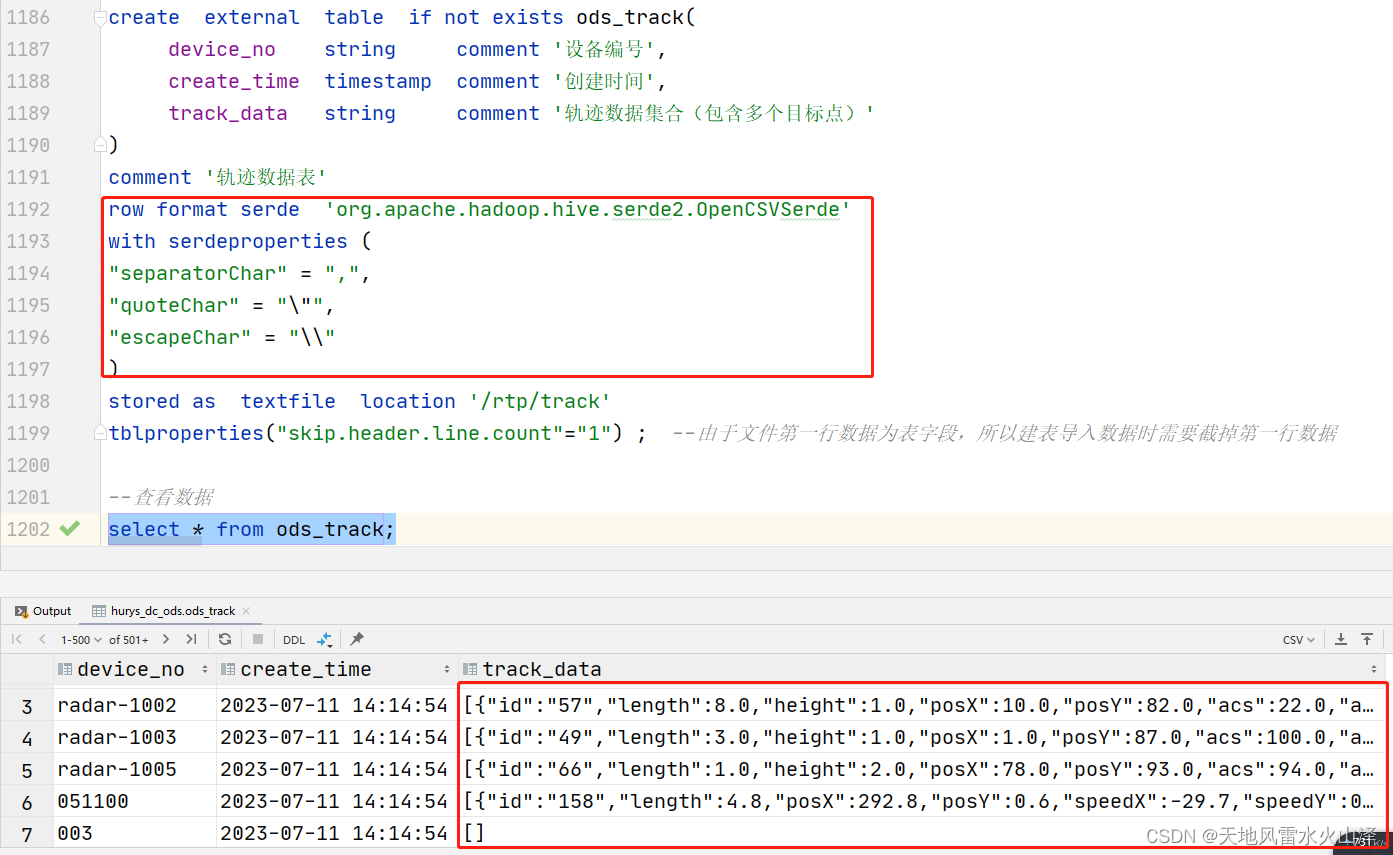
一百三十三、Hive——Hive外部表加载含有JSON格式字段的CSV文件数据
一、目标 在Hive的ODS层建外部表,然后加载HDFS中的CSV文件数据 注意:CSV文件中含有未解析的JSON格式的字段数据,并且JSON字段中还有逗号 二、第一次建外部表,直接以,分隔行字段,结果JSON数据只显示一部分…...
rust gtk 桌面应用 demo
《精通Rust》里介绍了 GTK框架的开发,这篇博客记录并扩展一下。rust 可以用于桌面应用开发,我还挺惊讶的,大学的时候也有学习过 VC,对桌面编程一直都很感兴趣,而且一直有一种妄念,总觉得自己能开发一款很好…...
《嵌入式 - 工具》J-link读写MCU内部Flash
1 J-Link简介 J-Link是SEGGER公司为支持仿真ARM内核芯片推出的JTAG仿真器。配合IAR EWAR,ADS,KEIL,WINARM,RealView等集成开发环境支持所有ARM7/ARM9/ARM11,Cortex M0/M1/M3/M4, Cortex A5/A8/A9等内核芯片的仿真,是学…...

算法练习-LeetCode1071. Greatest Common Divisor of Strings
题目地址:LeetCode - The Worlds Leading Online Programming Learning Platform Description: For two strings s and t, we say "t divides s" if and only if s t ... t (i.e., t is concatenated with itself one or more times). Given two strin…...

Nuget不小心用sudo下载后怎么在user里使用
问题发生 协同开发的过程中,同时在dotnet里面添加了nuget的grpc包,在不清楚的情况下执行自动生成脚本,下载nuget包失败,说是权限不足,于是就使用了sudo进行自动生成,结果在下一次重新打包的过程中ÿ…...

软件测试技能大赛环境搭建及系统部署报告
环境搭建及系统部署报告 环境搭建与配置过程(附图) JDK环境变量配置截图 【截取JDK环境变量配置截图】 查看JDK版本信息截图 【截取使用命令查看JDK版本信息截图,必须截取查看信息成功截图】 root账号成功登录MySQL截图 【截取使用root账…...

浅谈现代通信技术
目录 1.传统通信方法 2.传统通信方式的缺点 3.现代通信技术 4.现代通信技术给人类带来的福利 1.传统通信方法 传统通信方法指的是在数字化通信之前使用的传统的通信方式。以下是一些常见的传统通信方法: 1. 书信:通过邮件或快递等方式发送纸质信件。这…...

容盛兴达丨 32 寸医院自助查询终端机嵌入式触摸查询服务一体机
在数字化浪潮席卷各行各业的今天,医疗机构正经历着从传统服务模式向智慧化、人性化转型的关键时期。医院大厅里,患者及家属常常面临信息获取不便、排队时间长、流程不清晰等困扰。如何利用科技手段优化服务流程、提升患者就医体验,成为医院管…...

顺利毕业!一个能读懂学校要求的AI论文助手
作为一名即将毕业的大四学生,写毕业论文这件事,就像一座大山压在我心头。选题没方向,文献看不懂,最要命的是,学校发的那个十几页的写作要求,看得我头都大了,生怕自己辛辛苦苦写出来,…...
LumiPixel Canvas Quest生成人像的细节优化:高清修复与面部修复技术详解
LumiPixel Canvas Quest生成人像的细节优化:高清修复与面部修复技术详解 1. 为什么需要关注人像生成质量 用AI生成人像时,最让人头疼的就是面部细节问题。你可能遇到过这样的情况:生成的图片整体效果不错,但放大一看,…...

Qwen3.5小尺寸模型开源,9B碾压GPT开源版,消费级显卡就能跑
AI圈又出大新闻了✨ 阿里通义千问3.5系列小尺寸模型正式亮相,直接打破“小模型能力弱”的固有认知,甚至实现了“以小胜大”的逆袭,本地部署门槛直接拉到平民级! 先上核心干货——这次千问3.5一口气推出了4款小尺寸模型,…...

3分钟快速修复机械键盘连击问题:终极解决方案指南
3分钟快速修复机械键盘连击问题:终极解决方案指南 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker KeyboardChatterBlocker是…...

OpenClaw日志分析进阶:百川2-13B-4bits量化模型自动错误诊断
OpenClaw日志分析进阶:百川2-13B-4bits量化模型自动错误诊断 1. 为什么需要自动化日志分析 深夜两点,我的手机突然震动起来——服务器又报警了。强撑着睡意打开终端,面对满屏的报错日志,那种无力感相信每个运维人都深有体会。传…...

3步搞定ERPNext自动化部署:让企业管理系统安装变得简单
3步搞定ERPNext自动化部署:让企业管理系统安装变得简单 【免费下载链接】erpnext_quick_install Unattended install script for ERPNext Versions, 13, 14 and 15 项目地址: https://gitcode.com/gh_mirrors/er/erpnext_quick_install 还在为复杂的ERPNext安…...

uStepper S开源库深度解析:闭环步进控制与TMC2130驱动实战
1. uStepper S 开源驱动库深度解析:面向嵌入式工程师的实战指南 uStepper S 是一款集成了高性能步进电机驱动、高精度磁编码器反馈、ARM Cortex-M0 微控制器(NXP LPC11U35)与丰富外设接口的智能运动控制模块。其配套的 uStepper S Arduino…...

CGAL-6.0.1在Win11与VS2019环境下的高效编译与配置指南
1. 环境准备:搭建Win11VS2019开发环境 在开始编译CGAL-6.0.1之前,我们需要确保开发环境配置正确。我实测发现,Win11系统与VS2019的组合存在一些特殊配置需求,这里分享几个关键检查点: 首先确认VS2019的安装组件。打开V…...

OpenClaw故障排查大全:百川2-13B量化模型接入常见报错解决
OpenClaw故障排查大全:百川2-13B量化模型接入常见报错解决 1. 当网关拒绝启动时 上周深夜调试OpenClaw时,我遇到了最棘手的网关启动失败问题。控制台反复报错Error: listen EADDRINUSE: address already in use :::18789,但用lsof -i :1878…...