GoogleLeNet V2 V3 —— Batch Normalization
文章目录
- Batch Normalization
- internal covariate shift
- 激活层的作用
- BN执行的位置
- 数据白化
- 网络中的BN层
- 训练过程
- BN的实验效果
- MNIST
- 与GoogleLeNet V1比较
GoogleLeNet出来之后,Google在这个基础上又演进了几个版本,一般来说是说有4个版本,之前的那个是V1,然后有一个V2,V3和V4。
其实我个人感觉V2和V3应该是在一起的,都是综合了两篇论文中的一些改进点来的:
- Accelerating deep network training by reducing internal covariate shift
- Rethinking the Inception Architecture for Computer Vision
其中,第一篇是提出了一个重要的概念:Batch Normalization,是针对内部协变量偏移问题的,简单的说就是加速训练过程。把BN作为激活层之前的另外一个网络层,可以加速网络训练的收敛速度。
第二篇就提出了一些新的卷积方法等,然后总和第一篇论文一起就提出了一个inception v2的网络结构,没有明确提到v3,但是其中的一些变形作为了v3版本。
我们就来看一下这两篇论文说了点啥,这个v2和v3又改进了点啥。
Batch Normalization
internal covariate shift
讲BN之前,肯定要说说BN到底是解决一个什么问题,在论文中提到的就是internal covariate shift问题,翻译过来是内部协变量偏移。不明觉厉,这个看不太懂是什么东西。
原文中的描述为:
Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change.
This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities. We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs。
大致意思是在训练的反向传播过程中,每个输入数据的分布情况回发生变化,在计算损失的之后,这一层的输出也会发生变化,从而导致下一层的输入数据分布发生变化。这种情况就叫做内部协变量偏移。
简单点说就是网络的隐藏层数据分布变化很大,容易出现梯度消失和梯度爆炸,导致训练过程很难收敛。一个梯度一下大到天上,一下就等于0,确实很难收敛。
那么BN的基本逻辑就是针对每个训练的batch数据,在每个激活层(Sigmond或者ReLU之类)前增加一个BN层,也就是做一次数据标准化,把上一层的输出线性变化到一个固定的分布内(fixed distribution)
激活层的作用
这里增加一点,就是之前一直没太弄明白激活层的作用。看完这篇论文之后大概了解了。整个网络,中间基本都是卷积和全连接层,不管是卷积还是全连接层,都是针对前一层数据的一种线性变换。也就是前一层数据的一种多项式变化,如果中间没有激活层的话,那么实际上无论增加多少层,都可以简化成一层,因为线性变化是可以叠加的。
举个例子,如果第一层的处理是:
F ( x ) = 2 x + 3 F(x)=2x+3 F(x)=2x+3
第二层的处理是:
H ( x ) = 4 x − 4 H(x)=4x-4 H(x)=4x−4
这里的x就是上一层的 F ( x ) F(x) F(x),所以就是
H ( x ) = 4 ( 2 x + 3 ) − 4 = 8 x − 8 H(x)=4(2x+3)-4=8x-8 H(x)=4(2x+3)−4=8x−8
那么就可以简化成一层。复杂的线性变化也是一样的。但是如果增加了激活层的话,就不一样了,激活层是非线形函数,不满足
f ( x + y ) = f ( x ) + f ( y ) f(x+y)=f(x) + f(y) f(x+y)=f(x)+f(y),所以就不存在上述的变换。
这样就可以增强模型的表达能力(reprensetation power),就是对数据分布的拟合能力。
所以基本上,在网络结构里,每个卷积层后面都会跟一个非线性层(池化或者激活)。
BN执行的位置
论文中的描述是:To Batch-Normalize a network, we specify a subset of activations and insert the BN transform for each of them。
增加在所有的激活层之前。
数据白化
论文中提到:By fixing the distribution of the layer inputs x as the training progresses, we expect to improve the training speed. It has been long known that the network training converges faster if its inputs are whitened, linearly transformed to have zero
means and unit variances, and decorrelated。
这里提到就是利用了LeCun 1998年的论文中提到的,白化(whiten)的输入数据可以加速训练。而这个白化数据就是指数据分布符合均值为0,方差为1。
白化过程为:一个d维的矢量样本( x = ( x ( 1 ) , x ( 2 ) . . . . x ( d ) ) x=(x^{(1)},x^{(2)}....x^{(d)}) x=(x(1),x(2)....x(d)))的白化过程:
x ^ ( k ) = x ( k ) − E [ x ( k ) ] V a r [ x ( k ) ] \hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}} x^(k)=Var[x(k)]x(k)−E[x(k)]
把每一维计算完成之后就形成了服从0-1分布的 x ^ \hat{x} x^向量。
网络中的BN层
在白化之后,实际上还需要做一个线性变换:
y ( k ) = γ ( k ) x ^ ( k ) + β ( k ) y^{(k)}=\gamma^{(k)}\hat{x}^{(k)}+\beta^{(k)} y(k)=γ(k)x^(k)+β(k)
至于为什么要增加这么一个动作,论文中是说:
Note that simply normalizing each input of a layer may change what the layer can represent. For instance, normalizing the inputs of a sigmoid would constrain them to the linear regime of the nonlinearity.
我理解是直接标准化会降低网络的表达能力,可能是直接强行拉到一个0-1的分布,会造成一些损失吧。所以可以做一些拉伸和偏移(正态分布的那个图做一些拉伸和偏移),然后在学习的过程中去动态的调整这两个参数 γ \gamma γ和 β \beta β。也就是学习到底是拉伸多少,偏移多少能更好的拟合数据。
上面的数据白话相当于是把一个样本作了标准化,然后需要把一个训练batch的数据一起做标准化。
论文中是说:since we use mini-batches in stochastic gradient training, of the mean and variance each mini-batch produces estimates of each activation。
也就是说为每个批次也要做一个normalization。
计算方法为:

从上图可以看出来,前面三步就是对数据作了一次白化(类似),只是方向上需要理解一下。
比如输入为一张图像,图像为 p ∗ q p * q p∗q宽,总共有m张图像,那么这里的向量 x x x的长度就是 m m m,也就是沿着图像数的方向。总共有p✖️q个这样的向量。也就是要做p✖️q次normalization计算。
这样就完成了BN层的计算。计算之后相当于这个批次中的图像中的每个像素都是服从同一分布的,但是 γ \gamma γ和 β \beta β不同。
训练过程
以SGD,随机梯度下降的反向传播算法来说:
从输出层开始,计算完loss和随机梯度后,就会向后传播,那么这个BN层也是需要传播的。
通过下图,就可以计算出 γ \gamma γ和 β \beta β每次的更新量 Δ γ \Delta \gamma Δγ和 Δ β \Delta \beta Δβ

整个训练过程为:

针对每一个BN层,通过上述的计算过程进行训练。
BN的实验效果
MNIST
在手写上与最古老的LeNet比较,达到同样的精确度,训练次数大大减少。
与GoogleLeNet V1比较
针对V1做了一些改动
- 增大学习率
- 去掉DropOut
- 去掉LRN
- 重新打乱训练集
- 减少图像的扩展
做了下面几个模型的比对
- 基于上面改动,增加了BN层的基本模型:BN-Baseline
- Baseline的基础上,学习率提升5倍到 0.0075:BN-x5
- 学习率提升30倍到0.045:BN-x30
- 激活层使用Sigmond,5倍学习率的BN-x5-Sigmond
结论是在BN-x5的情况下,达到v1版本的精确率,训练次数最少。
而BN-30可以达到更高的精度,但是训练次数要多一点。
Sigmond根本达不到这个精度,BN更适用于ReLU激活层。
相关文章:
GoogleLeNet V2 V3 —— Batch Normalization
文章目录 Batch Normalizationinternal covariate shift激活层的作用BN执行的位置数据白化网络中的BN层训练过程 BN的实验效果MNIST与GoogleLeNet V1比较 GoogleLeNet出来之后,Google在这个基础上又演进了几个版本,一般来说是说有4个版本,之前…...
Mac 系统钥匙串证书不受信任
Mac 系统钥匙串证书不受信任 解决办法 通过尝试安装 Apple PKI 的 Worldwide Developer Relations - G4 (Expiring 12/10/2030 00:00:00 UTC) 解决该异常问题 以上便是此次分享的全部内容,希望能对大家有所帮助!...
一个企业级的文件上传组件应该是什么样的
目录 1.最简单的文件上传 2.拖拽粘贴样式优化 3.断点续传秒传进度条 文件切片 计算hash 断点续传秒传(前端) 断点续传秒传(后端) 进度条 4.抽样hash和webWorker 抽样hash(md5) webWorker 时间切片 5.文件类型判断 通过文件头判断文件类型 6.异步并发数控制(重要…...

安全渗透重点内容
this是js中的一个关键字,在不同的场合使用,this的值会发生变化,下面我将详细的介绍this在函数中的各种指向。 在方法中,this表示该方法所属的对象。 如果单独使用,this表示全局对象。 在函数中,this表示全…...
【触觉智能Purple Pi OH开发板体验】开箱体验:开源主板Purple Pi RK3566 上手指北
前言 前段时间收到来自【电子发烧友】的一款开发板,名叫:PurplePi,216G售价仅249元。它使用的芯片是rk3566,适配的OpenHarmony版本为3.2 Release 是目前最便宜的OpenHarmony标准系统开源开发板,并且软硬件全部开源&am…...

flink1.16使用消费/生产kafka之DataStream
flink高级版本后,消费kafka数据一种是Datastream 一种之tableApi。 上官网 Kafka | Apache Flink Kafka Source 引入依赖 flink和kafka的连接器,里面内置了kafka-client <dependency><groupId>org.apache.flink</groupId><arti…...

【多任务编程-线程通信】
进程/线程通信的方式 某些应用程序中,进程/进程和线程/线程之间不可避免的进行通信,进行消息传递,数据共享等 同一进程的线程之间通信方式包括Windows中常用Event, Message等。 不同进程之间的通信可以利用Event, FileMapping(内存共享), W…...

K8S暴露pod内多个端口
K8S暴露pod内多个端口 一、背景 公司统一用的某个底包跑jar服务,只暴露了8080端口 二、需求 由于有些服务在启动jar服务后,会启动多个端口,除了8080端口,还有别的端口需要暴露,我这里就还需要暴露9999端口。 注&a…...
Python 列表
""" #list函数 ls list() #创建一个空列表 print(list()) print(list(str(1234)))#[1, 2, 3, 4] print(list(range(5)))#[0, 1, 2, 3, 4] print(list((1,2,3,4)))#[1, 2, 3, 4] print(list(Lift is short, you need python))#注意空格也算一个字符 #[L, i, f,…...
Rabbitmq的安装与使用(Linux版)
目录 Rabbitmq安装 1.在Ubuntu上安装RabbitMQ: 打开终端,运行以下命令以更新软件包列表: 安装RabbitMQ: 安装完成后,RabbitMQ服务会自动启动。你可以使用以下命令来检查RabbitMQ服务状态: 2.在CentOS…...
Kubernetes对象深入学习之四:对象属性编码实战
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是《Kubernetes对象深入学习》系列的第四篇,前面咱们读源码和文档,从理论上学习了kubernetes的对象相关的知识ÿ…...

深度学习入门教程(2):使用预训练模型来文字生成图片TextToImageGenerationWithNetwork
本深度学习入门教程是在polyu HPCStudio 启发以及资源支持下进行的,在此也感谢polyu以及提供支持的老师。 本文内容:在GoogleColab平台上使用预训练模型来文字生成图片Text To Image Generation With Network (1)你会学到什么&a…...
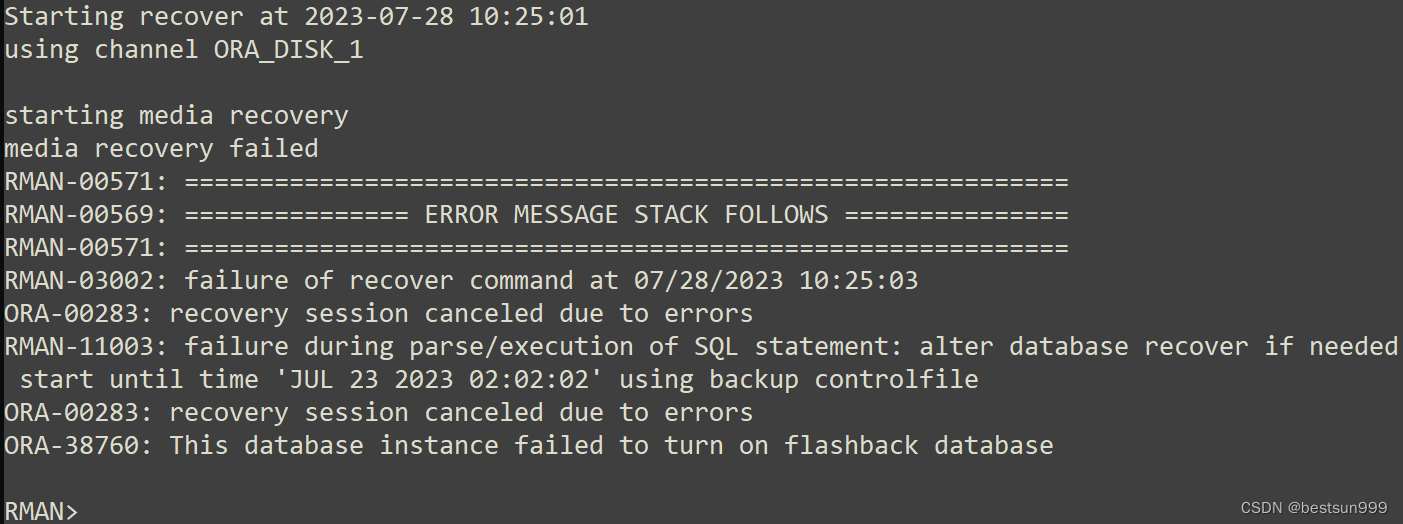
ORA-38760: This database instance failed to turn on flashback database
早晨接一个任务,使用rman备份在虚拟化单机上恢复实例,恢复参数文件、控制文件和数据文件都正常,recover归档时报错如下: Starting recover at 2023-07-28 10:25:01 using channel ORA_DISK_1 starting media recovery media reco…...

避免低级错误:深入解析Java的ConcurrentModificationException异常
在软件开发中,我们常常会遇到各种错误和异常。其中有一类比较低级但又常见的错误就是ConcurrentModificationException异常。最近了我就写了个这种异常,这个异常通常发生在使用迭代器遍历集合时,同时对集合进行修改,从而导致迭代器…...
7.28
1.思维导图 2.qt的sever #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTcpServer> //服务器类 #include<QTcpSocket> //客户端类 #include<QMessageBox> //对话框类 #include<QList> …...
java线程中的常见方法(详解)
方法简介 方法名 功能 说明 start() 启动一个新线程,在新的线程运行 run 方法中的代码 start 方法只是让线程进入就绪,里面代码不一定立刻运行(CPU 的时间片还没分给它)。每个线程对象的start方法只能调用一次,如…...

线程池参数配置
上次面试被人问到,如果是IO 密集型的任务,该如何配置合适的线程数,当初我说要按照IO具体的请求毫秒时间,来配置具体的线程数。 NthreadsNcpu*(1w/c) 公式中 W/C 为系统 阻塞率 w:等待时间 c:计算时间一般情况下,如果存…...

Spread for Winform 16.2.20231.0 (SP2) Crack
Spread for Winform 16.2.20231.0 (SP2)发布。此版本包含针对客户报告的问题的重要修复: 安装版本 16 后,FarPoint.Localization.dll 将丢失。 将数据绑定到 Spread 时会出现 InvalidOperationException。 通过 Spread Designer 设置的上标将不会保留。…...

Go程序结构
Go程序结构 1、名称 名称的开头是一个字母或下划线,且区分大小写。 实体第一个字母的大小写决定其可见性是否跨包: 若名称以大写字母开头,它是导出的,对包外是可见和可访问的,可以被自己包以外的其他程序所引用…...

JAVA面试总结-Redis篇章(四)——双写一致性
JAVA面试总结-Redis篇章(四)——双写一致性 问:redis 做为缓存,mysql的数据如何与redis进行同步呢?第一种情况,如果你的项目一致性要求高的话 采用以下逻辑我们应该先删除缓存,再修改数据库&…...

Ostrakon-VL扫描终端实战教程:像素特工式零售图像识别部署指南
Ostrakon-VL扫描终端实战教程:像素特工式零售图像识别部署指南 1. 像素特工终端介绍 想象你是一位未来世界的零售侦探,手持高科技扫描仪在商店里穿梭。Ostrakon-VL扫描终端就是你的数字助手,它能帮你"看"懂货架上的每一个细节。这…...

别再只改yaml了!深入理解YOLOv5检测头:从P2到P5,如何根据你的目标大小选择最优组合?
深入解析YOLOv5多尺度检测头:从理论到实践的选择艺术 在计算机视觉领域,目标检测一直是核心任务之一。YOLO系列算法以其高效的检测速度和良好的精度表现,成为工业界和学术界的热门选择。然而,很多开发者在使用YOLOv5时,…...

SEO优化建站费用是多少_SEO建站平台有哪些_哪个比较好
SEO优化建站费用是多少?SEO建站平台有哪些?哪个比较好? 在当今数字化时代,建立一个成功的网站不仅仅是创建一个静态的信息展示平台,更是要通过SEO优化提升网站的可见性和流量。SEO优化建站费用是多少呢?SEO…...

Qwen2.5-VL图文助手体验:RTX 4090极速推理,支持对话历史和一键清空
Qwen2.5-VL图文助手体验:RTX 4090极速推理,支持对话历史和一键清空 如果你手头有一张RTX 4090显卡,想找一个能看懂图片、能聊天、还能帮你处理各种视觉任务的本地AI助手,那么今天要聊的这个工具,你可能会很感兴趣。 …...

3步掌控《缺氧》存档:用Oni-Duplicity打造理想殖民地
3步掌控《缺氧》存档:用Oni-Duplicity打造理想殖民地 【免费下载链接】oni-duplicity A web-hosted, locally-running save editor for Oxygen Not Included. 项目地址: https://gitcode.com/gh_mirrors/on/oni-duplicity 你是否曾因《缺氧》中复制人负面特质…...

CTFshow Misc挑战:从WinRAR到明文攻击的实战解析
1. 初识CTFshow Misc挑战:压缩包破解的奥秘 第一次接触CTFshow的Misc题目时,我被那个看似普通的压缩包难住了整整两天。那是个名为6.zip的文件,用360解压提示需要密码,这种场景在CTF比赛中实在太常见了。很多新手遇到这种情况会直…...

CH347的JTAG模式怎么选?实测F/T型号在openFPGALoader下的速度与兼容性差异
CH347F与CH347T JTAG模式深度评测:openFPGALoader下的实战性能差异 当你在淘宝搜索"CH347模块"时,会发现两种主要型号:F型多功能版和T型切换版。价格相差无几,但商家描述往往含糊其辞。作为FPGA开发者,最关…...

ClawdBot代码实例:修改clawdbot.json实现模型热切换实操
ClawdBot代码实例:修改clawdbot.json实现模型热切换实操 1. 引言:你的个人AI助手,想换模型就换模型 想象一下,你有一个24小时在线的AI助手,它能帮你写代码、回答问题、整理文档。但用久了,你可能会想&…...

UEFI SCT编译调试踩坑记:我的AARCH64环境搭建与问题解决实录
UEFI SCT编译调试实战:AARCH64环境搭建与疑难问题全解析 当你在深夜的办公室里盯着屏幕上闪烁的光标,第N次尝试编译UEFI SCT测试套件时,那种既熟悉又陌生的挫败感再次袭来。作为UEFI开发者,我们都经历过这样的时刻——官方文档看似…...

AzurLaneAutoScript:碧蓝航线全自动游戏助手,释放您的双手与时间
AzurLaneAutoScript:碧蓝航线全自动游戏助手,释放您的双手与时间 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAuto…...