flink1.16使用消费/生产kafka之DataStream
flink高级版本后,消费kafka数据一种是Datastream 一种之tableApi。
上官网 Kafka | Apache Flink
Kafka Source
引入依赖 flink和kafka的连接器,里面内置了kafka-client
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.16.2</version>
</dependency>
使用方法
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics("input-topic").setGroupId("my-group").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");很简单一目了然。
topic和partition
多个topic
KafkaSource.builder().setTopics("topic-a", "topic-b");
正则匹配多个topic
KafkaSource.builder().setTopicPattern("topic.*");
指定分区
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);
反序列化
import org.apache.kafka.common.serialization.StringDeserializer;KafkaSource.<String>builder().setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));其实就是实现接口 DeserializationSchema 的deserialize()方法 把byte转为你想要的类型。
起始消费位点
KafkaSource.builder()// 从消费组提交的位点开始消费,不指定位点重置策略.setStartingOffsets(OffsetsInitializer.committedOffsets())// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))// 从最早位点开始消费.setStartingOffsets(OffsetsInitializer.earliest())// 从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest());有界 / 无界模式
Kafka Source 支持流式和批式两种运行模式。默认情况下,KafkaSource 设置为以流模式运行,因此作业永远不会停止,直到 Flink 作业失败或被取消。 可以使用 setBounded(OffsetsInitializer) 指定停止偏移量使 Kafka Source 以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source 会退出运行。
流模式下运行通过使用 setUnbounded(OffsetsInitializer) 也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source 会退出运行。
估计99的人都用不到这个 。也就是设置一个结束的offset的点
其他属性
除了上述属性之外,您还可以使用 setProperties(Properties) 和 setProperty(String, String) 为 Kafka Source 和 Kafka Consumer 设置任意属性。KafkaSource 有以下配置项:
client.id.prefix,指定用于 Kafka Consumer 的客户端 ID 前缀partition.discovery.interval.ms,定义 Kafka Source 检查新分区的时间间隔。 请参阅下面的动态分区检查一节register.consumer.metrics指定是否在 Flink 中注册 Kafka Consumer 的指标commit.offsets.on.checkpoint指定是否在进行 checkpoint 时将消费位点提交至 Kafka broker 这个还是有用的
Kafka consumer 的配置可以参考 Apache Kafka 文档。
请注意,即使指定了以下配置项,构建器也会将其覆盖:
key.deserializer始终设置为 ByteArrayDeserializervalue.deserializer始终设置为 ByteArrayDeserializerauto.offset.reset.strategy被 OffsetsInitializer#getAutoOffsetResetStrategy() 覆盖partition.discovery.interval.ms会在批模式下被覆盖为 -1
动态分区检查
为了在不重启 Flink 作业的情况下处理 Topic 扩容或新建 Topic 等场景,可以将 Kafka Source 配置为在提供的 Topic / Partition 订阅模式下定期检查新分区。要启用动态分区检查,请将 partition.discovery.interval.ms 设置为非负值:
KafkaSource.builder().setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区分区检查功能默认 不开启。需要显式地设置分区检查间隔才能启用此功能。
这个是为了扩容的,因为kafka的消费能力和分区有关,消费能力不够的时候需要动态增加分区
事件时间和水印
默认情况下,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");
消费位点提交
Kafka source 在 checkpoint 完成时提交当前的消费位点 ,以保证 Flink 的 checkpoint 状态和 Kafka broker 上的提交位点一致。如果未开启 checkpoint,Kafka source 依赖于 Kafka consumer 内部的位点定时自动提交逻辑,自动提交功能由 enable.auto.commit 和 auto.commit.interval.ms 两个 Kafka consumer 配置项进行配置。
注意:Kafka source 不依赖于 broker 上提交的位点来恢复失败的作业。提交位点只是为了上报 Kafka consumer 和消费组的消费进度,以在 broker 端进行监控。
这里是说明消费的offset是由kafka管理还是flink管理。
举个例子
.setProperty("enable.auto.commit","true")
.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"100")
并且env没有 env.enableCheckpoint()
此时只要消息进入到flink,过了100ms就会被认为已经消费过了offset会+1 不管你这个消息是否处理完,是否处理失败了。
但是如果你env.enableCheckpoint(),那么此时就是由checkpoint被提交的之前提交offset了。和checkpoint息息相关。checkpoint如果失败了 那么这个offset就不会被提交了。
kafka安全认证
KafkaSource.builder().setProperty("security.protocol", "SASL_PLAINTEXT").setProperty("sasl.mechanism", "PLAIN").setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");上面这个比较常用
另一个更复杂的例子,使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
KafkaSource.builder().setProperty("security.protocol", "SASL_SSL")// SSL 配置// 配置服务端提供的 truststore (CA 证书) 的路径.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks").setProperty("ssl.truststore.password", "test1234")// 如果要求客户端认证,则需要配置 keystore (私钥) 的路径.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks").setProperty("ssl.keystore.password", "test1234")// SASL 配置// 将 SASL 机制配置为 as SCRAM-SHA-256.setProperty("sasl.mechanism", "SCRAM-SHA-256")// 配置 JAAS.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。
Kafka Sink
KafkaSink 可将数据流写入一个或多个 Kafka topic。
使用方法
DataStream<String> stream = ...;KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers(brokers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("topic-name").setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();stream.sinkTo(sink);以下属性在构建 KafkaSink 时是必须指定的:
- Bootstrap servers,
setBootstrapServers(String) - 消息序列化器(Serializer),
setRecordSerializer(KafkaRecordSerializationSchema) - 如果使用
DeliveryGuarantee.EXACTLY_ONCE的语义保证,则需要使用setTransactionalIdPrefix(String)
序列化器
KafkaRecordSerializationSchema.builder().setTopicSelector((element) -> {<your-topic-selection-logic>}).setValueSerializationSchema(new SimpleStringSchema()).setKeySerializationSchema(new SimpleStringSchema()).setPartitioner(new FlinkFixedPartitioner()).build();其中消息体(value)序列化方法和 topic 的选择方法是必须指定的,此外也可以通过 setKafkaKeySerializer(Serializer) 或 setKafkaValueSerializer(Serializer) 来使用 Kafka 提供而非 Flink 提供的序列化器。
容错
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。 以下是对不同语义保证的解释:
一旦启用了基于 Kerberos 的 Flink 安全性后,只需在提供的属性配置中包含以下两个设置(通过传递给内部 Kafka 客户端),即可使用 Flink Kafka Consumer 或 Producer 向 Kafk a进行身份验证:
DeliveryGuarantee.NONE不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。-
启用 Kerberos 身份验证
-
Flink 通过 Kafka 连接器提供了一流的支持,可以对 Kerberos 配置的 Kafka 安装进行身份验证。只需在
flink-conf.yaml中配置 Flink。像这样为 Kafka 启用 Kerberos 身份验证:
1.通过设置以下内容配置 Kerberos 票据 security.kerberos.login.use-ticket-cache:默认情况下,这个值是true,Flink 将尝试在kinit管理的票据缓存中使用 Kerberos 票据。注意!在 YARN 上部署的 Flink jobs 中使用 Kafka 连接器时,使用票据缓存的 Kerberos 授权将不起作用。security.kerberos.login.keytab和security.kerberos.login.principal:要使用 Kerberos keytabs,需为这两个属性设置值。
2。将KafkaClient追加到security.kerberos.login.contexts:这告诉 Flink 将配置的 Kerberos 票据提供给 Kafka 登录上下文以用于 Kafka 身份验证。- 将
security.protocol设置为SASL_PLAINTEXT(默认为NONE):用于与 Kafka broker 进行通信的协议。使用独立 Flink 部署时,也可以使用SASL_SSL;请在此处查看如何为 SSL 配置 Kafka 客户端。 - 将
sasl.kerberos.service.name设置为kafka(默认为kafka):此值应与用于 Kafka broker 配置的sasl.kerberos.service.name相匹配。客户端和服务器配置之间的服务名称不匹配将导致身份验证失败。
问题排查
数据丢失
根据你的 Kafka 配置,即使在 Kafka 确认写入后,你仍然可能会遇到数据丢失。特别要记住在 Kafka 的配置中设置以下属性:
ackslog.flush.interval.messageslog.flush.interval.mslog.flush.*
UnknownTopicOrPartitionException
导致此错误的一个可能原因是正在进行新的 leader 选举,例如在重新启动 Kafka broker 之后或期间。这是一个可重试的异常,因此 Flink job 应该能够重启并恢复正常运行。也可以通过更改 producer 设置中的 retries 属性来规避。但是,这可能会导致重新排序消息,反过来可以通过将 max.in.flight.requests.per.connection 设置为 1 来避免不需要的消息。
ProducerFencedException
这个错误是由于 FlinkKafkaProducer 所生成的 transactional.id 与其他应用所使用的的产生了冲突。多数情况下,由于 FlinkKafkaProducer 产生的 ID 都是以 taskName + "-" + operatorUid 为前缀的,这些产生冲突的应用也是使用了相同 Job Graph 的 Flink Job。 我们可以使用 setTransactionalIdPrefix() 方法来覆盖默认的行为,为每个不同的 Job 分配不同的 transactional.id 前缀来解决这个问题。
相关文章:

flink1.16使用消费/生产kafka之DataStream
flink高级版本后,消费kafka数据一种是Datastream 一种之tableApi。 上官网 Kafka | Apache Flink Kafka Source 引入依赖 flink和kafka的连接器,里面内置了kafka-client <dependency><groupId>org.apache.flink</groupId><arti…...

【多任务编程-线程通信】
进程/线程通信的方式 某些应用程序中,进程/进程和线程/线程之间不可避免的进行通信,进行消息传递,数据共享等 同一进程的线程之间通信方式包括Windows中常用Event, Message等。 不同进程之间的通信可以利用Event, FileMapping(内存共享), W…...

K8S暴露pod内多个端口
K8S暴露pod内多个端口 一、背景 公司统一用的某个底包跑jar服务,只暴露了8080端口 二、需求 由于有些服务在启动jar服务后,会启动多个端口,除了8080端口,还有别的端口需要暴露,我这里就还需要暴露9999端口。 注&a…...
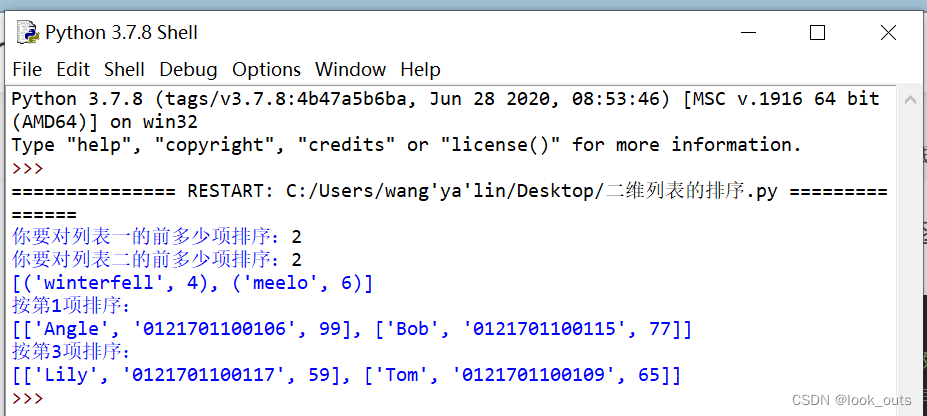
Python 列表
""" #list函数 ls list() #创建一个空列表 print(list()) print(list(str(1234)))#[1, 2, 3, 4] print(list(range(5)))#[0, 1, 2, 3, 4] print(list((1,2,3,4)))#[1, 2, 3, 4] print(list(Lift is short, you need python))#注意空格也算一个字符 #[L, i, f,…...
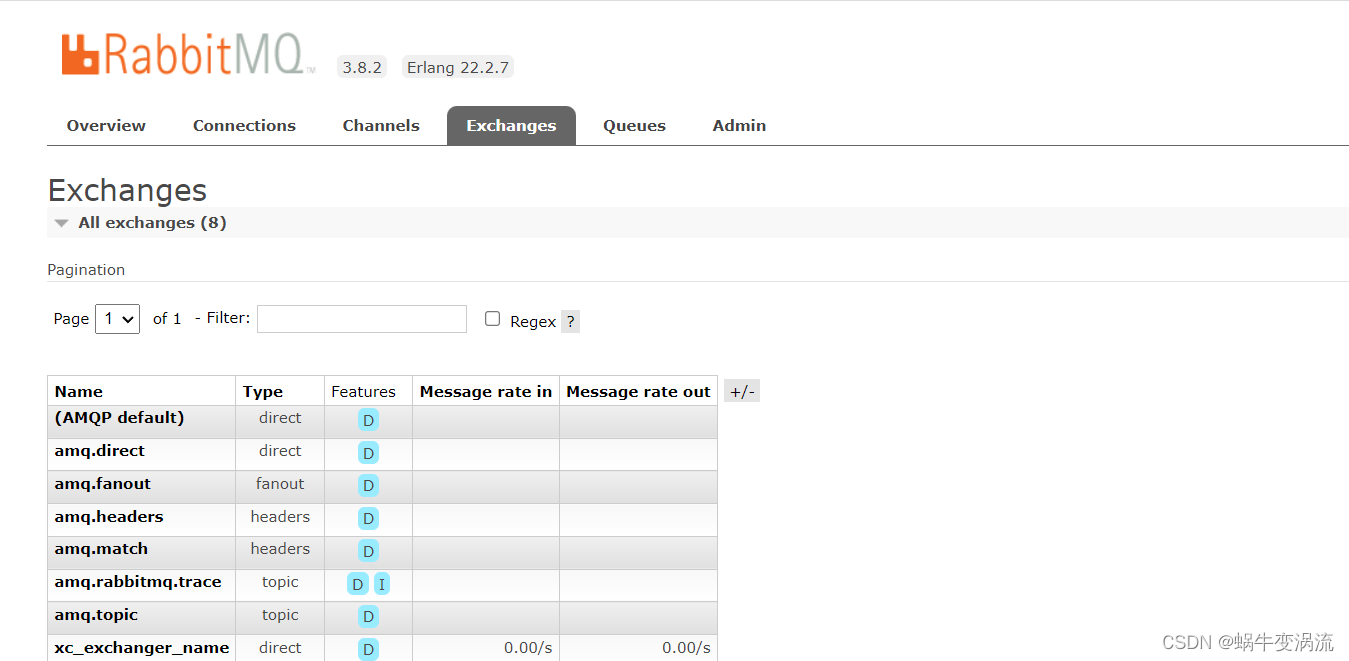
Rabbitmq的安装与使用(Linux版)
目录 Rabbitmq安装 1.在Ubuntu上安装RabbitMQ: 打开终端,运行以下命令以更新软件包列表: 安装RabbitMQ: 安装完成后,RabbitMQ服务会自动启动。你可以使用以下命令来检查RabbitMQ服务状态: 2.在CentOS…...
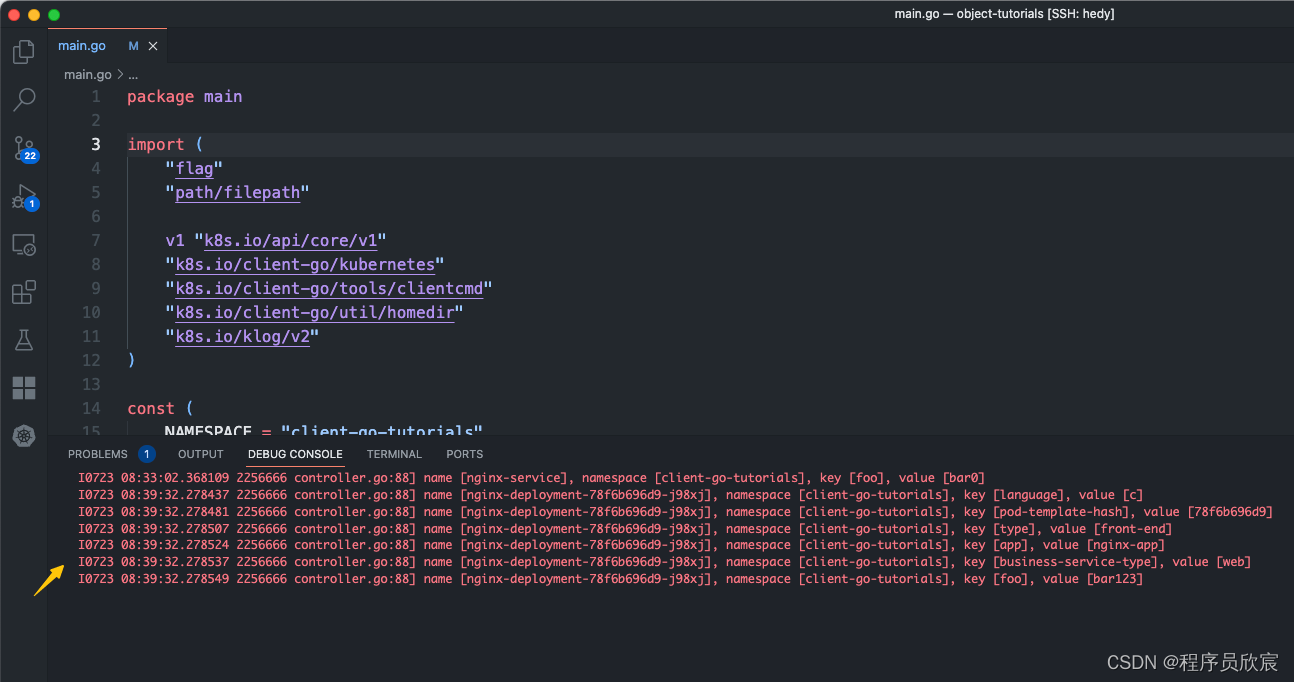
Kubernetes对象深入学习之四:对象属性编码实战
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是《Kubernetes对象深入学习》系列的第四篇,前面咱们读源码和文档,从理论上学习了kubernetes的对象相关的知识ÿ…...

深度学习入门教程(2):使用预训练模型来文字生成图片TextToImageGenerationWithNetwork
本深度学习入门教程是在polyu HPCStudio 启发以及资源支持下进行的,在此也感谢polyu以及提供支持的老师。 本文内容:在GoogleColab平台上使用预训练模型来文字生成图片Text To Image Generation With Network (1)你会学到什么&a…...
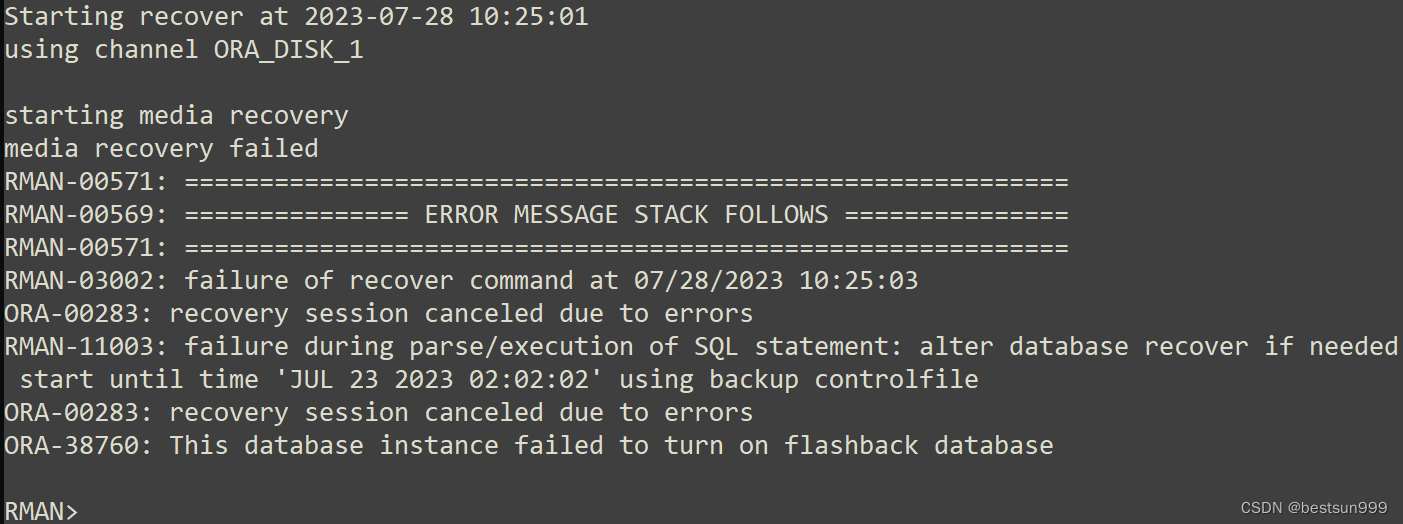
ORA-38760: This database instance failed to turn on flashback database
早晨接一个任务,使用rman备份在虚拟化单机上恢复实例,恢复参数文件、控制文件和数据文件都正常,recover归档时报错如下: Starting recover at 2023-07-28 10:25:01 using channel ORA_DISK_1 starting media recovery media reco…...

避免低级错误:深入解析Java的ConcurrentModificationException异常
在软件开发中,我们常常会遇到各种错误和异常。其中有一类比较低级但又常见的错误就是ConcurrentModificationException异常。最近了我就写了个这种异常,这个异常通常发生在使用迭代器遍历集合时,同时对集合进行修改,从而导致迭代器…...
7.28
1.思维导图 2.qt的sever #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTcpServer> //服务器类 #include<QTcpSocket> //客户端类 #include<QMessageBox> //对话框类 #include<QList> …...
java线程中的常见方法(详解)
方法简介 方法名 功能 说明 start() 启动一个新线程,在新的线程运行 run 方法中的代码 start 方法只是让线程进入就绪,里面代码不一定立刻运行(CPU 的时间片还没分给它)。每个线程对象的start方法只能调用一次,如…...

线程池参数配置
上次面试被人问到,如果是IO 密集型的任务,该如何配置合适的线程数,当初我说要按照IO具体的请求毫秒时间,来配置具体的线程数。 NthreadsNcpu*(1w/c) 公式中 W/C 为系统 阻塞率 w:等待时间 c:计算时间一般情况下,如果存…...

Spread for Winform 16.2.20231.0 (SP2) Crack
Spread for Winform 16.2.20231.0 (SP2)发布。此版本包含针对客户报告的问题的重要修复: 安装版本 16 后,FarPoint.Localization.dll 将丢失。 将数据绑定到 Spread 时会出现 InvalidOperationException。 通过 Spread Designer 设置的上标将不会保留。…...

Go程序结构
Go程序结构 1、名称 名称的开头是一个字母或下划线,且区分大小写。 实体第一个字母的大小写决定其可见性是否跨包: 若名称以大写字母开头,它是导出的,对包外是可见和可访问的,可以被自己包以外的其他程序所引用…...

JAVA面试总结-Redis篇章(四)——双写一致性
JAVA面试总结-Redis篇章(四)——双写一致性 问:redis 做为缓存,mysql的数据如何与redis进行同步呢?第一种情况,如果你的项目一致性要求高的话 采用以下逻辑我们应该先删除缓存,再修改数据库&…...

赋能医院数字化转型,医院拍摄VR全景很有必要
医院有没有必要拍摄制作VR全景呢?近期也有合作商问我们这个问题,其实VR智慧医院是趋势、也是机遇。现在外面很多的口腔医院、医美机构等都开始引入VR全景技术了,力求打造沉浸式、交互式的VR智慧医院新体验,通过VR全景展示技术来助…...

Vue3项目中没有配置 TypeScript 支持,使用 TypeScript 语法
1.安装 TypeScript:首先,需要在项目中安装 TypeScript。在终端中运行以下命令 npm install typescript --save-dev2.创建 TypeScript 文件:在 Vue 3 项目中,可以创建一个以 .ts 后缀的文件,例如 MyComponent.ts。在这…...

数据可视化大屏拼接屏开发实录:屏幕分辨率测试工具
一、可视化大屏开发 在数据可视化大屏开发时,确定数据可视化大屏拼接屏的板块尺寸需要考虑以下几个因素: 屏幕分辨率:首先需要知道每个板块屏幕的分辨率,包括宽度和高度,这决定了每个板块上可以显示的像素数量。 数据…...

每日一题7.28 209
209. 长度最小的子数组 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 本题应该是用前缀…...

Python + Playwright 无头浏览器Chrome找不到元素
用Python Playwright调试时,发现不用无头浏览器(即headlessFalse)代码能够运行成功,但是一用无头浏览器时(即headlessTrue)就会报错,提示找不到元素。换成Firefox浏览器又不会有这个问题&#…...

palworld-host-save-fix全攻略:解决幻兽帕鲁存档迁移难题的实战指南
palworld-host-save-fix全攻略:解决幻兽帕鲁存档迁移难题的实战指南 【免费下载链接】palworld-host-save-fix 项目地址: https://gitcode.com/gh_mirrors/pa/palworld-host-save-fix 在幻兽帕鲁的冒险旅程中,更换服务器或迁移平台时的存档丢失问…...
不用花钱买token版)
本地部署openclaw(window环境下)不用花钱买token版
步骤一:参考视频到安装 openclaw 前就行(剩下的步骤和博主不太样) 步骤 2 1、免费注册一个 NVIDIA NIM 账户: 【点击前往】 登入后在设置中心生成你自己的API Keys ,过期时间选择永不过期,目前可以直接免…...

steam_api.dll是什么文件?全面解析其作用与安全修复方法
不少玩家在启动Steam游戏时,都曾被“无法启动此程序,因为计算机中丢失steam_api.dll”这样的提示拦在门外。看着这串乱码般的文件名,第一反应通常是:这是什么?为什么没了它游戏就不动了?别急,这…...

Android项目中的Gradle文件详解:从基础配置到高级技巧
Android项目中的Gradle文件详解:从基础配置到高级技巧 在Android开发的世界里,Gradle文件就像是一个项目的"大脑",它控制着构建过程的方方面面。对于有一定经验的Android开发者来说,深入理解Gradle文件的配置不仅能够提…...

美国智能手机搜查法律现状:不确定性与风险并存
生物识别解锁:法律模糊地带的高风险在美国,配置生物识别解锁功能的设备一直面临易受攻击的问题。目前,关于手机搜查的合法权益并不明确。一方面,若手机设置密码锁,被拘留或逮捕时说出密码可能被视为自证其罪࿰…...

PyTorch 2.8镜像保姆级教程:RTX 4090D下HuggingFace Datasets高效加载
PyTorch 2.8镜像保姆级教程:RTX 4090D下HuggingFace Datasets高效加载 1. 环境准备与快速验证 1.1 镜像基本信息确认 本教程使用的PyTorch 2.8镜像已针对RTX 4090D显卡进行深度优化,主要配置如下: 核心组件:PyTorch 2.8 CUDA…...

基于鲸鱼优化算法改进XGBoost在MATLAB中的时间序列预测性能(迭代次数、最大深度和学习...
基于鲸鱼优化算法优化XGBoost(WOA-XGBoost)的时间序列预测 WOA-XGBoost时间序列 采用交叉验证抑制过拟合问题 优化参数为迭代次数、最大深度和学习率 matlab代码,注:暂无Matlab版本要求 -- 推荐 2016B 版本及以上 注:采用 XGBoost 工具箱&…...

Mac用户福音:Qwen3-TTS声音克隆在ComfyUI上的M芯片优化方案
Mac用户福音:Qwen3-TTS声音克隆在ComfyUI上的M芯片优化方案 1. 为什么Mac用户需要特别优化方案 苹果M系列芯片凭借其出色的能效比和统一内存架构,已经成为许多创意工作者的首选。然而,在运行AI模型时,特别是像Qwen3-TTS这样的语…...

DeerFlow效果展示:自动生成的深度研究报告与播客内容惊艳分享
DeerFlow效果展示:自动生成的深度研究报告与播客内容惊艳分享 1. DeerFlow核心能力概览 DeerFlow作为一款深度研究智能助手,整合了语言模型、网络搜索和代码执行能力,能够自动完成从信息收集到内容生成的全流程工作。其核心功能亮点包括&am…...

芯片研发的残酷真相:流片成功只是开始
芯片成功"点亮"那一刻,项目算完成了吗?如果你认为算,那大概率还没经历过真正的芯片项目后期。事实是,点亮和demo跑通,只不过是拿到了入场券而已。真正的战斗,从客户拿到样片那一刻才开始。很多工…...