【第二套】Java面试题
第二套:
一、JavaScript前端开发
1、下列的代码输出什么?
var y = 1;
if(function f(){}){y += typeof f;
}
console.log(y);
正确的答案应该是 1undefined。
JavaScript中if语句求值其实使用eval函数,eval(function f(){}) 返回 function f(){} 也就是 true。
下面我们可以把代码改造下,变成其等效代码。
var k = 1;
if (1) {eval(function foo(){});k += typeof foo;}
console.log(k);
上面的代码输出其实就是 1undefined。为什么那?我们查看下 eval() 说明文档即可获得答案
该方法只接受原始字符串作为参数,如果 string 参数不是原始字符串,那么该方法将不作任何改变地返回。
恰恰 function f(){} 语句的返回值是 undefined,所以一切都说通了。
注意上面代码和以下代码不同。
var k = 1;
if (1) {function foo(){};k += typeof foo;}
console.log(k); // output 1function
2、写出一个caNum函数,可以将参数想成,使用方法如下:
Console.log(caNum(2)(3)(4)); //输出:24
Console.log(caNum(4)(3)(4)); //输出:48
最普通的实现版本:
var multiply = function () {var a = 1;for (let i = 0; i < arguments.length; i++) {a = a * arguments[i];}return a;
}
console.log('11:',multiply(1,2,3,4)); // 输出:24
如果想了解优化版本,链接:https://blog.csdn.net/qq_37268201/article/details/113262983
3、编写一个函数,使用JQuery如何判断变量obj是否为数组。
var arr= [1,1,1,1]
var a = '2323'
var b = {name:'xiao',age:12}
var n = 1
1、instanceof
instanceof运算符用于检验构造函数的prototype属性是否出现在对象的原型链中的任何位置,返回一个布尔值。
注意的是,prototype属性是可以修改的,所以并不是最初判断为true就一定永远为真。
console.log('方法1',arr instanceof Array); //如果是数组 打印结果为 true
2、constructor
实例的构造函数属性constructor指向构造函数,那么通过constructor属性也可以判断是否为一个数组。
这种判断也会存在多个全局环境的问题,导致的问题与instanceof相同。
console.log('方法2',arr.constructor === Array);//true
3、Array.isArray() 最推荐方法
同样能准确判断,但有个问题,Array.isArray() 是在ES5中提出,也就是说在ES5之前可能会存在不支持此方法的情况。
console.log('方法3',Array.isArray(arr)); //truefunction isArray(obj){return $.isArray(obj)
}//JQuery isArray 的实现其实就是方法5
4、typeof
使用该方法 判断数组时 打印结果为object(弊端在于如果数据类型为引用数据类型,他只能返回 Object)
此方法的返回结果只有以下几种:Number、String、undefined、Bollean、Object、Function
console.log('方法4',typeof n); //number
console.log('方法4',typeof(b)) //object
5 Object.prototype.toSrtring.call()
当使用该方法判断其他数据类型时要注意一点是,IE8及IE8以下,undefined和null均为Object,IE9及IE9以上为[object Undefined]和[object Null]
console.log(Object.prototype.toString.call(arr).indexOf('Array') !== -1); //true
console.log(Object.prototype.toString.call(arr) === '[object Array]'); //truefunction isArray(obj){return Object.prototype.toString.call( obj ) === '[object Array]';
} //这里使用call来使 toString 中 this 指向 obj。进而完成判断
参考链接:https://blog.csdn.net/qq_43399210/article/details/111403146
4、以下代码运行时抛出异常,请将代码改正,确保可以执行。
var foo = function bar(){return 12;};
typeof bar();
输出是抛出异常,bar is not defined。 如果想让代码正常运行,需要这样修改代码:
var bar = function(){ return 12; };
typeof bar();或者是function bar(){ return 12; };
typeof bar();
二、Java后端开发:
1、Java 中如何将对象序列化,什么情况下需要序列化;
只有实现了Serializable或者Externalizable接口的类的对象才能被序列化为字节序列。(不是则会抛出异常)
一方面,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象。
序列化:把Java对象转换为字节序列(二进制)的过程。
反序列化:把字节序列恢复为Java对象的过程。
注:序列化是将对象状态转换为可保持或可传输的格式的过程。反序列化将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。JSON是用于接口数据交换的格式。核心作用就是对象状态的保存和重建
序列化和反序列化总的来说可以归结为以下几点:
-
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;(持久化对象)将对象转为字节流存储到硬盘上,当JVM停机的话,字节流还会在硬盘上默默等待,等待下一 次JVM的启动,把序列化的对象,通过反序列化为原来的对象,并且序列化的二进制序列能够减少存储空间
-
在网络上传送对象的字节序列。(网络传输对象)
-
通过序列化在进程间传递对象;
2、列举常用的Map集合,并简述HashMap 与 HashTable的区别;
Map映射:无序,键唯一,值不唯一
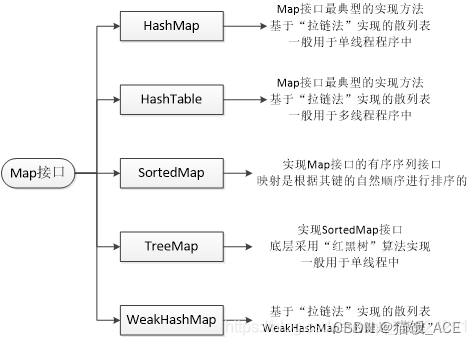
HashMap: 哈希映射/字典,无序字典,键值对数据,key是唯一的,Key和Value都可以为null
Hashtable: 与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
TreeMap: 红黑树实现的key->value融合,可排序,红黑树是一种自平衡二叉查找树。
LinkedHashMap: 链表映射/字典,继承了hashmap的所有特性,同时又实现了双向链表的特性,保留了元素插入顺序。
ConcurrentHashMap: 线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
HashMap 与 HashTable的区别:
- hashMap去掉了HashTable 的contains方法,但是加上containsValue()和containsKey()方法。
- hashTable同步的,线程安全的;而HashMap是非同步的,效率上逼hashTable要高。
- hashMap允许空键值,而hashTable不允许。
3、编写代码:Java遍历Map方式。
Map内容:{“name”:“张某某”,“age”:“30”,“sex”:“male”,“code”:“3010”}
1、在for循环中使用entrySet的遍历,也可以同时拿到key和value,用的最多
Map <String,String>map = new HashMap<String,String>();
map.put("熊大", "棕色");
map.put("熊二", "黄色");
for(Map.Entry<String, String> entry : map.entrySet()){String mapKey = entry.getKey();String mapValue = entry.getValue();System.out.println(mapKey+":"+mapValue);
}
2、在for循环中使用map.keySet()遍历key通过map.get(key)获取单个值,或使用map.values()遍历获取values
这种方式一般适用于只需要map中的key或者value时使用,在性能上比使用entrySet较好;
Map <String,String>map = new HashMap<String,String>();
map.put("熊大", "棕色");
map.put("熊二", "黄色");
//key
for(String key : map.keySet()){System.out.println(key);
}
//value
for(String value : map.values()){System.out.println(value);
}
System.out.println("通过map.keyset进行遍历key和value");for (String key:map.keySet()){System.out.println("key= "+key+" and value= "+map.get(key));}
3、通过Iterator遍历
在使用Iterator遍历时:使用foreach遍历map时,如果改变其大小,会报错,但如果只是删除元素,可以使用Iterator的remove方法删除元素
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
//用迭代器的时候注意:next()方法在同一循环中不能出现俩次!
//否则会抛出NoSuchElementException异常。
while(entries.hasNext()){Entry<String, String> entry = entries.next();String key = entry.getKey();String value = entry.getValue();System.out.println(key+":"+value);
}
4、通过键找值遍历(就是第二种遍历key的方式+get值的方式)
这种方式的效率比较低,因为本身从键取值是耗时的操作,不建议使用;
for(String key : map.keySet()){String value = map.get(key);System.out.println(key+":"+value);
}
一些结论:
如果只是获取key,或者value,推荐使用keySet或者values方式
如果同时需要key和value推荐使用entrySet
如果需要在遍历过程中删除元素推荐使用Iterator
如果需要在遍历过程中增加元素,可以新建一个临时map存放新增的元素,等遍历完毕,再把临时map放到原来的map中
map遍历参考链接:https://blog.csdn.net/qq_44750696/article/details/112254719
4、通过“反射”,创建com.weavercsd.po.UseerInfo 对象的实例。
通过反射创建对象有两种方式:
1、使用Class对象的newInstance方法创建该Class对象对应的类实例(该Class对象对应的类有默认的空构造器)
Class clazz = Class.forName("com.weavercsd.po.UseerInfo");
Person person = (Person) clazz.newInstance();
2、使用Constructor对象newInstance方法创建Class对象对应的类实例
该方法有两步:
1、通过Class对象获取指定的Constructor对象
2、调用Constructor对象的newInstance方法创建Class对象对应的类实例
该方法可以选定构造方法创建实例
Class clazz = Class.forName("com.weavercsd.po.UseerInfo");
Constructor declaredConstructor = clazz.getDeclaredConstructor(Integer.class, String.class, Integer.class, String.class);
Person person = (Person) declaredConstructor.newInstance(1, "张三", 30, "男");
使用Class对象的newInstance方法:
@Data
public class Person {private Integer id;private String name;private Integer age;private Integer sex;
}
public class TestReflectCreateObj {public static void main(String[] args) {Class clazz = null;try{clazz = Class.forName("com.kevin.base.reflect.Person");Person person = (Person) clazz.newInstance();System.out.println(person);}catch (ClassNotFoundException e){e.printStackTrace();} catch (InstantiationException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();}}
}执行结果:Person(id=null, name=null, age=null, sex=null)
使用Constructor对象newInstance方法:
@Data
@AllArgsConstructor
public class Person {private Integer id;private String name;private Integer age;private String sex;
}public class TestReflectCreateObj {public static void main(String[] args) {Class clazz = null;try{//1.获取Person类的Class对象clazz = Class.forName("com.kevin.base.reflect.Person");//2.获取构造方法并创建对象Constructor declaredConstructor = clazz.getDeclaredConstructor(Integer.class, String.class, Integer.class, String.class);//3.根据构造方法创建对象并设置属性Person person = (Person) declaredConstructor.newInstance(1, "张三", 30, "男");System.out.println(person);}catch (Exception e){e.printStackTrace();}}
}执行结果:
Person(id=1, name=张三, age=30, sex=男)
5、XML 和 JSON 有什么区别,分别有哪些解析方式;
区别:
XML主要是由element、attribute和element content组成。JSON主要是由object、array、string、number、boolean(true/false)和null组成。
XML要表示一个object(指name-value pair的集合),最初可能会使用element作为object,每个key-value pair 用 attribute 表示。
XML需要选择怎么处理element content的换行,而JSON string则不须作这个选择。
XML只有文字,没有预设的数字格式,而JSON则有明确的number格式,这样在locale上也安全。
XML映射数组没大问题,就是数组元素tag比较重复冗余。JSON 比较易读。
JSON的true/false/null也能容易统一至一般编程语言的对应语义。
XML文档可以附上DTD、Schema,还有一堆的诸如XPath之类规范,使用自定义XML元素或属性,能很方便地给数据附加各种约束条件和关联额外信息,从数据表达能力上看,XML强于Json,但是很多场景并不需要这么复杂的重量级的东西,轻便灵活的Json就显得很受欢迎了。
XML:JAVA中可使用DOM、SAX、DOM4J 或JDOM等解析
DOM形成了树结构,直观好理解,代码更易编写。解析过程中树结构保留在内存中,方便修改。当xml文件较大时,对内存耗费比较大,容易影响解析性能并造成内存溢出。
SAX采用事件驱动模式,对内存耗费比较小。适用于只需要处理xmI中数据时。但不易编码,很难同时访问同一个xml中的多处不同数据。
DOM4J 是一个非常非常优秀的Java XML API,将整个文档读入,然后解析,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。
JDOM是基于树的处理XML的Java API,把树加载在内存中,没有向下兼容的限制,因此比DOM简单速度快,缺陷少具有SAX的JAVA规则
,但不能处理大于内存的文档,JDOM表示XML文档逻辑模型。不能保证每个字节真正变换。针对实例文档不提供DTD与模式的任何实际模型。不支持与DOM中相应遍历包。
JSON:JAVA 使用FastJSON、Gson或Jackson等解析
Fastjson是一个Java语言编写的高性能的JSON处理器,由阿里巴巴公司开发。无依赖,不需要例外额外的jar,能够直接跑在JDK上。FastJson采用独创的算法,将parse的速度提升到极致,超过所有json库。
Gson是目前功能最全的Json解析神器,Gson当初是为因应Google公司内部需求而由Google自行研发而来,但自从在2008年五月公开发布第一版后已被许多公司或用户应用。Gson的应用主要为toJson与fromJson两个转换函数,无依赖,不需要例外额外的jar,能够直接跑在JDK上。
Jackson所依赖的jar包较少,简单易用并且性能也要相对高些。而且Jackson社区相对比较活跃,更新速度也比较快。Jackson对于复杂类型的json转换bean会出现问题,一些集合Map,List的转换出现问题。Jackson对于复杂类型的bean转换Json,转换的json格式不是标准的Json格式。json-lib最开始的也是应用最广泛的json解析工具,json-lib 不好的地方确实是依赖于很多第三方包
xml
可扩展标记语言,是互联网数据传输的重要工具,可以跨越互联网任何平台,不受编程语言和操作系统的限制.
特点:
- 1.xml与操作系统,变成语言的开发平台无关
- 2.实现不同系统之间的数据交互
作用:
- 配置应用程序
- 数据交互
- Ajax基石
规则:
- 必须有xml声明语句
- 必须有且仅有一个根元素
- 标签大小写敏感
- 属性值用双引号
- 标签成对出现
- 空标签关闭
- 元素正确嵌套
JSON
是一种数据交换格式.json全称是JavaScript Object Notation, 意思是对象表示法,它是一种基于文本,独立于语言的轻量级数据交换格式
特点:
- JSON是纯文本。
- JSON具有良好的自我描述性,便于阅读。
- JSON具有层级结构(值中存在值)。
- JSON可通过JavaScript进行解析。
- JSON数据可使用AJAX进行传输。
JSON和XML的区别:
6. 数据体积方面, JSON相对于XML来说, 数据的体积小,传递快
7. 数据交互方面,JSON与JavaScript交互更加方便,更容易解析处理,更好地数据交互
8. 数据描述方面,JSON对数据的描述性比xml较差
9. 传递速度方面,JSON的速度要远远快于xml
JSON和xml的优缺点:
- JSON轻便,解析简单,对客户端更加友好
- xml更加笨重,解析为DOM数并遍历节点来获取数据,优点是结构清晰,扩展性好
6、简述Restful架构,列举最常用的Rest支持的HTTP请求方法。
REST是所有Web应用都应该遵守的架构设计指导原则。就是用URI定位资源,用HTTP(GET,POST,DELETE,PUT)描述操作。
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。
RESTful是一个针对URI的架构,使用RESTful风格的URI可以使URI更具可读性。代码更加整洁且富有逻辑性。
首先要明白,RESTful架构是面向资源的。每一个URI可以确定一个资源。而用户或程序员使用URI其实就是在操作资源。
因此至始至终都应该围绕资源来设计URI。(可以在URI里带上资源的主键,在URI里边带上版本号,使用/来区分资源的层级关系,使用?用来过滤资源)
REST最大的几个特点为:资源(需要查询的数据库信息等等)、统一接口(get,post,delete,put)、URI(URI既可以看成是资源的地址,也可以看成是资源的名称,每个URI对应一个特定的资源)、无状态(所有的资源,都可以通过URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变)。
EX:有状态和无状态的区别,举个简单的例子说明一下。如查询员工的工资,如果查询工资是需要登录系统,进入查询工资的页面,执行相关操作后,获取工资的多少,则这种情况是有状态的,因为查询工资的每一步操作都依赖于前一步操作,只要前置操作不成功,后续操作就无法执行;如果输入一个url即可得到指定员工的工资,则这种情况是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个url与之对应,可以通过HTTP中的GET方法得到资源,这是典型的RESTful风格。REST遵循无状态通信原则。这并不代表客户端应用不能有状态。而是指服务端不应保留客户端的状态。
RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
2、客户端的HTTP的请求方式一般分为四种:GET、POST、PUT、DELETE、PATCH、HEAD 和 OPTIONS。
GET就是获取资源, POST就是创建资源(也可用于更新资源),PUT就是更新资源,DELETE就是删除资源
GET:获取资源, 当客户端使用 GET 方法请求服务器时,服务器将返回与请求 URI 相关联的资源的表示形式。GET 方法不应该改变服务器上的资源状态。GET只是访问和查看资源。GET操作是安全的。
GET /users HTTP/1.1
Host: api.example.com
上述示例中,客户端使用 GET 方法获取了所有用户的信息,并将响应数据以 JSON 或 XML 格式返回。
POST:创建资源(也可用于更新资源), 当客户端使用 POST 方法向服务器发送请求时,服务器会创建一个新的资源,并返回该资源的 URI。操作不是安全的,每次请求都会创建资源,当我们多次发出POST请求后,其结果是创建出了多个资源。
还有一点需要注意的就是,创建操作可以使用POST,也可以使用PUT,区别在于POST 是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx),再通俗点说,如果URL可以在客户端确定,那么就使用PUT,如果是在服务端确定,那么就使用POST,比如说很多资源使用数据库自增主键作为标识信息,而创建的资源的标识信息到底是什么只能由服务端提供,这个时候就必须使用
POST。
POST /users HTTP/1.1
Host: api.example.com
Content-Type: application/json{"name": "John Doe","age": 30,"email": "john.doe@example.com"
}
上述示例中,客户端使用 POST 方法创建一个新用户,并将用户信息以 JSON 格式发送到服务器。
PUT:更新资源。 当客户端使用 PUT 方法向服务器发送请求时,服务器将更新与请求 URI 相关联的资源的表示形式。用来修改数据的内容,但是资源不会增加
PUT /users/1 HTTP/1.1
Host: api.example.com
Content-Type: application/json{"name": "John Doe","age": 31,"email": "john.doe@example.com"
}
上述示例中,客户端使用 PUT 方法更新 ID 为 1 的用户信息,并将更新后的用户信息以 JSON 格式发送到服务器。
DELETE:删除资源。 当客户端使用 DELETE 方法向服务器发送请求时,服务器将删除与请求 URI 相关联的资源。
DELETE /users/1 HTTP/1.1
Host: api.example.com
上述示例中,客户端使用 DELETE 方法删除 ID 为 1 的用户信息。
PATCH:用于更新部分资源。 当客户端使用 PATCH 方法向服务器发送请求时,服务器将更新与请求 URI 相关联的资源的部分属性。
PATCH /users/1 HTTP/1.1
Host: api.example.com
Content-Type: application/json{"age": 31
}
上述示例中,客户端使用 PATCH 方法更新 ID 为 1 的用户的年龄信息,并将更新后的用户信息以 JSON 格式发送到服务器。
HEAD :用于获取资源的元数据,但不返回实际的响应主体。当客户端使用 HEAD 方法向服务器发送请求时,服务器将返回与请求 URI 相关联的资源的元数据,例如资源的大小和修改时间等。
HEAD /users HTTP/1.1
Host: api.example.com
上述示例中,客户端使用 HEAD 方法获取所有用户的元数据,并不返回实际的响应主体。
OPTIONS :用于获取服务器支持的 HTTP 方法和资源的元数据。当客户端使用 OPTIONS 方法向服务器发送请求时,服务器将返回与请求 URI 相关联的资源的支持的 HTTP 方法和元数据。
OPTIONS /users HTTP/1.1
Host: api.example.com
上述示例中,客户端使用 OPTIONS 方法获取所有用户支持的 HTTP 方法和元数据。
我们使用了 SpringBoot 提供的注解来定义 RESTful Web 服务的各种操作,例如 @RestController、@GetMapping、@PostMapping、@PutMapping、@DeleteMapping 和 @PathVariable 等注解。这些注解可以帮助我们更方便地定义 RESTful Web 服务的各种操作。
GET和POST的区别:
- GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:getCitycode?lat=100.22&lon=35.33;POST把提交的数据则放置在是HTTP包的包体中。
- 在浏览器上,GET方式提交的数据是有限制的,例如有时候请求的URL太长,会返回错误;但如果是客户端GET请求,是没有数据的限制的。POST没有限制,可传较大量的数据。
- POST的安全性要比GET的安全性高。这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,查看浏览器的历史纪录,就可以查看到GET请求的参数,比如登录的帐号密码、搜索关键字、个人信息等。
POST和PUT在创建资源的区别在于, 所创建的资源的名称(URI)是否由客户端决定。 例如为我的博文增加一个java的分类,生成的路径就是分类名/categories/java,那么就可以采用PUT方法。
PUT和POST方法语义中都有修改资源状态的意思,因此都不是安全的。但是PUT方法是幂等的,POST方法不是幂等的,这么设计的理由是:
HTTP协议规定,POST方法修改资源状态时,URL指示的是该资源的父级资源,待修改资源的ID信息在请求体中携带。而PUT方法修改资源状态时,URL直接指示待修改资源。因此,同样是创建资源,重复提交POST请求可能产生两个不同的资源,而重复提交PUT请求只会对其URL中指定的资源起作用,也就是只会创建一个资源。
7、描述Java对Excel读写的常用方式(可用文字说明或代码示例解答)。
EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理。
1、java读取Excel表中的内容:
- 准备实体类,converter转换类
- 准备导入监听器,主要用来监听读取Excel文件数据,用来一行行的读取数据,需要继承EasyExcel方法AnalysisEventListener,重写有三个方法(读取数据操作,读取表头操作,读取数据结束后操作)
- 使用 EasyExcel.read方法,指定读取的文件路径,使用哪个实体类读取,以及使用的监听器对象,读取那个sheet等等。
public class ExceListener extends AnalysisEventListener<UserData> {/*** 进行读的操作具体执行方法,一行一行的读取数据* 从第二行开始读取,不读取表头** @param userData* @param analysisContext*/@Overridepublic void invoke(UserData userData, AnalysisContext analysisContext) {System.out.println(userData);}/*** 读取表头信息** @param headMap* @param context*/@Overridepublic void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {super.invokeHeadMap(headMap, context);System.out.println("表头信息:" + headMap);}/*** 读取完数据的操作** @param analysisContext*/@Overridepublic void doAfterAllAnalysed(AnalysisContext analysisContext) {}
}
private static void read() {// 指定读的路径String fileName = "D:\1627870562085.xlsx";// 调用读的方法EasyExcel.read(fileName, UserData.class, new ExceListener()).sheet().doRead();
}
2、通过java将数据生成为Excel表:
- 导入相应的包,创建实体类
- 往外导出数据时,需要到调用EasyExcel的write方法写入文件或者写入有个输出流中都是可以的,指定使用哪个实体类写入文件,sheet指定Excel文件页面sheet值,dowrite(写入的数据集合)
private void writer() {List<UserData> userData = new ArrayList<>();for (int i = 0; i < 10; i++) {UserData data = new UserData();data.setUid(i);data.setName("zdk" + i);userData.add(data);}// 指定写的路径String fileName = "D:\\" + System.currentTimeMillis() + ".xlsx";// 这里 需要指定写用哪个class去写,然后写到第一个sheet,// 名字为模板 然后文件流会自动关闭EasyExcel.write(fileName, UserData.class).sheet("模板").doWrite(userData);}
8、编码实现创建多线程。(创建多线程的4种方式)
继承Thread类、实现Runnable接口、实现Callable接口、线程池的方式;
第一种:继承Thread类:
- 创建一个继承于Thread类的子类
- 重写Thread类的run() 将此线程执行的的操作声明在run()中
- 创建Thread类的子类的对象
- 通过此对象调用start()
/*** 多线程的创建,方式一:继承于Threadlei* 1.创建一个继承于Thread类的子类* 2.重写Thread类的run() 将此线程执行的的操作声明在run()中* 3.创建Thread类的子类的对象* 4.通过此对象调用start()** 例子:遍历100以内所有的偶数*/
public class ThreadTest {public static void main(String[] args) {//3.创建Thread类的子类的对象MyThread myThread = new MyThread();//4.通过此对象调用start() ①启动当前线程 ②调用当前线程的run()myThread.start();//不能通过myThread.run()的方式启动线程//再启动一个线程MyThread myThread1 = new MyThread();myThread1.start();//如下操作仍然是在main()线程中执行的for (int i = 0;i < 100 ;i++){if (i % 2 != 0){System.out.println(Thread.currentThread().getName() + ":"+"hello");}}}
}// 1.创建一个继承于Thread类的子类
class MyThread extends Thread {//2.重写Thread类的run()@Overridepublic void run() {for (int i = 0;i < 100 ;i++){if (i % 2 == 0){System.out.println(Thread.currentThread().getName() + ":" + i);}}}
}
第二种:实现Runnable接口
- 创建一个实现了Runnable接口的类
- 实现类去实现Runnable中的抽象方法:run()
- 创建实现类的对象
- 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
- 通过Thread类的对象调用start()
/*** 创建多线程的方式二:实现Runnable接口* 1.创建一个实现了Runnable接口的类* 2.实现类去实现Runnable中的抽象方法:run()* 3.创建实现类的对象* 4.将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象* 5.通过Thread类的对象调用start()** 比较创建线程的两种方式:* 开发中优先选择实现Runnable接口的方式* 原因:1.实现的方式没有类的单继承性的局限性* 2.实现的方式更适合来处理多个线程有共享数据的情况** 联系:都实现了Runnable接口* 相同点:两种方式都需要重写run()方法,将线程要执行的逻辑声明在run()中**/
public class ThreadTest1 {public static void main(String[] args) {// * 3.创建实现类的对象MyThread myThread = new MyThread();// * 4.将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象Thread thread1 = new Thread(myThread);// * 5.通过Thread类的对象调用start() ①启动线程 ②调用当前线程的run()thread1.start();Thread thread2 = new Thread(myThread);thread2.start();}
}// * 1.创建一个实现了Runnable接口的类
class MyThread implements Runnable{// * 2.实现类去实现Runnable中的抽象方法:run()@Overridepublic void run() {for (int i = 0; i < 100; i++) {if (i % 2 == 0) {System.out.println(Thread.currentThread().getName() + ":" + i);}}}
}
第三种:实现Callable接口
- 创建一个实现Callable的实现类
- 实现call方法,将此线程需要执行的操作声明在call()中
- 创建Callable接口实现类的对象
- 将Callable接口实现类的对象作为参数传递到FutureTask构造器中,创建FutureTask的对象
- 将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()方法
- 获取Callable中call方法中的返回值
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;/*** 创建线程的方式三:实现Callable接口。 JDK5.0新增** 如何理解实现Callable接口的方式创建多线程的方式比是实现Runnable接口创建多线程方式强大* 1.call()可以有返回值* 2.call()可以抛出异常*/
public class ThreadNew {public static void main(String[] args) {//3.创建Callable接口实现类的对象NumThread numThread = new NumThread();//4.将Callable接口实现类的对象作为参数传递到FutureTask构造器中,创建FutureTask的对象FutureTask futureTask = new FutureTask(numThread);//5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()方法Thread thread1 = new Thread(futureTask);thread1.start();try {//6.获取Callable中call方法中的返回值//get()返回值即为FutureTask构造器参数Callable实现重写的call()返回值。Object sum = futureTask.get();System.out.println(" 总和为:" + sum);} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}
}//1.创建一个实现Callable的实现类
class NumThread implements Callable{//2.实现call方法,将此线程需要执行的操作声明在call()中@Overridepublic Object call() throws Exception {int sum = 0;for (int i = 1; i <= 100; i++) {if(i % 2 == 0){System.out.println(i);sum += i;}}return sum;}
}
第四种:线程池的方式
- 提供指定线程数量的线程池
- 执行指定线程的操作,需要提供实现Runnable接口或Callable接口实现类的对象
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;/*** 创建线程的方式四:使用线程池** 好处:1.提高响应速度(减少创建新线程的时间)* 2.降低资源消耗(重复利用线程池中的线程,不需要每次都创建)* 3.便于线程管理** corePoolSize:核心池的大小* maximumPoolSize:最大线程数* keepAliveTime:线程没有任务时最多保持多长时间后会终止*/
public class ThreadPool {public static void main(String[] args) {//1.提供指定线程数量的线程池ExecutorService executorService = Executors.newFixedThreadPool(10);ThreadPoolExecutor service1 = (ThreadPoolExecutor) executorService;//设置线程池的属性service1.setCorePoolSize(10);//2.执行指定线程的操作,需要提供实现Runnable接口或Callable接口实现类的对象executorService.execute(new NumberThread());//适合使用于Runnable//executorService.submit();//适合使用与CallableexecutorService.execute(new NumberThread1());//关闭线程池executorService.shutdown();}
}class NumberThread implements Runnable{@Overridepublic void run() {for (int i = 0; i <= 100 ; i++) {if(i % 2 == 0){System.out.println(Thread.currentThread().getName() + ":" +i);}}}
}class NumberThread1 implements Runnable{@Overridepublic void run() {for (int i = 0; i <= 100 ; i++) {if(i % 2 != 0){System.out.println(Thread.currentThread().getName() + ":" +i);}}}
}

9、list存的值是有序可重复,set存的值无序不可重复,所以set根据什么判断不可重复?
- TreeSet,底层是一个TreeMap,子类是利用Comparable接口来实现重复元素的判断,但是Set集合的整体特征就是不允许保存重复元素。
- HashSet,底层是一个HashMap,值为HashMap的键,判断元素重复是利用Object类中的方法实现的:
- 对象编码:public int hashCode();
- 对象比较:public boolean equals(Object obj);
在进行重复元素判断的时候首先利用hashCode()进行编码匹配,如果该编码不存在表示数据不存在,证明没有重复,如果该编码存在了,则使用equals()方法,进一步进行对象的比较处理,如果发现重复了,则此数据是不能保存的。
在java程序中真正的重复元素的判断处理利用的就是hashCode()与equals()两个方法共同作用完成的。
只有在排序要求的情况下(TreeSet)才会利用Comparable接口实现。
三、数据库知识
1、人力资源表:HrmResource中存放的用户基本信息数据,分别用SqlServer,Oracle,MySQL 三种不同数据库查询第11条到20条的数据(备注:表中含唯一主键ID,但不连续)
-- 1.mysql : select * from tableName where 条件 limit 当前页码*页面容量-1 , 页面容量
select * from HrmResource limit 11,10; -- MySQL limit(起始行,每行多少页)--2.oracle 查询20-40条记录 注:第一种方法比第二种方法效率高
第一种方法:select * from (select A.* ,rownum rn from (select * from table_name) A where rn<=40) where rn>=20;第一种方法:select * from (select A.* ,rownum rn from (select * from table_name) A ) where rn between 20 and 40;-- 3. sql server分页查询: select top n <字段1>,...,<字段n> from <表名>
假设现在有这样的一张表:CREATE TABLE test(id int primary key not null identity,names varchar(20))然后向里面插入大约1000条数据,进行分页测试假设页数是10,现在要拿出第5页的内容方法一:原理:拿出数据库的第5页,就是40-50条记录。首先拿出数据库中的前40条记录的id值,然后再拿出剩余部分的前10条元素select top 10 * from test where id not in(--40是这么计算出来的:10*(5-1)select top 40 id from test order by id)order by id方法二:原理:先查询前40条记录,然后获得其最id值,如果id值为null的,那么就返回0然后查询id值大于前40条记录的最大id值的记录。这个查询有一个条件,就是id必须是int类型的。
select top 10 * from test where id >(select isnull(max(id),0) from ( select top 40 id from test order by id ) A)order by id方法三:原理:先把表中的所有数据都按照一个rowNumber进行排序,然后查询rownuber大于40的前十条记录 这种方法和oracle中的一种分页方式类似,不过只支持2005版本以上的row_number()函数,为结果集的分区中的每一行分配一个连续的整数。OVER()是一个开窗函数,对集合进行聚合计算select top 10 * from (select row_number() over(order by id) as rownumber,* from test) Awhere rownumber > 40方法四:存储过程
1. 创建存储过程
alter procedure pageDemo
@pageSize int,
@page int
AS
declare @temp int
set @temp=@pageSize*(@page - 1)
beginselect top (select @pageSize) * from test where id not in (select top (select @temp) id from test) order by id
end2. 执行存储过程
exec 10,5
2、考勤签到表的数据结构如下:表名:hrmschedulesign 请用SQL查询:昨天所有用户的签到和签退时间;
| ID | userid | signdate | signtime | clientaddress |
|---|---|---|---|---|
| 1 | A01 | 2019-06-17 | 08:32:40 | 192.168.3.232 |
| 2 | A01 | 2019-06-17 | 10:30:22 | 192.168.3.232 |
| 3 | A01 | 2019-06-17 | 18:15:30 | 192.168.3.232 |
| 4 | A02 | … | … | … |
(备注:在考勤表中每个用户会有1-N条打卡记录,以每天的最早时间为签到数据,最晚时间为签退数据,跨天问题不需考虑)
select userid,min(signtime) startTime,max(signtime) endTime from hrmschedulesign
where (sysdate - to_date(signdate,'YYYY-MM-DD'))=1 group by userid;通过where (sysdate - to_date(signdate,'YYYY-MM-DD'))=1 筛选出昨天的所有数据,
select sysdate from dual,可以得到目前系统的时间;
由于signdate不是标准的YYYY/MM/DD的形式,所以肯定不是date类型的,
因为我们在和sysdate比较的时候需要通过to_date()函数把字符串变成date类型的数据,
之后就可以比较了,得出的就是天数,对于signtime来说,可以使用min()和max()进行比较,
最后在通过userid进行分组3、简述常见数据库索引类型和作用。
1.普通索引(NORMAL)
没有任何限制条件
2.唯一索引(UNIQUE)
要求关键字值不能重复,同时增加唯一约束。
3.主键索引:
要求关键字不能重复,也不能为NULL。同时增加主键约束。
4.全文索引(FULLTEXT)
关键字的来源不是所有字段的数据,而是从字段中提取的特别关键词。mysql支持不是太好,一般用第3方的搜索引擎来解决 elasticsearch工具完成搜索;FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以
索引优点:
- 查询快,大大加快数据的检索速度;
- 创建唯一性索引,保证数据库表中每一行数据的唯一性;
- 加速表和表之间的连接;
- 在使用分组和排序子句进行数据检索时,可以显著检索查询中分组和排序的时间。
索引缺点:
- 索引需要占物理空间,增删改的频率大于查询的频率时,不建议使用索引;在不必要的字段上加索引的话性能是很差劲的。
- 当对表中的数据进行增加,删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
1)B+索引和Hash索引的区别:
B+索引的数据结构是红黑树,查询的时间复杂度是Ologn级别的 Hash索引的存储数据结构是哈希表,查询时间复杂度是O(1)级别的,
我们之所以用B+索引是因为Hash无序,不支持范围查找和排序功能
2)主键索引和普通索引的区别:
平时我们用索引的时候 进来用主键查询:因为主键索引的data存的是那一行的数据(innodb引擎),而普通索引(辅助索引)的data存的是主键,需要通过主键回表再次查询
4、写出为workplan表title字段创建普通索引的SQL。
创建索引
create index index_name on table_name(column_name)EX:
create index index_id on workplan(title asc)修改表结构(添加索引)
alter table table_name add index index_name(column_name)EX:
alter table workplan add index index_id(title asc)创建表时,直接指定索引
create table table_name(id int not null,username varchar(64) not null,index [index_name] (username)
);删除索引
drop index [index_name] on table_name
相关文章:
【第二套】Java面试题
第二套: 一、JavaScript前端开发 1、下列的代码输出什么? var y 1; if(function f(){}){y typeof f; } console.log(y);正确的答案应该是 1undefined。 JavaScript中if语句求值其实使用eval函数,eval(function f(){}) 返回 function f()…...

CSS3 实现边框圆角渐变色渐变文字效果
.boder-txt {width: 80px;height: 30px; line-height: 30px;padding: 5px;text-align: center;border-radius: 10px;border: 6rpx solid transparent;background-clip: padding-box, border-box;background-origin: padding-box, border-box;/*第一个linear-gradient表示内填充…...
第二天 kali代理配置
文章目录 环境一、虚拟机网络模式(1)NAT(2)NAT模式(3)桥接模式(4)仅主机模式(5)总结 二、配置代理(桥接模式)1、基础设置2、虚拟机浏览…...
stable-diffusion-webui汉化教程
第一种方法 1.打开stable diffusion webui,进入"Extensions"选项卡 2.点击"Install from URL" 3、注意"URL for extension’s git repository"下方的输入框 4、填入地址:https://github.com/VinsonLaro/stable-diffus…...
热备盘激活失败导致raid5阵列崩溃的服务器数据恢复案例
服务器数据恢复环境: 一台Linux Redhat操作系统服务器上有一组由5块硬盘组建的raid5阵列,包含一块热备盘。上层部署一个OA系统和Oracle数据库。 服务器故障: raid5阵列中的1块磁盘离线,硬盘离线却没有激活热备盘,直到…...
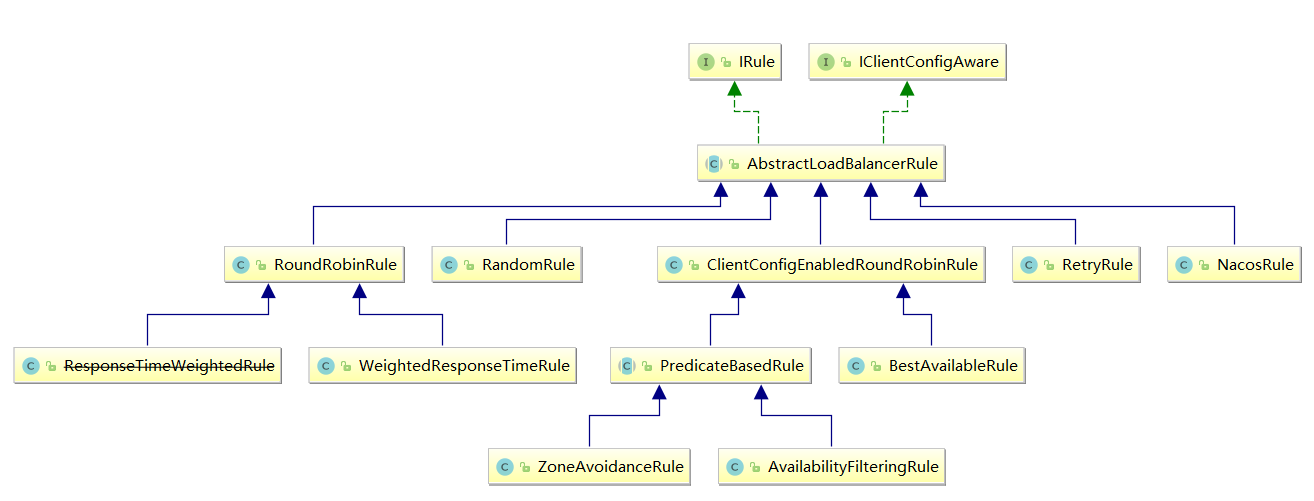
【ribbon】Ribbon的负载均衡和扩展功能
Ribbon的核心接口 参考:org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration IClientConfig:Ribbon的客户端配置,默认采用DefaultClientConfigImpl实现。IRule:Ribbon的负载均衡策略,默认采用ZoneA…...
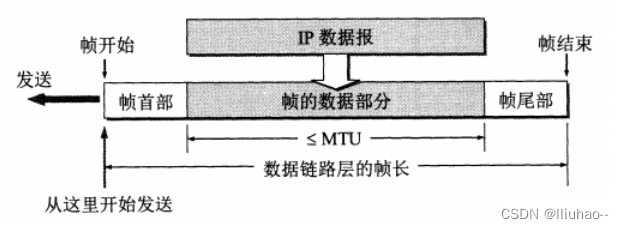
数据链路层是如何传递数据的
数据链路层是如何传递数据的 数据链路层功能概述封装成帧透明传输差错控制 数据链路层功能概述 数据链路层的主要作用就是加强物理层传输原始比特流的功能。其负责将物理层提供的可能出错的物理连接,改造成逻辑上无差错的数据链路。 数据链路层包括三个基本问题&a…...

积分规划:构建全面的会员积分管理系统
在现代私域营销中,会员积分管理系统是提升用户忠诚度和增加用户参与度的关键工具。通过建立全面的会员积分管理系统,企业可以吸引更多用户参与,提高用户活跃度,并在竞争激烈的市场中保持竞争优势。本文将详细介绍如何进行积分规划…...
)
amd的cpu有哪些型号(amd的cpu系列介绍)
1、amd处理器有什么系列? 2、AMD各系列CPU和对应的主板型号有哪些? 3、AMD双核CPU有哪几个型号? amd处理器有什么系列? amd处理器的系列有: 1、锐龙:AMD Ryzen是AMD开发并推出市场的x86微处理器品牌,AMD Zen微架构…...

网络安全(黑客)自学——从0开始
为什么学习黑客知识?有的人是为了耍酷,有的人是为了攻击,更多的人是为了防御。我觉得所有人都应该了解一些安全知识,了解基本的进攻原理。这样才可以更好的保护自己。这也是这系列文章的初衷。让大家了解基本的进攻与防御。 一、怎…...

uniapp使用uni-swipe-action后右侧多了小于1px的间隙
问题:uniapp使用uni-swipe-action后右侧多了小于1px的间隙。且在真机上没有问题,但是在微信开发者工具中有问题。 代码如下:在滑动滑块或者点击这个区域时,就会出现问题。 <scroll-view :scroll-y"true" :style&quo…...

随手笔记——演示如何提取 ORB 特征并进行匹配
随手笔记——演示如何提取 ORB 特征并进行匹配 说明知识点源代码 说明 演示如何提取 ORB 特征并进行匹配 知识点 特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。 ORB 特征亦由关键点和描述子两部分组成。它的关键…...

Python访问者模式介绍、使用
目录 一、Python访问者模式介绍 二、访问者模式使用 一、Python访问者模式介绍 访问者模式(Visitor Pattern)是一种行为型设计模式,它能够将算法与对象结构分离,使得算法可以独立于对象结构而变化。这个模式的主要思想是&#…...

深度学习实际使用经验总结
以下仅是个人在使用过程中的经验总结,请谨慎参考。 常用算法总结 图像分类 常用算法(可作为其他任务的骨干网络):服务端:VGG、ResNet、ResNeXt、DenseNet移动端:MobileNet、ShuffleNet等适用场景&#x…...

【广州华锐互动】AR智慧机房设备巡检系统
AR智慧机房设备巡检系统是一种新型的机房巡检方式,它通过使用增强现实技术将机房设备、环境等信息实时呈现在用户面前,让巡检人员可以更加高效地完成巡检任务。 首先,AR智慧机房设备巡检系统具有极高的智能化程度。该系统可以根据用户设定的…...
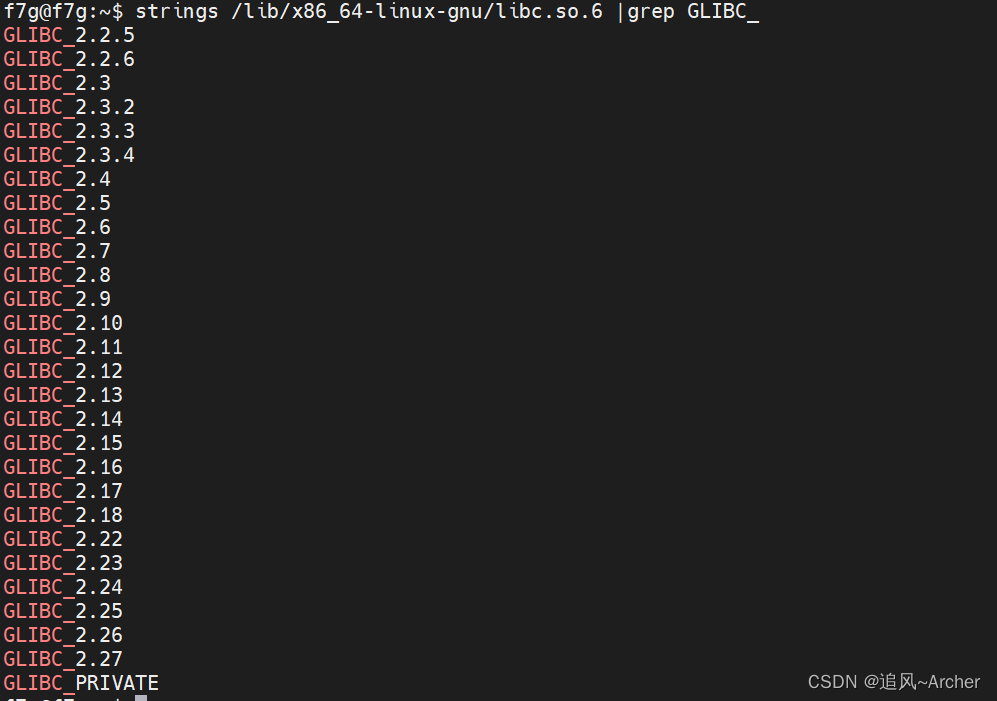
关于Ubuntu 18.04 LTS环境下运行程序出现的问题
关于Ubuntu 18.04 LTS环境下运行程序出现的问题 1.运行程序时出现以下情况 2.检查版本 strings /lib/x86_64-linux-gnu/libc.so.6 |grep GLIBC_ 发现Ubuntu18.04下的glibc版本最高为2.27,而现程序所使用的是glibc2.34,所以没办法运行, 3.解决办法 安装glibc2.34库, …...
「苹果安卓」手机搜狗输入法怎么调整字体大小及键盘高度?
手机搜狗输入法怎么调整字体大小及键盘高度? 1、在手机上准备输入文字,调起使用的搜狗输入法手机键盘; 2、点击搜狗输入法键盘左侧的图标,进入更多功能管理; 3、在搜狗输入法更多功能管理内找到定制工具栏,…...
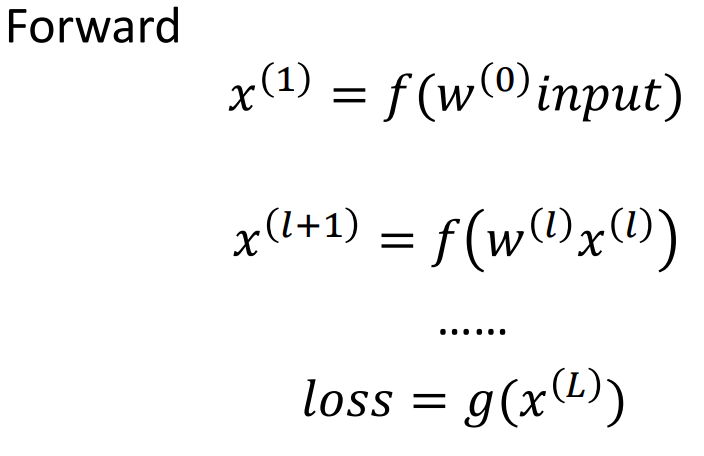
【人工智能】神经网络、前向传播、反向传播、梯度下降、局部最小值、多层前馈网络、缓解过拟合的策略
神经网络、前向传播、反向传播 文章目录 神经网络、前向传播、反向传播前向传播反向传播梯度下降局部最小值多层前馈网络表示能力多层前馈网络局限缓解过拟合的策略前向传播是指将输入数据从输入层开始经过一系列的权重矩阵和激活函数的计算后,最终得到输出结果的过程。在前向…...

一个tomcat部署两个服务的server.xml模板
一个服务的文件夹名字叫hospital,一个服务的文件夹叫ROOT,一个tomcat运行两个服务如何配置呢?注意一个appBase为webapps,另一个appBase为webapps1,当然也可以放在一个webappps里面。 <Service name"Catalina">&l…...

CentOS 7安装Docker
文章目录 安装Docker1.CentOS安装Docker1.1.卸载(可选)1.2.安装docker1.3.启动docker1.4.配置镜像加速 2.CentOS7安装DockerCompose2.1.下载2.2.修改文件权限2.3.Base自动补全命令: 3.Docker镜像仓库3.1下载一个镜像 安装Docker Docker 分为 …...

新手入门:用快马生成第一个交易平台风格的前端页面
今天想和大家分享一个特别适合前端新手的练手项目——用InsCode(快马)平台快速搭建一个简易的交易平台前端页面。作为一个刚接触金融科技开发的小白,我发现这种模拟真实业务场景的项目特别能激发学习兴趣。 项目目标拆解 这个模拟交易账户页面需要实现几个核心功能模…...

新手友好:基于快马平台快速上手dhnvr416h-hd设备数据监控开发
新手友好:基于快马平台快速上手dhnvr416h-hd设备数据监控开发 最近在做一个物联网项目,需要对接dhnvr416h-hd设备的数据监控功能。作为刚接触这个领域的新手,我发现理解设备数据格式和通信流程是最关键的第一步。好在通过InsCode(快马)平台的…...
)
从查表到公式:PT100温度转换的两种实现(附STM32+MAX31865完整代码)
从查表到公式:PT100温度转换的两种实现(附STM32MAX31865完整代码) 在工业测量和精密温度控制领域,PT100铂电阻因其出色的稳定性和线性度成为温度传感的首选。当工程师通过MAX31865芯片获取到PT100的电阻值后,如何高效准…...

LC_numStream:嵌入式轻量级数字流解析库
1. LC_numStream 库概述:面向嵌入式通信的轻量级数字流解析工具LC_numStream 是一个专为资源受限嵌入式系统设计的纯 C 语言文本数字流解析库。其核心定位并非通用字符串处理,而是解决嵌入式设备在串口、UART、I2C、SPI 或自定义协议通信中高频出现的一类…...

Phi-4-mini-reasoning应用场景:AI编程教练中算法题逻辑拆解与反馈生成
Phi-4-mini-reasoning应用场景:AI编程教练中算法题逻辑拆解与反馈生成 1. 模型介绍 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑分析的场景。与通用聊天模型不同,它被设计用来解决数学题、逻辑题等需…...

解码器精准调优:LoRA赋能Depth-Anything-V2实现绝对深度估计
1. LoRA技术如何革新Depth-Anything-V2的深度估计 当我在实验室第一次尝试用LoRA微调Depth-Anything-V2时,意外发现只需要调整解码器中1x1卷积层的极少量参数,就能让相对深度模型输出精确的绝对深度值。这就像给一个只会判断"远近"的模型突然装…...

智慧小区网络设计避坑指南:华为设备选型、无线覆盖与安全策略实战解析
智慧小区网络设计实战:华为设备选型与无线覆盖避坑指南 当接到智慧小区网络建设项目时,很多工程师会陷入理论完美主义陷阱——画出漂亮的拓扑图,却在实际部署中遭遇信号死角、设备过载、策略冲突等现实问题。本文将从三个真实项目复盘出发&am…...

input-overlay多语言支持:如何为全球观众轻松定制直播输入显示
input-overlay多语言支持:如何为全球观众轻松定制直播输入显示 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 想要让全球观众都能轻松理解你的游戏操作吗&a…...
和业务范围(Business Area)都是用于内部管理报告的组织单元,但它们在设计理念、功能和应用上存在显著区别。简单来说,利润中心是更现代)
在 SAP 系统中,利润中心(Profit Center)和业务范围(Business Area)都是用于内部管理报告的组织单元,但它们在设计理念、功能和应用上存在显著区别。简单来说,利润中心是更现代
在 SAP 系统中,利润中心(Profit Center)和业务范围(Business Area)都是用于内部管理报告的组织单元,但它们在设计理念、功能和应用上存在显著区别。简单来说,利润中心是更现代、更灵活、功能更强…...

ARM Cortex-M嵌入式通用头文件sarmfsw深度解析
1. sarmfsw项目概述sarmfsw(ARM-based Common Headers)是一个面向ARM Cortex-M系列微控制器的轻量级、跨平台通用头文件集合。它并非传统意义上的功能库,而是一套经过工程验证的类型定义(typedefs)、宏(mac…...