【Hive实战】Hive的压缩池与锁
文章目录
- Hive的压缩池
- 池的分配策略
- 自动分配
- 手动分配
- 隐式分配
- 池的等待超时
- Labeled worker pools 标记的工作线程(自定义线程池)
- Default pool 默认池
- Worker allocation 工作线程的分配
- 锁
- Turn Off Concurrency
- Debugging
- Configuration
- hive.support.concurrency
- hive.lock.manager
- hive.lock.mapred.only.operation
- hive.lock.query.string.max.length
- hive.lock.numretries
- hive.unlock.numretries
- hive.lock.sleep.between.retries
- hive.zookeeper.quorum
- hive.zookeeper.client.port
- hive.zookeeper.session.timeout
- hive.zookeeper.namespace
- hive.zookeeper.clean.extra.nodes
- hive.lockmgr.zookeeper.default.partition.name
Hive的压缩池
Compaction pooling
可以将压缩请求和工作线程分配到池中。 分配给特定池的工作线程将仅处理该池中的压缩请求。 没有分配池的工作线程和压缩请求隐式属于默认池。 池概念允许对处理压缩请求进行微调。 例如,可以创建一个名称为“高优先级压缩”的池,为其分配一些经常修改的表,并将一组工作线程专用于该池。 因此,即使默认队列中还有其他几个压缩请求(之前排队),这些表的压缩请求也将立即由专用工作线程获取。
池的分配策略
可以通过三种不同的方式将压缩请求分配给池。
自动分配
可以通过配置数据库、表和分区的属性的方式分配到压缩池:
hive.compactor.worker.pool={pool_name}
数据库/表属性。 如果该属性是在数据库级别设置的,则它适用于所有表和分区。 池也可以在表/分区级别上分配,在这种情况下,它会覆盖数据库级别值(如果设置)。
CREATE TABLE table_name (id int,name string
)
CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true",
);
如果设置了上述任何一项,则发起者在创建压缩请求期间将使用它。
手动分配
ALTER TABLE COMPACT table_name POOL 'pool_name';
还可以使用 ALTER TABLE COMPACT 命令将压缩请求分配给池(例如手动压缩)。 如果提供,该值将覆盖任何级别的 hive.compactor.worker.pool 值。
隐式分配
没有指定池名称的表、分区和手动压缩请求将隐式分配给默认池。
池的等待超时
如果压缩请求在预定义的时间内没有被任何标记池处理,它将回退到默认池。 超时时间可以通过设置
hive.compactor.worker.pool.timeout
配置属性。 该方法涵盖以下场景:
- 请求被意外分配给不存在的池。 (例如:发出 ALTER TABLE COMPACT 命令时池名称中的拼写错误。
- 发起者用来创建压缩请求的数据库或表属性中的拼写错误。
- HS2(HiveServer2) 实例由于缩减或计划而停止,并且仍应处理其挂起的压缩请求。
可以通过将配置属性设置为 0 来禁用超时。
Labeled worker pools 标记的工作线程(自定义线程池)
标记的工作池可以通过以下方式定义
hive.compactor.worker.{poolname}.threads={thread_count}
配置设置
Default pool 默认池
默认池负责处理未标记和超时的压缩请求。 在集群范围内,至少一个节点上的至少 1 个工作线程应分配给默认池,否则可能永远不会处理压缩请求。
Worker allocation 工作线程的分配
已经存在的 hive.compactor.worker.threads 配置值保存最大工作线程数。 工作线程分配如下:
- 标记池以随机顺序按顺序初始化。
- 每个池都会根据自己的工作线程数量减少可用工作线程的数量。
- 如果可分配的worker数量少于配置的数量,则池大小将被调整(换句话说:如果请求的池大小为5,但只剩下3个worker,则池大小将减少到3)。
- 如果可分配的worker数量为0,则池不会被初始化。
- 标记池中未用完的所有剩余工作人员将分配给默认池。
可以为每个 HS2 实例配置工作线程分配。
锁
Locking
并发支持(http://issues.apache.org/jira/browse/HIVE-1293)是数据库中必须的,并且它们的用例很好理解。 至少,我们希望尽可能支持并发读取器和写入器。 添加一种机制来发现当前已获取的锁将很有用。 不需要立即添加 API 来显式获取任何锁,因此所有锁都将隐式获取。
hive 中将定义以下锁定模式(注意不需要意向锁)。
- Shared (S)
- Exclusive (X)
As the name suggests, multiple shared locks can be acquired at the same time, whereas X lock blocks all other locks.
The compatibility matrix is as follows:
顾名思义,可以同时获取多个共享锁,而 X 锁会阻塞所有其他锁。
兼容性矩阵如下:
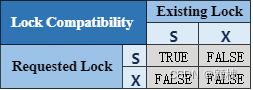
对于某些操作,锁本质上是分层的——例如,对于某些分区操作,表也被锁定(以确保在创建新分区时不能删除表)。
获取锁模式背后的原理如下:
对于非分区表,锁定模式非常直观。 读取表时,会获取 S 锁,而所有其他操作(插入表、更改任何类型的表等)都会获取 X 锁。
对于分区表来说,思路如下:
执行读取时,会获取表和相关分区上的“S”锁。 对于所有其他操作,都会在分区上获取“X”锁。 但是,如果更改仅适用于较新的分区,则在表上获取“S”锁,而如果更改适用于所有分区,则在表上获取“X”锁。 因此,可以读取和写入较旧的分区,同时将较新的分区转换为 RCFile。 每当一个分区被锁定在任何模式下时,其所有父分区都会被锁定在“S”模式下。
基于此,一个操作获取的锁如下:
| Hive Command | Locks Acquired |
|---|---|
| select … T1 partition P1 | S on T1, T1.P1 |
| insert into T2(partition P2) select … T1 partition P1 | S on T2, T1, T1.P1 and X on T2.P2 |
| insert into T2(partition P.Q) select … T1 partition P1 | S on T2, T2.P, T1, T1.P1 and X on T2.P.Q |
| alter table T1 rename T2 | X on T1 |
| alter table T1 add cols | X on T1 |
| alter table T1 replace cols | X on T1 |
| alter table T1 change cols | X on T1 |
| alter table T1 *concatenate* | X on T1 |
| alter table T1 add partition P1 | S on T1, X on T1.P1 |
| alter table T1 drop partition P1 | S on T1, X on T1.P1 |
| alter table T1 touch partition P1 | S on T1, X on T1.P1 |
| alter table T1 set serdeproperties | S on T1 |
| alter table T1 set serializer | S on T1 |
| alter table T1 set file format | S on T1 |
| alter table T1 set tblproperties | X on T1 |
| alter table T1 partition P1 concatenate | X on T1.P1 |
| drop table T1 | X on T1 |
为了避免死锁,这里提出了一个非常简单的方案。 将所有需要锁定的对象按字典顺序排序,并获取所需的模式锁。 请注意,在某些情况下,对象列表可能未知 - 例如,在动态分区的情况下,正在修改的分区列表在编译时未知 - 因此,该列表是保守生成的。 由于分区数量可能未知,因此应该在表或已知的前缀上采用独占锁(但目前不是由于 HIVE-3509 bug)。
将添加两个新的可配置参数来决定锁定的重试次数以及每次重试之间的等待时间。 如果重试次数非常高,可能会导致活锁。 查看 ZooKeeper recipes 以了解如何使用 Zookeeper api 实现读/写锁。 请注意,锁定请求将被拒绝,而不是等待。 现有的锁将被释放,并且在重试间隔后将全部重试。
由于锁的分层性质,上面列出的方法将无法按指定方式工作。
表 T 的“S”锁指定如下:
- 调用create()创建一个路径名为“/warehouse/T/read-”的节点。 这是协议后面使用的锁定节点。 确保设置序列和临时标志。
- 在锁定节点上调用 getChildren( ) 而不设置监视标志。
- 如果有一个子进程的路径名以“write-”开头且序列号比所获得的序列号低,则无法获取锁。 删除第一步创建的节点并返回。
- 否则授予锁定。
表 T 的“X”锁指定如下:
- 调用create()创建一个路径名为“/warehouse/T/write-”的节点。 这是协议后面使用的锁定节点。 确保设置序列和临时标志。
- 在锁定节点上调用 getChildren( ) 而不设置监视标志。
- 如果存在一个路径名以“read-”或“write-”开头且序列号低于所获取序列号的子进程,则无法获取锁。 删除第一步创建的节点并返回。
- 否则授予锁定。
这种模式的写入器或因为读取陷入饥饿状态。如果读取的时间太长,那么写入会陷入饥饿状态。
默认的 Hive 行为不会改变,并且不支持并发。
Turn Off Concurrency
您可以通过将以下变量设置为 false 来关闭并发:hive.support.concurrency。
Debugging
您可以通过发出以下命令来查看表上的锁:
- SHOW LOCKS <TABLE_NAME>;
- SHOW LOCKS <TABLE_NAME> EXTENDED;
- SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>);
- SHOW LOCKS <TABLE_NAME> PARTITION (<PARTITION_DESC>) EXTENDED;
EXPLAIN LOCKS
这对于了解系统将获取哪些锁来运行指定的查询很有用。
EXPLAIN LOCKS UPDATE target SET b = 1 WHERE p IN (SELECT t.q1 FROM source t WHERE t.a1=5)
可以支持JSON输出
EXPLAIN FORMATTED LOCKS <sql>
Configuration
锁的相关配置数据属性 Locking.
hive.support.concurrency
- Default Value:
false - Added In: Hive 0.7.0 with HIVE-1293
Hive 是否支持并发。 ZooKeeper 实例必须启动并运行,默认 Hive 锁管理器才能支持读写锁。
设置为true以支持INSERT … VALUES、UPDATE 和 DELETE 事务(Hive 0.14.0 及更高版本)。 有关打开 Hive 事务所需的参数的完整列表,请参阅 hive.txn.manager。
hive.lock.manager
- Default Value:
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager - Added In: Hive 0.7.0 with HIVE-1293
当 hive.support.concurrency 设置为true时使用的锁管理器。
hive.lock.mapred.only.operation
- Default Value:
false - Added In: Hive 0.8.0
此配置属性用于控制是否仅对需要执行至少一个 Mapred 作业的查询进行锁定
hive.lock.query.string.max.length
- Default Value: 1000000
- Added In: Hive 3.0.0
要存储在锁中的查询字符串的最大长度。 默认值为 1000000,因为 znode 的数据限制为 1MB。
hive.lock.numretries
- Default Value:
100 - Added In: Hive 0.7.0 with HIVE-1293
您想要尝试获取所有锁的总次数。
hive.unlock.numretries
- Default Value:
10 - Added In: Hive 0.8.1
您想要进行一次解锁的总次数。
hive.lock.sleep.between.retries
- Default Value:
60 - Added In: Hive 0.7.0 with HIVE-1293
各种重试之间的睡眠时间(以秒为单位)。
hive.zookeeper.quorum
- Default Value: (empty)
- Added In: Hive 0.7.0 with HIVE-1293
要与之通信的 ZooKeeper 服务器列表。 仅读/写锁需要此操作。
hive.zookeeper.client.port
- Default Value:
- Hive 0.7.0: (empty)
- Hive 0.8.0 and later:
2181(HIVE-2196)
- Added In: Hive 0.7.0 with HIVE-1293
要与之通信的 ZooKeeper 服务器的端口。 仅读/写锁需要此操作。
hive.zookeeper.session.timeout
- Default Value:
- Hive 0.7.0 to 1.1.x:
600000ms - Hive 1.2.0 and later:
1200000ms(HIVE-8890)``
- Hive 0.7.0 to 1.1.x:
- Added In: Hive 0.7.0 with HIVE-1293
ZooKeeper 客户端的会话超时(以毫秒为单位)。 如果在超时时间内未发送心跳,则客户端将断开连接,并且所有锁都会被释放。
hive.zookeeper.namespace
- Default Value:
hive_zookeeper_namespace - Added In: Hive 0.7.0
所有 ZooKeeper 节点均在其下创建的父节点。
hive.zookeeper.clean.extra.nodes
- Default Value:
false - Added In: Hive 0.7.0
在会话结束时清理多余的节点。
hive.lockmgr.zookeeper.default.partition.name
- Default Value:
__HIVE_DEFAULT_ZOOKEEPER_PARTITION__ - Added In: Hive 0.7.0 with HIVE-1293
ZooKeeperHiveLockManager 为 hive 锁管理器 时的默认分区名称。
相关文章:
【Hive实战】Hive的压缩池与锁
文章目录 Hive的压缩池池的分配策略自动分配手动分配隐式分配 池的等待超时Labeled worker pools 标记的工作线程(自定义线程池)Default pool 默认池Worker allocation 工作线程的分配 锁Turn Off ConcurrencyDebuggingConfigurationhive.support.concur…...

【VUE】使用elementUI tree组件根据所选id自动回显
需求如下: 1.点击父级节点 将父级节点下children中所有id放入数组 2.点击父级下的子节点 将点击的子节点放入数组 3.取消选择父节点,将放入数组的所有子节点id删除 4.根据选择的子节点数组,匹配他所属的父节点 <el-tree:data"tre…...
RocketMQ, Dashboard, 控制台安装
文章说明 本文主要说明RocketMQ的控制台(Dashboard)的安装过程。工作中一直用的是别人装好的,这次终于自己亲手装了一遍。 由于每次都要启动三个应用,比较烦,于是我写了一键启动脚本,分享给大家。这个脚本…...

chrome解决http自动跳转https问题
1.地址栏输入: chrome://net-internals/#hsts 2.找到底部Delete domain security policies一栏,输入想处理的域名,点击delete。 3.再次访问http域名不再自动跳转https了。...

FastGithub 下载
Releases dotnetcore/FastGithub GitHub 无需安装,双击UI程序即可运行。...

TSINGSEE青犀视频安防监控管理平台EasyNVR如何配置鉴权?
视频监控汇聚平台EasyNVR是基于RTSP/Onvif协议的视频平台,可支持将接入的视频流进行全平台、全终端的分发,分发的视频流包括RTSP、RTMP、HTTP-FLV、WS-FLV、HLS、WebRTC等格式。为了满足用户的集成与二次开发需求,我们也提供了丰富的API接口供…...
unittest 数据驱动DDT应用
前言 一般进行接口测试时,每个接口的传参都不止一种情况,一般会考虑正向、逆向等多种组合。所以在测试一个接口时通常会编写多条case,而这些case除了传参不同外,其实并没什么区别。 这个时候就可以利用ddt来管理测试数据…...

素数个数——数论
题目描述 求 1,2,⋯,N 中素数的个数。 输入格式 一行一个整数 N。 输出格式 一行一个整数,表示素数的个数。 样例 #1 样例输入 #1 10样例输出 #1 4提示 对于 100% 的数据,1≤1081≤N≤108。 本题时间限制在2秒以内。 因为题目时间限制是2秒,所…...
express编写一个简单的get接口
/01编写get接口.jsconst express require(express) const app express()// 创建路由 const useRouter require(./router/user.js) // 注册路由 app.use(/api,useRouter)app.listen(8080, (req, res) > {console.log(8080监听) }) ./02编写post接口 // 注意:如…...

【力扣刷题C++】环形链表
来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/linked-list-cycle 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。 【题目】给你一个链表的头节点 head ,判断链表中是否有…...
如何用Python统计CSDN质量分
文章目录 CSDN质量分查询selenium爬取博客地址单篇测试批量查询分析 CSDN质量分查询 CSDN对博客有一套分数评价标准,其查询入口在这里:质量分查询,效果大致如下 如果质量分太低,就会在博文的标题下面出现黄底黄字: 这…...
gin框架内容(三)--中间件
gin框架内容(三)--中间件 Gin框架允许开发者在处理请求的过程中,加入用户自己的函数。这个函数就叫中间件,中间件适合处理一些公共的业务逻辑,比如登录认证、权限校验、数据分页、记录日志、耗时统计等 即比如&#x…...

如何在工作中利用Prompt高效使用ChatGPT
导读 AI 不是来替代你的,是来帮助你更好工作。用better prompt使用chatgpt,替换搜索引擎,让你了解如何在工作中利用Prompt高效使用ChatGPT。 01背景 现在 GPT 已经开启了人工智能狂潮,不过是IT圈,还是金融圈。 一开…...
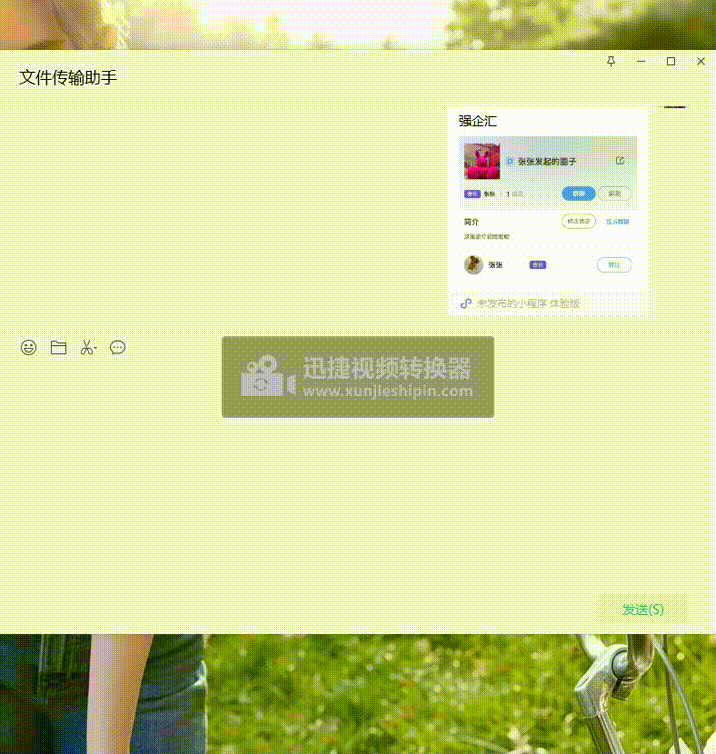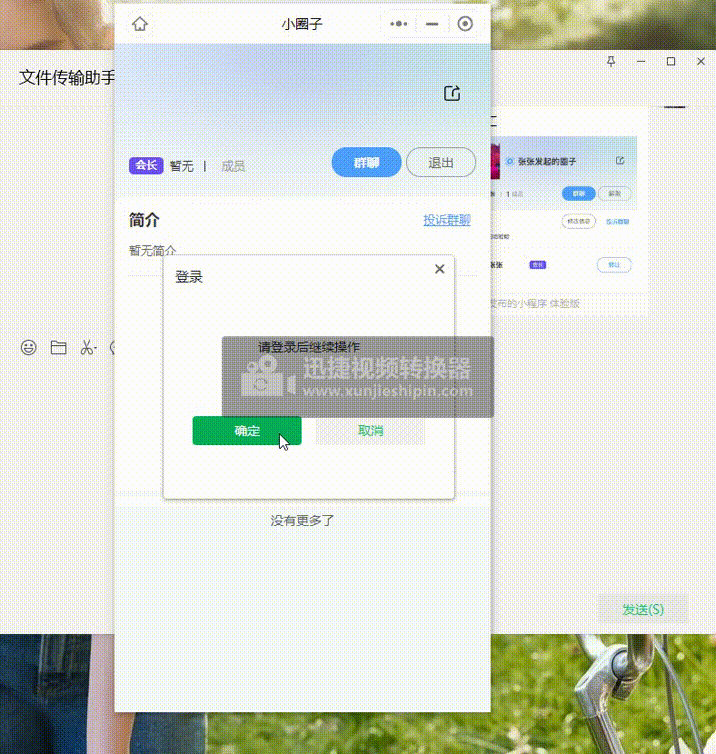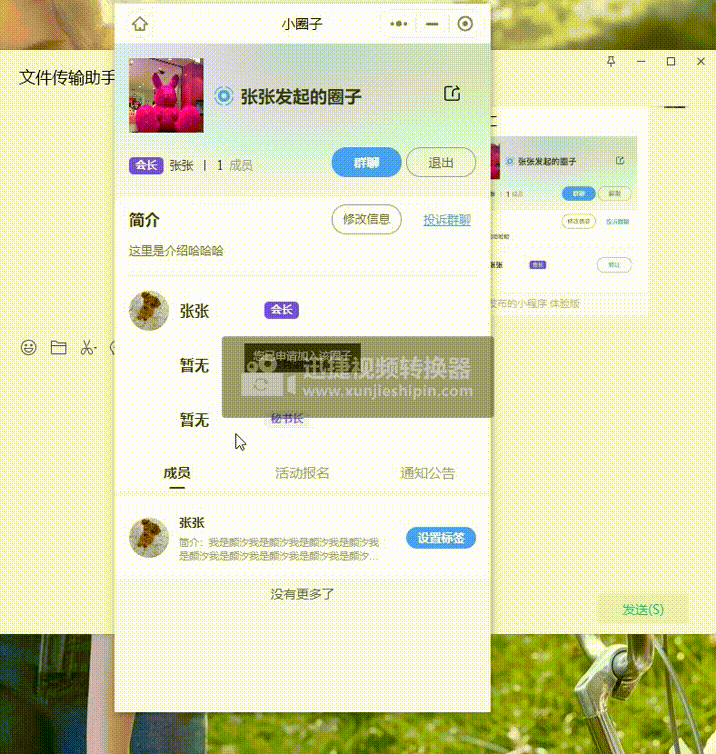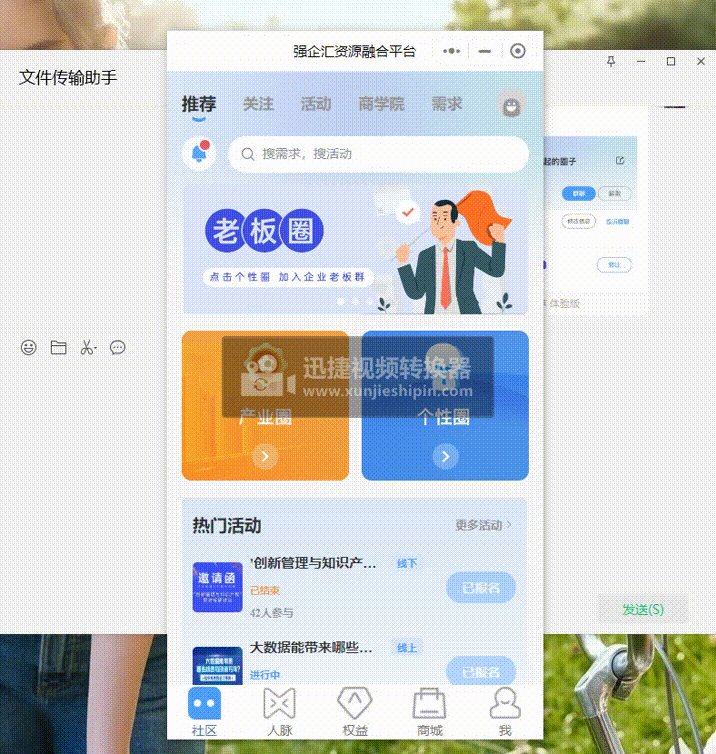
uniapp-小程序button分享传参,当好友通过分享点开该页面时,进行一些判断……
一、需求描述: 该小程序中,点击圈子列表页面—>进入圈子详情页面,在圈子详情页面点击button分享按钮后,发送给好友。当好友通过分享点开该页面时: 1.先判断是否登录,如果没有,先去登录&#…...

Ceph部署方法介绍
Ceph部署方法介绍 Installing Ceph — Ceph Documentation Ceph环境规划 admin是一个部署节点...

GoogleLeNet V2 V3 —— Batch Normalization
文章目录 Batch Normalizationinternal covariate shift激活层的作用BN执行的位置数据白化网络中的BN层训练过程 BN的实验效果MNIST与GoogleLeNet V1比较 GoogleLeNet出来之后,Google在这个基础上又演进了几个版本,一般来说是说有4个版本,之前…...
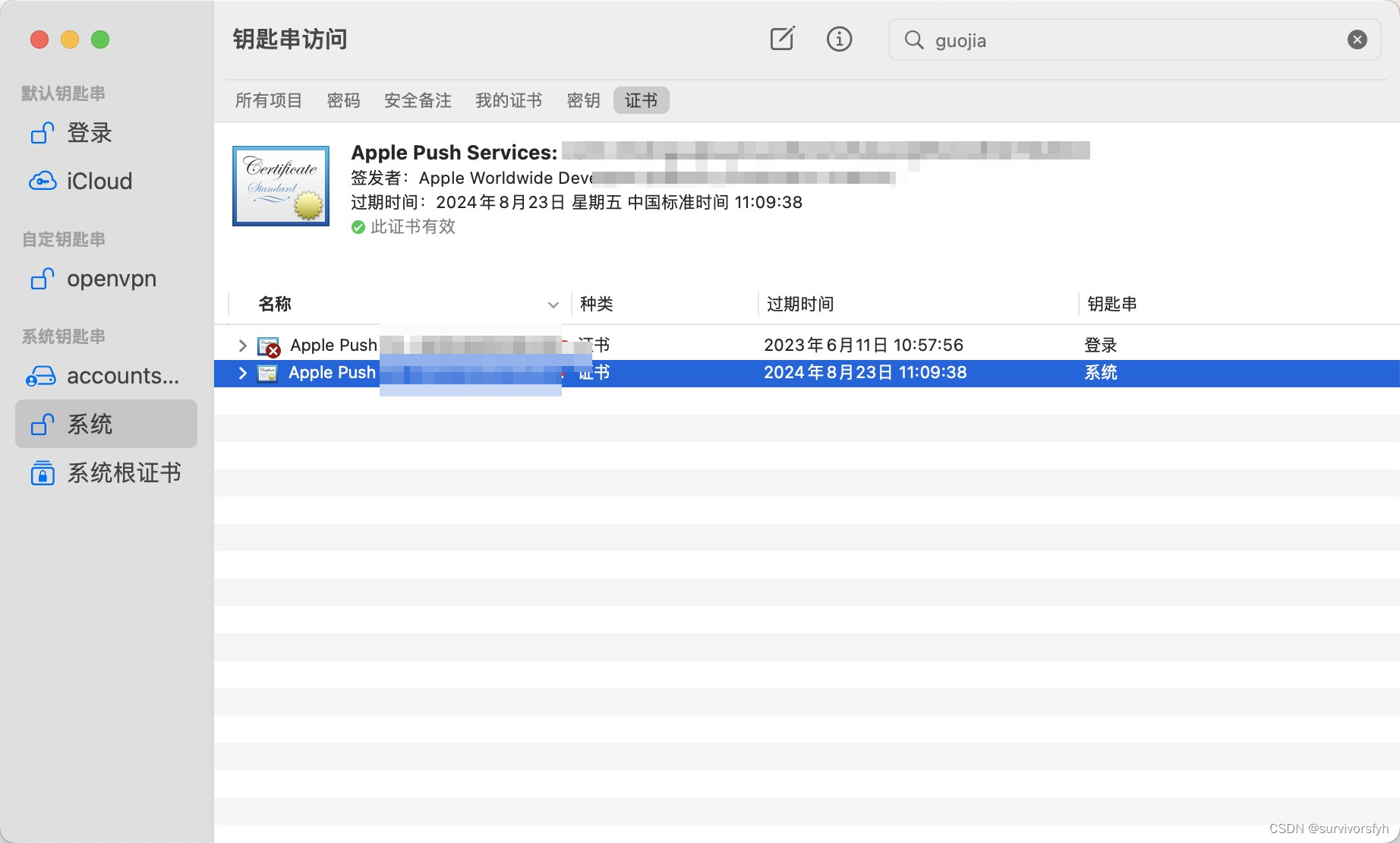
Mac 系统钥匙串证书不受信任
Mac 系统钥匙串证书不受信任 解决办法 通过尝试安装 Apple PKI 的 Worldwide Developer Relations - G4 (Expiring 12/10/2030 00:00:00 UTC) 解决该异常问题 以上便是此次分享的全部内容,希望能对大家有所帮助!...
一个企业级的文件上传组件应该是什么样的
目录 1.最简单的文件上传 2.拖拽粘贴样式优化 3.断点续传秒传进度条 文件切片 计算hash 断点续传秒传(前端) 断点续传秒传(后端) 进度条 4.抽样hash和webWorker 抽样hash(md5) webWorker 时间切片 5.文件类型判断 通过文件头判断文件类型 6.异步并发数控制(重要…...

安全渗透重点内容
this是js中的一个关键字,在不同的场合使用,this的值会发生变化,下面我将详细的介绍this在函数中的各种指向。 在方法中,this表示该方法所属的对象。 如果单独使用,this表示全局对象。 在函数中,this表示全…...
【触觉智能Purple Pi OH开发板体验】开箱体验:开源主板Purple Pi RK3566 上手指北
前言 前段时间收到来自【电子发烧友】的一款开发板,名叫:PurplePi,216G售价仅249元。它使用的芯片是rk3566,适配的OpenHarmony版本为3.2 Release 是目前最便宜的OpenHarmony标准系统开源开发板,并且软硬件全部开源&am…...
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程
GPU算力高效利用:Pixel Language Portal在单卡多实例部署中的资源隔离与负载均衡教程 1. 引言:为什么需要单卡多实例部署 在AI应用开发中,GPU资源往往是稀缺且昂贵的。Pixel Language Portal作为一款基于Tencent Hunyuan-MT-7B的高端翻译工…...

5分钟搞懂线结构光三维重建:从激光平面到深度信息的完整流程
线结构光三维重建:从激光平面到深度信息的实战解析 当你第一次看到激光线扫过物体表面时,可能不会想到这条细细的光线背后隐藏着精确测量物体三维形状的能力。线结构光三维重建技术正悄然改变着工业检测、逆向工程和医疗影像等领域——它不需要接触物体…...
通信的完整流程)
实战避坑:在Windows上用C++/WinRT搞定双模蓝牙(EDR+Ble)通信的完整流程
实战避坑:在Windows上用C/WinRT搞定双模蓝牙(EDRBle)通信的完整流程 蓝牙技术在现代设备中无处不在,但对于开发者而言,实现Windows桌面应用与双模蓝牙设备(同时支持经典蓝牙EDR和低功耗蓝牙BLE)…...

腾讯VersaViT:多模态视觉理解新标杆
腾讯VersaViT:多模态视觉理解新标杆 【免费下载链接】VersaViT 项目地址: https://ai.gitcode.com/tencent_hunyuan/VersaViT 导语:腾讯最新发布的多模态视觉编码器VersaViT,通过创新的多任务协同训练策略,同时强化语言介…...

Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响
Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响 1. 认识Qwen3.5-2B轻量化多模态模型 Qwen3.5-2B是Qwen3.5系列中的轻量级版本,仅有20亿参数规模。这个模型特别适合在资源有限的设备上运行,比如个人电脑、边缘计算设备等。…...

突破三维建模效率瓶颈:Blender对齐工具重新定义精准操作流程
突破三维建模效率瓶颈:Blender对齐工具重新定义精准操作流程 【免费下载链接】quicksnap Blender addon to quickly snap objects/vertices/points to object origins/vertices/points 项目地址: https://gitcode.com/gh_mirrors/qu/quicksnap 在复杂的三维建…...

用STM32F103的TIM3实现旋转编码器方向判断:AB相相位差处理的5个关键细节
STM32F103旋转编码器方向判断实战:TIM3相位差处理的5个核心技巧 旋转编码器作为工业控制和人机交互中广泛使用的传感器,其方向判断的准确性直接影响系统控制的可靠性。本文将深入探讨基于STM32F103的TIM3定时器实现旋转编码器方向判断的关键技术细节&…...

B站成分检测器:3分钟快速识别评论区同好身份
B站成分检测器:3分钟快速识别评论区同好身份 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分油猴脚本,主要为原神玩家识别 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-comment-checker 还在为B站评论区难以分辨用户…...

pdfsizeopt如何实现PDF文件无损压缩?3大行业案例与高级技巧全解析
pdfsizeopt如何实现PDF文件无损压缩?3大行业案例与高级技巧全解析 【免费下载链接】pdfsizeopt PDF file size optimizer 项目地址: https://gitcode.com/gh_mirrors/pd/pdfsizeopt 在数字化办公环境中,PDF文件已成为信息传递的标准格式ÿ…...

4个核心功能实现智能散热:FanControl个性化温控指南
4个核心功能实现智能散热:FanControl个性化温控指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/F…...